Python字符串以及字符串匹配算法KMP(一)
一 字符串
计算机领域,文字处理一类重要的计算机应用,这样的基本文字符号称为字符,符号的序列称为字符串。基于对字符串处理的需求,需要字符集有一种确定的序关系(字典序)
二 字符串的实现
字符串可以看做一种特殊的线性表,可以采用一体式顺序表(一块完整的存储空间),需要在创建之初就确定大小的字符串,或者采用分离式顺序表形式(由链表连接的多个独立的存储空间),字符串可以动态变化。可变类型的字符串只能由后者实现,但无论如何变化,线性表的实现基础只能基于顺序存储或者链接结构。
其实就是要确定(一体式顺序表和分离式顺序表的区别):
- 字符串内容的存储是全部存在一块连续区里,还是用链表连接的多个空间(每个空间只存储一个字符)。或者折中,将字符串分段保存在几段然后链接起来。
- 串结束的表示,用长度记录串结束的位置还是用特殊编码记录
三 字符串算法问题中需要注意的问题
- 大小写敏感问题
- 字符串大小比较
- 空串问题
- 子串关系问题,是否会有重叠,如何处理重叠?eg,babb在babbabbbbabb中出现了三次,需要处理几次?关系到是选择逐步(算两次)完成还是一步到位(算三次,如果逐步完成并且会有修改字符串的行为则重叠部分会被破坏)。
四 实际语言中的字符串
Python的str是一个不变类型,只可以进行迭代,不能进行修改,创建后其内容和长度都不会发生变化,采用了一体式顺序表标的形式,非内建函数的修改需要将str先为list才能进行修改,之后才拼接成字符串。因此,任何修改不变类型的操作都会产生新的对象。
Str对象的操作分类两类:
O(1):获取len,定位访问
O(N):扫描整个串的内容,包括一些不变类型的共有操作
五 字符串匹配(子串查找)
定义:在目标串t中搜索模式串p的过程。也成为模式匹配。字符串匹配时是其他字符串操作的基础
应用:文本编辑器查找单词或句子,email过滤垃圾邮件。防病毒软件检索病毒特征。
实际中要考虑的问题:
检索的文本很大,需要用同一个模式串反复检索。
模式串的集合还会经常变化。
六 字符串匹配算法BF
def naive_match(target, pattern):
l1, l2 = len(target), len(pattern)
i, j = 0, 0
while i < l1 and j < l2: # j==l2时,表示匹配成功。
if target[i] == pattern[j]:
i, j = i + 1, j + 1
else: # 字符不同,目标串回到前面的下一个位置,模式串回到起点
i, j = i - j + 1, 0
if j == l2:
return i - j
return -1
最坏的情况:每次都在模式串的最后一位匹配失败, 时间复杂度为O(m x n)
eg. target: 000000000000000000001
pattern: 00001
从数学上看,暴力算法默认目标串和模式串的字符都是相互独立的完全随机变量,而且取值范围为无穷。而实际情况上,字符串取值来自一个有穷集合。暴力算法没有利用之前比较中得到的信息,造成了很多无谓的回溯。因此提出了无回溯串匹配算法KMP
七 KMP无回溯匹配算法
其基本思想是匹配中不回溯(目标串的指针),其核心是建立了一套分析和记录模式串信息的机制,对模式串进行一些预处理过程,得到有用的信息并汇总到一整p_next表中,当模式串第i位匹配失败的时候,将模式串指针移动到p_next[i]的位置。
1)最大前后缀匹配长度求p_next表
p_next表中是当模式串第i位匹配失败的时候,希望模式串指针移动到p_next[i]的位置。考虑:

问题可以转化为在寻找前缀后缀相同的最长长度。最简单的方法无非是,将每个前缀后缀列出来,找到最长匹配,例如:
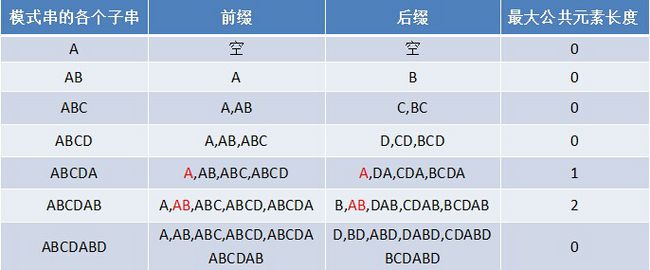
自然每个元素的最大匹配长度如下:

可以由此得到p_next表,将最大前缀后缀匹配表长度向右移动一位,因为p_next[i] = pattern[0 : i]的最大前后缀匹配长度决定的。
# 方法一 构造最大长度表
def cal_next_table1(pattern):
next_table = {}
max_com = {}
l = len(pattern)
for j in range(0, l):
max_com[j] = 0
pre = [pattern[0: i + 1] for i in range(0, j)]
suf = [pattern[i + 1: j + 1] for i in range(0, j)]
# suf是从长到短,第一个匹配的共同字符串就是最长字符串
for k in suf:
if k in pre:
max_com[j] = len(k)
break
# 移位构造next_table
next_table[0] = -1
for m, n in max_com.items():
next_table[m + 1] = n
return next_table
{0: -1, 1: 0, 2: 0, 3: 0, 4: 0, 5: 1, 6: 2, 7: 0}
2)递归求p_next表
就是已知next [0, ..., j],求出next [j + 1]的过程。
由1)得出p_next[j] 表中值代表了前j - 1个元素的最长的前后缀匹配长度,如图所示:

p_next[j] = k表示图中红色区域相等。所以只需要比较p_next[j] 和 p_next[k] 是否相等,如果相等则
p_next[j + 1] = p_next[j] + 1
如果不等的话则递归向下寻找,如图:

如果不相等则向下寻找最长匹配长度,p_next[k] = k' 表示 红绿区域相等,并且始终表示最长的匹配长度,此时只需要不断的令
k = p_next[k] 直到 k = 0。
# 方法二 递归构造
def cal_next_table2(p):
i, k, plen = 0, -1, len(p)
pnext = [-1] * plen
while i < plen - 1:
if k == -1 or p[i] == p[k]:
i, k = i+1, k+1
pnext[i] = k
else:
k = pnext[k]
return pnext
[-1, 0, 0, 0, 0, 1, 2]完整的kmp:
def kmp_match(t, p, pnext):
i, j = 0, 0
n, m = len(t), len(p)
while j < n and i < m:
if i == -1 or t[j] == p[i]:
j, i = j + 1, i + 1
else:
# 根据pnext表回溯
i = pnext[i]
# 两种情况,找到匹配则i==m,没找到匹配返回-1
if i == m:
return j - 1
return -1
pattern = "ABCDABD"
target = "BBC ABCDAB ABCDABCDABDE"
pnext = cal_next_table2(pattern)
print(kmp_match(target, pattern, pnext))
21时间复杂度分析:
如果文本串的长度为n,模式串的长度为m,那么匹配过程的时间复杂度为O(n),算上计算next的O(m)时间,KMP的整体时间复杂度为O(m + n)
八 更多字符串匹配算法
BM算法, Sunday算法,KMP算法拓展-AC自动机。
Ref:
https://blog.csdn.net/v_july_v/article/details/7041827从头到尾彻底理解KMP
《数据结构与算法python》裘宗燕