pyflink实现实时数据从kafka消费到mysql
写在前头:
更多大数据相关精彩内容请进我的知识星球,每周定期更新
正篇
技术路线:实时数据——>kafka——>flink——>mysql
1、 实时数据:
参考链接https://blog.csdn.net/qq_22611181/article/details/119900250,该链接是如何用python写kafka生产者程序。
2、flink:
这里我们直接在本地开发环境Pycharm跑的程序,就不需要安装flink了,感兴趣Linux镜像安装部署flink的可以参考该链接https://blog.csdn.net/qq_22611181/article/details/119812701。
3、模拟数据为客流数据:
客流数据格式为json,其关键key有车站id,车站名,发生时间,设备id,客流量,进站还是出站,具体如下所示
{'stationid':1, 'stationname':'车站1', 'time':'2021-08-01 00:00:00', 'equipmentid':10, 'num':10, 'inorout':0}
python代码如下(acks只能-1, 0, 1,然后hosts文件需要配置zk地址映射和kafka集群的地址映射):
4、配置pycharm的flink环境:
首先最重要的是版本问题,这里给出我的相关版本配置
kafka:0.10.2.0
jdk:1.8.0_201
apache-flink: 1.13.2
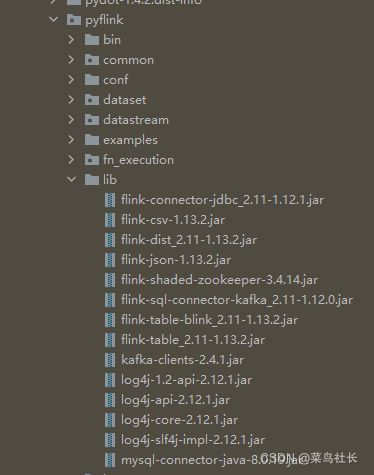
相应的jar包版本参考如下图所示的jar包版本。
将jar包放入External Libraries下的site-packages下的pyflink下的lib中,如下图所示的位置。
4.1、测试flink环境是否没问题
先创建一个test.py用下面代码测试
from pyflink.table import DataTypes,EnvironmentSettings,StreamTableEnvironment
from pyflink.table.expressions import col
from pyflink.table.udf import udf
def table_api_demo():
env_settings=EnvironmentSettings.new_instance().in_streaming_mode().use_blink_planner().build() #这里格式有点不对,自己调整
t_env=StreamTableEnvironment.create(environment_settings=env_settings)
t_env.get_config().get_configuration().set_string('parallelism.default','4')
tab=t_env.from_elements([("hello",1),("world",2),("flink",3)],['a','b'])
transformed_tab=tab.select(sub_string(col('a'),2,4))
print(transformed_tab.explain())
table_result=transformed_tab.execute()
withtable_result.collect()asresults:
for result in results:
print(result)
print(tab)
@udf(result_type=DataTypes.STRING())
def sub_string(s:str,begin:int,end:int):
returns[begin:end]
if__name__=='__main__':
table_api_demo()
测试结果如下:
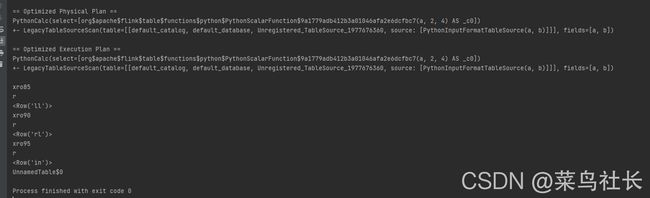
这说明flink安装没有问题,可以继续下一步了。
4.2、pyflink消费kafka实时数据到mysql
首先在mysql数据库中建立表
CREATE TABLE IF NOT EXISTS `flink-test`.`test3`(
`stationId` INT,
`stationName` VARCHAR(100),
`passengerNum` INT,
PRIMARY KEY ( `stationId` )
)ENGINE=InnoDB DEFAULT CHARSET=utf8;代码如下所示:
#!/u写入sr/bin/python3.8
#-*-coding:UTF-8-*-
import os
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import StreamTableEnvironment,EnvironmentSettings
#创建TableEnvironment,并选择使用的Planner
env=StreamExecutionEnvironment.get_execution_environment()
t_env=StreamTableEnvironment.create(
env,
environment_settings=EnvironmentSettings.new_instance().use_blink_planner().build())
sourceKafkaDdl="""
create table sourceKafka(
stationId int,
stationName varchar,
passengerNum int
)
with(
'connector.type'='kafka',
'connector.version'='universal',
'connector.topic'='passenger-flow2',
'connector.properties.zookeeper.connect'='tdh09:2181',
'connector.properties.bootstrap.servers'='tdh09:9092',
'format.type'='json',
'format.ignore-parse-errors'='true'
)
"""
# 数据库地址改为自己的,端口也是如此还有数据库名
mysqlSinkDdl="""
CREATE TABLE mysqlSink(
stationId INT,
stationName VARCHAR,
passengerNum INT,
PRIMARYKEY(stationId)NOT ENFORCED
)WITH(
'connector.type'='jdbc',
'connector.url'='jdbc:mysql://10.166.33.107:41949/flink-test',
'connector.table'='***',
'connector.username'='***',
'connector.password'='***',
'connector.write.flush.max-rows'='1'
)
"""
#创建Kafka数据源表
t_env.execute_sql(sourceKafkaDdl)
#创建MySql结果表
t_env.execute_sql(mysqlSinkDdl)
#取ID,TRUCK_ID两个字段写入到mysql
t_env.from_path('sourceKafka')\
.select("stationId,stationName,passengerNum")\
.insert_into("mysqlSink")
#执行作业
t_env.execute("pyFlink_mysql")
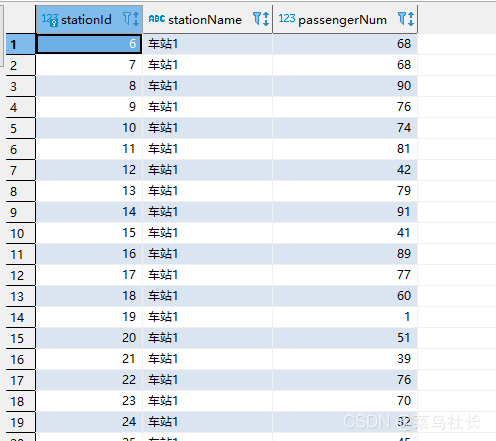
结果如下:
问题记录:
配置文件没有指定对kafka的版本
