LVS+Keepalivedd
Keepalived
- 一、Keepalived及其工作原理
- 二、实验
-
- 非抢占模式的设置
- 三、脑裂现象
- 四、Nginx高可用模式
一、Keepalived及其工作原理
keepalived是一个基于VRRP协议来实现的LVS服务高可用方案,可用解决静态路由出现的单点故障问题。
在一个LVS服务集群中通常有主服务器master和备用服务器backup两种角色的服务器,但是对外表现为一个虚拟IP(VIP),主服务器会发哦是那个VRRP通告信息给备份服务器,当备份服务器收不到VRRP消息的时候,即主服务器异常的时候,备份服务器就会接管虚拟IP,继续提供服务,从而保证了高可用性。
keepalived体系主要模块及其作用:
keepalived体系架构中主要有三个模块,分别是core、check、和vrrp
- core模块:为keepalived的核心,负责主进程的启动、维护及全局配置文件的加载和解析
- vrrp模块:实现vrr[协议,调度器之间的健康检查和主备切换
- check模块:负责健康检查,常见的方式有端口检查及URL检查,节点服务器的健康检查
二、实验
主DR服务器:192.168.136.51
备DR服务器:192.168.136.52
web服务器1:192.168.136.53
web服务器2:192.168.136.54
vip:192.168.136.188
客户端:192.168.136.55
1.配置负载调度器(主、备相同)
yum -y install ipvsadm keepalived
modprobe ip_vs
cat /proc/net/ip_vs
(1)配置keeplived(主、备DR 服务器上都要设置)
cd /etc/keepalived/
cp keepalived.conf keepalived.conf.bak
vim keepalived.conf

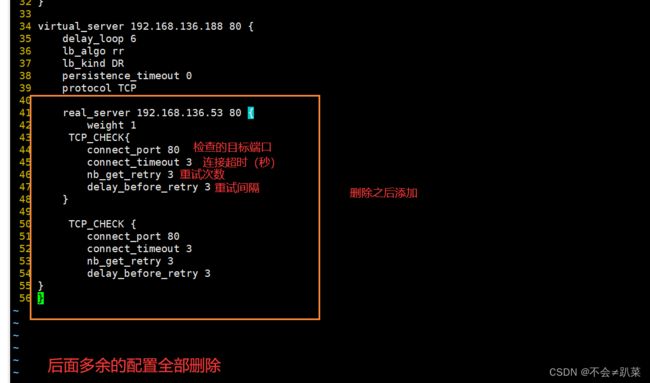
systemctl start keepalived
ip addr #查看虚拟网卡vip
两个负载调度器都得设置
(2)启动 ipvsadm 服务
ipvsadm-save > /etc/sysconfig/ipvsadm
systemctl start ipvsadm
(3)调整 proc 响应参数,关闭Linux 内核的重定向参数响应
vim /etc/sysctl.conf

2.配置节点服务器
systemctl stop firewalld
setenforce 0
yum -y install httpd
systemctl start httpd
–192.168.136.53—
echo ‘this is kgc web!’ > /var/www/html/index.html
–192.168.80.54—
echo ‘this is benet web!’ > /var/www/html/index.html
vim /etc/sysconfig/network-scripts/ifcfg-lo:0
DEVICE=lo:0
ONBOOT=yes
IPADDR=192.168.80.188
NETMASK=255.255.255.255
service network restart 或 systemctl restart network
ifup lo:0
ifconfig lo:0
route add -host 192.168.80.188 dev lo:0
vim /etc/sysctl.conf
net.ipv4.conf.lo.arp_ignore = 1
net.ipv4.conf.lo.arp_announce = 2
net.ipv4.conf.all.arp_ignore = 1
net.ipv4.conf.all.arp_announce = 2
sysctl -p
验证:

提问:
Keepalived通过什么判断哪台主机为主服务器,通过什么方式配置浮动IP?
答案:
Keepalived首先做初始化先检查state状态,master为主服务器,backup为备服务器。
然后再对比所有服务器的priority,谁的优先级高谁是最终的主服务器。
优先级高的服务器会通过ip命令为自己的电脑配置一个提前定义好的浮动IP地址。
keepalived的抢占与非抢占模式:
抢占模式即MASTER从故障中恢复后,会将VIP从BACKUP节点中抢占过来。非抢占模式即MASTER恢复后不抢占BACKUP升级为MASTER后的VIP
非抢占式俩节点state必须为bakcup,且必须配置nopreempt。
注意:这样配置后,我们要注意启动服务的顺序,优先启动的获取master权限,与优先级没有关系了。
非抢占模式的设置
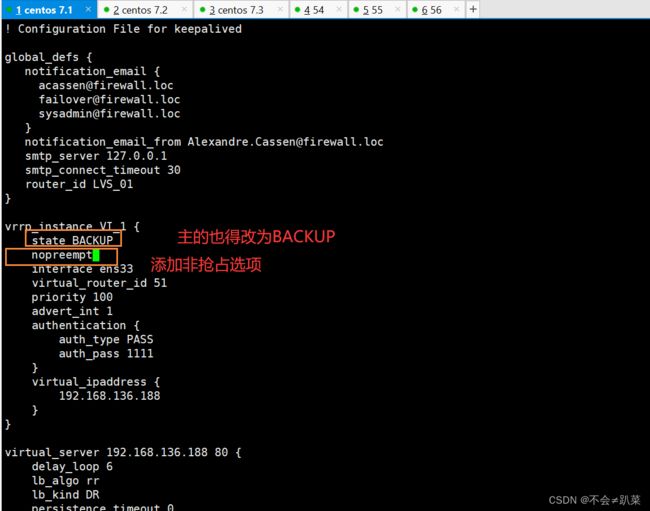

抢占模式在主的恢复之后会抢占回来,非抢占模式则不会再次抢占回来,除非副的挂掉了
三、脑裂现象
原因:
主调度器与备调度器之间会有一个连接,备是一直靠着接收主的存活信息来判断是否抢占成为主,如果这条链路断了,主还在运行,但是存活消息发送不到备,那么备就会抢占成为主,这样会导致有两个主,会导致数据流失。
判断方法:
使用一个节点服务器来Ping主调度器或者备调度器,若是能ping通,代表还在运行,如果ping不通,那就是挂掉了。
解决方案:关闭主调度器即可
判断链路有没有断的脚本:

Keepealived最常见的问题是会出现脑裂现象:
Master一直发送心跳消息给backup主机,如果中间的链路突然断掉,backup主机将无法收到master主机发送过来的心跳消息(也就是vrrp报文),backup这时候会立即抢占master的工作,但其实这时候的master是正常工作的,此时就会出现脑裂的现象。
预防:1.使用shell脚本对这两个主机之间的连通性进行监测,如果发现有问题,就会立即关闭keepalived服务来防止脑裂的产生。
2.增加一条链路作为备用链路,即使主链路挂掉了,备用链路也会顶上来,master主机可以继续给backup主机发送心跳消息。
3.3.使用监控软件的方法,这边主要是采用的zabbix来监控的,主要就是创建监控项,创建触发器来测试关闭keepalived服务。
四、Nginx高可用模式
在主副两个调度器上创建脚本,为了探测nginx进程是否存在
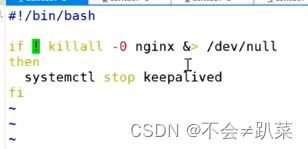
主调度器的keepalived配置文件


副调度器keepalived配置文件
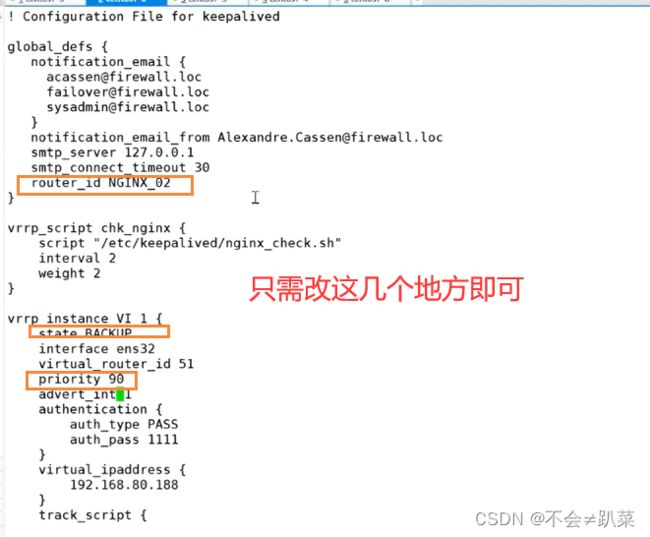
必须得先启动nginx才可以启用,否则脚本配置文件里的脚本无法执行