一文解析Multi-queue 架构
Linux上传统的块设备层(Block Layer)和IO调度器(如cfq)主要是针对HDD(hard disk drivers)设计的。我们知道,HDD设备的随机IO性能很差,吞吐量大约是几百IOPS(IOs per second),延迟在毫秒级,所以当时IO性能的瓶颈在硬件,而不是内核。但是,随着高速SSD(Solid State Disk)的出现并展现出越来越高的性能,百万级甚至千万级IOPS的数据访问已成为一大趋势,传统的块设备层已无法满足这么高的IOPS需求,逐渐成为系统IO性能的瓶颈。
为了适配现代存设备(高速SSD等)高IOPS、低延迟的IO特征,新的块设备层框架Block multi-queue(blk-mq)应运而生。本文就带大家来了解下Linux 块设备层的blk-mq框架和代码实现。
一、单队列框架和存在的问题
Linux上传统块设备层使用单队列(Single-queue/SQ)架构,如图1所示。简单来说,块设备层负责管理从用户进程到存储设备的IO请求,一方面为上层提供访问不同存储设备的统一接口,隐藏存储设备的复杂性和多样性;另一方面,为存储设备驱动程序提供通用服务,让这些驱动程序以最适合的方式接收来自上层的IO请求。Linux Block Layer主要提供以下几个方面的功能:
- bio的提交和完成处理,上层通过bio来统一描述发往块设备的IO请求
- IO请求暂存,如合并、排序等
- IO调度,如noop、cfq、deadline等
- IO记账,如统计提交到块设备的IO总量,IO延迟等信息
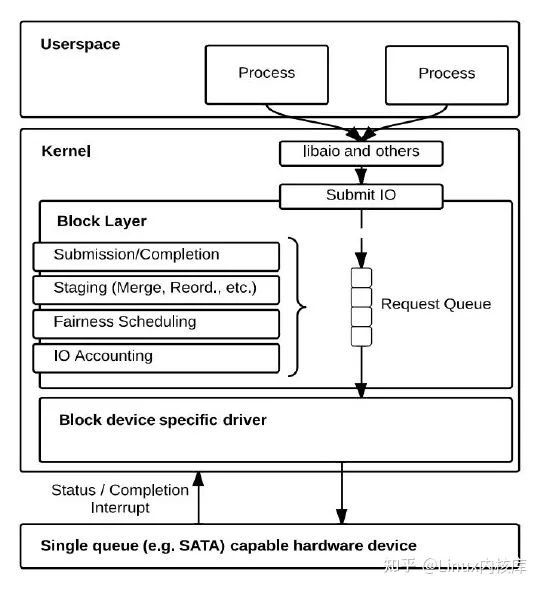
图1. 单队列的Linux block layer设计
图片引用自《Linux Block IO: Introducing Multi-queue SSD Access on Multi-core Systems》
由于采用单队列(每个块设备1个请求队列--Requst Queue)的设计,传统的Block Layer对多核体系的可扩展性(scalability)不佳。当系统配备现代高速存储器件时,单队列引入的软件开销变得突出(在多socket体系中尤为严重),成为IO性能的瓶颈。多核体系中blk-sq的软件开销主要来自三个方面:
- 请求队列锁竞争:blk-sq使用spinlock(q->queue_lock)来同步IO请求队列的访问,每次往请求队列中插入或删除IO请求,必须先获取此锁;IO提交时如果操作请求队列,必须先获取此锁;IO排序和调度操作时,也必须先获取此锁。这一系列操作继续之前,必须先获得请求队列锁,在高IOPS场景(多个线程同时提交IO请求)下,势必引起剧烈的锁竞争,带来不可忽视的软件开销。从图2中可以看到,Linux- 2.6.32 中scsi+blk-sq,高IOPS场景下,约80%的cpu时间耗费在锁获取上。
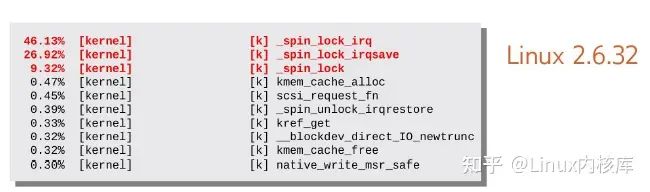
图2. 高IOPS场景下cpu热点数据
图片引用自《High Performance Storage with blk-mq and scsi-mq》
- 硬件中断:高的IOPS意味着高的中断数量。在多数情况下,完成一次IO需要两次中断,一次是存储器件触发的硬件中断,另一次是IPI核间中断用于触发其他cpu上的软中断。
- 远端内存访问:如果提交IO请求的cpu不是接收硬件中断的cpu且这两个cpu没有共享缓存,那么获取请求队列锁的过程中还存在远端内存访问问题。
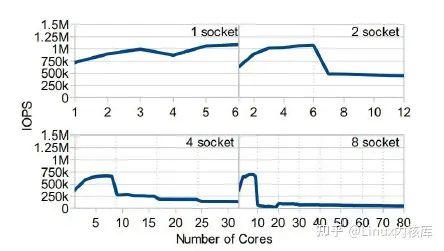
图3. blk-sq IOPS吞吐量随cpu数量的变化曲线,blk-sq支持的最高吞吐量大概在1MIOPS
图片引用自《Linux Block IO: Introducing Multi-queue SSD Access on Multi-core Systems》
二、多队列框架和解决的问题
针对blk-sq存在的问题,Jens Axboe (Linux内核Block Layer Maintainer)提出了多队列(multi-queue/MQ)的块设备层架构(blk-mq),如图4所示:
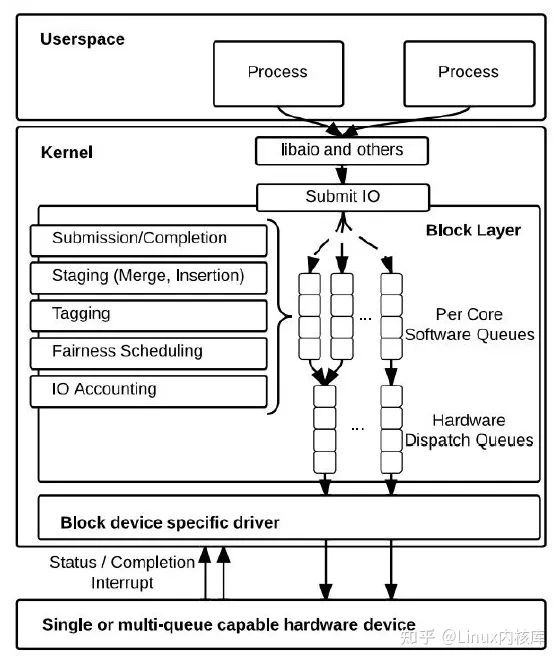
图4. 两层队列的Block Layer设计
图片引用自《Linux Block IO: Introducing Multi-queue SSD Access on Multi-core Systems》
blk-mq中使用了两层队列,将单个请求队列锁的竞争分散多个队列中,极大的提高了Block Layer并发处理IO的能力。两层队列的设计分工明确:
- 软件暂存队列(Software Staging Queue):blk-mq中为每个cpu分配一个软件队列,bio的提交/完成处理、IO请求暂存(合并、排序等)、IO请求标记、IO调度、IO记账都在这个队列上进行。由于每个cpu有单独的队列,所以每个cpu上的这些IO操作可以同时进行,而不存在锁竞争问题
- 硬件派发队列(Hardware Dispatch Queue):blk-mq为存储器件的每个硬件队列(目前多数存储器件只有1个)分配一个硬件派发队列,负责存放软件队列往这个硬件队列派发的IO请求。在存储设备驱动初始化时,blk-mq会通过固定的映射关系将一个或多个软件队列映射(map)到一个硬件派发队列(同时保证映射到每个硬件队列的软件队列数量基本一致),之后这些软件队列上的IO请求会往对应的硬件队列上派发。
MQ架构解决了SQ架构中请求队列锁竞争和远端内存访问问题,极大的提高了Block Layer的IOPS吞吐量。从图5中,我们可以看到Linux 3.17-rc3 中scsi-mq+blk-mq,与图2相同的高IOPS场景下仅3%的cpu时间耗费在锁获取上。

图5. scsi-mq_+blk-mq高IOPS场景下cpu热点数据
图片引用自《High Performance Storage with blk-mq and scsi-mq》
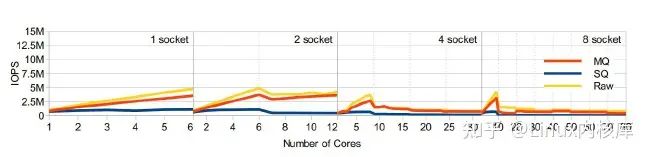
图6. IOPS吞吐量随cpu数量的变化曲线,blk-mq更加接近raw设备的性能
图片引用自《Linux Block IO: Introducing Multi-queue SSD Access on Multi-core Systems》
资料直通车:Linux内核源码技术学习路线+视频教程内核源码
学习直通车:Linux内核源码内存调优文件系统进程管理设备驱动/网络协议栈
三、多队列框架代码分析
blk-mq代码在Linux-3.13(2014)内核中合入主线,在Linux-3.16中成为内核的一个完整特性,在Linux-5.0内核中,blk-sq代码(包括基于blk-sq的IO调度器,如cfq、noop)已被完全移除,MQ成为Linux Block layer的默认选项。下面基于Linux-5.6.0内核介绍blk-mq代码和关键数据结构。
request和tag分配
blk-mq中,request和tag是绑定的。首先,我们来看下两个与tag分配有关的重要数据结构--blk_mq_tags和blk_mq_tag_set。
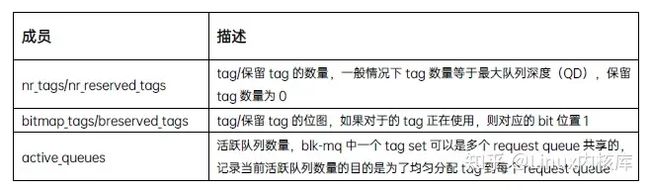
- blk_mq_tags,用于描述tag和request的集合,它的主要成员如下:
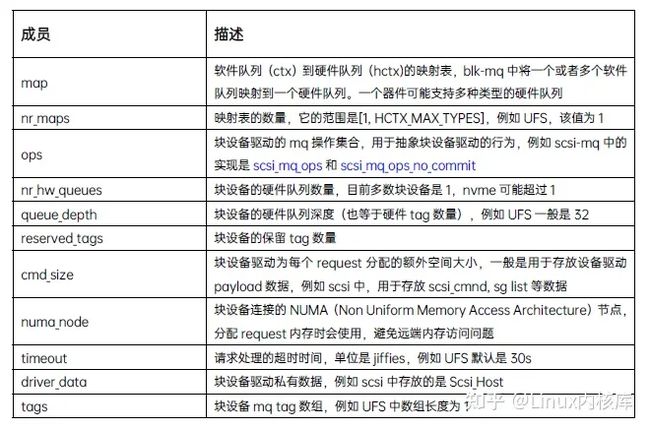
- blk_mq_tag_set,用于描述与存储器件相关的tag集合,抽象了存储器件的IO特征,它的主要成员如下:
与SQ框架一样,MQ框架中使用request结构体来描述IO请求;不同的是,SQ使用内存池来分配request结构体(参见__get_request),在request往驱动派发时分配tag(参见blk_queue_start_tag),MQ中request和tag分配是绑定在一起的(参见blk_mq_get_request), 具体表现为:
- request内存分配在块设备驱动初始化时完成(通过调用blk_mq_alloc_tag_set),避免IO发生时request内存分配带来的开销
- tag 作为request(static_rqs/rqs数组)的索引
blk_mq_alloc_tag_set: 为一个或者多个请求队列分配tag和request集合(tag set可以是多个request queue共享的,例如UFS设备,一个host controller只有一个tag set,但器件可能划分成多个LU--Logical Unit,每个LU有单独的request queue, 这些不同的request queue共享一个tag set),主要流程如下:
- 设置硬件队列数量(nr_hw_queues)和映射表数量(nr_maps)
- 调用blk_mq_realloc_tag_set_tag 根据硬件队列数量扩展tags数组
- 调用blk_mq_update_queue_map更新映射表(map: cpu id->hw queue id)
- 调用blk_mq_alloc_rq_maps分配request和tag(队列深度可能会根据内存状态下调)
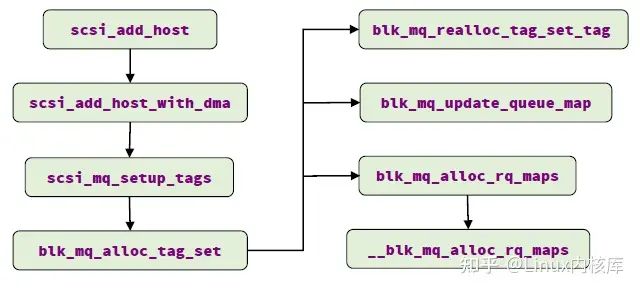
图7. scsi-mq驱动初始化时tag set分配流程
blk_mq_get_request: 为bio分配request。MQ中request占用的内存在块设备驱动初始化时分配完成(tags->static_rqs), tag作为数组的索引获取对应的request,因此MQ中分配request即分配tag(使用sbitmap标记对应tag的是否已被使用)。该函数的主要流程如下:
- 调用blk_mq_get_ctx 获取当前cpu的软件队列(ctx)
- 调用blk_mq_map_queue 找到软件队列(ctx)对应的硬件派发队列(hctx)
- 对于配置了调度器的队列,调用limit_depth限制队列深度(影响tag获取);对于无调度器的队列,更新tag set的当前活跃队列数量(用于均分tag到不同request_queue)
- 调用blk_mq_get_tag获取tag, 可能因当前无可用tag进入iowait状态
- 调用blk_mq_rq_ctx_init 初始化tag对应的request(tags->static_rqs[tag])
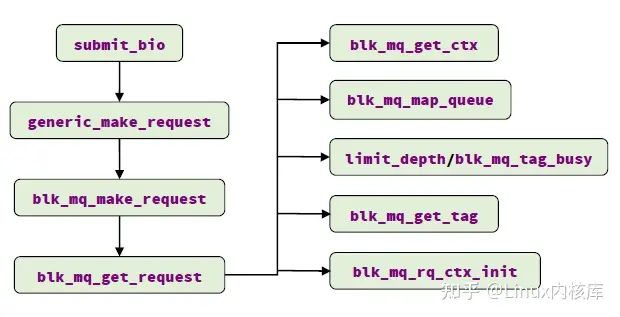
图8. blk-mq bio提交时request分配流程
request_queue初始化
基于blk-mq的块设备驱动初始化时,通过调用blk_mq_init_queue初始化IO请求队列(request_queue)。例如,scsi-mq驱动中,每次添加scsi设备(scsi_device)时都会调用blk_mq_init_queue接口来初始化scsi设备的请求队列。
blk_mq_init_queue:初始化IO请求队列--request_queue。函数的主要流程如下:
- 调用blk_alloc_queue_node分配请求队列的内存,分配的内存节点与设备连接的NUMA节点一致,避免远端内存访问问题。
- 调用blk_mq_init_allocated_queue初始化分配的请求队列(request_queue),blk-mq的request_queue中包含两层队列,即percpu的软件队列(ctx)和与块设备硬件队列一一对应的硬件派发队列(hctx)。这个初始化过程主要包含下面几步:
1.设置队列的mq_ops(q->mq_ops)为set->ops (例如scsi对应的实现是scsi_mq_ops)
2.设置request超时时间,初始化timeout_work(处理函数是blk_mq_timeout_work)
3.设置队列的make_request回调为blk_mq_make_request (bio的提交时会用到)
4.分配和初始化percpu软件队列(ctx)
5.关联request_queue和块设备的tag set
6.更新软件队列(ctx)到硬件派发队列(hctx)的映射关系(map: ctx->hctx)

图9. scsi-mq驱动创建scsi device时初始化requst_queue流程
IO的提交(submit)
blk-mq中,通过调用blk_mq_make_request将上层提交的bio封装成request并提交到块设备层,它的主要流程如下:
- 尝试与当前线程plug list(如果当前线程正在做IO plug)中的IO request合并
- 尝试与当前cpu软件队列中的IO request合并(如果使能调度器,且调度器实现bio_merge接口,则调用这个接口尝试与调度器队列中的IO request合并)
- 尝试IO请求的QoS(Quality of Service)限流(目前实现的QoS策略有wbt, io-latency cgroup, io-cost cgroup三种)

图10. blk-mq中IO提交流程
- 获取request,并将bio添加到request
- 生成request后,将request插入请求队列中,分下面几种情况
1.如果是fua/flush请求,则将request插入到flush队列,并调用blk_mq_run_hw_queue 启动请求派发
2.如果当前线程正在做IO plug且块设备是硬件单队列的(nr_hw_queues=1),则将request插入到当前线程的plug list
3.如果配置了调度器,则调用blk_mq_sched_insert_request将请求插入调度器队列(如果没有实现insert_requests接口,则插入到当前cpu的软件队列中)
4.如果是硬件多队列块设备上的同步IO请求,则调用blk_mq_try_issue_directly尝试将request直接派发到块设备驱动
5.其他情况,则调用blk_mq_sched_insert_request插入request(同case 3)
IO的派发(dispatch)
blk-mq中通过调用blk_mq_run_hw_queue派发IO请求到块设备驱动,MQ框架中存在很多的点会触发IO请求往块设备驱动派发,主要如下:
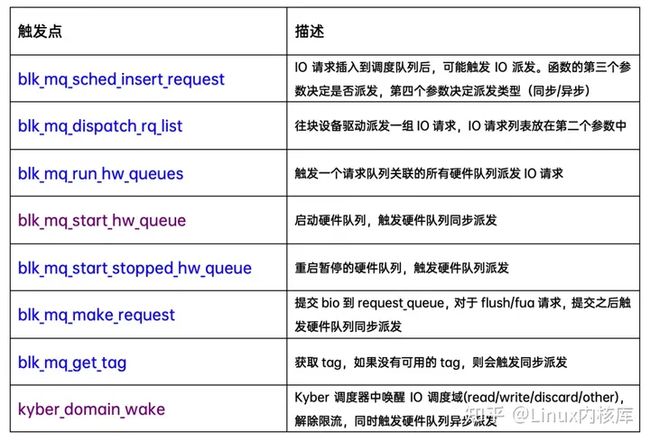
blk_mq_run_hw_queue: 启动硬件队列派发IO请求,可以是同步/异步的执行的。如果队列不在静默状态(quiesced)且有IO请求pending,则启动派发:
- 如果是同步派发,且当前cpu的软件队列映射到此硬件队列,则调用__blk_mq_run_hw_queue在当前线程上下文中执行IO请求派发
- 如果是异步派发,则启动延迟任务(hctx->run_work)执行IO请求派发
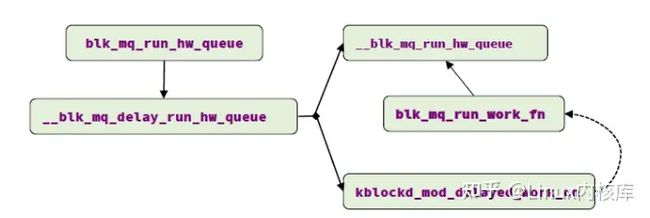
图11. blk-mq启动硬件队列派发IO请求的流程
无论是同步还是异步的派发模式,最终都会调用__blk_mq_run_hw_queue派发IO请求,这个函数先检查执行的上下文,然后调用blk_mq_sched_dispatch_requests派发IO请求到块设备驱动,这个函数的主要流程如下:

图12. blk-mq派发IO请求的流程
- 如果硬件派发队列(hctx->dispatch)非空, 则先调用blk_mq_dispatch_rq_list派发这个队列中的IO请求
- 如果配置了调度器,则调用blk_mq_do_dispatch_sched 从调度队列中派发IO请求
- 如果队列繁忙(dispatch_busy记录繁忙状态),则调用blk_mq_do_dispatch_ctx 从软件队列(软件队列选取采用Round-Robin策略)中取1个IO请求派发
- 否则,取映射到这个硬件队列的所有软件队列上的IO请求,调用blk_mq_dispatch_rq_list派发
上述4种情况都会调用blk_mq_dispatch_rq_list 将IO请求派发到块设备驱动,这个函数使用块设备驱动实现的几个接口完成派发逻辑:
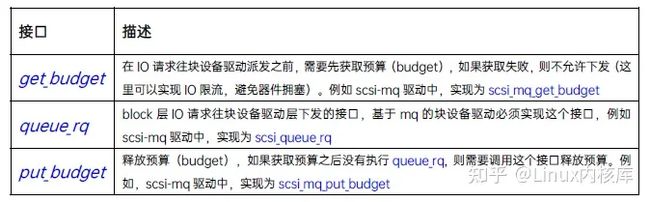
IO的完成(complete)
下面以UFS+scsi-mq驱动为例,讲解IO完成处理的过程,主要流程如图13所示:
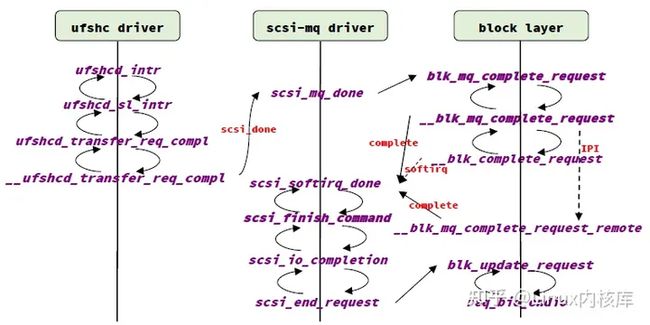
图13. ufs+scsi-mq驱动中一个IO的完成流程
- UFS设备完成一个IO请求之后,触发中断, ufshc(UFS host controller)驱动负责处理这个中断(服务例程是ufshc_intr),通过中断状态寄存器(REG_INTERRUPT_STATUS)判断是否有IO请求完成(UTP_TRANSFER_REQ_COMPL位),通过对比门铃寄存器(REG_UTP_TRANSFER_REQ_DOOR_BELL)和outstanding_reqs的值(异或操作)取得完成的IO请求。对于每个完成的IO请求,调用scsi_done进入scsi 命令的完成处理流程
- scsi-mq驱动中scsi_done的实现是scsi_mq_done,这个函数会调用blk-mq中的接口blk_mq_complete_request 进入块设备层的request完成处理流程
- Block Layer对于request完成处理有4种方式,具体如下:
1.对于硬件单队列的块设备,调用__blk_complete_request处理。如果发起IO请求的cpu就是当前cpu或者和当前cpu共享缓存,则发起当前cpu上的block软中断,在block软中断中继续request完成处理流程
2.对于硬件单队列的块设备,如果不满足case 1的条件,则通过IPI(inter-processor interrupt)发起其他cpu上的block软中断,在block软中断继续request完成处理流程
3.对于硬件多队列设备,如果当前cpu与发起IO请求的cpu不共享缓存(且不是高优先级的IO请求),则调用__blk_mq_complete_request_remote发起远端cpu上的request完成处理流程(IPI)
4.对于硬件多队列设备,非上述情况,直接在当前cpu上(硬件中断上下文)继续request完成处理流程
- 上述4种情况,最后都会调用mq_ops->complete 继续处理request的完成,对于scsi-mq驱动,这个接口的实现是scsi_softirq_done,经过一系列过程调用后(参见图13),由req_bio_endio 完成bio
四、多队列IO调度器
事实上,在blk-mq框架一开始是不支持IO调度器的(Linux-3.13)。由于高速存储器件IO特征是高IOPS,低延迟,我们希望IO的软件开销尽可能低,而IO调度会增加软件开销,所以专门针对这类器件设计的blk-mq在一开始并没有加入IO调度的能力。
当时的Linux块设备层是SQ和MQ两套框架共存的(SQ用于HDD这样的慢速块设备驱动,MQ用于nvme这样的高速块设备驱动)。Linux Block Layer的发展趋势是希望能够使用一套框架同时满足慢速器件和高速器件的需求,所以blk-mq引入后,Linux上的块设备驱动程序开始往MQ框架迁移,在Linux-5.0上,所有基于SQ的块设备驱动都完成了向MQ框架的转化,Block Layer的SQ框架和相关IO调度器被完全移除。
我们知道对于慢速器件(特别是旋转磁盘,随机IO性能很差)来讲,IO调度是十分重要的,同时一些高速器件(特别是硬件单队列的器件,如emmc,ufs)也有IO调度的需求。
因此在Linux-4.11上,Jens Axboe在MQ框架上增加了IO调度的能力,同SQ框架一样,MQ中的IO调度器也是插件化的,框架提供一系列的接口,由具体的IO调度算法(如mq-deadline)实现这些接口:

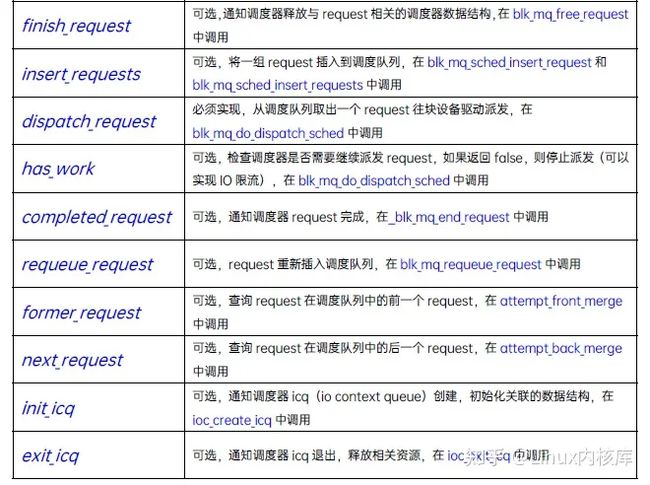
目前基于blk-mq实现的IO调度器主要有下面几个:
- mq-deadline: 根据IO请求的类型(read/write)分配不同的到期时间(deadline),并将IO请求按照deadline排序,同时支持IO合并,派发时优先选择deadline最小的IO请求,以此来控制IO的延迟。它在Linux-4.11上合入主线,是mq调度器的默认选项。对这个调度器感兴趣的同学可以阅读参考资料8和源码(mq-deadline.c)进一步了解相关细节
- bfq: budget fair queuing, 它在Linux-4.12上合入主线,主要针对的是慢速器件,如机械硬盘。它提供了IO排序、IO优先级、按权重均匀分配IO带宽和组调度的能力,它保证每个IO的最大延迟可控的同时充分利用器件IO带宽。它的缺点是调度的软件开销比较高,例如Arm CortexTM-A53 8核系统中,最高只能支持80KIOPS,因此不适用于高速器件(如百万级IOPS的SSD)。对这个调度器感兴趣的同学可以阅读参考资料9和源码(bfq-iosched.c)进一步了解相关细节
- kyber: 它在Linux-4.12上合入主线,是一个真正意义上的mq调度器,适用于高速器件。它对不同类型的IO(read/write/discard/others)设置不同的延迟要求,分开调度,同时监控每个IO调度域的延迟情况,如果某个IO调度域的延迟过高,则动态增加这个IO调度域的队列深度,并减小延迟OK的IO调度域的队列深度,以达到控制IO延迟的目的。本质上这种调度算法倾向于优先调度延迟要求高的IO(如read)。对这个调度器感兴趣的同学可以阅读参考资料10和源码(kyber-iosched.c)进一步了解相关细节
五、结语
本文主要介绍了blk-mq框架,基于这个框架,我们能够实现下面几件事情:
- 实现基于blk-mq的块设备驱动程序(具体实现可以参考空设备驱动--null_blk)
- 实现基于blk-mq的IO调度器,例如提供关键IO的优先处理能力、IO限流等(具体实现可以参考kyber-iosched.c)
- 改进或者扩展blk-mq框架,来达到业务的需求(事实上,在blk-mq演进的过程中,许多想法都来自底层块设备驱动,特别是nvme驱动和scsi-mq驱动)
