【深度学习】基于华为MindSpore和pytorch的卷积神经网络LeNet5实现MNIST手写识别
1 实验内容简介
1.1 实验目的
(1)熟练掌握卷积、池化概念;
(2)熟练掌握卷积神经网络的基本原理;
(3)熟练掌握各种卷积神经网络框架单元;
(4)熟练掌握经典卷积神经网络模型。
1.2 实验内容及要求
请基于pytorch和mindspore平台,利用MNIST数据集,选择一个典型卷积模型,构建一个自己的卷积模型,以分类的准确度和混淆矩阵为衡量指标,分析两个模型的分类精度。
要求:pytorch可与tensorflow替换,但mindspore为必选平台。(mindspore可以在华为云ModelArts上实现);自己构建的模型必须与经典模型的网络结构有显著区分,但总体分类准确度需要在97%以上记为合格(不扣分)。
1.3 实验数据集介绍
1.3.1 数据集简介
MNIST数据集(Mixed National Institute of Standards and Technology Database)是一个用来训练各种图像处理系统的二进制图像数据集,广泛应用于机器学习中的训练和测试。MNIST数据集共有70000张图像,其中训练集60000张,测试集10000张。所有图像都是28×28的灰度图像,每张图像包含一个手写数字。
1.3.2 数据集详细信息
(1)数据量
训练集60000张图像,其中30000张来自NIST的Special Database 3,30000张来自NIST的Special Database 1。测试集10000张图像,其中5000张来自NIST的Special Database 3,5000张来自NIST的Special Database 1。
(2)标注情况
每张图像都有标注。
(3)标注类别
共10个类别,每个类别代表0~9之间的一个数字,每张图像只有一个类别。
1.3.3 数据集文件结构
(1)目录结构
·解压前
dataset_compressed/
├── t10k-images-idx3-ubyte.gz #测试集图像压缩包(1648877 bytes)
├── t10k-labels-idx1-ubyte.gz #测试集标签压缩包(4542 bytes)
├── train-images-idx3-ubyte.gz #训练集图像压缩包(9912422 bytes)
└── train-labels-idx1-ubyte.gz #训练集标签压缩包(28881 bytes)
·解压后
dataset_uncompressed/
├── t10k-images-idx3-ubyte #测试集图像数据
├── t10k-labels-idx1-ubyte #测试集标签数据
├── train-images-idx3-ubyte #训练集图像数据
└── train-labels-idx1-ubyte #训练集标签数据
(2)文件结构
MNIST数据集将图像和标签都以矩阵的形式存储于一种称为idx格式的二进制文件中。该数据集的4个二进制文件的存储格式分别如下:
·训练集标签数据 (train-labels-idx1-ubyte)

·训练集图像数据(train-images-idx3-ubyte)

·测试集标签数据(t10k-labels-idx1-ubyte)
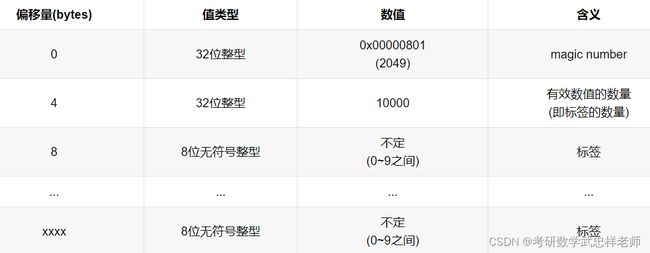
·测试集图像数据 (t10k-images-idx3-ubyte)

2 算法原理阐述
2.1 LeNet-5网络结构
LeNet-5由LeCun等人提出于1998年提出,是一种用于手写体字符识别的非常高效的卷积神经网络,出自论文《Gradient-Based Learning Applied to Document Recognition》。LeNet-5的网络结构如下图所示:

整个 LeNet-5 网络总共包括7层(不含输入层),分别是:C1、S2、C3、S4、C5、F6和OUTPUT。输入二维图像(单通道),先经过两次卷积层到池化层,再经过全连接层,最后为输出层。接受输入图像大小为32×32=1024,输出对应10个类别的得分。LeNet-5 中的每一层结构如下:
(1)C1层是卷积层,使用6个5×5的卷积核,得到6组大小为28×28 = 784的特征映射。因此,C1 层的神经元数量为6×784 = 4 704,可训练参数数量为6×25 + 6 = 156,连接数为156×784 = 122304(包括偏置在内,下同)。
(2)S2层为汇聚层,采样窗口为2×2,使用平均汇聚,并使用一个非线性函数。神经元个数为6×14×14 =1176,可训练参数数量为6×(1 + 1) = 12,连接数为6×196×(4 + 1) = 5880。
(3)C3 层为卷积层。LeNet-5 中用一个连接表来定义输入和输出特征映射之间的依赖关系。共使用60个5×5的卷积核,得到16 组大小为10×10的特征映射。如果不使用连接表,则需要96个5×5的卷积核。神经元数量为16 ×100 = 1600,可训练参数数量为(60×25) + 16 = 1516,连接数为100×1516 = 151600。
(4)S4 层是一个汇聚层,采样窗口为2×2,得到16个5×5大小的特征映射,可训练参数数量为16×2 = 32,连接数为16×25×(4 + 1) = 2 000。
(5)C5 层是一个卷积层,使用120×16 = 1 920 个5×5的卷积核,得到120 组大小为1×1的特征映射。C5 层的神经元数量为120,可训练参数数量为1 920×25 + 120 = 48120,连接数为120×(16×25 + 1) = 48120。
(6)F6 层是一个全连接层,有84 个神经元,可训练参数数量为84× (120 +1) = 10164。连接数和可训练参数个数相同,为10164。
(7)输出层:输出层由10 个径向基函数(Radial Basis Function,RBF)组成。
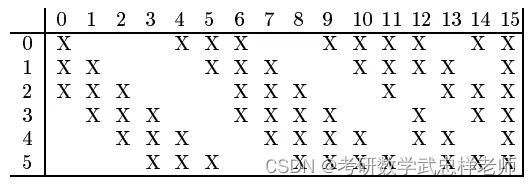
卷积层的每一个输出特征映射都依赖于所有输入特征映射,相当于卷积层的输入和输出特征映射之间是全连接的关系。实际上,这种全连接关系不是必须的。我们可以让每一个输出特征映射都依赖于少数几个输入特征映射。定义一个连接表(Link Table)来描述输入和输出特征映射之间的连接关系。在LeNet-5中,连接表的基本设定如下图所示。C3层的第0-5个特征映射依赖于S2层的特征映射组的每3个连续子集,第6-11个特征映射依赖于S2层的特征映射组的每4个连续子集,第12-14个特征映射依赖于S2层的特征映射的每4个不连续子集,第15个特征映射依赖于S2层的所有特征映射。
3 实验流程及代码实现
3.1 实验平台简介
3.1.1 MindSpore
MindSpore是华为公司自研的最佳匹配昇腾AI处理器算力的全场景深度学习框架,为数据科学家和算法工程师提供设计友好、运行高效的开发体验,推动人工智能软硬件应用生态繁荣发展,目前MindSpore支持在EulerOS、Ubuntu、Windows系统上安装。
3.1.2 pytorch
PyTorch是一个开源的Python机器学习库,基于Torch,用于自然语言处理等应用程序。2017年1月,由Facebook人工智能研究院(FAIR)基于Torch推出了PyTorch。它是一个基于Python的可续计算包,提供两个高级功能:1、具有强大的GPU加速的张量计算(如NumPy)。2、包含自动求导系统的深度神经网络。
3.2 评价指标
3.2.1 混淆矩阵
混淆矩阵(Confusion Matrix)又被称为错误矩阵,通过它可以直观地观察到算法的效果。它的每一列是样本的预测分类,每一行是样本的真实分类(反过来也可以),顾名思义,它反映了分类结果的混淆程度。

·P(Positive):代表1,表示预测为正样本;
·N(Negative):代表0,表示预测为负样本;
·T(True):代表预测正确;
·F(False):代表预测错误。
下列Positive和Negative表示模型对样本预测的结果是正样本(正例)还是负样本(负例)。True和False表示预测的结果和真实结果是否相同。
·True positives(TP)
预测为1,预测正确,即实际为1;
·False positives(FP)
预测为1,预测错误,即实际为0;
·False negatives(FN)
预测为0,预测错误,即实际为1;
·True negatives(TN)
预测为0,预测正确,即实际为0。
3.2.2 准确率
准确率(Accuracy)衡量的是分类正确的比例。
3.3 实验流程
3.3.1 基于MindSpore的LeNet-5网络
首先导入实验需要的模块。mindspore中context模块用于配置当前执行环境,包括执行模式等特性;vision.c_transforms模块是处理图像增强的高性能模块,用于数据增强图像数据改进训练模型。同时需要设置MindSpore的执行设备和模式。
import os
import mindspore as ms
# 导入mindspore中context模块,用于配置当前执行环境,包括执行模式等特性。
import mindspore.context as context
# c_transforms模块提供常用操作,包括OneHotOp和TypeCast
import mindspore.dataset.transforms as C
# vision.c_transforms模块是处理图像增强的高性能模块,用于数据增强图像数据改进训练模型。
import mindspore.dataset.vision as CV
import numpy as np
from mindspore import nn
from mindspore.nn import Accuracy
from mindspore.train import Model
from mindspore.train.callback import LossMonitor
import matplotlib.pyplot as plt
# 设置MindSpore的执行模式和设备
context.set_context(mode=context.GRAPH_MODE, device_target='CPU') # Ascend, CPU, GPU
对数据进行预处理:
def create_dataset(data_dir, training=True, batch_size=32, resize=(32, 32),
rescale=1/(255*0.3081), shift=-0.1307/0.3081, buffer_size=64):
data_train = os.path.join(data_dir, 'train') # 训练集信息
data_test = os.path.join(data_dir, 'test') # 测试集信息
ds = ms.dataset.MnistDataset(data_train if training else data_test)
ds = ds.map(input_columns=["image"], operations=[CV.Resize(resize), CV.Rescale(rescale, shift), CV.HWC2CHW()])
ds = ds.map(input_columns=["label"], operations=C.TypeCast(ms.int32))
ds = ds.shuffle(buffer_size=buffer_size).batch(batch_size, drop_remainder=True)
return ds
MindSpore的model_zoo中提供了多种常见的模型,可以直接使用。我们构建LeNet-5模型:
class LeNet5(nn.Cell):
def __init__(self):
super(LeNet5, self).__init__()
#设置卷积网络(输入输出通道数,卷积核尺寸,步长,填充方式)
self.conv1 = nn.Conv2d(1, 6, 5, stride=1, pad_mode='valid')
self.conv2 = nn.Conv2d(6, 16, 5, stride=1, pad_mode='valid')
self.relu = nn.ReLU()
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.flatten = nn.Flatten()
self.fc1 = nn.Dense(400, 120)
self.fc2 = nn.Dense(120, 84)
self.fc3 = nn.Dense(84, 10)
#构建网络
def construct(self, x):
x = self.relu(self.conv1(x))
x = self.pool(x)
x = self.relu(self.conv2(x))
x = self.pool(x)
x = self.flatten(x)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
使用MNIST数据集对上述定义的LeNet5模型进行训练。训练策略如下表所示,损失函数使用交叉熵损失函数。
| batch size |
number of epochs |
learning rate |
optimizer |
| 32 |
5 |
0.01 |
Momentum 0.9 |
def train(data_dir, lr=0.01, momentum=0.9, num_epochs=5):
ds_train = create_dataset(data_dir)
ds_eval = create_dataset(data_dir, training=False)
net = LeNet5()
#计算softmax交叉熵。
loss = nn.loss.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
#设置Momentum优化器
opt = nn.Momentum(net.trainable_params(), lr, momentum)
loss_cb = LossMonitor(per_print_times=ds_train.get_dataset_size())
metrics = {"Accuracy": Accuracy(), "Confusion_matrix": nn.ConfusionMatrix(num_classes=10)}
model = Model(net, loss, opt, metrics)
model.train(num_epochs, ds_train, callbacks=[loss_cb], dataset_sink_mode=True)
metrics_result = model.eval(ds_eval)
res = metrics_result["Confusion_matrix"]
print('Accuracy:',metrics_result["Accuracy"])
print('Confusion_matrix:', res)
return res
3.3.2 基于pytorch的LeNet-5网络
首先导入实验需要的模块:
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from matplotlib import pyplot as plt
from sklearn.metrics import confusion_matrix
from torchvision import datasets, transforms
接下来构建LeNet-5网络:
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5, 1 )
self.conv2 = nn.Conv2d(6, 16, 5, 1)
self.fc1 = nn.Linear(16 * 4 * 4, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.max_pool2d(self.conv1(x), 2, 2)
x = F.max_pool2d(self.conv2(x), 2, 2)
x = x.view(-1, 16 * 4 * 4)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return F.log_softmax(x, dim=1)
训练和测试模块,采用训练策略与MindSpore保持一致,损失函数使用交叉熵损失函数。
def train(model, device, train_loader, optimizer, epoch):
model.train()
for idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
pred = model(data)
loss = F.nll_loss(pred, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if idx % 100 == 0:
print("Train Epoch: {}, iterantion: {}, Loss: {}".format(epoch, idx, loss.item()))
def test(model, device, test_loader,):
model.eval()
total_loss = 0.
correct = 0.
predict=[]
true=[]
with torch.no_grad():
for idx, (data, target) in enumerate(test_loader):
data, target = data.to(device), target.to(device)
output = model(data)
total_loss += F.nll_loss(output, target, reduction="sum").item()
pred = output.argmax(dim=1)
true.append(target.tolist())
predict.append(pred.tolist())
correct += pred.eq(target.view_as(pred)).sum().item()
total_loss /= len(test_loader.dataset)
acc = correct / len(test_loader.dataset) * 100
print("Test loss: {}, Accuracy: {}".format(total_loss, acc))
predict = [n for a in predict for n in a]
true=[n for a in true for n in a]
return predict,true
4 实验结果及分析
4.1 实验结果
4.1.1 基于MindSpore的LeNet-5网络
4.1.1.1 准确率

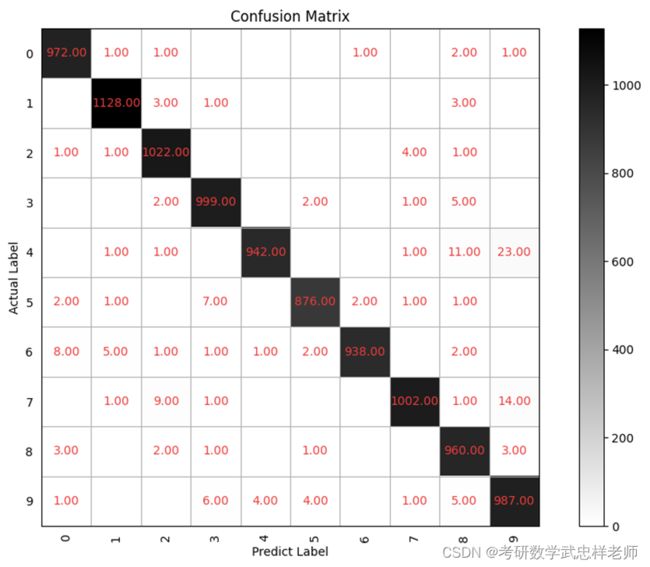
可见经过5轮训练,准确率已达到98.267%。
4.1.1.2 混淆矩阵
混淆矩阵及其可视化效果如下:

4.1.2 基于pytorch的LeNet-5网络
4.1.2.1 准确率

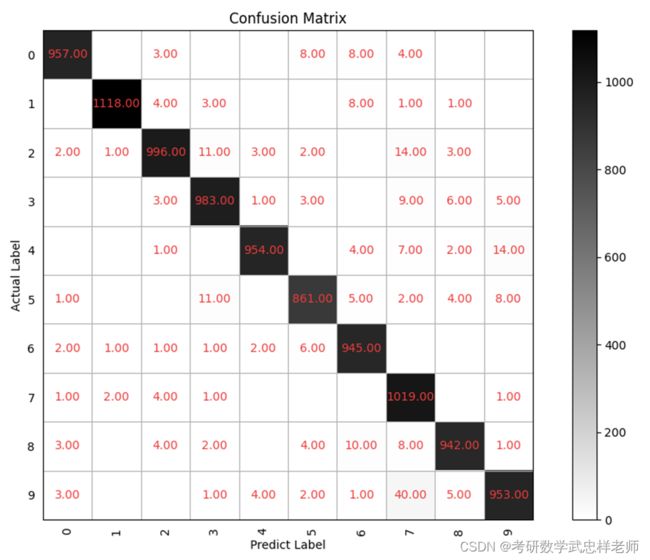
可见经过5轮训练,准确率已超过97%。
4.1.2.2 混淆矩阵
4.2 结果分析与对比
用于手写数字识别(图像分类)的LeNet-5是卷积神经网络(CNN)的开山之作, AlexNet、ResNet等都是在其基础上发展而来的。CNN提出了三个创新点:局部感受野(Local Receptive Fields)、共享权重(Shared Weights)、时空下采样(Spatial or Temporal Subsampling)。
局部感受野(Local Receptive Fields):用来表示网络内部的不同位置的神经元对原图像的感受范围的大小,对应于CNN中的卷积核,可以抽取图像初级的特征,如边、转角等,这些特征会在后来的层中通过各种联合的方式来检测高级别特征。
共享权重(Shared Weights):在卷积过程中,每个卷积核所对应的窗口会以一定的步长在输入矩阵(图像)上不断滑动并进行卷积操作,最后,每个卷积核会生成一个对应的feature map(也就是卷积核的输出),一个feature map中的每一个单元都是由相同的权重(也就是对应的卷积核内的数值)计算得到的,这就是共享权重。
时空下采样(Spatial or Temporal Subsampling):对应于CNN中的池化操作,也就是从卷积得到的feature map中提取出重要的部分,此操作可以降低模型对与图像平移和扭曲的敏感程度。
下表列出了各模型的准确率对比情况:
| 模型 |
准确率 |
| 基于MindSpore的LeNet-5网络 |
98.267% |
| 基于pytorch的LeNet-5网络 |
97.35% |
可见LeNet在不同平台的手写数字识别方面均展现出了优异的性能,无愧为卷积神经网络的开山鼻祖。
源代码
MSLeNet手写识别.py
import os
import mindspore as ms
# 导入mindspore中context模块,用于配置当前执行环境,包括执行模式等特性。
import mindspore.context as context
# c_transforms模块提供常用操作,包括OneHotOp和TypeCast
import mindspore.dataset.transforms as C
# vision.c_transforms模块是处理图像增强的高性能模块,用于数据增强图像数据改进训练模型。
import mindspore.dataset.vision as CV
import numpy as np
from mindspore import nn
from mindspore.nn import Accuracy
from mindspore.train import Model
from mindspore.train.callback import LossMonitor
import matplotlib.pyplot as plt
# 设置MindSpore的执行模式和设备
context.set_context(mode=context.GRAPH_MODE, device_target='CPU') # Ascend, CPU, GPU
def create_dataset(data_dir, training=True, batch_size=32, resize=(32, 32),
rescale=1/(255*0.3081), shift=-0.1307/0.3081, buffer_size=64):
data_train = os.path.join(data_dir, 'train') # 训练集信息
data_test = os.path.join(data_dir, 'test') # 测试集信息
ds = ms.dataset.MnistDataset(data_train if training else data_test)
ds = ds.map(input_columns=["image"], operations=[CV.Resize(resize), CV.Rescale(rescale, shift), CV.HWC2CHW()])
ds = ds.map(input_columns=["label"], operations=C.TypeCast(ms.int32))
ds = ds.shuffle(buffer_size=buffer_size).batch(batch_size, drop_remainder=True)
return ds
ds = create_dataset('D:/Dataset/MNIST', training=False)
data = ds.create_dict_iterator().get_next()
images = data['image'].asnumpy()
labels = data['label'].asnumpy()
#显示前4张图片以及对应标签
for i in range(1, 5):
plt.subplot(2, 2, i)
plt.imshow(images[i][0])
plt.title('Number: %s' % labels[i])
plt.xticks([])
plt.show()
#定义LeNet5模型
class LeNet5(nn.Cell):
def __init__(self):
super(LeNet5, self).__init__()
#设置卷积网络(输入输出通道数,卷积核尺寸,步长,填充方式)
self.conv1 = nn.Conv2d(1, 6, 5, stride=1, pad_mode='valid')
self.conv2 = nn.Conv2d(6, 16, 5, stride=1, pad_mode='valid')
self.relu = nn.ReLU()
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.flatten = nn.Flatten()
self.fc1 = nn.Dense(400, 120)
self.fc2 = nn.Dense(120, 84)
self.fc3 = nn.Dense(84, 10)
#构建网络
def construct(self, x):
x = self.relu(self.conv1(x))
x = self.pool(x)
x = self.relu(self.conv2(x))
x = self.pool(x)
x = self.flatten(x)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
def train(data_dir, lr=0.01, momentum=0.9, num_epochs=5):
ds_train = create_dataset(data_dir)
ds_eval = create_dataset(data_dir, training=False)
net = LeNet5()
#计算softmax交叉熵。
loss = nn.loss.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
#设置Momentum优化器
opt = nn.Momentum(net.trainable_params(), lr, momentum)
loss_cb = LossMonitor(per_print_times=ds_train.get_dataset_size())
metrics = {"Accuracy": Accuracy(), "Confusion_matrix": nn.ConfusionMatrix(num_classes=10)}
model = Model(net, loss, opt, metrics)
model.train(num_epochs, ds_train, callbacks=[loss_cb], dataset_sink_mode=True)
metrics_result = model.eval(ds_eval)
res = metrics_result["Confusion_matrix"]
print('Accuracy:',metrics_result["Accuracy"])
print('Confusion_matrix:', res)
return res
# 绘制混淆矩阵
def plot_confusion_matrix(cm, title='Confusion Matrix'):
classes = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
plt.figure(figsize=(12, 8), dpi=100)
np.set_printoptions(precision=2)
# 混淆矩阵中每格的值
ind_array = np.arange(len(classes))
x, y = np.meshgrid(ind_array, ind_array)
for x_val, y_val in zip(x.flatten(), y.flatten()):
c = cm[y_val][x_val]
if c > 0.001:
plt.text(x_val, y_val, "%0.2f" % (c,), color='#EE3B3B', fontsize=10, va='center', ha='center')
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.binary)
plt.title(title)
plt.colorbar()
xlocations = np.array(range(len(classes)))
plt.xticks(xlocations, classes, rotation=90)
plt.yticks(xlocations, classes)
plt.ylabel('Actual Label')
plt.xlabel('Predict Label')
tick_marks = np.array(range(len(classes))) + 0.5
plt.gca().set_xticks(tick_marks, minor=True)
plt.gca().set_yticks(tick_marks, minor=True)
plt.gca().xaxis.set_ticks_position('none')
plt.gca().yaxis.set_ticks_position('none')
plt.grid(True, which='minor', linestyle='-')
plt.gcf().subplots_adjust(bottom=0.15)
plt.show()
confusion = train('D:/Dataset/MNIST')
plot_confusion_matrix(confusion,title='Confusion Matrix')
pytorchLeNet手写识别.py
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from matplotlib import pyplot as plt
from sklearn.metrics import confusion_matrix
from torchvision import datasets, transforms
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5, 1 )
self.conv2 = nn.Conv2d(6, 16, 5, 1)
self.fc1 = nn.Linear(16 * 4 * 4, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.max_pool2d(self.conv1(x), 2, 2)
x = F.max_pool2d(self.conv2(x), 2, 2)
x = x.view(-1, 16 * 4 * 4)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return F.log_softmax(x, dim=1)
def train(model, device, train_loader, optimizer, epoch):
model.train()
for idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
pred = model(data)
loss = F.nll_loss(pred, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# if idx % 100 == 0:
# print("Train Epoch: {}, iterantion: {}, Loss: {}".format(epoch, idx, loss.item()))
def test(model, device, test_loader,):
model.eval()
total_loss = 0.
correct = 0.
predict=[]
true=[]
with torch.no_grad():
for idx, (data, target) in enumerate(test_loader):
data, target = data.to(device), target.to(device)
output = model(data)
total_loss += F.nll_loss(output, target, reduction="sum").item()
pred = output.argmax(dim=1)
true.append(target.tolist())
predict.append(pred.tolist())
correct += pred.eq(target.view_as(pred)).sum().item()
total_loss /= len(test_loader.dataset)
acc = correct / len(test_loader.dataset) * 100
print("Test loss: {}, Accuracy: {}".format(total_loss, acc))
predict = [n for a in predict for n in a]
true=[n for a in true for n in a]
return predict,true
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
batch_size = 32
train_dataloader = torch.utils.data.DataLoader(
datasets.MNIST("D:/Dataset/pytorch/", train=True, download=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True,
num_workers=1, pin_memory=True # True加快训练
)
test_dataloader = torch.utils.data.DataLoader(
datasets.MNIST("D:/Dataset/pytorch/", train=False, download=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True,
num_workers=1, pin_memory=True
)
# 绘制混淆矩阵
def plot_confusion_matrix(cm, title='Confusion Matrix'):
classes = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
plt.figure(figsize=(12, 8), dpi=100)
np.set_printoptions(precision=2)
# 混淆矩阵中每格的值
ind_array = np.arange(len(classes))
x, y = np.meshgrid(ind_array, ind_array)
for x_val, y_val in zip(x.flatten(), y.flatten()):
c = cm[y_val][x_val]
if c > 0.001:
plt.text(x_val, y_val, "%0.2f" % (c,), color='#EE3B3B', fontsize=10, va='center', ha='center')
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.binary)
plt.title(title)
plt.colorbar()
xlocations = np.array(range(len(classes)))
plt.xticks(xlocations, classes, rotation=90)
plt.yticks(xlocations, classes)
plt.ylabel('Actual Label')
plt.xlabel('Predict Label')
tick_marks = np.array(range(len(classes))) + 0.5
plt.gca().set_xticks(tick_marks, minor=True)
plt.gca().set_yticks(tick_marks, minor=True)
plt.gca().xaxis.set_ticks_position('none')
plt.gca().yaxis.set_ticks_position('none')
plt.grid(True, which='minor', linestyle='-')
plt.gcf().subplots_adjust(bottom=0.15)
plt.show()
if __name__ == '__main__':
lr = 0.01
momentum = 0.9
model = LeNet().to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=lr, momentum=momentum)
num_eopchs = 5
for eopch in range(num_eopchs):
train(model, device, train_dataloader, optimizer, eopch)
y_pre,y=test(model, device, test_dataloader)
plot_confusion_matrix(confusion_matrix(y, y_pre), title='Confusion Matrix')