OpenMMLab-AI实战营第二期——4-2.MMDetection代码课
文章目录
- 1. MMDetection介绍(vs MMSegmentation,MMdetection3d)
- 2. MMCV和MMengine
-
- 2.1 mmopenlab框架
- 2.2 mmopenlab(涵盖其下所有库)的帮助文档和教程
- 2.3 MMengine
- 2.4 MMCV
- 3. 代码
-
- 3.1 使用pycocotools配合exif可视化图像
- 3.2 mmdetection中config的继承
- 3.3 mmdet的数据集可视化问题(VISUALIZERS)
- 3.4 pin_memory参数设置
- 3.5 max_split_size_mb设置
- 3.6 MMYOLO特征图可视化
- 3.7 数据集转为COCO格式
- 视频教程链接:MMDetection代码课
- 如果想为OpenMMLab项目做贡献,可以看看这个:https://openmmlab.com/activity/codecamp
1. MMDetection介绍(vs MMSegmentation,MMdetection3d)
三个项目的Github Readme:
- mmdetection/README_zh-CN.md
- mmsegmentation/README_zh-CN.md
- mmdetection3d/README_zh-CN.md
MMDetection 支持了各种不同的检测任务,包括目标检测,实例分割,全景分割,以及半监督目标检测。
- 检测是分割的基础,所以它也包含了很多分割任务,和MMSegmentation的区别是:
- 目前,MMSegmentation 支持的分割任务为语义分割 ,MMDetection 中支持了实例分割和全景分割。
- 详见:超详细!带你轻松掌握 MMSegmentation 整体构建流程
- 语义分割的应用:①自动驾驶;②遥感图像分析;③医学图像分析。
- 所以可以理解为专门为了这三个垂直方向把语义分割方向的模型(MMSegmentation)单独列出来了
- MMdetection3d这个库主要是面向3D的,感觉重点在点云数据上,支持与 2D 检测器(MMDetection)的自然整合
- 详见:全面支持激光雷达语义分割!MMDetection3D 新特性抢先看
- 关于MMpretrain,前面说的三个库也都有自己的预训练模型。
- 其实MMpretrain里主要放的模型大部分都是作为主干网络的模型,目前主要包括
图像分类,图像多标签分类和图像检索,里面并不包含mmdetection等的检测的预训练模型,详见:模型库统计。
- 其实MMpretrain里主要放的模型大部分都是作为主干网络的模型,目前主要包括
所以mmopenlab下面这些不同的repo,彼此之间功能还是很独立的,没有重复什么。
注意,
- (b)语义分割是分类+分割(一类物体一个颜色,自动驾驶其实用语义分割就够了),
- (c)实例分割(语义分割基础上+同类不同个体区分),
- (d)全景分割(全图的每个像素都要分)
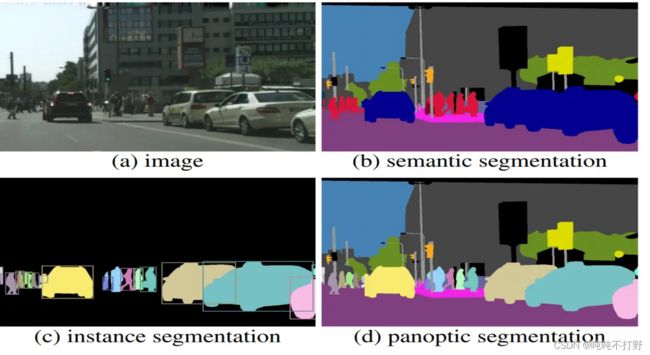
图自这里
2. MMCV和MMengine
课程过程中逐渐意识到这两个库的重要性,安装永远都是先安装这两个库,报错最后的位置源头基本也都是这两个库,所以稍微看一下。
注意:
- mmopenlab的库改动很快(还很大),文档有时候跟不上代码的改动。。
- 出问题的时候除了怀疑是自己代码或者配置出错,也要怀疑一下是不是库的问题(issue)
2.1 mmopenlab框架
根据:github-OpenMMLab的介绍,以下是整体框架图

基于Pytorch,
- OpenMMLab使用MMEngine作为统一的训练评估引擎,
- MMCV提供神经网络算子和数据变换,是整个项目的基础
- 其他面向具体方向的库:MMDection、MMSegmentation等,都是基于这两个库进行开发的。
- 所以关于config方面的内容,去MMengine里看;详细的神经网络算子和数据变换,去MMCV里看
2.2 mmopenlab(涵盖其下所有库)的帮助文档和教程
github-OpenMMLab的介绍文档里,其实给了一个比较不起眼的链接: tutorials videos (in Chinese) ,对应的是open-mmlab/OpenMMLabCourse项目,
- 这里基本涵盖了OpenMMLab的各种公开课,以及和其他机构的视频课程
- 同时还有知乎上的文章合集整理:OpenMMLabCourse/articles.md,
- 其实知乎上也分了专栏,但是感觉标题有点模糊
其实找找,有几个挺有意思的项目:
- mmfashion:https://github.com/open-mmlab/mmfashion
- open-mmlab-Playground:
- playground/mmtracking_open_detection
- MMEditing 将更加拥抱生成式 AI(Generative AI),正式更名为 MMagic(Multimodal Advanced, Generative, and Intelligent Creation),致力于打造更先进、更全面的 AIGC 开源算法库。这个库感觉好玩一点,
- Animated Drawings (SIGGRAPH’2023)
2.3 MMengine
关于MMengine,详见:MMengine-Doc-介绍。
- 核心组件包含训练引擎、评测引擎和模块管理
- 训练引擎的核心模块是执行器(Runner)。执行器负责执行训练、测试和推理任务并管理这些过程中所需要的各个组件。在训练、测试、推理任务执行过程中的特定位置,执行器设置了钩子(Hook)来允许用户拓展、插入和执行自定义逻辑。执行器主要调用如下组件来完成训练和推理过程中的循环:
- 数据集(Dataset):负责在训练、测试、推理任务中构建数据集,并将数据送给模型。实际使用过程中会被数据加载器DataLoader封装一层,数据加载器会启动多个子进程来加载数据。
- 模型(Model):在训练过程中接受数据并输出 loss;在测试、推理任务中接受数据,并进行预测。分布式训练等情况下会被模型的封装器Model Wrapper,如 MMDistributedDataParallel)封装一层。
- 优化器封装Optimizer:优化器封装负责在训练过程中执行反向传播优化模型,并且以统一的接口支持了混合精度训练和梯度累加。
- 参数调度器Parameter Scheduler:训练过程中,对学习率、动量等优化器超参数进行动态调整。
- 在训练间隙或者测试阶段,评测指标与评测器Metrics & Evaluator会负责对模型性能进行评测。其中评测器负责基于数据集对模型的预测进行评估。评测器内还有一层抽象是评测指标,负责计算具体的一个或多个评测指标(如召回率、正确率等)。
- 公共基础模块,算法模型执行过程中需要用到的公共基础模块,包括:
- 配置类(Config):在 OpenMMLab 算法库中,用户可以通过编写 config 来配置训练、测试过程以及相关的组件。
- 注册器(Registry):负责管理算法库中具有相同功能的模块。MMEngine 根据对算法库模块的抽象,定义了一套根注册器,算法库中的注册器可以继承自这套根注册器,实现模块的跨算法库调用。
- 文件读写(File I/O):为各个模块的文件读写提供了统一的接口,以统一的形式支持了多种文件读写后端和多种文件格式,并具备扩展性。
- 分布式通信原语(Distributed Communication Primitives):负责在程序分布式运行过程中不同进程间的通信。这套接口屏蔽了分布式和非分布式环境的区别,同时也自动处理了数据的设备和通信后端。
- 其他工具(Utils):还有一些工具性的模块,如 ManagerMixin,它实现了一种全局变量的创建和获取方式,执行器内很多全局可见对象的基类就是 ManagerMixin。
所以config主要是MMengine,config里有什么问题去MMengine里搜
2.4 MMCV
关于MMCV,详见:MMCV-Doc-介绍。
包括以下功能:
- 图像和视频处理:图像模块提供了一些图像预处理的函数,该模块依赖 opencv
- 所以putText默认不支持中文,想支持的话,可以看看这个issue:Can cv2. putText support Chinese output?python opencv #14579)
- 支持的图像处理函数,详见:Docs > 数据处理
- 图像和标注结果可视化:展示图像以及标注(目前只支持标注框)
- 这个功能比较简单,对应的就是代码里的这部分:mmcv/mmcv
/visualization/ - 目前只有三个脚本:
color.py,image.py,optflow.py
- 这个功能比较简单,对应的就是代码里的这部分:mmcv/mmcv
- 图像变换:就是配置文件里的数据变换pipeline指定的那部分内容
- 约定所有数据变换都接受一个字典作为输入,并将处理后的数据输出为一个字典
- 默认情况下,在需要图像尺寸作为初始化参数的数据变换 (如Resize, Pad) 中,图像尺寸的顺序均为 (width, height)。
numpy; 在数据变换返回的字典中,图像相关的尺寸, 如 img_shape、ori_shape、pad_shape 等,均为 (height, width)。opencv - 详见:数据变换
- 多种 CNN 网络结构:为卷积神经网络提供了一些构建模块,包括层构建、模块组件和权重初始化(专门的视觉库,所以不涉及RNN、LSTM那些)
- ✅高质量实现的常见 CUDA 算子:提供了检测、分割等任务中常用的算子,
- 例如:ActiveRotatedFilter, Iou3d, KNN, NMS等。
- 简单来说,算子就是用把一些功能用torch的tensor重写一遍,同时要保证可以融合到神经网络训练过程中的梯度计算、前向传播等
- 可以去看看代码:mmcv/mmcv/ops/iou3d.py
- 同时每一个都有配套的cuda代码:mmcv/mmcv/ops/csrc/common/cuda/iou3d_cuda_kernel.cuh,大部分都是头文件,确实是C++的语法
关于这个算子,可以看看:
- 手把手教你如何高效地在 MMCV 中贡献算子
- MMCV 是 follow PyTorch 官方提供的 Custom C++ and CUDA extension 进行算子扩展的,不能算是 “搞了一套完全不同的流程”。
另外,还看到一个知乎问题:mmcv及其系列存在的意义是什么?
- 结论就是:可能更适合学术,工程方面还是有点弱吧
3. 代码
- 视频中的链接并没有找到,但是有个差不多的:mmdetection/demo/MMDet_Tutorial.ipynb
- 特征可视化部分:
- mmYOLO-Docs > 可视化数据集分析结果
- MMYOLO 自定义数据集从标注到部署保姆级教程-6. 数据集可视化分析
- OpenMMLabCourse/codes/MMYOLO_tutorials/[工具类第一期]特征图可视化.ipynb
- 我照着视频里内容敲的(库版本可能不是很一致,有些结果无法完全复现):openMMLabCampusLearn/Exercise_3/Exercise_3.ipynb
3.1 使用pycocotools配合exif可视化图像
关于pycocotools库,捎带连COCO数据集格式一起说了,东西有点多,另外开了一篇,详见:
3.2 mmdetection中config的继承
mmopenlab的
_base_ = [
'../_base_/default_runtime.py', '../_base_/schedules/schedule_1x.py',
'../_base_/datasets/coco_detection.py', './rtmdet_tta.py'
]
有个歪门邪道的技巧,来获取继承之后完整的配置文件,
参考:
- mmdetection.readthedocs.io- 在标准数据集上训练预定义的模型(待更新)
- mmdetection.readthedocs.io-自定义数据集
- https://github.com/open-mmlab/mmdetection/blob/main/configs/rtmdet/rtmdet-ins_tiny_8xb32-300e_coco.py
3.3 mmdet的数据集可视化问题(VISUALIZERS)
from mmdet.registry import DATASETS,VISUALIZERS
我的结果是Filling的,教程的结果是没有Filling的

参考:
- 使用MMDetection3.x 在Balloon气球数据集上训练并对视频进行实例分割和制作成Color Splash效果
3.4 pin_memory参数设置
参考:
- 相关-37. 释放GPU显存
- 详解Pytorch里的pin_memory 和 non_blocking
3.5 max_split_size_mb设置
If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation
参考:
-
mmdetection-CUDA out of memory when testing
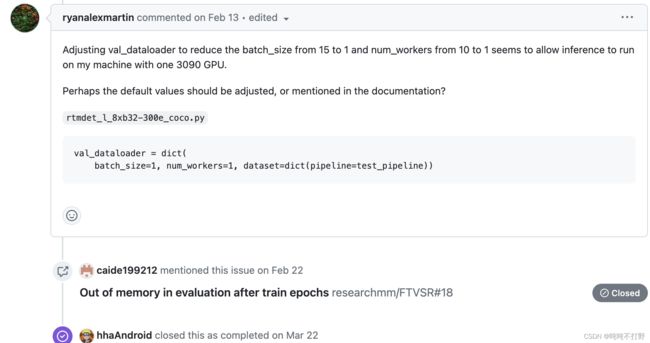
所以这个问题是已知的,训练结束后的validation阶段就会发生内存泄漏,要么就跳过val阶段。。。 -
RuntimeError: CUDA out of memory. How setting max_split_size_mb?
ValueError: val_dataloader, val_cfg, and val_evaluator should be either all None or not None, but got val_dataloader={'batch_size': 1, 'num_workers': 1, 'persistent_workers': True, 'drop_last': False, 'sampler': {'type': 'DefaultSampler', 'shuffle': False}, 'dataset': {'type': 'CocoDataset', 'data_root': '/content/cat_dataset', 'ann_file': 'annotations/test.json', 'data_prefix': {'img': 'images/'}, 'test_mode': True, 'pipeline': [{'type': 'LoadImageFromFile', 'backend_args': None}, {'type': 'Resize', 'scale': (640, 640), 'keep_ratio': True}, {'type': 'Pad', 'size': (640, 640), 'pad_val': {'img': (114, 114, 114)}}, {'type': 'PackDetInputs', 'meta_keys': ('img_id', 'img_path', 'ori_shape', 'img_shape', 'scale_factor')}], 'backend_args': None, 'metainfo': {'classes': ('cat',), 'palette': [(220, 20, 60)]}}}, val_cfg={'type': None}, val_evaluator=None
3.6 MMYOLO特征图可视化
AM(特征图可视化,激活值可视化),CAM(带有类的特征图可视化)
参考:
- https://mmyolo.readthedocs.io/zh_CN/latest/recommended_topics/visualization.html
- 玩转 MMYOLO 工具类第一期: 特征图可视化
3.7 数据集转为COCO格式
这个问题和3.1有相关性,都放在另一篇博客里了:
参考:
- TommyZihao/MMDetection_Tutorials/mmdet-0829/【E2】气球数据集 (2).ipynb
- 使用MMDetection3.x 在Balloon气球数据集上训练并对视频进行实例分割和制作成Color Splash效果