Python模块
1 模块的导入
1.1 import语句导入法
基本语法
import 模块名
# 演示
import math # 导入math模块
import turtle # 导入turtle模块# 示例
import math
a = math.sqrt(16)
print(a) # 4第2行代码要调用math模块中的sqrt()函数来计算16的平方根,所以在sqrt()函数前加上了模块名math的前缀。
1.2 from语句导入法
有些模块中的函数特别多,用import语句全部导入后会导致程序运行速度较慢,将程序打包后得到的文件体积也会很大。
如果只需要使用模块中的少数几个函数,就可以采用from语句导入法,这种方法可以指定要导入的函数。
基本语法格式
from 模块名 import 函数名
from math import sqrt # 导入math模块中的单个函数
from turtle import forward,backward,right,left # 导入turtle模块中的多个函数使用该方法导入模块的最大优点就是在调用函数时可以直接写出函数名,无须添加模块名前缀。
from math import sqrt # 导入math模块中的sqrt()函数
a = sqrt(16)
print(a)因为第1行代码中已经写明了要导入哪个模块中的哪个函数,所以第2行代码中就可以直接用函数名调用函数。
提示:当模块名或函数名很长,可以在导入时使用as关键字对它们进行简化。
import xlwings as xw # 导入xlwings模块,并将其简写为xw
from math import factorial as fc # 导入math模块中的factorial()函数,并将其简写为fc提示:使用from语句导入法时,如果将函数名用通配符“*”代替,写出“from 模块名 import * ”,则和import语句导入法一样,会导入模块中的所有函数。
2 处理文件和文件夹的模块——os
os模块是python和操作系统进行交互的一个接口,提供了许多操作文件及文件夹的函数。
2.1 获取当前运行的python代码文件路径
要获取当前运行的Python代码文件的路径(即该文件的保存位置),可以用os模块中的getcwd()函数来实现。
在C盘中新建一个“list”文件夹,再在其中新建一个Python代码文件(扩展名为“.py”),然在该文件中输入以下代码。
import os
path = os.getcwd()
print(path)运行结果:

2.2 列出指定路径下的文件夹包含的文件和子文件夹名称
如果要查看某个文件夹包含的所有文件和子文件夹的名称,可以使用os模块中的listdir()函数。
# 要列出D盘的“list”文件夹下的所有文件和子文件夹的名称
import os
path = 'D:\\list'
file_list = os.listdir(path)
print(file_list)2.3 分离文件主名和扩展名
如果要分离一个文件的文件主名和扩展名,可以使用splitext()函数。
import os
path = 'example.xlsx'
separate = os.path.splitext(path)
print(separate)运行结果:

可以看到splitext()函数返回的是一个包含两个元素的元组,前一个元素是文件主名,后一个元素是扩展名。
2.4 重命名文件和文件夹
os模块中的rename()函数可以重命名文件和文件夹。
语法格式
rename(src,dst)
参数src:指定要重命名的文件或文件夹
参数dst:指定文件或文件夹的新名称
# 将D盘“list”文件夹下的“test.xlsx"文件重命名为”example.xlsx“
import os
oldname = 'd:\\list\\test.xlsx'
newname = 'd:\\list\\example.xlsx'
os.rename(oldname,newname)注意:如果D盘的"list"的文件夹下没有名为“test.xlsx”的文件,则会显示“FileNotFoundError”的异常提示。如果D盘的“list”文件夹下已经存在名为“example.xlsx ”的文件,也会报错。
rename()函数还可修改文件路径
import os
oldname = 'd:\\list\\test.xlsx'
newname = 'd:\\mask\\example.xlsx'
os.rename(oldname,newname)对文件夹重命名
import os
oldname = 'd:\\list'
newname = 'd:\\newlist'
os.rename(oldname,newname)注意:在对文件夹进行重命名时,只能重命名最后一级的文件夹,而不能像重命名文件那样移动位置。
3 批量处理Excel文件的模块——xlwings
可以处理Excel文件的python模块有很多,如XlsxWriter、xlrd、xlwt、xlutils、openpyxl和xlwings等。
| XlsxWriter | xlrd | xlwt | xlutils | openpyxl | xlwings | |
| 读 | × | √ | × | √ | √ | √ |
| 写 | √ | × | √ | √ | √ | √ |
| 修改 | × | × | × | √ | √ | √ |
| 支持xls格式 | × | √ | √ | √ | × | √ |
| 支持xlsx格式 | √ | √ | √ | × | √ | √ |
| 支持批量操作 | × | × | × | × | × | √ |
通过上表可以发现,xlwings模块的功能是最齐全的。
3.1 创建工作簿
利用xlwings模块创建一个新的工作簿
import xlwings as xw
app = xw.App(visible= True,add_book=False)
workbook = app.books.add()第1行代码导入xlwings模块并简写为xw。
第2行代码启动Excel程序窗口,但不新建工作薄。App()是xlwings模块中的函数,该函数有两个常用参数:visible用于设置Excel程序窗口的可见性,如果为True,表示显示Excel程序窗口,如果为False,表示隐藏Excel程序窗口;add_book用于设置启动Excel程序窗口后是否新建工作薄,如果为True,表示新建一个工作簿,如果为False,表示不新建工作簿。
第3行代码新建一个工作簿。其中add()为books对象的函数,用于新建工作簿。
3.2 保存工作簿
对上面创建的工作簿进行保存
workbook.save('d:\\example.xlsx')
workbook.close() # 关闭工作簿
app.quit() # 退出Excel程序第1行中的save()函数用于保存前面创建的空白工作簿,括号里的参数为工作簿的保存路径和文件名。
绝对路径:表示文件的路径总是从根文件夹开始。例如,如果操作系统是Windows,那么就以盘符(C:、D:等)作为根文件夹。
第1行中的'd:\\example.xlsx'就是一个绝对路径
相对路径:表示相对于当前运行的代码文件的路径。例如,如果将第1行代码修改为“workbook.save('.\example.xlsx')”或“workbook.save('example.xlsx')”,那么就会在代码文件夹下创建一个名为“example.xlsx”的工作薄。
第2行代码中的close()函数用于关闭创建的工作簿。
第3行代码中的quit()函数用于退出Excel程序。
3.3 打开工作薄
利用xlwings模块打开一个已有的工作簿
import xlwings as xw
app = xw.App(visible=True,add_book=False)
workbook = app.books.open(r'd:\example.xlsx') # 打开D盘根文件下名为“example.xlsx"的工作簿注意:指定的工作簿必须真实存在,并且不能处于以打开的状态。
3.4 操控工作表和单元格
xlwings模块还能操控工作表和单元格。在3.3的代码后面继续输入
worksheet = workbook.sheets['Sheet1'] # 选中工作表”Sheet1“
worksheet.range('A1').value = '编号' # 在单元格A1中输入内容在打开的工作簿中新增一个工作表,在3.3的代码后继续输入
worksheet = workbook.sheets.add('产品统计表') # 新增一个名为”产品统计表“的工作表import xlwings as xw
app = xw.App(visible=False)
workbook = app.books.add()
worksheet = workbook.sheets.add('产品统计表')
worksheet.range('A1').value = '编号'
workbook.save(r'd:\北京.xlsx')
workbook.close()
app.quit()运行后会看到在D盘的根文件夹下新建了一个名为”北京.xlsx"的工作簿,该工作簿中有一个名为“产品统计表”的工作表,该工作表的单元格A1中输入了内容“编号”。
4 数组计算的数学模块——numpy
Numpy模块的名称是由“Numerical Python”缩写来的,这个模块是一个运行速度非常快的数学模块,主要用于数组计算。
4.1 数组的基础知识
import numpy as np
a = [1,2,3,4]
b = np.array([1,2,3,4]) # 创建数组的一种方式,array就是数组的意思
print(a) # 输出变量a的值
print(b) # 输出变量b的值
print(type(a)) # 输出变量a的数据类型
print(type(b)) # 输出变量b的数据类型
第3行代码中的array()是Numpy模块中的函数,用于创建数组。
运行结果:
 提取列表和数组中的元素。
提取列表和数组中的元素。
import numpy as np
a = [1,2,3,4]
b = np.array([1,2,3,4]) # 创建数组的一种方式,array就是数组的意思
print(a[1]) # 提取列表a的单个元素
print(b[1]) # 提取数组b的单个元素
print(a[0:2]) # 对列表a进行切片
print(b[0:2]) # 对数组b进行切片运行结果:

从运行结果可以看出,列表和数组有着相似的元素索引机制,唯一的区别就是数组中的元素用空格分隔,而列表中的元素用逗号分隔了。
数组能很好支持一些数学运算,而列表来完成数学运算则较为麻烦。
import numpy as np
a = [1,2,3,4]
b = np.array([1,2,3,4])
c = a * 2
d = b * 2
print(c)
print(d)运行结果:

可以看到同样是做乘法运算,列表是把元素复制了一遍,而数组则是对每个元素都进行了乘法运算。
数组可以存储多维数据,而列表通常只能存储一维数据。
import numpy as np
e = [[1,2],[3,4],[5,6]] # 大列表里嵌套小列表
f = np.array([[1,2],[3,4],[5,6]]) # 创建二维数组的一种方式
print(e)
print(f)运行结果:

可以看到,列表e虽然包含了3个小列表,但其结构是一维的。
数组f则是3行2列的二维结构。
4.2 数组的创建
import numpy as np
# 创建一维数组
a = np.array([1,2,3,4])
# 创建二维数组
b = np.array([[1,2],[3,4],[5,6]])使用np.arange()函数来创建一维数组,该函数的括号里可以输入1~3个参数,会得到不同的效果。
import numpy as np
# 1个参数:起点取默认值0,参数值为终点,步长取默认值1,左闭右开
x = np.arange(5)
# 2个参数,第一个参数为起点,第2个参数为终点,步长取默认值1,左闭右开
y = np.arange(5,10)
# 3个参数,第一个参数为起点,第2个参数为终点,第3个参数为步长,左闭右开
z = np.arange(5,10,2)
print(x)
print(y)
print(z)运行结果:

使用np.random中的函数创建随机一维数组。
例如,用np.random.randn(3)创建一个一维数组,其中包含服从正态分布(均值为0、标准差为1的分布)的3个随机数。
import numpy as np
c = np.random.randn(3)
print(c)运行结果:
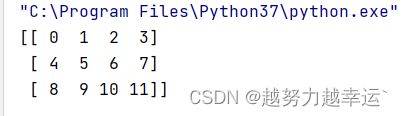
二维数组,可以利用创建一维数组的np.arange()函数和reshape()函数来创建。
例如,将包含0-11这12个整数的一维数组转换成3行4列的二维数组。
import numpy as np
d = np.arange(12).reshape(3,4)
print(d)运行结果
创建随机整数二维数组的方法
import numpy as np
e = np.random.randint(0,10,(4,4))
print(e)运行结果
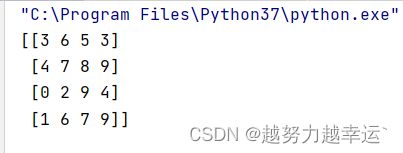
第2行代码中的np.random.randint()函数用来创建随机整数,括号里第1个参数0为起始数,第2个参数10为终止数,第3个参数(4,4)则表示创建一个4行4列的二维数组。
5 数据导入和整理模块——pandas
pandas模块提供了非常直观的数据结构及强大的数据管理和数据处理功能,与numpy相比,pandas模块更擅长处理二维数据,其主要有Series和DataFrame两种数据结构。
Series类似于通过Numpy模块创建一维数组,不同的是Series对象不仅仅包含数值,还包含一组索引。
import pandas as pd
s = pd.Series(['一一','二二','三三'])
print(s)运行结果

可以看到,s是一个一维数据结构,并且每个元素都有一个可以用来定位的行索引。
5.1 二维数据表格DataFrame的创建与索引的修改
5.1.1 DataFrame的创建
DataFrame可以通过列表、字典或二维数组创建。
(1)通过列表创建DataFrame
利用pandas模块中的DataFrame()函数可以基于列表创建DataFrame。
import pandas as pd
a = pd.DataFrame([[1,2],[3,4],[5,6]])
print(a)运行结果

DataFrame更像Excel中的二维表格,它也有行索引和列索引。
注意:索引序号是从0开始的。
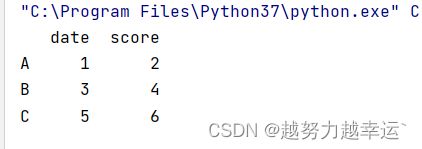
在创建DataFrame时自定义列索引和行索引。
import pandas as pd
a = pd.DataFrame([[1,2],[3,4],[5,6]],columns=['date','score'],index=['A','B','C'])
print(a)第2行代码中的参数columns用于指定列索引名称,参数index用于指定行索引名称。运行结果
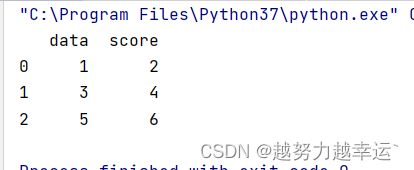
通过列表创建DataFrame方式二
import pandas as pd
a = pd.DataFrame() # 创建一个空DataFrame
date = [1,3,5]
score = [2,4,6]
a['data'] = date
a['score']= score
print(a)运行结果
注意:要保证列表date和score的长度一致,否则会报错。
(2)通过字典创建DataFrame
默认字典的键名作为列索引。
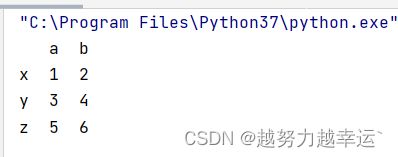
import pandas as pd
b = pd.DataFrame({'a':[1,3,5],'b':[2,4,6]},index=['x','y','z'])
print(b)运行结果
如果想以字典的键名作为行索引,可以用from_dict()函数将字典转换成DataFrame,同时设置参数orient的值为‘index’。
import pandas as pd
c = pd.DataFrame.from_dict({'a':[1,3,5],'b':[2,4,6]},orient='index')
print(c)参数orient指定以字典的键名作为列索引或行索引,默认值为‘columns,即以字典的键名作为列索引,如果设置为“index”,则表示以字典的键名作为行索引。
运行结果

(3)通过二维数组创建DataFrame
import numpy as np
import pandas as pd
a = np.arange(12).reshape(3,4)
b = pd.DataFrame(a,index=[1,2,3],columns=['A','B','C','D'])
print(b)运行结果

5.1.2 DataFrame索引的修改
通过设置index.name属性的值可以修改行索引那一列的名称。
import pandas as pd
a = pd.DataFrame([[1,2],[3,4],[5,6]],columns=['date','score'],index=['A','B','C'])
a.index.name = '公司'
print(a)运行结果

如果想重命名索引,可以使用raname()函数
import pandas as pd
a = pd.DataFrame([[1,2],[3,4],[5,6]],columns=['date','score'],index=['A','B','C'])
a.index.name = '公司'
a = a.rename(index={'A':'万科','B':'阿里','C':'百度'},columns={'date':'日期','score':'分数'})
print(a)运行结果

注意:rename()函数会用新索引名创建一个新的DataFrame,并不会改变a的内容。
也可以通过设置参数inplace为True来一步到位完成索引重命名。
import pandas as pd
a = pd.DataFrame([[1,2],[3,4],[5,6]],columns=['date','score'],index=['A','B','C'])
a.index.name = '公司'
a.rename(index={'A':'万科','B':'阿里','C':'百度'},columns={'date':'日期','score':'分数'},inplace=True)
print(a)如果想将行索引转换为常规列,可以用reset_index()函数重置索引。同样需要将操作结果重新赋值给a,或在reset_index()函数里设置参数inplace为True
a = a.reset_index()运行结果

如果想把常规列转换为行索引,例如,将“日期”列转换为行索引
a = a.set_index('日期') # 或 a.set_index('日期',inplace = True)运行结果

5.2 文件的读取和写入
5.2.1 文件读取
# 读取名为“data.xlsx"的工作簿
import pandas as pd
data = pd.read_excel('data.xlsx')第2行代码中的read_excel()函数设置的文件路径参数是相对路径,即代码文件所在的路径,也可以设置为绝对路径。
read_excel()函数常用参数:
- sheetname用于指定工作表,可以是工作表名称,也可以是数字(默认为0,即第一个工作表)
- encoding用于指定文件的编码方式,一般设置为UTF-8或GBK编码,以避免中文乱码。
- index_col用于设置索引列。
例如,要以UTF-8编码方式读取工作薄”data.xlsx"的第一个工作表,则可将第2行代码修改为
data = pd.read_excel('data.xlsx',sheet_name=0,encoding='utf-8')pandas模块还可以读取CSV文件。
# 读取CSV文件
data = pd.read_csv('data.csv')read_csv()函数的常用参数:
- delimiter 用于指定CSV文件的数据分隔符,默认逗号。
- encoding用于指定文件的编码方式,一般设置为UTF-8或GBK编码,以避免中文乱码。
- index_col用于设置索引列。
例如,要以UTF-8编码方式读取CSV文件’data.csv‘,以逗号作为数据的分隔符
data = pd.read_excel('data.xlsx',delimiter=',',encoding='utf-8')5.2.2 文件写入
import pandas as pd
data = pd.DataFrame([[1,2],[3,4],[5,6]],columns=['A列','B列']) # 创建一个DataFrame
data.to_excel('data.xlsx') # 将DataFrame中的数据写入工作簿第3行代码中的文件存储使用的是相对路径,可以根据需要写成绝对路径。运行之后将在代码所在的文件夹生成一个名为‘data.xlsx'的工作簿,打开工作簿可看到如下图所示的文件内容。
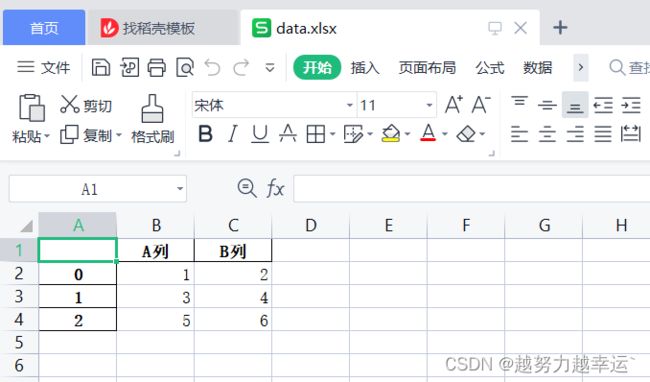
上图中,行索引信息被存储在工作表的第1列中,如果想在写入数据时不保留行索引信息,可以设置to_excel()函数的参数。
该函数常用参数:
- sheetname 用于指定工作表名称
- index用于指定是否写入行索引信息,默认为True,即将行索引信息存储在输出文件的第一列;若设置为False,则忽略行索引信息
- columns 用于指定要写入的列
- encoding用于指定编码方式
例如,要将data中的A列数据写入工作簿并忽略行索引信息
data.to_excel('data.xlsx',columns=['A列'],index=False) # 将DataFrame中的数据写入工作簿将data中是数据写入CSV文件
data.to_csv('data.csv')和to_excet()函数类似,to_csv()函数也可以设置index、columns、encoding等参数
5.3 数据的选取和处理
创建一个3行3列的DataFrame,行索引为r1、r2、r3,列索引为c1、c2、c3
import pandas as pd
data = pd.DataFrame([[1,2,3],[4,5,6],[7,8,9]],index=['r1','r2','r3'],columns=['c1','c2','c3'])
通过二维数组创建DataFrame,以数字1为起点,数字10为终点(终点取不到),生成1-9共9个整数。
data = pd.DataFrame(np.arange(1,10).reshape(3,3),index=['r1','r2','r3'],columns=['c1','c2','c3'])两种方法得到data的结果是一样的。
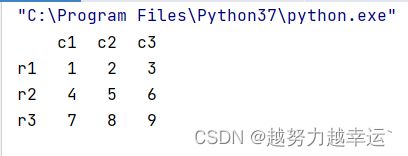
5.3.1 数据的选取
(1)按列选取数据
a = data['c1']运行结果
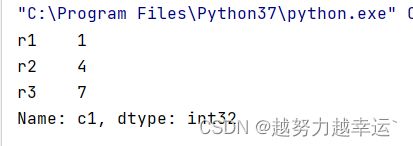
可以看到,选取的数据不包含列索引信息,因为通过data['c1']选取一列返回的是一个一维的Series类型的数据。
返回一个二维的表格数据
a = data[['c1']] 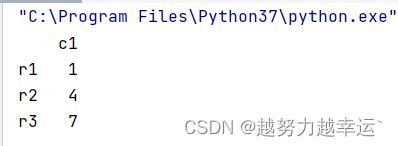
选取多列,则需在中括号[]中以列表的形式给出索引列。
例如,选取c1和c3列
a = data[['c1','c3']]运行结果

(2)按行选取数据
根据行序号来选取数据
# 选取第2-3行是数据,注意序号是从0开始,左闭右开
b = data[1:3]运行结果
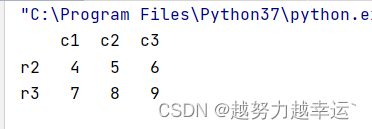
推荐使用iloc方法根据行序号选取数据
c = data.iloc[1:3]如果要选取单行,就必须用iloc方法。
例如,选取倒数第1行
c = data.iloc[-1:]此时如果使用data[-1],则python可能会认为-1是列名,导致混淆错误
使用loc方法根据行的名称来选取数据
d = data.loc[['r2','r3']]如果函数有很多行,可以用head()函数选取前5行数据。
e = data.head()这里因为data只有3行数据,所以用head()函数会选取全部数据。如果只想选取前两行数据,可以写成data.head(2)。
(3)按区块选取数据
# 选取c1和c3列的前两行数据
a = data[['c1','c3']][0:2] # 也可以写成data[0:2][['c1','c3']]其实就是把按行和按列选取数据的方法进行了整合。运行结果
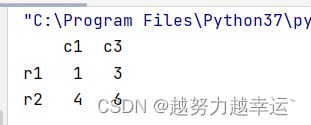
使用iloc方法选取行,在选取列
b = data.iloc[0:2][['c1','c3']]选取c3列第1行的数据
c = data.iloc[0]['c3']使用iloc和loc方法同时选取行和列
d = data.loc[['r1','r2'],['c1','c3']]
e = data.iloc[0:2,[0,2]]注意:loc方法使用字符串作为索引,iloc方法使用数字作为索引。
运行结果
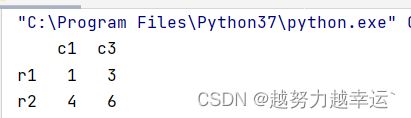
选取区域数据还可以使用ix方法,它的索引不像loc或iloc必须为字符串或数字
f = data.ix[0:2,['c1','c3']]其操作逻辑和效果与data.iloc[0:2][['c1','c3']]一样,但pandas模块的官方文档目前已经不推荐用ix方法了。
5.3.2 数据的筛选
通过在中括号里设定筛选条件可以过滤行。
例如,筛选c1列中数字大于1的行
a = data[data['c1'] > 1]运行结果

当有多个筛选条件,可以用“&”或“|”连接起来。
例如,筛选c1列中数字大于1且c2列中数字等于5的行。
注意:要用小括号将筛选条件括起来
b = data[(data['c1'] > 1) & (data['c2'] == 5)]运行结果

5.3.3 数据的排序
使用sort_values()函数可以按列对数据进行排序。
例如,将data按c2列进行降序排序
a = data.sort_values(by='c2',ascending=False)参数:
- by用于指定按哪一列来排序
- ascending(’上升‘)默认值为True,表示升序排序,若设置False则表示降序排列。
运行结果

使用sort_index()函数可以按行索引进行排序。
例如,按行索引进行升序排序
a = a.sort_index()运行上面代码后,前面按c2列降序排序后生成的a的行索引又变成r1、r2、r3的升序排序形式了。
sort_index()函数同样也可以通过设置参数ascending为False来进行降序排序。
5.3.4 数据的运算
data['c4'] = data['c3']-data['c1']运行结果

5.3.5 数据的删除
使用drop()函数可以删除DataFrame中的指定数据
该函数常用参数介绍:
- index用于指定要删除的行
- columns用于指定要删除的列
- inplace默认值为False,表示该删除操作不改变原DataFrame,而是返回一个执行删除操作后的新DataFrame。如果设置为True,则会直接在原DataFrame中进行操作
# 删除data中的c1列数据
a = data.drop(columns='c1')
# 删除多列数据时,要以列表的形式给出列索引
# 删除c1 和 c3列的代码
c = data.drop(columns=['c1','c3'])
# 删除多行数据时,同样要以列表的形式给出行索引。
# 删除第1行和第3行
c = data.drop(index=['r1','r3'])注意:给出行索引时要输入行索引名称而不是数字序号,除法行索引名称本来就是数字。
上述这些操作并不会改变原DataFrame(data)的结构。
要想改变原dataFrame(data)的结构,可以设置参数inplace为True。
data.drop(index=['r1','r3'],inplace=True)5.4 数据表的拼接
两个数据表的拼接主要涉及merge()函数、concat()函数、append()函数。
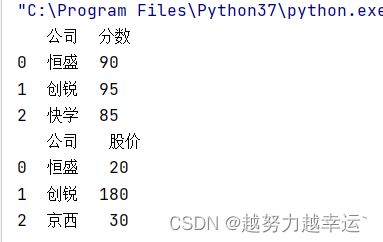
创建两个DataFrame数据表。
import pandas as pd
df1 = pd.DataFrame({'公司':['恒盛','创锐','快学'],'分数':[90,95,85]})
df2 = pd.DataFrame({'公司':['恒盛','创锐','京西'],'股价':[20,180,30]})
运行结果
5.4.1 merge()函数
merge()函数可以根据一个或多个同名的列将不同数据表中的行连接起来。
df3 = pd.merge(df1,df2)运行结果
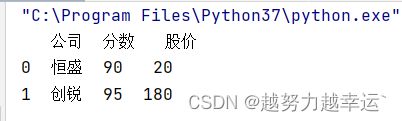
可以看到,merge()函数直接根据相同的列名(“公司”列)对两个数据表进行了合并,而且默认选取的是两个表共有的列内容(‘恒盛’、‘创锐’)。
如果同名的列不止一个,可以通过设置参数on指定按照哪一列进行和并。
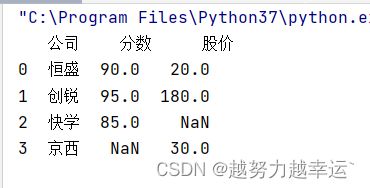
df3 = pd.merge(df1,df2,on='公司')默认是合并方式其实是取交集(inner连接),即选取两个表共有的内容。如果想取并集(outer连接),即选取两个表所有的内容,可以设置参数how
df3 = pd.merge(df1,df2,how='outer')运行结果
如果想保留df1的全部内容,而对 df2不太在意,可以将参数how设置为‘left’
df3 = pd.merge(df1,df2,how='left')运行结果

完整保留了df1的内容(‘恒盛’、‘创锐’、‘快学’)
如果想保留df2的全部内容,不在意df1,可以将参数how设置为‘right’。
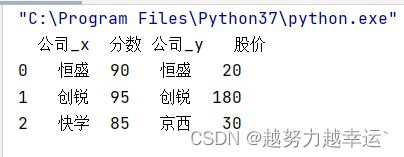
按照行索引进行合并,可以设置参数left_index和right_index
df3 = pd.merge(df1,df2,left_index=True,right_index=True)运行结果
5.4.2 concat()函数
concat()函数使用全连接(UNION ALL)方式完成拼接,它不需要对齐,而是直接进行合并,即不需要两个表有相同的列或索引,只是把数据整合到一起。
使用参数axis指定连接的轴向。该参数默认值为0,指按行方向连接(纵向拼接)。
df3 = pd.concat([df1,df2]) # 或者写成 pd.concat([df1,df2],axis=0)运行结果

此时的行索引为原来两个表的各自索引,如果想要重置索引,可以使用reset_index()函数,或者在concat()函数中设置参数ignore_index为True来忽略原有索引。
df3 = pd.concat([df1,df2],ignore_index=True)如果想按列方向连接,即横向连接,可以设置参数axis=1。
df3 = pd.concat([df1,df2],axis=1)运行结果
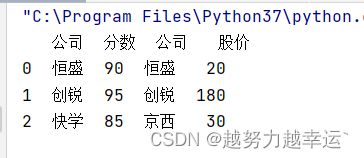
5.4.3 append()函数
append()函数可以看出concat()函数的简化版,效果和pd.concat([df1,df2])类似,实现的也是纵向拼接。
df3 = df1.append(df2)append()函数还有一个和列表的append()函数一样的用途——新增元素
df3 = df1.append({'公司':'腾飞','分数':'90'},ignore_index=True)运行结果:

注意:这里一定要设置参数 ignore_index为True来忽略原索引,否则会报错。
6 数据可视化模块——Matplotlib
Matplotlib是一个非常出色的数据可视化模块,其导入代码通常写成import matplotlib.pyplot as plt,将模块名简写为plt。
6.1 绘制折线图
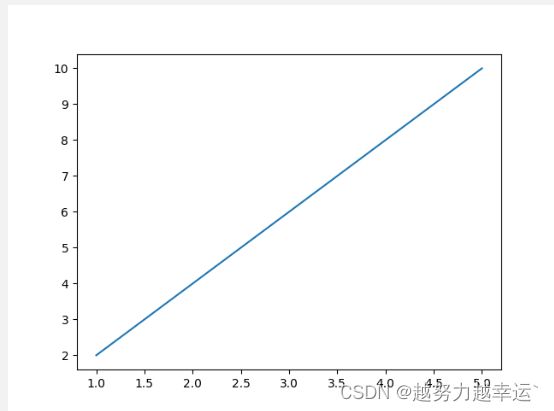
import matplotlib.pyplot as plt
x=[1, 2, 3, 4, 5]
y=[2, 4, 6, 8, 10]
plt.plot(x, y)
plt.show()运行结果
6.2 绘制柱形图
import matplotlib.pyplot as plt
x = [1,2,3,4,5,6]
y = [6,5,4,3,2,1]
plt.bar(x,y)
plt.show()运行结果

7 模块的交互
7.1 xlwings模块与pandas模块的交互
例,用pandas模块创建数据表格,再用xlwings模块将表格写入工作簿
import xlwings as xw
import pandas as pd
app = xw.App(visible=False)
workbook = app.books.add()
worksheet = workbook.sheets.add('新工作表')
df = pd.DataFrame([[1,2],[3,4]],columns=['a','b'])
worksheet.range('A1').value=df
workbook.save(r'D:table.xlsx')
workbook.close()
app.quit()运行之后就会再D盘的根文件下生成一个工作簿”table.xlsx",打开该工作簿,可以看到工作表中有一个2*2的表格。
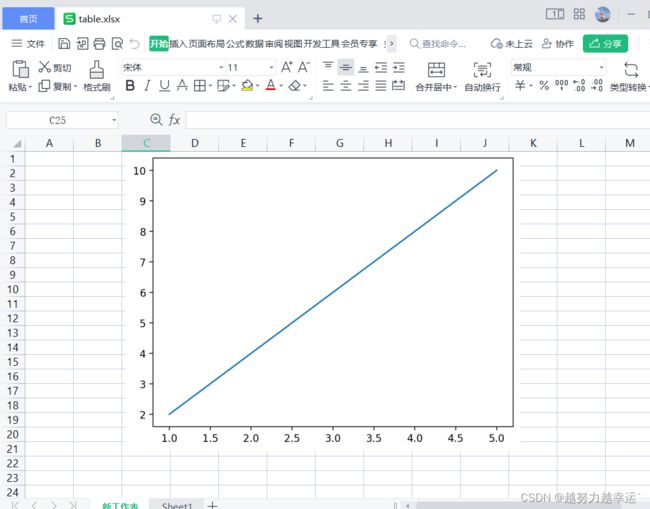
7.2 xlwings模块与Matplotlib模块的交互
import xlwings as xw
import matplotlib.pyplot as plt
figure = plt.figure()
x = [1,2,3,4,5]
y = [2,4,6,8,10]
plt.plot(x,y)
app = xw.App(visible=False)
workbook = app.books.add()
worksheet = workbook.sheets.add('新工作表')
# 将绘制的图表写入工作薄
worksheet.pictures.add(figure,name='图片1',update=True,left=100)
workbook.save(r'd:\table.xlsx')
workbook.close()
app.quit()运行代码,打开创建的工作簿”table.xlsx",可看到如下图所示的图表
worksheet.pictures.add()函数可以将Matplotlib模块绘制的图表写入工作簿。
该函数设置的参数函数:
- figure为固定写法,代表之前用Matplotlib模块绘制的图表
- name用于指定图表的名称,这个名称并不显示再图表上,它是绘制多个图表时使用的,如果要在同一个工作表里绘制第二个图表,则需要把name设置成另一个名称
- update设置为True,则在后续通过pictures.add()函数调用具有相同名称(‘图片1’)的图表时,可以只更新图表数据而不更改其位置或大小
- left用于设置图表与左侧边界的距离,这里设置left为100,表示让图表距离左侧边界100像素,同理可以设置参数top为400,表示让图表距离顶部边界400像素