Python的基础语法知识
1、变量
变量是一个代号,它代表的是一个数据。
在Python中,定义一个变量的操作包含两个步骤:
①为变量起一个名字
②为变量指定其所代表的数据
这两个步骤在同一行代码中完成。
1.1 变量的命名规则
- 变量名可以由任意数量的字母、数字、下划线组合而成,但是必须以字母或下划线开头,不能以数字开头。如:a、b、a_1、b_1等。
- 不要用Python的关键字或内置函数来命名变量。例如,不要用print来命名变量,因为它与内置函数print()重名。
- 变量名对英文字母区分大小写。例如,D和d是两个不同的变量
- 建议使用英文字母和数字来组成变量名,并且变量名要有一定的意义,能够直观地描述变量所代表的数据内容。
1.2 演示
变量的赋值用等号‘=’来完成,‘=’的左边是一个变量,右边是该变量所代表的值。
Python有多种数据类型,但在定义变量时并不需要指明变量的数据类型,在变量赋值的过程中,Python会自动根据所赋值的值的类型来确定变量的数据类型。
x = 10
print(x)
y = x + 15
print(y)运行结果:

在第2行和第4行代码中用到的print()函数是python的一个内置函数,用于输出信息。
2、数据类型:数字与字符串
2.1 数字
数字可分为整型和浮点型两种。
2.1.1 整型
整型(integer,简写int)数字指不带小数点的数字,包括正整数、负整数和0。
以下都是整型:
a = 10
b = -80
c = 850000
d = 0
2.1.2 浮点型
浮点型(float)指带有小数点的数字。
a = 10.5
pi = 3.1414926
c = -0.153
2.2 字符串
字符串(string,简写str)就是由一个个字符连接起来的组合,组成字符串的字符可以是数字、字母、符号、汉字等。
字符串的内容需置于一对双引号内。
引号可以是单引号、双引号或三引号,且必须是英文状态下的引号。
print(123)
print('123')
输出两个123看起来没有任何差别,但是第一个是整型数字,可以参加加减乘除等算术运算;后一个是123是字符串,不能参与加减乘除等算术运算。
2.2.1 用单引号定义字符串
print('明天会更好')
2.2.2 用双引号定义字符串
print("明天会更好")
与单引号的效果是一样的。
2.2.3 用三引号定义字符串
print('''2023,
一起努力''')
运行结果:

可以发现,三引号中的字符串内容是可以换行的。如果只想使用单引号或双引号来定义字符串,但又想在字符串中换行,可以使用转义字符\n。
print('2023,\n一起加油')
除了\n之外,转义字符还有很多,它们的共同特征是:
反斜杠+想要实现的转义功能首字母
当我们想输出一个文件路径时:
print('d:\number.xlsx')
运行结果

可以发现python将路径字符串中的\n视为了一个转义字符了。
此时正确输出该文件路径应该是
print(r'd:\number.xlsx')
print('d:\\number.xlsx')
第一行通过在字符串的前面增加一个字符r来取消转义字符\n的换行功能;
第二行则是将路径中的”\“改为"\\"也是一个转义字符,代表一个反斜杠字符”\“。
2.3 数据类型的查询
当不知道该数据的类型时,可以使用python内置的type()函数来查询数据的类型。
a = 'Tam'
b = '88'
c = 23
d =55.345
print(type(a))
print(type(b))
print(type(c))
print(type(d))运行结果:

2.4 数据类型的转换
2.4.1 str()函数
str()函数能将数据转换成字符串,不管这个数据是整型数字还是浮点型数字。
a = 88
b = str(a)
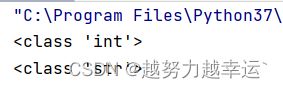
print(type(a))
print(type(b))运行结果:
2.4.2 int()函数
a = '88'
b = int(a)
print(type(a))
print(type(b))运行结果:

浮点型数字也可以被int()函数转换为整数,转换过程中的取整处理方式不是四舍五入,而是直接舍去小数点后面的数,只保留整数部分。
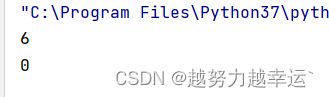
print(int(6.8))
print(int(0.6154))运行结果:
2.4.3 float()函数
float()函数可以将整型数字和内容为数字的字符串转换为浮点型数字。
pi = '3.14545'
pi1 = float(pi)
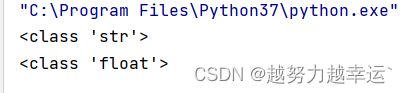
print(type(pi))
print(type(pi1))运行结果:
3、数据类型:列表、字典、元组与集合
3.1 列表
语法格式:
列表名 = [元素1,元素2,元素3,……]
列表的元素可以是字符串,也可以是数字,甚至可以是一个另一个列表。
1、利用for语句可以遍历列表中的所有元素
list = ['yiyi','erer','sansan','sisi','wuwu']
for i in list:
print(i)2、统计列表元素个数
统计列表的个数(又叫列表的长度),可以使用len()函数。
语法格式:
len(列表名)
list = ['yiyi','erer','sansan','sisi','wuwu']
a = len(list)
print(a) # 53、提取列表的单个元素
提取列表的单个元素,可以在列表名后加上"[序号]"
list = ['yiyi','erer','sansan','sisi','wuwu']
a = list[1]
print(a) # erer为什么list[1]提取的不是‘yiyi’呢 ?,因为python中序号都是从0开始的,所以list[0]才是提取‘yiyi’。
4、提取列表的多个元素——列表切片
语法格式:
列表名[序号1:序号2]
序号1的元素可以提取到,而序号2的元素提取不到,俗称”左闭右开“。
list = ['yiyi','erer','sansan','sisi','wuwu']
a = list[1:4]
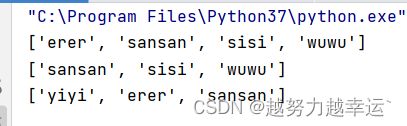
print(a) # ['erer', 'sansan', 'sisi']list = ['yiyi','erer','sansan','sisi','wuwu']
a = list[1:] # 提取第2个元素到最后一个元素
b = list[-3:] # 提取倒数第3个元素到最后一个元素
c = list[:-2] # 提取倒数第2个元素之前的所有元素(因为”左闭右开“,所以不包含道倒数第二个元素)
print(a)
print(b)
print(c)运行结果:
5、添加列表元素
用append()函数可以给列表添加元素。
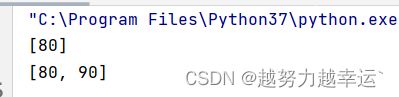
score = []
score.append(80) # 用append()函数给列表添加一个元素
print(score)
score.append(90) # 给列表在添加一个元素
print(score)运行结果:
6、列表与字符串的相互转换
语法格式:
‘连接符’.join(列表名)
引号(单引号、双引号皆可)中的内容是元素之间的连接符,如:“,” “;”等。
list = ['yiyi','erer','sansan','sisi','wuwu']
# 将list转换成一个用逗号连接的字符串
a = ','.join(list)
print(a) # yiyi,erer,sansan,sisi,wuwu将字符串转换为列表主要用的函数是split()
语法格式:
字符串.split('分隔符')
# 使用空格作为分隔符,将字符串“hi hello world”拆分成列表
a = 'hi hello world'
print(a.split(' ')) # ['hi', 'hello', 'world']3.2 字典
字典是另一种存储数据的方式。
定义一个字典基本语法格式:
字典名 = {键1 : 值1, 键2 : 值2, 键3 : 值3,……}
字典的每个元素都由两个部分组成(而列表的每个元素只有一个部分),前一个部分称为键,后一个部分称为值,中间用冒号连接。
dict ={'一一':85,'二二':99,'三三':75,'四四':95,'五五':55}提取字典中某个元素的值的语法格式:
字典吗['键名']
# 提取“二二”的分数
dict1 = dict["二二"]
print(dict1) # 99如果想输出每个人的姓名和分数
dict ={'一一':85,'二二':99,'三三':75,'四四':95,'五五':55}
for i in dict:
print(i+':'+str(dict[i]))运行结果:

这里的i是字典里的键,dict[i]则是键对应的值,即每个人的分数。因为分数为数字,所在在进行字符串拼接前需要先用str()函数转换为字符串。
另一种遍历字典的方法用字典items()函数
dict ={'一一':85,'二二':99,'三三':75,'四四':95,'五五':55}
a = dict.items()
print(a)运行结果,items()函数返回的是可遍历的(键,值)元组数组。

3.3 元组和集合
元组的定义和使用方法与列表非常类似,区别在于定义列表的符号是中括号[],而定义元组的符号是小括号(),并且元组中的元素不可修改。
a = ('yiyi','haha','sansan','sisi','wuwu')
print(a[1:3])运行结果:

可以看到,元组的元素提取方法和列表是一样的。
集合是一个无序的不重复序列, 也就是说,集合中不会有重复的元素。可以使用大括号{}来定义集合,也可以使用set()函数来创建集合。
a = {'一一','二二','三三','四四','五五','一一','三三'}
print(set(a))运行结果:

4、运算符
4.1 算术运算符和字符串运算符
| + | 加法运算符,计算两个数相加的和 |
| - | 减法运算符,计算两个数相减的差 |
| * | 乘法运算符,计算两个数相乘的积 |
| / | 除法运算符,计算两个数相除的商 |
| ** | 幂运算符,计算一个数的某次方 |
| // | 取整除运算符,计算两个数相除的商的整数部分(舍弃小数部分,不做四舍五入) |
| % | 取模运算符,冲用于计算两个正整数相除的余数 |
“+”和“*”除了能作为算术运算符对数字进行运算,还能作为字符串运算符对字符串进行运算。
“+”用于拼接字符串,“*”用于将字符串复制指定的份数。
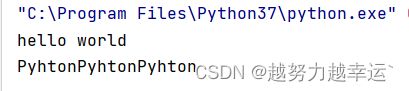
a = 'hello'
b = 'world'
c = a+ ' ' + b
print(c)
d = 'Pyhton' * 3
print(d)运行结果:
4.2 比较运算符
比较运算符又称为关系运算符,用于判断两个值之间的大小关系,其运算结果为True(真)或False(假)。比较运算符通常用于构造判断条件,以根据判断的结果来决定程序的运行方向。
| > | 大于,判断运算符左侧的值是否大于右侧的值 |
| < | 小于,判断运算符左侧的值是否小于右侧的值 |
| >= | 大于等于,判断运算符左侧的值是否大于等于右侧的值 |
| <= | 小于等于,判断运算符左侧的值是否小于等于右侧的值 |
| == | 等于运算符,判断运算符左右两侧的值是否相等 |
| != | 不等于运算符,判断运算符左右两侧的值是否不相等/ |
a = 10
if a < 20:
print('还要加油') # 还要加油注意:“=”是赋值运算符,作用是给变量赋值
“==”是比较运算符,作用是比较两个值是否相等。
a = 1
b = 2
if a == b: # 注意这是两个等号
print('a和b相等')
else:
print('a和b不相等') # a和b不相等4.3 赋值运算符
| = | 简单赋值运算符,将运算符右侧的值分配给左侧 |
| += | 加法赋值运算符,执行加法运算并将结果分配给左侧 |
| -= | 减法赋值运算符,执行减法运算并将结果分配给左侧 |
| *= | 乘法赋值运算符,执行乘法运算并将结果分配给左侧 |
| /= | 除法赋值运算符,执行除法运算并将结果分配给左侧 |
| **= | 幂赋值运算符,执行幂运算并将结果分配给左侧 |
| //= | 取整除赋值运算符,执行取整除运算并将结果分配给左侧 |
| %= | 取模赋值运算符,执行取模运算并将结果分配给左侧 |
prince = 100
prince += 10
print(prince) # 110 第2行代码表示将变量prince的当前值(100)与(10)相加,再将计算结果重新赋值给变量prince,相当于prince=prince+104.4 逻辑运算符
逻辑运算符的运算结果也为True或False,因而也通常用于构造判断条件来决定程序的运行方向。
| and | 逻辑与,只有该运算符左右两侧的值都为True时才返回True,否则返回False |
| or | 逻辑或,只有该运算符左右两侧的值都为False时才返回False,否则返回True |
| not | 逻辑非,该运算符右侧的值为True时返回False,为False时则返回True |
# 例如,仅在某条新闻同时满足“分数是负数”和年份是2019年“这两种条件时,才把它录入数据库
score = -10
year = 2019
if (score < 0) and (year == 2019):
print('录入数据库')
else:
print('不录入数据库') 运行结果: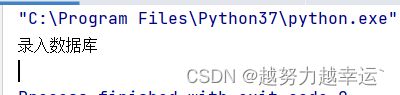
把第3行代码中的“and”换成“or”,那么只要满足一个条件,就可以录入数据库。
5、编码基本规范
5.1 缩进
缩进类似于Word的首行缩进。
如果缩进不规范,代码在运行时就会报错。
缩进是快捷键是【Tab】键,在if、for、while等语句中都会用到缩进。
x = 10 # 当x = 10 时
if x > 0: # 如果x大于0:
print('正数') # 输出字符串‘正数’
else: # 否则:
print('负数') # 输出字符串‘负数’在输入第3行和第5行代码之前,必须按【Tab】来缩进,否则运行代码会报错
如果要减小缩进量,可按快捷键【Shift+Tab】。
如果要同时调整多行代码的缩进量,可以选中要调整的多行代码,按【Tab】键统一增加缩进量,按快捷键【Shift+Tab】统一减小缩进量。
5.2 注释
# 3个单引号表示多行注释
'''
这是多行注释,用3个单引号
这是多行注释,用3个单引号
这是多行注释,用3个单引号
'''
print('hello ,python')5.2.1 单行注释
单行注释以“#”好开头。
单行注释可以放在被注释代码的后面,也可以作为单独的一行放在被注释代码的上方。
a = 1
b = 2
if a == b: # 注意表达式里是两个等号
print('a和b相等')
else:
print('a和b不相等')第三行代码中的“#”号后面的内容就是注释内容,它不参与程序的运行。
5.2.2.多行注释
# 3个单引号表示多行注释
'''
这是多行注释,用3个单引号
这是多行注释,用3个单引号
这是多行注释,用3个单引号
'''
print('hello ,python')第2-6行代码就是注释,不参与运行。
注释还有一个作用,就是在调试程序时可以把暂时不需要运行的代码转换为注释,而不是删除,等调试结束后再取消注释。
6、控制语句
6.1 if语句
语法格式
if 条件: # 注意不要遗漏冒号
代码1 # 注意代码前要有缩进
else: # 注意不要遗漏冒号
代码2 # 注意代码前要有缩进
score = 95
if score >= 60:
print('及格')
else:
print('不及格')
# 输出 及格如果有多个判断条件,可以用elif语句来处理
score = 95
if score >= 80:
print('优秀')
elif (score >= 60) and (score < 80):
print('及格')
else:
print('不及格')
# 结果 优秀6.2 for语句
for语句常用于完成指定次数的重复操作
语法格式:
for i in 序列: # 注意不要遗漏冒号
要重复执行的代码 # 注意代码前要有缩进
list = ['一一','二二','三三']
for i in list:
print(i)运行结果:
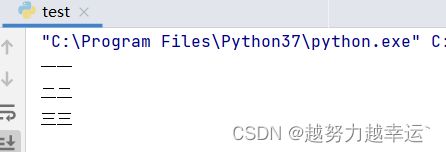
for语句再执行过程中,会让i依次从列表liet的元素里取值,每取一个元素就执行一次第三行代码,知道取完所有元素为止。因为列表list有3个元素,所以第3行代码会被重复执行3次。
上述代码用列表作为控制循环次数的序列,还可以用字符串、字典等来作为序列。如果序列是一个字符串,则i代表字符串的字符;如果序列是一个字典,则i代表字典的键名。
还可以用range()函数来创建一个整数序列
a = range(5)
range()函数创建的序列默认从0开始,并且该函数具有与列表切片类似的“左闭右开”特性,因此,这行代码表示创建一个0-4的整数序列(即0、1、2、3、4)并赋给变量a。
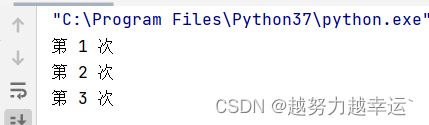
for i in range(3):
print('第',i+1,'次')运行结果:
6.3 while语句
while语句用于指定条件成立时重复执行操作。
语法结构:
while 条件: # 注意不要遗漏冒号
要重复执行的代码 # 注意代码前要有缩进
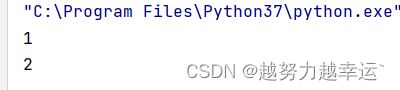
a = 1
while a < 3:
print(a)
a = a+1 # 也可以写成 a+=1第1行代码让a的初始值为1;
第2行代码的while语句会判断 a的值是否满足“小于3”的条件,判断结果是满足,因此执行第3、4行代码,先输出a的值1,再将a的值增加1变成2;
随后返回第2行代码进行判断,此时a的值仍然满足“小于3”的条件,所以会再次执行第3、4行代码,先输出a的值2,再将a的值增加1变成3;
随后返回第2行代码进行判断,此时a的值已经不满足“小于3”的条件,循环便终止了,不再执行第3、4行代码。
运行结果:
while语句经常与True搭配使用来创建永久循环
基本语法
while True:
要重复执行的代码
要是想试试永久循环,则可输入以下代码:
while True:
print('hahha')强制停止永久循环,在IDLE中按快捷键【CTRL+C】,在pycharm中安快捷键【CTRL+F2】
6.4 控制语句的嵌套
控制语句的嵌套是指在一个控制语句中包含一个或多个相同或不同的控制语句。
math = 95
chinese = 80
if math >= 90:
if chinese >= 90:
print('优秀')
else:
print('加油')
else:
print('加油')这个嵌套结构的含义是:
如果math的值大于等于90,且Chinese的值也大于等于90,则输出“优秀”;
如果math的值大于等于90,且Chinese的值小于90,则输出“加油”;
如果math的值小于90,则无论Chinese的值为多少,都输出“加油”。
for i in range(5):
if i == 1:
print('加油')
else:
print('安静')第1-5行代码为一个for语句
第2-5行代码为一个if语句,后者嵌套在前置之中。
第1行代码中for语句和range()函数的结合使用让i可以依次取值0、1、2、3、4,然后进入if语句,当i的值等于1时,输出“加油”,否则输出“安静”。
7、函数
函数就是把具有独立功能的代码块组织成一个小模块,在需要是直接调用。
函数又分内置函数和自定义函数。
7.1 内置函数
7.1.1 len()函数
len()函数可以统计列表的元素个数
title = ['标题1','标题2','标题3']
print(len(title))统计字符串的长度
a = 'abae32425'
print(len(a))还可以与range()函数一起使用
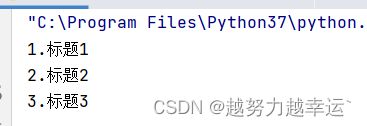
title = ['标题1','标题2','标题3']
for i in range(len(title)):
print(str(i+1)+'.'+title[i])第2行代码中的range(len(title))就表示range(3),因此for语句中的i会依次取值为0、1、2,在生成标题序号是就要写成i+1,并用str()函数转换成字符串,再用“+”运算符进行字符串拼接。
运行结果:
7.1.2 replace()函数
replace()函数主要用于在字符串中进行查找和替换
语法格式
字符串.replace(要查找的内容,要替换的内容)
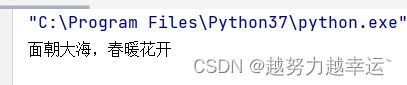
a = '面朝大海,春暖花开'
a = a.replace('','')
a = a.replace('','')
print(a)在第2行和第3行代码中,replace()函数的第2个参数的引号中没有任何内容,因此,这两行代码表示将查找到的内容删除。
运行结果:
7.1.3 strip()函数
strip()函数的主要作用是删除字符串首尾的空白字符(包括换行符和空格),
语法结构
字符串.strip()
b = ' 今天天气 真好 '
b = b.strip()
print(b)运行结果:
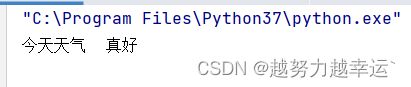
可以看到,字符串首尾的空格都被删除了,字符串中间的空格则被保留下来。
7.1.4 split()函数
split()函数的主要作用是按照指定的分隔符将字符串拆分为一个列表
语法结构
字符串.split('分隔符')
today = '2023-06-10'
a = today.split('-')
print(a)如果想调用拆分字符串得到年、月、日信息
a = today.split('-')[0] # 获取年信息,即拆分字符串所得列表的第1个元素
a = today.split('-')[1] # 获取月信息,即拆分字符串所得列表的第2个元素
a = today.split('-')[2] # 获取日信息,即拆分字符串所得列表的第3个元素7.2 自定义函数
7.2.1 函数的定义与调用
基本语法
def 函数名(参数):
代码
def y(x):
print(x + 1)
y(1) # 2第1行和第2行代码定义了一个函数y(),该函数有一个参数x,函数的功能是输出x+1的运算结果。第3行代码调用了y()函数,并将1作为y()函数的参数。
从上述代码可以看出,函数的调用很简单,只要输入函数名,如函数名y,如果函数含有参数,如函数y(x)中的x,那么在函数名后面的括号中输入参数的值即可。如果将上述第3行代码修改为y(2),那么运行结果就是3。
定义函数时的参数称为形式参数,它只是一个代号,可以换成其他内容。
def y(z):
print(z + 1)
y(1) # 2定义函数参数时也可以传入多个参数,以自定义含有两个参数的函数为例
def y(x,z):
print(x + z +1)
y(1,2) # 4因为第1行代码在定义函数时指定了两个参数x和z,所以在第3行代码在调用函数时就得在括号中输入两个参数。
定义函数也可以不要参数,如下:
def y():
x = 1
print(x + 1)
y() # 27.2.2 定义有返回值的函数
在定义函数时使用return语句来定义函数的返回值。
def y(x):
return x+1
a = y(1)
print(a) # 2在第1行和第2行代码定义了一个函数y(),函数的功能不是直接输出x+1的运算结果,而是将x+1的运算结果作为函数的返回值返回给调用函数的代码;第3行代码在执行时会先调用y()函数,并以1作为函数的参数,y()函数内部使用参数1计算出1+1的结果为2看,在将2返回给第3行代码,赋给变量a。
7.2.3 变量的作用域
函数内使用的变量与函数外的代码是没有关系的。
x = 1
def y(x):
x = x + 1
print(x)
y(3)
print(x)
# 运行结果
# 4
# 1第4行和第6行代码同样是print(x),为什么输出的内容不一样呢?这是因为函数y(x)里面的x和外面的x没有关系。
可以把y(x)换成y(z)
x = 1
def y(z):
z = z + 1
print(z)
y(3)
print(x)
# 运行结果
# 4
# 1可以发现两段代码的运行结果一样。y(z)中的z或者说y(x)中的x只在函数内部生效,并不会影响外部的变量。函数的形式参数只是一个代号,属于函数的局部变量,因此不会影响外部的变量。