4.多线程之JUC并发编程1
1.List集合类不安全(以前单线程永远是安全的,多线程集合就不安全了)
都是ConcurrentModificationException并发修改异常,在有sout输出的情况下出来的,因为多线程边读边写
//并发情况下ArrayList是不安全的 可以用Vector在jdk1.0出来的,List1.2出来的加了同步锁
- List list=new Vector<>(); //使用数组长度++还有一种就是判断数组长度,采用复制相同数组
- List list =Collections.synchronizedList(new ArrayList<>());//把他变安全
- 写入时复制,比Vector重锁效率高,使用可重入锁,读写分离避免覆盖 COW(Copy-on-write)是计算机程序设计领域的一直以来的优化策略(读写分离)
List list =new CopyWroteArrayList(); //先复制给一个数组长度+1,再设置list的数组
public class CopyOnWriteList1 {
public static void main(String[] args) {
List<String> ls = new CopyOnWriteArrayList<>();
for (int i = 0; i <100 ; i++) {
new Thread(()->{
ls.add(UUID.randomUUID().toString().substring(0,5));
System.out.println(ls);
System.out.println(ls.size());
},String.valueOf(i)).start();
}
}
}
//他的add源代码分析
public boolean add(E e) {
final ReentrantLock lock = this.lock; //使用可重入锁
lock.lock();
try {
Object[] elements = getArray(); //得到之前存的数组
int len = elements.length;//得到之前数组长度
Object[] newElements = Arrays.copyOf(elements, len + 1); //复制之前的object数组(为了适配传进来的泛型类型),复制到另外一个数组并长度变长1
newElements[len] = e; //把新数组赋值
setArray(newElements); //设置当前数组(替换掉之前的数组)
return true; //处理完成
} finally {
lock.unlock(); //解锁
}
}
//之前没有看过 这种,可以理解为只是一个泛型函数全部用泛型操作
public static <T> T[] copyOf(T[] original, int newLength) {
return (T[]) copyOf(original, newLength, original.getClass());
}
//代表用了T和U的泛型,-_-看不懂先跳过
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) {
@SuppressWarnings("unchecked")
T[] copy = ((Object)newType == (Object)Object[].class) //对比了是否有null
? (T[]) new Object[newLength]
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
}
2.Set不安全 (和list没有区别) hashMap使用散列表结构
Set<String> set =Collections.synchronizedList(new HashSet<>());
Set<String> set =new CopyWroteArraySet();
//HashSet的底层实现是HashMap ,因为map是不可重复的,所以set放入的值00不重复
//源代码
public HashSet() {
map = new HashMap<>();
}
//装载因子0.75
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
//
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true); //对key进行hash计算
}
原码(反码,补码):00000000 00000000 00000000 00000010
右移一位(最左边一位添0)
结果: 2
原码(反码,补码):00000000 00000000 00000000 00000001
结果:1
//为了避免hash碰撞,无符号右移(二进制忽略正负号),异或 ^ 是不相同的就为1 比如 1^1=0 1^0=1
static final int hash(Object key) {
int h; //key为空 hash为0,
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
3.Map也不安全(最大容量16和默认加载因子0.75)
//企业不用 Map m=new HashMap(); //而使用下面代码,去看源码
Map<String,String> map =new ConcurrentHashMap<>(); //用了 synchronized 同步锁
4.Callable 可返回值和抛出异常方法不同 call() Runnable是run()
如图relationship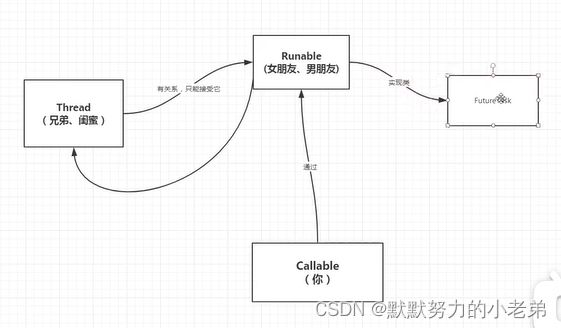
//因为Thread已经设计好了,不能增加代码,所以间接使用FutureTask(Runable的实现类)创建Runable给Thread
- MyThread类实现 Callable 修改call()的返回值为Integer
- 运行main
MyThread thread=new MyThread();
FutureTask ft=new FutureTask(thread); //这个是为了Thread程序拓展增加的类
new Thread(futureTask,"a").start();
new Thread(futureTask,"b").start();//坑 会有缓存,之前的结果
//得到返回值
Interger o=(Integer)ft.get();//可能产生阻塞,最好放最后一行,或者异步通信
public class CallableTest {
public static void main(String[] args) {
FutureTask<String> stringFutureTask = new FutureTask<>(new MyCallable());
Thread thread = new Thread(stringFutureTask);
thread.start();
String s = null;
try {
s = stringFutureTask.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
System.out.println(s);
}
}
class MyCallable implements Callable<String>{
@Override
public String call() throws Exception {
return "aaa";
}
}
-----------必须要学会的工具----------
5.CountDownLatch 是一个减法计数器 latch门栓
//用在必须要执行的任务上,6个学生全部出教室才关门
CountDownLatch count=new CountDownLatch(6);
//多线程时候 数量-1
count.countDown();
count.await();//等待计数器归0才向下执行
public class CountDownLatch1 {
public static void main(String[] args) {
CountDownLatch countDownLatch = new CountDownLatch(6);
for (int i = 0; i < 6; i++) {
new Thread(()->{
countDownLatch.countDown();
System.out.println("after"+countDownLatch.getCount());
}).start();
}
try {
//全部执行完,才执行这里,可以用在执行指定的任务个数后关闭连接
countDownLatch.await();
System.out.println("全部出去了");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
6.CyclicBarrier是一个加法计数器,还可以完成后执行一个线程
//集齐7颗龙珠召唤神龙
CyclicBarrier cyc=new CyclicBarrier(7,()->{sout("召唤神龙成功")});
for(int i=1;i<=7;i++){
//lambda拿不到i的值,因为它本身是一个类,需要final变量才能拿到
final int temp=i;
new Thread(()->{
cyc.await(); //每执行一次+1,没有达到数量不执行结果
}).start()l
}
//执行结果 先执行 集齐七龙珠释放神龙 后执行线程的东西,
7.信号量 Semaphore 抢3个车位,先抢到acquire后等待,后释放
作用:多个共享资源互斥的使用,并发限流,控制最大的线程数
Semaphore sm= new Semaphore(3);
fori6
new Thread(()->{
sm.acquire();//如果满了其他线程等待
TimeUnit.SECONDS.sleep(2);
finally{
sm.release();//释放;信号量+1,唤醒等待线程
}
})
public class Semaphore1 {
public static void main(String[] args) {
Semaphore sm = new Semaphore(3);//限制有3个线程进入,如果其中有线程退出,其他线程立即可以加入,做限流
for (int i = 0; i < 6; i++) {
new Thread(()->{
try {
sm.acquire();//信号量满等待
System.out.println(Thread.currentThread().getName()+"抢到车位");
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
sm.release();//信号量+1 其他线程可以进来
}
}).start();
}
}
}
8.ReadWriteLock读写锁 (读可以多个线程读[共享锁],写只能一个线程写[独占锁]) 可重入锁的一种
//自定义缓存 读-读可以共存 读-写不能共存 写-写不能共存
private volatile Map<String,Object> map=new HashMap<>();
//读写锁可以更细粒度的控制 可以提高程序性能
private ReadWriteLock readWriteLock=new ReenrantReadWriteLock();
//和普通的与普通的ReentrantLock()区别,可以细粒度控制读写分离
//写的方法
readWriteLock.writeLock().lock
try{ //业务
}finally{ readWriteLock.writeLock().unlock();}
//读的方法 ,可以乱序访问
readWriteLock.readLock().lock
try{
//业务
}finally{ readWriteLock.readLock().unlock();}
9.阻塞队列 FIFO (和List和Set同级 不是新东西)
图与Collection的关系
Deque双端队列(两边可以插入)
AbstractQueue非阻塞队列
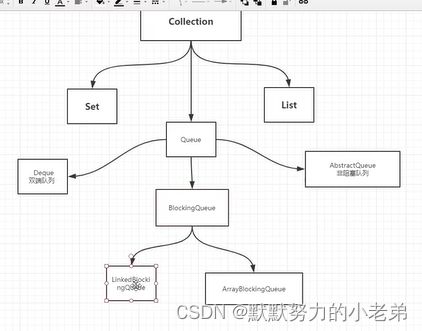
什么是阻塞?
写入(put):如果队列满了,必须阻塞等待
取(pop):如果队列是空的必须阻塞生产四组api (工作经常使用,根据需求使用)
- 全部抛出异常的方法(加入超过长度和取为空)
ArrayBlockingQueue q = new ArrayBlockingQueue<>(3);
q.add(“a”);
q.add(“b”);
q.add(“c”);
boolean d = q.remove(“d”);//删除不存在的不会报错,返回删除结果
q.remove(“a”);
q.remove(“b”);
q.remove(“c”);
try{
System.out.println(q.element());//取队首元素,可以判断队首是否为空
}catch (Exception e){
System.out.println(“队列为空”);
}//不抛出异常的方法,返回boolean值,放和取都是返回boolean值,全部方法不抛出异常
ArrayBlockingQueue q = new ArrayBlockingQueue(3);
q.offer(“10”);
q.offer(“20”);
q.offer(“30”);
System.out.println(“队首元素”+q.peek());
String poll = q.poll();String poll1 = q.poll();
System.out.println(poll);
System.out.println(poll1);
if (poll==null){
System.out.println(“队列为空”);
}
//阻塞等待, 没有元素还是拿超元素,都会一直等待,可能会让程序崩溃 put() take() ArrayBlockingQueue q = new ArrayBlockingQueue(3);
new Thread(()->{
try {
Thread.sleep(3000);
q.put(“20”); //队列等待的时候给新的值使他继续执行
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
try {
q.put(“10”);
String take = q.take();
System.out.println(take);
String take1 = q.take();
System.out.println(take1);} catch (InterruptedException e) {
e.printStackTrace();
}//等待超时 如队列阻塞,超过时间就不等待了直接退出
q= new ArrayBlockingQueue<>(3);
q.offer(“a”,2,TimeUnit.SECOND);//放. 放和取都是返回boolean
q.poll(2,TimeUnit.SECOND);//取
-------完整代码------
public class BlockingQueueWaitingTimeUniteAndLeave {
public static void main(String[] args) {
ArrayBlockingQueue<String> q = new ArrayBlockingQueue<String>(3);
new Thread(()->{
try {
Thread.sleep(1000);
q.put("20"); //队列等待的时候给新的值使他继续执行
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
try {
q.offer("10",2, TimeUnit.SECONDS);
String poll = q.poll();
System.out.println(poll);
String poll1 = q.poll(2, TimeUnit.SECONDS);
System.out.println(poll1); //null
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
10.SynchronousQueue同步队列 没有容量(不存储元素)(只有一个容量) 进去一个元素,必须取后才能重新放入元素 put() take()
public class SynchronousQueueDemo {
public static void main(String[] args) throws InterruptedException {
SynchronousQueue<String> q = new SynchronousQueue<String>();
// System.out.println(q.take());,主线程不能测试,必须要在开启新线程才能测试
//
new Thread(()->{
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
String take = null;
try {
q.put("aa");
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(take);
}).start();
new Thread(()->{
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
String take1 = q.take();
System.out.println(take1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}
11.线程池(重点) 使用了阻塞队列
池化技术 线程池 jdbc连接池 内存池 对象池 不用销毁和创建,用完资源还给我,不用创建直接拿
优化了什么?
减低资源消耗
提高响应速度
方便管理使用 alibaba开发手册 强制线程池不允许使用Executors(但是很多公司使用它)创建(指定了max为21亿个线程,会OOM异常),而是使用ThreadPoolExecutor直接去创建
//下面几种方式,都可能会OOM
threadPool=Executors.newSingleThreadExecutor();//创建单线程
.newFixedThreadPool(5);//固定大小的线程池
.newCachedThreadPool();//可伸缩的,遇强则强,遇弱则弱
try{
fori
threadPool.execute(()->{
// sout线程名可看多少个线程
//在这里执行业务代码
});}finally{
//关闭线程池
threadPool.shutdown();
}
------完整代码-------
public class ExecutorDemo {
public static void main(String[] args) {
ExecutorService thread = Executors.newSingleThreadExecutor();
ExecutorService thread1 = Executors.newFixedThreadPool(2000000000);
ExecutorService thread3 = Executors.newCachedThreadPool();
//
// for (int i = 0; i < 10; i++) {
// thread.execute(()->{
// System.out.println("你好"+Thread.currentThread().getName());
// });
// }
// for (int i = 0; i < 10; i++) {
// thread1.execute(()->{
// System.out.println("你好"+Thread.currentThread().getName());
// });
// }
for (int i = 0; i < 1000000000; i++) { //不要测试,电脑直接黑屏,声明Cached会导致系统奔溃,创建太多线程
thread3.execute(()->{
System.out.println("你好"+Thread.currentThread().getName());
});
}
}
}
ThreadPoolExecutor7大参数
阻塞队列
工厂代码
ExecutorService threadPool=new ThreadPoolExecutor(
2, //core核心大小(正常可以处理的情况使用多少线程)
5, //max(core处理不过来需要扩大线程数)
3, // keepAliveTime超时等待时间(如果多出来的max-core数没有被使用,等待关闭的时间)
TimeUnit.SECONDS, // keep等待的时间单位
new LinkedBlockingDeque(3), //双端队列
Executors.defaultThreadFactory(),//工厂
new ThreadPoolExecutor.DiscardOldestPolicy() // 拒绝策略 //4个,如果线程池满了不能处理后的操作
); // 当前使用线程大小=max+阻塞队列的长度
//拒绝策略详细解释
new ThreadPoolExecutor.DiscardOldestPolicy()//,如果最老的线程还在被占用,则抛弃,否则使用他
.Discard();//如果线程不够用了,直接抛弃
.CallerRunsPolicy(); //哪里来的线程回哪里去处理 可能main处理
.AbortPolicy();//不处理直接抛出异常
----完整代码----
public class LocalThread {
public static void main(String[] args) {
int max=Runtime.getRuntime().availableProcessors();
ThreadPoolExecutor thread = new ThreadPoolExecutor(
3,
max,
2,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(3),
Executors.defaultThreadFactory(),
// new ThreadPoolExecutor.AbortPolicy()
// new ThreadPoolExecutor.CallerRunsPolicy()
// new ThreadPoolExecutor.DiscardPolicy() //多出来的线程不执行
new ThreadPoolExecutor.DiscardOldestPolicy() //去找执行完的线程 如果没有抛弃任务
);
for (int i = 0; i < 100; i++) {
thread.execute(()->{
System.out.println(Thread.currentThread().getName());
});
}
}
}
12.最大线程如何定义?(调优)
- 分类
1. CPU密集型(): 逻辑核数 ,通过代码可以获得核数>Runtime.getRuntime().availableProcessors()
2. IO密集型 全部线程数-判断你的程序十分耗IO资源的线程数
13.四大函数式接口(必须掌握)
新时代程序员: jdk8新特性 lambda表达式 链式编程 函数式接口 Stream流式计算
- 函数式接口(只有一个方法的接口) 超级多的在代码底层存在,简化编程模型,新版本框架底层大量使用
//自带foreach()方法 ,接口上面定义这个注解
@FunctionalInterface- 四大函数
//有个
Function<String,String> function=new Function<String,String>(){
public String apply(){return str){return str}} //看源码,第二个参数是返回的类型
};
//lambda简化
Function<String,Integer> function=(str)->{return 1;}
sout(function.apply("aaa")); //返回1,进入什么返回什么
//断定性接口(一个函数返回boolean)
//普通写法
Predicate<String> stringPredicate = new Predicate<String>() {
@Override
public boolean test(String s) {
return s.isEmpty();
}
};
//lambda简化后,好方便
Predicate<String> predicate=(str)->{return str.isEmpty()};//判断字符串是否为空
sout(predicate.test("aa")); //false
- 补充了默认方法,默认方法可以在接口写 具体的实现 代码如下 实现类不用实现默认方法
public class TestDefault implements MyInterface {
@Override
public int size() {
// TODO Auto-generated method stub
return 1;
}
public static void main(String[] args) {
TestDefault testDefault = new TestDefault();
MyInterface.getInfo(testDefault.size(), testDefault.isEmpty());
}
}
// 函数式接口
interface MyInterface {
// 抽象方法
int size();
// 默认方法
default boolean isEmpty () {
return size() == 0;
}
// 静态方法
static void getInfo(int size, boolean isEmpty) {
System.out.println("size is " + size + ", empty: " + isEmpty);
}
}
13.Consumer(消费者没有返回值只有输入)和Supplier(没有参数只有返回值 提供者)接口
//消费者类似于 一块石头丢入大海,杳无音信,被消费了
//提供者类似于 我调用方法就可以拿到我的东西
Consumer<String> objectConsumer = (str)->{
System.out.println("已经消费没有返回值");
};
objectConsumer.accept("aaa");
//lambda返回值是根据你方法里面返回的类型自动判断的
Supplier<String> supplier = ()->{return "aa";};
String s = supplier.get();
System.out.println(s); //"aa"
14.Stream流式计算(必须掌握) 大数据: 集合就是存储 +计算交给流
//用一行代码,选择有5个用户,筛选出 id为偶数 年龄大于12岁 用户名转为大写 用户名倒着排序 只输出一个用户
User ls = new User(1, 21, "ls");
User sz = new User(3, 12, "sz");
User dz = new User(4, 50, "dz");
User zs = new User(2, 27, "zs");
User qq = new User(5, 10, "qq");
List<User> list = Arrays.asList(ls, sz, dz, zs, qq);
list.stream()
.filter(u->{return u.getId()%2==0;})
.filter(u->{return u.getAge()>12;}) //过滤
.map(u->{return u.getName().toUpperCase();}) //过滤出 返回的值
.sorted((uu1,uu2)->{return uu2.compareTo(uu1);}) //从小到大排序,自己在实体类写对比id
.limit(1) //分页
.forEach(System.out::printLn); //输出 ZS
15.ForkJoin(中级) jdk1.7 并行执行任务提供效率,大数据量(mapreduce大任务拆分成小任务的思想)时使用
1.特点 工作窃取 (另外一个任务完成了可以窃取其他任务的子任务) 都是双端队列
//求和demo,相当于递归实现,并且拆分任务递归
public class ForkJoinWork extends RecursiveTask<Long> { //继承了递归任务实现了方法
private Long start;//起始值
private Long end;//结束值
public static final Long critical = 10000L;//临界值
public ForkJoinWork(Long start, Long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
//判断是否是拆分完毕
Long lenth = end - start;
if(lenth<=critical){
//如果拆分完毕就相加
Long sum = 0L;
for (Long i = start;i<=end;i++){
sum += i;
}
return sum;
}else {
//没有拆分完毕就开始拆分
Long middle = (end + start)/2;//计算的两个值的中间值
ForkJoinWork right = new ForkJoinWork(start,middle);
right.fork();//拆分,并压入线程队列
ForkJoinWork left = new ForkJoinWork(middle+1,end);
left.fork();//拆分,并压入线程队列
// //合并小任务和合并结果,相当于一颗递归树
//先将任务拆分为小任务,然后从树低到树顶合并执行任务结果
return right.join() + left.join();
}
}
}
public class ForkJoinWorkDemo {
public static void main(String[] args) throws ExecutionException,
InterruptedException {
test(); //15756 // 14414 // 203
}
public static void test() throws ExecutionException,
InterruptedException {
//ForkJoin实现
long l = System.currentTimeMillis();
ForkJoinPool forkJoinPool = new ForkJoinPool();//实现ForkJoin 就必须有ForkJoinPool的支持
ForkJoinTask<Long> task = new ForkJoinWork(0L,10000001L);//参数为起始值与结束值
ForkJoinTask<Long> result = forkJoinPool.submit(task);
Long aLong = result.get();
long l1 = System.currentTimeMillis();
System.out.println("invoke = " + aLong +" time: " + (l1-l));
}
public static void test2(){
//普通线程实现
Long x = 0L;
Long y = 2000000000L;
long l = System.currentTimeMillis();
for (Long i = 0L; i <= y; i++) {
x+=i;
}
long l1 = System.currentTimeMillis();
System.out.println("invoke = " + x+" time: " + (l1-l));
}
public static void test3(){
//Java 8 并行流的实现 (高级)
long l = System.currentTimeMillis();
long reduce = LongStream.rangeClosed(0,
2000000000L).parallel().reduce(0, Long::sum);
long l1 = System.currentTimeMillis();
System.out.println("invoke = " + reduce+" time: " + (l1-l));
}
}
//代码运行模拟,但是没有模拟出递归