网络基础(一)
网络基础(一)
你不用担心说,怎么听不懂,一点儿头绪都没有,你要记住感觉,不要现在有些听不懂,你后面能听懂了,觉得没进步。第一个是,网络基础(一)主要谈的是网络框架;第二个呢,网络套接字;第三个,网络原理;第四个,叫做高级IO。 高级IO我们主要谈,多路转接,5种IO模型以及reactor模式。
》第一个说说网络发展背景;第二个呢,局域网和广域网;第三个呢,理解网络协议,然后重新理解一下tcp、ip5种模型;第四个,网络传输的基本常识,理解封装和分用的关系。对我们来讲呢,网络部分比系统学习的成本更加低一些,第一次写代码呢会写的生份一点,写多了就是固定套路。
网络背景
》截止到目前为止我们写的所有代码都是单机的,也就是说你可以创建进程、线程、什么信号通信你全部都可以搞起来,但是依旧只是单机的。什么叫做单机呢,就是在一台机器上,早些年人们在进行编程的时候或者写代码处理某些事情的时候,大部分都是单机的,可是呢总架不住我们需要协同工作。假设一台电脑叫做独立模式。假设有三个3电脑即3个终端,其中呢我们要把不同的数据进行处理,比如有一份数据是同学们的名单,第一个人要做什么呢,要把同学们的名单中错别字挑出来;第二个人呢,然后呢把挑出来的错别字全部改成;第三个人他要继续基于我们的名单呢继续对我们名单排版进行调整,然后就完成了对名单的处理工作。假设有3台电脑,A、B、C,所以三个人用不同的电脑做不同的工作,这个没有什么问题,但是早些年呢,机器和机器,计算机和计算机是独立的,其实说白了,就跟你现在拿计算器按来按去一个道理,做计算,左处理嘛,所以此时呢,A把数据全部挑出来了 ,他要把东西交给B,怎么交给呢,在那个没有网络和网线的年代,怎么把数据从终端A到终端B呢,有人说用U盘拷 ,那时候没有。那就只能人工交给B了。那么其中呢,我们主机A生产完的数据在交给主机B,中间就要经过人工处理,记住只要有人参与的地方,一定是效率很低的地方,所以后来随着时代的发展,对应的各种实验室,他们有强烈的诉求,不同的人做着不同的事情,大家的电脑如果不连通,一个人电脑处理完想交给另外一个人就只能通过软盘,恰好实验室的人懂技术觉得这样不妥,所以此时呢就有人尝试把多台计算机连接起来,用线路连接起来,此时就有了多台计算机互相连接来完成对应的数据共享。说白了就是理解成多台计算机用网线把我们的所有主机连接起来,各主机之间就可以彼此之间互相通信了,我们就有了网络的初步的形态。
》我们先抛出一个话题,就是我们如何重新看待计算机结构—理解计算机通过网络互联的可能性!!我们重新把之前计算机上面各种体系结构和硬件呢给大家讲个故事,让大家重新认识计算机体系结构,然后再重新看看,你说拿根网线连起来就可以,那这个原理该怎么去理解呢,不能说连起来就是网络了,太肤浅了。所以让同学们在体系结构层面上重新换一个视角去理解一下,他这个连起来之后,主机和主机之间通信,我们应该以怎么样去看待这个现象。我们接下来重新理解一下计算机体系结构。
》我们之前在讲的时候说过一个概念,我们有输入设备、输出设备、内存、CPU,然后呢在我们CPU内部呢又有运算器和控制器。我们曾经一直在说,输入设备,比如磁盘、外设,对应的一定要将自己的数据从外设般至内存当我们正在被访问时。然后CPU呢对数据做处理加载回内存,然后再刷新到我们的显示器上或者外设,这都没问题,这叫做冯诺伊曼。但是你曾经讲输入设备把数据从外设搬入到内存里,然后输出设备呢就是从内存搬出去。可是我有这么一个问题,那么其中输入、内存、CPU、输出他们都是硬件,这些硬件是如何进行数据交互的??什么意思,就是你说把数据从外设搬到内存里, 这不是你拿嘴说的,我们确实外设可以生产数据,然后拷贝至我们的内存里,但是呢,这是两个设备,是两个独立的硬件设备,那么这两个独立的硬件设备是如何交互的呢?同学们,两个设备交互,前提条件不是隔空去交互的,前提条件是,这几个设备之间必须得用我们称做的线连接起来。这个应该是一个常识,两个设备互相独立,用线连起来,他们两个才有可能通信,要不然他们两个怎么通信?一般这个线呢,你内存有自己的内存槽,然后你把内存插刀内存槽里面,设备呢要接入到我们的主板当中,CPU呢也是内嵌到我们的主板当中的,你是可以拿下来的。但是呢,有一个什么问题呢,我们所有的电路,它这个线呢,其实就是有的你能看到的线,有的呢就是直接在我们的主板当中焊接好的硬件电路,总之呢,要有线,不然拿什么完呢。只不过,因为我们对应的这些硬件设备是在一台机器上。所以一台机器,那么线就比较短。所以通信的时候,它的数据各方面的问题呢,比如通信时,因为不涉及长距离传输,所以它这个线呢,传输的可靠性还是很强的。
》但是呢,如果我们是两台机器呢。假设有网卡设备,两台计算机都有网卡设备,两台计算机在通信的时候,一定是要能够,每台电脑内部是有线的,我们两台计算机也要能互相通信,那么这两台计算机也得用线连接起来,你现在就理解成网线,当还有我们对应的无线Lan。但是呢,无论你通过什么方式去连接,它也是线,所以计算机内它本质上我们可以称之为,叫做计算机体系结构本质也可以被看作成为一个小型的网络。也就是说在体系结构里面呢,它们各自独立的硬件设备用线连接起来,所有不同的设备都有不同能力,所以它本质就是一个小型的网络,所有计算机内部之间各个硬件设备也是用线连接起来的。所以我们所谓的计算机体系结构,我们把它就看做成一个小型网络,本来就是用线连接起来的,只不过是短而已。
》如果我们有两台计算机连接起来的时候,本质上是不是相当于我们对应的两台,我们可以称之为,叫做两台计算机,与其说在体系结构层面上是两个计算机通信,倒不如说两台计算机的网卡之间又通过网线连接起来了,无外乎就是线长了一些。换而言之,我们的多主机连接本质上,其实也是通过“线”连接起来。两台计算机也是线连接起来的,体系结构内的线短而已,仅此而已。那么我们可以这么去理解,我们现阶段认为两台主机之间 互相连接通信,本质上是可以理解成它是体系结构上的延展,也是通过线连接起来的。所以我们回过头看一下,我们从单主机到多主机拉根线就完了,我们就应该想到他是具有可行性的。因为只要是计算机里面,硬件设备和硬件设备用线连接起来就可以通信,那么我们也可以把两台计算机的网卡用线连接起来,只不过线长了点,只不是计算机体系结构的延展,当然就能够通信了。
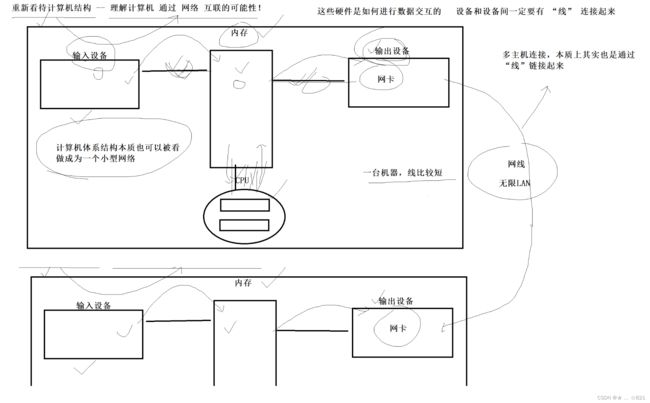
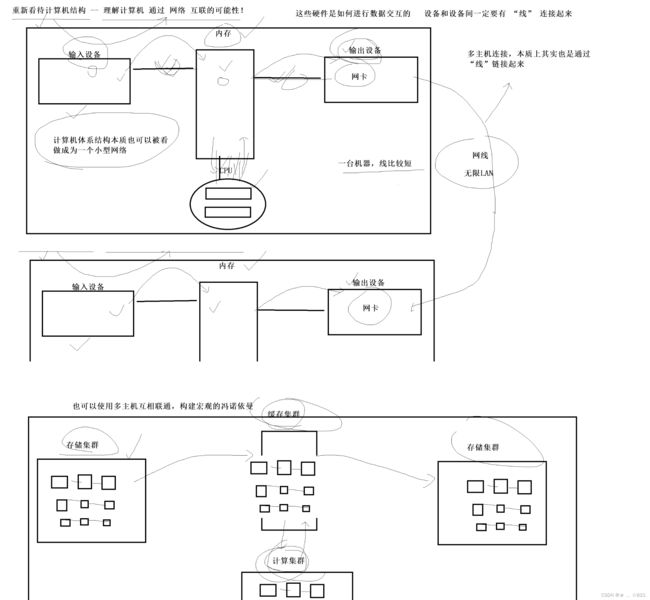
》当我们有了这么一个理解,我们就听说过,大型公司呢,有自己的存储集群,然后有自己的计算集群,缓存集群。所谓的集群说白了就是有特别多的主机,在主机的内部呢用内网连接起来。对每一个内部的集群呢也照样充满了很多很多的主机,大型互联网公司有自己集群,所以要被计算集群计算之后,所以可以把任务放到我们的缓存集群里面,然后呢以任务队列的方式让我们的计算集群拿到,计算集群拿到之后返回到缓存集群里面 ,再把数据写到存储集群里面。我们是不是照样可以使用多主机互相联通,构建宏观的冯诺伊曼呢。所以,我们再重新回过头看我们的计算机体系结构,你就会发现,其中体系结构上呢有网络, 网络呢也可以构建体系结构,它们两个其实是不分的。所以当你有这样的宏观认识,此时再看我们刚刚所说的概念时你也一瞬间就懂了。
》那么其中我们在一台计算机里面,我们把外设和内存之间连接起来的这根线,我们一般叫做,IO总线。外 和内存人家还有新的设备,比如南桥。CPU和内存之间连接的线呢,我们一般叫做系统总线,我们一般听说的32位、64位就是指的CPU和内存之间线的个数,这是硬件决定的。所以我们知道了一台计算机内部其实也是一个小型的网络结构。我们两台小型网络结构通过网线,长距离连接构成了更大的网络结构其实很正常,多个网络结构构成,我们也可以把他们搞成 不同的主机集群,然后我们可以构建冯诺伊曼体系,此时我们叫做大型互联网计算和存储平台。其实是一个道理。 这就是你换成不同的视角看到不一样的结果。
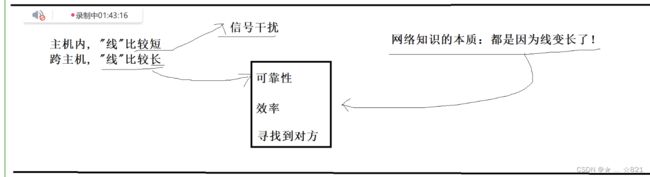
》当我们理解到这一层之后,你不得不面面对一个问题,主机内,“线”比较短, 跨主机,“线”比较长。同学们记住了,短有短的好处,长有长的难处。短一定面临的一定是数据和数据之间信号相互干扰的问题。有的时候我们把总线设计的很密集,线路线路大家都知道,当电子在流动的时候会形成磁场,磁场和磁场之间会互相干扰,所以一旦太近了就容易互相干扰。所以一台机器里面,设备把数据交到我们的内存里面,它往往也要定协议的,他不是单纯的把数据放到内存里,他也有自己对应的协议,只不过呢我们在硬件和硬件一台机器里面,他们互相交互的时候,做得最多的就是纠错,防止比特位翻转,所以放数据的时候会有一些校验信息,来校验这部分数据曾经是否在传输过程中出现问题。所以不要简单的认为,计算机里面没有任何处理,它是做了的,也有自己的校验的。对我们来讲,线路一长也会带来问题,物理结构变化一定会带来新的问题。线一旦长了,第一个就是,可靠性的问题;第二个,就是效率的问题;第三个,就是寻找到对方的问题。 所有的网络研究的问题,本质最根本的道理就是机器与机器之间传输的线路太长。大家也知道,数据经过长距离传输,短距离不影响,短距离信息密集可能干扰的话我们校验一下,重做的话很快就能完成。但是长距离面临和短距离面临的问题是不一样的。比如说你丢包了怎么办,数据在传输过程中会发生我们信号衰减的,越来越弱了,长距离传输很容易出现我们丢包、比特位翻转各种其他问题。还有就是传输的时候你怎么尽快的保证把数据交给对方,距离太长了,所以效率问题怎么保证。第三个呢,你今天是网络一台主机,同时和多个主机连接,可是不像你在一台机器里面,比如说我的磁盘要找到内存,那我们对应的就可以通过我们连接的线和我们内存的线在主板的什么位置,大致是确定的,所以一个设备找到另一个设备,但是长距离的时候你要找到那个主机可能和你距离相隔千里之外。所以我们学网络知识的本质都是因为我们的线边长了。
》一开始主机之间不能通信,也就是不联通,然后我们发展,在硬件级别上,我们可以把所有主机用线连接起来,当然话说到这里,你单单用线把主机连接起来也是不行的,就跟你平时打电话一样,把线拉到你家里面,你不用,也没办法。所以网络除了把线连接起来,其实还要进行我们软件上的配合,这就叫做协议,后面说。所以对我们来讲,各个主机之间呢, 它互相使用我们对应的叫做,同学们可以理解成网络将我们的所有主机连接起来。后来我们在有了网络之后呢,连接的主机越来越多了。越来多的时候呢,此时我们一个网络,可以称做局域网,小型的局域网呢,比如说呢,清华大学有一个局域网,内部实验室用的是一个网络,然后呢北京大学也有一个局域网…后来呢,不仅在公司内部有交流,在学校有交流,我们可能还要跨学校,所以我们有了各种新的设备诞生,其中局域网为了能够更好的通信呢,就引入了,交换机的概念,每一个局域网都引入了交换机的概念。关于交换机呢,我们后面再讲Mac帧的时候再说。在下面呢,还有我们说的路由器进行局域网和局域网内进行数据包转发,所以我们最后接入对应的网络变得越来越大,我们其中有一个局域网LAN,说白就是一个局域网,在局域网通信的范围之内我们可以直接去通信,然后呢各个局域网内部可以去通信,但是两个机器通过跨网络传输,因为线长了,那我们得有很多的策略把数据安全可靠的送到对方,那么其中就衍生出来了很多的设备,这个道理呢举一个小例子来理解。就好比古代的时候,我住在城里面, 我要吃饭就去城里面找一家馆子,这叫距离近。比如说我们是在北京城里,然后呢想去南京城里面去吃饭,此时单纯从北京走到北京城里的某一家馆子吃饭,这叫做路上走,那么我从北京到南京也是在路上走,本质上是路变长了,它不仅仅是路变长了,他一定也要衍生出新的东西来,比如说路上会出现驿站等新的东西出来。所以一旦距离变长了呢,我们为了支持在长距离传输等过程中,包括数据衰减了怎么办,包括我们为了更好进行在网络中传输,我们数据该怎么去编码这个问题,然后再下来呢,我们数据包互相转发的时候,凭什么找到对方主机,那么我就要有路由器这么一个东西。所以长距离传输带来新的问题,就一定要有新的设备去解决它。当我们的网络变大的时候呢,中间就诞生了各种各样的设备,其中关于设备呢我们后面都会介绍,但是同学们, 常识告诉我们路由器他一定是用来连接不同的网络的,所以左侧是局域网,右侧也是局域网,中间通过路由器来进行连接。
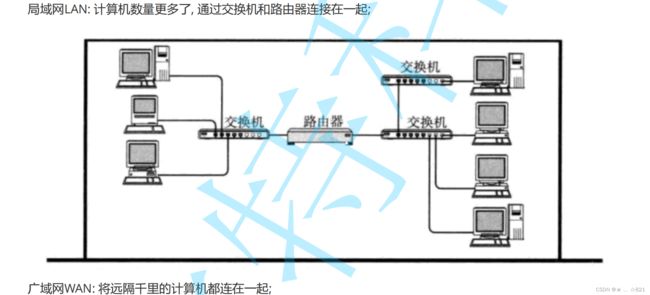
所以就有了局域网概念。后面慢慢的随着一个地方的网络结构变得越来越复杂,最后我们就有了广域网,所谓广域网就是将我们所有内部主机组成局域网,然后各个局域网将我们的数据通过路由器在公网内转发我们的数据包到不同的城市。所以从我们上面来看呢,课件里面说了一句话,局域网和广域网或者城域网,本质上是相对的概念,如果你非得要明确的概念,我给你一个概念,所谓的局域网网络的内部没有路由器,可以有其他的设备,但是没有路由器,这叫做局域网。但如果是广域网的话,一定是要涉及到多种路由器,还要接入公网和私网或者内网,这些网的概念在讲我们的IP协议的时候我们会说。所以现阶段网络来讲其中大家要理解的就是,可以通过不同的 ,我们构建不同的网络呢可以让所有的主机跨网络进行传输,这就叫做局域网和广域网。我们说的局域网和广域网呢,其实就是想对的概念。比如说你宿舍就是一个子网,当然在学校里面,也可以将学校看成局域网,我们国家呢也可以看成大的广域网。
认识“协议”
因为长距离传输了,我们刚刚讲的局域网和广域网这么一个概念帮助大家去理解,其实在设备之间呢进行连接,那么他们两个就构成了新的体系结构,其实说白了,他就是计算机体系结构,只不过距离长了一点,长有长的难度,长了的话,我们双方就必须得定协议。关于协议的例子呢课件上有,但是我不想用它的。
》什么叫协议呢,关于协议呢,我们先讲什么是协议,然后再是如何去看待协议。给大家讲一个小故事,在以前的年代,打一次电话很费钱,你也知道是三大运营商给我们提供的通话服务。假设呢有一个学生是张三,张三收拾包袱准备去上学了,张三家是云南的,考上了北京要去上学了,他有一个担心,就是他的家庭条件不是很好,它每一个月要给家里报平安,第二个给家里要钱,第三比如说 有其他事情要给家里要说。所以张三呢心里就盘算着,怎么更好能够帮家里面省了钱,还能把我要表达的信息传递到呢。所以张三就想到了一个招跟他爸爸说,我要去北京上大学了,我后面给家里打电话的时候, 你只要看到是北京打得电话一定是我打的,如果我今天打了电话,电话响一声这是给家里报平安,如果想了两声这是我这个月没钱了,如果电话响了三声,你在接电话我们来沟通。所以张三和自己父亲约定好规则后呢,就奔赴北京上大学了。后面张三去北京上了大学,然后给家里打了电话只响了一声说明自己是平安的,父亲也知道;又过了一个月响了两声,父亲知道孩子没钱了。我们把父亲与儿子之间的约定,我们把它称之为“协议”。
》所以什么叫做协议呢,所谓的协议是通信双方,很明显张三是要发消息,老爹呢是要收消息,通信的双方做的一项大家心知肚明的约定,约定好了之后呢,他们就遵照约定来进行后续的工作,那么其中这就叫做协议。刚刚是我们告诉大家的,可以称做我们日常当中的约定。其实呢,关于协议的内容呢,我之前已经有意无意的写过了代码,代码里面呢也已经体现了协议定制的问题,虽然很小,但是也能说明问题。记不记得我们曾经在讲系统的时候,父进程和子进程直接通过管道通信,我们写了一个简单的进程池。当时我们通过管道让父进程向子进程写入4字节的数据,我们还有隐形的规定,我们写入的4字节数据必须得是整数。作为父进程和子进程,子进程怎么知道一次要从管道里面读几字节呢,它怎么知道我把读上来的若干个字节当做什么类型来看待呢?全都是我们约定好的。所以我们在写的时候使用uint32_t,读的时候我们也是用的uint32_t去读,我们隐形的至少做过两个约定。第一个就是,记住我每次只写4个字节,你读的时候也只能读4个,不能少也不能多,你必须4个4个读;第二,还有一个约定就是,我给你发的是整数,你必须将其转成整数再做处理。这叫做计算机上的约定,我们所做的就是约定,这叫做协议。我们在讲网络的时候,一定会涉及到各种各样的协议场景,这些场景呢慢慢说,
》如上就是要讲的协议,所以我们两台计算机之间想要互相通信的时候,我们也知道计算机只认识二进制,不光计算机,网络也是只认识二进制。在我们计算机里面呢,我们表示二进制在不同的设备上表现形式是不一样的,有的是通过信号的有无来表示信息的,比如说我们的CPU和内存互相传数据,有的是用强弱,比如说网路,有的可能是用频率等,包括我们之前讲的磁盘,用南极北极来表示二进制。所以我们想要传递不同的信息的话,我们只要双方约定好数据的格式,此时我们就叫做把协议定好了。光光将协议定制好,两台计算机就能通信吗?给大家举一个例子,那么其中只有协议够不够呢, 就能足以支撑两台计算机通信吗?答案是:还不够。同学们,对我们来讲呢,协议对我们来讲呢是一个软性层面上,我们多台主机规定好,我们可以遵守同样的通信协议,但是我们的计算机对应的生产厂商可是非常多的,不同的厂商对应的操作系统有很多,即便是操作系统一样,在硬件上呢也有很多大家都不一样。我们可以遵照协议,但是呢大家硬件和软件上实现的不同,极有可能带来的结果就是大家看到协议的时候,可能以同样的方式去解释时大家就听不懂。给大家举例子,比如说我们玩某某蹲的游戏,说到哪一个东西要蹲下来的话,那大家都得蹲下来,这叫约定好了游戏规则,约定好了就是协议定制好了,所以在给大家说话的时候,其实就是广播协议的时候,喊某个种类的蹲的时候,所有人按照游戏规则正常规定。但是突然里面有一个李四,他呢是一个博学多才,玩游戏的时候就是不跟你好好玩,他用法语说话,那我是不是也遵守了游戏规则,只不过用的法语说的,但是没有人能够听懂,所以也没有人能够正常的跟他玩下去。如果你把游戏的协议规则定好了,但是大家玩这个游戏时所采用的语言的不同,就无法沟通。就好比所有的主机都遵守网络协议,但是有的厂商有无来表示二进制,有的根据波峰波谷来区分0/1等,大家都可以用1010表示我们多个主机之间发送某些信息,但是呢我们不同的厂商解释的不一样所以互相之间也不能正常通信,所以除了要把协议定制好后,我们的主机与主机之间输入二进制上也必须得有标准。说白了就是,你不光要把约定做好,你还必须得保证不同的厂商之间人家会遵守你的约定,但是必须得保证他们是一样的,那么这里就有难度了,什么意思呢,比如说硬件设备通信的时候,他用的硬件层面上的传递的0/1信号的方式和对应主机传递0/1信号的方式必须得是一样的,这样大家对协议的解释方式是一样的,那么提取协议的时候也是一样的,这样才能正常通信。也就是说协议本身是双方沟通好的,就跟大家玩游戏,我们都用中文说,你非得一个人搞法语,你一个人在那里玩的很开心,最后你也遵守了游戏规则,确实你话说完没有人听得懂,你遵守了游戏规则呀,但是你照样玩不下去,这叫做大家底层硬件不一样,你照样玩不转,怎么办呢,此时我们不但要把游戏规则统一,我们还要能够把我们的表达方式统一,就好比我们要把协议统一,同时我们还要要求对应的厂商制作操作系统或者硬件的时候也必须采用统一的标准。我们为什么说比较复杂呢,这涉及到一个标准定制的问题,标准谁定呢,各个厂商都说我来定,那听谁的呢?谁的技术能力强就听谁的。
》我们刚刚只说了一个概念就是协议,顺便让大家理解我们有协议,也会有标准,除了软件上,硬件上也得有标准,如果你软硬件都不一样,你也写代码,有时候一个字节写错了程序就编译不过。更别说计算机需要大家都配合的,这么精密的仪器,出现任何问题你都是通不了信,所以大家都得遵守协议。下面呢我们要讲协议的层状结构。
协议分层
问同学们一个问题,你是如何理解软件分层的?我们在讲系统的时候是说过,什么叫做软件分层呢,给大家举例子,你以前一开始写代码的时候大概率就是把所有代码一股脑写在main()函数里面,后来你学会了要把功能写到一个个函数里面,然后我们在对应的main()函数里面你去调用对应的函数,你需要什么功能就去写什么功能,这叫做面向过程,然后呢你把所有的功能都封装成函数,那么此时呢我们可以认为你的代码是分层的,第一层是你的main()函数在顶层叫做调用逻辑;第二层就是你调用的函数。后来学了C++,我们学了继承,有了基类和子类,我们可以采用多态的方式来实现让我们基类指针指向不同的子类,从而体现出调用不同的方法。这也是一种分层是面向对象,这一层面是是分了两层。给你抽象出来基类,然后使用基类去指向子类去实现多态,这也是一种软件分层。再到后面呢,我们讲过一个非常重要的概念,就是linux下一皆文件,它通过操作系统层面上为每一个被打开的文件创建struct file,然后1.填充上所有属性,2.文件操作的函数指针,通过函数指针的方式指向底层不同设备所具有的方法,所以我们此时就有了,上层呢,就是struct file那层我们称之为虚拟文件层, 底层就是具体的设备对应的读写,这也是一种软件分层。所以我们必须得承认软件是可以分层的。虽然我们目前呢软件分层我们接触还不是很多,但是不影响,软件是可以分层的。也就是说呢,我们知道可以分了,那为什么呢?
》为什么要分层?从目前来看,我们所说的所有软件层面的解耦或分层,最终大家明显能够感觉到一点就是越分层代码的逻辑结构越清楚。而且对应的软件层状结构当中,对应的文件系统,上层调用下层的方法,通过函数指针指向不同的方法就能够实现C语言式的面相对象和多态,这就是分层带来的好 处。所以除此之外呢,我们未来在排出如那件问题的时候,如果我们发现struct file访问其他设备好着呢,访问另一个设备就不行,那么大概率不是struct file那层出问题了,而是我们的下层对应的设备读写逻辑出问题。所以分层有什么好处呢,1.软件在分层的同时,也把问题归类的,哪一层出问题其实我们是可以通过排查对应的哪一层出问题我们就解决哪一层的问题。因为层与层之间呢是调用和被调用的关系,所以对我们来讲呢,我们只要把某一层的问题解决了,并不影响另一层,所以呢方便我们排查对应的问题,这是其一;其二呢,2.分层的本质,就是软件上解耦。分层之后呢,层与层之间只有调用和被调用的关系,就和我们虚拟文件系统和底层设备每一个具体的读写,它底层对应的是磁盘,它就读的是磁盘的文件系统里面的具体文件系统的读写方法,它若指向我们的显示器,它对应的就是显示器的读写方法,如果是我们对应的键盘,那么就是键盘底层的读写方法,所以它呢把我们操作系统层面上维护文件的逻辑,和我们设备上具体维护的方法进行解耦,这就是分层带来的好处。与此同时呢,由于问题归类了,软件上也互相解耦了,那么其中我们一定带来的最终的结果就是,3.便于软件工程师进行软件维护,其实说白了就是好找问题和好改代码,什么叫做好维护,说白了就是出现问题好排查,第二个就是想改代码好改,我们可以改动的时候呢并不影响其他层,这就是为什么要分层的原因。所以基于一,软件是可以分层的,第二,软件的分层有这么多的好处,我们所对应的网络,网络所对应的协议栈本身呢,**网络本身的代码,就是层状结构!**我说的东西应该是能理解的。因为当时我们在讲硬件驱动,操作系统再到系统调用接口再到我们的库,再到我们的用户,我们其实自底向上在讲软硬件上,它就是层状结构,所以对我们来讲呢,层状结构是我们软件领域非常重要的一种结构,。所以软件行业里面有一句话,没有任何一个问题不能通过加一层来解决,也就是说呢,我们软件设计上了出现了不同的概念,我们可以通过加一层来解决,加一层什么呢,叫做软件层。话说到这,我们曾经讲的虚拟地址空间,没有虚拟地址空间的时候,我们的所有的进程是实模式下访问内存的,也就是直接能看到内存并对内存进行读写,这有问题吗?有,比如说是越界访问,可能自己有意或无意的对内存做修改,不安全,也不便于操作系统进行进程管理问题,其实他有很多问题,其实这就是问题。本着只要有软件问题,我们都可以通过添加一层软件层来解决,所以虚拟地址空间便诞生了,它本质上不就是加了一层软件层叫做虚拟地址空间吗,让页表进行映射,此时我们就可以在我们虚拟地址空间那一层对我们所谓的非法请求进行侦测拦截,操作系统识别对目标进程发信号,终止目标进程,这就叫做用层状来解决问题,当我们理解了这一点之后呢,网络协议栈也是这样设计的。
》所以软件本质上是分层的结构,关于分层的好处呢,给大家举一个例子,有A、C互相打电话,通过座机,双方通过打电话约定好吃什么了。那么我们可以认为我们打电话其实是分为两层的,第一层叫 做我们对应的语言层,我们双方能够语言来进行通话的;第二层呢就是通信设备层,我们认为我们是通过电话来沟通的。那么其中,如果有一天发生变化了,我们两个人继续通话,但是不再用我们的座机而是我们的手机。在语言层,该怎么说还是怎么说,没有改变,我们只是把底层设备换了,但是并不影响我们上层通信,只要你提供的功能是我所需要的通信功能就可以了。再说,底层没有变就是网络通信层没有变,而上层的两个人由汉语沟通,变成了英语沟通,也并不影响两部电话的通信,这就叫做软件分层。我相信能理解,因为我们当时在讲虚拟地址空间的时候,一个struct file函数指针,指向底层不同的设备,指向不同的方法就会有不同的表现,这个没有问题,我们都能知道,他们是可以直接进行我们对应的通信的,对我们同学来讲呢,我相信这个问题也能理解。
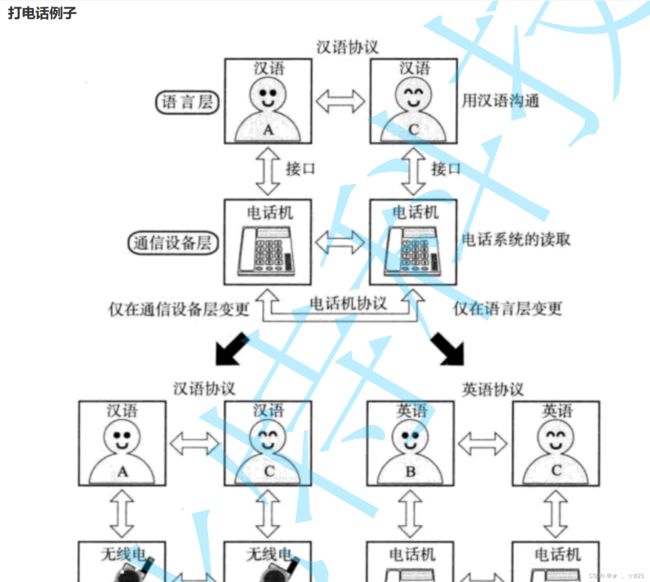
》我们再来谈下一个问题,我们层与层之间,它们之间又是怎么去通信的呢,比如说A、C两个人打电话,张三和李四,两个人打电话的时候,它们约定吃什么在哪里吃,当我们在打电话的时候,我们认不认为张三和李四两个人是直接通话呢?答案是:是的。是认为张三和李四是直接沟通的,但是呢,在实际上真正的直接沟通并不存在,为什么呢,就比如直播因为并不是在和同学们直接沟通,而是我们把说的话、声音等采集好,采集好之后,传到给平台,然后平台再帮我们做转发到我们每一个同学的桌面上。这是什么呢,这是站在普通老百姓用户的角度我在认为和你直接沟通,但是呢我们实际上呢,底层是通过不同的设备帮我们做转发的,比如说电话,电话实际上采集声音,然后对声音做编码,然后压缩,压缩完之后通过无线网,把数据推广到离我最近的基站,然后基站内部呢再做转发到对应的最近的基站然后再转到手机上,然后再解压和解码,然后调用我们喇叭的程序把我们的声音播放出来。其实我们正常沟通的时候底层帮我们做了很多很多的事情,但是不好意思我们并不关心。第二个呢,我认为我们两个在直接通信,那么这两个电话怎么想,这两个电话有没有认为在直接沟通呢?是的,它们也认为他们两个在直接沟通,可是呢,可能我在中国,你在美国,我们两个电话他们认为自己是在通信实际上数据是经过底层大量的转发,所以,这里呢我想告诉大家一个结论叫做,**层状结构下的网络协议,我们认为,同层协议,都可以认为自己在和对方直接通信,忽略底层细节。**我们可以认为每一层都在和自己同层的程序在直接通信,底层呢给他赋予的这样的功能呢,它完全不关心,这就叫做层状结构,所以呢,我们一般在定协议的时候,所以对我们来讲,每一层都认为自己在和对方直接通信,网络是层状的的,所以,同层之间一定都要有自己的协议。比如说,给大家举一个例子,比如说我们人之间的协议是什么呢,人之间协议就是打电话,打电话的时候我们两个把电话接起来,永远你把电话接起来的第一句话,永远是,喂?然后另一方也是,喂?此时我们就叫做语言层我们建立了通信。我们两个人之间呢,用的是人类自然语言定制的协议沟通。比如我说什么了,你就不能说,你在说什么,我就不能说。我们两个以半双工的方式进行通信,当然两台设备之间也是有自己的通信协议,所以同层之间,你们都如果认为自己在直接通信的话,那直接带来的结果就是,同层之间每一层都要有自己的协议。所以对我们来讲,分完层之后,层跟层之间最大的好处是什么呢,最大的好处就可以是,上层只需要调用下层提供的接口或者方法就可以了,你具体怎么做,我们不关心,我们不管,反正我调用一下你,最后你把功能直接给我,我要的结果直接拿到,我的目的就达成了,你具体底层怎么办和我没关系。就跟你调用printf,你从来都不关心底层实现,就跟你调用fork一样,你从来都不关心它会做什么,read、write一样也不会知道他们要做什么,我们要的是拿到的结果。因为网络是分层的结构,我们知道他是层状的,那下面就是它有哪些层呢?
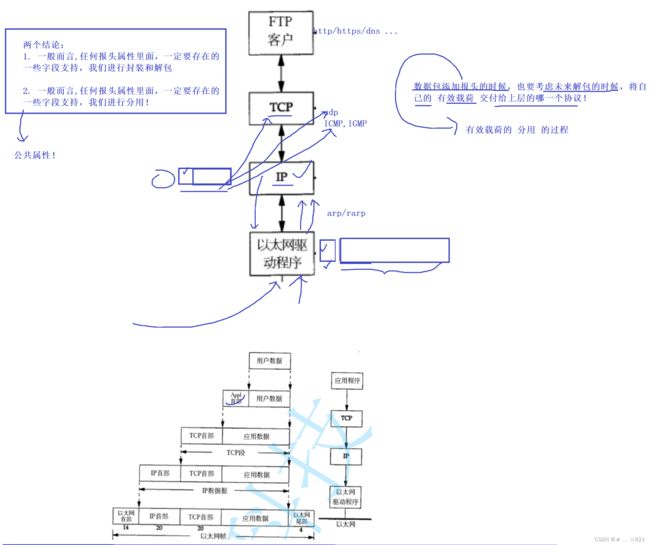
》既然网络是分层的,网络的代码也是用软件写的,所以对于网络来讲,它是层状的,那它有哪些层呢,最常见的,我们当时定网络协议的时候,有个组织叫做OSI,承担了网络协议栈的标准的定制,定标准的和写代码的有可能不是同一批人。所以OSI这个机构呢定制的协议,当时把网络划分成了七层模型,自底向上,分别是物理层、数据链路层、网络层、传输层、会话层、表示层、应用层。那么它其中呢,把我们忘网络划分成了若干层,它的这些每一层都负责有不同的功能,你现在肯定不太理解,因为还没有讲,站在一个很懂网络的视角呢,OSI他们的这一套标准定的时候,是定的特别好的,而且每一层该做什么工作,其实做的非常好,只不过呢,实际上在实施的时候,我们会发现实施的时候你所定义的协议呢挺好的,但是呢呢有很多东西不可能在标准情况下定好的。尤其是上三层,会话层、应用层、表示层是不好处理的,所以呢,实际上做出来的时候,我们的协议其实是五层,其实更准确的来说是四层协议,不过大部分教材写的时候是五层,因为我们谈的是网络协议栈,纯软件的有四层,所以我们就有了对应的,应用层、传输层、网络层、数据链路层、物理层。其中呢我们实际上制作就变成了五层协议。我们也承认许多教材里面的叫法,其中也把物理层也纳入某一层,其实也挺好,因为物理层本来就不属于软件范畴,但是我们后面在讲的时候,我们是按四层去讲的,因为我们重点讲的是软件层,也就是说应用、网络、传输、数据链路四层。这里呢,就不得不给大家谈一谈,产品经理和开发者故事,架构师把代码架构的再好,实际上在执行的时候也会发生变化,这个很正常,其实很多软件在设计的时候,曾经的设想和现在已经形成的其实差别很大,主要是受到实际客户的需求影响,其中,OSI中的上三层,应用、表示、会话,为什么实际上在制作的时候发现是不太行的,原因是,你看会话层解释有一句话:何时建立连接、何时断开连接以及保持多久的连接?实际上工程师子啊设计的时候发现,我们底层的协议呢是没办法去支撑它想要的功能,因为对应的工作是由软件去帮我们维护的,就比如说有的软件就不需要你,链接建立好完了,比如说http通信建立好了,很快就将连接断开,但有的软件就需要你维持长链接,就比如说我们的聊天系统,我们的QQ或者做一些其他软件,这东西就是要我们把链接保持请求。同时呢,如果你长时间不通信,会自动给你断链接。其实你会发现,这个东西是操作系统万全没办法做的,为什么呢,因为操作系统无法决定上层软件何时断开连接,所以对我们来讲实际上施工的时候无法达成。OSI做的挺好,但是把其写到操作系统内部是不太合理的。表示层在做的时候也是有问题的,就是你可以理解成,文字我们需要什么格式,不同的软件要求是不一样的,比如说微信上发的消息就可能是你的消息加你的头像,其他软件呢,可能是用来推送声音的,什么声音,分贝多少,这些其实都不一样 。应用场景更不用说了,每一个应用的场景不一样,所以你作为一个协议的定制着你想把这部分内容坐到内核里是很困难困难的,因为应用层的协议实在是太多了,有的是超文本传输的,有的是文件传输的,有的是域名解析的,有的是远程登录的,还有很多网络服务的,不同网络服务呢,协议不一样,你作为操作系统,你能把协议全部归纳到内核里面吗,做不到,实际上我们在做的时候,工程师在内核当中实现的是下面:传输、网络层,然后数据链路层是由我们的驱动程序去提供的。然后表示层、会话层、应用层由我们的用户自己去完成,后来我们会越来越感同身受,其实当时定这个标准是定的很好,但是在实际施工的时候发现做不到。如上就是网络分层有哪些层。
》·OSI(Open System Interconnection,开放系统互连)七层网络模型称为开放式系统互联参考模型,
是一个逻辑上的定义和规范;(你要记住了,你像网络通信协议这种,你不遵守就拿不到数据,你通不了信,这样的协议呢,除了定制协议的组织或个人或者公司本身权威之外,也倒逼着公司或者个人必须遵守我的标准,若不这样你就做不了。但是呢也有一些规范和标准也不能促使其它人或公司去做。OSI显然就是不被严格遵守的规范,它将网络分了七层,事实上我们网络也就是四层。)
·把网络从逻辑上分为了7层. 每一层都有相关、相对应的物理设备,比如路由器,交换机;
·OSI 七层模型是一种框架性的设计方法,其最主要的功能使就是帮助不同类型的主机实现数据传输;
·它的最大优点是将服务、接口和协议这三个概念明确地区分开来,概念清楚,理论也比较完整. 通过七
个层次化的结构模型使不同的系统不同的网络之间实现可靠的通讯;
·但是, 它既复杂又不实用; 所以我们按照TCP/IP四层模型来讲解
TCP/IP五层(或四层)模型
我们自底向上给大家说一下,比如我们说说硬件物理层,主要是解决光电信号问题,比如说我们通信的时候用的什么网线(双绞线),什么是双绞线呢,就是家里面的蓝色网线,现在大部分家庭用的是光纤,光纤在家里面入网口和你家里的猫的设备连接着的,从墙里面出来的。第二个就是无线WIFI就是路由器,它呢实际上就是用的电磁波作为他的物理层,物理层呢本质上就是,有可能用的是双绞线,光纤、无线WIFI,他们通信标准,因为物理结构不一样嘛,那么通信标准也肯定不一样。物理层一般考虑的就是设备和设备之间传输速率、传输距离,包括抗干扰性等等,其中呢集线器就工作物理层 。集线器是一个什么设备呢,大家都知道我们的数据在经过长距离传输的时候,信号是会衰减的,信号一旦衰减了,就直接决定了 ,无论你以哪种物理层通信作为我们基本的通信方式,当你实际上在做通信的时候,长距离传输一定会衰减,衰减了就决定了这个信号传不远,可事实上呢,当今的互联网是全球性的,你坐在家里,几秒钟你的信息就直接发送到了美国,这就是信息能穿多远呢,其实有一个设备就叫做集线器,集线器最主要的工作就是信号放大,也就是当你的信号很弱的时候,当你经过中间的某一个集线器的时候,它会把你的信号放大,相当于你不强了,就给你放大一下。
》还有呢就是数据链路层:硬件呢负责光电信号,数据链路层呢主要负责设备和设备之间数据帧的传送。后面在讲的时候,不同层的数据有不同的叫法,大家都懂,这就是大家都是二进制,只不过在不同层有不同的名称,数据链路层呢,我们一般都用数据帧,它利用帧的转发与识别。比如说,我们在网卡的驱动层面上,它能帮我们去编写数据链路层的代码,包括我们在局域网当中进行帧同步,负责局域网当中帧发送,数据帧的碰撞检测等,包括冲突了就会给我们重发,这东西其实就是我们数据链路层这个软件配合网卡做的。网卡这个硬件设备就属于物理层,而我们控制网卡的驱动程序它是软件层,对应的就是数据链路层。当然数据链路层是一种叫法,因为你也知道,不同的硬件也就决定了不同的驱动,有的网卡叫做有线,有的网卡叫做无线,所以不同的网卡对应的,不同的数据链路层代码逻辑是不一样的,这就是底层的差异嘛。所以呢,像我们底层的那些网络知识呢,局域网当中,以太网、令牌环网、无线LAN各种各样的标准。其中有一个设备叫做交换机工作在数据链路层的。交换机呢主要是用来局域网当中数据帧转发的,这里呢还有很多的问题,我们后面讲的时候再说
》再下来就是网络层:网络层呢,主要负责我们对应的一个叫做地址管理,还有路由选择的。我们刚刚说了,如果长距离传输的时候,我们面临的一个是效率的问题、一个是可靠性的问题,还有一个就是你怎么找到对方,所以我们在软件层面上呢,定了一套我们IP地址的方式,然后呢,在我们的路由器当中形成路由表,通过路由转发的方式,帮我们把数据转发,找到局域网中的主机。同学们,记住了,唐三藏从长安城出发,在地球上能找到西天并且见到如来佛祖,一个人从千里之外找到另外一个人,就决定了,一个数据包他也一定能过经过大量的数据转发找到目标主机,这是能做到的,只不过确实比较复杂。所以我们对应的路由器就工作在这一层,像家里连网的时候, 连接你家里的路由器,这东西就是帮你上外网的。
》再下来呢还有传输层:传输层通常是在两台主机之间,比如说A主机和B主机,他们通过某些协议来长距离传输,传输层呢就重点帮我们去解决可靠性问题,比如说效率的问题,实在传输层帮我们解决的;
》再下来呢就是我们的应用层:应用层呢是负责程序见沟通, 比如我们的电子邮件、FTP等协议,我们后面写的代码其实都是应用层的代码。
》这些呢就是我们的网络层状结构,这些与你们相关的,肉眼可见,在家里知道还是不知道,有两个设备你要知道,有一个设备叫做,猫,也叫做调制解调器,一般在家里面呢可能是根路由器落在一起,也有可能是在你们家中的网络入口处,若你家里事无线网的话就会有,猫,这么一个设备;第个设备呢就是路由器,路由器好理解,同学们上网连手机是要拿路由器的。,猫,这个设备做什么的呢,他其实是工作在物理层的,它跟那个集线器还不一样,它是为了支持长距离传输,负责信号的发大的。而调制解调器,它主要是用来进行我们的物理层的数据的一个转化的。我们通信领域呢,一般在网络里传输和家里传输,二进制的编码格式是不一样的,有一种信号叫做数字信号,有一种信号叫做模拟型号,所以我们的猫呢主要是信号转模拟,模拟转信号。一个是有利于我们在局域网内通信的,一个是比较利于长距离转发的。所以当你从外网进入的时候呢,对应的信息是要经过转发,经过转发到你的路由器被你所识别到。
我们要讲三层概念,第一层封装、解包概念,另外一层呢,数据包以及网络协议栈整体的包括它的角色定位,数据包它怎么去走的,宏观的轮廓给大家一说。第三点呢,我们要认识两个地址,一个是MAC地址,还有一个就是IP地址。我们临近下课的时候讲了网络分层的时候,我们TCP/IP分层,分为物理层、数据链路层、网络层、传输层、应用层,每一层呢都有自己对应的协议,当然OSI也规定了,他自己定出来的七种模型,这七种模型确实划分的很好,但是呢,让我们实际上落地的时候呢,是不太OK的,原因是有些划分的层次在操作系统层面上想完成是很难去做的,包括你用户层想去把这些全写了也是非常费事的,实际上我们在讲的时候呢,是按四层来说的。其中呢OSI模型是左边的,TCP/IP是右侧的。最底层呢,我们都叫做物理层,再上面呢我们叫做数据链路层,其实呢也有人叫做网卡层,我们暂时不管。再下来呢,我们叫做IP层等对应的就是网络层,还有呢就是传输层对应的就是传输层;而上面上会话、表示、应用,而我们TCP/IP实现里面统称为应用层。而应用层的协议非常多,包括http、https,包括我们FTPS等很多,你可以理解成应用层协议和上层用户等基本使用情况有很大的关系。我们的硬件和我们的数据链路层其实是属于我们的驱动和网络网卡这样的硬件设备之间的关系,再下面呢,我们把TCP/IP这两层协议其实是属于操作系统帮我们去完成的。再下来我们经常听说的http、https等属于应用层对应的协议,所以对我们来讲呢,这一点我们要搞清楚。还有呢,我们要想清楚,一般呢,在我们的实际应用当中呢,物理层我们实际上考虑的比较少,所以一般我们把网络协议层称为TCP/IP四层协议。
》一般而言
对于一台主机, 它的操作系统内核实现了从传输层到物理层的内容;(其实准确一点的说法呢,操作系统实现了,从我们的传输层到IP层之间的内容,然后呢,下两层硬件就不说了。数据链路层呢帮我们解决驱动硬件在局域网当中通信的一个功能。)
对于一台路由器, 它实现了从网络层到物理层;(我们路由器不仅是IP转发的功能了,IP甚至有了自己组建局域网,还能够帮我们提供应用层的服务都有可能哈。所以我们每一层硬件呢对应的,在它1本层当中都有自己的核心功能哈。)
对于一台交换机, 它实现了从数据链路层到物理层;
对于集线器, 它只实现了物理层;
网络分层和数据包封装和解包概念
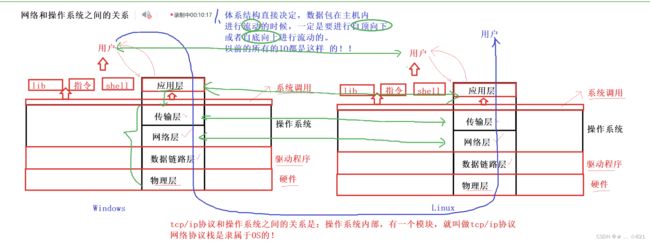
一般呢,在我们的网络当中,记住了,我们首先回答同学们一个问题,首先回答网络和我们操作系统之间的关系。我们经常会说网络如何如何,那它和我们操作系统有什么关系呢?下面嗯给大家画一张图,首先呢,我们现在知道网络其实是一个层状结构,我们把物理层也带上吧,其中最下面呢就是物理层,再上面数据链路层;在上面就是网络层;在上面呢就是传输层;在上面就是应用层。那么其中对我们来讲呢,你给我说的这些软件分层的这些概念,和我们的操作系统是什么关系呢?
》我们操作系统也有自己的层状结构,一层是驱动程序,然后最下面一层呢叫做硬件。我们真正在内核当中实现的是传输层和网络层,而数据链路层是属于驱动程序的范畴,而物理层其实是属于硬件级别的。我们曾经也说过,操作系统他对上呢,对于任何人来讲要使用我们对应的,你想想,最终来回发数据不就是用网卡嘛,网卡不就是一个硬件嘛,你要访问硬件你就必须得贯穿操作系统,必须得贯穿操作系统什么意思呢,意思很简单,你必须得贯穿操作系统,没有所谓的操作系统,对不起,你不能直接访问硬件,因为操作系统是硬件的管理者,所以你必须贯穿操作系统,那么其中我们操作系统必须对上提供一个概念,叫做系统调用,所以呢,以前我们学习各种创建进程、线程、信号,包括我们的基础IO还有一些其他的接口呢,实际上最终都叫做系统调用,用来在系统层面上做相关工作。而同样的吗我们对应的有一层叫做应用层,应用层本来就是一层软件,它本质上一定是在我们的系统调用之上做的系统调用来完成对应的工作。所以呢,一个问题,网络和操作系统,严格意义上来讲,TCP/IP协议和我们操作系统之间的关系是:操作系统内部有一个模块,就叫做TCP/IP协议。那么换句话说呢,网络协议栈是隶属于我们操作系统的,这一点我们要注意。
》我们曾经也讲过,在操作系统在操作系统再往上还有什么呢, 是不是有一些库、编写的程序、shell外壳程序等,所以再往上是谁呢,那就是用户了。所以经常在系统部分说,我们有各种库、程序、指令、shell,再上面就是我们的用户了,用户可以使用这些功能来完成对操作系统的访问。同样的,我们应用层本质上也是和我们曾经的所谓的lib、指令、shell一样,也是需要被普通用户所使用的。所以用户是用来,使用应用层,来完成他自己的数据的转发功能,这就是我们操作系统和网络协议栈之间对应的关系。
》那么其中对我们来讲呢,我们更重要的是,网络协议隶属于操作系统,同时,它也是一套标准,它的这一套标准必须要我们每一个操作系统都必须遵守,包括你的手机。所以对我们来讲,未来可能是windows、linux等,但无论你是什么操作系统,你的底层一定要用你自己的方式来将我们的网络协议栈来实现起来。所以我们在这里如果有多台主机的话,他们要想通信,比如说一个是Windows,另一个是Linux,两台主机完成通信,一定是由用户发起,然后呢使用我们的应用层协议,这个应用层协议可以自己写,也可以用现成的,然后贯穿我们整个网络协议栈自顶向下哈,到我们的物理层,然后呢,再经过网络路由转发,被对方主机的物理层收到,交到对方的链路层, 依次上面的每一层提交,最后就达到了,对方的用户。所以此时呢,我们一定要清楚的是,网络的最终流向呢,一定是自顶向下,或者自底向上的。为什么要自底向下呢,因为我们的计算机最终发数据也要通过硬件去转发,用户层的数据无法直接抵达硬件,必须得贯穿操作系统,而你的网络协议栈隶属于操作系统,所以你必须得自顶向下交付给硬件,这是其一;其二,我为什么又要自底向上交付呢,原因很简单,因为发数据的时候,大部分的数据都是用户给用户的,所以你要给用户,你底层的硬件也没办法直接给用户,你必须贯穿我们的操作系统,以及对应的协议栈来讲数据进行交付。所以同学们,那**我们的体系结构直接决定,数据包在主机内部进行流动的时候,一定要进行自顶向下,或者自底向上流动的!**这一点我们并不陌生,为什么呢?因为,以前的所有的IO过程都是这样的!比如说你写磁盘,你要把数据写到磁盘的时候,不也是从用户层,再通过系统调用接口把数据交给操作系统,操作系统再通过自己对数据进行缓存,定期把数据经过我们对应的操作系统内部,把数据刷新到外设,刷新到磁盘上,那你读取文件的时候,本质上也是把磁盘上的数据再拿到操作系统内部,再通过系统调用接口在内部让用户拿到,所以我们以前所有的行为,其实全部都遵守这里的所谓的从上到下,自底向上这样的规则,只不过我们以前从来没有提过罢了。这是我们今天要讲的第一点。所以,同学们,我们要对他进行重新想象,这个过程我们并不陌生,以前我们经常说,同学你把数据写到显示器上,算不算你访问硬件呢,你们说算,那我们访问硬件的话,其中我要不要自己访问呢,是不是自己写到硬件上呢,同学们说不是,那我们怎么访问呢,我们说,操作系统是硬件的管理者,我们必须得自顶向下的把数据贯穿我们的操作系统,同学们,那时候我们都已经在讲自顶向下了,当我们读取的时候也是一样的。所以网络当中他要自顶向下也是很正常的,自底向上更加正常,因为这就是计算机它本身的工作方式,这是第一点。第二点,上次我们谈过一个问题,问题是这样的,我们是说过,网络协议栈是分层的,比如说我今天给同学们打电话的时候,给你打电话,比如说我给手机说话,你从你手机听到说话,那我们是不是问了一个问题,同学们,你们认不认为是在给你直接通信呢,同学们,说是的,你在给我直接通信,然后我说,实际上我们并没有直接通信,而是我把我说的话给了手机,我的手机把对应的数据交给了你的手机,你的手机把数据转化之后才听到我的声音的。但是呢,我们上面阐述了一个结论,这些细节作为平民老百姓压根就不关心,什么意思呢?我们上面产生的第二个结论就是,同层协议都认为自己在和对方直接通信。什么意思呢,意思就是说这里对应的用户,自己认为在和对方的用户直接通信,那这里的应用层协议呢,它呢,认为自己在和对方的应用层在直接通信,这里的传输层呢,认为在和对方的传输层通信;这里的网络层呢,认为自己在和对方的网络层通信,以此类推。所以同层协议,都认为自己在和对方直接通信。我们对应的呢,可以认为,这里的应用层呢完全不关心底层怎么做,好像我们打电话的时候,从来不关心电话是怎么把消息发到你那里的。上层协议呢永远只是知道我调用什么接口,能拿到什么结果。就好比我知道,我呢给手机按下号码,这叫做我们称之为给手机传某些参数,然后再点击发送,那么就可以去拨打电话了,它里面的工作细节我们从来不关心,我们知道跟我们没关系,每一层呢,都认为自己在和对方直接通信。
》第三点,我们要来进行重谈协议了,你说的挺好的,反正就是第二点我还得慢慢体会一下,其实第一点绝对能理解,但第二点不一定,第二点告诉你同层协议都认为自己在和对方直接通信,这个呢是要需要一定程度的想象力的, 也就是说,同层协议是忽略底层协议的一些细节的,我呢知道调用你底层的一些方法,我就能得到什么样的结果,但是你的工作细节我不关心,但是我呢,比如说我是传输层,我的任务就是把我的数据层层交给对方的传输层 ,应用层呢就是把它的数据再交给对方的应用层,就跟快递员一样,我们以快递员为例,你在网上跟对方的店家,比如说店家是卖电脑配件的,你买了一个鼠标,你此时在店家下了单,你在通信时是跟店家沟通的,你沟通完之后呢,底下的细节你是不关心的,因为你知道你沟通完,你把钱付了,对应的卖家一定会把东西发过来的,然后呢,卖家跟你沟通了, 然后此时调用了底层的接口,就是快递员填了一个单子,把东西邮给你,邮给你之后呢,其中你是不关心底层快递员是怎么过来的,你不关心,你只关系什么时候给我送到,你商品出现任何问题,你永远都不会找快递员而是直接会去找卖家,因为卖家这个人和你是同层的,这点要注意,第二点需要大家慢慢体会。我们写写代码就能理解了。
》第二个我们说协议的时候,说过一句话,协议是一种约定,什么是约定呢,就是双方约定好,某一种行为代表什么含义,比如说电话响一次代表的是报平安,电话响两次是没钱了, 响三次的话你再接,这叫做约定。同学们,那这里就有一个问题,所谓的约定,那么有没有成本呢?也就是说,**在计算机的视角如何看待协议呢?**也就是,你两个人之间的约定有没有成本呢?两台计算机之间的约定有没有成本呢?以及两台计算机你说约定好就约定好,那么两台计算机的约定是谁来约定的?最后这个约定是怎么体现出来的呢,你不能光拿嘴说是由约定的,你得有东西来证明它。
》下面呢给大家举一个例子,同学们,有没有可能你会忘记约定呢?我们得有一个人,后来忘了,生活当中处处存在忘事的人,当然明天答应给人送报告但是忘了等等,你做的约定有可能忘嘛?答案是:有可能。还有什么,约定既然能够被人遗忘,说明约定一定要被人记住,它是有成本的,什么意思呢,你自己就得把曾经双方的约定记下来,同学们,约定什么了,时间、地点、人物、事情等等,本质上人类世界里的约定占你的大脑的存储空间的,不管是永久的还是临时的,反正会占用你的空间,那么我们双发在大脑里面 构建了一个约定的数据结构来进行我们约定的处理,只有我们双方脑子里都记下来我们曾经的约定的细节,我们最后才能把事情做成,这是人,计算机呢,它如何去看待所谓的协议呢?记住了,协议呢实际上在计算机当中,我们双方能够根据协议去办事,就一定是,1. 体现在代码逻辑上;2.体现在数据上。
》给大家举一个例子,你们经常呢,有网购的经历,比如说呢,今天就买了一个键盘,买了一个键盘,快递员会不会千里迢迢到你的楼下给你打电话,然后呢当东西到了给你打电话,你下了楼之后,快递员给你把键盘给你,会不会呢,你就是买了一个键盘,快递员就拿了一个键盘给你,现实生活当中是不是这样子的呢?并不是!实际上当你收到了东西的时候,你是收到了一个包裹,**你和卖家沟通好要买一个键盘,实际上快递员不是光光的给你一个键盘,而是一个包裹,包裹里面是有键盘的。**那么同学们,对我们来讲呢,我们就要一个键盘,但它实际上给我的是一个包裹。说明我要一个键盘,实际上,它多给了我一些东西,我要的是键盘,但实际上当我拿出来的时候,**多给我了一些东西,多给我们什么呢?多给了一个盒子,当然今天的盒子不重要,因为所有的包裹都有盒子,但是所有的包裹上总是会贴一个东西,叫做快递单。那么换句话说呢,我们就想要一个键盘,但实际上当我们收到东西的时候,会比我期望的要的东西会多一些,多出来的东西呢就是我们的快递单。那么这个快递单上呢,其中快递单上呢填的是一些数据,这些数据有什么用呢?这些数据写着,发货人是谁、发货人的联系方式等等,这个数据呢,这个快递单呢,实际上,当你收到这个快递时,你压根就不关心,但是为什么还要贴上纸呢?答案是:快递单子不是给你用的,是给快递公司用的,这个单子呢其实给我们起的是路由的功能,或者呢是帮我们定位你这个人的功能 。其中我们把快递单子多出来的数据,那么它就叫做快递公司和快递点以及快递小哥之间的协议!**换句话说呢,我们的快递单呢其中是让快递公司来进行,和快递点之间和快递小哥之间定的协议。包裹当中的各种细节呢不是给你看的,而是给别人看的。所以对我们来讲呢,其中上面我们对应的快递单子呢其实是包裹在我自己的一个键盘盒子上多出来的一些东西。那么这件事情说明什么呢?说明我们告诉大家,实际上你在网上买东西的时候,你就想买一个键盘,但是你会多出来一部分东西,多出来的这部分东西是一部分数据,这部分数据就是我们为了维护或者干脆就叫做快递公司定制的协议字段。每个字段是什么意思,同学们,一个不认识字的快递小哥,能做快递员吗?答案是:不能,它上面的字都不认识,上面单子上派发给谁,客户叫什么名字呀,它可能都做不到。所以,同学们,这里一定要注意的点叫做,我们快递单上的数据呢,他就是快递公司和快递点,快递点和快递小哥之间定的协议。
》所以这里我们想说一个,为了维护协议,一定要在被传输的数据上,新增其他数据,这个新增的其他数据,叫做协议数据。我们要注意,任何一个这里对应的,只要他有协议,必须得新增自己的协议数据。也就是说,我们可以看到,协议一定会体现在某种意义的数据上,这是第一个。第二个,快递公司根据你的协议,它一定是要能够,根据数据有不同的动作的,什么叫做不同的动作呢,就是根据不同的协议,要能够派发我们的包裹,将包裹从北京邮递到上海等等,不管怎样,它一定要根据包裹上的字段完成对应的动作。这个呢其实体现在代码逻辑上,举个例子,同样的快递单,大家比如说,采用顺丰或者菜鸟,他们采用的是同一套物流系统,所以呢,不管是谁填的单子,中间哪一个物流公司它都能物流,其中对我们来讲,为什么呢,因为他们能够根据协议上的数据来执行公司内部的物流策略,然后完成数据包的转发,这就叫做代码逻辑上。当然代码逻辑上的体现,暂时还没有这个感觉,你可以简单理解成,快递小哥拿着你这个快递,他一定给你打电弧,而不是给其他人打电话,为什么呢,因为快递小哥,根据单子上的数据,决定了他的动作就是给你打电话。所以同学们,我想告诉大家的最终结论呢,就说,我们的协议呢,一定在传输的数据上新增其他数据。这个多出来的,就叫做协议数据。

》同学们,再继续,你刚刚说的,1.同层协议都在认为直接和对方通信;2.体系结构决定,数据在流动时,一定是自顶向下,或者自底向上流动。好的,既然同层协议都认为自己在和对方通信,那么这就直接决定了,每一层都要有自己的协议。就相当于什么呢,同层协议呢,都认为自己在和对方通信,我们两个,不管你是在网络层还是什么的,我的网络层和对方网络层通信,两个网络层开口说话了,然后呢,一个网络层说,我给你发了消息,你注意一下。其中我这个网络层会不会关心我上层是什么,下层是什么呢?不会关心,我只能为我在和对方的网络层通信。所以,同学们,同层协议呢,要直接通信不是拿嘴来说的,而是同层的协议呢,每一层都要有自己的一套协议规范。那么我们可以得到的结论有三个了,1.数据要进行流动,方向是自顶向下或者自底向上,这是其一;2.同层协议呢,都认为自己在和对方协议,直接通信,所以要有自己的协议;3.一定要在被传输的数据上新增其他数据。
》我又不懂,我根据你这3个结论又能得出什么结论呢?所以我们的数据呢,它在进行自顶向下,自底向上进行转发的时候,这里可以是向下交付,也可以向上交付。现在,我们有两套套完整的协议,就相当于是两台主机了。假如,我们有一个数据叫做“你好”,当我们要发送一个 你好 的时候,首先,从上面的结论我们知道,这个 你好 的信息必须要被对方,必须得自顶向下交付到自己的底层,这是其一;其二呢,交付给底层,要一层一层过,而每一层都认为自己在和对方通信,每一层都有自己的协议,而协议呢是要在自己要传输的数据上,新增协议数据,所以,‘你好’在从用户这里产生,到应用层的时候一定要添加应用层的一部分协议数据,然后当我们这一部分协议数据呢,经过路由转发,到了我们对方的应用层的时候,对方应用层也就能看到对方的应用层添加的协议报头。就好比,我们作为人来讲,是不可能跟一条狗或者一条猪做约定的,因为我们是属于不同的层级,大家所属的层级不同呢,语言上也就没有共识,它也听不懂我们在说什么,所以无法建立我们的协议字段。当我们属于同层的时候,我把我的数据交给对方,其中呢,因为我是把我的数据交给了你,我不仅仅是把数据交给了你,我们为了要让数据被你所识别,被你所处理,我们还要在被传输的“你好”数据上一定要新增一些其他数据,这个数据,我们到了应用层加进来,应用层要继续调用系统接口继续向下交付,为什么一定要继续向下交付呢?原因很简单,因为体积结构规定了他必须得自顶向下交付,每一层协议都要有自己的协议,都要保证自己在和同层进行通信,所以每一层都要维护自己的协议,都要添加自己的协议的信息。所以到了我们的传输层之后,传输层说,知道了,我要给对方发消息,我要添加我的一个协议有效数据,添加完之后呢,传输层他也不管,它只知道我把数据呢调用接口交给下一层,下一层就能够直接收到,数据被对方是怎么转发或接收的我不管,我传输层在认为自己和对方直接通信,所以我自己填了自己的协议字段之后,同层协议就能通过,要收到的这部分数据呢,多出来的协议字段来决定对方传输层收到的是什么信息。同样的传输层还得继续向下交付,此时我们又必须得添加网络层的多出来的字段,然后又向下交付给数据链路层,添加对应的字段,此时有交付到了硬件,硬件我们不考虑,然后就到了对方的物理层,被对方收到,对方收到,然后将数据向上交付到数据链路层,到了数据链路层呢,当他收到数据时他收到的数据其实是上面几层要看的协议数据,也就是你实际收到的数据比你期望收到的数据要多,就好比你要收到的键盘里面会在快递包裹里面多一张快递信息。你数据链路层此时收到了数据,你将上面几层要的协议数据提出来,这是对方给我发的消息,就好比,当你拿到快递单子的时候,快递单的细节你其实不关心,但是呢,你得确定这个快递单子是不是发给你的,所以你首先要读取快递单子,然后发现上面写的是你的名字,那这就是我的快递,你也要处理这里多出来的协议字段,处理完之后,此时你要做的就是把数据向上交付,为什么你要向上交付呢,原因是体系结构规定的,因为我们现在正在完成的是用户和用户之间的通信,所以你从上到下把数据给我,传送到了对方,对方必须把数据向上交付,因为对方必须得吧数据交给用户,这是由体系结构决定的。所以交付给网络层后,他要确定是不是发给我的,所以他收到的信息是上面几层要的协议数据,他要的是自己对方网络层发的协议报头,然后他会去掉自己要的报头,就好比你发现包裹是你的,然后你就把包裹拆了,拿出自己要的,拿出来之后呢,收到的数据继续向上交付,传输层拿到对方传输层添加的协议字段,我知道了,然后再把自己的报头拎出来,然后将其余数据继续向上交付,此时应用层知道了,我是直接和对方应用层通信的,因为我们是同层都认为自己在和对方通信,所以我们每一层都要有自己的协议,两个应用层之间定好的协议数据拿出来自己要,多出来的数据自底向上继续交付。所以用户发的是“你好”,对方收到的就是你“你好”。用户发的“你好”,然后交给应用层,添加自己的协议数据,然后对方应用层收到的就是同层的协议数据以及要交付的数据,以此类推。
》那么其中,我们把多出来的,新增的协议数据,在我们每一层协议交给下一层之前,添加上自己当前协议数据的这部分内容,即我们把每一层要交付给下一层数据,给他添加上本层“多出来的协议数据”(不太严谨的说法)拼接到原始数据的开头,那么此时我们把这部分多出来的数据,我们可以称之为“报头”,所以我们协议当中,报头就是用来描述某一层协议的相关字段的,那么其中每一层都要有自己的协议,每一层都有属于他当前层的报头结构,就好比同学们,你收到的快递单子,单子上面写的东西,他其实就是对应的报头,每一层协议都有自己的报头,所以我们在自顶向下交付的时候,每一层协议都要添加自己的报头字段,那么其中我们把这个动作叫做封装的过程。也就是说我们封装。也就是添加报头的过程,就是对数据包进行封装的过程,然么其中当我们的数据到了对方层,在进行把他解出来,自底向上交付的过程,我们同层都是把自己的报头去掉交给上层,我们这个就叫做解包的过程。
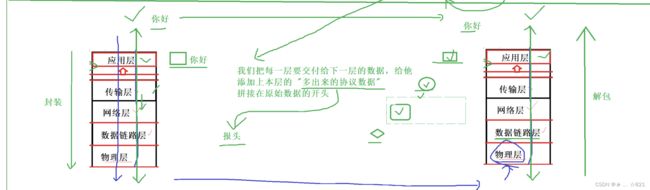
》我们就根据计算机的体系结构帮助大家理解,所以能不能理解一定要自顶向下交付呢和自底向上交呢,原因是体系结构决定的,你要用网络通信,你必须得把应用层交给底层,因为只有硬件才能收发数据,这是一定的,这是第一。第二呢,每一层都认为自己在和对方层直接通信,通信呢,我们的本质是,通信的双方进行添加报头,所以每一层都要有自己的协议,背后的含义就是每一层协议都有自己的报头,其中自顶向下交付的时候一定要不断添加报头,然后到了对方的时候,要不断的自底向上不断的把报头再拆出来,这就是我们的一个 “封装” 和 “解包” 的概念。
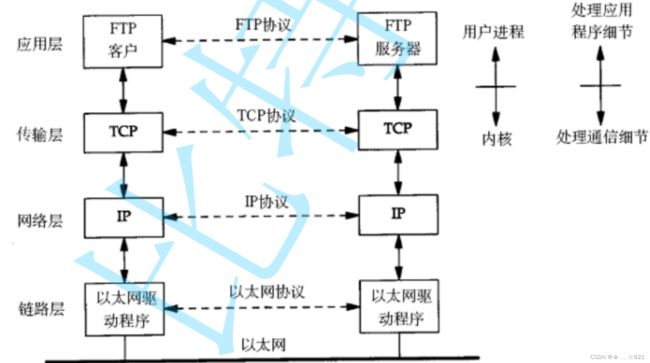
下面呢有两个协议栈,以后当你看到有两个协议栈的时候,你首先要想到的什么,这两个协议栈,一套操作系统有一套协议栈,这是两台主机,你要想到这一点,这是其一;其二呢,我们就是要考虑到一点呢,就是双方进行我们所对应的通信的时候,我们左侧和右侧是两台主机,这两台主机之间呢,通过协议栈来进行我们所对应的通信,那么其中我们把下三层(传输层、网络层、数据链路层)是隶属于操作系统的,而我们应用层称之为用户进程,它呢是属于用户的,我们称之为应用层,至于处理通信细节我们会每一层每一层去讲。那么其中对我们来讲,我们就看到有两台主机之间通过局域网联通,那么此时又有一个小问题需要和大家确认一下,这个问题问一下吧,如果两台主机属于同一个局域网,那么这两台主机能够直接通信吗??告诉大家:同一个局域网内的两台主机是可以直接通信的。给大家讲一个故事,以前写完一个代码在一间房间里,代码的测试就可以在局域网一起测试了,这是其一;其二不知道大家以前有没有打过竞技类游戏,有些游戏需要联网,比如CS,只要同一个网段里面你就可以直接在一起玩了。其实我们在同一个局域网就能够直接通信了,学校不让上网怎么办呢,没关系一栋楼的少年们有自己的娱乐方式,电脑一连,反正大家都在局域网,互相就可以通信了。首先我们要告诉大家,如果在同一个局域网当中,我们两台的主机是可以通信的。第二个,我们其中最常见的所谓的局域网呢,有一种局域网称之为叫做以太网,它是一种局域网的标准,当然它里面的一些工作细节和工作原理呢后面会说,但现在我就告诉大家,它名字叫做以太网。你要清楚一点的就是,在局域网当中所有的主机能通信,本质上也是要有局域网的一套标准的,这个最常见的标准就是以太网,还有呢就是令牌环网或者无线LAN,我们拿手机在局域网当中就属于无线LAN,不重要,以太网呢是我们局域网当中的一套标准。
》这个以太网呢,给大家今天不谈它的一个就是内容,严格上他是怎么工作的我们还谈不了,稍后会给大家谈一点点。但是呢我想给大家说的是,以太网这个东西呢,它的名字就叫做以太网,有人说令牌环网这个东西我也不太懂,然后无线LAN就更不懂了,但是以太网呢我们首先不是想他是谁怎么通信的,我总是觉得他的名字特别奇怪,就是说他对我这个网为什么,叫做以太网呢。其实是有一个故事在露面的。在20世纪初,在物理学界有一个特别重要的争论,争论是什么呢,任何事物的传播是要有介质的,就好比我们能听到对方的声音,本质上是空气帮我们传播了声音。所以在任何地方呢,声音的传播是需要有介质的,所以很多物理学家呢就想,既然所有的传播都需要介质,那么光的传播是更加需要有介质的,所以这个时候呢,科学家呢有一个问题,太阳和地球之间有段是真空的,那么是怎么走到地球的呢,根据正常思维,不是说任何事物的传播都是需要有介质嘛,所以有科学家猜想说,我们看到的宇宙是真空的,但是不一定是真空的,只不过填充了某些物质没有被我们发现,只是我们认为看不到罢了。所以当时就有人猜想,宇宙当中是充满一种物质的,个这个物质呢取名叫做 “以太”。最后有科学家想要论证是否存在以太这个物质的,本来要做几个月,结果做了两三天就做不下去了,因为所有现象表示这个物质并不存在。所以这个事情相当于被证伪了,也就是并不存在。后来就称为物理学界的一个笑话,因为当时科学家对此观点保持肯定,认为肯定存在以太,而且一旦以太被证实,我们物理学所有的理论全部都落地了。反正物理一直存在的笑话就是以太的存在。在五六十年代的时候,就有一大批网络工程师开始局域网通信了,当开始对应的通信的时候,构建了一个局域网能够通信,可是这些工程师工程师在想给他取一个什么名字呢,不是物理学界有一个笑话嘛,那么我们就致敬一下吧,所以命名程以太网叫法。所以以太网名字由来还是值得一提的。
》所以以太网是一种局域网的通信标准,这是其一;其二呢,这里有两台主机可以通过以太网来进行通信,以太网的工作方式我们待会儿给大家提一下。但是我们今天不在于细节上,而是能不能通信。所以我们数据在流动的时候,根据我们刚刚所讲,通过体系结构的学习呢,数据要发送到对方的主机,一定要自顶向下交付,那么数据被收到的时候,一定要自底向上进行交付,那么其中同层协议之间要有协议字段,协议就是在原始发的数据之上多出来的一部分数据,一定要进行封装,到达对方之后,一定要进行我们对应的解包,那么其中对我们来讲呢,这就叫做封装和解包这样的概念。那么其中呢,我们这就叫做局域网通信。在我们局域网通信呢,就要稍微谈一谈局域网通信的原理。我们下面来谈一谈一个原理,稍微说一下。
》我们要引入一个概念,局域网通信,尤其是以太网局域网通信,它的通信原理是什么呢,比如说,老师和同学在一间教室上课,突然在班上挑一个人,叫张三站起来,你为什么上次的作业为什么没完成?让张三这名学生回答问题的时候,你们听到了吗?听到了,问题是,你们为什么不站起来呢,有人说,叫的又不是我,我站起来干什么呢。所以张三颤颤巍巍的站起来,解释说作业完了,那么此时张三和老师说话的时候,请问你听到了吗?答案是:你也听到了。其中所有的谈话你都听到了,但是你为什么不处理呢?原因很简单,因为他们的谈话不是发给你的,但是当老师根张三进行一次互相通信的时候,老师和张三认不认为他们在单独通信呢?也就是说老师把张三叫起来,两个人在不断说话的时候,张三也在回复,他们两个在通信的时候认不认为在教室里面单独通信呢?答案是:认为。但是他们两在单独沟通的时候,旁边有一大群的吃瓜群众,其实也能够听到这个声音,这就叫做局域网通信的原理。换句话说。在刚刚讲的例子当中呢,其实有几个细节要一个个说一下,第一个细节叫做,在教室里面呢,一定要有名字,要不然没有唯一性的标识的话,怎么能让张三站起来呢,同时其他的同学怎么能证明,这个老师叫的时候不是叫的自己呢。所以同学们正如我们在教室里面每一个人都有一个唯一的名字一般,即每一台主机都要有唯一的标识,那么我们把每台主机上唯一的标识叫做该主机上对应的MAC地址。也就是说每一台主机上呢,对应的至少要有一个MAC地址,这个MAC地址呢实际上是叫我们的网卡地址,也就是我们对应的机器电脑在出产的时候配套的装有网卡,网卡上面呢已经内嵌了该网卡所对应的MAC地址,这个MAC地址主要工作在局域网,用来在局域网当中饭标定主机的唯一性,这是第一;第二,第二天又来教室和同学们愉快的上课,在正在上课的时候,突然喊,张三昨天叫你做的作业,今天怎么又不做,当叫张三的同时,李四王五都在大声的沟通,赵六和钱七打起来了等等,我们的课堂秩序非常的混乱,此时叫起张三的时候,张三此时压根就听不到老师说的话,那么其中我们在封闭的环境当中呢,任何一个人在说一句话的时候,比如说,张三在说一句话的时候,被同时其他的同学也能听到,那么其他同学不说话的时候,其他同学能正常听到老师讲的话,但是所有人都在说话的时候,一个接收到的信息是会互相干扰的,所以我们一般在局域网当中任何一台主机在任何时刻都可以说话,就好比在课间休息的时候,在教室里面,任何时刻,它都可以说话。那么其中任何一个人,在任何时刻,都可以随时发消息。就好比在教室里面,每一个同学都可以给对方给任何一个人说话 ,那么此时我们把这种局域网称作碰撞领域的概念。也就是局域网内的信息可能会互相干扰,有碰撞域的话就无法准确的听到对应的消息。就好比上课期间,秩序良好的时候,老师和张三沟通的时候,同学们是不说话的,张三在跟我说的时候,其他同学也是不说话的,那么我跟张三认为是成功沟通,可以想像一下小学、初中应该会有一个早上6、7点你们会晨读,当你在早读的时候,你在读的时候,旁边同学也在读,你在外面听到的声音就是乌拉乌拉一大片,压根就不知道在念什么,这叫做信息发生了碰撞,那么其中对我们来讲呢,在任何一个局域网当中,任何一台主机都可以直接向对方发消息,一旦发消息此时信息会互相干扰,我们就称之为碰撞域,一旦有了碰撞域,任何人都会发,这个时候就出问题了, 同一个局域网里,任何主机想要通信,那是不可能的,因为我已发对方也发,信息就干扰了,怎么办呢,没关系,所以呢我们就有一个叫做,同学们可以理解成是什么呢,对我们来讲呢,我们的工作方案就是这种,基于概率去碰撞,然后向局域网去发消息。但是呢每一台主机呢要能够识别到局域网当中是碰撞的,发生了碰撞就好比我今天在跟张三说话,张三说的时候也正在给王五说,王五也在跟赵六说等等,当我发现想说的时候,突然发现别人也在说话,那我就不说话,让别人说完,每一个人都执行别人的原则,那么其中我们识别发生了碰撞(碰撞检测),我呢看到别人说话,我就不说话了,那么此时我们做的动作就叫做碰撞避免,听到没有人说话的时候,再说。我们任何时刻都只能有一个人在说,两个以上的人说话,信息干扰了,那么就要执行信号碰撞检测和碰撞避免,这就是局域网通信的原理,。首先我们要清楚,在局域网当中两台主机是可以直接通信的,所以每一台主机在局域网当中有唯一的MAC地址,唯一的MAC地址呢,所有的主机就可以根据局域网向指定主机发消息了,这就叫做局域网通信的概念。刚刚讲的这个呢,我们把原理一说,到后面再给大家讲MAC帧的细节的时候再谈,总之只要能理解将来以太网是能够通信的就可以了。
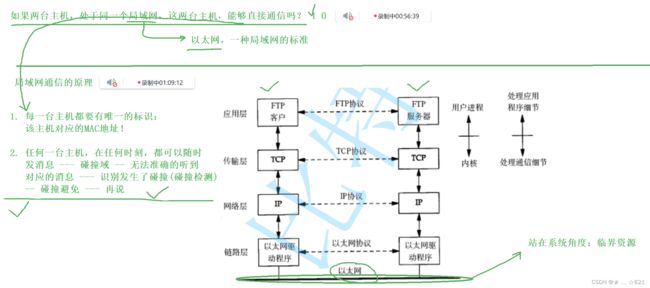
》所以两台主机之间要进行互相通信,第一它要贯穿我们所谓的协议栈,这个是由体系结构决定的,所有的数据都必须得从上到下,从下到上,对于磁盘读取是这样的,任何硬件都是这样的,不仅仅是网络。其二呢,我们为了能够正常通信,我们每一层都要封装它的一个报头,为什么每一层要报头呢,因为每一层协议都和对方的同层协议定了协议,定了协议就得在沟通的时候多携带一些我们多出来的数据,这是第二个;第三个呢,两台在局域网当中通信的主机是可以直接通信的,当进行通信的时候,自顶向下交付,要完成封装,在局域网当中可以把数据交付给对方,在局域网当中呢,一、可以直接交付;二、工作原理呢,同上课一样,在一间教室上课呢,A给B说话能够听到,B给A说话能够听到,只要大家不同时说就可以了。
》给大家再延伸一步,我们再换一个视角。为什么两台主机不能同时向网络里面发呢?其实很简单,你再发的同时,别人也在发,这在硬件上都是光电信号,光电信号之间相互干扰了,互相干扰的时候呢,其中,你在发的时候别人也在发,同学们,你在发的时候,别人也能发,你在写的时候别人也能写,你在访问的时候,别人也能访问,所以此处这里的以太网,我们如果换一种视角,站在系统角度,两台主机你想发我也想发,我们两能够干扰本质是我们访问的是同一个以太网,所以此时在局域网当中,这种公共能够被大家同时访问的资源,我们叫做什么资源呢?叫做临界资源。所以本质上在通信的时候,要保证信息不互相干扰本质上是保护临界资源当中数据的一致性,再比如说,当我们实际上访问的时候发生了碰撞,发生碰撞之后,然后我们执行碰撞避免,这叫做让我们访问以太网时,串型访问的其他策略。所以我们为什么说碰撞避免,碰撞了我们就要实行碰撞避免,然后呢,没有人发的时候我再发,也就意味着,没有人在使用以太网时我们再使用,这叫做什么呢,这就叫做我们站在系统角度去重新看待它。所以以太网本质上在局域网当中,可以把以太网看作成两台主机之间的临界资源,访问临界资源的代码呢我们就叫做临界区。那么任何人想要访问临界资源,如果出现冲突,那么我们把数据作废,我们双方延迟一下再重新发送,这就叫做碰撞检测和碰撞避免,同学们跨主机之间保证临界资源,数据一致性,大家可以看到和同一台主机内做法就不一样了,有人说两台主机之间加一把锁,有没有呢,有的!只不过,主机A和主机B 两个之间呢,要互相进行我们对应的进行竞争这里的以太网资源,那么因为你要加锁,前提条件先要让这两台主机看到同一把锁,现在两台主机没有同一把锁怎么办呢,那么你也就没办法加锁,但是我们可以在主机内呢,可以有一个,不知道同学们还记不记得我们讲互斥锁的时候,我们说互斥锁就是拿CPU内的寄存器和我们内存当中做交换,那么如果我们规定一种特定的数据格式,那么拿到特定的数据格式的主机才能互相访问发消息,那个东西其实就相当于一把锁,对应的通信标准呢就是令牌环网。所谓的令牌环网当中,只有拿到令牌的人才能向网络里面发消息,没有令牌的人不可以。同学们,拿着令牌的人不就是申请锁成功了吗。所以我们正式也引出了MAC地址。
认识MAC地址
·MAC地址用来识别数据链路层中相连的节点(是用来识别主机的地址);
·长度为48位, 及6个字节. 一般用16进制数字加上冒号的形式来表示(例如: 08:00:27:03:fb:19)
·在网卡出厂时就确定了, 不能修改. mac地址通常是唯一的(也是全球唯一的)(虚拟机中的mac地址不是真实的mac地址, 可能会冲突,但是不重要,重要的是我们知道MAC地址在一定程度上要保证他的全球唯一性。知道同学们有一个困惑,MAC地址不是局域网内用的吗?你怎么搞个全球都唯一呀,这个说来话长,首先MAC地址必须唯一,每一个厂商不能生产出一样的,虽然是在局域网工作,但是你必须这样做; 也有些网卡支持用户配置mac地址)
IP地址和MAC地址
下面我们再进入下一个,如果两个主机之间通过,我们可以称之为叫做跨网络呢,那么数据帧又是怎么流向呢?一会儿把这个一说,把IP地址一引入、封装解包概念和分用,那么我们网络基础一就结束了。
》刚刚给大家提了一种地址就是MAC地址,它呢在我们的机器当中呢是我们网卡硬件的地址,如果我们想查看我们的MAC地址怎么去查呢?云服务器输入#ifconfig。
》下面我们再来谈下一个概念,如果我们两个主机通信通过协议栈叫做跨网络传输呢,跨网络传输呢,如果有两个局域网,两个局域网通过路由器连接起来。那么其中对我们来讲,数据呢从上到下进行通信,自底向上进行交付,大家知道左边一个协议栈,右边一个协议栈说明是两台主机,这两台主机呢是属于不同的局域网的,不同的局域网呢其中我们用路由器连接起来,图中虚线框框里面的就是路由器,同学们,只要它是一台路由器,这台路由器只要能够在两个网络内,跨网络传送数据的时候,这个时候,这个路由器一定是至少具有两个网络接口,甚至是两张网,这两张网卡一定是连接左侧的一个网络,还连接另一个右侧的网络。所以此时要把数据帧转发到对方,前期是你得把数据帧自顶向下转到路由器上,到了路由器,再经过路由器转发到另一台机器上。所以对我们来讲呢,我们是可以把我们讲的路由器呢,当作左侧的一台主机,在另一个局域网当中也当作它的主机,所以路由器它是横跨两个局域网的,只有你横跨两个局域网,身处两个局域网当中,才有可能完成我们数据的路由转发功能。今天我们不谈细节,但是我们常识应该知道,比如说上层用户发了一个“你好”这样的信息,它呢经过我们的用户发下去,交给了我们的FTP层,FTP层呢要添加我们所对应的报头,添加好报头之后,它也一定要向下交付给我们的TCP层,TCP呢他也要添加自己的报头,然后继续向下交付,到了IP层呢也要添加自己的报头,继续向下交付给我们的以太网驱动程序 ,它当然也要添加自己的报头,添加好之后呢,此时所有的数据转发到我们的路由器当中,转发到路由器,一定是通过我们的以太网,因为这个路由器属于这个局域网当中的一台主机,通过以太网转发到所对应的路由器当中的网卡,至此我们就把数据交给了路由器。
》这个时候必须得引入另外一个概念了,就叫做IP地址。下面为了让大家对IP地址有更好的理解呢,给大家讲一个故事,我们呢可以发现一个问题,假设我是一个北京人,假设我的朋友在云南,比如张三和李四,张三说,李四赖我云南玩呀,所以此时我就特别想去云南玩,当我想去云南玩的时候,我此时并不能直接从我们的北京到我们的云南,有人说坐飞机不就完了,暂时不考虑,假设我们就要坐高铁或者火车去玩,我们去云南首先要做的就是从河北到山西,从山西到伤陕西,然后从陕西到云南。那么我的问题是我在北京的时候想去云南,下一站去的是山西呢?为什么不是黑龙江呢。这个问题呢,得把根给大家说清楚,答案很简单,当我们到了山西之后,山西一个朋友说,你从哪儿来,你说你从河北来,他说你怎么来山西呢,你说,我要去云南。换句话说呢,我们从河北到山西到时候,别人问我从哪儿来,然后告诉别人说我们从河北来的,然后别人问我你要到哪儿去呀,为什么要来山西呀,你回答说是要去云南。所以当我们从山西到了陕西之后呢,又碰到了一个陕西的老铁,陕西老铁聊的很开,你哪儿人,从哪里来的,你说你是北京人,从河北过来的,陕西老铁说,你为什么来我陕西呢?然后你说,因为我要去云南。同时呢,我们陕西老乡呢有多问了一句,你上一站从哪儿来的呀,你说,我上一站是从山西来的,然后这一站就到了陕西了,那么其中当我继续到四川再到云南的时候,那么其中我们到达了我的目的地,其中这个过程就叫做我的路径选择,这是一个生活当中的常识。下面呢,结合这个常识再举一个例子 ,我们看过西游记,西游记里面呢,唐僧每到一个地方,别人都会问他两套话,第一套话,和尚你从哪儿来到哪儿去,然后他会说,我从东土大唐而来,我要去西天取经;第二套话呢就是,和尚你上一站从哪儿来,下一站到哪儿去?上一站我从A,下一站我要去B。所以呢,我想告诉大家的是,常识告诉我们,我们一般在进行路线选择的时候,我们身上一般有两套地址,**1.从哪里来,到哪里去。2.上一站从哪里来,下一站去哪里。**就好比呢,我在河北,然后呢,我从哪儿来呢,我从河北来,到哪儿去呢,我要去云南;那你上一站从哪儿来呢,我上一站从河北来,下一站计划去山西。那么请问,我下一站去哪里由谁来决定?是由我们要到哪里去决定。换而言之,我们把2这一套,上一站从哪儿来,下一站到哪儿去,这种地址我们称之为,MAC地址。而我们的从哪里来到哪里去,称之为IP地址。所以我们的地址从粗略程度划分上有两套,一套是IP,另一套就是MAC了。我们细细的去划分呢,可以划分为原IP地址,和目的IP。其中呢,我们得MAC地址细细划分呢,划分为,原MAC地址,和目标MAC地址。其中呢,当我们自己在进行我们的,假设我自己就是数据包,其中我要去云南的时候,我为什么要去山西呢?原因很简单,我们的目的IP是云南,所以我必须得把我下一个MAC地址按照目标来设定,下一站我就应该去山西。
》所以对我们来讲呢,我们今天很简单的道理,你今天要把你的数据交给对方,对方没有直接和你相连,你要把数据交给他,所以他的IP地址,假设叫做IP A,接收方呢叫做IP B。所以对我们来讲呢,讲清楚非常关键的一个点,我们标识一台主机是IP A,另一台主机呢叫做IP B。所以给一个定义,什么定义呢,MAC地址,用来在局域网当中用来标定主机的唯一性;IP地址,用来在广域网(公网),标定主机的唯一性(不太严谨,我们暂时先不管)。也就是说呢, IP地址解决的是我的数 据包从哪儿来到哪儿去的问题,所以当我有了一个数据包,经过网络,你要把数据包交给对方主机,那么前提条件是你得把主机先交给和这个主机同样所在的局域网里面的路由器,你不可能直接交给对方。我们的数据呢,其实是进行转发,必须得先交给路由器,再由路由器交给对方。你不能跨越我们的路由器直接把数据交给对方,是做不到的。所以对我们来讲呢,我们其中要在我自己的IP层,我要决定我的数据包该怎么走。该怎么走呢,我发现我要去的主机是IP B,所以此时,我知道我必须得先把我的数据转发交给我们的路由器,其中呢,我们在将数据进行向下交付的时候,在IP层就做好了路由选择,就好比你出发前和你朋友商量,你说你已经到了陕西了,下一站到哪里呢,然后你朋友说去四川,此时你继续向南走。其中呢,就好比我们的主机呢,当前数据包交付到IP层了,识别到自己要去的是IP B的主机,所以识别到不在同一个网段,然后一定是跨网络的,所以要将数据交给路由器,所以呢就通过以太网直接交到路由器。记住了,当我们把数据交给了以太网,一定是以太网底层的数据链路层先拿到,就好比当我们任何时刻,自顶向下发数据,收发的时候,对方收到数据的,一定是对方最底层的物理层先收到,收到之后要做什么呢,路由器是工作在网络层的,所以它收到数据的时候也要向上交付。因为是以太网,他们都是用的以太网驱动程序,所以最终呢,数据帧呢被以太网驱动程序层收到,收到之后就要解包,解包之后向上交付给IP层,对于他来讲,他也要路由呀,也要识别下一站我要去哪里,此时路由器是被到,你要去的IP呢就是IP B,和我的路由器是直接连着的呀,所以此时这个路由器就要把数据帧继续向上交付吗?不是的,是交付给令牌环驱动程序的,添加令牌环驱动程序的报头,因为可能用的是不同的网络标准,没关系,此时报头加完之后,就将数据发送对方,对方收到之后呢,此时确认了这个报文就是发给我这个主机的,怎么发呢,是不是就是向上交付了呀,怎么交付呢,那么一定是去掉同层的报头,进行解包,然后再交给上层,交给上层之后,上层识别到,你这个报文当时写的时候,填充的IP呢是要去的主机IP B,此时就拿数据里面的IP B和我的IP做对比,确实是发给我的,继续向上交付麦,当然也要把自己的协议数据给去掉对不对。交付到TCP后,也要识别自己的报头,再进行解包,然后再向上交付,交付给应用层,应用层再解包,交到了用户。所以你会发现,经过这样的转发之后呢,同层协议,尤其是IP层,这一层要发的数据包,就是对方收到的数据包,其中我们这个呢就称作,我们可以跨网络传输。很细节的一个点就是,当我们的数据包呢,发到局域网当中,被我们路由器的某一个网口,即以太网驱动程序收到,收到之后向上交付给路由器的时候,路由器是要解包的,路由器再重新进行路径选择,发到对方主机时,要重新封包的,交付给令牌环网驱动程序(不是说就是令牌环网,看用的什么网络标准),封包之后,对方收到的,就是我要发的,然后此时,我们就完成了数据的转发。其中最关键的是,我们看到了一个细节在IP层,即往上看,也就是在发送方的IP层、路由器的IP层、接收方的IP层,在各个IP层看到的数据的样子都是一样的,并且在IP层往上的层都是一样的,所以我们发现一个现象 ,叫做所有的,IP往上的协议层,发送和接收主机看到的数据是一摸一样的 !那么什么意思呢,当我们的自顶向下交付,封装的时候,然后我们在IP层进行路径选择,我们发现你要去的目标主机是IP B,是它怎么办呢,你必须得经过路由器这么一个IP层,所以你要把数据交给路由器,交给我们的路由器,此时我封装的我的MAC帧写的一定是路由器的MAC帧,把数据交给以太网驱动程序层,交给他,它也没闲着,它不是直接就把数据交给路由器IP层,而是要先解包,解包之后就是我发送方IP层交给它的样子,交给了路由器,然后路由器IP层交下交给令牌环网驱动程序层,令牌环网驱动程序层再进行封装自己对应的报头,这叫做入乡随俗。然后到了对方主机的时候,重新向上交付给对方的令牌环网驱动程序,它进行解包交付给接收方的IP层就是发送时的数据的样子。所以我们在IP这一层看到的所有的数据都是一样的!所以我们的IP协议呢,有一个非常大的亮点,就是IP层往上,只要站在IP层往上,我们可以认为互联网当中,只有一层协议就是IP协议,也不敢这么说,或者说,站在IP层往上,所有的主机看到的IP报文都是一样的。所以我们一般把我们看到的网络叫做IP网络。所以为什么我们叫做IP网络呢?原因很简单,因为在IP层往上,所有的每一层都,包括我的发送端、中间任何路由器IP层、目标主机的IP层收到的数据包都是一样的,所以IP这一层呢,是不是就叫做,**屏蔽了底层网络的差异!**我们底层的网络呢,有以太网、令牌环网,但是在IP层往上呢,我们看到的所有的报文都是一样的,所以大家协议定制的时候,无论你是什么主机,无论你在哪一个局域网当中,都不重要了,只要在IP层往上,我们就可以使用同样的一套的协议标准,全网的主机都可以了,这个呢就是IP带来的意义,屏蔽了底层网络的差异。
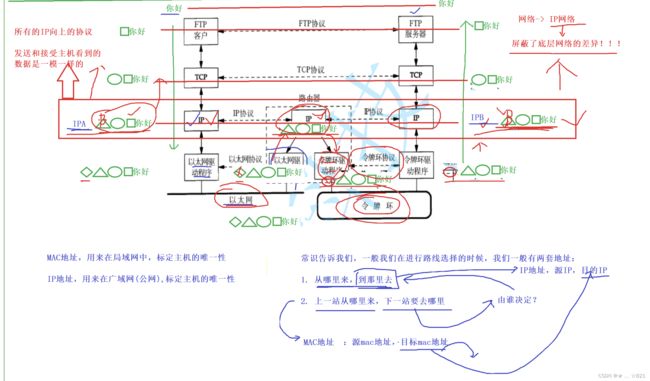
》那么他是怎么做到的呢?其实是当他走到局域网时,套上对应的局域网的报头,当经过路由器又会去掉对应的局域网报头,然后路由器内重新转到下一个路由器的时候,会重新封装MAC地址,所以当一个IP报文不断流动的时候,它的目的,尤其是目的IP一直都不变,但是原MAC地址和目的MAC地址一定是在变的,但是IP地址不变,相当于IP层在网络内将所有的主机设置了一个虚拟的软件层,也叫做IP协议往上,所有人看到的报文呢,在任何设备上,只要你是一个IP层往上的设备,曾经对方发的和你收到的,在哪一个中间设备上看到的数据都是一样的,这就是IP的意义。同学们,你想到了什么呢?是不是经过我们IP协议的设定,那么我们是不是屏蔽了底层局域网当中网络的差异之后,上层的协议在全网内其实都是统一的,因为我们收到的原始报文都是IP报文,底层我就不再管了,这就是一种软件虚拟化技术。在我们Linux学的时候,叫做一切皆文件,创建了一层软件层,在操作系统层面上看,所有的文件都是普通文件,struct file结构。大家讲进程的时候,我们给进程和内存之间构建了一个虚拟地址空间,让所有进程看到内存时,都以4GB的空间来看待内存。在网络这里有了IP的存在,我们全网内所有的机器在IP层往上大家看到的所有的网络报文都可以从IP报文为起始,底层的差异就不用管了,同学们,这叫做什么,这叫做任何问题都可以添加一层软件层来解决。如果没有IP协议呢,路径路由成为了困难;第二我们光处理不同网络之间的差别那你就要花很长时间。
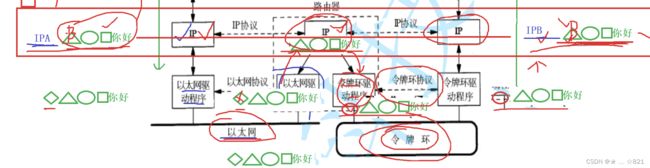
》再继续,在我们讲的过程中呢,我们每经过一次路由器, 我们一定要重新解包,再向上交付(比如图中的以太网程驱动程序解包交给路由器,然后路由器再向令牌环网传的时候,会在令牌环网驱动程序 那里进行封包),再向下重新封包,一解一封就给他换了一个底层的MAC报头。其中这个概念呢,就跟我们在生活当中一样,你要去云南旅游,无论你到哪个城市,你从哪儿来到哪儿去,永远都是不变的,但是上一站你从哪儿来,下一站你到哪儿去,这个是一直在变化。同学们,当你从河北到了山西的时候,你上一站是河北,下一站是山西;到达山西之后呢,你接下来正准备从山西要进入陕西的时候,那么其中对你来讲呢,此时你上一站就成了山西,下一站你就是要进陕西了。但是不管你在哪一座城市,你进入到了哪一个省份,其中你从哪儿来到哪儿去,这个地址是不变的,但是上一站和下一站一直都在变化,所以对我们来讲这就是IP和对应的MAC地址的概念。所以最后我们强调了一个非常重要的概念,叫做IP地址和MAC地址。
下面呢,当我们实际在理解了这一点之后,我来告诉大家,我们一般网络通信的时候,它的一个基本轮廓是什么样子的呢?给大家画一张图。
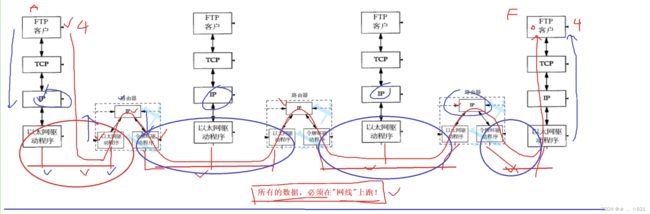
》我们肯定会经过很多很多的局域网,一个协议栈代表了一台主机。所以我们必须得先承认一件事实,叫做,所有的数据必须在“网线”上跑,也就是说呢,所有的数据你再怎么网络传输,你必须得在网络里面跑,所以网线在哪儿呢?比如说,一个协议栈和路由器之间就是有一条网线,所有我们必须得承认,你再怎么数据转发,你必须得考虑所有的数据都得在网线上跑。给大家讲一个故事,你辅导员呢在A栋宿舍4楼(FTP客户层),其中它呢把你叫过去说,张三,你帮我去找一下叫做F栋,然后在4楼帮我们把文件袋放到4楼的桌子上,此时你呢就拿着辅导员的文件袋 ,你是不是直接飞过去到F栋4呢?不是的,你听到要求,肯定是先下楼(封装向下交付),下楼之后呢,然后你走到了一个对应的位置(以太网驱动程序层),你不知道路,你只知道你要去F栋4楼,你不知道路怎么办呢,你导员跟你说,你在路上不认识了,你在路上找一下两层的房间,2楼(路由器层)有保安大爷,你问一下保安大爷,所以当你此时不认识路的时候,你进入到二楼,然后问保安大爷你怎么走,保安大爷告诉你从哪里出去,然后你就下来了(路由器往下倒令牌环网驱动程序),一定要记住你在路上走,路上走之后呢,你又不认识路了,你再去自底向上到2楼找到保安大爷,然后你再下楼循环往复,我们要记住了,我们在进行我们数据转发的时候,因为所有的数据必须在网线上跑,就跟你一样,从一个地方到另一个地方必须得脚踏实地走在路上,所以每一个设备呢,出来的数据必须得到达它所在局域网,然后呢,在局域网内,自底向上交付,经过路由器,在以太网驱动程序这里封包,在令牌环网这里进行解包,重新再转发,最后经过路由器的路径选择,最后到达目标主机,所以我们整个数据的流向是这么流,其中你要记住了,因为一个局域网内的所有主机是可以直接通信的,所以某一个协议栈即一台主机认为自己是和一个路由器是在同一个局域网内的,同理,其他主机和路由器都认为咱两是同一个局域网的。记住一句话,我们的所有主机都认为自己在局域网当中可以和另一台主机之间通信,所以同一个局域网的一个主机和路由器,这两个被当成一台主机,而路由器一定横跨两台主机,也一定横跨两个局域网(子网),一旦这个局域网可以通信,另一个局域网可以通信,而路由器可以即在这个局域网里通信,又在那一个局域网通信,局域网内可以直接通信,就决定了两个局域网内的数据也一定能够互相通信,只不过做法会更加复杂一些。
》当我们真正的意识到这一点的时候呢,我们的同学才慢慢的体会出,数据是要自顶向下交付的时候要添加每一层的报头,其中我们把添加的报头过程称之为,封装的过程!那么其中对我们来讲,我们再把它反过来,数据反过来向上交付的时候,反过来看的时候,他要不断的去掉同层报头后,再交给上层,这个过程叫做解包的过程。这就是封装和解包的过程,经过我们刚刚呢会发现,实际当中,当一个报文发出的时候,他一定会经过一次完整的封装,在路上会进行一定程度的解包和封装,到了目标主机再彻底的解包。所以我们网络传播的本质就是,数据在网络当中不断的被封装和解包的过程,同时配合着查找我们对应的IP层,对应的各种路由表来进行,来进行路径选择,这就是我们数据转发的整个过程。
最后一个问题,我们再把了图拎出来,再来给大家一个概念,这个概念呢很好理解。当一个数据包呢,被收到了,被以太网驱动程序收到,收到之后呢,它当然要向上交付咯,我们要知道,每一种协议向上交付的时候,以太网上面可不止一个IP层协议,还有arp/rarp等协议,只不过课件的图简化了,TCP层呢还有UDP协议、ICMP等协议,应用层呢不仅是FTP客户层,还有有http、https、dns等等各种协议。当我们对应的底层收到了数据帧的时候,接下来他要向上进行交付,可是当他向上进行交付的时候,假设从IP层向上交付为例子更好理解,它怎么知道数据帧里面有它去掉的报头呢?当他要把去掉的报头后的数据帧继续向上交付的时候,它怎么知道是向上交付给TCP、UDP还是TCMP等协议层呢?IP层脑袋上可是顶着多种协议的 。所以我们要记住一个点,叫做,数据包添加报头的时候,也要考虑未来解包的时候,将自己的有效载荷交付给我们上层的哪一个协议!是什么意思呢,意思就是说,我们每一个数据帧/包,当以太网层序层它识别到自己的报头的时候,剩下的我们称之为,有效载荷,此时他要向上交付,它怎么知道他要向上交付的是IP协议还是其他协议呢?所以这里呢就要有一个问题,我们一般在封装报头的时候,添加报头字段的时候,它的字段里面呢,也要考虑解包的时候,将有效载荷交付给上层的哪一个协议。其中我们把报头添加的决定将有效载荷交付给哪一个协议呢,这个字段是必须得有的,而且我们把决定向上交付给哪一层协议过程,我们称作有效载荷分用的过程。什么意思呢,意思就是说,当我们以太网驱动程序收到了数据帧,他要向上交付的时候,它怎么知道把有效载荷交给脑袋上的哪个层呢?那么以太网驱动程序的报头必须考虑,考虑什么呢,就是把有效载荷交给哪一层协议。我们再解包的时候,决定把我们的有效载荷交付给哪一个协议,就是分用的过程。
》最后基于我们上面所说的所有点,要给大家产出2个基本结论,我们在封装的时候,一般而言,任何报头,都必须解决一个问题,因为它能够封包,那之后是不是还得把它解出来,你如果解不出来的话,那是不是出现问题了,所以不管是同层的MAC帧还是同层的IP,原IP层还是目的IP层,还是在其他层,一般而言,任何报头的属性里面一定要存在的一些字段要支持,我们进行封装和解包。也就是你说,你给我封了,报头是什么,报头就是添加的数据,这数据里面肯定有不同的字段,一定要有一个字段来决定哪些属于报头,哪些属于有效载荷,必须得把这个说清楚,要不让对方没办法通过我们对报头的解析,将报头和有效载荷进行分离。怎么分离呢,报头里面必须得添加属性。第二个,任何的报头的字段里面一定也要有一些字段支持,支持什么呢,就是支持分用。也就是,一般而言,任何报头的属性里面一定要存在的一些字段要支持,我们进行分用。也就是说呢,它必须得有一个来表明,我这个报文的有效载荷将来是要交给上层的哪一个协议的。上面的这个结论呢,是我们未来要学习协议的公共属性。也就是说,我们未来学习的时候,每一个报头都有各种的字段,但是在这么多字段里面呢,我们首先把共性都抽出来,就可以大大减少我们的记忆和理解成本。就好比什么呢,就好比我们封装应用层协议的时候,它的报头里面就必须得决定,第一个我未来怎么把报头字段和有效载荷分开,比如说,它的报头字段表示的是,整个报文是多长,报头字段是多长,整个报文-报头,剩下的就是有效载荷,它得有这样的字段。第二个呢,它未来得决定将有效载荷交付给上层的哪一个协议,上层的协议很多,所以它里面一定要有。同样的,当在TCP层协议封装的时候也得有将自己的报头和有效载荷分离的字段,比如说,整个数据段长度是多少,然后报头是多少,此时呢,就可以将报头和有效载荷分开,分开之后,它里面还得有字段表明,我要把我的有效载荷交付给哪一层协议。其中这两个结论一定要记住,至此,我们的网络原理一我们全部讲完。
》我们在网络基础一呢,学到了一些零散的知识,比如知道了,局域网和广域网,理解两台主机通过网线连接是可以通信的;第二个,我们知道了协议,这是约定,计算机和计算机之间的协议呢,对应的也是要通过数据来表达他们定的协议的;第三个零散知识呢,就是MAC地址,MAC的基本通信原理,在局域网当中,反正能够通信就可以了,再下来就是IP,IP和MAC地址的区别我们也知道了,他其实相当于MAC地址标定的是局域网中计算机的唯一性,IP地址表示的是公网当中的唯一性,那么其中对我们来讲呢,IP地址和MAC地址的作用是不一样的,就跟我们原地址和目的地址,上一站地址和下一站地址的差别,这是第四个零散知识。第五个,我们知道有封装和解包。
》总体结构性重要知识,我认为是三个。第一个呢,我们的网络协议栈是层状结构;第二个呢叫做,我们的网络协议栈的层状结构和操作系统之间的关系属于操作系统内的一部分;下一个就是我们数据包转发的时候,一定是从上到下,然后经过路由器不要断的去转发,最后到达了目标主机,在转发过程中,数据必须得在我们对应的具体的某一个局域网当中被进行转发。
》最后我们得出了两个结论,就是,一般而言,任何报头字段里面,能够支持我们进行解包和分用。你想想,你要能够解包和分包,必须考虑解包,你说解包就解包,凭什么呢?所以你的报头里面必须得包含哪几个字节属于报头,哪几个字节属于我们的有效载荷,所有报头里面都要有这个属性。第二个呢,我们的有效载荷交付给哪一层协议呢?上层的协议那么多,交付给哪一个呢?其中我们就要考虑每一个报头的属性里面,他一定会有我们对应的,支持我们分用的功能,这就是我们网络基础一。
网络基础2
我们是从自顶向下去讲,大部分教材是自底向上去讲的,都是先讲最底层协议,再讲最顶层协议,我们自顶向下去讲。因为我们已经有了应用层的应用了,后面会说我们的socket究竟是在做什么。
》其二呢,我们先遇到的第一层协议是应用层。当然第一层协议叫做应用层没有错,但是呢,接下来你可以理解成,应用层协议太多了,它不像UDP、TCP、IP协议、MAC帧等,我们重点是想贯穿把重点的讲讲,尤其是应用层,它的协议太多了,我们主要是以http为主线然后把应用层全部搞定。
》我想先问一个问题,我们曾经用到的套接字接口都是什么接口呢?我们一起用的socket、bind、liset等,这些都是系统调用接口。
》我们说过,网络协议栈是层状结构的。最上层,我们称之为应用层,接下来就是传输层,再下面就是网络层、数据链路层。最底层的硬件设备是网卡。中间的传输层和网络层它其实是属于我们操作系统的,最下面的数据链路层其实是属于我们的设备驱动层。最后衍生出来一个问题。
》**请问,我们之前写的各种socket代码,是在干什么呢??**我们首先用的是socket、listen、bind这些接口,我们也要明确我们之前写的所有代码都是隶属于应用层。也就是传输层、网络层、数据链路层和你半毛钱关系都没有, 你只是用人家的接口,另外,你用的这批接口是谁给你提供的接口呢?说白了就是传输层给你提供的接口,有些tcp给你提供,有些事udp给你提供的。而我们所做的工作,其实都是在原生的编写应用层代码。我们之前写的代码,其实已经是在做应用层的工作了。
》其中对我们来讲呢,应用层的应用呢,有很多的场景。我们写的网络套接字可以完成一些任务,但是我们少了一份工作,我们没有定制协议。有人说,我们不是定制了吗,我们发的就是字符串呀。是的,如果你是这样理解的话,那确实是没有问题的。但实际上呢,你发过来的字符串是什么呢?当我们聊天的时候,我们认为我们发过来的是字符串,这就是我们的一种约定嘛。但是呢,这个协议定制的并不明显,这是其一。其二呢,应用层有很多的其他概念。
》为了满足不同的应用场景,早已经有很多的前辈,早就给我们写好了应用层协议!http、https、DNS等。人家早就写好了,我们之前做的工作,可以叫做,造轮子或者学习网络通信,或者呢,未来在公司里面叫做,定制化服务,也就是你自己从原生的套接字往上去写,这叫做定制化服务。目前在主流的服务器里面,早有一大批的开源项目帮我们去解决。比如说,应用层,你想用htpp,那就有http框架,你想基于远程调用,就有rpc等 。虽有很多的框架已经帮我们准备好了,但是我们必须得学会这些轮子,因为这一个经历你少不了。如果你没有写轮子的经历的话,人家做的事情,你压根就看不懂,学到现在,应该是能理解这句话的。
》对我们来讲,人家早就写好的,人家已经开始用了,比如说java等。记住了,所有的网络服务器,如果你要说,网络服务器是怎么写的,都是由C、C++来写的,其中虽然有python、java也有写,但是不要忘了,python底层也适用的我们学的东西来写的。你听到过的所有服务器,都是用C、C++来写的。 另外,在有些特殊领域,需要我们不要用现成的协议,需要我们定制化,那么就需要自己定制一大堆。我们C、C++既可以用来做服务器,也可以用在各种嵌入式设备。搭建网站其实是最简单的应用,手写服务器才是最牛逼的存在。

应用层
再谈“协议”
所谓的协议就是一种约定,人和人之间可以约定,我们所对应的程序和程序之间也是可以做约定的,我们曾经算不算定过协议呢?算的,只不过,我们的协议太简单了,比如给你发一个消息,就是人类可识别的字符串,服务器也这么认为;我给你发一个命令,你也认为我在给你发命令。我在给你发对应的命令,意味着什么呢?意味着,当前我们最终认为所有的字符串都是命令,客户端发送完之后,服务器立马就可以知道字符串不需要被转发,应该是被我们的open()执行,为什么呢?因为双方有共识,我们今天要干的,就不仅仅是它了。
》协议既然是一种约定,那我们在编写的时候,socket api的接口,在读写数据时,都是按字符串的方式来发送接收的。那如果要传送一写结构化的数据怎么办呢?
》这个可以给大家举一个例子,可以想想,我们传过去的呢,都是“字符串”,其实说是字符串是不太准确的,更准确的说法,应该是,我们在用TCP通信时,注意,从现在开始,我们主讲的都是以TCP为主,因为TCP是最难的,UDP呢,没什么好说的。我们都知道,实际上我们在进行网络发送时,你发送的数据都是TCP,而TCP都是面向字节流的,而这里的读写是按字符串的说法是不太准确的,应该是按字节流的方式来发送。只不过流式概念呢,大家对其还有一些障碍,那么我们就用字符串的话术来给大家说了,。
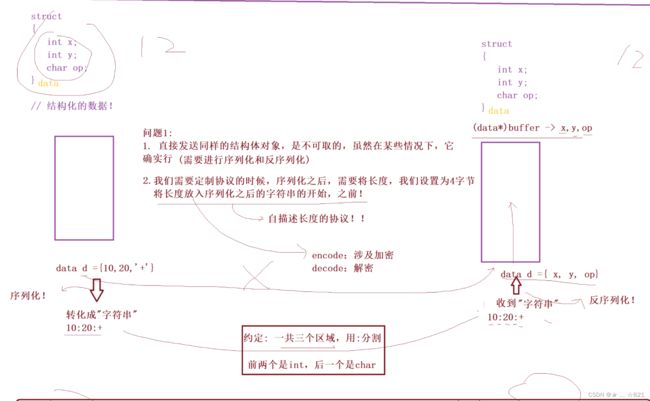
》如果我们要传一些结构化数据,那么又有问题了,什么叫做结构化数据呢?比如说,在C语言里,我想传一个结构体怎么办呢,一个结构体,它有整数,也有字符串、浮点数等等数据,那么我们该怎办呢?答案是:你不能怎么办,你也暂时不能传。那为什么不能传呢?这个结构化数据不也是看做二进制数据,看成二进制数据,我直接给对方发过去不就完了嘛。同学们,你想的挺简单,也想的挺美的,但是,结构化的数据在C语言里面,比如说,就是一个结构体,或者结构体定义出来的变量;在C++当中就是一个类,类内成员。你把一个结构化的数据发送给对方,你此时想把它按照字节的发送。说实话,理论上是可行的。
》比如说,我们接下来要进行的一个操作,叫做,网络版本计算器。我们想写一个网络版本计算器,想让它能够帮我们做某种计算。所以,我们一定是,首先定义一个,我们的数据请求,第一个struct data{int x;int y;char op;}这个就相当于结构化数据。我们将我们的结构化数据,发送到网络里面。我们用data定义一个数据data d = {10,20,“+”};我直接把d对象发送给对方。有人说,发过去有什么不好呢,可以呀,此时这不就是字节流嘛,那你把它当作二进制,直接给对方发。对方收到了,对方直接做一个这样的操作不就好了嘛,比如,对方收到了,对方收到的消息叫做buffer,我把buffer强转成我们的data*,这样是不是可以直接访问x、y、op了。这样其实你给我发过来一个结构化数据,这个结构化数据是12个字节,这12个字节对方也收到了,对方将收到的数据进行强转,强转呢,就能得到x、y、op,再进行对应的操作不就完了嘛。这就是我定义的结构化数据,同学们,这样可以吗?
》大部分情况下,是可以的。为什么呢?因为,网络协议就是这么定制的。实际上你可以去看看,网络协议,我们曾经不就讲过嘛,讲IP的时候,网络协议的定制,就是这么定的,其实就是按照字节来定的。 一旦网络协议定制的时候,定义出来就是一个结构体,然后结构体:位段等等。虽然这样是可以,这只是网络协议可以,但你不要这么干。而且你也绝对不能这么干。为什么呢?
》第一个问题,比如大小端问题。再比如说,大家都学过结构体对齐,那么结构体对齐的时候,我们也学过,一个结构体,它在不同的对齐规则下,它的大小是不一样的。我们就以结构体对齐为例。其实,在网络通信的时候,它已经帮我们把大小端给考虑好了,这个我们可以不用关心。但是呢,一个结构体的大小,在不同的对齐规则下是不一样的大小的。有人说,这有什么不一样呢?我客户端和服务器编译的时候,是一块编译的呀。同学们,你怎么这么天真呢?我们今天写的服务器和客户端是在linux下统一编的,未来服务器是Linux下编的,客户端是在Windows下编的,或者甚至是在手机上编的。你怎么保证 在Linux、手机、Windows下编译的结构体大小都是12个字节呢?
》所以,再怎么写代码,这种直接传结构体方案,在我们了,Linux、Windows下编,肯定是可以的。为什么呢?因为,大家的字节数都是一样,但是,在我们实际应用当中,绝对不可以这么干。你也不要想着,网络协议是这么干的,我也这么干。你能,但是不要这么做。收下你的锋芒,人家网络协议是踩着几十年的坑,所以不要去传结构体,除非你自己是在做本地传送,否则还是不要,甚至本地都不要这么做。我们不能够把数据直接二进制的传送给对方。有人说,我就是在Linux和Windows下通信都不行吗?你能保证你自己,把服务器写好了,可是代码还要维护,十几年之后,你的服务器不知道被迭代了多少个版本了,你的编译器也优化了多少个版本了。一旦客户端把你写的客户端下载过去了,客户很懒,就是不想升级,或者你的服务器升级了,用的更新版的服务器。但是,客户端已经把软件下载过去了,你已经鞭长莫及了,客户就是不更新。
》所以,你就用结构体来通信,未来服务端收到消息的时候,收到了还好,大小没变化还好,即便是同样一个软件,在不同的版本下,结构体大小就会有不一样。所以,如果出现你把服务器升级,那么所有的老客户,你不就管了吗。所以,直接传送结构体的方案,是绝对不可以的。
》第一个问题:直接发送同样的结构体对象,是不可取的,虽然在某些情况下,它是可以的。
》如果,我不用你说的这样的做法,不进行发结构体了,那我该怎么办呢?所以,我们一般在想发送结构体之前,把结构体转化成“字符串”,这个字符串只是一种手法,有的甚至编译成二进制,都有可能。但是呢,我今天告诉大家,我们把它转成字符串。
》转字符串相当于什么呢?就比如说,我的结构体就变成了这么一个样子了10:20:+,我把它变成字符串的样子了,只是举一个例子。然后怎么办呢?然后,我将字符串发送给对方,对方它就会收到这个字符串。因为两方有约定:一共三个区域,用:分割。所以对方收到这个字符串,紧接着要根据自己的算法呢,把我们所对应的字符串按照“:”作为分隔符,把我们发送的10、20、+进行提取,将其提取成对应的数据,而且我们协议定制还得加上,前两个是int,后一个是char类型字符。这叫做什么呢,这叫做,我们把它全部给我们提取划分成10、20、+三个子串,我把前两个10、20转化成我们叫做,结构体。所以我再在它本地构建一个data对象,data d = {x,y,op}此时,就在重新形成一个属于它本地的结构化对象,此时再将它向上交付,那么上层就可以用了。其中,我们把这一个动作称作,把一个结构化数据,转化成字符串,或者叫做字节流的序列,我们叫做序列化!我们把对应的,你发过来的字符串的工作,按照我们的要求,把它进行转成我们的服务器所需要用的对象,叫做反序列化。这也就是我们定制的协议。
》给大家举一个例子:比如说你在软件上给我回复消息。所以在网络通信里面,其实你将来要送的消息message,其实是这个样子的struct message{std::string name;std::string_image;std::string message…}这就是结构化数据。这里有三个字符串,我们要做的就是,将这3个字符串转成我们对应的1个字符串,那我们怎么转呢?那么我们就可以定制协议哈,比如说:nick_name\3image\3message\3。此时就把3个字符串转成了一个字符串。转完之后,再发送给对方。对方收到之后,就会把你转成的1个字符串,它呢,也会有struct message msg = {part1,part2,part3},此时就有了格式化,反序列化的数据。
》我们将字符串3变1的过程叫做序列化。我们把网络里面传送好之后,收到之后就要进行反序列化。但是,你怎么知道是3部分呢?你又怎么知道是用\3作为标识的呢,这叫做协议定制。
》协议定制:有几个字段,每个字段什么含义?
》有了序列化和反序列化的过程,我们未来要对软件做扩展,然后你在你的结构体里面做新增。你的老客户端没有更新,还是只是原来的变量,没关系。我收到之后,是可以判断你的新老客户端。如果你只有原来的变量,那么你就是老客户端,我就按老的一套给你处理,如果你是新版客户端,那么我就按照新的处理方法。
换而言之呢,有了这个,序列化和反序列化这么一层。这就相当于,在用户发送 和 网络之间,加了一层软件层!!可以进行各种操作。我们以前也说过,任何问题都可以通过加一层软件层来解决。以前我们说,进程在访问内存的时候,它可能会出现越界访问内存的情况,进而导致软件不可用,或者操作系统挂掉,这样我们就加了一层虚拟地址空间。后来又是,我们读写文件的时候,文件底层的差异太大,我们每一个硬件直接暴露给用户,那么就会有成百上千个接口需要用户全部熟悉。打开网卡、磁盘、显示器等等的接口完全不一样,对于用户来讲是不友好的,那么我们就加了一层虚拟文件系统,那么一切皆文件。一切的一切都在告诉大家,有什么问题,都能够添加一层软件层来解决。
》所以,序列化和反序列化就是充当了这么一层软件层,这个软件层,你可以在这里面做各种各样的处理。比如说,我们在进行序列化和反序列化的时候,我可不可以带上我序列化和反序列化的对应的定制化的版本,那么协议版本,如果你是老版本,那么此时我就知道,我就提取3个数据,如果你是新版本,我就提取若干个字段就可以了。所以,我们可以在用户和网络之间添加一层软件层,方便我们服务器进行各种任务。
》这也就是未来进入工作了,如果你是做的网络方向,你会发现底层的协议,比如TCP、UDP,它在通信时,就是我说的,用的结构体,挺好的。但是,一旦到公司层面上,在进行软件通信的时候,永远都要自己用一些组件或者框架等其他方式来完成序列化和反序列化的工作。为什么呢?最根本的就是,如果你愿意的话,你也可以用结构体来定义自己的协议,但太麻烦了,然后你要永远记住,网络底层协议为什么敢用结构体,它的大小端等等都考虑好了,为什么呢?第一,网络要求效率,它不允许你有任何浪费数据的存在;第二,网络协议的底层变化不大,它不变,不变的话,那让产品经理怎么提需求,提不了需求,那我们就考了效率呗。那么所有字段能给你压缩就压缩,用几个bit位就是几个bit位,暂时不用考虑扩展的问题。所以用的就是结构体通信,而且是二进制的。但是,告诉你们,应用层不一样,应用层你面临的用户,有可能是老版本用户,可能给你服务端发来的有5个版本,所以,作为服务器来讲,它要考虑的不仅是最新的,还要考虑老版本。所以,怎么让自己的协议在软件通信的时候,更好的适配各种的应用场景呢,这里就必须得增加灵活度,考虑的是灵活度优先而不是效率优先,所以,我们必须得添加软件层,也必须得有序列化和反序列化的过程。所以,这也就是网络服务器必须得有这么一步。
》你所说的约定我懂了,你所说的结构化数据,不管是C语言的结构体,还是C++ 当中的类,这些东西都是我们将来定制协议的字段,我们要将其转成对应的字符串。怎么转呢?有很多的做法,可以自己去写,去定制,也可以用其他的组件。现在的问题是,就这样完了吗?还差一点,
》比如说,我传的是一个结构体,但是你想过没有,如果今天将其序列化了,就按你说的用特殊字符将其分割。可是每一个人的name、message等字段的长度不一样,头像大小不一样,发的消息也不一样。消息呢,有大有小,就直接决定了,字符串整体的长度,你是怎么知道的?意思就是说,你的格式我是知道的,有几个字段,每一个字段的含义我都知道,但是我在网络读取的时候,我怎么知道字符串是多长呢?
》有人会问,需要知道吗?答案是:非常需要。因为TCP是面向字节流的。你发过去的长度,你以为你发了1024个字节,可是对方收的时候,就根本没有收。可能上层应用层在忙着,没时间去read。那么可能你发消息特别快。就跟我们曾经讲的管道一样,客户端可能往管道里面塞了一段数据,那么对方就读一条数据。客户端发的特别快,一下子发了10条信息,那么你读端可能一次就将10个消息都读上去了。
》但问题是,你怎么知道这个字符串的整体长度是多长呢?因为你要单独的去区分一个字符串嘛。就是,字符串发过去了,我们之前写的服务没有什么问题,是因为我们的场景比较简单,再加上我们发消息比较短。如果发的消息特别长,读取特别快,而且还有混着发的。我虽然知道你的格式和字段,我解析他,反序列化,是不是得保证我把字符串读全了,既不能多读,也不能少读,那怎么办呢?所以,你怎么知道字符串的长度呢?对不起,你并不知道。那怎么办呢?你不是玩我吗,我不知道,我怎么去通信呢?
》所以,我们还有第二个问题。我们在对应第一个问题上,我们要对它进行,我们对应的,它确实不知道我们数据结构体对象,我们这里需要做什么呢?我们需要进行序列化和反序列化。
》第二个问题,你怎么知道字符串的长度是多长呢?很简单,我们需要定制协议的时候,序列化之后,我们需要将长度,我们设置为4字节,将长度放入序列化之后的字符串的开始,之前!
》说白了,什么意思呢,意思就是说, 我在发送的时候,我规定好,我前4个字节,我发送的50这个数据,然后后面跟着的是字符串。所以对方在读的时候,他可以先只读取4字节,把长度读取出来,然后根据长度,再决定读取多少个字符。这种定制的协议,我们叫做自描述长度的协议!
》所以,我们终于解决了,我们在网络通信的所有问题,当然,为什么要这么干,然后还有其他做法吗?后面在讲TCP字节流的时候,我们再来给大家把原理讲完之后,我们再深刻的去体会一下他。今天呢,我们就先进行网络服务器的最后一块拼图。我们一般给我们添加的数据,添加字节数的动作呢,叫做,encode,对方在读时候呢,那就叫做decode。当然encode,不仅仅会有长度,其他协议里面有可能会涉及加密和解密,我们不考虑这个。
》下面,我们进入造轮子的环节。
网络版本计算器—序列化和反序列化
例如, 我们需要实现一个服务器版的加法器. 我们需要客户端把要计算的两个加数发过去, 然后由服务器进行计算, 最后再把结果返回给客户端。
》我们接下来要做的工作,是属于哪一层呢?应用层。我们前面写过了TCP服务器和客户端了!所以直接复用。
》我们在SeverTCP.cc里面添加 void netCal()函数。所以Task t定义出来的对象,初始化的时候调用的方法直接改成netCal()函数,即 Task t(serviceSock, peerIp, peerPort, netCal);我们还差一口气,我们再来一个文件Protocol.hpp,这叫做什么呢,接下来我们要在里面进行自己的协议定制。换句话说呢,我们要将我们协议相关的内容写到里面,我们自己来定制对应的协议。我们对应的服务器和客户端都要包含对应的协议头文件Protocol.hpp,协议肯定是双方都要知道。
》接下来就是,我们怎么去定制协议呢?我们要做的是,网络版本的计算器。定义一个class Request{}请求类,也还要定义一个class Responce{}响应类。那么请求和响应,我们都有了。在请求Request里面,我们得有int x;int y;char op的成员变量。我们接下来就是要在Responce里面,有int exitCode_;int result_;这里面的result很明显是我们定义的协议当中的运算结果,那么exitCode_,是什么呢?你能保证你的计算结果是正确的吗?你可能在进行计算的时候,对应错误,你怎么保证你的计算是正确的呢?你只有是正确的,那么你的结果才是会有意义的。如果你在服务端除0了,那怎么办呢?那么此时,我们服务器应该是不给你计算,给你返回退出状态,所以我们用0表示运算结果合法,非0表示运算结构是非法的。
》我们将协议字段定好还不够。你不是定协议嘛,我们要求的协议标准就是,我们将来是x op_ y,你凭什么让x作为被除数,y作为除数呢?那么我们就要服务器和客户端约定好,x就是左边,y就是右边。我们规定好op的操作就是±*/%运算,如果不是,那不好意思,那么当前的数据直接就是违法的,你就是非法请求,可以吗?可以呀,这就叫做约定。我们约定好,客户端和服务器都必须遵守,这就叫做协议定制。整体的结构就叫做结构化数据。
》那么我们的Request一定要提供对应的构造方法Requset()和~Request()析构方法。Responce少不了构造和析构函数。除此之外,Request在发送的时候,需要序列化,在收到的时候,需要反序列化,所以就需要有一个序列化和反序列化接口。比如说,你这个请求,我序列化完成肯定是变成字符串了,我要发给对方,对方是不是要进行反序列化,就要有序列化serialize()函数和deserialize()反序列化函数。
》序列化呢,我们是需要把3个计算的成员变量进行转化成对应的字符串,void serialize(string& out),反序列化deserialize(string& in),这就有了序列化和反序列化。对于我们今天所讲的Request,因为Requset是客户端请求,那么客户端就需要序列化,服务端获取,就要进行反序列化。
》对于我们的Responce,服务器要进行响应,是不是要序列化成字符串发出去,客户端是不是还要反序列化,把字段提出来呀。
》作为请求,还需要添加长度,我们再来一个对序列化的字符串进行添加长度encode()函数,对我们的string in字符串,进行添加uint32_t len的长度,即string encode(const string& in, uint32_t len),另外,还需要对序列化之后的字符进行提取长度string decode(const string& in,uint32_t len);我们Responce需要添加字节数和解析字节数,我们的Request也是需要的。
》我们将来的协议是这个样子的,我们想让整个发送过来的字符串,前面加上长度,即strlenxxxxxx,这个长度呢,有两种方案,一种是,就单纯的是4字节,定长的4字节,然后直接被转成二进制,在将信息扔给对方,对方只要读取,对方必定先读取前4个字节,必须得把前4字节全部读上来,读完之后,转化成我的有效字符串是多长,然后再从网络里面读取报头长度,len长度所标定的对应的字符长度,才算是将完整的字符串读完。当然,你发的时候,肯定也是按照协议来发的。
》第二种方案呢,就是采用字符串风格的“strlen”,即“strlen\r\n”用\r\n作区分,紧接着把有效字符串带上,即“strlen\r\nxxxxxx\rn”。我不喜欢采用第一种方案, 因为它的可读性不好,如果中间出了问题想要调试,是非常难的。如果想要打印一下读取的内容,可能都不全。但是,如果转成字符串,大家也都知道,我们把字节数当作字符串,然后再去处理有效字符的内容的话。我们把长度获得之后,把字符串转成整数,再去读取有效字符串,那么也就把序列化之后的数据读到了。所以,我们采用第二种方案。
》可能大家还有疑惑,第一个疑惑:你现在有一个整数,假如我的有效载荷长度是1000个字符,那么你前面的strlen的长度就是1 0 0 0 ,可是你的长度也是变化的呀,不像第一种方案,用标准的4个字节,就固定死,报头长度是4个字节,你爱读不读,所以,用4个字节的方案可以吗?可以的,但是可读性不好。用第二种方案呢,有一个问题,你对应的字符串长度呢,它本身也是变长的,有可能是10、20个字节,那么你的strlen也是变长的,我在读取的时候,我怎么知道,strlen长度就是整个字符串中的长度字符串风格全部读完呢?我怎么保证呢?很简单,我只要读完\r\n就可以了。
》有人说,你读到\r\n可以的,你是说,只要读到\r\n了,我就已经将长度大小读到了,那我为什么还要用你呢?我直接xxxxxx\r\n不就好了吗?何必还要在前面加上strlen长度,即"strlen\r\nxxxxx\r\n"呢。这里就有一个问题了,你怎么保证,序列之后的字符串本身就不包括\r\n呢?假如,对方就是发的\r\n呢,那么你这个协议定制的时候,就特别的不好处理。那又有人说,你就能保证你加上长度字符串之后,就能保证长度字符串里面没有\r\n呢?是能够保证的! 因为,长度都是由整数组成的,而且可以称作是一个无符号数,一定是一个数字,0~9,它不可能出现\r\n,所以,我们只要将\r\n,按照正常的去读,读到\n之后,我们就认为长度的字符串读完了,将读到的长度字符串转出来,然后再去读有效字符串。这都是细节,一定要搞清楚。
》同样的,如果此时你用标准的4字节来标定长度,是可以的,因为你是定长报头。但是呢,这种方案的可读性不好。这种方案反而好写,无非就是在内存空间里面,把一个整数长度按4字节拷贝到空间里面,把字符串也拷进去然后再发出去,这种方案,反而还好写。虽然第二种方案不太好写,但是这种的可读性很好,而且我们就采用前面是长度,后面是字符串。“strlen\r\n”是报头,然后“xxxxxx”是有效载荷,我定的就是应用层协议。只不过我们的报头比较简陋。我们可以将我们的有效信息都放到xxxx里面哈。
》“strlen\r\nxxxxx\r\n”这种样子的字符串可读性比较好,一旦读上来是这个,但实际上,我们的代码里面要用的是xxxxx的内容,所以,我们可以调用decode()函数进行解码,发送的时候进行加码encode(),也就是在我们的序列化和反序列化之后,添加报头字段。说一下,我们今天是从0开始写的,像别的java语言等,当然,我们也可以不从0开始写,但是我们得有这么一个过程,不然的话,别人写的你也不理解。现在最重要的问题是什么呢,实际上encode和decode可以做添加字节数,也能做加密和解密的工作。
》Request如此,我们的Responce也是同样的逻辑,我们把所有的功能写好,双方之间就可以用Request或者Responce来通信了。现在讲的整个协议定制,涉及到x、y、op这是你的结构化数据,x是什么,y是什么、op是什么。op为什么是± /%呢,这是协议的规定,为什么是x-y、x%y等等呢,这也是协议规定。我们Responce响应的时候,exitCode_,result又是什么意思,为什么exitCode_表示状态呢,result表示结果呢,这是协议规定好的。以后呢,exitCode_0表示/0,1表示%0等等这也叫做我们所对应的协议定制。所以在上面的一批字段呢,exitCode_和result是和我们的业务强相关,也就是和我们要写的网络版本计算器逻辑是强相关的。对我们来讲呢,我们网络通信之中还要做序列化和反序列化,还要对整个报文定制我们网络传送的解决方案,你前面为什么是长度然后是\r\n,为什么不是\3\5等等呢,不好意思,这是因为协议定制,这才叫做整体的协议定制。
》你如果不用长度,而是就用\r\n来分割,这样可以吗?答案是,这样是有问题的。你字符串本身就有可能包含\r\n的,你用特殊字符再怎么定,有可能你字符串本身就包含了你设置用来作为分割的有效字符。如果存在了,就有可能会影响你协议的运行。这种其实是一种二进制不安全的方案,所以我们要做的,加长度的方法是最安全的,也是目前最合适的。
》接下来就要编写网络版本计算器,协议雏形已经定制好了。后面会写大量的序列化和反序列化的代码。我会写两种方案,第一种:全部手写;第二种:部分采用别人方案–序列化和反序列化的方案。
首先别人给我发来的一定是序列化后的字符串,我们先来写服务端。你能保证一次读取就能把别人序列化好之后的字符串全部读上来呢?我们的字符串里面报头表示的长度不会将\r\n包含进去的。你怎么保证,你一次能够把发送过来的字符串一次全部读完呢,能做到吗?因为TCP是面向字节流的,它在发送的时候呢,有自己的一套机制,所以,对方不一定将全部内容一次就发送到你这里了,有可能只发送一部分,然后再给你发送后面的部分。所以对我们来讲,对方不一定一次全部发完,而我们心里清楚,我们要的是什么。我们要的是,必须前面得有长度,再带我们的报文长度。这样的才是一个完整的报文,才方便我们后续处理。所以在读取对方发送来的序列化的字符串有相当多的细节来处理一下。
》所以,我无法保证对方,一次将数据全部发送过来,那怎么办呢?所以此时,只能是没读完的时候,就让它继续循环的读。没有读完一个完整的报文的时候,就只能让他继续读,否者的话,我们没法处理。所以我们得加上inbuffer,我们在读的时候,可以这么去处理。char buff[128],我们说字符串,但是我们也不来考虑\0,你读多少就是多少,所以read()读到buff里面,读多少呢?读sizeof(bufff),接下来,读上来,此时s > 0,说明我们读取成功了,s == 0,说明对方是关闭的, s < 0说明就是读取失败了。
》网络版本计算器这个任务呢,主进程将其排发给线程。读的时候呢,对方把链接直接关了,关了之后,即便是做计算,我把结果返回给他,所以当s = =0的时候,我们什么也做不了,我们打印日志logmessage()。s < 0读取失败,我们也打印日志。
》当我们s > 0,读取成功的话, 因为我们是要把数据单独放在一个buffer里面。我们从read()里面读上来放在buff里面的数据,是只包含了序列化后上来的一部分字符,所以到底有没有读完,是需要自己做检测的。所以读了之后呢,buff是需要拼接到buffer里面的。然后在inbuffer里面做检测哈。那该怎么写呢?
》因为要做拼接,那么我们还是sizeof(buff)-1把。然后buff[s] = 0,inbuffer += buff;所以此时我们就把对应的缓冲区buff里面的数据添加到我们的buffer里面了。
》下面我们就需要检查我们的inbuffer是不是具有了一个,当然,别人在给你发的时候,也有可能发过来就是给你发了2个报文,是不是也有可能。因为TCP是基于流式,现在对方发过来的字符串里面呢,一次给我塞过来两个字符串,可能这次read呢,一次读多了,我要的是把一个报文拿全就可以了。那我们就要检查是不是已经具有了一个完整的报文了。如果具备了,我们就要提炼出来,进行后续的反序列化工作,如果没有具备,那么我们就需要让他继续读取。
》别人发来的,一定是一个Request,而一旦是一个Request呢,我们Request要执行的第一个步骤就是decode,就要根据它传入的字符串进行提取长度,那么返回的就是有效的字符串。就是,我们的decode,1.必须具有完成的长度;2.必须具有和长度相符合的有效载荷。只有当这两个条件满足了,我们才返回有效载荷和对应的len。否则,decode就是一个检测函数。
》换句话说呢,decode就是身兼两职,它对字符串做扫描,它里面必须满足,长度它是有了,第二,长度识别出来之后呢,它的有效载荷和长度是匹配的,而且必须是一个完整的报文。此时我们才将其解析出来返回的是报文,然后len长度是一个输出型参数,是字符串本身含的长度。
》如果就是,长度没有,比如我的有效载荷有10个长度,可是你呢,有效载荷只有9个,那不好意思,我直接给你的len就是0,那就不做字符串返回了。这就是相当于decode是一个检测函数。否则满足条件的话,decode就相当于是一个提取函数了。
》所以我们要构建一个请求的话,是需要定义一个Requset对象,即Request req;这个req呢,就充当我们的客户端请求的。所以,我们read()成功后,就需要req.decode(),将inbuffer传入,并将报文长度要传入&packageLen,即req.decode(inbuffer,&packagLen);长度是不可能为0,别人发过来的请求是不可能为0的,它至少得是一个3吧,即1 + 1。如果packgelen = =0,那么这次decode,我们没有解出完整的报文,那我们得continue,让你回到read()继续读取之后放到buff里面,然后再次拼接到inbuffer里面,这也是为什么inbuffer被放在while循环外面定义的原因。
》如果decode给我们输出的参数是一个大于0的,那么就是获得了一个完整的报文了,也就是我们把xxxxx的内容读了。接下来,我们要做的就是,反序列化的工作了。因为是经过别人给我们发过来的消息是经过序列化的,那我们就需要反序列化,把字符串里面的字段反序列化到我们的Request的内部。
》也就是说,我们接下来要进行反序列化,即req.deseialize()函数,将我们的package获得的报文进行反序列化。如果反序列化成功,那是不是字段已经在Request里面了,x、y、op我们全都有了,然后就是我们处理逻辑了。
》处理逻辑怎么处理呢,是不是就是我们真正的网络计算了呀。网络计算你需要什么,网络计算,你输入的是一个request请求,得到的是一个responce响应。我们来进行一下封装,用一个calculator()函数进行封装。计算的时候呢,我们传进来的是一个req,就是把刚刚已经反序列化完成之后对象传进去,里面的x、y、op都有了。那我想要得到什么呢,我想要得到的是一个responce,那么就是Responce resp = calculator(req);那么就要单独编写一下calculator()函数,那么如何编写呢?
》这个calculator()函数不需要暴露给外面,也能够将其定义层static函数。为了方便,我们就直接将Request里面的成员变量公开,即public,方便我们使用。另外,我们的Responce里面的成员变量也public,也方便我们使用变量。我们在calcutor里面定义一个Responce对象,即Responce resp;那我们怎么计算呢?
》我们switch(res.op_),进行选择,然后根据不同运算符进行将结果放入resp里面的result和exitcode里面。这样就把我们的请求的计算完成了,然后我们就是return resp,就完成对应的计算了。
》那么我们现在已经得到了一个responce了,那我们接下来应该干什么呢?因为responce是一个结构化的数据。有人说,就两个字段也是结构化数据嘛?是的!哪怕只是一个字段也是结构化数据。所以我们接下来要做的事情是不是要将我们的响应responce转成我们对应的序列化对应的数据,你一定能够理解。
》那么我们就要进行序列化。怎么序列化呢?我么你的responce类是提供序列化的方法的,直接调用类内函数,resp.serialize()。我们希望是拿到一个序列化完之后的结果,那么我们定义一个string respPacka,作为响应报文。我们将serialize()函数传入一个输出型参数,则resp.serialize(&respPackage),然后呢?后面就和你的resp就没关系了,就只和respPackage有关系了。可是光光有这个序列化后的字符串你能不能将其发出去呢?是不能的,因为我们还有协议呀,对方怎么知道我序列化之后的字符串是多长呢?所以我们还得对报文进行encode,添加上我们的报头长度呀。后续呢,encode和decode我们是可以单独拎出来,一会儿写完会发现Responce和Request的encode和decode其实写法是一样的,与类无关,它只是对字符串相关的做提取。
》我们现在要添加报头长度,就要需要调用Responce的encode()函数了,它所需要的参数呢,第一个是你要添加报头的字符串和你想添加长度的大小,完成之后,返回的就是你添加长度之后的报头+有效载荷,即resp.encode(resPackage, resPackage.size()),这个只是添加报头长度,是一定能够成功的。然后呢,返回之后的字符串就用我们的resPackage字符串来接收算了。
》然后我们接下来是不是就可以发送了呀,发送也是有问题的。你调用的write()函数,你再仔细的考虑一下,write()的返回值是你实际上发了多少字节。比如说你要发1000字节,最后呢返回的是500字节,也就是说没有按要求一下子全部将1000字节发出去,会有这种情况吗?会有的,那么就需要将你的发送的缓冲区全部记录下来,当我们发送的时候,你也要判断这个pakcage有没有发完,所以这块是需要做处理的。我们今天简单一点处理,我们将关注点聚焦在读取上,保证读取上来的报文是完整的,对于写入呢,我们在后面统一解决,后面会给出解决方案,其实说白了就是将读取那部分的代码也再类似的写一写。就相当于读取的时候inbuffer是用+=,它写入呢就使用-=哈。发多少字节,就将发出去的去掉,然后下次循环再发,写起来会将代码写的非常乱,这里呢就简单进行发送—后续再处理。虽然我们考虑到了这个问题,但其实我们现在所写的所有工作,大部分情况下是不会出错的,因为,我们现在的报文量少,且很短,所以不会出现很严重,你说的问题,但是也得考虑上,后面会处理发送的问题。
》接下来发,往哪里发呢,你读的时候read()是从socket里面读,发的时候也是往socket里面发呀。从我们的respPackage里面发,发resPackage.size()的大小,即write(socket,resPackage,resPackage.size());
》稍后有一些地方我们要单独做处理,第一个呢,strunf package = req.decode(inbuffer,&packageLen)这里要做一下处理。因为,后面我们在写的时候会发现encode和decode,因为是协议嘛,客户端遵守这样的规则,服务器也遵守这样的规则,所以encode和decode方法其实可以共用。而decode和encode其实只需要给我们提供所对应的序列化和反序列化功能就可以了,稍后再说,只有写出来才知道。所以encode()我们也会稍微改一下。
》至此,我们将逻辑大概的写出来了,接下来,我们再一步一步的完善函数内部的实现方法。
》我们先来完善Request里面的decode。首先你给decode()函数传进去了一个字符串,我们ServerTcp传进去的是inbuffer。我们在decode的时候呢,一方面,它要对我们的长度做检查,对后续的有效载荷也要做检查处理,只有条件满足才会将我们的有效载荷做返回,否则什么都不会做。那么我们该怎么去写呢?
》首先用assert(len);因为对方发过来的消息是满足协议要求的,所以前面呢,需要在我们的inbuffer里面查找我们表示长度的字符串,即一开始的\r\n之前的是表示有效载荷的长度,要先进行对它进行查找。当然,因为在查的时候呢,涉及到\r\n的问题,所以为了方便,我们宏定义一下,#define CRLF “\r\n”,我们还需要\r\n的长度,那么后续在切割长度的时候,就不需要再做了, #define CRLF_LEN strlen(CRLF),但是这里千万不要用sizeof(CRLF),因为sizeof会将\0也会计算进去,那么此时你提取字符串的时候会出问题。所以呢,我们现在就有了,中间的分隔符,它对应的宏和他的长度,在提取对应的字数的时候,就不用手写\r\n,这么麻烦了。
》我们先调用find()函数,即在我们的传入的inbuffer里面找一下有没有CRLF,即ssize_t pos = in.find(CRLF);如果pos = =npos了的话 ,那就是说明没有\r\n,也就是,你不是以\r\n开始,那我就不玩了,那我就没有办法去提取长度,那么有效载荷我也没办法去提取,那么,我们返回一个空串,光光这样还不行。我们在给decode传入参数的时候,是传入了packageLen的,并且它是一个输出型参数,并且用它来判断是否decode已经给我们返回了有效载荷的字符串,如果不是,会继续从socket里面读取内容。所以在decode()里面做解析之前,先将len设为0,即len = 0;如果提前返回不符合decode的条件的话,那么len就是0。
》其中,我们也知道,string的find()函数,如果找到了指定的字符,会返回\r的位置,所以pos是指向\r的。所以,如果pos!=npos,那就说明,我们是可以提取长度字符串。所以就可以提取长度,但是,在提取长度的时候,不要对传入的字符串inbuffer原始字符串做任何修改,暂时还不需要。
》那在提取长度的时候怎么做呢?我们定义string inLen;将长度字符串单独提取出来,那怎么做呢?是不是可以调用substr()函数呀,in.substr(),从0位置开始,提取的长度刚好是find()返回的位置pos,即string inLen = in.substr(0,pos)。
》这里有一个常识,一般在循环的时候,for(int i =3 ,i < 9;i++),这个属于[),这样有一个好处就是,9 - 3刚好是你得到的元素个数,所以我们find()返回的是\r的位置,“1234\r\n”,那么pos刚好是前面有多少个字符,这就是[)的写法。
》然后呢,我们inLen已经拿到了子串,那我们就需要把字符串转化成整数呀,调用atoi()函数,int inLen = atoi(inLen.c_str());我们必须具有完整长度这一个条件已经有了。
》第二步,得保证,in字符串剩下的有效载荷里面的长度必须能够>=inLen的长度,因为只有>=inLen了,才能得到一个完整的报文。
》所以接下来要做的第三件事情,就是确认in字符串中有效载荷也是符合要求的,如何确认呢?很简单,我们已经有了find()后返回的pos,pos指向的\r,我们要拿到后面的有效载荷的长度必须能够>=inLen。所以我们计算一下,去掉前面长度字符串,即第一组\r\n前面表示有效载荷长度的字符串,然后剩下的长度是多长,我们算出来。因为,现在in的总长度,我们是可以知道的,即in.size();现在pos指向的是\r位置,其中第一组\r\n我们也是不需要的,第二组\r\n我们也是不需要的,当然如果包含第二个报文的内容,那更好,即123\r\nxxxxx\r\n12\r\n…,先将前面2组的\r\n长度也不计算在内,所以int surplus = in.size() - 2CRLF_LEN-pos;其中这里的pos就是表示长度字符串的个数哈。那么相减后,剩下的大小surplus就是至少要包含一个完整有效载荷的内容长度哈。
》所以就需要判断一下,if(surplus >= inLen),说明至少包含一个完整的有效载荷,如果不满足if(surplus < inLen),那么就返回空串,输出型参数len = 0不会被修改。
》如果有完整的报文,那么前半部分就是我们说的decode有充当检测的功能的。确认有完整的报文结构,接下来就是,我们现在长度已经有了,那么我们传进来的输出型参数len就可以被赋值了,len = inLen;当然除了给len赋值,我们还得把有效载荷给提出来。
》我们一定也是string package = in.substr(),从我们的\r往后+2就是我们的有效载荷的开头了呀,所以其实位置就是pos + CRLF_LEN,剩下的报文长度,我是不想要\r\n,只想要xxxx部分,那么xxx部分是多大还用算吗?不需要了,因为已经前面算了有多大了,就是inLen大小,即string package = in.substr(pos + CRLF_LEN,inLen),此时,我们的报文是不是就提取出来了呀。
》这就完了吗?还没有,我的报头长度和报文都拿到了,还需要玩什么呢?没必要再往后面走了呀。想多了,你还要再考虑一个问题。我们在用read()读取的时候呢,我们是把读取的数据全部都拼接到inbuffer里面的。但是当我们将其decode出一个完整的报文的时候,那我是不是还要再处理下一次报文呀,那么被提取出来的报文不应该再留在inbuffer里面了。那是不是还要再做一个工作,将我们当前的完整报文从我们的in中移除!不然的话,我们inbuffer里面的第一个报文,永远都是已经被提取出来过的。
》这也算是报文和报文之间要进行协议处理,报文之间不能互相影响。那么接下来的工作,就是将已经提取出来的报文从inbuffer里面移除。
》如果要移除的话,我们就要确认我们的报文长度是多长,那我们应该怎么去移除呢?那我是不是要知道整个报文的长度呀,怎么移除呢?我们int removeLen;你可以自己再算,但是也可以不用再算了,因为移除的长度,无非就是inLen长度,它是不是我们提取出来的报头的长度呀,再加上我们整个提取出来的报文长度package.size(),然后加上2组\r\n呀,即int removeLen = inLen.size() + package.size() + 2CRLF_LEN;此时我就将要移除的数据的长度是多少就算出来了,然后就是调用in.erase()函数,怎么进行移除呢?需要传入要从哪里删除,然后要删除多少,这两个参数,即in.erase(0,removeLen);
》移除工作做完了,我们才进行正常返回,return package;就行了。此时我们就完成了对应的decode()函数,该函数记完成了检测工作,还兼容了对缓冲区的移除。我们只是一次提取一个报文,你自己也可以循环的进行提取多个报文,然后定义一个vector,将package放入vector里面。
》下面我们要对报文进行的就是deserialize反序列化,我们在decode的时候是一整个字符串,当走到deserialize()反序列化,我们是传入的已经被提取出来的一个完整报文了,即“100 + 200”这个样子的了。
》就是你传入的pacakage的完整报文,你必须得是严格按照我的格式要求“x op y”才行。所以我从头到尾,先找到第一个空格,然后再找到第二个空格。找到2个空格之后,就是从0开始到第一个空格,第一个空格到第二个空格,第二个空格到末尾,分3次将数据提取出来。所以我们,#define " " SPACE size_t spaceOne = in.find(SPACE),然后就是判断pos 和 npos,即if(spaceOne = =string::npos)那就说明你要格式不存在,那就说明有问题,那我直接return false;如果第一个空格符合格式,我们再找第二个空格,我们可以从后向前着,那么就可以调用rfind()函数了,即size_t sapceTwo = in.rfind(SPACE),同样判断一下if(npos = =spaceTwo),说明不符合要的格式,就return false;如果第二个空格也符合,那么,我们就可以一个个的将数据提取出来了。
》string dataOne = in.substr(0,spaceOne);string dataTwo = in.substr(sapceTwo + 1),因为我觉得+1可读性不高,所以我们提前宏定义一下#define SPACE_LEN strlen(SPACE),记住用strlen()而不是用sizeof()不然会多出大小。所以 string dataTwo = in.substr(spaceTwo + SPACE_LEN);这样第二个数据就得到了。操作符string oper = in.substr(spaceOne + SPACE_LEN,spaceTwo-(spaceOne + SPACE_LEN));spaceTwo-(spaceOne + SPACE_LEN)意思就是我要截取多少个的大小哈。然后我们必须得保证if(oper.size() = =1)操作符必须得是等于1的,如果操作符不合规,那么就return false;
》接下来就是将数据转化成类内成员,因为我们为了方便,是将成员变量是公开public的,所以x_ = atoi(dataOne.c_str());y_ = atoi(dataTwo.c_str());op_ = oper[0];这就完成了反序列化。
》反序列化完了,我们一定知道,已经将我们的数据都提取出来了,为了后面方便调试,我们给我们的Request类里面加一个方法,void debug(),打印我们的数据。
》我们calculator()函数处理逻辑是传入了我们已经反序列化完的Request类的req对象,然后该函数最后会返回一个Responce对象resp,resp是一个结构化的数据,那么我们得对resp进行序列化,要得出来的是一个respPackage字符串。也就是我们将两个结果数据转成一个字符串,该怎么转呢?
》我们要的字符串就是按照我们的要求,把结果处理好就可以。我们的serialize()函数得是Responce类的成员函数,我们要的呢,就是将result_、exitCode_转成字符串。在形成字符串的时候呢,因为字符串是有长度。我们想要转化成什么样子呢,“exitCode_ result_”就是两个整数,中间用空格隔开,因为我们还会调用encode()函数给他们添加长度,那么对方收到就能知道一次响应的结果有多长,然后再以空格为分隔符,将我们退出码和结果提取出来就可以。
》所以开始将我们的整数转成字符串了,string ec = to_string(exitCode_);string res = to_string(result_);现在已经有了ec、res两个字符串。我们给seralize()传入的是我们需要序列化后的字符串out哈,所以我们将转成的字符串拼接到out上面。out = ec;out += SPACE;out += res;这样序列化就完成了。
》光光序列化还是不够的,序列化呢,你只是将你的结构化数据转成了一个字符串。为了对方收到之后方便提取,你还得添加长度,所以还得到用encode()函数。encode呢,我们需要传入已经序列化后的字符串和该字符串的长度。
》我们知道,我们传入的序列化后的字符串是这个样子的“exitCode_ result_”的格式,我们现在要对其进行encode,那要改成什么样子呢?是“len\r\nexitCode_ result_\r\n”这种样式。
》我们先得到长度字符串,string encodein = to_string(len);然后就是encodein +=CRLF;encodein += in;encodein +=CRLF;然后就是return encodein;这样我们就可以将其发给对方了。所以我们就完成了,网络版本的计算器,服务端的一个基本编写。
》你会发现还是不够,因为Request的序列化你怎么没写呢,encode()你怎么也没写呢。Responce中的反序列化和decode你怎么没写呢?这个是因为,我们刚写的是单独一方的服务端,其实按照我们的主逻辑,是将我们的服务端要用到的接口全部写完了。但是你别忘了,你还有客户端。
》我们客户端ClinetTcp.cc里面,你客户输入了表达式,我们是要将数据构建成一个Request请求的,即Request req;然后调用req.serialize()对结构化的数据进行转成字符串,然后就是要req.encode(),对序列化后的字符串添加字节数。所以我们定义一个string package;我们将其传给serialize()函数,使其得到序列化后的数据。我们还得package = req.encode(package,package.size()),就得到了一个完整的字符串报文,将其发送出去。
》我们发送出去,是不是会得到对方服务器的响应之后发过来的数据呀,那是不是得将服务器发送过来的数据进行读取。读取的操作,我们也可以像服务器那样,同样的处理方式。我们定义一个char buff[1024],调用read()读取的数据放到buff里面,即ssize_t s = read(socket,buff,sizeof(buff) - 1);if(s > 0)说明读取成功,buff[s] = 0;然后将buff拼接到,响应字符串echoPackage += buff;按道理是要和服务器一样这样处理。但是为了偷懒,我们就string echoPackage = buff了。
》然后接下来就要对echoPackage进行解码。解码,按道理我们是不是对响应Responce类进行解码呀。那么我们定义一个Responce对象,Responce resp;然后调用resp.decode()函数。我们decode解码是不是取决于对应的编码,而无论是服务器编码还是客户端编码,我们不考虑他们有效载荷的区别,因为有效载荷肯定是不一样的,Request的有效载荷是3个成员变量,Responce的有效载荷是2个成员变量,所以序列化和反序列化不一样。但是我们解码decode的时候,你是怎么解的?是不是先确认是不是一个薄汗len的有效字符串,然后提取长度进行判断,然后就是确认有效载荷是符合要求的,进行操作,然后确认有完整的报文结构再进行操作,接着将当前报文完整的in中全部移除掉,最后就是正常返回。其实是和我们上面的服务器的编写decode的步骤是一样的。
》所以decode()函数不应该是分别属于Request、Responce类内方法,我们将这个decode()函数单独拎出来。我们请求和响应的报文的格式是一样的,我说的一样,是不牵扯有效载荷,序列化和反序列化肯定是不一样的,但是无论是响应还是请求,都是字符串长度+有效载荷的格式。那么其中ecode()方法对于Request和Responce来说,也是一样的,所以encode()函数也单独拎出来。
》所以继续客户端里面编写,int len = 0,echoPackage = decode(echoPackage,&len);我们有了一个完整的报文之后,我们就对echoPackage进行反序列化,resp.deserialize(echoPackage);反序列化成功之后,我们所要的结果是不是就有了,resp.reust_和resp.exitCode_;
》下面我们就得完成,Resquest的序列化seralize(),序列化的话,一定是x、y、op都已经填好了,和我们上面序列化Responce的一样的,Resquest的序列化完成之后呢,我们还得完成Responce的反序列化工作,对于反序列化呢,也很好写,就是“exitCoide_ result_”。
》我们来编写Request的序列化,在此之前,我们先来看看Request的反序列化是怎么做的。我们当时反序列化是这么写的:我们期望对方发过来的报文是“100 + 200”的格式,你必须严格按照我这种要求来做,所以,提取的时候呢,就是按照这种规定好的格式去挨个进行提取,如果你不规范的话,我方法里面也有逻辑检查。下一个问题,就是序列化我们又该怎么去写呢?
》因为你的格式必须是“100 + 200”的样子,这是其一,其二,记住了,我们现在是假设了一个前提,我们说了,我们ClinetTcp.cc里面,是先定义出了Request的对象req,我们要对req进行序列化,前提条件是我们认为req里面的字段已经被填充了,也就是说,我们Request类里面的3个字段x、y、op已经有了,所以,我们呢已经认为我们的结构化字段中的内容已经被填充,我们不考虑内容是多少,而是他们三个应该怎么序列化。我们可以看到,再定义Request req前面,是我们客户输入的内容,我们要从标准输入里面获得输入内容,然后我们要做的是,根据用户输入的内容构建Request对象req,这时候是真正的填充x、y、op字段的,所以我们还有一段代码还没有写,这个是要注意的。
》我们接下来要做的基本工作呢就是,已经有了,我该怎么去序列化呢?首先我得因为你的参数呢是整数的,所以我得将整数转化成字符串呀,string xstr = to_string(x_);string ystr = to_string(y_);string opstr = to_string(op_);字段都被我们转成字符串了,我们现在就是将它们拼接到我们传入的out字符串里面,out = xstr;out += SPACE;out += opstr;out += SPACE;out += ystr;
》我们clinetTcp.cc读取的时候肯定是能一次读取成功的,因为我们的报文并不复杂,长度也不长,虽然有bug,但是读的话也是能读到完整的报文的。读取后面的decode()函数其实是做了3件事情,第一件事情就是对我们的合法性报文做检查,包括是不是完整的报文检查,再下来呢就是提取一条完整的报文,第三件事情就是要移除提取了的报文。
》我们下面再来写Response的反序列化deserialize()函数,还是要先看Responce的序列化serialize(),序列化很简单,就是两个整数,然后用空格将它们隔开的。然后,我们就要进行提取,我们这个提取比之前要简单的多。我们要做的就是将字符串转化成两子串,然后将其填充到成员变量字段里面。
》所以,我们先进行定点寻找分隔符,size_t pos = in.find(SPACE);紧接着就是判断if(npos = =pos),没找到就只能return false;找到之后呢,根据我们格式的要求,就是“exitCode_ result_”所以pos指向的是空格,exitCode_后面一位。那么string codestr = in.substr(0,pos);string resstr = in.substr(pos + SPACE_LEN);因为,我们说了,我们clinetTcp.cc的读取为了简便,就是没有将收到的buff拼接到inbuffer里面,认为读取一次就能将服务器发来的字符串读完整。在取res的时候就只是给了从哪个位置开始取子串,没有给出取多长,默认就是npos大小。
》既然将一条完整的字符串,分出了我们想要的结构化数据,下面就是将反序列化的结果写入到内部成员中,形成真正的结构化数据。所以我们就exitCoide_ = atoi(code.c_str()) ;result_ = atoi(resstr.c_str());
》我们现在的Request的对象req已经定义有了,用户输入的字符串也有了,我们前面不是说了嘛,当用户输入完了,我们其实就应该将用户输入的数据填充到Request对象里面的成员变量里面的。本来是说,用户必须得是“1 + 1”要带空格输入的,但是算了用户输入就“1+1”这个样子就行了。
》那么,我们现在得再来一个接口makeRequest(),就是用户输入了一段字符串,我们要的是,将你输入的字符串,将其构建成一个请求,这个请求呢,最终就是x是啥、y是啥、op是啥。请求构建完成了之后,再进行我们的后续的序列化和反序列化等一系列工作。所以我们现在来编一些makeRequest()接口,bool makeRequest(string& str,Requestreq);“1+1”构建成一个结构化数据,我们怎么处理呢?
》也是一样,可以对字符串呢,做相关的提取。那么也是要根据特定的分隔符来进行提取子串。我们呢就用C语言对应的strtok()函数来进行切割,切割完成之后,哪一个字符,我们将其操作码提取出来,所以我们可以直接先#define BUFFER_SIZE 102,再char strtmp[BUFFER_SIZE];我们调用snprintf()格式化输入,snprintf(strtmp,sizeof(strtmp),“%s”,str.c_str());现在就已经有了用户输入的数据了,然后我要提取它的数据。因为用户输入可能是1+1、11等,所以操作码不确定。那么我们分隔符在提取的时候怎么去分割它们呢?我们定义一个charleft = strtok(),strtok()可以指定分割符,是可以传入多个的哈。第一个参数,我们要分隔的字符串是strtmp, 第二个参数传入我们要分割的字符是哪些,我们将要分割的字符宏定义一下,#define OPS ±/%,即charleft = strtok(strtmp,OPS);对我们来讲,用户输入的字符里面必须得是左右两边必须得有数据的,如果你left为空NULL了,if(!left)return false;如果获取子串成功,这是第一次提取,我们也不处理。接着,charright = strstok(nullptr,OPS);第一次是提取左边的操作数,第二次提取操作数的右边,如果你right为空NULL,那么也是不正确,那么直接返回false了。
》那么接下来要提取操作符是什么了。我们是可以去扫描,因为用户输入的字符串,操作符的左半部分一定是0~9字符或者负数就有“-”这个符号,不会出现除此之外的符号,所以可以从左向右遍历,因为可能用户输入的是负数,所以我们最好是从第二个字符开始遍历,所以就不需要单独考虑负数的符号“-”了,然后遍历的时候直到碰到不是数字的时候就跳过,这是一种做法。当然,你已经把left都得到了,那么远是字符串紧跟着不就是操作符打头的字符串嘛(要去了解一下strtok()函数!)其实严格来讲,用户可能就是喜欢在输入的时候添加空格“1 + 1”,那么我们其实还得在用户输入完之后,加一个清理函数trimStr()。
》所谓的清理什么意思呢,就是,用户可能输入“1+1”是我们要的标准格式,但也有可能“1 + 1”带有空格,或者“1 +1”,等等各种穿插空格的情况。那么我们得将其中的所有特殊字符都要请理掉。说麻烦也不麻烦,就是遍历,就是碰到特殊字符,就将其erase()掉就行了,或者干脆,重新定义一个字符串,只要不是其他的特殊字符,就将其+=到新字符串里面,否则一概不要。这个呢,我们就不处理了吧。 所以算了,我们就不搞trimStr()函数了。
》我们继续来接着我们分割的思路。我们也清楚strtok()函数,它就是将你分隔符设置为"\0",那么前面就是一个子串,后面就是一个子串。所以呢,我现在要提取这个操作符,我们在此之前是调用了snprintf()函数,将我们的str临时保存在我们的strtmp里面,也就相当于做了一个副本,因为strtok()会对传入的字符串做修改,因为strtok()函数将我们的分隔符全部改成"\0"了,我们做了副本之后,我们的str是没有变的。那我们已经提取了操作符的左边数据和右边数据,我们现在就可以再根据我们原来的字符串来进行找分割符,char mid = str[strlen(left)];这个mid指向的就是我们原字符串操作符位置,那么也就拿到了操作符。现在所有的字段,我们都拿到了,就可以构建我们的Request了。
》req->x_ = atoi(left);req->y_ = atoi(right);req->op_ = mid;至此,我们就完成了构建Request对象这么一个结构体了。也就是,用户输入数据后,我们makeRequest()函数构建了已经填充好的Request对象,那么makeRequest()走到最后成功了,就返回return true;也就相当于,用户你输入完之后,我紧接着就构建好了一个Request请求对象。其实我们的makeRequest()也是一个反序列化的工作,它是不是将我们用户输入的字符串,转成对应的结构化数据呀!所以,说白了,这也是一个反序列化工作。
》所以,要记住一点,反序列化呢,不仅仅是在网络中应用,本地也是可以直接使用的。就比如说,我们今天是将用户输入的内容,我们自己闲着没事干,将其反序列化,将输入的数据构建成了一个结构化数据,这是从标准输入里面去做的。比如说,我现在想写一个通讯录,它是不是就有结构体呀,实际上呢,我们可以做持久化,来进行保存。你们以前是怎么写的呢,是直接把结构体的二进制文件直接写到了文件里面。今天,你也知道了,二进制的文件大小,直接以二进制写,万一你的软件升级了呢?比如你现在有一个一年之前保存好的通讯录数据,一年之后,你将代码改了,结构体什么的,甚至编译器都变了, 对齐规则和大小都变了,你直接写到对应的文本文件的二进制内容,你再读就读不出来了。也就是说,你只要软件变了, 那么文件的内容你也就读不出来了,所以你不应该那样去做。当然,不是不行,但是你必须得定制协议。也就是说,你得将你通讯录当中的每一个字段,你也要按照特定的协议,然后给他写到文件里,因为你用的是协议,所以你后面软件在改的时候,也不会影响,因为协议你很少改,你软件再怎么修改,我们读取的时候也能够很好的做兼容。结论就是,不要觉得序列化和反序列化只存在网络当中,网络也是文件呀,Linux下一切皆文件!我也可以将内容序列化到文件当中,然后再从文件里面将其反序列化出来,这就完成了数据保存和数据恢复的工作。其实,序列化和反序列化在哪里都是可以的。
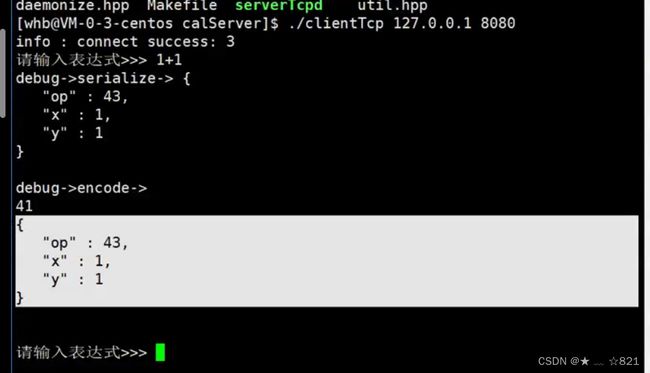
》我们的Request对象构建好了,下面的其他接口也都完善好了,就可以开始我们的测试了。我们客户端给服务端发送1+1的时候,我们在客户端的输出窗口中得到的是 1 43 1,这是为什么呢?因为➕号的Acicall码值就是43。然后给我们打印的debug->encode显示的是6,6是1、空格、43、空格、1加起来是6个有效载荷长度。现在关键是没有响应,肯定是我们的代码当中有一点问题。
》为什么是显示的➕变成了43呢,是因为string opstr = to_string(op_)的时候,op_是char类型,char呢从属于int类型,所以就转成了43,那么就将整数的43转成了字符串“43”了!因为我们的string既支持+=string,也是支持+=char的。所以改成out += op_。
至此我们完成我们代码的第一个阶段,叫做,手写自定义协议。但是总觉得用自己定制的协议比较low。协议呢,添加报文长度是必须的,我必须得保证我读取到的是一个完整的报文,但是我觉得序列化和反序列化那里写的比较低端。我们也看到了,我们手写序列化和反序列化的过程,格式化、空格等,挺麻烦的,所以呢,我们可以把有一部分工作交给比较成熟的解决方案来处理,就是序列化和反序列化的部分。序列化和反序列化部分,我们在写的时候,要注意,encode和decode()是你必须自己去做的,这个呢是没办法的,因为你必须保证读取IO没有问题。关键在于,你把它解决出来之后,我们序列化和反序列化写了很多。倒不是说它有问题,而是稍微有一点点low,那怎么办呢?所以,我们可以不用自己花那么多时间去序列化和反序列化。
》我们可以部分采用别人的方案,这个解决方案,目前比较主流的有xml、 json、protobuf等,有很多的解决方案,不过我们呢, 用最好玩的,可读性最强的josn。所以,我们压根就不需要自己手写序列化和反序列化,我们直接用josn就可以搞定了。那我们应该怎么弄呢?
》你要用josn,你得保证,因为josn是一个独立的第三方库,所以你得保证你在你的云服务器上安装了对应的库,那怎么安装呢?------sudo yum install -y jsoncpp-devel
》我们安装好库之后,我们可以宏定义一下,#define My_SELF 1;就是为了给我们选择是用我们自己写的协议还是用json给我们提供的库文件。在我们的protocol.hpp中添加条件编译,#ifdef MY_SELF #else #endif,意思就是说,如果我们定义了MY_SELF,那么序列化的方案,我们就采用自定义方案,否则的话,我们就调用#else下面json写的。同样的,在反序列化deserialize()里面也添加条件编译。
》下面我们把json带进来,json的版本比较多,如果想多了解的话,可以去jsonCPP的官网或者查找一下jsonCpp相关的资料去学习。我们想要使用的话呢,我们的json安装之后,头文件是在,/usr/include/jsoncpp/json;库文件是在/usr/lib64/libjson。
》所以我们在protocol.hpp里面这样包含:#include
》填充好了之后呢,我们下一步要做的就是序列化,那我们就又需要定义json::FastWriter fw对象。这个对象有点像什么呢?你可以将填充的字段,如root[“x”] = x_等看成一个unorder_map,现在要做的呢就是,用FastWriter对象想把法将root对象写成字符串,所以怎么写呢?fw.write()方法,给write传入的参数呢,就是你刚刚填充好的root对象,即fw.write(&root);返回值,就是序列化后的字符串了,我们直接
》因为,我们曾经有过序列化的经历,虽然,不懂它,但是我们是能够理解他的。我反正知道,不管你怎么做,你将来得让我序列化成一个字符串,完了之后,还得方便我提取,对不对,所以下面继续deseralize(),进行反序列化。
》deseralize()反序列化该怎么写呢?我们一样的,得要有一个中间类型json::Readr rd;然后rd里面有一个parse()方法,第一个参数呢,就是你要进行反序列化,那么你就得告诉我,你想进行反序列化的字符串是谁,这个字符串呢,将来一定是经过decode之后提取到的json字符串,所以,我们要进行反序列化的话,数据源就直接从in里面拿就行了。你像我们上面自己写的字符串in呢,就是通过我们对应的in,从它里面提取出来的,所以,我们在填充参数的时候呢,第一个参数就是in字符串;第二个参数,就是一个输出型参数,我要把字符串结果再把你转成json:;Value,那么直接就是传对应的root;即rd.parse(in,root);至此我们就完成了反序列化。反序列化之后的结果在哪里呢?结果是在我们的Value对象的root当中,可是我们要填充的是x_、y_、op_呀,怎么办呢?我们直接反序列化完成之后,我们叫做x_ = root[“x”];因为你曾经在设置root的时候,你是以KV的形式设置的,那你接下来提取参数,是不是得告诉我,你要提哪一个参数,对不对。因为你提取的时候。root[“x”]全都是字符串,这个字符串可能是把曾经的float、double等类型转成了字符串,当你要提取的时候,root[“x”],提取出来了, Value是字符串,那是不是还得转回我们原先初始化的类型呀!所以x_ = root[“x”].asInt();这样我们就简单的,将x提取出来了,那么y_怎么提取呢,一样,y_ = root[“y”].asInt();op_ = root[“op”].asInt;至此,我们也就完成了反序列化。
》我们接着来写Response的序列化。json::Value root;root[“exitCode”] = exitCode_;root[“result”] = result_;我们依旧是out = Json::FastWriter fw;fw.write(root);就这样序列化就搞定了。
》反序列化呢,Json::Value root;Json::Reader rd;rd.parse(in,root);exitCode_ = root[“exitCode”].asInt();result_ = root[“result”].asInt();至此完成了反序列化工作。
》我们在进行测试的时候,发现编译的时候链接不通过,那是因为,我们用到了第三方库,你得在Makefile里面这样写g++ -o $@ $^ -std=c++11 -l jsoncpp,才可以的哈。一下图片就是我们用json之后的序列化的打印。
我们上面用的是json的FastWriter对象,为什么用FastWriter对象呢,因为它给我们序列化之后的字符串是一行,比较好看。然后呢,但实际上可读性还有一种就是我们的Json::StyledWriter,使用上呢,没有任何区别,只不过显示的话呢,是以更加人性的方式去显示,它会给你将KV字段以行为显示。
我们protocol在写的时候,encode和decode是和Request和Responce无关的,它直接就是根据传入的字符串,以前传入的是你自定义协议之后的字符串,现在又变成了,你用json协议之后的字符串。只要我们一开始用自己协议之后的字符串传入能够成功,那么json协议之后的字符串也是一定能够成功的。
》很明显,我们想要切换我们底层的序列化和反序列化方案,我们就只要改宏就可以进行切换了。最好的就是,我们想要改成哪一个方案,就很容易变成想要的方案,这是什么呢?这其实就是一种软件解耦。就是你上层的逻辑,和我下层的解决方案,虽然在数据上面有耦合,但是在方案层面上,我们是分开的,这是最好的。
》我们除了在代码里面修改我们的宏来选择方案,我们也可以在我们的Makefile里面进行处理。我们在Makefile里面添加Method=-DMY_SELF(—D选项是命令行式的定义宏的意思),然后在我们的方法指令上面稍微修改一下:g++ -o $@ $^ $(Method) -std=c++11 -ljsoncpp。现在呢,我们已经在命令行上将我们的宏已经定义好了, 我们在实际上编译的时候,它默认的就是采用MY_SELF方案,如果我不想用自己的方案了,我们只要打开Makefile,将我们的Method=-DMY_SELF中的-DMY_SELF注释掉,即Method=#-DMY_SELF,这样Method就是空了,那么就没有这个选项了,此时就变成了json的方案。
》所以,我想说的是呢,以后我们可以选择这样的方式去自由选择我们底层的方案,不需要再改源代码了,直接在Makefile当中添加宏就可以了。 那么-D就相当于是可以在命令行上面的定义宏的方式。我闲着没事干,我为什么要将宏定义放在Makefile里面呢, 我自己改源代码也是可以的呀。但是,你应该会发现一个问题,当我们去编译一个软件的时候,它会自动根据我们当前的系统,对我们的代码做自动化裁剪。比如说,我们要进行编写项目,项目代码既在windos下面跑,又在Linux下面跑,所以,它底层就是拿条件编译完成的,那它怎么知道,我们是windows还是Linux,是x86还是64呢? 所以,实际上在他的源代码充斥着大量的条件编译,但是呢,实际上在编译的时候,不能把宏定义放在源代码里面,而是应该在Makefile这里,它里面也有一些功能识别你的平台是什么,是多少位的,然后设置对应的选项,然后再把参数设置好之后,再用gcc、g++使用定义好的宏,再进行代码裁剪,所以,我们这种方案,就是一整套的裁剪的整体解决方案。我只是为了让大家能够在理解别人的项目,经常看到别人也有条件编译,它是怎么做的呢,实际上呢,他将条件编译写好,写好之后,它把宏定义不放在源代码里面,而是放在编译gcc、g++的选项里面,最后呢,就可以自由的裁剪内容了。
》至此,我们的全部的序列化和反序列化全部讲完了哈。再总结一下。为什么要,手写一次,再去采用别人的方案呢,为什么呢?第一、手写之后能够感觉到,摒弃掉我们对序列化和反序列化的恐惧感这是第一;第二呢、我们能够感受到它的不容易,我们今天的场景仅仅是一个计算器,那如果场景更加复杂呢?这个序列化和反序列化,那如果有大量字符串提取操作呢?那是不是也太麻烦了,所以,序列化和反序列化并不简单。我们也通过手写的痛苦经历,能够感受到,站在巨人肩膀上的快感,也就是用别人的方案呢,我们很快就能做出东西,这就是在对比之下,能够感受到谁优谁劣哈。
》我们代码讲完了,就要进入下一个阶段了。这份代码很有意义,能够帮组大家承上启下,下面呢,我们进入到下一个阶段了。我们再回过头看看协议,什么叫做约定呢,这你就理解了。从我们的通信角度呢,你怎知道你的报文能完整地被对方收到,你怎么知道出现部分报文的时候你还得再继续读,保证你读取的是完整的报文?那是不是我们自己定义的协议,我们的协议格式就是“长度\r\n有效载荷r\n”这是第一;第二就是,我们在业务上也有协议的字段,有x、y、op、exitCode、result,这些字段,我们都叫做协议,双方通信的时候,是都有的。现在我们再理解协议,协议就是一种约定,各位同学不能再是脑子一懵,不知道在说啥了哈。现在应该已经知道,我们就是在逻辑上做好约定就可以了。
SeverTcp.cc
static Response calculator(const Request &req)
{
Response resp;
switch (req.op_)
{
case '+':
resp.result_ = req.x_ + req.y_;
break;
case '-':
resp.result_ = req.x_ - req.y_;
break;
case '*':
resp.result_ = req.x_ * req.y_;
break;
case '/':
{ // x_ / y_
if (req.y_ == 0) resp.exitCode_ = -1; // -1. 除0
else resp.result_ = req.x_ / req.y_;
}
break;
case '%':
{ // x_ / y_
if (req.y_ == 0) resp.exitCode_ = -2; // -2. 模0
else resp.result_ = req.x_ % req.y_;
}
break;
default:
resp.exitCode_ = -3; // -3: 非法操作符
break;
}
return resp;
}
// 1. 全部手写 -- done
// 2. 部分采用别人的方案--序列化和反序列化的问题 -- xml,json,protobuf
void netCal(int sock, const std::string &clientIp, uint16_t clientPort)
{
assert(sock >= 0);
assert(!clientIp.empty());
assert(clientPort >= 1024);
// 9\r\n100 + 200\r\n 9\r\n112 / 200\r\n
std::string inbuffer;
while (true)
{
Request req;
char buff[128];
ssize_t s = read(sock, buff, sizeof(buff) - 1);
if (s == 0)
{
logMessage(NOTICE, "client[%s:%d] close sock, service done", clientIp.c_str(), clientPort);
break;
}
else if (s < 0)
{
logMessage(WARINING, "read client[%s:%d] error, errorcode: %d, errormessage: %s",
clientIp.c_str(), clientPort, errno, strerror(errno));
break;
}
// read success
buff[s] = 0;
inbuffer += buff;
std::cout << "inbuffer: " << inbuffer << std::endl;
// 1. 检查inbuffer是不是已经具有了一个strPackage
uint32_t packageLen = 0;
std::string package = decode(inbuffer, &packageLen);
if (packageLen == 0) continue; // 无法提取一个完整的报文,继续努力读取吧
std::cout << "package: " << package << std::endl;
// 2. 已经获得一个完整的package
if (req.deserialize(package))
{
req.debug();
// 3. 处理逻辑, 输入的是一个req,得到一个resp
Response resp = calculator(req); //resp是一个结构化的数据
// 4. 对resp进行序列化
std::string respPackage;
resp.serialize(&respPackage);
// 5. 对报文进行encode --
respPackage = encode(respPackage, respPackage.size());
// 6. 简单进行发送 -- 后续处理
write(sock, respPackage.c_str(), respPackage.size());
}
}
}
protocol.hpp:
#pragma once
#include Makefile:
.PHONY:all
all:clientTcp serverTcpd
Method=#-DMY_SELF
clientTcp: clientTcp.cc
g++ -o $@ $^ $(Method) -std=c++11 -ljsoncpp
serverTcpd:serverTcp.cc
g++ -o $@ $^ $(Method) -std=c++11 -ljsoncpp -lpthread
.PHONY:clean
clean:
rm -f serverTcpd clientTcp
我们刚刚写的网络版本计算器,你可以理解成,我们写的是应用层。有三件事情,我们是做了,1.基本系统的socket接口使用;2.定制协议;3.编写我们对应的业务。
》那么有没有已经非常成熟的场景,全世界人民都要用的场景呢?有程序员自定义协议,并且写的还不错,被所有人接受,最后这套协议就成了一套标准,成了应用层的特定协议的标准。就拿我们刚刚写的网络版本计算器,假设我们写的还不错,后来还有很多的人要用,可以的,但是你必须得按照我的标准,比如说我的协议必须得是整数\r\n有效载荷\r\n,序列化和反序列化的字段必须得是x、y、op,结果必须得是exitCode、result,你必须得遵守我的协议,那么遵守我们的标准,就诞生出了很多写好的应用层协议了,就能被别人直接使用了。
》比如说http、https等等协议都是被用的比较多的。所以,我们必须得清楚,我们下面呢,要学习应用层协议,学的就是别人定制应用层协议的细节。就好比,你今天把你的代码写完了, 给别人了,你说,你能不能学一下我写的定制协议的过程,那么别人不看你的源代码,它只看你的protocl.hpp这样的头文件,然后把你的方法看懂,那么协议就能看懂了。所以呢,我们就先来讲应用层协议http、https为主,这一块非常重要。
》个人觉得应用层、TCP层,像IP层和MAC帧层,那其实就是让我们理解原理,对于我们来讲,最重要的就是应用层和传输层这两层协议,能够做出东西才是最重要的!所以呢,我们自顶向下,先来讲http协议。

HTTP协议
http更多的是在我们网页的获取上面,当然,为什么应用层那么多协议,我们就挑http来讲呢?因为http的用途太广了 。有人说,我现在,在电脑上访问,我经常可以随便访问一个网站,你可以发现,比如说,访问百度、qq它们的网站,全部都是http,有人说,不是后面带了s嘛。但是大概在2008年之前,我们的互联网处于草莽阶段,除了像银行会采用单例模式,其他的互联网公司基本上都是http,但是现在,基本上都是https ,所以,我们http会讲,我们https也一定会讲。
》所以,我们先讲http有一个概念。有人说,我们怎在手机上面没有见过,那是因为手机上的网络请求或者链接,全部都给你隐藏了。你打开哪个app就是帮你连接了它的服务器了,是不会出现链接的。当然,也有分享内容,转发的是什么呢?其实,说白了就是链接,只不过app给你进行了图片化处理,让你看起来是一个图片,它底层全都是https。所以,我们整个互联网的应用层世界,都是用由https构建的,这是其一;
》其二,我们也有一些特殊应用,它是自定义协议,我这么告诉你,在自定义写协议当中,在应用层有相当大的一批协议呢,是模仿http定制的协议的。所以呢,你说http协议重要不重要呢。应用层http+https几乎是应用层最具代表性,没有之一。
》我们认识http,就得先来认识一下URL。
认识URL

一般呢,我们的网址包含的就是http、https,然后就是://+登录信息,但是从来没见过呀,也没有登录过呀,我看到的全都是手机扫一扫或者账号登录了。你记住了,现在所有的应用端,让我们很方便去登陆,底层全部都是http,只不过会给你做相关的转化罢了,所以登录信息会被省略,我们全都是用http网页方式,让用户去输入账号密码,然后再去登陆,这个登录信息,已经是以特定的方式,比如说是在请求报文当中,发送给我们对应的服务端的,所以对我们来讲呢,登录信息这个字段我们不用考虑。
》再下来呢,就是我们的域名,比如www.com。再下来呢,就是服务器端口号,端口号呢,现在肯定不陌生了,一个服务呢,要绑定端口号,我们写的所有服务器内容都是需要端口号的,端口号呢,也是需要在URL当中出现的。那么为什么得必须要有端口号呢?你一定要记住这句话,域名,比如说www.com,域名就是我们的www.com这种,就是我们的域名,当域名在进行我们对应的访问网站的时候,它必须被转化成为IP地址。访问网络服务,服务端必须具有端口号port!
》你信誓旦旦的给我说这个结论,是凭什么呢?因为我们现在懂了,网络通信了里面,我们都是套接字通信,所以网络通信里本质就是:套接字socket通信,就是IP + Port。所以呢,域名必须得被转化成IP地址。当然转化过程,你不用管,也是浏览器+一个服务,叫做DNF服务来给我们做域名解析。然后端口号这个字段呢,我们有一个问题。那么,你告诉我,一完整的URL当中呢,必须得包含我们对应的端口号,但是,我怎么没在网址上见到呢?你的www.baidu.com怎么没有带端口号呢?比如说,我搜索中国:https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&tn=84053098_3_dg&wd=%E4%B8%AD%E5%9B%BD&oq=%25E4%25B8%25AD%25E5%259B%25BD&rsv_pq=b49cce810000a212&rsv_t=562c2WPRH%2FlDVBJT0Us0fDSgdzmFgQPQSlBtcPL8XnjCfjbcmORnNzmuiowrWj2vYpOLqg&rqlang=cn&rsv_enter=1&rsv_dl=tb&rsv_sug3=11&rsv_sug1=4&rsv_sug7=101&rsv_sug2=0&rsv_btype=t&inputT=1478&rsv_sug4=1767。也没有见到什么端口号呀。你说域名必须会被转化成IP地址,我先暂且接受了,具体后面再谈,现在问题就是,域名对应IP地址,我们的网络服务必须得具有端口号,但是,我并没有看到端口号呀。
》不见端口号的原因是,在使用确定协议(是我们常见的,http、https、smtp等)的时候,我们一般显示的时候,会缺省我们所对应的端口号,说白了,就是把你的端口号忽略了。它所谓的缺省是在URL上面,包括你分享的链接上面,它不用再带上端口号了,并不代表,它发送请求的时候没有,是有的!也必须得有。什么意思呢,就是说,我们在给别人分享链接呢,是没有端口号的,但是,当任何一个浏览器,或者手机app收到了一个链接,在点击的时候,就有浏览器或者你的app必须得给你自动添加上端口号,只不过没有在我们的URL上面体现出来。
》说白了,就是我们自己肉眼看到的URL,大部分用的是没有端口号,我们在请求的时候,我们的浏览器它是自动给我们添加的,域名转成IP地址之后,再加上端口号,那么IP地址 + 端口号Port,然后才能发起connet,没有这个工作的话你别想通信,那是不行的。
》这也就衍生出第二个问题,第二个问题就是,浏览器它怎么知道我的端口号是多少呢?你浏览器要自动添加端口号,你怎么知道我的端口号是多少呢?所以呢,浏览器在访问指定的URL(统一资源定位组)的时候,我们确实看到URL本身没有带端口号,但是浏览器必须得给我们自动添加Port,如果没有Port,当然域名对应的IP得有,没有Ip、Port,你这个客户端是没有办法去访问服务器的。我们也写了这么多的服务器了,我们写的都是命令行的,但是呢,你现在看的是图形化界面或者app,但是它底层必须得有这个东西,没有这个东西它走不起来的。所以,它得自动添加报头,那么现在的问题是,浏览器如何得知,我们对应的URL匹配的Port是谁呢?你为什么给我加特定的端口呢?这个我们回忆一下,这个很好解决,因为特定的纵所周知的服务,端口号必须得是特定的!也就是说http对应的server必须得帮我们绑定端口号->80,https绑定的端口号是->443,这就是服务和端口了必须得是绑定的、确定的。
》有人说,不对呀,你给我演示的端口号,换的很勤快呀,一会儿8081,一会儿8080等。那是因为,我们在做测试,一旦你服务上线,端口号是必须确定的。我们曾经讲过,我们用户自己写的网络服务bind端口的时候,你只能bind 1024之后的端口,因为1024之前的是给特定的服务使用的!你把别人占了,就会导致别人启动不了了,所以,有时候,这些端口是不会让你去绑定的。
》它们两者之间的关系呢,一个特定的服务和特定的端口之间的关系,就好比110和警察的关系,119和我们的火警关系等关系一样,它们是强绑定的。所以你怎么去标定一个协议的成熟呢?你就看操作系统和整个网络的生态,有没有给你的服务留端口,如果没有给你留端口,那么就说明你的应用不算特别成熟。有人又说,我们经常用的mysyql3306、redis3379这些端口也是1024之后的呀,这个确实用的是1024之后的,但是呢,这些端口号也是被全世界人民都知道了,一般这些端口,我们也是不会轻易去使用的。只不过,我们用的1024之前的端口呢,太成熟了,相当于被使用的最广泛最基础的服务,整个操作系统或者云服务器说,你要用这个端口不行,我不能让你使用。当然可以试试在虚拟机里面能不能绑定。所以,我们URL里面的端口号也是可以被省略的!因为,我们前面有协议字

段,所以我们端口号是可以被省略的。
》有了IP地址可以确认主机,有了端口号就能确定那个服务,那么http是做什么的,我们重新理解一下http是干什么的。我们只清楚了URL的前半部分,我们要来搞一搞http是干什么的。
》一般在我们的浏览器或者手机App上,你一般都是干什么?以浏览器为例,你可不可以查阅文档呢?比如说,我看了一个网上的教程,或者在CSDN上看了一篇文章,这是查阅文档。我们还可以观看音视频,就相当于有些听音乐、视频等。
》它们的呈现方式都是以网页的形式,说白了网页就是一个最基本的.html文件。无论你是什么,当你浏览器发起请求的时候,我们的服务端有一个文件,比如说网页文件,你浏览器请求的时候,我把网页返回给你。网页文件有内容,那它是不是也是数据,所以本质上,我们请求一个服务时,我们本质上也是进程间通信,说比啊了就是套接字嘛。所以,它把文件内容,打开文件,然后把内容读取到内存里面再给我们发过来,然后我们的浏览器就能收到它了。换句话说呢,我们就可以通过获取网页的方式来得到我所想要得到的东西。
》所以,最终,我们永远清楚一件事情,**http–是获取网页资源的,视频、音频等也都是文件!!所以我们浏览器可以请求的资源呢,目前像文件、图片、视频、音频等所有的资源呢,我们可以称之为http是向我们指定的服务器申请特定的资源的。**像我们今天,把所谓的网页文件、图片文件、视频文件等我们统称为资源。http呢,核心目标是申请特定的资源,把资源获取到本地,本地可能是你的app、浏览器、迅雷等等,拉取到本地进行展示或者使用的,这就是http协议。
》人家官方叫法,叫做超文本传输协议,那么他为什么叫做,超文本传输协议呢?网页就是文本的,为什么叫做超文本呢? 超在哪里呢?超就超在,他可以传图片、音频等等。按照今天,我们曾经对网络代码的编写,对于一个数据如何发给客户端,我们肯定能过理解,一个文件发给客户端,你们也能理解!说白了就是,在我们的服务端,你要访问哪一个文件,我把文件给你打开就行了,然后把内容给你读取出来,然后把内容发给你就行了,这一定是能过理解的。
》但是忽略了一个问题,无论是网页、图片、音频、视频,**如果我们clinet没有获取的时候,资源在哪里呢?**比如说,你想去腾讯视频看电影,你没看的时候,资源在哪里呢?还能在哪里呢,你自己部署的服务,在你的服务器上,那么资源也就只能在这个服务器上呀,你不在服务器上,我怎么去获取和打开呢,所以,这个虽然是一个常识性的东西,但往往会被我们所忽略。所以,很简单,**资源就在你的网络服务器所在的服务器上(硬件,计算机上)。**比如说,优酷经常上一批新的电影,它没有上线之前呢,它的电影在版权商上面, 买过来了呢,就将版权给了优酷了,优酷是不是就可以将视频文件上传到服务器上,部署对应的网络服务,那么就可以将资源打开之后发给你了,我们就这么理解。
》那么,**服务器都是什么系统呢?Linux系统!那么请问,在我们Linux系统上,这些资源是文件呢? 有的资源呢,有图片、视频、音频、网页等,这些是文件吗?全部都是文件,那是文件就能够被打开,无非是文本打开,还是二进制打开。那么,既然是文件,我们就得出一个结论,叫做,资源文件在我们的Linux服务器上,那么当我们后续有人请求的时候,我们的服务呢,想把文件打开,你是不是要把文件打开 ,比如说,自己写了一个网络服务,bind、listen等都搞定,搞定之后呢,别人想访问html,它要得到html,那么我服务端是不是要将文件打开,打开之后,用read读到我们的内存里面,然后再write给别人写回去,所以资源文件在服务器上,我是不是得打开。所以,我作为服务器,我得先打开这个文件。
》所以要打开资源文件,读取,发送给我们的客户端,一切一切的前提是,软件服务器必须得先找到这个文件。**你连文件都找不到,谈何打开文件呢,是不是!请问Linux下要找到这个文件,如何找到呢?根据路径!所以,我们可以通过在机器上使用路径找到这个文件呀,找到之后就能访问这个文件呀!
》当我们知道了,在访问我们服务器上的某一个资源,它一定要有路径的,所以我们URL后面的部分会跟上/dir/index.html等其他相关的信息。www,example是机器,80是机器上的服务,/dir/index.html这个是我想在该机器上在该路径下,用该服务,将这个资源给别人返回去,所以这个叫做资源路径。这就是URL后面会带上这个的原因。所以你有没有发现,有带上“/”呀,随便翻其他网页都是会有的。因为“/”是Linux下的路径分割符,这个也证明服务是部署在Linux服务器上的!
》那么路径的第一个"/“是不是就是根目录呢?答案是:不一定!因为你也懂,访问某些文件是可以用绝对路径访问,也可以用相对路径访问,所以最开始的”/"呢,可能是以根目录开始,也可能从某个特定路径开始,怎么做的后面会说。
》http人家官方说法叫做超文本传输协议,重点是可以获得各种各样的资源。我们呢,给资源下了一个定义,我们在Linux当中呢,以后站在网络视角上,Linux服务器上的所有东西都称之为资源,无论是图片、音频、视频、网页等,我们都叫做资源。所以http说白了就是从本地向服务端获取资源的,这就叫做http协议。虽然我们http一行代码没写,其他理论基本也没讲,但是我们心里其实也已经很清楚了。他这个资源呢,通过网络服务器呢,收到之后就可以在本地,根据它传来的,要访问什么资源,既然路径已经给我了,那么我直接打开之后,然后再发给他,这就叫做http。
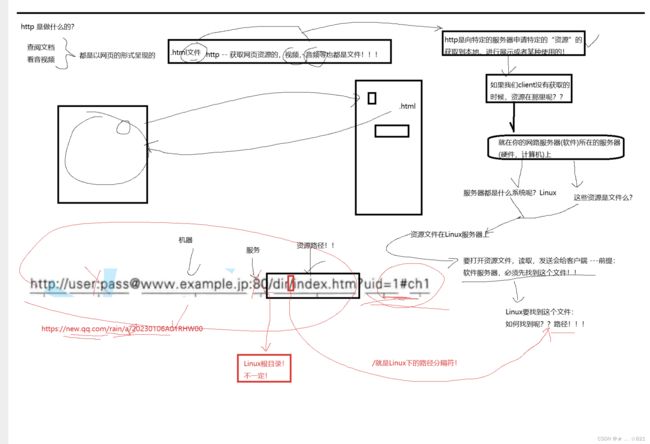
实际上,在我们进行网络请求的时候,因为我们是中国人,用的是汉字。如果,我想通过http协议去传输URL你本身的一些字段呢。比如说,你URL里面的特殊符号,比如?等,我也想要在URL当中传输其他符号,一些特殊符号本来就是在URL当中有特殊用途的,那么我该怎么去处理呢?总不能再加上特殊符号,把我的特殊符号以字面值的方式放在后面,那这样解析URL的时候就出问题了,我们用的是一些汉字,另外有些汉字也是需要给你重新编码的,所以我们就有了urlencode和urldecode。
urlencode和urldecode
关于urlencode和urldecode这两个概念呢,我们之前给大家讲的时候,主要是给大家用来做协议处理的,我们也说过,协议处理的字段比较简单,有时候要传输的字段呢会包含一些特殊符号,这些特舒服好在进行我们URl传送的时候,我们需要把这些特殊符号进行一定程度上的编码,这些编码呢体现在哪儿呢?
》假设我今天要搜索C++,然后对应的会跳出网页会有对应的URL,那么我们复制出来,我们可以看到,https://www.baidu.com/s?wd=C%2B%2B&rsv_spt=1&rsv_iqid=0xea23843c0007f2f0&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_dl=tb&rsv_enter=1&rsv_sug3=14&rsv_sug1=5&rsv_sug7=101&rsv_sug2=0&rsv_btype=i&inputT=3759&rsv_sug4=5154。前面https是协议,然后www.xxx.com是域名,然后加上我想访问资源的路径,后面还跟着一些以&符号隔开的信息字段,其中这些就是通过URL的方式来向服务端传参,其中就包括有KV式。我们再搜索一下CPP,再粘贴URL,其实大部分字段是差不多的,唯一差别会在下面的图中用方框括起来。
》那么百度怎么知道你要搜索什么东西呢?除了你URL一大堆的属性信息,kV值传给了我们的百度,最重要的就是wd,wd就是word的简写,你要搜索的关键字是什么,然后C%2B%2B,另一个是CPP,两者有一些区别。原因是,一个我们搜索的是C++,一个我们搜索的是CPP。什么意思呢,意思就是说,我们实际上发起我们http请求的时候,有些字段是需要给我们进行编码的,记住,编码不是加密,而是将我们有些字符进行编码。因为有些符号呢会在URL里面出现特殊符号,+号就是一种特殊符号,所以你C++发出去的时候,就会给你重新编码了,那么CPP呢不是特殊符号就给你保留了。
》我们搜索好人的时候,可以看到URL里面的wd值也是一串特舒符号哈。后面回血mysyql,会告诉大家,一个汉字呢,它通常被编码的时候会采用3个字节来进行编码的。所以,你要首先理解的就是,实际上进行我们编码是为了便于我们传输,有些内容,尤其是http上面,它的有些字段呢,是会给我们进行编码的,所以呢,这些信息是被你本地编码完之后,再交给服务器端,服务器就要能够对编码进行解码说白了就是将%2B解码成+号,那么就需要urlencode和urldecode了。

》urlencode和urldecode核心工作,就如它的名字一样帮我们进行编码和解码。当然这里的编码和解码呢,和我们前面代码进行对接就相当于,如果我要做这件事情,那么我们在我们的encode那里除了将报文解析出来,还要做的工作就是将报文进行encode和decode,你可以在序列化之前做,也可以在序列化之后做。我们推荐的是一般在序列化之后做。当然,不同的自定义协议,它是不一样的。所以就可以理解成,urlencode和urldecode对出现的特殊字符进行重新编码,到服务端进行重新解码。
》那你这个编码的工作是谁做的呢?编码的工作就是由你的浏览器来做,那么解码是由谁来解呢?那么就是由我们对应的服务端去做的。那么为什么,我们前面写的socket没有做这份工作呢?那是因为你写的代码是不需要做的,因为客户端也是你写的,但并不代表在http里面不需要哈。http协议的特殊性就决定了。
》那么如果,我想知道哪些符号被编码之后的值是怎么样子的呢?我们可以搜索在线进行编码和解码平台。
http协议格式
http的请求格式
说白了,我们现在对应用层也清楚了,我们前面写了一个基于自定义或者jsoncpp方案的一个序列化和反序列化的代码的关系了。现在的问题是什么呢?那么现在对我们来讲呢,我们能够序列化和反序列化,然后有自定义协议的经历了。那么http也是曾经另一批人呢,也在做这样的事情,另一批人呢,在应用层做这件事情的时候呢,说白了它底层就使用的套接字接口 ,它也进行读写,但是他在应用层要自己定制协议,它们的协议格式呢,非常简单。我们下面先来看看http请求格式。
》http reqeust我们简化一下方便理解。http请求很多教材按3部分,但是我们按照4部分来说。
》第一部分以行为单位\r\n,这就是我们为什么在写自定义写网络计算器的时候,非要给大家用\r\n这个东西,如果不加也是可以的,那么就是为了让大家能够理解。那么http协议的第一行,我们称之为叫做,请求行。要记住,http是基于行的一个协议。其实说白了,就和我们上面写网络版本计算器也是基于行的 ,我们第一行是长度\r\n,再下来就是正文,必须得根据长度,再去读取报文,报头和有效载荷用\r\n区分开。请求行一般会被分为3部分。第一部分叫做请求方法,请求方法,常见的有get方法、post方法,当然还有其他方法,delete方法,当然我们最常见的就2中get、post方法。然后就是以“空格”作为分割符,URL,其中URL一般是去掉端口号的,只包含路径的URL,但并不排除有时候URL是一个字段全的URL,包括了你的所有的http请求,你要请求的服务器是谁,你请求的资源是谁。说白了,这里的URL只有从路径开始“/”往后的部分。但是,有时候web服务器充当代理的时候,它的URL就是整个URL,这样才方便进行二次代理。
》我们今天呢,能看到的就是,你想请求服务器的资源路径是什么。第三个就是发起请求的客户端的http协议的版本,常见的有http1.0、1.1版本,现在主流的就是1.1版本,其中呢以\r\n作为结尾。我们的协议第一行就是下面图片这个样子,来进行我们对应的处理。

》第二个部分是包含了有多行,但是我想将其看成一个整体,但实际上呢,http第二个部分是有多行内容,所以每一行都要包含一堆的\r\n。虽然将多行看成一个整体,但依然是多行内容哈。 其中这么多行当中呢,主体就很多http请求的报头属性,我们可可以把http第二个部分整体叫做请求报头。但是请求报头的属性非常多。最常见的可能是给大家讲的5、6个,但是所有字段呢,都是key:value,也就是说http请求当中,包含的所有的字段里面包含的都是KV形式的。有个小细节就是“K : 空格 value”的形式,这就是http请求的第二个部分,它是按行为单位的。
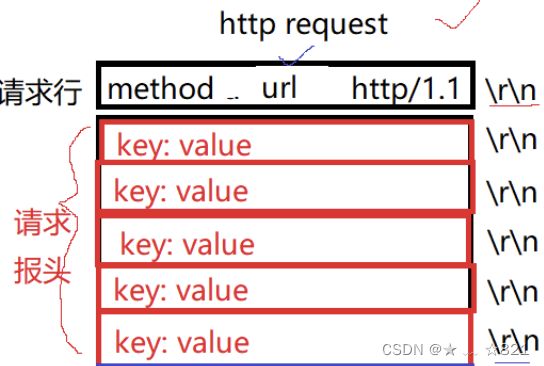
完成之后,紧接着,在第三部分,本身就是\r\n开头。说白了就是,我这个http第二个部分请求报头它是\r\n结尾就会跳到下一行,然后第三部分是一个\r\n开头的,那么又会跳到下一行。所以我们说的第三部分表现的最典型的特征呢就是空行。它这一个空行带来的一个比较好的地方呢就是,我们前面的内容能够保证,前面的内容不会有空行,是必须得有字段,有字段的话,按照我http协议读取的时候,我们可以按行去读,读一行、两行…一直读,直到读到空行,我们就能证明我们把报头和请求行全部读完了。因为,我们把我们说的第三部分之前的全部读了,我只要知道,第一行是我们对应的请求行内容,那么剩下的就是请求报头。
》那么我们说的第三部分是一个空行,就相当于用空行来做分割符,来将自己的报头,全部让别人解析出去。
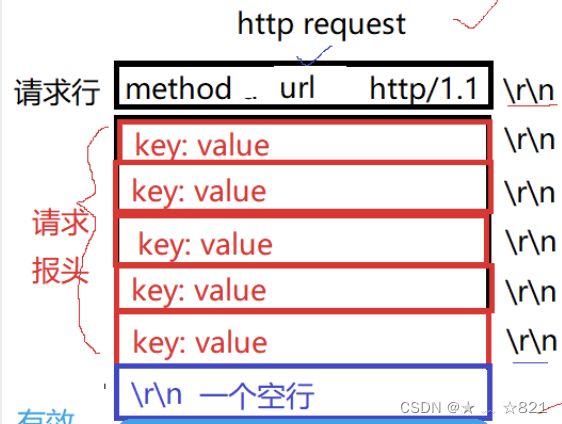
所以对我们来讲呢,http请求呢,当我们看到目前的结构就能够理解,用特殊符号来表示报头部分。不知道大家还记不记,曾经问过大家一个问题,任何协议,都要面临如何将报头和有效载荷分离的问题,当时我们在讲网络基础一的时候讲过。我们在我们的代码中也践行了这个规则。我们在写我们的网络版本计算器,其中我们就是先用我们的报文长度,然后就是读到\r\n,证明我已经将长度读完了,然后解析长度,将有效载荷提取出来。
》现在的问题就是,当我们实际在按照我们所对应的协议去定的话呢,就是用特殊字符\r\n,今天呢,我们http它也是这个样子,它也是通过\r\n能够把报头,不管你是请求行还是请求报头,都可以称之为前半部分,协议的本身字段。后半部分以空行作为分割符,然后再下来的一部分内容,我们称它为叫做,有效载荷。说白了就是用户你自己定的哈,有点像我们前面写的网络版本计算器,我们的有效载荷呢,就是数字+操作符+数字这样子的,或者就是状态嘛+结果这样的。所以这里最后的部分用网络术语就叫做有效载荷,用http术语称它为请求正文。
》一般请求正文就是,登录账号和密码、个人信息、音频、视频等,都属于客户资源。所以内容呢,就是在有效载荷或者叫做请求正文里面了。

》所以http请求就被分为了4部分,其中请求行和请求报头是前2部分,空行独立成一部分,然后有效载荷时第四部分,而我们前两部分是一体,后两部分是一体,或者干脆就分两部分,请求行、请求报头和空行是http协议等报头,然后有效载荷就是报文。这就是http协议等请求!
》所以http就可以通过浏览器构建了一个http请求,发起一次http Request,说白了就是把我们所对应的字符串呢,会按照行为单位,把我们全部的发送过去。然后最终,服务器是不是就收到了,就和我们前面自己写的协议一样。我们自己构建了一个序列化和反序列化,定义了一个protocol,然后客户端向服务端发起我们对应的请求,客户端向服务端发起请求的格式就像我们这个样子。发的格式是这个样子,我们在解析的时候可以按行去读。读取呢,解析请求方法,你想要请求什么资源,协议的版本是什么, 然后你请求的相关报头属性 ,包括你的空行和有效载荷。
》那么我们接下来就要做什么呢?作为http的处理方,也就是服务器方,那我是不是要收到http,我就要对他的请求做解析,就好比,我们上节课收到计算器的request,我们要对Request做解析,进行解码和序列化和反序列化相关工作,然后进行逻辑计算,得到结果,那么就能够构建Responce,那么http响应分几步呢?也叫做http的Responce。
http的响应格式
http的responce分为几个部分呢?也是分为4部分,这也就是http设计的比较优雅的地方。其中http响应的第一部分,它响应也是按行为单位的,即\r\n。它的响应行呢,也包含3部分。第一个叫做状态码,这个状态码不应该感受到陌生了,我们前面的计算器是不是也就有状态码呀,用不同的数字表示不同的状态。状态码呢说白了就是http这次响应是怎么个样子,最典型的就是,404,那么404表示的意思就是,你这个请求的资源不存在,这就是状态码。状态码一般是数字,为了能够支持更好地理解这个意思,所以会在后面跟上另一个部分叫做,状态码描述。那么状态码描述呢,说白了就是解释状态码是什么意思,比如说,404对应的就是Not Find这样的报错。第一行呢,除了有状态码、状态码描述,还有一个就是http协议的版本。大家应该是有这样的一个感觉,我们能够知道,我们现在的网络呢是有客户端和服务器这样的概念的。有时候客户端是一个软件,它定期会更新各种版本,比如说你现在有微信、抖音、快手等,这些app都有自己的版本,那么服务器有咩有自己的版本呢?服务器也是有版本的。
》那么这里就有一个问题,如果我拿一个老客户端,不小心访问了新的服务器,那么按照照道理来讲,我们要保证老客户端正常工作;还有,要保证客户端没有升级就不应该看到新的功能。所以,我们一般在进行我们企业级或商业级呢,会定制自己的版本,说白了就是,你将来在双方第一次通信的时候, 有的人说app协议发来发去有什么意思,其中这个呢,就是表明客户端给服务器说,我的版本是1.1的,服务器响应的时候,也说,我的版本也是1.1的。当然,客户端给服务器响应我的版本是1.0的,那么此时你客户端和服务器通信的时候,就以版本最低的协议来进行通信。所以双方在长时间没有维护的协议或者软件或者版本的话,那么双方就会在建立通信的时候,有可能会有交换协议版本的过程。通过协议版本来保证双方都能够正常工作,也保证了很好的软件向前向后的兼容。

》所以出现两次http协议版本呢,大家也不用觉得奇怪,一个是表明客户端,一个是表明服务端。
》那么,http响应的第二部分,和我们的http请求是一模一样的。响应的第二部分也是以KV的方式组织的,只不过它的这个字段的报头呢,我们称之为响应报头。响应报头也有很多,它是以KV方式帮我们去组织好了,以换行符的方式,可以按行进行呈列。这一点呢,和我们的请求也是一样的。
》再下来呢,也是和我们的Request一样的是,\r\n开头,说白了也是空行。换句话说,http协议的响应和请求很像,它也是4部分,然后以空行为分割符,然后把前半部分内容响应给客户。
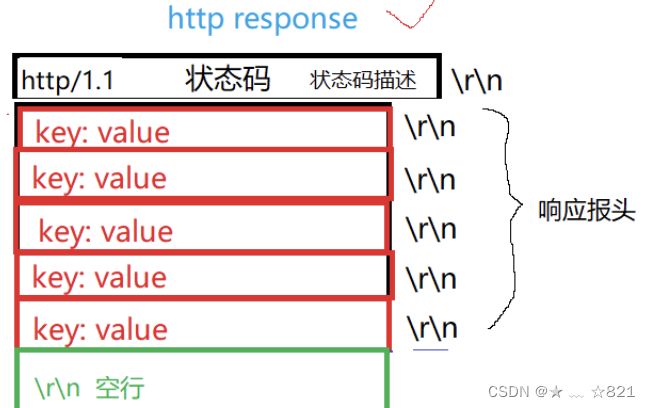
》最后一部分当然是,有效载荷了,这个有效载荷,是我们通常称作的响应正文。你Request有请求正文,同样的,我Responce也应该有自己的响应正文。响应正文是什么呢?不要忘了,你一般请求什么都是在你的URL当中,URL里面是不是包含了,你在我这台机器上请求了什么资源对不对。所以,在进行响应的时候,对应的响应正文部分涵盖的就是客户请求资源。一般,资源包含什么?像我们听过的html、css、js、图片、视频/音频等等,说白了这些都是我们前面说到的一个概念–资源。换而言之,就相当于你的请求呢,服务端识别到你是要请求什么资源,然后再把对应的资源给你打开,然后通过网络的方式返回给你,返回给你之后就拿到了对应的资源。
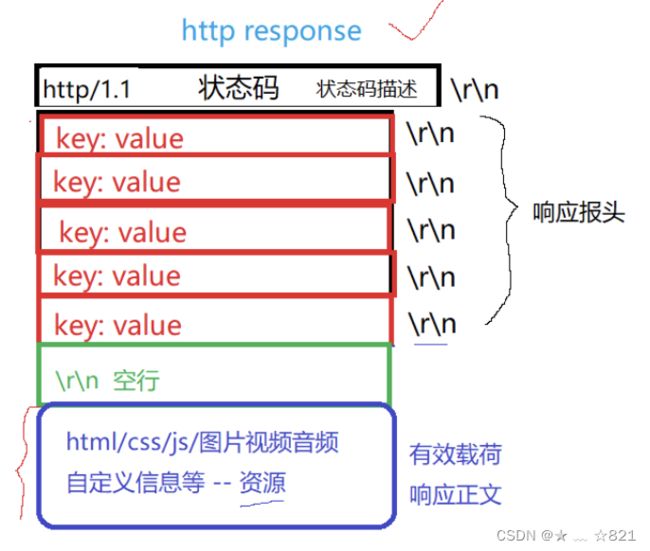
》这就是http整体的框架结构。
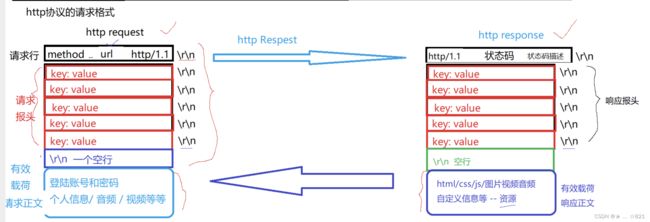
实验和解释GET、POST方法
下面呢,我们要做一些实验。你说的请求是这个样子,那我是不是得见一见呀,一个是见到请求,一个见到响应。我们不废话,我们先尝试获取到客户端发过来的请求。我们尝试了一下,在浏览器输入我们服务器的IP地址+服务端的端口号,我们就收到了浏览器发来的请求,我们可以看到:Get是请求方法,请求资源呢,是“/”,http版本呢,是1.1这是对应我们说的请求行。然后接下来就是请求报头:Host行;Connection行,它表示我们请求时所采用的链接方式,keep-alive后面会说它的,表示长链接;Cache-Control行;Upgrade行,我们也暂时不考虑。重要的是User-Agent代表的就是我们所用的浏览器对应的版本;还有很多行,就不说了。下面图片就是完整的http请求。
浏览器本来就是客户端软件,请求失败,会发送多次请求,所以你收到的请求可能是多条也是正常的。目前可以看到请求,如果还想看到响应的话,我们可以在命令行上获取某一个特定服务器的响应。图片在下面。
我们现在请求和响应都见到了,我们接下来要做什么呢?那么我们是不是要慢慢的学习它里面的一个个字段呀。所以我们从请求开始。
》我们第一个学的就是请求方法字段,这个我们会在待会儿边写代码边给大家验证的。我们已经通过handlerHttpRequest(int sock)函数读取出请求了,我们先对请求不做处理,我们给它一点响应。我们定义一个string responce;我们学过http响应的格式,所以responce = “HTTP/1.0 200 OK\r\n”;然后还要继续+=,目前响应报头的字段我们还不懂,那么我们先不写,那就直接跳到空行那一部分,即responce += \r\n;那么空行下来是不是就是响应正文了呀,可是正文我们也不懂呀,那么没关系,我们也responce += “hello bit”;我们除了可以read()和write()之外呢,我们还可以调用send()函数,它可以向特定的套接字,发送特定的缓冲区数据,并且可以指定希望发多少,然后还有一个flag可以设置为0,那么send()就和write()等价。所以我们就调用send()函数了,即send(sock,responce.c_str(),responce.size(),0);到底能不能工作呢?
》我们将我们的服务器启动起来,然后再开一窗口,我们输入#telnet 127.0.0.1 8080,只要显示“^]”符号表示我们登录成功了,紧接着#contrl + ^],再回车键一下,我们就可以发起请求了,输入#Get/http/1.0,回车键,就能收到服务器的响应了,如下图。
我们再用我们的浏览器来向我们的服务器发起请求,可以看到,我们在网页上面看到一个hello bit。
我们现在就知道,我们一般用的浏览器请求的服务,说白了,是一定有人写过服务,然后部署在Linux下,然后你才可以请求。当然,我们今天可不仅仅想这样写,我们也想简单的进行响应的时候,在响应正文当中,响应的是一个网页,这个网页其中的基本字段,我们该怎么设置呢?我们不懂,没有学过,怎么办呢?没关系,我们可以搜搜html的教程就可以了,我们将它给的代码片段复制一下就可以了,或者模仿一下它的格式。responce += “
hello bit
\r\n”我们再用浏览器去访问试试,我们可以看到,得到了比较大的hello bit,很显然,浏览器根据我服务器给他返回的网页,做了一定程度渲染才得到的结果。
可是这样还没完,虽然现在的主流浏览器已经做的非常好了,它知道我给它响应的是什么东西,但是呢,我还是想告诉它,我给它的是什么东西。所以呢,就好比,我们刚刚请求的时候,是那样子请求的,服务器给我返回的响应也是我们预期的效果。那么,我怎么知道响应的正文是什么类型呢?多长呢?
》一个完整的响应呢,我就得告诉别人,我给你的是什么类型。我们在讲http响应的格式也说了,响应的正文包含了很多的类型,如html、音频等等,所以,换句话说呢,现在就是,怎么让别人知道,我给它的是一个网页呢?所以我们继续在返回的响应responce里面+=一个字段,那就是“Content-Type:”Content代表内容,Type代表类型。意味着,我这次给你的响应的类型是什么。Contnet-Yupe字段究竟有哪些类型呢,有非常多的类型,作为后端开发,我们只需要了解一下就可以了。换而言之Content-Type标定了,我们这个响应正文的类型是什么,因为我们这个是一个网页,所以responce += “Content-Type:text/html\r\n”。我们再来命令行发起请求,就会看到响应正文有它的身影了。
》下面还有一个问题,我的一次请求和响应当中,现在呢,就要回答两个问题,任何协议的Request 和 Responce是包含两个部分的,那就是 报头 ➕ 有效载荷。那么现在的问题呢,就是,第一个,**http是如何保证自己的报头和有效载荷被全部读取呢?**无论是请求还是响应。也就是无论是请求还是响应,http是如何保证你能够读到一个完整的报文呢?
》那么,我们是不是可以很好的去理解。1.读取完整报头:按行读取,直到读取到空行!(那么你如何按行读取,你怎么保证你读到空行,这个是关于IO处理,我们就暂时不处理它)现在呢,我们原理上是按行进行把一行读取,这个工作,我们在前面写计算器就做过了哈。所以,我们容易读到报头,当然更重要的不是它哈。
》 2.你如何保证,你能读取到完整的正文呢?就是,我现在能够将报头读完了,那你怎么知道正文有多长呢?就好比,我们前面写的网络版本计算器,我们说了,我们能保证报头读完,那么我们怎么知道报文有多长呢?没关系,我们读取到报头就是长度,我们再将字符串转整数,然后就知道报文有多长了。现在问题就是,你能够将http完整的报头读到,这没问题,可是正文部分如何保证呢?
》我们有办法,其实和我们的计算器的思路类似。我们读取报头的时候,报头里面有那么多的属性呢,那么我们是能够首先保证报头属性读取完毕。只要你的请求是合法的,或者你没有出现关的情况,那么正常情况,你发过来了,那么我肯定能把报头读完。不管是请求还是响应,你不是都有一堆的报头属性嘛。所以, 请求或者响应的属性中,一定要包含正文的长度。(但是,客户端并不是我们自己写了,可能人家客户端有自己的很聪明的做法,不需要长度哈。)
》那么,我们在响应报头当中带上正文的长度字段哈。那么问题是,我们怎么到正文有多长呢?我们先string html = “
hello bit
\r\n”保存一份。那么我们现在给responce +=( “Content-Length:” + to_string(html.size()) + “\r\n”);》我们再来进行测试一下,我们是能够看到响应中会带上长度的字段是34。
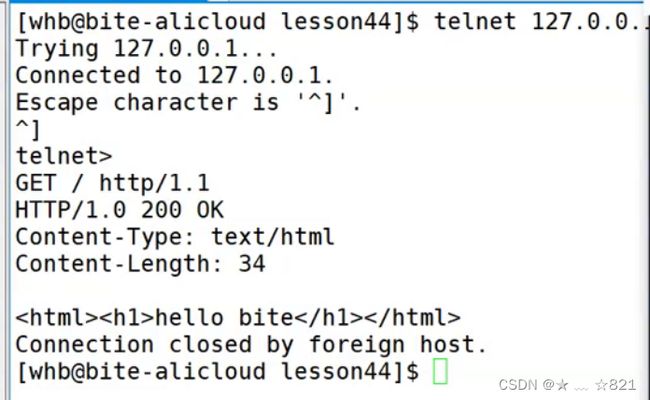
你说的挺好,没有什么问题。现在有一个问题,什么问题呢?我自己写的服务器,网页有什么内容,难道还要我关心嘛?作为一款服务器,我只负责请求,将信息给你推过去就可以了,难道还要我服务器关注一大堆html的东西吗?那是不是太麻烦了。所以,实际上我们在服务端这里,我们C++写端服务器呢,比如一些做网站开发的,我们和网站开发没什么关系哈,我们的重点是服务器 。现在就相当于,现在有一个做前端的同学,它可能写了一堆的网页,包括其他图片等一些资源,现在的问题是,难道还要我一个服务器去关心你刚才说的那些东西吗?
》我们就不需要string html = “
hello bit
\r\n”保存一份了,我们直接string html = readfile()从文件里面把内容拿上来,然后再将html拼接到responce里面。如果从文件里面拿的话,这里会衍生出两个问题, 第一个问题:文件在哪里?第二个问题:如何取呢?》第一个问题,我们重来没有讨论过,什么意思呢?意思就是说,你想访问什么文件呢,你想访问什么资源呢?不知道还记不记得,我们在前面讲,你在请求html的时候,即URL的前半部分是域名,端口号忽略,然后后面就会跟着你要访问文件的路径,这也是Linux下的文件路径。第二个,我怎么知道它要访问什么文件呢?
》我们来做一件事:#control ➕^],然后回车键,输入#GET方法,即GET /a/b/c.html http/1.0,然后就发起请求了,可以看到,服务器收到了我的请求行当中要请求的东西,如下图。
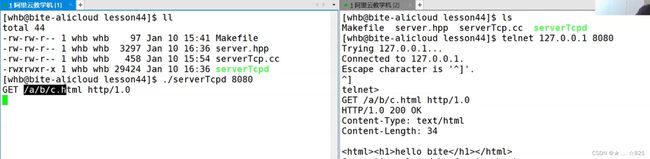
换而言之,第一个问题我们就能回答了,文件在哪里呢?**文件在请求行中,请求行的第二个字段就是你要访问的文件! 想一想,它想要访问文件,它会带路径,如果他访问的这个路径是一个不存在的路径,那么他访问的资源是不是也势必不存在呀,如果不存在,我给它返回的响应不就是“404”嘛,如果存在了,且各种权限都没问题,那是不是我就将文件打开,返回文件内容给你就行了,对不对。
》现在的问题就是,我们前面也说过,在URL格式中,紧跟域名和端口号后面的是要访问文件的路径,其中“/”是路径分割符,第一个“/”是什么东西呢?就是你请求的东西是从“/”开始的,那么这个“/”是什么呢?之前没有谈过,但是现在是要有一个感觉,我们前面也特意说了,放在开始的“/”不是根目录,但是可以为根目录,它是web根目录,可以设置成为根目录。**这句话的意思就是说,从概念上讲,他不是Linux根目录,它是web根目录,如果你愿意的话,你可以让根目录充当web根目录。那么,我们今天让它成为根目录是最简单的,直接去访问他就可以,但是我不想让“/”成为根目录,我想把我的资源都放在特定的路径下,所以,我们创建一个文件夹wwwroot,所以这个文件夹保存的是我们想要的文件信息。所以我们在该wwwroot文件夹下再建立一个index.html。一般特定的网址当中包含的首页信息就在index.html里面了。换而言之,文件在哪里呢?文件就在请求行的第二个字段里面(即URL)。
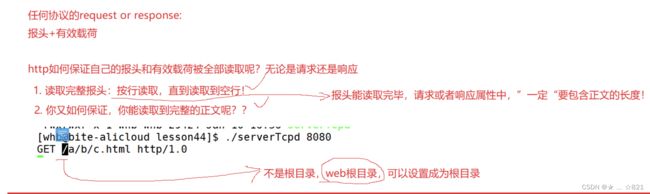
》比如说,我们将来读取到,解析请求的时候,读到了,它要访问的资源在path里面,所以我的path是这样子的,path = “/a/b/cindex.html”,这个样子的话,我再继续往后面读取的话,那么我们得先做一件事情,你想要的资源在哪里呢?所以,我得给你拼接一个resource = “./wwwroot”;这个就是我们的web根目录,然后呢?resource += path;这样就构建出了一个“./wwwroot/a/b/index.html”。
》换而言之,对于外部想使用我服务器的人呢,它在请求的时候,只要知道“/a/b/index.html”就可以了,而在我们服务器内部呢,我知道资源实际上是在我当前目录下的wwwroot目录下的,所以我给你的路径path加上了前缀“./wwwroot”,就限定了在用户请求的路径下呢有特定的资源。此时呢,我们服务器就可以去打开特定路径下的文件就可以了。
》所以,有没有清楚,当别人请求“/a/b/index.html”时候的首符号“/”可以不是我们的根目录!当然你服务器内部不加前缀,那么就是根目录了,但是我们一般还是建议大家加上前缀。所以当你来了所有的请求,我在你所有的请求当中前面都加上前缀wwwroot文件夹,那么当别人想访问的时候,就直接访问就可以了。我们目前是没有做请求处理的,如果想处理一下的话,我们也可以做一点处理。
》我们可以写一个getPath()的方法,将我们从sock读到的buffer内容当作参数传进去,即string = getPath(buffer),也就是我就处理一下路径。一旦我确定了路径,我就可以加上我想加的前缀,最后呢,已经确定好要访问哪个资源了,那我再用readFile()函数给你打开并读取到,读取到之后,将其作为响应给你发回去。
》我们先来写从我们的请求当中获取路径字段,即string getPath(string http_request)。对于我们来讲呢,我们已经得到了一次http请求,我们也就不做判断了,我们就认为一次就将请求全部读上来了。所以,我们要考虑的就是,先要提取一行对不对。我们先找"\r\n",size_t pos = http_request.find(CRLF。)我认为我已经读到了一个完整的请求行了,反正闭着眼睛我们都知道,我们拿到的是我们想要的第一行。然后string request _line = http_request.substr(0,pos);然后我们再要找的就是空格,size_t first = request_line.find(SPACE);因为第一行的每一个字段都是以空格来隔开的。我们也说了,请求行有3个字段,我们还得再找一个空格,size_t second = http_request.rfind(SPACE);
》所以string path = request_line.subst(first + SPACE_LEN,second - (first + SPACE_LEN));此时我们就将请求行的URL读到了嘛,那么直接return path。
》这里呢,有一个问题,如果对方访问我的时候,路径就只有一个/的话,那不就是要访问我的web根目录嘛,说白了就是将我web根目录下的所有内容都返回,你想的是不是有点太美了,怎么可能将web根目录下的所有资源都给你呢,如果我web根目录下有几百上千部电影,难道资源全给你嘛?当然不行。
》所以,如果用户请求的是一个“\”的话,那么我们就得拼接上,我们默认的首页字段,那怎么加呢?所以,我们就要在分割出path之后,返回retrun之前要做一个判断,if(path.size() == 1 && path[0] = = “/”)那么我就要给你加上index.html,即path += “index.html”或者我们宏定义之后,path += HOME_PAGE;
》有了路径之后,我想要干什么呢,不能乱读,你要请求的资源,我现在有。我现在要把你请求的资源呢,进行给你返回。那我们就还需要再处理一下,要给你的路径继续拼接上我的web根目录。我们现在,在命令行发起请求用的GET方法。我们来拼接,string resource = ROOR_PATH;resource += path;所以我们就给提取到的路径path拼接上了我们的根目录。我们的重点是在原理上,不是在代码上。
》接下来就完成下一个工作就是读取文件readFile()函数。int fd = open(),打开路径就是recource.c_str(),打开的方式呢,毫无疑问,就算该路径下的文件不存在,你也不能给我创建,因为你必须存在,那么就使用的O_RDONLY,算了,我们用C++接口打开吧。所以,ifstream in(recource);如果成功打开了,那么我们继续往后走,没成功,if(!in.is_open()),没有成功,正常情况下,我们外面获取返回值,然后进行判断,将状态码什么的都改一下,我们这里就简单一点,返回return “404”;如果打开文件成功的话,那当然是对文件的内容进行读取。string content;string line;while(getline(in,line))content += line;读取完之后就是in.close();将我们读取的内容进行返回return content;
》反正就是,你要访问什么文件我知道,我将文件打开并读取内容,将其返回给你。我们下面就是要来编写首页index.html,我们就网上随便搜索并复制代码。我们简单的将index.html首页代码写完了,那么一会儿,我们的服务器启动,任何人想要访问我的网站,默认先输入的就是域名或者iP,加上端口号,默认发过来的就是/,你发过来的是/,那么我再服务器内部提取你的文件路径,然后再对你做路径的拼接,拼接之后,你就会在我们的wwwroot目录下去找index.html,所以会将index.html给你们返回出去,那么你们就可以浏览这个首页,可以跟树状结构继续往下浏览,当然我们就是单独一个首页,就不提供继续点击其他链接往后读了。
》我们来进行测试,在命令行启动telnet输入之后,输入#GET / http/1.0,方法是GET,路径是/,http版本1.0。所以,经过测试,我们的请求和响应都得到了成功。
我们下面要来学习GET和POST方法:
为什么,刚刚要写一个服务器,将我们的网页返回呢?原因就在于我们要研究一个表单的东西。表单是什么呢?说白了,平时在登录的时候,不管是登录还是注册,只要你想把你自己的个人信息上传上去,你就必须得有表单这个东西。
》我们先说一个概念:我们的网络行为无非就是两种,1.我想把远端资源拿到你的本地,即GET /index.html http/1.1;2.我们想把我们的属性字段,提交到远端。换句话说就是,我们搜索引擎,提交搜索关键字;登录的时候,有登录的字段,包括你注册的时候,会加上注册的字段。说白了其实就是这两种行为。
》其中很显然,GET方法就是要将我们的远端的资源拿到我们的本地。然后,我们的GET和POST方法,还有一个行为就是想把我们的属性字段,提交到远端。现在我们听到一些网站说是“静态网站”,说白了就是,只能够将东西拿到;还有一些网站呢,是“动态网站”,说白了就是能够交互的,能够交互的话,就能够提交一些什么东西。比如说,一个被阉割的论坛,只能让你看帖子,不让你发评论,那么这就是一个静态网站,如果允许你发评论,那么就是能够交互。
》现在呢,我们交互的时候呢,我们将数据提交到远端呢有两种方法,一种是GET,还有一种就是POST。GET和POST相比,肯定是有区别的,什么区别么,后面再说。我们现在对GET和POST的提交没有办法处理,因为,GET和POST在提交上面,有相当多的细节,我们有一个项目http实现 ,其中它呢是用到了一些第三方库。
》其实最难的并不是把东西拿下来,把东西拿下来,我们目前学到的是够用的。但是,你要将东西提交上去,提交之后,你还要进行解析字段,包括你提交上来的东西要做什么呢,比如说,你提交上来的数据是要注册,那么服务端还要写一大堆的注册逻辑,你要搜索的话,还要有一大堆的搜索逻辑。那么用户提交上来的数据是第一步,再往后面你是要有业务的 ,所以处理肯定还是比较复杂的。
》我们下面要做的就是构建一个表单,那么表单该怎么做呢?不懂没关系,我们直接网上搜索一下html表单就行了。