Lora模型训练-koya SS GUi
前提
现在大部分 AI 产品采用的的大模型(dreamboth),但是在产品的训练中也发现了不仅仅需要较大的内存还需要好的 GPU 成本较高,而且模型较大修改只能重新训练不能修改,为了解决这个问题开始推荐 lora 小模型时代.接下来讲解 lora 模型以及使用小模型(lora)的Koya.SS.GUI的流程.
关于Koya.SS.GU的使用教程后期会慢慢讲出来,后面的所有理论或者是英文后面都会给解释.
补充 2 个概念"扩散模型"与"微扩散模型"
首先讲一个基础概念"扩散模型"与"微扩散模型",在机器学习的流程是AI将图片马赛克化,并且提取图片或者是文本的特征,然后结合网络上或者是现有的模型进行绘图.
扩散模型:
一种用于描述某些物质或现象在空间和时间上传播或扩散的数学模型。扩散模型通常基于一些基础假设,如扩散物质的性质、扩散介质的特性、扩散过程中的环境影响等因素,以及一些已知的实验数据或观察结果。扩散模型可以帮助科学家和工程师预测和控制许多现实世界中的扩散现象。
扩散模型虽然在研究物质或现象在空间和时间上的传播和扩散方面具有重要意义,但是也存在一些缺点,下面是几个主要的缺点:
- 假设条件过于简化:扩散模型通常基于一些假设条件,如扩散物质的性质、扩散介质的特性、扩散过程中的环境影响等,这些条件往往过于简化,不能完全反映实际情况。
- 参数难以确定:扩散模型需要大量的实验数据和观测结果来确定模型的参数,但是这些数据和结果往往受到许多因素的影响,如实验条件、观测误差等,使得参数难以准确确定。
- 预测精度有限:由于扩散模型往往是基于简化的假设条件和参数估计,所以其预测精度有限,不能完全准确地描述实际情况。
- 无法考虑复杂的非线性效应:扩散模型通常是基于线性扩散方程建立的,不能考虑复杂的非线性效应和反应,如化学反应、生物反应等。
- 受到空间和时间尺度的限制:扩散模型通常是基于一定的空间和时间尺度建立的,不能完全描述微观和宏观尺度上的扩散现象。
随着 AI 技术的发展,为了解决dreamboth,逐步的使用了微扩散模型
微扩散模型
是一种描述粒子在随机环境中运动的数学模型。它通常被用来研究一些复杂系统的动力学行为,如生物群体的扩散、金融市场的波动等。该模型假设粒子在空间中随机游走,并且在每个时间步长内以一定的概率跳到相邻的位置。这个概率是根据粒子周围环境的特征来确定的。微扩散模型的数学形式通常是一个随机微分方程,可以使用随机模拟的方法来模拟粒子的运动行为。
微扩散模型是一种数学模型,它主要用于研究物理、化学、生物等领域中的扩散现象。与传统的扩散模型相比,微扩散模型具有以下几个优点:
- 能够更准确地描述扩散过程中的非线性效应:传统的扩散模型通常假设扩散系数为常数,但实际上扩散系数往往与溶液浓度、温度等因素有关,因此具有非线性特性。微扩散模型可以考虑这些因素对扩散系数的影响,从而更准确地描述扩散过程中的非线性效应。
- 能够考虑扩散过程中的纳米尺度效应:传统的扩散模型通常假设扩散过程是一种连续的、平滑的过程,但实际上在纳米尺度下,扩散过程会受到表面效应、界面效应等因素的影响,因此具有非连续、非平滑的特性。微扩散模型可以考虑这些因素对扩散过程的影响,从而更准确地描述扩散过程中的纳米尺度效应。
- 能够更好地预测扩散过程中的异常行为:在某些情况下,扩散过程中可能会出现异常行为,比如出现扩散的逆向流动、出现非高斯分布等现象。传统的扩散模型无法很好地解释这些异常行为,而微扩散模型可以通过考虑扩散过程中的各种非线性、非连续、纳米尺度效应等因素来解释这些异常行为。
用简单的话来说就是就是更加的丝滑还能够更佳精准的描述.
而现有很多大模型都是使用的是扩散模型像(dreamboth),而小的像 lora 等用的是微扩散模型.
为什么选择选择 lora模型?
lora 是一种使用图像训练自己的主题方法,该图像针对于小型显卡进行的优化,这意味着与Drembetch 语文本反转相比,可以只要训练一个只有 6 到 7GB的 VRAM 的主题 ,这个对于没有好的 GPU的所有人是一个超级好的消息,基本上 lora 有点像 drembooth 和 文本反转之间的创建的这些100M 字节的小文件,可以使用与文本新版本侵入式完全相同的方式
vram:视讯随机存取记忆体,这里可以理解为一个随时可以调用的数据
文字反转:在某些机器学习模型中,文字反转指的是将输入的文本数据进行反转操作,以增加模型的鲁棒性和泛化能力。具体来说,将输入文本进行反转操作后,可以使模型学习到输入文本中不同顺序的特征表达,从而提高模型对于输入数据的理解和泛化能力。----这里可以理解为是一种抽离特征并且进行训练的方式
为什么推荐Koya.SS.GUI
koya.ss.gui 是一款超级酷的软件 非常易于使用,可以在其中训练 loar模型并且降低检查点和纹理反转嵌入甚至微调模型.而且操作上也是比较简化的.
接下来就讲讲训练的流程
训练流程
训练前提
你将确保你安装了 python 和git2 个软件,python 主要是负责搜索 git 主要是负责下载模型.
如果你已经安装了,安装稳定之后,他就应该已经在那里,推荐 NVIDIA 的30 或者 40 系列的显卡.低一些的也可以带得动.
图像准备
准备高质量的图像的并且图像有很多变化,所以你有不同角度的变化,不同的角度的不同灯光确保至少有 10 张,,拥有少量高质量的比大量低质量图像更好,那么你可以使用像:berm.net这样的网站将,图像大小调整为 512*512 分辨率,尽管分辨率较低你不一定调整任何图像的大小,可以使用任何分辨率的图像,但如果你不自信,可以在 SD 中,或者是 koyaGUi中通过进入实用程序来完成这个步骤,然后相信它基本会做能完全相同的事情,将分析每张图片.
然后创建与图片同名的文本文件,然后对于每张图片,您可以收订修改提示词,以至于它能够完美的描述图片,要输入你模型的名称,提示看起来像你的模型,但是如果你想要更精准的提示,你可以地在标题的开头输入模型的名字,
你的角色名字,你的角色的名字在较低的嵌入中,将链接在一起,但是如果不想这么做这也没什么大不了的.这取决于您,所以既然我们的图像已经准备好了,我们将不得不创建一个特定的文件夹结构,所以这也是不同的地方.
与dreamboth训练相比,但相当简单,每一张图片至少要训练 100 步骤,每一组图片至少要训练 1500 步,你将要 1500 除以你拥有的图像数量,会给你 150 个,这个数字是需要输入到文件夹名称中每张图像的训练样式的数量,因此为此你要右键右键 150 步(决定每一个训练步骤的数量),假如说后期添加图片的话所有数据需要需要进行计算(但是这个数字至少是 100).
导入文件
首先涉及到了 2 个文件:Json 与 Lora,第二个你如果 vram 少于 8GB 你可以使用点击配置文件
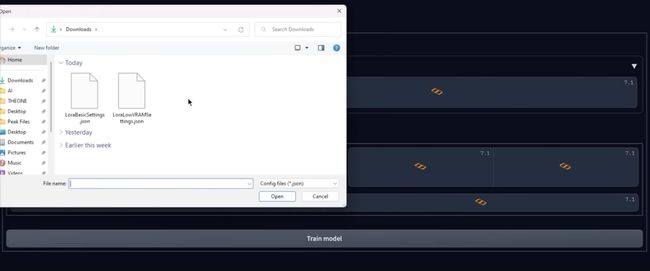
按钮点击打开然后选择这个 2 个文件之一,所以我这里只选择基本配置,文件然后点击
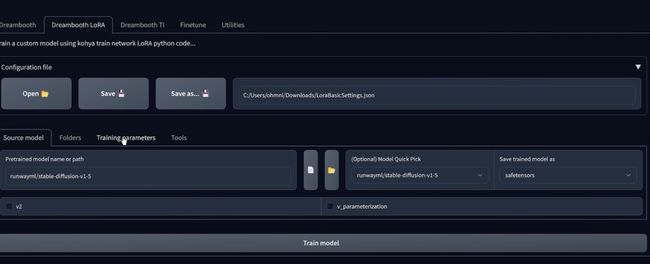
文件然后点击,如果你训练参数,你可以看到其中一些选项已经为你完成了,这些是适用于劳拉
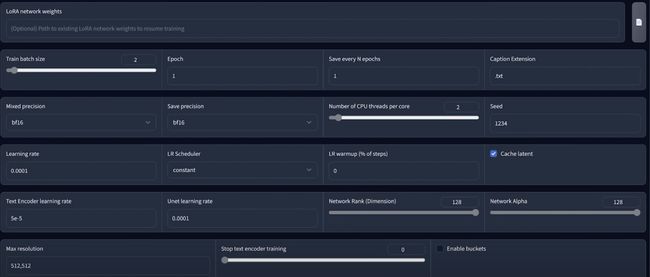
首选修改训练中的填充让我们实际选择.
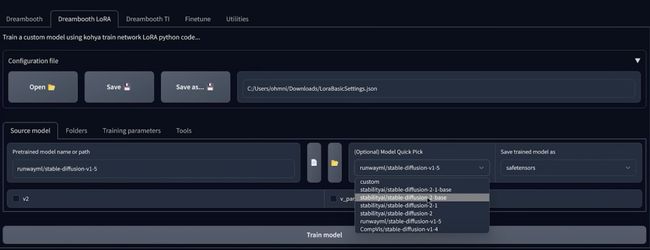
常规的有:1.4 1.5 2.0 2.1 512*512和 2.1 512*512.如果你选择一个在这些模型汇总,它将自动将从 GitHub并且还会根据您选择的模型选择的一些选项,因此您如果选择例如 1.5 ,将会看到此复选项框不会被选中,因为这不是 V2 模型,但是你选择 2.0 基础,会看到这个复选框现在被选中,如果你选择
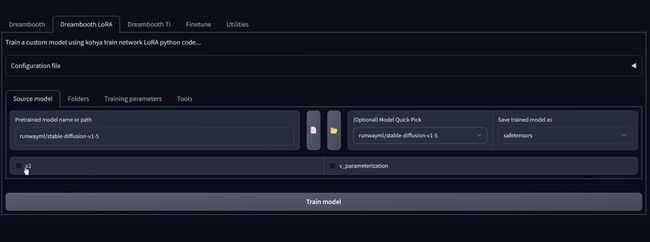
选择 2.0 768 版本,你会看到现在这个 V 参数化,复选框也会被选中,现在你需要记住这些复选框,
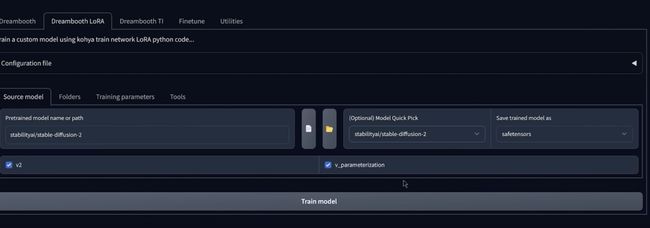
因为如果来这里并且单击自定义,您设计上可以选择自己的模型,如果您选择自定义模型的,则需要知道它基于什么模型的来源.
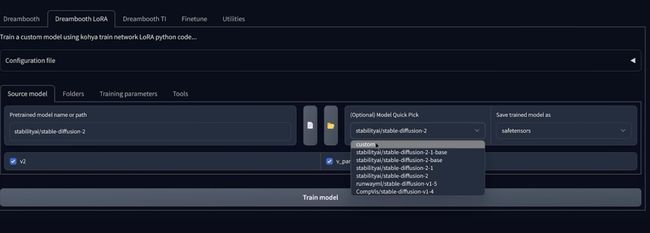
但是我知道是来源于哪个模型的话,就在此处选择复选框,如果它.这一步是稳定扩散模型最安全的扩散,所以只要您有选择,就选择保存的结果
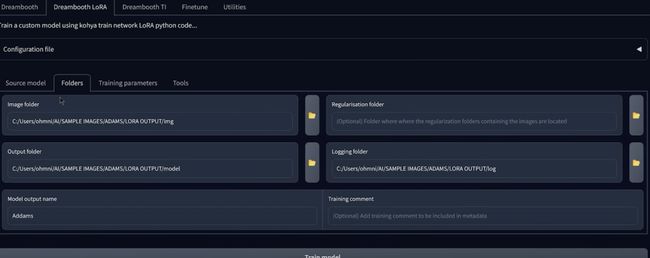
输入文件夹路径
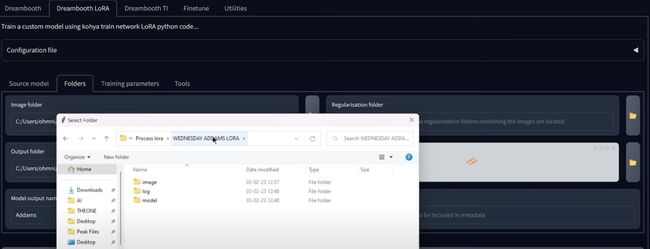
文件夹和相同,一旦添加了UPS lora然后同步文件夹,现在还可以选择一个正则化文件夹,
正则化(Regularization)是一种常用的机器学习技术,用于防止模型过拟合和提高模型的泛化能力。正则化的基本思想是在模型的损失函数中加入一个正则项(Regularization Term),用于惩罚模型的复杂度,从而限制模型参数的大小和数量。 常用的正则化方法包括L1正则化、L2正则化和弹性网络正则化
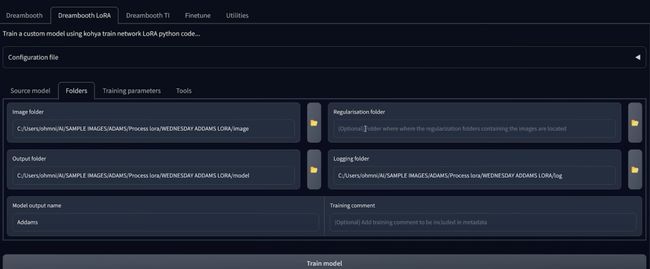
可以防止正则化图像,单对于较低级别的训练,您实际上并不需要正则化图像,因为无论如何您都讲将训练一个主题,所以在这里你要输入模型输出名称,所以录入信息
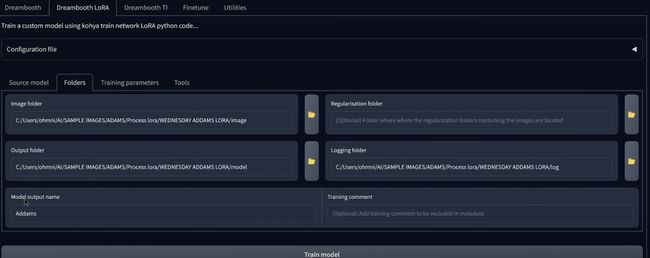
已经架子了你没有的配置文件之后,如果你现在想开始训练,实际上需要出触摸到任何东西,你你所要做的就是点击训练模型按钮,你就完成了
完成
训练完成之后,进入到模型文件夹,你会在这里看待你最终保存的张力文件,并在你要选择的稳定扩散模型中使用它.复制他到 UI 文件夹子 lora 中,然后将文件粘贴进去,然后就可以启用稳定扩散模型.
还需要安装一个特殊扩展,为此
可以点击扩展选择可用负荷
然后你会向下滚定并寻找 Konya SS额外的网络然后点击安装

点击安装然后点击应用并重启 UI
当看到额外的网络选项卡,这意味着扩展已经正确安装,然后最终在提示中使用 lora,将选择型号编写新的提示词,然后您将在此处单击
显示额外的网络,然后后选择模型,正如你所看到的,拥有的我们之前创建的所有较低权重,如果想用其中的一种单击一个就好
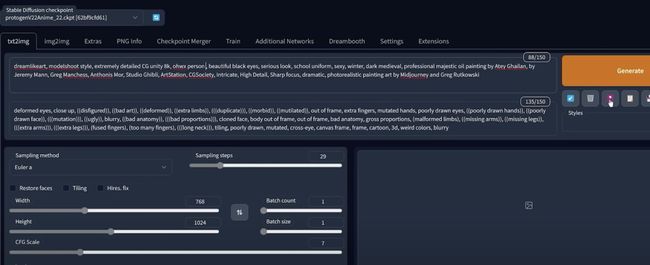
划线的关键词完全可以进行替换,以模板的形式适配不同的形式.
注意点
CUP 较弱的话
如果你的 GPU 较弱的话建议启用内存注意点以及梯度检查点,这个可能会增加训练时间,但也会使用更少的 vram.
模型混用
可以调用其他的 lora 的模型进行混用,不过要设置相关的权重,还有要使用相同的种子模型才可以.
一次要训练的图像数量
数字越大,训练速度越快,因为您基本上讲训练步骤的数量除以该数字,但是你没有很多,这里有一些如果你这里只有 10 或者是 15 的话,建议你选择 1 批量大小,他实际会提高一点训练质量,当然这可能需要更长的训练时间,但最终的结果是值得的,当然更高批次大小也会增加用于训练的vram 的数量,所以你的显卡较弱的话,我建议你讲批量大小设置为 1,否则默认状态下将其保留 2,所以当涉及到这里的所有内容时,我们将默认白柳所有的内容学习率非常,你不用改变任何内容.
关于训练的最大分辨率:
如果你只有 512*512 张图片的话,如果可以的话,这是我的建议,如果你有一个好的 GPU 而不是 512*512,请请尝试 768*768 分辨率训练它,你讲使用更多 vram 但是你有高质量的图像你的最终模型会看起来更好,否则如果你有一个较弱的 GPU 只需要将它保留在 512*512 默认情况下.
总结
模型训练是一个时间长且复杂的过程,需要不断地投入到时间/经历/设备成本,还需要训练师的耐心.一旦能到 1.0 版本之后,就可以慢慢进行调试才能出结果.