pandas
pandas
- 数据结构
- 生成数据
-
- 创建 Series
- 创建 DataFrame
- 数据处理
-
- 相关方法功能介绍
数据结构
| 描述 | 举例 | |
|---|---|---|
| Series | 带有标签的一维数组 |  |
| DataFrame | 带有标签的二维数组 | 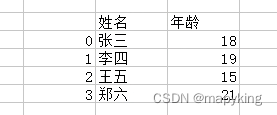 |
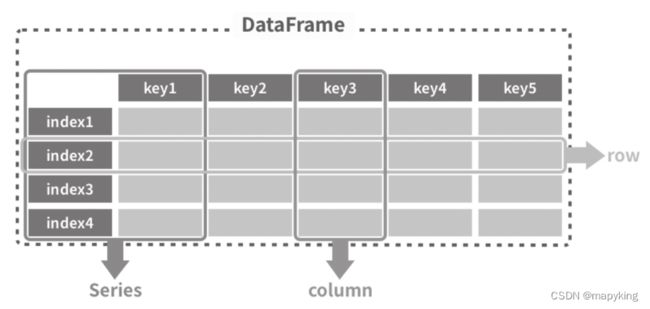
生成数据
创建 Series
# s = pd.Series(data, index=index)
s1 = pandas.Series(['张三','李四','王五','郑六'])
s2 = pandas.Series(['张三','李四','王五','郑六'],index=['a','b','c','d'])

创建 DataFrame
# df = pd.DataFrame(data=None, index=None, columns=None)
import pandas
df = pandas.DataFrame(
{
'姓名':['张三','李四','王五'],
'年龄':['21','30','29'],
'职业':['学生','警察','医生']
}
)
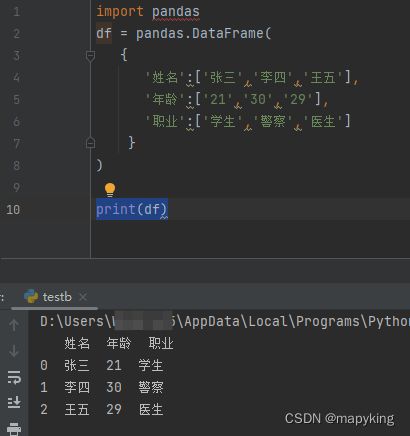
数据处理
Pandas可以将指定格式的数据读取到DataFrame中,并将DataFrame输出为指定格式的文件

# 读函数 df=pandas.read_xxx(fileName)
pandas.read_csv('data1.csv')
# 输出函数 df=pandas.to_xxx(fileName)
pandas.to_csv('data2.csv')
相关方法功能介绍
import pandas
df = pandas.read_excel('./data1.xlsx')
| 方法 | 描述 |
|---|---|
| df.cloName / df[ [‘cloName1’,‘cloName2’] ] |
取对应列 |
| df.filter(items=[‘cloName1’,‘cloName2’]) / df.filter(regex=‘^a’, axis=0).filter(like=‘Q’, axis=1) |
选择对应列 / 索引以a开头列名有Q的行 |
| df.axes | 返回一个列内容和行内容组成的列表 |
| df.head() /.tail() /.sample() / df[:3] | 返回前默认5行 / 后默认5行 / 随机1行 / 前3行 |
| df.loc[[0,5,10]] / df.loc[0:5,[‘cloName1’,‘cloName2’]] / df.loc[ df[“cloName1”]==89 ] |
返回0,5,10行 / 返回cloName1 2 前5行 / 返回cloName1=89的行 |
| df.query(‘cloName1 > 90’) | 返回cloName1 > 90的所有行 |
| df.shape | 返回 一个 (行数,列数) 的元组 |
| df.cloName.mean() | 若该列数据类型为int,则可以计算该列平均值 |
| df.cloName.add() / .sub() / .mul() / .div() | 对数据进行广播式加/减/乘/除 |
| df.nunique() | 去重 |
| df.truncate(before=x, after=y) | 将x-y行以外数据剔除 |
| df.select_dtypes(include=[‘int’]) / df.select_dtypes(exclude=[‘int’]) |
选择 / 排除 int类型数据 |
| df.replace() | 替换数据 |
| df.fillna() | 填充空值 |
| df.rename(columns={‘cloName1’:‘cloName2’}) | 修改cloName1列名为cloName2 |
| df.assign(k=v) | 指定一个新列,k为新列的列名,v为此列的值 |
| df.dropna() / df.dropna(axis=‘columns’) / df.dropna(how=‘all’) / df.dropna(thresh=2) / df.dropna(inplace=True) |
一行中有一个缺失值就删除 / 只保留全有值的列 / 行或列全没值才删除 / 至少有两个空值时才删除 / 删除并使替换生效 |
| df.where(df > 70) | 将大于70数据筛选出来,不满足的位置填充为NaN,df.where(df==9999999, np.where(df>=60, ‘合格’, ‘不合格’)) 使用NumPy弥补panda的不足,大于等于60值为及格,小于则置为不及格 |
import pandas
df = pandas.read_excel('./data.xlsx')
# 使用迭代
# .iterrows()
for index ,row in df.iterrows():
print(index ,row.Q1,row['name'])
# 结果
0 89 Liver
1 36 Arry
2 57 Ack
3 93 Eorge
4 65 Oah
5 24 Harlie
6 61 Acob
7 9 Lfie
# .itertuples()
# 可以在itertuples()内进行筛选,df.itertuples(colName1='xxx',colName2>yyy)
for index ,row in df.itertuples():
print(row)
# 结果
Pandas(Index=0, name='Liver', team='E', Q1=89, Q2=21, Q3=24, Q4=64)
Pandas(Index=1, name='Arry', team='C', Q1=36, Q2=37, Q3=37, Q4=57)
Pandas(Index=2, name='Ack', team='A', Q1=57, Q2=60, Q3=18, Q4=84)
Pandas(Index=3, name='Eorge', team='C', Q1=93, Q2=96, Q3=71, Q4=78)
Pandas(Index=4, name='Oah', team='D', Q1=65, Q2=49, Q3=61, Q4=86)
Pandas(Index=5, name='Harlie', team='C', Q1=24, Q2=13, Q3=87, Q4=43)
Pandas(Index=6, name='Acob', team='B', Q1=61, Q2=95, Q3=94, Q4=8)