java进程引发的内存泄露问题排查分析
近期工作过程中遇到了一次容器内存不断增高,最终达到90%引发告警的情况。
特征1,把监控面板时间轴拉长会发现,重启后内存占用78%左右,每天增长1%,大约2周后会涨到90%触发告警(即如果2周内有代码发布部署,则需要以最新部署时间开始再往后推2周才会再次触发告警)。
特征2,生产环境14台机器,只有2台机器内存占用达到90%告警,这2台机器是内灰机器平常没有流量。
缉拿罪魁祸首进程
第一步自然是缉拿罪魁祸首了,登录服务器发现java进程RSS不断增高,一开始觉得很简单,以为是堆内存泄露,结果发现并没有想象中那么简单
#如何可以看出java进程占用RSS不断增长的呢?
执行 ps aux 即可看出各个进程的RSS使用情况,如下实际案例来看,PID是2669的进程RSS占用了5579008KB ,间隔一段时间再执行就可以看出来,一直在小范围增长
$ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
……
admin 2669 73.3 66.5 9308832 5579008 ? Sl 15:13 15:52 /opt/xxxxxx/java/bin/java -Dspring.profiles.active=ppe -Dstdout=false -DlimitTime=30 -Ddruid.load.spifilter.skip -Dhsf.consumer.ini
……
#RSS小知识
RSS是什么单词的缩写?Resident Set Size,它是进程分配的物理内存的大小,单位为KB
RSS增长也有可能是合理的,观察一段时间后如果发现进程RSS地增长,也有可能是合理的情况,可能是java进程在运行过程创建对象造成的,但是随着周期性的JVM GC垃圾收集工作,过一段时间后再观察还是会RSS还降下来的,比如令天观察总比昨天RSS在增长,明天比今天也在增长,那么就不是合理的。
锁定到进程PID:2669 内存泄露
进程PID:2669 是java应用,内存泄露可能是来自堆内存,也可能是非堆内存,还有可能是堆外内存
逐个排除内存泄露点
第二步采用逐个排除法,依次分析内存泄露的可能性
堆内存泄露?
堆内存泄露?公司层面已经有了JVM监控面板,时间拉长到1天后会发现堆内存使用是涨涨跌跌,最终稳定在一个相对固定值上,初步可以排除堆内存泄露引发的问题了

注:如果想详细查看堆内存中对象的分布情况可以使用如下命令
jcmd 2669 GC.class_histogram > dump.log
非堆内存泄露?
非堆内存泄露?非堆内存包括了Metaspace,CompressedClassSpace,CodeHeap
Java应用的执行,JVM自身也需要消耗一些内存的,通过开启Native Memory Tracking,我们就能知道JVM自身消耗了多少内存。
书归正传,通过修改JVM参数并重启Java进程开启NativeMemory Tracking:
-XX:NativeMemoryTracking=detail
进程重启后,可以通过NMT的一些子命令(summary/detail/baseline/diff)查看Native Memory的占用情况:
sudo -u jcmd VM.native_memory
sudo -u jcmd VM.native_memory detail
完整命令:
alioopid=`ps aux|grep java|grep alsc-growth-fission|awk -F ' ' '{print $2}'`
jcmd $alioopid VM.native_memory scale=MB
jcmd $alioopid VM.metaspace
命令结果:
28040:
Native Memory Tracking:
Total: reserved=6804MB, committed=5448MB
- Java Heap (reserved=4096MB, committed=4096MB)
(mmap: reserved=4096MB, committed=4096MB)
- Class (reserved=630MB, committed=424MB)
(classes #71617)
( instance classes #68709, array classes #2908)
(malloc=14MB #249010)
(mmap: reserved=616MB, committed=410MB)
( Metadata: )
( reserved=360MB, committed=358MB)
( used=350MB)
( free=9MB)
( waste=0MB =0.00%)
( Class space:)
( reserved=256MB, committed=52MB)
( used=47MB)
( free=5MB)
( waste=0MB =0.00%)
- Thread (reserved=1185MB, committed=125MB)
(thread #1176)
(stack: reserved=1180MB, committed=119MB)
(malloc=4MB #7058)
(arena=1MB #2351)
- Code (reserved=271MB, committed=181MB)
(malloc=13MB #53389)
(mmap: reserved=258MB, committed=168MB)
- GC (reserved=203MB, committed=203MB)
(malloc=18MB #88815)
(mmap: reserved=184MB, committed=184MB)
- Compiler (reserved=6MB, committed=6MB)
(malloc=6MB #5145)
- Internal (reserved=9MB, committed=9MB)
(malloc=9MB #17612)
- Other (reserved=262MB, committed=262MB)
(malloc=262MB #367)
- Symbol (reserved=58MB, committed=58MB)
(malloc=53MB #766877)
(arena=4MB #1)
- Native Memory Tracking (reserved=20MB, committed=20MB)
(malloc=1MB #12232)
(tracking overhead=19MB)
- Arena Chunk (reserved=57MB, committed=57MB)
(malloc=57MB)
- Module (reserved=6MB, committed=6MB)
(malloc=6MB #36247)
- Synchronizer (reserved=1MB, committed=1MB)
(malloc=1MB #12399)
# 详细看一下metaspace空间的完整命令:
alioopid=`ps aux|grep java|grep alsc-growth-fission|awk -F ' ' '{print $2}'`
jcmd $alioopid VM.metaspace
jcmd 28040 VM.metaspace
28040:
Total Usage - 8641 loaders, 71659 classes:
Non-Class: 25515 chunks, 359.73 MB capacity, 351.59 MB ( 98%) used, 6.57 MB ( 2%) free, 11.78 KB ( <1%) waste, 1.56 MB ( <1%) overhead, deallocated: 16419 blocks with 4.91 MB
Class: 10152 chunks, 52.04 MB capacity, 47.46 MB ( 91%) used, 3.96 MB ( 8%) free, 448 bytes ( <1%) waste, 634.50 KB ( 1%) overhead, deallocated: 1413 blocks with 461.28 KB
Both: 35667 chunks, 411.77 MB capacity, 399.06 MB ( 97%) used, 10.53 MB ( 3%) free, 12.22 KB ( <1%) waste, 2.18 MB ( <1%) overhead, deallocated: 17832 blocks with 5.36 MB
Virtual space:
Non-class space: 360.00 MB reserved, 359.75 MB (>99%) committed
Class space: 256.00 MB reserved, 52.12 MB ( 20%) committed
Both: 616.00 MB reserved, 411.88 MB ( 67%) committed
Chunk freelists:
Non-Class:
specialized chunks: 1, capacity 1.00 KB
small chunks: (none)
medium chunks: (none)
humongous chunks: (none)
Total: 1, capacity=1.00 KB
Class:
specialized chunks: 1, capacity 1.00 KB
small chunks: 9, capacity 18.00 KB
medium chunks: (none)
humongous chunks: (none)
Total: 10, capacity=19.00 KB
Waste (percentages refer to total committed size 411.88 MB):
Committed unused: 88.00 KB ( <1%)
Waste in chunks in use: 12.22 KB ( <1%)
Free in chunks in use: 10.53 MB ( 3%)
Overhead in chunks in use: 2.18 MB ( <1%)
In free chunks: 20.00 KB ( <1%)
Deallocated from chunks in use: 5.36 MB ( 1%) (17832 blocks)
-total-: 18.18 MB ( 4%)
MaxMetaspaceSize: 768.00 MB
CompressedClassSpaceSize: 256.00 MB
Initial GC threshold: 768.00 MB
Current GC threshold: 768.00 MB
CDS: off
InitialBootClassLoaderMetaspaceSize: 4.00 MB
# 详细看一下CodeHeap空间的完整命令:
$jcmd 28040 Compiler.codecache
28040:
CodeHeap 'non-profiled nmethods': size=126784Kb used=80270Kb max_used=80270Kb free=46513Kb
bounds [0x00007f50f2143000, 0x00007f50f6fb3000, 0x00007f50f9d13000]
CodeHeap 'profiled nmethods': size=126780Kb used=93363Kb max_used=94520Kb free=33417Kb
bounds [0x00007f50ea574000, 0x00007f50f0214000, 0x00007f50f2143000]
CodeHeap 'non-nmethods': size=8580Kb used=2808Kb max_used=5690Kb free=5772Kb
bounds [0x00007f50e9d13000, 0x00007f50ea2b3000, 0x00007f50ea574000]
total_blobs=56234 nmethods=54803 adapters=1336
compilation: enabled
stopped_count=0, restarted_count=0
full_count=0
结论:没有关系,发现’non-profiled nmethods’,‘profiled nmethods’,‘non-nmethods’ 三个部分size之和才256M,不会造成整个容器内存膨胀到100%
至此发现非堆空间的使用量跟启动脚本的是一致的,并没有超过启动脚本指定的阀值,所以这部分也排除掉了。
附:启动脚本的几个核心参数:
SERVICE_OPTS="${SERVICE_OPTS} -Xms4g -Xmx4g"
SERVICE_OPTS="${SERVICE_OPTS} -XX:MetaspaceSize=768m -XX:MaxMetaspaceSize=768m -XX:CompressedClassSpaceSize=256m"
SERVICE_OPTS="${SERVICE_OPTS} -XX:MaxDirectMemorySize=512m"
SERVICE_OPTS="${SERVICE_OPTS} -XX:ReservedCodeCacheSize=256m -XX:+PrintCodeCache"
当然了,还可以把上述命令封装到一个脚本中写入到linux crontab中,让它自动周期执行
cat > /home/admin/$APP_NAME/logs/monitor.sh <&1 >> /home/admin/app_name_xxx/logs/monitor.log
堆外内存泄露?
堆外内存泄露?那么接下来的怀疑对象就是堆外内存这部分了,然而这部分的监控显示这部分内存使用非常稳定,堆外内存一直只占用200m内存左右,也没有增长过,也被排除掉了。

JVM工具江郎才尽,希望寄托到Linux命令工具pmap
JVM工具江郎才尽,希望寄托到Linux命令工具pmap,关于JVM内存泄露分析工具能想到的都用到了,在还没有头绪的情况下,接下来只能靠pmap命令来进一步分析了,首先去看一下ARENA区,在高并发的应用中,往往ARENA区占用的内存会比较多。为什么先看ARENA区的内存占用呢?是因为这个步骤是不需要重启JVM进程就可以完成的。
alioopid=`ps aux|grep java|grep $APP_NAME|awk -F ' ' '{print $2}'`
pmap $alioopid -x | sort -k 2 -n -r |less
# 如果存在大量大小为65536或60000左右的内存区域,则很大
ps可能是ARENA区域占用了太多的内存,如图2所示:
Address Kbytes RSS Dirty Mode Mapping
0000000700000000 4246912 4225732 4225732 rw--- [ anon ]
0000000803360000 463488 0 0 ----- [ anon ]
00007f252b556000 141992 0 0 r--s- modules
00007f250c000000 131072 77024 77024 rw--- [ anon ]
00007f2338000000 131072 82792 82792 rw--- [ anon ]
00007f252381d000 104192 104192 104192 rwx-- [ anon ]
00007f24e5abe000 103688 448 0 r---- locale-archive
00007f251bae5000 97728 97692 97692 rwx-- [ anon ]
00007f2534000000 65536 39080 39080 rw--- [ anon ]
00007f24f4000000 65536 65536 65536 rw--- [ anon ]
00007f24e0000000 65536 65520 65520 rw--- [ anon ]
00007f245c000000 65516 25140 25140 rw--- [ anon ]
00007f2430000000 65508 55648 55648 rw--- [ anon ]
00007f2500021000 65404 0 0 ----- [ anon ]
00007f24f0021000 65404 0 0 ----- [ anon ]
00007f24c8021000 65404 0 0 ----- [ anon ]
00007f2454021000 65404 0 0 ----- [ anon ]
00007f2424021000 65404 0 0 ----- [ anon ]
00007f241c021000 65404 0 0 ----- [ anon ]
00007f2418021000 65404 0 0 ----- [ anon ]
00007f2414021000 65404 0 0 ----- [ anon ]
00007f240c021000 65404 0 0 ----- [ anon ]
00007f2404021000 65404 0 0 ----- [ anon ]
00007f23f4021000 65404 0 0 ----- [ anon ]
00007f23ec021000 65404 0 0 ----- [ anon ]
00007f23e8021000 65404 0 0 ----- [ anon ]
00007f239c021000 65404 0 0 ----- [ anon ]
00007f2368021000 65404 0 0 ----- [ anon ]
00007f2358021000 65404 0 0 ----- [ anon ]
00007f22c8021000 65404 0 0 ----- [ anon ]
00007f22bc021000 65404 0 0 ----- [ anon ]
00007f2270021000 65404 0 0 ----- [ anon ]
00007f2254021000 65404 0 0 ----- [ anon ]
00007f21e0021000 65404 0 0 ----- [ anon ]
00007f21a4021000 65404 0 0 ----- [ anon ]
00007f2184021000 65404 0 0 ----- [ anon ]
00007f2124021000 65404 0 0 ----- [ anon ]
00007f2100021000 65404 0 0 ----- [ anon ]
00007f2058021000 65404 0 0 ----- [ anon ]
00007f2014021000 65404 0 0 ----- [ anon ]
注:pmap命令的输出结果几个部分详细含义:
Address Kbytes RSS Dirty Mode Mapping
Address:内存映射的起始地址。
Kbytes:内存映射的大小,以KB为单位。
RSS(KB):驻留内存大小,即实际使用的内存。
Dirty(KB):脏页大小,即被修改过的内存页。
Mode:内存映射的访问权限(r:可读,w:可写,x:可执行)。
Mapping:内存映射的来源(文件、设备、匿名内存等)。
可以看到64M内存块非常多,间隔一天后会发现64M内存块数量还会增多,这个跟每天的内存增长情况是可以对上的,那么问题来了,64M内存块存放的内容是什么,为什么每天都会增加呢?
glibc 使用内存池为 java 应用通过 malloc 申请堆外内存,当 jvm 回收内存归还操作系统时,操作系统在 free 的时候并不会真正释放内存,而是维护到 glibc 的内存池中供下次使用,从而避免重复申请(当时也有个想法 jvm 和 linux 层面的内存监控不一致,是不是 linux 并未真正释放内存)
$ldd /opt/xxxxxx/java/bin/java
linux-vdso.so.1 => (0x00007ffdd29e6000)
/lib/libsysconf-alibaba.so (0x00007f9037e4a000)
libjemalloc.so.2 => /opt/xxxxxx/java/bin/../lib/libjemalloc.so.2 (0x00007f9037c01000)
libz.so.1 => /lib64/libz.so.1 (0x00007f90379e7000)
libpthread.so.0 => /lib64/libpthread.so.0 (0x00007f90377cb000)
libjli.so => /opt/xxxxxx/java/bin/../lib/jli/libjli.so (0x00007f90375b9000)
libdl.so.2 => /lib64/libdl.so.2 (0x00007f90373b5000)
libc.so.6 => /lib64/libc.so.6 (0x00007f9036fe7000)
librt.so.1 => /lib64/librt.so.1 (0x00007f9036dde000)
libm.so.6 => /lib64/libm.so.6 (0x00007f9036adc000)
/lib64/ld-linux-x86-64.so.2 (0x00007f9038251000)
根据第4行内容,可以看到上面使用的是jemalloc(不是原生的 glibc 版本,这是因为我使用的是AJDK,AJDK底层已经采用了性能更好的jemalloc替换工具),为了验证是否能自动释放内存碎片,手动执行调用 malloc_trim 函数:
alioopid=`ps aux|grep java|grep $APP_NAME|awk -F ' ' '{print $2}'`
gdb --batch --pid=$alioopid -ex "call (int)malloc_trim(0)"
……
[New LWP 7568]
[New LWP 7569]
[New LWP 7570]
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib64/libthread_db.so.1".
0x00007f2310b36017 in pthread_join () from /lib64/libpthread.so.0
Thread 339 "sentinel-system" received signal SIGSEGV, Segmentation fault.
[Switching to Thread 0x7f226fded700 (LWP 3890)]
0x00007f22fd1ed557 in ?? ()
The program received a signal in another thread while
making a function call from GDB.
Evaluation of the expression containing the function
(malloc_trim) will be abandoned.
When the function is done executing, GDB will silently stop.
[Inferior 1 (process 2601) detached]
验证结果返回1表明有内存释放(0表示无内存释放),说明存在内存优化空间。执行完成之后再次查看此java进程内存占用,发现已经下降到3G多了(之前是6G)

方法1:禁用thread arena
这种情况下,最简单粗暴的办法是在JVM启动参数中增加配置:
export MALLOC_ARENA_MAX=1
这种解决问题的思路是禁用thread arena,经过预发环境验证此思路可行(什么是thread arena?如果应用程序每次分配内存的时候都通过系统调用 mmap,sbrk等来分配,效率会很低,所以glibc 中实现了一个内存池,应用程序使用内存的时候通过glibc的内存池来提供,早期的 glibc 版本中,只有一个内存池,称为 main arena,在多线程场景中,每次分配和释放需要进行加锁。后来为了降低锁的粒度,从glibc 2.10版本开始引入了 thread arena,线程在申请内存的时候,glibc 为他创建一个 thread arena,这个内存池的大小一般是64M,thread arena被不被某个线程独占,全部的 thread arena被加入到环形链表,被所有线程共享使用。)
方法2:升级ajdk到最新reelase版本
那么为什么之前没有内存泄漏,最近为什么会发生呢,联想到JDK近期版本升级过(jdk8->jdk11), 进一步思考会不会新版本会不会有Bug呢,结果根据JDK发布记录还真找到了一个堆外内存泄漏的Bug
AJDK 11.0.14.13_fp1发布内容:
● G1: 修复一个G1BarrierSkipDCQ下堆外内存泄漏问题. Redirty使用的C数据结构只在Full GC时清空, 在Young GC时没有清空.
○ 这个也可以解释为什么有流量的机器内存反而没有一直上涨(有流量的机器随着运行肯定会不断创建对象,也一会会触发fullGC)
发现应用使用的jdk版本比这个版本号要小,那么解决这个问题就是升级到jdk11的最新版本,经过预发环境验证此思路可行
附修复此Bug的关键代码:
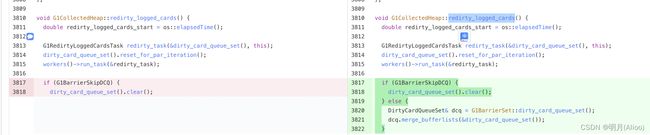
总结
上述2个方法都是可行的,方法1其实是禁用了thread arena,对性能是有一定影响的,故更加推荐方法2,也在此友情提醒大家升级JDK11时尽可能选择最新发布的release版本,避免重复踩坑
参考文章
https://dbaplus.cn/news-134-4002-1.html
https://easyice.cn/archives/341