MySQL索引和事物

日升时奋斗,日落时自省
目录
一、索引操作
1、查找索引
2、创建索引
3、删除索引
二、索引内部结构
(1)哈希表 (在MySQL中否定)
(2)二叉搜索树(在MySQL中否定)
(3)N叉搜索树(在MySQL中否定)
(4)B树
三、事务
1、 事务的四大特性:
2、隔离性
首先要知道索引是什么
索引就像一个全智能自动化的枪一样,指哪打哪,想要的信息可能是一个也可能是多个,一个的话好找是吧,但是多个就不好找了,所以这时候就需要索引来指哪打哪。
实际的例子:一本书的目录,需要某块信息的时翻目录就行了,因为目录的划分都是独一无二的,会提高你的查询效率(不用担心查找重复)
索引的效果:加快查询速度(记得仅是查询加快了)
尽然有这么好的东西为啥不都全部用了
不用的原因:(1)索引也有缺陷,提高了增 删 改 的开销
(2)索引也提高了空间的开销,构造索引需要额外硬盘空间保存(当然这其实在当下不算什么问题,硬盘空间可以买嘛,问题也就解决了)
例如:新增一个内容,索引就会有一个变化,不仅仅是内容,目录就要从新排一下板
索引使用看需求,虽然不全面的,但是还是提高了很多情况的效率的
实例:电子书友友们都看过吧,这个其实就很简单了,一本已经完结的书是不是就只需要查询了,这里为了用户体验,加上索引就很快了。
在所有的软件开发中都没有能一击解决所有问题的,都是因需求而定,灵活应用解决方案
一、索引操作
1、查找索引
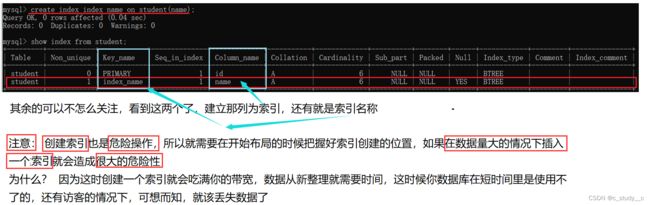
show index from student;

2、创建索引
create index (索引名称) on student(列名); 这里的student是表名
当前的索引只有一个id 被创建索引了,现在创建一个新索引来看一下
有重复元素可以创建索引吗,可以但是会导致效率不是太好,不会报错
个例:如果性别创建一个索引,你找男还是找女,觉得用处大吗,缩小不了范围空间,
只有在重复名不多的情况下才能够提升效率
慎重:在创建数据库的时候就把索引的布局想好,中途尽量不要修改,因为数据量会慢慢增加,就不好在加索引了
索引是个目录,他会自己跑的
SQL是通过数据库中的引擎来执行的 会有一定的优化操作,评估成本最低的速度最快的来执行。
代码优化:这个平常说的不是我们自己优化,而是在编译器中在建立后大佬们,添加上的,我们的代码不一定是最优的,编译器会在保留源代码的基础上进行修改提高速度
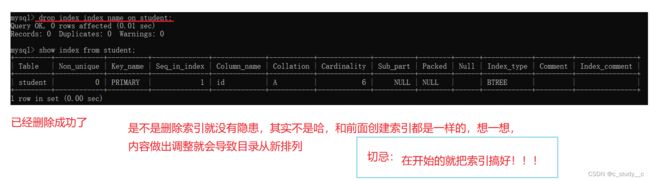
3、删除索引
drop index (索引名称) on 表名
二、索引内部结构
索引的数据结构是什么?但是这里的索引不会数组的索引,索引的两个是不一样的。
因为两个索引没有什么关系,这两个东西不是同一类的,所以没有可比较性
常见查询猜测
(1)哈希表 (在MySQL中否定)
时间复杂度O(1)
索引的数据结构是什么:我们很容易想到的就是哈希表,因为快嘛,这是数据结构里最重要的,没有之一,这里确实涉及不到
不是哈希表的原因: 哈希表只能比较相等,无法进行 范围性查询,数据库很少进行的个位数的查询,更多的是进行大范围查询
(2)二叉搜索树(在MySQL中否定)
时间复杂度O(N) 主要考虑最坏时间复杂度 有一个单枝树 使用树的话就相当与一个链表
二叉搜索树是可以查询范围的,但是其实也并没有使用二叉搜索树,二叉搜索树在多个元素的时候就会有很大的高度,树的高度就决定了查询的时候,元素的比较个数,数据库的比较都是需要读取硬盘的,比较消耗时间
(3)N叉搜索树(在MySQL中否定)
以二叉搜索树作为实例就知道N叉搜索树是什么意思了,这里画图解释一下
B树 :
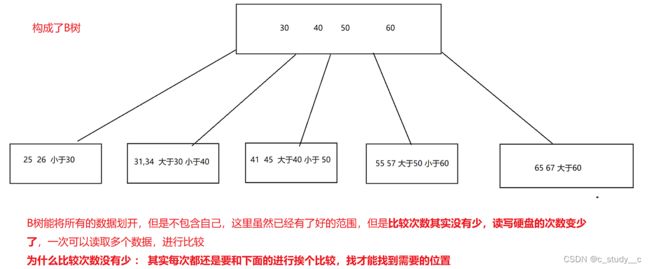
是不是觉得这个已经很好了,但是事实上,它还不是最合适的,接下来介绍一个专门为索引而生的一种数据结构
(4)B树
B树其实更适合对于当前索引使用,B树是在二叉搜素树上加了一部分的特点,
这里我们需要的是B+树,画图解释一下B+树长什么样子 ,还拿原来的数据来解释
B+树同样和N叉搜索树一样的,都是有N个节点的
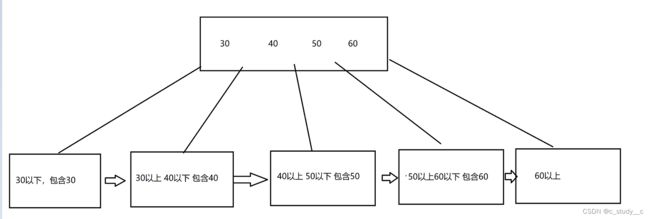
这个图作为解释,B+树基本就是这个样子了,在纸叶子节点中包含上面的节点作为本也叶子的最大 (父元素会在子元素中在出现一遍)
实例:
优点:
(1)B+树,高度相比N叉搜索树降低了高度,硬盘IO比较次数减少(IO 就是输入输出)
(2)适合范围性查找
(3)所有查询,都是要在子节点的,每个元素中间过程相同(查找速度相同)
(4)数据库虽然有很多数据,但是这里不是全部都会放进去的,只存放一行给到B+树的子节点,非子节点都只存了简单的 数值 如:id (节省空间,减少缓存,提高查询速度)
其他实例:
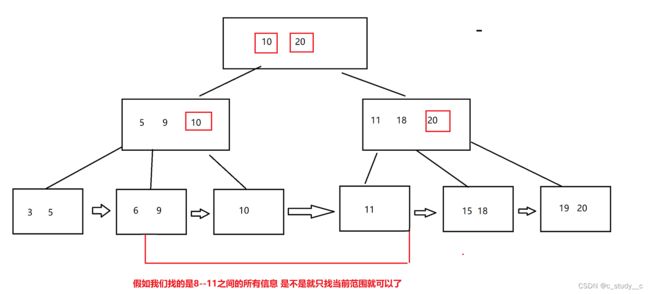
主键有索引,如: id 就是以上的B+树进行建立的,但是如果是其他作为索引呢,如: 姓名会先把非子节点里面存入姓名,最后的叶子节点存放主键:id
使用主键查询是最好的,因为就走B+树一遍
如果使用非主键查询的话,就要先把本索引进行查询后 再查询主键索引一遍(后者称为回表)
针对性:B+树结构只针对MySQL的InnoDB这个数据库引擎
不同的数据库,不同的引擎,里面存储数据的解耦还可能存在差异,前面提了几种不同的猜测,不是不用是有可能使用的,有特殊存储引擎,满足需求而已
存储引擎: 指的最核心模块, 这里说的就是数据库的存储引擎(数据库如何组织数据的)
三、事务
事务:就相当于一个整体,所有操作的集合
实例: 以转账为例
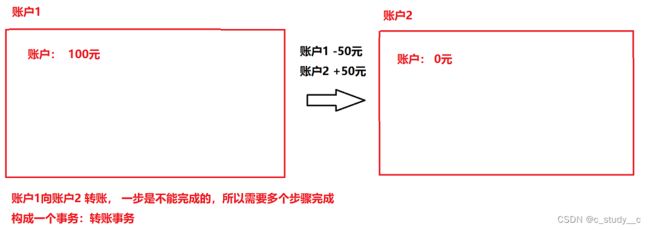
将多个操作打包成一个整体,要么全部执行,要么不执行(解释)
不执行的解释:转账要保证在失败的情况下恢复平衡,以免造成市面上的恐慌,所以会有一个回滚的操作,在中途执行中断的话,就会恢复原来的数据,相当于没有执行:这就是一致性
解释回滚:相当于 逆向操作 恢复回去, (类似于撤销)
所以数据库会把每次执行的操作都记录下来,如果某个操作出错了,就会把事务中的操作进行会滚
回滚操作开销很大,只能保存当下的正在执行的事务
(间接性理解:如果可以无限制回滚是不是就算把库删了都没事,主要是需要很大空间能在把这些操作在装一遍,很费钱,所以不会这么做)
事务特性:打包成一个整体 就是 事务的“原子性”
开启事务:start transaction
中间写 :你的操作 (所有操作都进行完了)
结束事务 : commit (commit才会执行保证了原子性)
1、 事务的四大特性:
(1)原子性(事务的初心)
(2)一致性:事务执行前后,都必须是合法状态,刚刚的账户转账已经解释了,可以中途出错,但是,不能让数据出现丢失现象
(3)持久性:事务产生的修改,都会写入硬盘的,及时程序重启/主机断电,事务都可以正常工作,保证修改会生效,(就算断电了,只要电来了,操作都能给你续上,例如重启后回滚会接着上次执行的位置)
(4)隔离性:数据库服务器,同时执行多个事务的时候,就会有相互影响程度(详细解释)
解释一下相互影响为什么?
例如一个服务器有多个客户端在用,此时就是并发关系,一个客户端频繁大数据使用就会导致就相当于占住了服务器,导致其他的客户端不能使用,或者使用速度较慢
与事务相仿的内容:事务中会保存当前操作系统正在执行的操作,所以在操作错误时就会进行回滚,保证数据的一致性,相当于进行了保存
那删除数据,操作系统上是怎么解决的,其实不是真的删除了,通常采用逻辑删除,不会真的删除所有
逻辑删除:将删除进行标记,不会直接物理性删除,就相当于我们前面写的堆,再删除的时候就是有效数据的个数减少,不是真的把数据清空了,这就是为什么在我们不小心删除部分数据的时候可以通过某些方法进行找回(某些回复软件)
真正的删除是通过物理删除,这些数据都是放在硬盘里的,所以物理删除就是把硬盘弄坏(那数据就真没了)
2、隔离性
MySQL服务器 同时会给多个客户端提供服务
这里细说一下,多个客户端在同一个服务器上使用,并且操作同一个数据库的同一个表,那是不是并发程度就比较高,就不会那么准确
隔离性和并发程度的关系
如果隔离性越高,并发程度就越低(隔离后关联性小,并发可能性就小),执行效率就越慢(隔离后关联性减小,每次就会需要执行的就多),但是数据准确性就高
如果隔离性越低,并发程度就越高(隔离后关联性大,并发可能性就大),执行效率就越快(隔离后关联性增大,每次需要执行的就会减少),但是数据准确性就低
速度和准确性不可以兼固,同样是视情况而定,因地制宜,做好取舍
实例:
(1)隔离性高的情况下,需要的是,当然跟钱有关系的肯定就比较慎重了,可以慢点,但是一定要准确,所以隔离性就比较高了
(2)隔离性低的情况下,例如:有些点赞的操作,当你点的很快的时候,多一个少一个其实并不影响用户的体验,所以这里为了用户体验我们会选择求速度,不那么最追求数据准确性
MySQL应对不同的需求提供了不同的档位调控隔离性的高低/并发程度的高低/执行效率的高低/数据准确性的高低
(1)脏读

那刚刚说到脏读问题,那如何解决呢
是不是2号滑稽可以些写完了,再给1号滑稽看,所以嘛,把2号滑稽关起来(加锁),就解决了脏读问题

但是问题真的就解决了吗
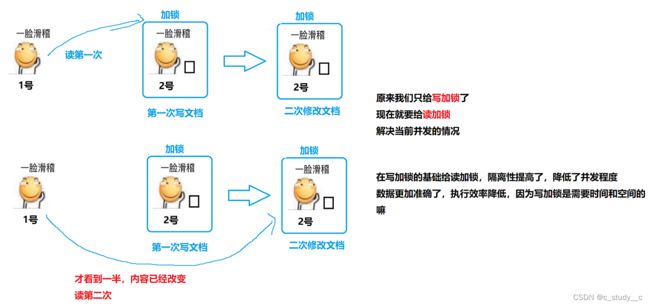
(2)其实没有(不可重复读)
解释:当1号滑稽在读2号滑稽写完的文档时,2号滑稽又想在给文档里填一点内容,再次提交,这时候就导致,1号滑稽看到一半,后面的内容还没有看后面的内容,内容就已经改变了
在数据中,不能重复读一组数据两次,其实当前就是因为该数据已经被读了两次了
这里解释一下:为什么是两次,2号滑稽第一次提交,1号滑稽看的时候,就是读第一次了,但是2号滑稽又想再加一点再次提交,1号滑稽还是看同一个文档的改后版,虽然对于1号滑稽是同一份文档,但是内容已经改变,相当于读了第二次
(3)幻读
前面已经完成了加锁问题,但是加锁只是可以封闭文档,但是并不代表就封闭了文件夹,一个大的文档下有多个子文件,2号滑稽确实在1号滑稽读的时候不能进行修改,1号滑稽在2号滑稽写的时候不能读,但是2号在这里要是不小心删了一个子文件,那1号滑稽看到文件少了(幻读),还没有看就出现问题了,两人接收的东西就不大一样了

事务不同档位,四个隔离分段

这些隔离档位可以在MySQL配置文件上进行修改,
MySQL配置文件 my.ini 可以直接进行修改

在配置文件里面找[mysqld]部分,在下面进行添加
transaction-isolation = REPEATABLE-READ
transaction-isolation = READ-COMMITTED
transaction-isolation = READ-UNCOMMITTED
transaction-isolation = SERIALIZABLE
当然其实不用在配置文件夹里也可以改隔离等级
搜一下在MySQL的代码执行
就算你加了,也不会有是什么反应的,因为我们现在使用数据量也不大,基本看不出来
只能选一个写进去哈,不是把这些都写进去,
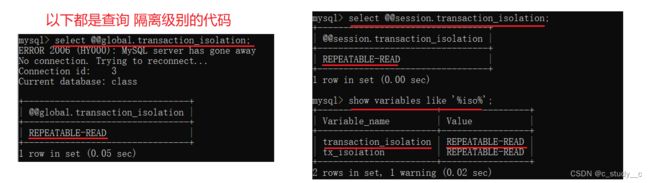
这里怎么看,我们改了没有,就用以下代码进行查看
select @@global.transaction_isolation; (全局隔离级别)
select @@session.transaction_isolation; (会话隔离级别)
show variables like '%iso%';