redis 字典的实现
1.数据结构
节点数据结构
因为是基于开链法的哈希表实现,所以需要维护了一个next节点
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;复制
哈希表数据结构
其中size是当前哈希表的大小,used是当前使用的大小,size会根据当前used的大小来做相应的调整,调整的过程就是字典动态扩容的过程,具体过程下面会描述。sizemask=size-1,是用来做掩码的,哈希算法算出的index,通过index&sizemask操作来代替除留余数,这么做的原因是&操作比%更快。
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;复制
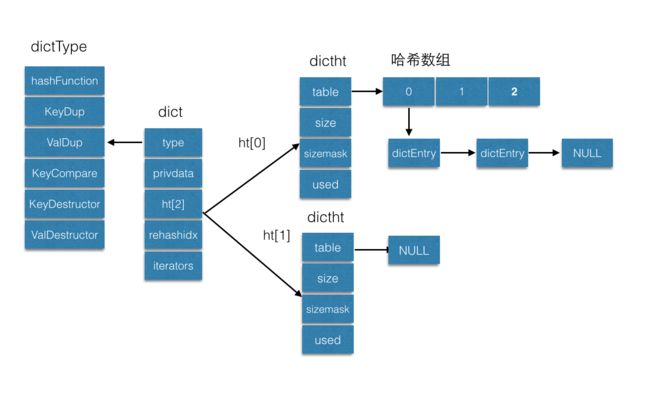
字典数据结构
type是函数指针类型,封装了哈希函数,key比较函数,释放内存函数等等。一个高效的哈希函数能保证哈希的结果尽量均匀分布,redis中的字符串哈希算法便是著名的开源算法MurmurHash2,但是因为上层的有不同的数据结构,所以实现了不同的哈希函数。字典中维护两张哈希表,主要是用来做动态rehash的,rehashidx便是两张表动态rehash的索引。iterators是当前迭代器的个数,具体后面会详细介绍。
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
int iterators; /* number of iterators currently running */
} dict;复制
字典定义整体的结构图如下:
2.特性介绍
redis的字典实现了很多特别的东西,花式造轮子的根本原因还是从时间与空间上做考量。
动态扩容/缩容
redis的数据都是放在第一张哈希表中ht[0]中的,所谓的动态扩容就是说ht[0]那张哈希表快不够用的时候,目前是used/size > 5的时候,使用ht[1]来扩大哈希表的容量。这其中有两种方式,一种是redis提供了显示的扩容的接口dictExpand,供外部调用,另外一种是在添加数据的时候调用_dictExpandIfNeeded,以此来判断是否需要扩容。缩容就是当前哈希表使用率 used/size 低于某个值时,目前这个值是10%,利用ht[1]缩小哈希表的容量。扩容和缩容的操作就是rehash的过程。
rehash+渐进式
rehash就是将第一张ht[0]的数据迁移到ht[1]的过程,rehash实现了两种策略,一种是在定时器的每个tick里面,执行databasesCron操作的时候,还有一种是在增加查找删除等字典操作的时候执行,这样的过程可以保证rehash的时候不会阻塞redis服务器,对用户来说,也是无感知的。rehash的过程中维护了一个索引,就是上面介绍的字典结构中的rehashidx,使用这个索引遍历ht[0],将数据无缝迁移到ht[1]。因为在rehash中的任何时刻,一个节点只能存在其中一张哈希表中,所以每次操作都需要处理两张表。
迭代器
redis里面的字典实现了两种迭代器,一种是安全的迭代器,一种是普通的迭代器。所谓安全就是指在迭代的过程中可以执行添加查找等操作,非安全的迭代器就是只能执行迭代操作。其实本质上就是安全的迭代器会给dict设置iterators++(dict里面的变量),这样字典的各种操作就不会执行rehash操作,如果在迭代的过程中执行了rehash,迭代索引就会错乱。
3.接口介绍
dict *dictCreate(dictType *type, void *privDataPtr);复制
创建字典,目前redis中用到字典的地方有很多,包括全量的key,超时的key等等db中的kv, 命令回调表,hash结构,set结构,sortset结构等等。
int dictAdd(dict *d, void *key, void *val);复制
添加数据,前面说到会执行rehash操作,并且如果字典底层正在rehash,索引的计算会读取两张表来判断,并且数据只会添加到第二张表里面。
dictEntry *dictFind(dict *d, const void *key)复制
查找数据,和添加数据很类似,唯一的区别是查找数据的时候不会计算是否需要扩容。
int dictDelete(dict *d, const void *key);复制
删除数据,和添加数据的过程类似,但是在删除数据的过程中不做缩容操作,缩容是上层负责主动调用缩容接口htNeedsResize和dictResize。
dictEntry *dictNext(dictIterator *iter)复制
迭代字典,搭配dictGetIterator或者dictGetSafeIterator操作,前面有说到安全迭代器和非安全迭代器的区别,非安全的迭代器在初次迭代的时候会计算一个哈希值,释放迭代器的时候assert这个哈希值是否被改变了。
总结
redis字典的实现有很多有趣的特性,包括动态扩容缩容,渐进式rehash等,所有这些特性的出发点都是基于充分使用内存的角度去考虑。