玩转数据采集:PC端爬虫工程师如何高效完成数据入库?
前言
数据入库是指将采集好的数据存储到数据库中以便后续处理和分析。作为一名PC端爬虫工程师,掌握数据入库技能是必不可少的。在进行数据采集的同时,将数据实时地存储到数据库中,可以让数据得到更好地管理和利用,提高效率和效益。
一般而言,进行数据入库有以下几个步骤:
-
数据库的创建和配置:选择一个合适的数据库,根据实际需要创建数据库表和配置数据库连接等参数。
-
数据库连接:建立数据库与Python的连接。有关Python连接数据库的方法有很多种,比如通过Python自带的SQLite数据库模块、通过MySQL Connector等第三方库进行连接。
-
数据准备和清洗:在进行数据入库之前,需要进行针对性的数据准备和清洗工作。比如,对采集到的数据进行初步处理,处理掉无意义的数据,将有用的数据组织好。
-
数据的插入和更新:通过Python提供的数据库操作工具(如SQLAlchemy)或sql语句来进行数据的插入和更新操作。
-
数据库的维护:包括对数据库表的清理、优化和备份等操作,以确保数据库的稳定运行。
需要注意的是,数据库入库不仅涉及到数据库本身的知识,还需要对Python编程语言有一定的掌握。因此,PC端爬虫工程师在进行数据入库之前,需要先掌握Python的基础语法,熟练掌握Python的相关技巧,才能顺利地进行数据采集和入库工作。
总而言之,数据入库是PC端爬虫工程师不可或缺的一项技能。只有掌握好数据入库技能,才能为企业或个人实现更好地数据分析和应用,提高数据价值。
关注公众号:python技术训练营,精选优质文档,好玩的项目
内容:
1.面试专题几十个大厂面试题
2.入门基础教程
3.11模块零基础到精通笔记
4.百个项目实战+爬虫教程+代码
5.量化交易,机器学习,深度学习
6.Python游戏源码
7.交流学习
8.了解接单市场
9.DNF自动识别打怪
10.3263页学习资料
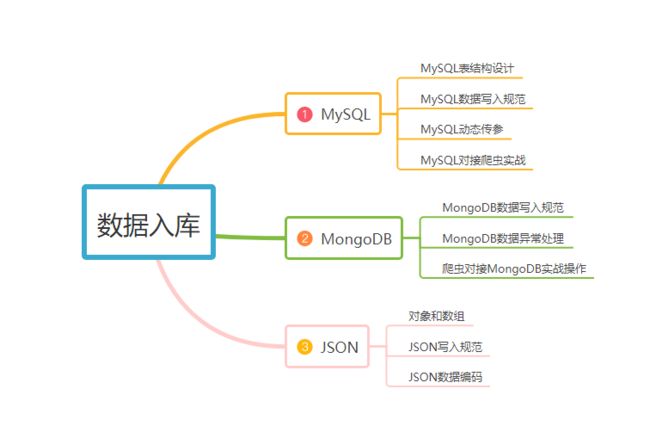
一丶MySQL
MySQL是一种常用的关系型数据库管理系统,广泛应用于各种应用场景。在进行数据采集和入库工作时,掌握MySQL数据库的使用是极为重要的。
1.MySQL表结构设计
MySQL表结构设计是进行数据入库时需要考虑的一个重要问题。一个好的表结构设计可以保证数据的存储和管理更加高效和便捷。以下是几个关键点,供PC端爬虫工程师在进行MySQL表结构设计时参考:
-
字段设定:在表结构设计中,需要设定字段和对应的数据类型。字段的设定需考虑数据的类型、长度、是否允许为空、是否唯一、是否自增等因素。在设计字段时需遵循最小化原则,避免不必要的字段,以减轻数据库处理压力。
-
主键、唯一键、索引等设定:通过索引可以提高查询的效率,因此在数据入库时应该考虑添加索引。一般而言,需要给表中的字段设定主键、唯一键和普通索引等,以优化数据的查询性能。
-
表的级联关系:在设计表结构时,需要考虑多表之间的关系。比如,是采用多个独立的表,还是将其合并为一个复杂的表。还需考虑多表之间的级联关系,以确保数据的一致性。
-
设定数据表的字符集和排序规则:在MySQL表的结构设计中,还需考虑字符集和排序规则的设定。要根据实际情况,选择合适的字符集和排序规则,以避免数据存储时出现乱码或者排序问题。
2.MySQL数据写入规范
MySQL数据写入规范是进行数据入库时需要考虑的一个重要问题。一个良好的数据写入规范可以保证数据的准确性和一致性,确保数据在数据库中的正确存储。以下是PC端爬虫工程师需要遵循的MySQL数据写入规范:
-
字段值格式与表结构匹配:在进行数据写入时,需要确保字段值的格式与表结构匹配。即使数据库允许数据随意写入,也应该遵循表结构设计的原则,将数据写入到正确的字段中。
-
数据的完整性:在进行数据写入时,需要确保数据的完整性。应尽量避免数据缺失、重复或者错误等问题,以免对后续分析和应用造成影响。
-
数据的规范化:对于涉及字符串、日期等数据类型的字段,需要考虑到数据的规范化。比如,对于日期数据,应统一使用一种日期格式,并避免使用默认格式等导致的问题。
-
事务管理:在进行数据写入时,应尽量使用事务来确保数据的一致性。比如,在写入多条记录时,可以将它们一起写入到数据库中,并在最后再统一提交,以确保数据在写入的过程中保持一致性。
-
避免超限数据的写入:在进行数据写入时,应严格避免超限数据的写入,例如数据长度超出字段长度等问题。如果数据超限,会导致数据丢失或者数据库撑爆等问题。
3.MySQL动态传参
MySQL动态传参是进行数据入库时经常用到的一种技巧。通过动态传参,可以有效地提高MySQL数据库写入的效率,减少程序代码的冗余,优化数据入库过程。以下是几种常用的MySQL动态传参方式:
使用Python的字符串格式化方法进行动态传参:可以使用Python的字符串的format方法进行MySQL参数的传递。在进行数据写入操作时,可以将MySQL语句和Python字典或元组进行结合,实现动态传参的效果。例如:
import MySQLdb
# 定义数据表名
table_name = "student"
# 定义学生信息
student_info = {
"name": "Tom",
"age": 18,
"grade": "A"
}
# 动态传参
sql = "INSERT INTO {table_name} (name, age, grade) VALUES ('{name}', {age}, '{grade}')".format(
table_name=table_name,
name=student_info['name'],
age=student_info['age'],
grade=student_info['grade']
)
# 连接数据库
conn = MySQLdb.connect('localhost', 'username', 'password', 'database_name')
# 获取游标对象
cursor = conn.cursor()
# 执行操作
cursor.execute(sql)
# 提交事务
conn.commit()
# 关闭游标和连接
cursor.close()
conn.close()
使用MySQLdb模块的execute方法进行动态传参:使用MySQLdb的execute方法进行动态传参,只需要在SQL语句中使用占位符%s,然后在执行execute方法时传递参数列表即可。例如:
import MySQLdb
# 定义数据表名
table_name = "student"
# 定义学生信息
student_info = {
"name": "Tom",
"age": 18,
"grade": "A"
}
# 动态传参
sql = "INSERT INTO {table_name} (name, age, grade) VALUES (%s, %s, %s)".format(
table_name=table_name
)
# 连接数据库
conn = MySQLdb.connect('localhost', 'username', 'password', 'database_name')
# 获取游标对象
cursor = conn.cursor()
# 执行操作
cursor.execute(sql, (student_info['name'], student_info['age'], student_info['grade']))
# 提交事务
conn.commit()
# 关闭游标和连接
cursor.close()
conn.close()
总之,MySQL动态传参是进行数据入库时经常使用的一种技巧。PC端爬虫工程师掌握MySQL动态传参的使用方法,可以对SQL语句进行动态的参数传递,从而提高数据库写入的效率、减少代码冗余。在进行数据入库时,建议使用MySQL动态传参技巧,以提高数据的写入效率和准确性。
4.MySQL对接爬虫实战
在进行爬虫数据采集和入库时,MySQL是一个常用的关系型数据库管理系统,其稳定性和可靠性被广泛认可。以下是PC端爬虫工程师可以按照的步骤,将爬虫采集数据写入到MySQL数据库中:
-
创建MySQL数据库表结构:在MySQL数据库中创建一个数据表,该表的表结构应根据数据的类型和存储需求进行设计。在表结构设计时需要考虑字段设定、主键、唯一键、索引等因素。
-
使用Python中的爬虫框架进行数据采集:使用Python中的Scrapy或者BeautifulSoup等常用的PC端爬虫框架进行数据采集,将采集到的数据存储在Python的变量中。
-
连接MySQL数据库:使用Python的MySQLdb或pymysql等第三方库连接MySQL数据库,并进行相应的参数配置。
-
实现数据写入操作:使用Python的cursor对象,通过sql语句将数据插入到MySQL数据库中。在插入数据时,需要遵循MySQL数据库的数据写入规范,保证数据的完整性、一致性和安全性。如果需要动态传参,在插入数据时还需要用到字符串格式化方法或者MySQLdb的execute方法进行动态传参。
-
关闭数据库连接:当完成数据入库操作后,应及时关闭数据库连接,以释放资源。
下面是一个将采集到的数据写入MySQL数据库的示例代码:
import MySQLdb
# 连接MySQL数据库
conn = MySQLdb.connect('localhost', 'username', 'password', 'database_name')
# 获取游标对象
cursor = conn.cursor()
# 采集到的数据
book = {'name': 'Python入门精通', 'author': '张三', 'price': 28}
# 数据库写入操作
sql = "INSERT INTO books (name, author, price) VALUES ('%s', '%s', %f)" % (book['name'], book['author'], book['price'])
try:
# 执行SQL语句
cursor.execute(sql)
# 提交事务
conn.commit()
except Exception as e:
# 发生异常时回滚
print(str(e))
conn.rollback()
# 关闭游标和连接
cursor.close()
conn.close()
将爬虫采集的数据写入MySQL数据库是PC端爬虫工程师需要掌握的重要技能之一。需要合理设计数据表结构,使用Python的爬虫框架进行数据采集,正确连接MySQL数据库,遵循MySQL的数据写入规范进行数据写入操作,并严格保障数据的完整性和一致性。
二丶MongoDB
除了关系型数据库MySQL,另一种非常流行的数据库是NoSQL数据库MongoDB。相比于MySQL,MongoDB具备更好的可扩展性和更方便的数据处理方式,是现代Web应用程序的热门选择。以下是将爬虫采集数据写入MongoDB数据库的步骤:
-
安装MongoDB数据库:在开始使用MongoDB数据库之前,需要安装MongoDB以及相应的Python驱动程序pymongo。MongoDB官网提供了各种安装方式和文档。
-
连接MongoDB数据库:使用pymongo库连接MongoDB数据库,并进行相应的参数配置。MongoDB需要指定数据库所在服务器地址、端口号、数据库名称等连接信息。
-
创建MongoDB数据库和集合:MongoDB是面向文档的数据库,不需要像MySQL一样设计表结构,而是直接存储JSON格式的文档。可以首先创建MongoDB数据库和集合,然后在代码中直接插入文档。使用pymongo库提供的MongoClient对象可以连接MongoDB数据库,并使用相应的方法创建数据库和集合等。
-
实现数据写入操作:使用pymongo库提供的
insert_one或insert_many等方法将Python变量中的数据插入到MongoDB中。在插入数据时,需要遵循MongoDB的数据写入规范,保证数据的完整性、一致性和安全性。如果需要动态传参,在插入数据时还需要用到Python格式化字符串或bson模块的tobson方法。 -
关闭数据库连接:当完成数据入库操作后,应及时关闭数据库连接,以释放资源。
下面是一个将采集到的数据写入MongoDB数据库的示例代码:
import pymongo
import json
# 连接MongoDB数据库
client = pymongo.MongoClient(host='localhost', port=27017)
# 创建MongoDB数据库和集合
db = client['bookstore']
collection = db['books']
# 采集到的数据
book = {'name': 'Python入门精通', 'author': '张三', 'price': 28}
# 数据库写入操作
try:
# 将Python字典转换为MongoDB的文档格式
doc = json.loads(json.dumps(book))
# 插入文档到MongoDB
collection.insert_one(doc)
except Exception as e:
print(str(e))
# 关闭MongoDB连接
client.close()
将爬虫采集的数据写入MongoDB数据库是PC端爬虫工程师需要掌握的另一个重要技能。需要首先安装MongoDB数据库和Python驱动程序pymongo,然后使用pymongo库连接MongoDB数据库,创建数据库和集合,使用insert_one和insert_many等方法将数据插入到MongoDB中。同时也需要遵循MongoDB的数据写入规范,保障数据的完整性和一致性。
1.MongoDB数据写入规范
MongoDB是一种非关系型数据库,相对于传统关系型数据库MySQL,它有许多的特性和优势,但是在使用时需要遵守一定的数据写入规范,以保证数据的安全性和一致性。下面是在将数据写入MongoDB时需要遵守的规范:
-
字段命名规范:MongoDB支持使用Unicode字符集中的所有字符作为字段名称,但是不推荐使用除字母数字和下划线以外的特殊字符,且建议使用小写字母。字段名称不能为空字符串,并且不能以$开头。
-
数据格式规范:在将数据写入MongoDB中时,需要保证文档中每个字段的数据类型和数据格式的一致性。如果想要将Python中的数据写入MongoDB,可以先将Python中的数据格式化为JSON字符串或字典,然后再将其转换为MongoDB文档格式。
-
文档唯一性规范:MongoDB中的每个文档都应该具有唯一的_id字段。如果在写入文档时没有指定_id字段,则MongoDB会为每个文档自动生成一个ObjectId类型的_id字段。
-
数据写入确认规范:当使用MongoDB写入数据时,应该使用写入确认来确保数据已经成功写入数据库。MongoDB提供了四种写入确认级别,分别为:未确认写入、确认主节点写入、确认大多数节点写入和确认所有节点写入。
-
数据更新规范:在更新MongoDB中的文档时,可以使用update方法进行更新。使用update方法时,需要指定更新的文档、更新的方式和更新的条件。如果不指定更新条件,则默认会更新所有符合条件的文档。更新操作还可以将某个字段的值进行递增或递减操作。
-
数据删除规范:在MongoDB中删除文档时,可以使用remove方法进行删除。使用remove方法时,需要指定删除的文档和删除的条件。如果不指定条件,则默认会删除所有文档。
在将数据写入MongoDB中时,需要遵守一定的规范,以保证数据的安全性和一致性。需要注意字段命名规范、数据格式规范、文档唯一性规范、数据写入确认规范、数据更新规范和数据删除规范。
2.MongoDB数据异常处理
在进行数据入库到MongoDB的过程中,可能会遇到一些异常情况,例如写入数据失败、查询数据出错等等。为了保证数据的完整性和正确性,需要进行一些异常处理。
以下是在使用MongoDB进行数据入库时,可能会遇到的异常情况及相应的处理方法:
-
写入数据失败:在将数据写入MongoDB的过程中,可能会由于网络问题、数据库连接失败或者其他原因导致写入失败。此时,需要进行重试操作,并且可以使用MongoDB提供的异常处理机制来捕获异常,并进行相应的处理。
-
查询数据出错:在查询MongoDB中的文档时,可能会由于查询条件错误、查询字段不存在或其他原因导致查询出错。此时,可以使用MongoDB提供的异常处理机制来捕获异常,并进行相应的处理。
-
数据库连接失败:在连接MongoDB数据库时,可能会由于网络问题、数据库服务未启动或其他原因导致连接失败。此时,需要检查数据库服务是否正常运行,并重新连接数据库。
-
数据库连接断开:在MongoDB与客户端进行通信时,可能会由于网络问题或者其他原因导致连接断开。此时,需要重新连接MongoDB数据库,并处理异常情况。
-
数据库写锁:在进行写入操作时,可能会由于另一个线程正在写入同一个文档而出现写入锁。此时,需要等待写入锁释放,然后再进行操作。
-
数据库读锁:在进行读取操作时,可能会由于另一个线程正在更新同一个文档而出现读取锁。此时,可以选择等待读取锁释放,或者强制获取读取锁进行读取操作。
在进行数据入库到MongoDB的过程中,可能会遇到各种异常情况,需要注意异常处理,以保证数据的完整性和正确性。需要使用MongoDB提供的异常处理机制,对可能出现的异常进行捕获,并进行相应的处理。此外,还需要注意在进行写入操作时可能出现的写锁,以及在进行读取操作时可能出现的读锁。
3.爬虫对接MongoDB实战操作
在进行爬虫数据采集时,将采集到的数据存储到MongoDB数据库中是一个比较常见的操作。下面简单介绍一下如何使用Python爬虫程序对接MongoDB数据库进行实战操作。
- 安装MongoDB驱动程序:Python爬虫程序可以使用第三方库–pymongo–来操作MongoDB数据库。首先需要安装pymongo库,可以使用pip命令进行安装:
pip install pymongo
- 连接MongoDB数据库:使用pymongo库连接MongoDB数据库非常简单。需要指定MongoDB服务器的IP地址及端口号,同时指定要使用的数据库名称和集合名称。示例代码如下:
import pymongo
# 连接MongoDB服务器
client = pymongo.MongoClient("mongodb://localhost:27017/")
# 选择数据库和集合
db = client["testdb"]
col = db["testcol"]
在实际操作中,可以根据需要自己定义数据库和集合的名称。
- 插入数据到MongoDB:将爬虫采集到的数据插入到MongoDB中,需要使用pymongo库提供的
insert_one()或insert_many()方法。如果要插入多条数据,可以使用insert_many()方法。示例代码如下:
import pymongo
# 连接MongoDB服务器
client = pymongo.MongoClient("mongodb://localhost:27017/")
# 选择数据库和集合
db = client["testdb"]
col = db["testcol"]
# 插入一条数据
data = {"title": "Python编程", "price": 88.8}
col.insert_one(data)
# 插入多条数据
datas = [
{"title": "Java编程", "price": 99.9},
{"title": "C++编程", "price": 79.9},
{"title": "PHP编程", "price": 69.9},
]
col.insert_many(datas)
- 查询数据:查询MongoDB数据库中的数据,需要使用pymongo库提供的
find()方法。可以根据需要指定查询条件和查询字段。示例代码如下:
import pymongo
# 连接MongoDB服务器
client = pymongo.MongoClient("mongodb://localhost:27017/")
# 选择数据库和集合
db = client["testdb"]
col = db["testcol"]
# 查询数据
data = col.find_one({"title": "Python编程"})
print(data)
for data in col.find():
print(data)
- 更新数据和删除数据:使用pymongo库提供的
update_one()、update_many()、delete_one()和delete_many()方法可以更新和删除MongoDB数据库中的数据。
import pymongo
# 连接MongoDB服务器
client = pymongo.MongoClient("mongodb://localhost:27017/")
# 选择数据库和集合
db = client["testdb"]
col = db["testcol"]
# 更新数据
query = {"title": "Python编程"}
new_data = {"$set": {"price": 99.99}}
result = col.update_one(query, new_data)
print(result.modified_count)
# 删除数据
query = {"title": "Python编程"}
result = col.delete_one(query)
print(result.deleted_count)
以上就是对接MongoDB数据库的实战操作。需要注意的是,MongoDB数据库在进行大量写入数据时,可能会遇到性能瓶颈问题,可以通过使用分片和索引等技术来提高MongoDB数据库的性能。
三丶JSON
进行数据采集时,一种常见的数据存储格式是JSON(JavaScript Object Notation)。JSON格式具有轻量级、结构化等优点,且易于使用和解析。下面介绍PC端爬虫工程师采集数据后如何将数据存储为JSON格式。
使用Python标准库json将数据转换为JSON格式
Python标准库json提供了loads(),load(),dumps()和dump()四个函数用于JSON数据的解析和编码。其中,dump()函数可以将Python对象直接序列化为JSON文件,如下使用示例:
import json
data = {
"name": "Tom",
"age": 18,
"gender": "male"
}
with open("data.json", "w") as f:
json.dump(data, f)
使用Python第三方库pandas将数据存储为JSON格式
pandas是一种基于NumPy的数据分析工具,支持多种数据格式的解析、操作和存储,其中就包括JSON格式。pandas提供了to_json()方法,可以将DataFrame对象、Series对象或Python字典对象存储为JSON格式文件。示例如下:
import pandas as pd
data = pd.DataFrame({
"name": ["Tom", "Jack", "Lucy"],
"age": [18, 19, 20],
"gender": ["male", "male", "female"]
})
data.to_json("data.json")
使用Python第三方库scrapy将数据存储为JSON格式
scrapy是一种广泛应用于Web爬虫数据采集的Python框架,它默认支持多种数据存储方式,包括JSON格式。在使用scrapy框架进行数据采集时,可以将数据存储为JSON格式,示例代码如下:
import scrapy
class MySpider(scrapy.Spider):
name = "example.com"
start_urls = ["http://www.example.com"]
def parse(self, response):
# 爬虫采集到的数据
data = {
"name": "Tom",
"age": 18,
"gender": "male"
}
# 将数据存储为JSON格式
yield data
进行数据采集时,可以选择将采集到的数据存储为JSON格式。可以使用Python标准库json、第三方库pandas或爬虫框架scrapy提供的方法将数据以JSON格式存储起来,以达到方便解析和处理的效果。
1.JSON对象和数组
JSON对象
JSON对象是由花括号“{}”包围的一组属性-值对。属性和值之间使用冒号“:”分隔,不同属性之间使用逗号“,”分隔。一个JSON对象可以包含零到多个属性-值对,示例如下:
{
"name": "Tom",
"age": 18,
"gender": "male",
"hobbies": ["reading", "traveling"]
}
其中,name、age、gender是属性,对应的值分别是Tom、18、male;hobbies是一个数组,包含两个元素reading和traveling。
JSON数组
JSON数组是由方括号“[]”包围的一组值,不同值之间使用逗号“,”分隔。一个JSON数组可以包含零到多个值,示例如下:
[
{"name": "Tom", "age": 18, "gender": "male"},
{"name": "Jack", "age": 19, "gender": "male"},
{"name": "Lucy", "age": 20, "gender": "female"}
]
这是一个包含三个JSON对象的数组,每个对象都包括name、age、gender三个属性,分别表示姓名、年龄、性别。
使用JSON对象和JSON数组可以灵活地组织和存储数据。在进行数据采集和数据处理时,PC端爬虫工程师需要了解和掌握这两种JSON结构的相关知识,以便更好地将采集到的数据存储为JSON格式,进行数据解析和处理等操作。
###2.JSON数据编码
进行数据采集和数据存储时,需要将采集到的数据编码为JSON格式,以便后续进行解析和处理等操作。在Python语言中,使用json模块可以方便地进行JSON数据编码。
具体操作如下:
导入json模块:
import json
将Python数据类型转换为JSON格式:
使用json.dump()方法,将Python数据类型(如字典、列表)转换为JSON格式,并存储到指定文件中。语法如下:
json.dump(obj, fp, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)
其中,参数obj为Python数据类型,参数f为文件路径。
代码示例:
import json
data = {"name": "Tom", "age": 18, "gender": "male"}
with open("data.json", "w") as f:
json.dump(data, f)
运行代码后,会在当前工作目录中生成一个data.json文件,文件内容为转换后的JSON格式数据:
{"name": "Tom", "age": 18, "gender": "male"}
将Python数据类型转换为JSON格式,返回JSON字符串:
使用json.dumps()方法,将Python数据类型(如字典、列表)转换为JSON格式,并返回一个对应的JSON字符串。语法如下:
json.dumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)
其中,参数obj为Python数据类型。
代码示例:
import json
data = {"name": "Tom", "age": 18, "gender": "male"}
json_str = json.dumps(data)
print(json_str)
运行代码后,控制台会输出转换后的JSON格式字符串:
{"name": "Tom", "age": 18, "gender": "male"}
可以根据实际情况选择使用json.dump()或json.dumps()进行JSON数据编码,以便将采集到的数据存储为JSON格式,方便后续的数据处理和解析等操作。
关注公众号:python技术训练营,精选优质文档,好玩的项目
内容:
1.面试专题几十个大厂面试题
2.入门基础教程
3.11模块零基础到精通笔记
4.百个项目实战+爬虫教程+代码
5.量化交易,机器学习,深度学习
6.Python游戏源码
7.交流学习
8.了解接单市场
9.DNF自动识别打怪
10.3263页学习资料