优化3500倍,从70s到20ms的顶级调优,此方案人人可用
前言:
在40岁老架构师尼恩的读者社区(50+)中,很多小伙伴拿不到offer,或者拿不到好的offer。
尼恩经常给大家 优化项目,优化简历,挖掘技术亮点。在指导简历的过程中, Java 调优是一项很重要的指导。
问题是,很多小伙伴,连一点调优的基础都没有, 当然,连高并发的场景也搞不清楚。
实际上,无论是调优,还是高并发的场景,我们都需要解决一些基础问题,比如说:
一亿用户量,平均每人每天10次的业务量,要求并发数在5000以上,峰值在5w到10w之间,QPS在25w以上, 如何进行压测?如何进行调优?
对于架构师、高级开发来说, 调优是 核心内容, 那么压测更是内功中的内功。
尼恩团队从 高并发压测实操开始,给大家梳理一个系列的《Java 调优圣经》PDF 电子书,包括本文在内规划的五个部分:
(1) 调优圣经1:零基础精通Jmeter分布式压测,10Wqps+压测实操
(2) 调优圣经2:从70s到20ms,一次3500倍性能优化实战,方案人人可用
(3) 调优圣经3:零基础精通JVM调优实操,实现JVM自由 (写作中)
(4) 调优圣经4:零基础精通Mysql调优实操,实现Mysql调优自由 (写作中)
(5) 调优圣经5:零基础精通Linux、Tomcatl调优实操,实现基础设施调优自由 (写作中)
以上的多篇文章,后续将陆续在 技术自由圈 公众号发布。 完整的《Java 调优圣经》PDF,可以找尼恩获取。
文章目录
-
- 前言:
- 用户中台的性能问题
- 用户中台性能优化的常规思路
- 第一轮优化:数据库层面优化,提升60倍
- 第二步:应用层优化,提升70倍
- 第三步:分布式缓存优化,但是高并发场景失败率过高
-
- 使用分布式 jmeter集群的方式来进行压测
- 第四步:BigKey问题优化,4000并发场景到100ms
- 第五步:本地缓存优化,优化到20ms
-
- 优化总结
- 第六步:网关层面的优化
- 从70s到20ms调优小结
- 《Java 调优圣经》迭代计划
- 技术自由的实现路径 PDF:
-
-
- 实现你的 架构自由:
-
用户中台的性能问题
在一个大型科技公司用户中台中,组织机构扮演着至关重要的角色,涉及到多个部门、团队和员工的关系和层级。
然而,随着公司规模的不断扩大和组织结构的复杂性增加,组织机构树的数据量也日益庞大。
这给内部用户在内部系统平台查询组织机构树时带来了一系列挑战和问题。
其中最突出的问题之一是查询的效率问题。
传统的查询方式无法有效应对组织机构树庞大数据量的挑战,导致页面在查询时出现卡顿、响应时间过长甚至超时的情况。
有关问题详细的数据
单次点击 rt时间 > 70s
100并发 压测,平均RT时间 > 160
在某个大型科技公司用户中台中,组织机构接口的RT时间为70s。
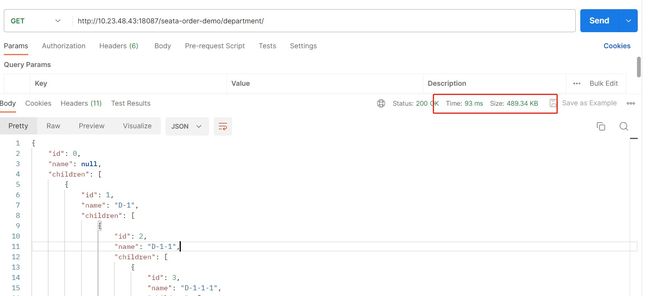
通过postman工具调用接口获取组织树,可以看到这个时间:
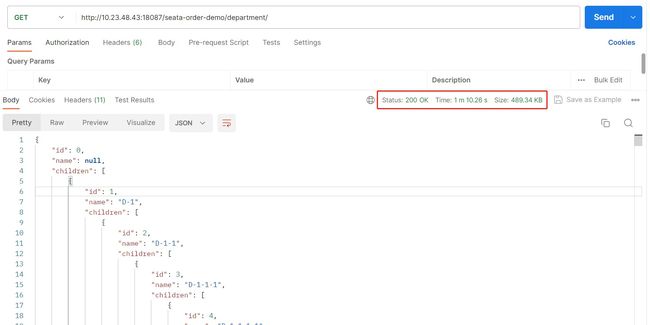
我们可以看到,这一次组织树查询接口耗时大概在70s左右。 这个是太长了,性能太差了。
一般系统RT要求在500ms内,并且越短越好。
接下来,我们利用jmeter对该接口进行压测,
JMeter(Apache JMeter)是一个开源的、纯Java编写的性能测试工具。它主要用于对软件和服务进行压力测试、负载测试、功能测试以及性能测试等。JMeter提供了一个图形化界面,使用户能够轻松创建测试计划并配置各种测试场景。
以下是JMeter的一些主要特点和功能:
- 多协议支持:JMeter支持多种协议,包括HTTP、HTTPS、FTP、JDBC、SOAP、REST等,使其适用于测试各种类型的应用程序。
- 分布式测试:JMeter支持分布式测试,可以通过多个JMeter实例协同工作,模拟大量用户同时访问目标系统,以评估系统的性能和承载能力。
- 灵活的测试计划:使用JMeter,您可以创建灵活的测试计划,定义并发用户数、请求的顺序、延迟时间、断言、监听器等。您可以根据需要对测试计划进行自定义配置。
- 监控和分析:JMeter提供了多种监听器,可以实时监控和分析测试结果。您可以查看响应时间、吞吐量、错误率等指标,帮助您评估系统的性能和稳定性。
- 脚本录制和回放:JMeter支持通过代理服务器录制用户的操作,并生成对应的测试脚本。这使得创建测试脚本变得更加简单和快速。
- 可扩展性:JMeter具有丰富的插件和扩展机制,可以通过插件来增加新的功能和协议支持,满足更多特定的测试需求。
在《 调优圣经:零基础精通Jmeter分布式压测,10Wqps+超高并发 》这篇文章中,对jmeter进行了详细介绍,
由于接口查询耗时太长,当前仅采用单机jmeter 进行压测,模拟100QPS的执行情况,
启动压测,等压测执行完后,查看聚合报告:
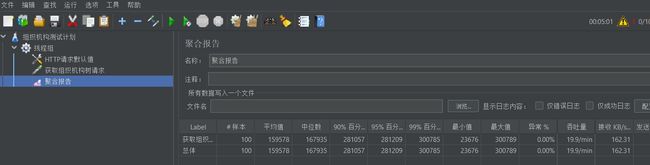
从报告中我们可以看到,100次查询请求,平均耗时接近160秒。
性能问题所带来的严重影响:
这严重影响了用户的工作效率和体验。 是严重的生产问题。
面对这一问题,我们需要寻找优化的解决方案,以提升组织机构树查询的性能和响应速度。
这涉及到在数据库层面、缓存层面以及网关层面进行针对性的优化措施。
通过优化数据库表结构、使用缓存技术、合理配置网关等手段,我们可以显著改善组织机构树查询的效率和用户体验。
接下来, 尼恩团队带大家开始,一步一步的进行优化。
用户中台性能优化的常规思路
首先,梳理一下用户中台性能优化的常规思路。
常见的优化思路如下:
- 统一数据源:建立一个中心化的组织机构数据源,将所有部门和团队的组织机构数据集中存储,确保数据的一致性和准确性。
- 数据库优化:设计合适的数据库表结构和索引,以支持高效的组织机构查询操作。使用合适的数据库技术和优化方法,如垂直拆分或水平拆分等,来提高查询性能。
- 缓存机制:使用缓存来存储组织机构数据,如Redis等。通过合理的缓存策略,如设置适当的过期时间、使用LRU算法等,减少对数据库的频繁查询,提高查询效率。
- 分布式架构:采用分布式架构,将查询负载分散到多个节点上,通过水平扩展来提高查询性能和并发处理能力。
- 异步处理:对于复杂的组织机构查询,可以将其放入异步任务队列中处理,减少前端请求的等待时间,提高系统的并发处理能力。
- 数据同步机制:确保组织机构数据的同步和更新的及时性,使用合适的数据同步技术和机制,如定时任务、事件驱动等,保证数据的一致性。
- 前端优化:采用前端技术和界面设计优化,如数据分页加载、懒加载等方式,减少一次性加载大量组织机构数据所带来的性能压力。
本文将深入探讨针对大型科技公司中组织机构树数据量过大所引发的问题,并提供一系列优化方案。通过这些优化措施,我们将帮助您克服组织机构树查询中的困难,使您能够更快速、高效地获取所需的组织机构信息,提升工作效率和决策能力。
接下来,本文将带着大家一起实践组织架构树的优化!
第一轮优化:数据库层面优化,提升60倍
数据库优化是解决大型科技公司组织机构查询问题的重要一环。下面是一些详细的数据库优化策略和技术:
- 合适的表结构设计:
- 根据组织机构的特点,设计合适的表结构,以支持高效的查询操作。可以采用适当的关系型数据库或者NoSQL数据库,根据具体需求选择合适的数据库引擎。
- 使用范式化或者反范式化的设计方式,根据查询需求和数据一致性的要求来决定表结构的规范化程度。
- 使用合适的数据类型来存储组织机构数据,以节省存储空间并提高查询效率。
- 索引优化:
- 通过创建合适的索引来加速组织机构查询。根据查询的字段和条件,为经常被用于查询的列创建索引,以提高查询的速度。
- 选择适当的索引类型,如B-tree索引、哈希索引或者全文索引,根据具体查询的需求和数据的特点做出选择。
- 定期进行索引维护和优化,包括索引重建、碎片整理等操作,以保持索引的性能。
- 查询优化:
- 编写高效的查询语句,使用合适的SQL语法和操作符,避免不必要的查询或子查询,提高查询的效率。
- 使用合适的查询缓存机制,如数据库自带的查询缓存或者第三方缓存工具,以减少对数据库的频繁查询。
- 避免过度使用JOIN操作,尽量减少关联查询的复杂性。考虑使用预加载或延迟加载的方式,根据实际需求来优化查询操作。
- 分析查询执行计划,通过索引优化、表结构调整或者SQL重写等手段,改善查询执行计划的性能。
- 数据分区和分片:
- 如果组织机构数据量非常大,可以考虑将数据分区或者分片存储。通过按照一定规则将数据拆分为多个分区或者分片,提高查询的并行度和扩展性。
- 使用分区表或者分片表的方式,将数据均匀地分布到多个物理存储设备或者数据库实例中,提高查询的性能和响应时间。
- 定期数据清理和维护:
- 定期清理不再使用的数据,如过期的组织机构信息或者历史数据。通过删除或者归档这些数据,可以减少数据库的存储压力和提高查询性能。
- 定期进行数据库的维护工作,包括备份、日志清理、统计信息更新等操作,以保持数据库的健康状态和性能。
一般组织机构对应的表结构如下所示:
CREATE TABLE `department` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(100) COLLATE utf8mb4_unicode_ci NOT NULL,
`parent_id` int(11) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`remark` varchar(100) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`created_at` datetime DEFAULT NULL,
`deleted` tinyint(1) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
KEY `department_parent_id_IDX` (`parent_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='部门';
在这个表结构中,每个目录节点都有一个唯一的id标识和一个name字段表示部门的名称。
parent_id字段表示该节点的父节点的id。根节点可以通过parent_id为0来表示。
注意添加parent_id为索引,加快查询效率。
通过这种表结构,可以使用递归查询或者多级查询来构建整个树的结构。
例如,通过以下查询可以获取第一层目录树:
SELECT * FROM department WHERE parent_id = '0L';
然后,通过递归或者多级查询,可以根据每个节点的id值,获取其子节点。
我们预先生产了一万多条的测试数据,组织结构层级最大4级,
获取组织机构树的示例代码如下:
public DepartmentDTO findAll() {
DepartmentDTO departmentDTO = new DepartmentDTO();
departmentDTO.setId(0L);
queryChildren(departmentDTO);
return departmentDTO;
}
// 递归查询
private void queryChildren(DepartmentDTO parent) {
List<DepartmentPO> children = departmentDao.queryByParentId(parent.getId());
if (CollectionUtils.isEmpty(children)) {
return;
}
for (DepartmentPO po : children) {
DepartmentDTO departmentDTO = new DepartmentDTO();
BeanUtil.copyProperties(po, departmentDTO);
parent.getChildren().add(departmentDTO);
queryChildren(departmentDTO);
}
}
回到优化之前,接下来调用接口获取组织树:
优化之后,进行单次接口的 调用接口,数据如下:
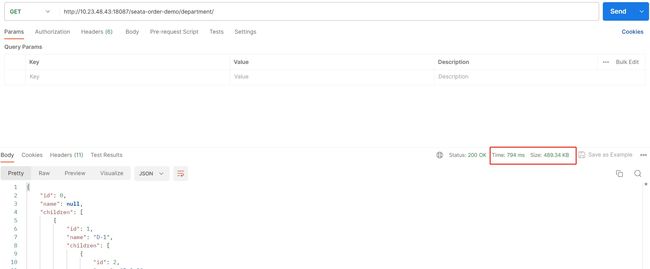
可以发现,通过降低SQL调用次数,接口耗时从70多s降低到了800ms左右。
接下来,我们同样对接口进行下压测,
压测后,聚合报告如下所示:
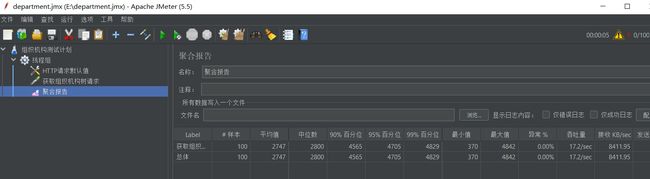
聚合报告显示,100次查询请求平均耗时仅2秒多,且吞吐量提升近60倍。
当然我们还需要进一步优化,以减少接口耗时和提升吞吐量。
第二步:应用层优化,提升70倍
在第一步优化过程中,我们采用级联查询,从根节点查询下级子节点列表,再从下级子节点查询下下级节点,每次查询都要提交SQL到MySQL,相当于一次接口调用,后端需要发起上万次SQL请求,效率非常低下。
因此我们可以在应用服务里,每次查询一次性从数据库中获取所有数据,在内存里排序、拼装成树形数据,
代码示例如下:
private void queryChildren2(DepartmentDTO root) {
// 一次性取出所有数据
List<DepartmentPO> list = departmentDao.findAll(Sort.by("parentId", "id").ascending());
Map<Long, DepartmentDTO> departmentMap = new HashMap<>();
departmentMap.put(root.getId(), root);
// 遍历数据,组成树形结构
for(DepartmentPO po : list) {
DepartmentDTO departmentDTO = new DepartmentDTO();
BeanUtil.copyProperties(po, departmentDTO);
departmentMap.put(po.getId(), departmentDTO);
DepartmentDTO parent = departmentMap.get(po.getParentId());
parent.getChildren().add(departmentDTO);
}
}
调用接口, 结果如下:
可以看到,应用层优化后,接口的耗时从700多ms降低到100ms左右,基本已满足生产环境要求的接口耗时,接下来,我们还需要对接口进行压测,
第三步:分布式缓存优化,但是高并发场景失败率过高
传统的数据库查询往往需要耗费大量的时间和资源,特别是在数据量庞大的情况下。
通过引入分布式缓存,我们可以将组织机构数据缓存在内存中,以避免频繁访问数据库的开销。
分布式缓存采用分布式架构,将数据存储在多个缓存节点中,每个节点都具备独立的内存和处理能力。
当进行组织机构查询时,首先检查缓存中是否存在相应的数据。
如果缓存中存在数据,则直接返回结果,避免了对数据库的查询操作。这样可以大大减少查询的响应时间,提高整体系统的性能。
在引入分布式缓存时,需要设计合理的缓存策略和数据更新机制。
可以采用缓存失效策略,设置合适的缓存过期时间,确保缓存中的数据与数据库的数据保持一致。当组织机构数据发生变化时,及时更新缓存,保证查询结果的准确性。
此外,还可以考虑使用分布式缓存技术如Redis或Memcached,并进行合理的缓存数据划分和数据分片,以实现横向扩展和负载均衡。这样可以提高系统的可伸缩性和容错性,应对高并发访问和大规模组织机构数据的查询需求。
总之,引入分布式缓存是一种高效的优化策略,通过减少对数据库的访问次数和加速查询响应,可以极大地提升组织机构查询的效率和响应时间,从而提高整体系统的性能和用户体验。
首先,我们尝试在接口调用时,使用redis缓存组织结构树,之后每次接口请求时,都优先查询缓存,
代码示例如下:
public DepartmentDTO findAll() {
// 查询缓存
DepartmentDTO departmentDTO = (DepartmentDTO) redisTemplate.opsForValue().get(DEPARTMENT_CACHE_KEY);
// 缓存不存在则查询数据库
if (Objects.isNull(departmentDTO)) {
departmentDTO = new DepartmentDTO();
departmentDTO.setId(0L);
queryChildren2(departmentDTO);
}
// 更新缓存
redisTemplate.opsForValue().set(DEPARTMENT_CACHE_KEY, departmentDTO, 1, TimeUnit.MINUTES);
return departmentDTO;
}
使用分布式 jmeter集群的方式来进行压测
为了模拟高并发场景,使用分布式 jmeter集群的方式来进行压测。
由于单台jmeter压测受限于本地机器的CPU,内存,网络及其他原因,需要采用jmeter集群的方式来进行压测。
这里我们将参考《 调优圣经:零基础精通Jmeter分布式压测,10Wqps+超高并发 》这篇文章,利用Jmeter集群来进行压测,
Jemter集群采用docker-compose的方式搭建,
在本机新建jmeter文件夹,在文件夹下创建jmeter-master文件夹,
docker-compose.yml内容如下:
version: "3.9"
services:
jmeter-master:
image: zhangyx1619/jmeter-master:orcaljdk17-jmeter5.5-graphs-plugins-release
volumes:
- "./jmeter-master:/usr/local/jmeter/apache-jmeter-5.5/work_space/"
networks:
- swarmnet
hostname: jmeter-master
deploy:
labels:
- com.service.name=jmeter-master
mode: global
update_config:
parallelism: 1
delay: 1s
failure_action: rollback
jmeter-slave01:
image: zhangyx1619/jmeter-slave:orcaljdk17-jmeter5.5-graphs-plugins-release
volumes:
- jmeter-slave01:/usr/local/jmeter/apache-jmeter-5.5/
networks:
- swarmnet
hostname: jmeter-slave01
deploy:
mode: global
labels:
- com.service.name=jmeter-slave01
update_config:
parallelism: 1
delay: 1s
failure_action: rollback
jmeter-slave02:
image: zhangyx1619/jmeter-slave:orcaljdk17-jmeter5.5-graphs-plugins-release
volumes:
- jmeter-slave02:/usr/local/jmeter/apache-jmeter-5.5/
networks:
- swarmnet
hostname: jmeter-slave02
deploy:
mode: global
labels:
- com.service.name=jmeter-slave02
update_config:
parallelism: 1
delay: 1s
failure_action: rollback
jmeter-slave03:
image: zhangyx1619/jmeter-slave:orcaljdk17-jmeter5.5-graphs-plugins-release
volumes:
- jmeter-slave03:/usr/local/jmeter/apache-jmeter-5.5/
networks:
- swarmnet
hostname: jmeter-slave03
deploy:
mode: global
labels:
- com.service.name=jmeter-slave03
update_config:
parallelism: 1
delay: 1s
failure_action: rollback
networks:
swarmnet:
driver: bridge
volumes:
jmeter-slave01:
jmeter-slave02:
jmeter-slave03:
在当前jemeter目录打开终端,运行docker命令, 启动容器。
docker compose up -d
启动后,容器详情如下:
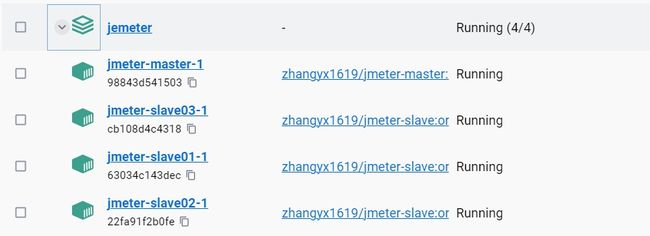
其中包含一个主节点和4个子节点。
接下来,修改jmx脚本, 线程组的线程数我们调大到1000, 这样的话,4个子节点分别发起1000次请求,相当于是模拟4000 QPS 压测,
点击左上角文件 -> 保存 , 将当前jmeter脚本department.jmx 文件,保存到jmeter-master文件夹下,
ok,到这里一切准备就绪后,就可以开始执行压测命令,
在终端运行如下命令:
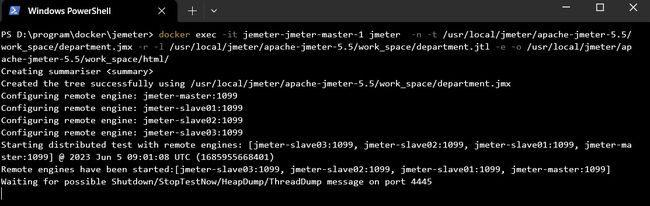
docker exec -it jemeter-jmeter-master-1 jmeter -n -t /usr/local/jmeter/apache-jmeter-5.5/work_space/department.jmx -r -l /usr/local/jmeter/apache-jmeter-5.5/work_space/department.jtl -e -o /usr/local/jmeter/apache-jmeter-5.5/work_space/html/
这是一个使用Docker执行JMeter性能测试的命令,具体含义如下:
docker exec: 运行一个命令在Docker容器中执行操作。-it: 分配一个交互式终端,并将其连接到容器的输入和输出,以便与JMeter进行交互。jemeter-jmeter-master-1: Docker容器的名称或ID,指定要执行命令的目标容器,这里是主节点容器名称。jmeter: 要执行的命令,这里是执行JMeter性能测试。-n: 在非GUI模式下运行JMeter。-t /usr/local/jmeter/apache-jmeter-5.5/work_space/department.jmx: 指定要运行的JMX测试计划文件的路径和文件名。-r: 运行以分布式方式执行测试。-l /usr/local/jmeter/apache-jmeter-5.5/work_space/department.jtl: 指定测试结果的日志文件路径和文件名。-e: 生成HTML格式的测试报告。-o /usr/local/jmeter/apache-jmeter-5.5/work_space/html/: 指定生成的HTML测试报告的输出目录路径。
通过这个命令,您可以在指定的Docker容器中执行JMeter性能测试,并生成相应的测试结果日志和HTML报告。请注意,命令中的文件路径和名称需要根据实际情况进行修改。
执行过程如下图所示:
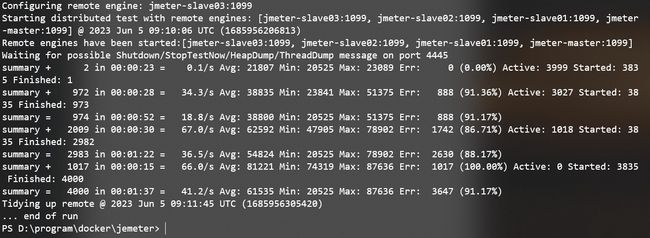
查看生成的报告

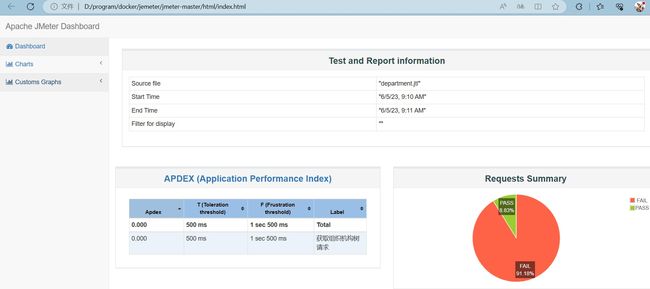
我们可以看到,4台jmeter节点模拟1000个并发,一共是4000并发,Fail的占比90%多,
服务器会出现大量的异常,
org.springframework.dao.QueryTimeoutException: Redis command timed out; nested exception is io.lettuce.core.RedisCommandTimeoutException: io.lettuce.core.RedisCommandTimeoutException: Command timed out after 3 second(s)
at org.springframework.data.redis.connection.lettuce.LettuceExceptionConverter.convert(LettuceExceptionConverter.java:70)
at org.springframework.data.redis.connection.lettuce.LettuceExceptionConverter.convert(LettuceExceptionConverter.java:41)
at org.springframework.data.redis.PassThroughExceptionTranslationStrategy.translate(PassThroughExceptionTranslationStrategy.java:44)
at org.springframework.data.redis.FallbackExceptionTranslationStrategy.translate(FallbackExceptionTranslationStrategy.java:42)
at org.springframework.data.redis.connection.lettuce.LettuceConnection.convertLettuceAccessException(LettuceConnection.java:273)
at org.springframework.data.redis.connection.lettuce.LettuceStringCommands.convertLettuceAccessException(LettuceStringCommands.java:799)
at org.springframework.data.redis.connection.lettuce.LettuceStringCommands.get(LettuceStringCommands.java:68)
at org.springframework.data.redis.connection.DefaultedRedisConnection.get(DefaultedRedisConnection.java:266)
at org.springframework.data.redis.core.DefaultValueOperations$1.inRedis(DefaultValueOperations.java:57)
at org.springframework.data.redis.core.AbstractOperations$ValueDeserializingRedisCallback.doInRedis(AbstractOperations.java:60)
at org.springframework.data.redis.core.RedisTemplate.execute(RedisTemplate.java:228)
根因分析:
异常的原因是redis读取超时,因为一个键值对的数据量比较大,导致redis出现了BigKey问题,我们需要进一步优化
狼来了: BigKey问题来了
第四步:BigKey问题优化,4000并发场景到100ms
在Redis中,BigKey指的是占用大量内存空间的键值对。当一个键值对的数据量过大,超过Redis的配置限制或者内存容量时,就称之为BigKey。
BigKey会导致以下问题:
- 内存占用过高:BigKey占用大量内存空间,可能导致Redis服务器的内存资源紧张,影响其他操作和缓存数据的存储。
- 延迟和性能下降:由于读写大型BigKey的数据需要较长的时间,会导致读写操作的延迟增加,并且消耗更多的CPU资源和网络带宽,影响系统的整体性能。
- Redis持久化和备份问题:BigKey在进行持久化(如RDB快照或AOF日志)或备份时,会增加持久化和备份的时间和资源消耗。
解决BigKey问题的一些优化方法包括:
- 数据拆分:将大型BigKey拆分成多个较小的键值对,根据数据的逻辑关联性和查询模式进行合理的拆分和分组。这样可以降低单个键值对的大小,减少内存占用。
- 分片存储:将数据分散存储在多个键中,使用合适的哈希函数或者分片算法,将数据均匀地分散到不同的键中,避免单个键值对过大。这样可以平衡数据的存储和访问压力。
- 数据压缩:对于可以压缩的数据类型(如字符串或JSON格式的数据),可以使用压缩算法(如LZF、Snappy、Gzip等)进行压缩,减少BigKey的内存占用。
- 数据分页和增量加载:对于查询结果过大的BigKey,可以采用数据分页或者增量加载的方式,只加载部分数据或者按需加载,以降低单次查询的数据量和内存消耗。
- 避免无意义的数据存储:避免将无需持久化或频繁变更的数据存储为BigKey,可以使用临时缓存或者其他数据存储方案。
通过合理的数据拆分、分片存储和压缩等优化方法,可以有效地解决BigKey问题,提高Redis的性能和资源利用率。
因为在根节点下的第一级优10个组织,这10个组织分别有不同的子孙节点,我们可以尝试将单个key先拆分成10个key,每个key分别对应这10个组织及子节点数据。
示例代码如下:
public DepartmentDTO findAll() {
DepartmentDTO root = new DepartmentDTO();
root.setId(0L);
// 从10个key里获取缓存数据,放入到根节点的children集合里
for (int i = 0; i< 10; i++) {
DepartmentDTO child = (DepartmentDTO) redisTemplate.opsForValue().get(DEPARTMENT_CACHE_KEY + i);
// 没有缓存数据
if (Objects.isNull(child)) {
root.setChildren(new ArrayList<>());
break;
}
root.getChildren().add(child);
}
if (root.getChildren().size() == 0) {
// 查询数据库
queryChildren2(root);
}
// 将数据按照1级部门存储到10个key
List<DepartmentDTO> children = root.getChildren();
for (int i = 0 ; i < 10; i++) {
redisTemplate.opsForValue().set(DEPARTMENT_CACHE_KEY + i, children.get(i), 1, TimeUnit.HOURS);
}
return root;
}
接下来,继续进行分布式压测:
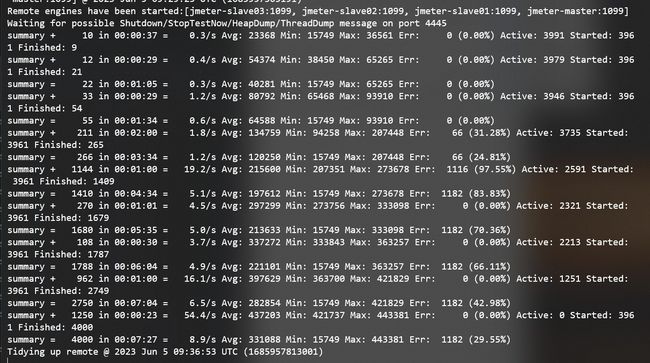
我们再来看下生成的报告:
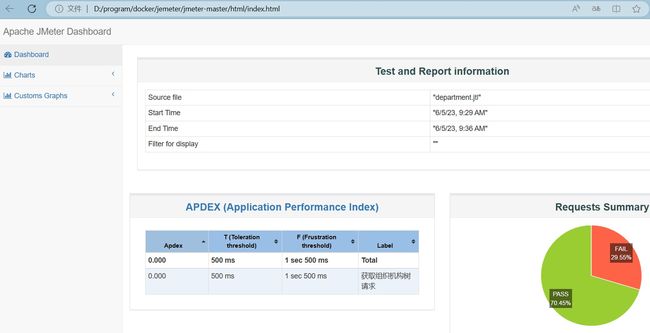
这时我们可以看到通过率从8%提升到70%多,如果我们将key的数量提升到100, 通过率将进一步提升。
有兴趣的同学可以来尝试继续优化直到通过率为100%。
第五步:本地缓存优化,优化到20ms
在分布式缓存的基础上,引入本地缓存是进一步提升组织机构查询效率和响应时间的一种优化方案。
本地缓存是指将数据缓存在应用程序的内存中,以避免频繁地访问分布式缓存或数据库,从而快速响应查询请求。
引入本地缓存的好处是可以减少对分布式缓存的访问次数,从而降低网络延迟和通信开销。
当应用程序发起组织机构查询时,首先检查本地缓存中是否存在相应的数据。如果数据在本地缓存中命中,则无需进一步访问分布式缓存或数据库,可以直接返回结果,极大地提升了查询的效率和响应时间。
本地缓存的使用需要考虑以下几个关键因素:
- 缓存策略:选择合适的缓存策略,如LRU(最近最少使用)、LFU(最近最不常用)等,以平衡内存使用和数据命中率。
- 缓存更新机制:在组织机构数据发生变化时,及时更新本地缓存。可以通过订阅数据库或分布式缓存的数据变更事件,保持本地缓存与数据源的一致性。
- 缓存失效处理:设置合理的缓存失效时间,以确保缓存中的数据不过期。可以根据数据更新的频率和重要性进行调整。
- 内存管理:合理管理本地缓存使用的内存,避免因缓存过多导致内存溢出或应用程序性能下降的问题。
引入本地缓存的优化方案需要综合考虑应用程序的特点、数据的更新频率和一致性要求。合理使用本地缓存可以减少对分布式缓存和数据库的访问,提升组织机构查询的效率和响应时间,从而提高系统的整体性能和用户体验。
在当前SpringBoot框架下,可以通过以下步骤集成Caffeine作为本地缓存:
- 添加Caffeine依赖:在
pom.xml文件中添加Caffeine的依赖项。
<dependency>
<groupId>com.github.ben-manes.caffeinegroupId>
<artifactId>caffeineartifactId>
dependency>
- 创建缓存配置类:创建一个Java类,用于配置Caffeine缓存。
import org.springframework.cache.CacheManager;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.cache.caffeine.CaffeineCacheManager;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import com.github.benmanes.caffeine.cache.Caffeine;
import java.util.concurrent.TimeUnit;
@Configuration
@EnableCaching
public class CacheConfig {
@Bean
public Caffeine<Object, Object> caffeineConfig() {
return Caffeine.newBuilder()
.expireAfterWrite(10, TimeUnit.MINUTES) // 设置缓存失效时间为10分钟
.maximumSize(10_000) // 设置缓存的最大容量为10_000
.recordStats(); // 启用统计信息,可通过Cache.stats()获取缓存命中率等统计数据
}
@Bean
public CacheManager cacheManager(Caffeine<Object, Object> caffeine) {
CaffeineCacheManager cacheManager = new CaffeineCacheManager();
cacheManager.setCaffeine(caffeine);
return cacheManager;
}
}
在上面的示例中,我们配置了一个名为"cacheManager"的缓存管理器,使用了Caffeine作为底层的缓存实现,并设置了缓存的失效时间和最大容量。
- 使用缓存:在需要缓存的方法上添加
@Cacheable注解,以告诉Spring应该缓存该方法的返回值。
@Cacheable("department-cache")
public DepartmentDTO findAll() {
// 省略其它代码
}
在上述示例中,findAll方法会首先检查名为"department-cache"的缓存中是否存在对应的数据。如果存在,直接从缓存中返回数据;如果缓存中不存在,则执行方法体的逻辑,并将返回值缓存起来供下次使用。
同样我们调用下接口,看下执行时间
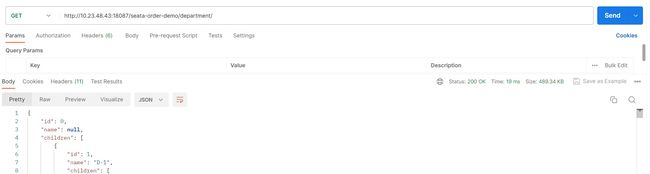
由于采用本地缓存,耗时几乎忽略不计。
接下来,继续执行下jmeter集群压测,压测报告如下所示:
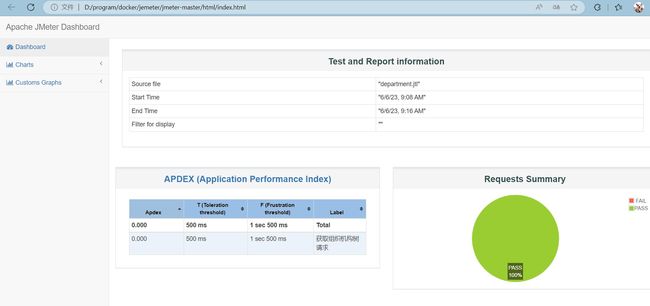
优化总结
如果本地缓存命中, 经过这一轮优化, 性能提升到 20ms,提升700倍
如果本地缓存位命中, 经过上一轮优化, 性能提升到 100ms ,提升3500倍
第六步:网关层面的优化
除了数据库、缓存、bigkey打散、本地缓存优化之外,还有很多其他的优化:
- 网关层面的优化
- 系统层面的优化等等。
接下来说一下网关层面的优化。
在网关层面进行优化可以提高组织机构树接口查询的性能和可扩展性。
以下是一些优化方案:
1、Nginx压缩:
- 在Nginx配置中启用压缩功能,将响应数据进行压缩,减少数据传输的大小,提高网络传输效率和响应速度。
- 配置
gzip指令开启压缩,可以设置合适的压缩级别和压缩类型。
http {
gzip on;
gzip_types text/plain text/css application/json;
gzip_comp_level 5;
}
2、网关缓存:
在Nginx中,可以通过配置代理缓存来缓存接口的响应结果。以下是详细的步骤:
- 启用代理缓存:
在Nginx的配置文件中,开启代理缓存功能并定义一个缓存区域。
http {
proxy_cache_path /path/to/cache levels=1:2 keys_zone=my_cache:10m max_size=10g inactive=60m use_temp_path=off;
}
/path/to/cache:指定缓存存储路径。levels=1:2:定义缓存路径层级。keys_zone=my_cache:10m:为缓存区域指定一个名称(my_cache)和分配的内存大小(10MB)。max_size=10g:设置缓存区域的最大容量为10GB。inactive=60m:指定缓存项在60分钟内没有被访问时被认为是过期的。use_temp_path=off:禁止使用临时路径。
- 配置代理缓存:
在Nginx的配置文件中,为需要缓存的接口添加缓存配置。
server {
location /api/department {
proxy_cache my_cache;
proxy_cache_valid 200 1d;
proxy_pass http://backend_server;
}
}
proxy_cache my_cache:指定使用前面定义的缓存区域(my_cache)进行缓存。proxy_cache_valid 200 1d:设置缓存有效期为1天,对于状态码为200的响应进行缓存。proxy_pass http://backend_server:指定反向代理的目标后端服务器。
- 清除缓存:
如果需要手动清除缓存,可以使用Nginx的proxy_cache_purge模块,通过发送特定请求来清除缓存。
location /purge-cache {
proxy_cache_purge my_cache "$scheme$request_method$host$request_uri";
}
proxy_cache_purge:启用proxy_cache_purge模块。my_cache:指定要清除的缓存区域。"$scheme$request_method$host$request_uri":指定要清除的缓存键值。
通过上述配置,Nginx会在接收到请求时先查看缓存,如果缓存中存在对应的响应,则直接返回缓存的结果,减少对后端服务的请求。如果缓存中不存在或已过期,则会转发请求到后端服务,并将响应结果缓存起来,以供后续相同请求使用。
请注意,缓存接口需要根据具体的业务需求和接口特性进行配置。需要根据接口的频率、数据更新频率和缓存策略进行合理的调整。
对于动态生成的树形数据页面,也可以采用页面缓存技术,将页面内容缓存到CDN或其他缓存中,并设置合适的缓存过期时间。
从70s到20ms调优小结
针对组织结构树的优化设计,我们可以在数据库层面、缓存层面和NGINX网关层面进行优化,以提高查询性能和系统的可伸缩性。
在数据库层面,我们可以采取以下优化设计:
- 使用适当的表结构和索引,优化组织结构树的存储和查询效率。
- 考虑采用合适的分库分表策略,将数据水平拆分,减少单表数据量。
- 针对组织结构树的查询,使用适当的查询语句和优化技巧,如递归查询、嵌套集模型等。
在缓存层面,我们可以采取以下优化设计:
- 使用Redis等缓存技术,将组织结构树的数据缓存在内存中,减少对数据库的访问次数。
- 针对频繁访问的组织结构树数据,设置合适的缓存过期时间和缓存策略。
- 使用合理的缓存命名规则和缓存键设计,确保缓存的准确性和一致性。
在NGINX网关层面,我们可以采取以下优化设计:
- 使用Nginx的压缩功能,减小响应数据的大小,提高网络传输效率。
- 使用CDN缓存静态资源,减轻网关和后端服务器的负载,加速资源传输。
- 配置代理缓存,将组织结构树接口的响应结果缓存起来,减少对后端服务的请求。
- 设置适当的负载均衡机制,分发请求到多个后端服务实例,提高系统的可扩展性和容错性。
综合上述优化设计,可以大大提升组织结构树接口的查询性能和系统的可伸缩性。通过数据库的优化,可以提高数据的存储和查询效率;通过缓存的优化,可以减少对数据库的访问次数;通过网关层面的优化,可以降低网络传输成本和后端服务的负载压力。这些综合的优化措施将显著改善系统的整体性能和用户体验。
《Java 调优圣经》迭代计划
尼恩团队的所有文章和PDF电子书,都是 持续迭代的模式, 最新版本永远是最全的。
尼恩团队从 高并发压测实操开始,给大家梳理一个系列的《Java 调优圣经》PDF 电子书,包括本文在内规划的五个部分:
(1) 调优圣经1:零基础精通Jmeter分布式压测,10Wqps+压测实操 (已经完成)
(2) 调优圣经2:从70s到20ms,一次3500倍性能优化实战,方案人人可用(已经完成)
(3) 调优圣经3:零基础精通JVM调优实操,实现JVM自由 (写作中)
(4) 调优圣经4:零基础精通Mysql调优实操,实现Mysql调优自由 (写作中)
(5) 调优圣经5:零基础精通Linux、Tomcatl调优实操,实现基础设施调优自由 (写作中)
以上的多篇文章,后续将陆续在 技术自由圈 公众号发布。 完整的《Java 调优圣经》PDF V2,可以找尼恩获取。
技术自由的实现路径 PDF:
实现你的 架构自由:
《吃透8图1模板,人人可以做架构》
《10Wqps评论中台,如何架构?B站是这么做的!!!》
《阿里二面:千万级、亿级数据,如何性能优化? 教科书级 答案来了》
《峰值21WQps、亿级DAU,小游戏《羊了个羊》是怎么架构的?》
《100亿级订单怎么调度,来一个大厂的极品方案》
《2个大厂 100亿级 超大流量 红包 架构方案》
… 更多架构文章,正在添加中
尼恩 架构笔记、面试题 的PDF文件更新,▼请到下面【技术自由圈】公号取 ▼