PyFlink中使用kafka和MySQL
PyFlink中使用kafka和MySQL
文章目录
- PyFlink中使用kafka和MySQL
- 1 需求配置
- 2 MySQL的安装与配置
-
- 2.1 配置yum源
- 2.2 安装MySQL源
- 2.3 检查MySQL源是否安装成功
- 2.4 安装MySQL
- 2.5 启动MySQL服务
- 2.6 查看MySQL的状态
- 2.7 查看初始密码
- 2.7 以初始密码登录MySQL
- 2.8 修改root本地登录密码
- 3 单机系统下的kafka安装与配置
-
- 3.1 下载kafka压缩包
- 3.2 解压kafka到指定目录
- 3.3 修改server.properties
- 3.4 启动zookeeper
- 3.5 启动kafka
- 3.6 创建topic
- 3.7 删除topic
- 3.8 查看当前系统中所有的topic
- 3.9 启动生产者
- 3.10 启动消费者
- 4 kafka和MySQL在PyFlink中的使用
-
- 4.1 环境配置
- 4.2 程序代码
- 4.3 程序运行流程
- 4.4 启动kafka的生产者
- 4.5 遇到的问题
- Reference
1 需求配置
系统:Centos
Java环境:Java8
Pyflink-1.10.1
kafka_2.13-2.4.0
MySQL 8.0.21
2 MySQL的安装与配置
在PyFlink中使用MySQL,我们要先对MySQL进行安装和配置
2.1 配置yum源
在MySQL官网中下载YUM源rpm安装包:
http://dev.mysql.com/downloads/repo/yum/
下载过程如下图所示:

2.2 安装MySQL源
输入以下指令进行安装:
yum localinstall mysql80-community-release-el8-1.noarch.rpm
安装过程如下图所示:

2.3 检查MySQL源是否安装成功
输入以下指令进行检查:
yum repolist enabled | grep "mysql.*-community.*"
安装结果如下图所示:

看到上图内容表示安装成功。
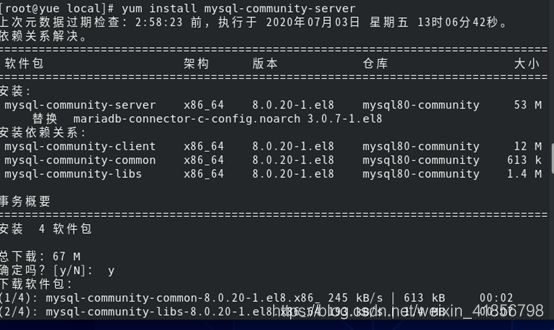
2.4 安装MySQL
输入以下指令进行安装:
yum install mysql-community-server
可能出现的问题:
未找到匹配的参数: mysql-community-server

解决方法:
输入yum module disable mysql指令,先禁用默认的MySQL模块,然后再进行安装就可以安装成功了
2.5 启动MySQL服务
输入以下指令启动MySQL服务:
systemctl start mysqld
2.6 查看MySQL的状态
输入以下指令查看mysql的状态:
systemctl status mysqld
查询结果如下图所示:

2.7 查看初始密码
查看初始密码的指令如下所示:
grep 'temporary password' /var/log/mysqld.log
查询结果如下图所示:
![]()
我的初始密码为:EqPX0rUauh>X
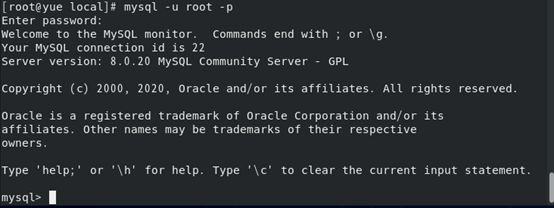
2.7 以初始密码登录MySQL
登录MySQL的指令为:
mysql -u root -p
登录MySQL后结果如下图所示:
2.8 修改root本地登录密码
使用如下指令修改本地登录密码:
ALTER USER 'root'@'localhost' IDENTIFIED BY 'Yue724223949_';
修改结果如下图所示:
![]()
注:“Yue724223949_”是我所设置的密码
3 单机系统下的kafka安装与配置
在PyFlink中使用MySQL,我们要先对MySQL进行安装和配置
3.1 下载kafka压缩包
使用如下指令下载kafka压缩包:
wget http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.4.0/kafka_2.13-2.4.0.tgz
3.2 解压kafka到指定目录
使用如下指令将kafka压缩包解压到指定目录(这里指定到/usr/local,自行修改):
tar -zxvf kafka_2.13-2.4.0.tgz -C /usr/local
3.3 修改server.properties
broker的含义:Kafka集群包含一个或多个服务器,每个服务器节点都被称为broker,每个broker都有唯一的id值用来区分,Kafka在启动时会在zookeeper中/brokers/ids路径下创建一个以当前broker的id为名称的节点,当broker下线时,该节点会自动删除,其他broker或客户端通过判断/brokers/ids路径下是否有此broker的id来确定该broker是否存在。
进入server.properties所在的目录并修改其配置:
cd /usr/local//kafka_2.13-2.4.0/config/
vim server.properties
找到broker.id并修改为1(如果是多个kafka服务,需配置不同broker.id作为标识)
broker.id=1
![]()
找到log.dirs并修改为指定路径(自行修改)
log.dirs=/usr/local/kafka_2.13-2.4.0/kafka_log
以后kafka产生的日志都会存在此路径
![]()
3.4 启动zookeeper
进入到kafka_2.13-2.0目录之下,输入以下命令启动zookeeper
bin/zookeeper-server-start.sh config/zookeeper.properties
启动结果如下图所示:

出现这个界面说明zookeeper启动成功,但由于是前台启动的,所以需要重新打开一个窗口,此时在新的窗口输入jps,可以看到如下内容:
![]()
此时说明zookeeper已经成功启动。
3.5 启动kafka
使用如下指令启动kafka:
bin/kafka-server-start.sh config/server.properties
启动结果如下图所示:

此时再打开一个新的窗口,原因与上述相同,然后在新的窗口输入jps可以看到下图的内容:
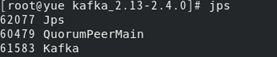
说明kafka启动成功。
3.6 创建topic
使用如下指令创建主题topic(topic为类别属性,来划分数据的所属类,可以理解为数据库的一张表,topic的名字就是表的名字):
bin/kafka-topics.sh --create --zookeeper localhost:2181 -replication-factor 1 --partitions 1 --topic test_statistic
其中各个参数的含义为:
–create为创建
–zookeeper localhost:2181为指定zookeeper的地址(这里为本地,非本地需指定ip,zk的默认端口为2181)
–replication-factor 1 为指定副本的个数(partition的副本,consumer并不会从副本中消费数据,而是为了防止数据丢失)
–partitions 1 为指定分区个数(topic的数据被分割成一个或多个partition,topic至少有一个partition)
–topic test_statistic 指定topic的名字为test_statistic
建立后的结果如下图所示:

3.7 删除topic
使用如下指令删除topic:
bin/kafka-topics.sh --delete --zookeeper localhost:2181 --topic test_statistic
删除结果如下图所示:

3.8 查看当前系统中所有的topic
使用如下指令查看当前系统中所有的topic:
bin/kafka-topics.sh --list --zookeeper localhost:2181
查询结果如下图所示:

3.9 启动生产者
使用如下指令启动生产者:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test_statistic
其中参数的含义为:
–broker-list localhost:9092 为连接对应的broker(这里连接的是本地端口为9092的broker服务,可指定ip连接指定的broker)
–topic test_statistic 指定把消息生产到哪个topic中
启动生产者后我们可以看到如下图所示的内容:
![]()
此时说明生产者启动成功。
3.10 启动消费者
我们可以使用如下指令启动消费者:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test_statistic --from-beginning
其中参数的含义为:
–bootstrap-server localhost:9092 指定从哪个broker中拉取消息,(当我们连接到任意一个Broker后,
我们就已经连接到了整个Kafka集群,我们连接的第一个Broker称之为Bootstrap Broker)
–from-beginning 表示从头开始读取
此时我们可以看到如下图所示的内容:

此时说明消费者启动成功,并拉去了来自生产者的两条信息:“hello”和“ www.baidu.com 8080”
至此,整个单机系统下的kafka安装成功。
4 kafka和MySQL在PyFlink中的使用
4.1 环境配置
在使用PyFlink代码连接kafka之前,我们需要先将connector所需要的jar包导入到pyflink的lib目录中,一般情况下lib目录的路径为:/usr/local/lib/python3.6/site-packages/pyflink/lib
我们需要用下列命令将所需要的jar包导入lib目录中:
curl -O https://repo1.maven.org/maven2/org/apache/flink/flink-sql-connector-kafka_2.11/1.10.0/flink-sql-connector-kafka_2.11-1.10.0.jar
curl -O https://repo1.maven.org/maven2/org/apache/flink/flink-jdbc_2.11/1.10.0/flink-jdbc_2.11-1.10.0.jar
curl -O https://repo1.maven.org/maven2/org/apache/flink/flink-csv/1.10.0/flink-csv-1.10.0-sql-jar.jar
curl -O https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.19/mysql-connector-java-8.0.19.jar
添加完成后如下图所示:

因为PyFlink内部系统不一定都包含你所需要的类库、模块等,所以需要导入jar包。
Curl可以认为是使用url的一个下载工具。
注:如果使用命令将代码提交到Flink上,要进入jar所导入的lib目录内提交,本文是在/usr/local/lib/python3.6/site-packages/pyflink下提交的,因为该目录下lib目录中存有运行该程序所需要的所有jar包(也就是说在哪里使用命令行,就在哪个flink-conf里面添加jar包)
4.2 程序代码
cdn_demo.py
import os
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.table import StreamTableEnvironment, EnvironmentSettings
from cdn_connector_ddl import kafka_source_ddl,mysql_sink_ddl
# 创建Table Environment, 并选择使用的Planner
env = StreamExecutionEnvironment.get_execution_environment()
t_env = StreamTableEnvironment.create(
env,
environment_settings=EnvironmentSettings.new_instance().use_blink_planner().build())
# set source table
# 创建Kafka数据源表,以及会创建一个kafka的新的topic——cdn_access_log
t_env.sql_update(kafka_source_ddl)
# 创建MySql结果表,这个创建的只是flink内部的table,所以在此之前我们需要在MySQL中重新建立MySQL的table表。
t_env.sql_update(mysql_sink_ddl)
# 核心的统计逻辑
t_env.from_path("cdn_access_log") \
.select("uuid, "
"client_ip as province, "
"response_size, request_time")\
.group_by("province")\
.select( # 计算访问量
"province, count(uuid) as access_count, "
# 计算下载总量
"sum(response_size) as total_download, "
# 计算下载速度
"sum(response_size) * 1.0 / sum(request_time) as download_speed") \
.insert_into("cdn_access_statistic")
# 执行作业
t_env.execute("test")
cdn_connector_ddl.py
kafka_source_ddl = """
CREATE TABLE cdn_access_log (
uuid VARCHAR,
client_ip VARCHAR,
request_time BIGINT,
response_size BIGINT
) WITH (
'connector.type' = 'kafka',
'connector.version' = 'universal',
'connector.topic' = 'cdn_access_log',
'connector.properties.zookeeper.connect' = 'localhost:2181',
'connector.properties.bootstrap.servers' = 'localhost:9092',
'format.type' = 'csv',
'format.ignore-parse-errors' = 'true'
)
"""
# 注意修改MySQL中table的名称和MySQL的登录密码
mysql_sink_ddl = """
CREATE TABLE cdn_access_statistic (
province VARCHAR,
access_count BIGINT,
total_download BIGINT,
download_speed DOUBLE
) WITH (
'connector.type' = 'jdbc',
'connector.url' = 'jdbc:mysql://localhost:3306/flink?autoReconnect=true&failOverReadOnly=false&useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=GMT%2B8',
'connector.table' = 'cdn_access_statistic',
'connector.username' = 'root',
'connector.password' = 'Yue724223949_',
'connector.write.flush.interval' = '1s'
)
"""
4.3 程序运行流程
(1)首先使用如下指令打开zookeeper和kafka:
进入到 kafka_2.13-2.0 目录之下,输入以下命令启动 zookeeper:
bin/zookeeper-server-start.sh config/zookeeper.properties
启动kafka:
bin/kafka-server-start.sh config/server.properties
(2)进入/usr/local/lib/python3.6/site-packages/pyflink/bin,启动单集群下的Flink:
./start-cluster.sh
(3)提交代码到Flink:
./bin/flink run -m localhost:8081 -pyfs /usr/local/flink/enjoyment.code/myPyFlink/enjoyment/cdn/cdn_connector_ddl.py -py /usr/local/flink/enjoyment.code/myPyFlink/enjoyment/cdn/cdn_demo.py
可能遇到的问题:
org.apache.flink.client.program.OptimizerPlanEnvironment$ProgramAbortException
解决方案:
查找日志文件,然后发现问题主要是“java.io.IOException: Cannot run program “python”: error=2, 没有那个文件或目录”
出现问题的原因:python3.6是真正安装的版本,但是系统需要python版本,所以我们通过建立一个链接来解决这个问题,我们使用如下代码来建立一个新的链接
ln -s /usr/bin/python3.6 /usr/bin/python
注:一定要学会看日志文件,日志文件中有出错的具体原因,Flink的日志文件在log文件夹中
提交完成后打开网址localhost:8081,界面如下所示:

4.4 启动kafka的生产者
进入到 kafka_2.13-2.0 目录之下,输入以下命令启动 producer:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic cdn_access_log
如果没有创建,需要先创建cdn_access_log这个topic
向kafka中输入:11,110,20,200
打开MySQL,进入Flink数据库,select表cdn_access_statistic,可以得到以下结果:

此时说明代码已经运行成功。
4.5 遇到的问题
(1)首先,所有遇到的错误,都要先找到其cause by,也就是看出错的原因是什么。
例如如下错误,出错的原因就是url出现了问题:
org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:74)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleMessage(AkkaRpcActor.java:152)
at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:26)
at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:21)
at scala.PartialFunction$class.applyOrElse(PartialFunction.scala:123)
at akka.japi.pf.UnitCaseStatement.applyOrElse(CaseStatements.scala:21)
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:170)
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171)
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171)
at akka.actor.Actor$class.aroundReceive(Actor.scala:517)
at akka.actor.AbstractActor.aroundReceive(AbstractActor.scala:225)
at akka.actor.ActorCell.receiveMessage(ActorCell.scala:592)
at akka.actor.ActorCell.invoke(ActorCell.scala:561)
at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:258)
at akka.dispatch.Mailbox.run(Mailbox.scala:225)
at akka.dispatch.Mailbox.exec(Mailbox.scala:235)
at akka.dispatch.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260)
at akka.dispatch.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339)
at akka.dispatch.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979)
at akka.dispatch.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)
Caused by: java.lang.IllegalArgumentException: Expecting a non-empty string for url
在找到出现问题的原因后,我们就可以去处理问题了。
(2)在提交命令时使用-pyfs可以用来添加import的python文件,也就是添加python的依赖文件,不同的文件中间使用“,”隔开
(3)输入数据进入kafka的时候一定要与你定义的数据格式相一致,例如你定义了两个field,你只能输入两个数据,如果输入数据过多的话就无法将kafka内的数据导入到MySQL中了。(因为我们是先在flink内部创建了一个关于kafka的table,然后才通过这个table将数据输入到Flink关于MySQL的table中,最后才将数据输入到外部的MySQL表中)
(4)外部的Kafka的topic与MySQL的table都要在程序运行之前进行创建。
(5)注意使用DDL的时候要修改好MySQL的配置,特别是passport和URL.
Reference
PyFlink 场景案例 - PyFlink实现CDN日志实时分析