Mercury: Enabling Remote Procedure Call for High-Performance Computing
Abstract
Abstract—Remote Procedure Call (RPC) is a technique that has been largely used by distributed services. This technique, now more and more used in the context of High-Performance Computing (HPC), allows the execution of routines to be delegated to remote nodes, which can be set aside and dedicated to specific tasks. However, existing RPC frameworks assume a sockets based network interface (usually on top of TCP/IP) which is not appropriate for HPC systems, as this API does not typically map well to the native network transport used on those systems, resulting in lower network performance. In addition, existing RPC frameworks often do not support handling large data arguments, such as those found in read or write calls.
We present in this paper an asynchronous RPC interface specifically designed for use in HPC systems that allows asynchronous transfer of parameters and execution requests and direct support of large data arguments. The interface is generic to allow any function call to be shipped. Additionally, the network implementation is abstracted, allowing easy porting to future systems and efficient use of existing native transport mechanisms.
远程过程调用(RPC)是分布式服务广泛使用的一种技术。 这种技术现在越来越多地用于高性能计算 (HPC) 的上下文中,它允许将例程的执行委托给远程节点,这些节点可以留出并专用于特定任务。 然而,现有的 RPC 框架采用基于套接字的网络接口(通常在 TCP/IP 之上),这不适合 HPC 系统,因为此 API 通常不能很好地映射到这些系统上使用的本机网络传输,从而导致网络性能较低。 此外,现有的 RPC 框架通常不支持处理大数据参数,例如在读取或写入调用中发现的参数。我们在本文中提出了一个异步 RPC 接口,专门设计用于 HPC 系统,允许参数和执行请求的异步传输和直接支持大数据参数。 该接口是通用的,允许传送任何函数调用。 此外,网络实现是抽象的,允许轻松移植到未来的系统并有效使用现有的本地传输机制。
RPC(远程过程调用,Remote Procedure Call)是一种用于在分布式系统中实现远程通信的协议和编程模型。它允许一个计算节点(通常是客户端)通过网络调用另一个计算节点(通常是服务器端)上的函数或方法,就像本地调用一样。RPC隐藏了网络通信的细节,使得远程调用过程对开发者来说更加透明和简单。
在RPC中,客户端和服务器之间的通信通常通过网络传输协议(如TCP或UDP)来实现。整个过程通常包含以下步骤:
1.定义接口:首先,需要定义客户端和服务器之间通信的接口。这可以通过使用特定的IDL(接口定义语言)来实现,例如Protocol、Buffers、Thrift或SOAP。接口定义描述了可用的方法、参数和返回值类型。
2.生成代码:根据接口定义,客户端和服务器代码可以通过IDL编译器生成。这些生成的代码包含了客户端和服务器的存根(Stub)和桩(Skeleton),用于处理网络通信和序列化/反序列化数据。
3.远程调用:客户端应用程序可以通过调用本地的客户端存根来触发远程调用。存根负责将调用请求封装为网络消息并发送给服务器。服务器收到请求后,使用桩解析请求并执行相应的方法。执行结果将被封装为响应消息,并发送回客户端。
4.数据传输和序列化:在RPC中,函数参数和返回值需要在客户端和服务器之间进行序列化和反序列化。这是为了将数据转换为网络传输所需的格式,以便在不同的计算节点之间传输。
5.错误处理和异常:RPC框架通常提供错误处理机制和异常传播。当远程调用发生错误或异常时,错误信息可以传递回客户端,以便进行适当的处理。
常见的RPC框架包括 gRPC、Apache Thrift、Apache、Avro、XML-RPC等。这些框架提供了各种功能,如跨语言支持、负载均衡、服务发现和身份验证等,使得远程调用更加方便和可靠。
RPC在分布式系统中广泛应用于各种场景,包括微服务架构、分布式计算和远程数据访问等,以便实现不同节点之间的通信和协作。
I. INTRODUCTION
When working in an heterogeneous environment, it is often very useful for an engineer or a scientist to be able to distribute the various steps of an application workflow; particularly so in high-performance computing where it is common to see systems or nodes embedding different types of resources and libraries, which can be dedicated to specific tasks such as computation, storage or analysis and visualization. Remote procedure call (RPC) [1] is a technique that follows a client/server model and allows local calls to be transparently executed onto remote resources. It consists of serializing the local function parameters into a memory buffer and sending that buffer to a remote target which in turn deserializes the parameters and executes the corresponding function call. Libraries implementing this technique can be found in various domains such as web services with Google Protocol Buffers [2] or Facebook Thrift [3], or in domains such as grid computing with GridRPC [4]. RPC can also be realized using a more object oriented approach with frameworks such as CORBA [5] or Java RMI [6] where abstract objects and methods can be distributed across a range of nodes or machines.
当在异构环境中工作时,工程师或科学家能够分配应用程序工作流程的各个步骤通常非常有用; 尤其是在高性能计算中,通常会看到嵌入不同类型资源和库的系统或节点,这些资源和库可以专用于特定任务,例如计算、存储或分析和可视化。 远程过程调用 (RPC) [1] 是一种遵循客户端/服务器模型并允许对远程资源透明地执行本地调用的技术。 它包括将本地函数参数序列化到内存缓冲区并将该缓冲区发送到远程目标,远程目标反过来反序列化参数并执行相应的函数调用。 实现该技术的库可以在各种领域中找到,例如使用 Google Protocol Buffers [2] 或 Facebook Thrift [3] 的 Web 服务,或者使用 GridRPC [4] 的网格计算等领域。 RPC 也可以使用更面向对象的方法和框架来实现,例如 CORBA [5] 或 Java RMI [6],其中抽象对象和方法可以分布在一系列节点或机器上。
异构环境:异构环境指的是由不同类型的计算设备和处理器组成的计算系统。在异构环境中,不同的设备可能具有不同的体系结构、处理能力和特性。 常见的异构环境包括:
1.多核CPU和加速器:这种环境中,计算系统由多个CPU核心和加速器(如GPU、FPGA或ASIC)组成。CPU核心通常用于通用目的的计算任务,而加速器则用于高度并行的特定计算任务,如图形渲染、深度学习或密码学运算。
2.分布式计算集群:这种环境中,计算系统由多台计算机组成,每台计算机可能具有不同的处理器类型和架构。集群中的计算机可以通过网络连接,并协同工作以完成大规模的计算任务。
3.云计算环境:云计算提供了基于网络的计算资源,可以是虚拟化的虚拟机或容器。在云环境中,用户可以选择不同类型的虚拟机实例,每个实例可能具有不同的处理能力和特性。这使得用户能够根据其需求和预算选择最适合的计算资源。
在异构环境中,为了充分利用各种计算设备的优势,需要开发相应的编程模型和工具。例如,使用并行编程框架(如CUDA、OpenCL或MPI)来利用加速器的并行处理能力,或使用任务调度器和分布式系统管理工具来管理分布式计算集群。
异构环境的挑战在于有效地利用不同设备的计算能力,并管理数据传输和同步问题。然而,通过合理的任务分配和调度,可以实现高性能和高效能的计算。
However, using these standard and generic RPC frameworks on an HPC system presents two main limitations: the inability to take advantage of the native transport mechanism to transfer data efficiently, as these frameworks are mainly designed on top of TCP/IP protocols; and the inability to transfer very large amounts of data, as the limit imposed by the RPC interface is generally of the order of the megabyte. In addition, even if no limit is enforced, transferring large amounts of data through the RPC library is usually discouraged, mostly due to overhead caused by serialization and encoding, causing the data to be copied many times before reaching the remote node.
但是,在 HPC 系统上使用这些标准和通用的 RPC 框架有两个主要限制:1. 无法利用本地传输机制有效地传输数据,因为这些框架主要是在 TCP/IP 协议之上设计的; 2. 并且无法传输非常大量的数据,因为 RPC 接口施加的限制通常是兆字节(MB)的数量级。 此外,即使没有强制限制,通常也不鼓励通过 RPC 库传输大量数据,主要是由于序列化和编码带来的开销,导致数据在到达远程节点之前被多次复制。
The paper is organized as follows: we first discuss related work in section II, then in section III we discuss the network abstraction layer on top of which the interface is built, as well as the architecture defined to transfer small and large data efficiently. Section IV outlines the API and shows its advantages to enable the use of pipelining techniques. We then describe the development of network transport plugins for our interface as well as performance evaluation results. Section V presents conclusions and future work directions.
本论文组织如下: 我们首先在第二部分讨论相关工作,然后在第三部分讨论构建接口的网络抽象层,以及为高效传输小型和大型数据而定义的架构。 第 IV 节概述了 API 并展示了其支持使用流水线技术的优势。 然后我们描述了我们接口的网络传输插件的开发以及性能评估结果。 第五节提出结论和未来的工作方向。
II. RELATED WORK
The Network File System (NFS) [7] is a very good example of the use of RPC with large data transfers and therefore very close to the use of RPC on an HPC system. It makes use of XDR [8] to serialize arbitrary data structures and create a system-independent description, the resulting stream of bytes is then sent to a remote resource, which can deserialize and get the data back from it. It can also make use of separate transport mechanisms (on recent versions of NFS) to transfer data over RDMA protocols, in which case the data is processed outside of the XDR stream. The interface that we present in this paper follows similar principles but in addition handles bulk data directly. It also does not limit to the use of XDR for data encoding, which can be a performance hit, especially when sender and receiver share a common system architecture. By providing a network abstraction layer, the RPC interface that we define gives the ability to the user to send small data and large data efficiently, using either small messages or remote memory access (RMA) types of transfer that fully support onesided semantics present on recent HPC systems. Furthermore, all the interface presented is non-blocking and therefore allows an asynchronous mode of operation, preventing the caller to wait for an operation to execute before another one can be issued.
网络文件系统 (NFS) [7] 是使用 RPC 处理大量数据传输的一个很好的例子,因此非常接近在 HPC 系统上使用 RPC。 它利用 XDR [8] 序列化任意数据结构并创建独立于系统的描述,然后将生成的字节流发送到远程资源,远程资源可以反序列化并从中取回数据。 它还可以使用单独的传输机制(在最新版本的 NFS 上)通过 RDMA 协议传输数据,在这种情况下,数据在 XDR 流之外进行处理。 我们在本文中介绍的接口遵循类似的原则,但另外直接处理批量数据。 它还不限于使用 XDR 进行数据编码,这可能会影响性能,尤其是当发送方和接收方共享一个公共系统架构时。 通过提供网络抽象层,我们定义的 RPC 接口使用户能够使用小消息或远程内存访问 (RMA) 类型的传输有效地发送小数据和大数据,这些传输完全支持最近 HPC 系统上存在的单边语义。 此外,所有呈现的接口都是非阻塞的,因此允许异步操作模式,防止调用者等待一个操作执行后再发出另一个操作。
网络文件系统(NFS): NFS(Network File System)是一种用于在计算机网络中共享文件和目录的协议。它允许多台计算机通过网络透明地访问共享的文件系统,就像访问本地文件一样。NFS最初由Sun Microsystems开发,并成为一种广泛使用的网络文件共享协议。它使用客户端-服务器模型,其中文件的存储和管理在文件服务器上,而客户端通过网络请求访问服务器上的文件。
NFS的工作原理如下:
1.文件服务器设置:文件服务器上的目录被标记为共享目录,并配置允许访问的客户端列表。2.客户端挂载:客户端通过使用特定的NFS挂载命令将服务器上的共享目录挂载到本地文件系统上。一旦挂载完成,客户端就可以像访问本地文件一样访问共享目录和文件。
3.文件访问:客户端可以对挂载的共享目录和文件执行标准的文件操作,如读取、写入、创建和删除等。这些操作被传输到文件服务器上,并在服务器上执行相应的操作。
4.文件同步:NFS支持文件的并发访问,多个客户端可以同时读取和写入同一个文件。服务器负责处理并发访问的同步和冲突解决。
NFS提供了以下优势和特性:
1.透明性:NFS使得远程文件系统对客户端来说是透明的,客户端可以像访问本地文件一样访问远程文件。
2.共享性:多个客户端可以同时访问和共享同一个文件系统,促进协作和资源共享。
3.跨平台支持:NFS是跨平台的,可以在不同的操作系统之间共享文件,如UNIX、Linux、Windows等。
4.性能优化:NFS支持缓存和预读等机制,以提高文件访问的性能。
尽管NFS在文件共享方面具有许多优点,但也存在一些考虑因素,如网络延迟、安全性和性能等。在配置和使用NFS时,需要考虑网络环境和安全需求,并采取相应的措施来确保文件访问的可靠性和安全性。
XDR(External Data Representation)是一种数据序列化格式,用于在不同计算机系统之间传输和存储数据。它定义了一套规范,描述了如何将数据转换为与机器无关的格式,以便在不同的系统中进行数据交换。XDR序列化使用固定的数据表示格式,使得数据在不同的机器和操作系统之间具有一致的表示和解析方式。这样可以确保数据的可移植性和互操作性。 XDR序列化的过程将数据转换为一个规范的二进制表示形式,以便在网络上传输或存储到磁盘等介质中。序列化后的数据可以通过网络传输协议(如RPC)进行传输,或者进行持久化存储。
XDR序列化的特点包括:1.与机器无关:XDR定义了一套独立于具体机器和操作系统的数据表示方式,使得数据可以在不同的平台上进行交换。
2.简洁性:XDR序列化格式相对简单,不包含冗余信息,提供了高效的数据表示和解析方式。
3.可扩展性:XDR序列化支持多种数据类型,包括整数、浮点数、字符串、结构体等,可以根据需要定义和使用复杂的数据结构。
4.互操作性:XDR序列化格式在多个编程语言和平台上都有支持,使得不同系统之间可以使用统一的数据表示方式进行数据交换。
XDR序列化常用于RPC(远程过程调用)协议中,作为数据的传输格式。通过将数据序列化为XDR格式,可以方便地在客户端和服务器之间进行参数传递和结果返回。需要注意的是,使用XDR序列化需要定义数据的结构和类型,并编写相应的解析和序列化代码。在使用XDR进行数据交换时,发送方和接收方需要使用相同的数据定义和序列化规则,以确保数据的正确解析和一致性。
RMA(Remote Memory Access)是一种用于在并行计算和高性能计算(HPC)系统中实现远程内存访问的技术。它允许计算节点直接访问其他节点的内存,而不需要通过传统的消息传递接口(如消息传递接口MPI)进行数据传输。在传统的消息传递编程模型中,节点之间的数据交换需要通过显式的发送和接收操作来完成,涉及到数据的拷贝和消息传输。而在RMA模型中,节点可以直接访问远程节点的内存,使得数据交换更加高效且减少了数据拷贝的开销。
RMA模型通常使用两种主要的操作:
远程写(Remote Write):通过远程写操作,节点可以向远程节点的内存中写入数据。发送节点将数据直接写入接收节点的内存空间,而不需要接收节点的显式接收操作。远程读(Remote Read):通过远程读操作,节点可以从远程节点的内存中读取数据。发送节点可以直接从接收节点的内存中读取数据,而不需要接收节点的显式发送操作。
RMA模型的实现通常依赖于专用的高性能网络接口,如InfiniBand(IB)或以太网的RDMA(远程直接内存访问)技术。这些接口提供了低延迟和高带宽的通信能力,以支持RMA操作的高效执行。RMA模型在高性能计算领域中具有重要的应用,尤其在并行计算和大规模数据处理中。它可以减少数据拷贝和通信开销,提高计算节点之间的数据交换效率,从而加速并行计算任务的执行。然而,RMA模型也需要合理的编程和调试技巧,以确保内存访问的正确性和一致性,避免数据竞争和并发问题。
RDMA(Remote Direct Memory Access)是一种高性能网络通信技术,用于在计算节点之间实现远程内存访问。RDMA技术允许计算节点直接在彼此之间进行数据传输,而无需中央处理单元(CPU)的干预。在传统的网络通信模型中,数据的传输通常需要经过CPU的介入,即数据从源节点复制到发送节点的内核缓冲区,然后再从接收节点的内核缓冲区复制到目标节点的内存。这种数据复制的过程涉及CPU的处理和上下文切换,导致额外的延迟和系统开销。而通过RDMA技术,数据可以直接从源节点的内存复制到目标节点的内存,绕过了CPU和内核缓冲区的干预。这使得数据传输更加高效,具有低延迟和高带宽的特性。
RDMA技术通常基于专用的高性能网络接口,如InfiniBand(IB)或以太网上的RDMA over Converged
Ethernet(RoCE)。这些接口提供了硬件级别的支持,包括数据包传输、数据完整性校验和流量控制等功能。RDMA技术在高性能计算(HPC)领域得到广泛应用,特别适用于大规模并行计算、数据中心互连和存储系统等场景。它可以提供低延迟、高吞吐量和低CPU占用的通信能力,从而加速数据传输和处理任务。需要注意的是,使用RDMA技术进行数据传输需要适当的编程模型和软件支持,如MPI(消息传递接口)或RDMA-aware的库和框架。这些工具提供了对RDMA的抽象和封装,使得开发人员可以方便地利用RDMA技术进行高效的远程内存访问。
异步操作模式是一种编程模式,用于处理需要长时间执行的操作,如网络请求、文件读写、数据库查询等。在传统的同步操作模式下,程序会一直等待操作完成才能继续执行,而在异步操作模式下,程序可以继续执行其他任务,而不必等待操作完成。异步操作模式的关键在于将操作委托给另一个任务或线程,并在操作完成后通知主线程或调用回调函数来处理结果。这样可以提高程序的并发性和响应性,尤其适用于需要处理大量IO操作的场景。
异步操作模式通常涉及以下几个概念:
1.异步函数/方法:异步函数或方法是指可以在操作进行期间挂起并返回一个中间结果的函数或方法。它们通常使用特殊的关键字或修饰符(如async/await)标识,并指示编译器将其转化为适当的异步代码。
2.回调函数:回调函数是在异步操作完成时被调用的函数。它通常作为参数传递给异步操作,并在操作完成后被调用,以处理操作的结果。回调函数可以用于处理成功的情况、错误处理、清理资源等。
3.异步任务调度器:异步任务调度器负责管理和调度异步任务的执行。它可以根据可用的系统资源、任务优先级等条件来决定任务的执行顺序和分配资源。
4.异步事件循环:异步事件循环是一个在主线程中运行的循环,用于接收和处理异步操作的完成通知,并调度回调函数的执行。它负责管理事件队列,处理已完成的操作,并将相应的回调函数推入执行队列。
异步操作模式的好处包括:
1.提高程序的并发性和响应性:可以同时处理多个操作,而不需要等待每个操作完成。
2.减少资源浪费:在等待IO操作完成时,可以利用CPU资源执行其他任务,提高资源利用率。
3.更好的用户体验:异步操作可以使程序在执行耗时操作时保持响应,提高用户体验。
The I/O Forwarding Scalability Layer (IOFSL) [9] is another project upon which part of the work presented in this paper is based. IOFSL makes use of RPC to specifically forward I/O calls. It defines an API called ZOIDFS that locally serializes function parameters and sends them to a remote server, where they can in turn get mapped onto file system specific I/O operations. One of the main motivations for extending the work that already exists in IOFSL is the ability to send not only a specific set of calls, as the ones that are defined through the ZOIDFS API, but a various set of calls, which can be dynamically and generically defined. It is also worth noting that IOFSL is built on top of the BMI [10] network transport layer used in the Parallel Virtual File System (PVFS) [11].It allows support for dynamic connection as well as fault tolerance and also defines two types of messaging, unexpected and expected (described in section III-B), that can enable an asynchronous mode of operation. Nevertheless, BMI is limited in its design by not directly exposing the RMA semantics that are required to explicitly achieve RDMA operations from the client memory to the server memory, which can be an issue and a performance limitation (main advantages of using an RMA approach are described in section III-B). In addition, while BMI does not offer one-sided operations, it does provide a relatively high level set of network operations. This makes porting BMI to new network transports (such as the Cray Gemini interconnect [12]) to be a non-trivial work, and more time consuming than it should be, as only a subset of the functionality provided by BMI is required for implementing RPC in our context.
I/O 转发可扩展性层 (IOFSL) [9] 是另一个项目,本文介绍的部分工作基于该项目。 IOFSL 使用 RPC 专门转发 I/O调用。 它定义了一个名为 ZOIDFS 的 API,它在本地序列化函数参数并将它们发送到远程服务器,在那里它们可以依次映射到文件系统特定的 I/O 操作。 扩展 IOFSL 中已经存在的工作的主要动机之一是能够不仅发送一组特定的调用(如通过 ZOIDFS API 定义的调用),而且能够发送各种调用,这些调用可以动态和通用地定义。 同样值得注意的是,IOFSL 建立在并行虚拟文件系统 (PVFS) [11] 中使用的 BMI [10] 网络传输层之上。它允许支持动态连接和容错,还定义了两种类型的消息传递, 意外和预期(在第 III-B 节中描述),可以启用异步操作模式。 然而,BMI 在其设计中受到限制,因为它没有直接公开显式实现从客户端内存到服务器内存的 RDMA 操作所需的 RMA 语义,这可能是一个问题和性能限制(使用 RMA 方法的主要优点在第 III 节中描述 - B). 此外,虽然 BMI 不提供单边操作,但它确实提供了一组相对较高级别的网络操作。 这使得将 BMI 移植到新的网络传输(例如 CrayGemini 互连 [12])成为一项重要的工作,并且比它应该更耗时,因为在我们的上下文中实现 RPC 只需要 BMI 提供的功能的一个子集。
IOFSL(I/O Forwarding Scalability Layer)是一种用于在高性能计算(HPC)系统中提供可扩展性的I/O转发层。它旨在解决大规模并行计算中的I/O瓶颈和性能问题,通过优化和分发I/O负载来提高系统的I/O性能和可扩展性。IOFSL通过在计算节点和存储节点之间引入中间层,将I/O请求从计算节点转发到存储节点,并对I/O负载进行均衡和优化。它提供了以下关键功能:
1.I/O分发和负载均衡:IOFSL层通过将I/O请求分发到多个存储节点上的多个磁盘设备,实现负载均衡和并行化的I/O操作。这样可以充分利用存储系统的带宽和吞吐量,提高整体的I/O性能。
2.数据聚合和缓存:IOFSL层可以将来自不同计算节点的小型I/O请求聚合成更大的数据块,并进行数据缓存,以减少存储系统的负载和网络传输开销。这有助于提高数据访问的效率和整体的I/O性能。
3.数据压缩和编码:IOFSL层可以实施数据压缩和编码技术,以减少数据在网络传输中的带宽消耗。这有助于降低存储系统的负载和加速数据传输过程。
4.可扩展性和弹性:IOFSL设计为可扩展和可配置的,可以适应不同规模和需求的HPC系统。它支持动态增加或减少存储节点,并自动适应系统的变化和故障。
通过引入IOFSL层,HPC系统可以充分利用存储资源,并提高I/O性能和可扩展性。它对于大规模并行计算和数据密集型应用非常有益,能够优化I/O操作,减少数据传输的开销,从而提高整体的计算效率和系统性能。
并行虚拟文件系统(Parallel Virtual File System,简称PVFS)是一种用于构建高性能并行计算环境中的分布式文件系统。PVFS的设计目标是提供高吞吐量、低延迟和可扩展性,以满足大规模并行计算中对文件系统的高性能要求。PVFS支持将多个存储节点组织成一个逻辑文件系统,并提供并行访问文件的能力。它通过将文件数据分布到多个存储节点上,同时允许多个计算节点并行访问文件,以实现高效的I/O操作。
PVFS的主要特性和设计原则包括:
1.分布式架构:PVFS采用分布式架构,将文件数据分散存储在多个存储节点上,以实现数据的并行访问和高吞吐量的I/O操作。
2.并行访问:PVFS允许多个计算节点同时访问文件,实现并行的读写操作。这种并行访问方式可以提高文件系统的性能和响应速度。
3.数据分布和负载均衡:PVFS使用数据分布策略将文件数据均匀地分布到多个存储节点上,以实现负载均衡和高效的数据访问。
4.容错和可扩展性:PVFS具有容错机制,支持节点故障的自动检测和恢复。此外,PVFS还具有良好的可扩展性,可以根据需要增加存储节点来扩展文件系统的容量和性能。
BMI(Bulk Memory Operations)是引入到x86-64体系结构中的一组指令和功能,用于改善大块内存操作的性能。它提供了高效操作大块内存的方法,如复制、填充和比较内存区域。BMI包括多个指令,如movs、stos、cmps和lods,用于操作内存块。这些指令经过优化,可以利用SIMD(单指令多数据)功能,以及减少所需的内存访问次数,从而高效处理大量数据。 BMI指令的主要优势包括:
1.提升性能:BMI指令通过利用SIMD功能和减少内存访问次数,提高了大块内存操作的性能。
2.减少指令数量:使用BMI指令可以减少所需的指令数量,从而减少了指令的执行时间和功耗。
3.简化代码:BMI指令提供了直接操作内存块的功能,可以简化代码的编写和维护,提高开发效率。
Another project, Sandia National Laboratories’ NEtwork Scalable Service Interface (Nessie) [13] system provides a simple RPC mechanism originally developed for the Lightweight File Systems [14] project. It provides an asynchronous RPC solution, which is mainly designed to overlap computation and I/O. The RPC interface of Nessie directly relies on the Sun XDR solution which is mainly designed to communicate between heterogeneous architectures, even though practically all High-Performance Computing systems are homogeneous.Nessie provides a separate mechanism to handle bulk data transfers, which can use RDMA to transfer data efficiently from one memory to the other, and supports several network transports. The Nessie client uses the RPC interface to push control messages to the servers. Additionally, Nessie exposes a different, one-sided API (similar to Portals [15]), which the user can use to push or pull data between client and server.Mercury is different, in that it’s interface, which also supports RDMA natively, can transparently handle bulk data for the user by automatically generating abstract memory handles representing the remote large data arguments, which are easier to manipulate and do not require any extra effort by the user.Mercury also provides fine grain control on the data transfer if required (for example to implement pipelining). In addition, Mercury provides a higher level interface than Nessie, greatly reducing the amount of user code needed to implement RPC functionality.
另一个项目,桑迪亚国家实验室的 NEtworkScalable 服务接口 (Nessie) [13] 系统提供了一个简单的 RPC 机制,最初是为 LightweightFile Systems [14] 项目开发的。 它提供了一个异步RPC的解决方案,主要是为了重叠计算和I/O而设计的。 Nessie 的 RPC 接口直接依赖于 Sun XDR 解决方案,该解决方案主要设计用于异构架构之间的通信,即使实际上所有高性能计算系统都是同构的。Nessie 提供了一种单独的机制来处理批量数据传输,它可以使用 RDMA 从一个高效地传输数据 内存到另一个,并支持多种网络传输。 Nessie 客户端使用 RPC 接口将控制消息推送到服务器。 此外,Nessie 公开了一个不同的、单方面的 API(类似于 Portals [15]),用户可以使用它在客户端和服务器之间推送或拉取数据。Mercury 不同,因为它的接口本身也支持 RDMA,可以透明地处理通过自动生成代表远程大数据参数的抽象内存句柄为用户提供批量数据,这些句柄更易于操作,不需要用户做任何额外的工作。如果需要,Mercury 还提供对数据传输的细粒度控制(例如,实现流水线)。 此外,Mercury 提供了比 Nessie 更高级的接口,大大减少了实现 RPC 功能所需的用户代码量。
Another similar approach can be seen with the Decoupled and Asynchronous Remote Transfers (DART) [16] project.While DART is not defined as an explicit RPC framework, it allows transfer of large amounts of data using a client/server model from applications running on the compute nodes of a HPC system to local storage or remote locations, to enable remote application monitoring, data analysis, code coupling, and data archiving. The key requirements that DART is trying to satisfy include minimizing data transfer overheads on the application, achieving high-throughput, low-latency data transfers, and preventing data losses. Towards achieving these goals, DART is designed so that dedicated nodes, i.e., separate from the application compute nodes, asynchronously extract data from the memory of the compute nodes using RDMA. In this way, expensive data I/O and streaming operations from the application compute nodes to dedicated nodes are offloaded, and allow the application to progress while data is transferred.While using DART is not transparent and therefore requires explicit requests to be sent by the user, there is no inherent limitation for integration of such a framework within our network abstraction layer and therefore wrap it within the RPC layer that we define, hence allowing users to transfer data using DART on the platforms it supports.
另一种类似的方法可以在 Decoupledand Asynchronous Remote Transfers (DART) [16] 项目中看到。虽然 DART 未定义为显式 RPC 框架,但它允许使用客户端/服务器模型从计算节点上运行的应用程序传输大量数据 HPC 系统到本地存储或远程位置,以实现远程应用程序监控、数据分析、代码耦合和数据归档。 DART 试图满足的关键要求包括最小化应用程序的数据传输开销、实现高吞吐量、低延迟数据传输以及防止数据丢失。 为了实现这些目标,DART 的设计使得专用节点(即与应用程序计算节点分离)使用 RDMA 从计算节点的内存中异步提取数据。 通过这种方式,从应用程序计算节点到专用节点的昂贵数据 I/O 和流操作被卸载,并允许应用程序在数据传输的同时进行。虽然使用 DART 是不透明的,因此需要用户发送明确的请求,但是在我们的网络抽象层中集成此类框架并没有固有限制,因此将其包装在我们定义的 RPC 层中,从而允许用户在其支持的平台上使用 DART 传输数据。
III. ARCHITECTURE
As mentioned in the previous section, Mercury’s interface relies on three main components: a network abstraction layer, an RPC interface that is able to handle calls in a generic fashion and a bulk data interface, which complements the RPC layer and is intended to easily transfer large amounts of data by abstracting memory segments. We present in this section the overall architecture and each of its components.
如前一节所述,Mercury 的接口依赖于三个主要组件:网络抽象层NA、能够以通用方式处理调用的 RPC 接口和批量数据接口(Bulk),它补充了 RPC 层,旨在轻松传输大量数据 通过抽象内存段的数据量。 我们在本节中介绍了整体架构及其每个组件。
A. Overview
The RPC interface follows a client / server architecture. As described in figure 1, issuing a remote call results in different steps depending on the size of the data associated with the call. We distinguish two types of transfers: transfers containing typical function parameters, which are generally small, referred to as metadata, and transfers of function parameters describing large amounts of data, referred to as bulk data.
RPC接口遵循客户机/服务器体系结构。如图1所示,根据与调用相关联的数据的大小,发出远程调用会导致不同的步骤。我们区分了两种类型的传输:包含典型功能参数的传输,通常较小,称为元数据;描述大量数据的功能参数的传输,称为批量数据。
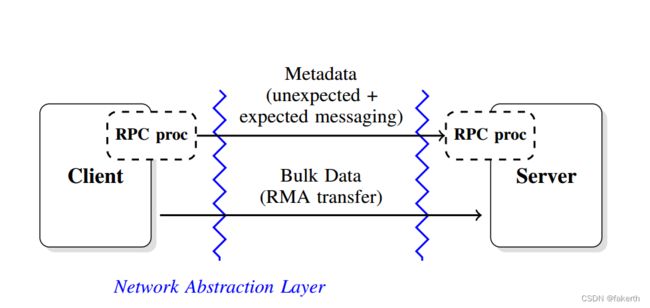
图1:体系结构概述:每一方都使用RPC处理器来序列化和反序列化通过接口发送的参数。调用参数相对较小的函数会导致使用网络抽象层公开的短消息传递机制,而包含大数据参数的函数则会额外使用RMA机制
Every RPC call sent through the interface results in the serialization of function parameters into a memory buffer (its size generally being limited to one kilobyte, depending on the interconnect), which is then sent to the server using the network abstraction layer interface. One of the key requirements is to limit memory copies at any stage of the transfer, especially when transferring large amounts data. Therefore, if the data sent is small, it is serialized and sent using small messages, otherwise a description of the memory region that is to be transferred is sent within this same small message to the server, which can then start pulling the data (if the data is the input of the remote call) or pushing the data (if the data is the output of the remote call). Limiting the size of the initial RPC request to the server also helps in scalability, as it avoids unnecessary server resource consumption in case of large numbers of clients concurrently accessing the same server. Depending on the degree of control desired, all these steps can be transparently handled by Mercury or directly exposed to the user.
通过接口发送的每个 RPC 调用都会导致函数参数的序列化 进入内存缓冲区(其大小通常限制为 1 KB,具体取决于互连),然后使用网络抽象层接口将其发送到服务器。 关键要求之一是在传输的任何阶段限制内存副本,尤其是在传输大量数据时。 因此,如果发送的数据很小,它会被序列化并使用小消息发送,否则将在同一条小消息中将要传输的内存区域的描述发送到服务器,然后服务器可以开始拉取数据(如果数据 是远程调用的输入)或推送数据(如果数据是远程调用的输出)。 限制对服务器的初始 RPC 请求的大小也有助于可伸缩性,因为它避免了在大量客户端同时访问同一服务器的情况下不必要的服务器资源消耗。 根据所需的控制程度,所有这些步骤都可以由 Mercury 透明地处理或直接暴露给用户。
B. Network Abstraction Layer
The main purpose of the network abstraction layer is as its name suggests to abstract the network protocols that are exposed to the user, allowing multiple transports to be integrated through a system of plugins. A direct consequence imposed by this architecture is to provide a lightweight interface, for which only a reasonable effort will be required to implement a new plugin. The interface itself must defines three main types of mechanisms for transferring data: unexpected messaging, expected messaging and remote memory access; but also the additional setup required to dynamically establish a connection between the client and the server (although a dynamic connection may not be always feasible depending on the underlying network implementation used).
顾名思义,网络抽象层的主要目的是抽象向用户公开的网络协议,允许通过插件系统集成多个传输。这种体系结构带来的一个直接后果是提供了一个轻量级接口,因此只需要合理的努力就可以实现一个新的插件。接口本身必须定义三种主要类型的传输数据的机制:意外消息传递unexpect、预期消息传递expected和远程内存访问rma;而且还需要在客户机和服务器之间动态建立连接所需的额外设置(动态连接可能并不总是可行的,具体取决于底层使用的网络实现根据所)。
Unexpected and expected messaging is limited to the transfer of short messages and makes use of a two-sided approach.The maximum message size is, for performance reasons, determined by the interconnect and can be as small as a few kilobytes. The concept of unexpected messaging is used in other communication protocols such as BMI [10]. Sending an unexpected message through the network abstraction layer does not require a matching receive to be posted before it can complete. By using this mechanism, clients are not blocked and the server can, every time an unexpected receive is issued, pick up the new messages that have been posted. Another difference between expected and unexpected messages is unexpected messages can arrive from any remote source, while expected messages require the remote source to be known.
意外消息和预期消息仅限于短消息的传输,并使用双边方法。出于性能原因,最大消息大小由互连决定,可以小到几千字节。意外消息传递的概念也用于其他通信协议,如BMI[10]。通过网络抽象层发送意外消息不需要在完成之前发布匹配的接收。通过使用这种机制,客户机不会被阻塞,并且每次发出意外接收时,服务器都可以拾取已发布的新消息。预期消息和意外消息之间的另一个区别是,意外消息可以从任何远程源到达,而预期消息需要知道远程源。
The remote memory access (RMA) interface allows remote memory chunks (contiguous and non-contiguous) to be accessed. In most one-sided interfaces and RDMA protocols, memory must be registered to the network interface controller (NIC) before it can used. The purpose of the interface defined in the network abstraction layer is to create a first degree of abstraction and define an API that is compatible with most RMA protocols. Registering a memory segment to the NIC typically results in the creation of a handle to that segment containing virtual address information, etc. The local handle created needs to be communicated to the remote node before that node can start a put or get operation. The network abstraction is responsible for ensuring that these memory handles can be serialized and transferred across the network.Once handles are exchanged, a non-blocking put or get can be initiated. On most interconnects, put and get will map to the put and get operation provided by the specific API provided by the interconnect. The network abstraction interface is designed to allow the emulation of one-sided transfers on top of two-sided sends and receives for network protocols such as TCP/IP that only support a two-sided messaging approach.
远程内存访问 (RMA) 接口允许访问远程内存块(连续和非连续)。 在大多数单向接口和 RDMA 协议中,内存必须先注册到网络接口控制器 (NIC) 才能使用。 在网络抽象层中定义接口的目的是创建一级抽象并定义与大多数 RMA 协议兼容的 API。 将内存段注册到 NIC 通常会导致创建该段的句柄,其中包含虚拟地址信息等。创建的本地句柄需要在远程节点可以开始放置或获取操作之前传达给远程节点。 网络抽象负责确保这些内存句柄可以序列化并通过网络传输。交换句柄后,可以启动非阻塞放置或获取。 在大多数互连上,put 和 get 将映射到互连提供的特定 API 提供的 put 和 get 操作。 网络抽象接口旨在允许在双向发送和接收网络协议(例如仅支持双向消息传递方法的 TCP/IP)之上模拟单向传输。有了这个网络抽象层,Mercury 可以很容易地成为 移植以支持新的互连。 网络抽象提供的相对有限的功能(例如,没有无限大小的双向消息)确保接近本机性能。
With this network abstraction layer in place, Mercury can easily be ported to support new interconnects. The relatively limited functionality provided by the network abstraction (for example, no unlimited size two-sided messages) ensures close to native performance.
有了这个网络抽象层,可以很容易地移植Mercury以支持新的互连。网络抽象提供的相对有限的功能(例如,没有无限大小的双边消息)确保了接近本机的性能。
双边消息(Two-sided messages)也称为双向消息,是一种通信模式,其中两个实体可以在两个方向上交换消息。在这种模式下,每个实体既可以作为发送方,也可以作为接收方,实现双向的通信。
在并行计算或分布式系统的上下文中,双边消息允许两个进程或节点之间进行数据或信息的交换。每个实体都可以通过发送消息来启动通信,接收方可以处理消息并发送回应。这种双向的消息交换允许实体之间进行交互和协调的通信。双边消息在并行计算和分布式计算框架中的消息传递系统和通信协议中经常被使用。其中的一个例子是高性能计算中的消息传递接口(MPI),以及网络协议如TCP/IP。使用双边消息能够实现比单向或单边通信更灵活和动态的通信模式。它允许进行请求-响应的交互,发送方可以向接收方请求信息或服务,并接收特定的响应。
C. RPC Interface and Metadata
Sending a call that only involves small data makes use of the unexpected / expected messaging defined in III-B. However, at a higher level, sending a function call to the server means concretely that the client must know how to encode the input parameters before it can start sending information and know how to decode the output parameters once it receives a response from the server. On the server side, the server must also have knowledge of what to execute when it receives an RPC request and how it can decode and encode the input and output parameters. The framework for describing the function calls and encoding/decoding parameters is key to the operation of our interface.
发送一个只涉及小数据的调用使用了 III-B 中定义的意外/预期消息传递。 然而,在更高的层次上,向服务器发送函数调用具体意味着客户端必须知道如何在开始发送信息之前对输入参数进行编码,并且在收到服务器的响应后知道如何解码输出参数。 在服务器端,服务器还必须知道在收到 RPC 请求时要执行什么,以及如何对输入和输出参数进行解码和编码。 描述函数调用和编码/解码参数的框架是我们接口操作的关键。
One of the important points is the ability to support a set of function calls that can be sent to the server in a generic fashion, avoiding the limitations of a hard-coded set of routines.The generic framework is described in figure 2. During the initialization phase, the client and server register encoding and decoding functions by using a unique function name that is mapped to a unique ID for each operation, shared by the client and server. The server also registers the callback that needs to be executed when an operation ID is received with a function call. To send a function call that does not involve bulk data transfer, the client encodes the input parameters along with that operations ID into a buffer and send it to the server using an unexpected messaging protocol, which is non-blocking. To ensure full asynchrony, the memory buffer used to receive the response back from the server is also pre-posted by the client. For reasons of efficiency and resource consumption, these messages are limited in size (typically a few kilobytes).However if the metadata exceeds the size of an unexpected message, the client will need to transfer the metadata in separate messages, making transparent use of the bulk data interface described in III-D to expose the additional metadata to the server.
其中一个要点是能够支持一组可以以通用方式发送到服务器的函数调用,从而避免一组硬编码例程的限制。通用框架如图 2 所示。在初始化阶段, 客户端和服务器通过使用映射到每个操作的唯一 ID 的唯一函数名称注册编码和解码函数,由客户端和服务器共享。 服务器还注册了在通过函数调用接收到操作 ID 时需要执行的回调。 要发送不涉及批量数据传输的函数调用,客户端将输入参数与该操作 ID 一起编码到缓冲区中,并使用非阻塞的非预期消息传递协议将其发送到服务器。 为了确保完全异步,用于从服务器接收响应的内存缓冲区也由客户端预先发布。 出于效率和资源消耗的原因,这些消息的大小受到限制(通常为几千字节)。但是,如果元数据超过意外消息的大小,客户端将需要在单独的消息中传输元数据,从而透明地使用批量数据 III-D 中描述的接口,用于向服务器公开额外的元数据。
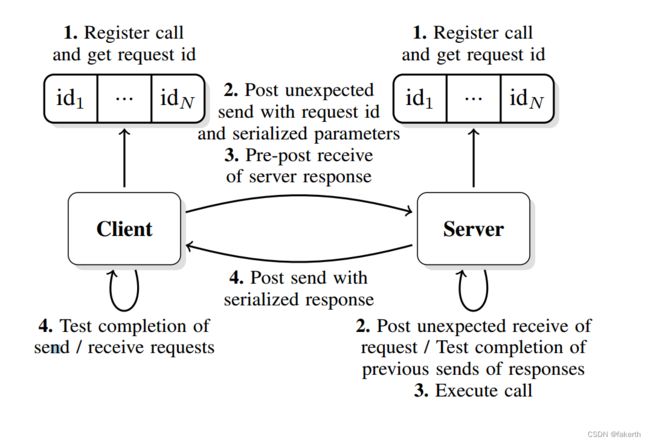
图2:RPC调用的异步执行流程。接收缓冲区是预先发布的,允许客户端在远程执行调用和发送响应时完成其他工作
When the server receives a new request ID, it looks up the corresponding callback, decodes the input parameters, executes the function call, encodes the output parameters and starts sending the response back to the client. Sending a response back to the client is also non-blocking, therefore, while receiving new function calls, the server can also test a list of response requests to check their completion, freeing the corresponding resources when an operation completes. Once the client has knowledge that the response has been received (using a wait/test call) and therefore that the function call has been remotely completed, it can decode the output parameters and free the resources that were used for the transfer.
当服务器接收到一个新的请求ID时,它查找相应的回调,解码输入参数,执行函数调用,编码输出参数,并开始将响应发送回客户机。将响应发送回客户端也是无阻塞的,因此,在接收新函数调用时,服务器还可以测试响应请求列表以检查其完成情况,从而在操作完成时释放相应的资源。一旦客户端知道响应已被接收(使用等待/测试调用),因此函数调用已远程完成,它就可以解码输出参数并释放用于传输的资源。
With this mechanism in place, it becomes simple to extend it to handle bulk data.
有了这种机制,扩展它来处理批量数据就变得简单了。
D. Bulk Data Interface
In addition to the previous interface, some function calls may require the transfer of larger amounts of data. For these function calls, the bulk data interface is used and is built on top of the remote memory access protocol defined in the network abstraction layer. Only the RPC server initiates onesided transfers so that it can, as well as controlling the data flow, protect its memory from concurrent accesses.
除了前面的接口之外,一些函数调用可能需要传输更大量的数据。对于这些函数调用,使用了大容量数据接口,并构建在网络抽象层中定义的远程内存访问协议之上。只有RPC服务器发起单边传输,这样它才能控制数据流,保护其内存不受并发访问的影响。
As described in figure 3, the bulk data transfer interface uses a one-sided communication approach. The RPC client exposes a memory region to the RPC server by creating a bulk data descriptor (which contains virtual memory address information, size of the memory region that is being exposed, and other parameters that may depend on the underlying network implementation). The bulk data descriptor can then be serialized and sent to the RPC server along with the RPC request parameters (using the RPC interface defined in section III-C). When the server decodes the input parameters,it deserializes the bulk data descriptor and gets the size of the memory buffer that has to be transferred.
如图3所示,批量数据传输接口使用单侧通信方法。RPC客户端通过创建批量数据描述符(其中包含虚拟内存地址信息、正在公开的内存区域的大小以及可能依赖于底层网络实现的其他参数)向RPC服务器公开内存区域。然后,批量数据描述符可以被序列化,并与RPC请求参数一起发送给RPC服务器(使用章节III-C中定义的RPC接口)。当服务器对输入参数进行解码时,它对批量数据描述符进行反序列化,并获取必须传输的内存缓冲区的大小。
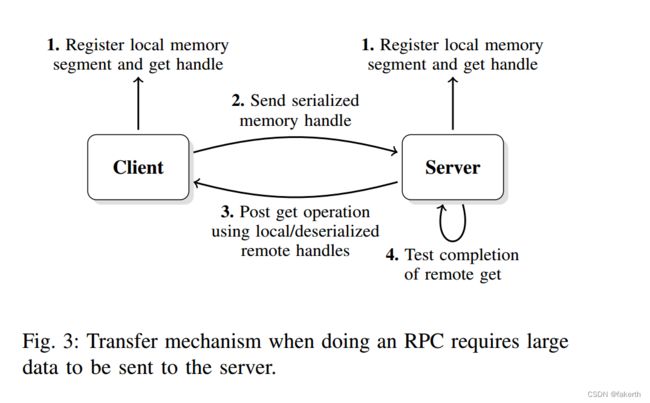
In the case of an RPC request that consumes large data parameters, the RPC server may allocate a buffer of the size of the data that needs to be received, expose its local memory region by creating a bulk data block descriptor and initiate an asynchronous read / get operation on that memory region.The RPC server then waits / tests for the completion of the operation and executes the call once the data has been fully received (or partially if the execution call supports it). The response (i.e., the result of the call) is then sent back to the RPC client and memory handles are freed.
在RPC请求消耗大量数据参数的情况下,RPC服务器可能会分配一个需要接收的数据大小的缓冲区,通过创建批量数据块描述符公开其本地内存区域,并在该内存区域上启动异步读/获取操作。然后RPC服务器等待/测试操作的完成,并在完全接收到数据(或者部分接收到数据,如果执行调用支持)后执行调用。然后将响应(即调用的结果)发送回RPC客户端,并释放内存句柄。
In the case of an RPC request that produces large data parameters, the RPC server may allocate a buffer of the size of the data that is going to be produced, expose the memory region by creating a bulk data block descriptor, execute the call, then initiate an asynchronous write / put operation to the client memory region that has been exposed. The RPC server may then wait/test for the completion of the operation and send the response (i.e., the result of the call) back to the RPC client. Memory handles can then be freed.
在产生大数据参数的RPC请求的情况下,RPC服务器可以分配一个与将要产生的数据大小相同的缓冲区,通过创建一个批量数据块描述符来公开内存区域,执行调用,然后对已经公开的客户端内存区域发起异步写/放操作。然后RPC服务器可以等待/测试操作的完成,并将响应(即调用的结果)发送回RPC客户端。然后可以释放内存句柄。
Transferring data through this process can be transparent for the user, especially since the RPC interface can also take care of serializing / deserializing the memory handles along with the other parameters. This is particularly important when non-contiguous memory segments have to be transferred. In either case memory segments are automatically registered on the RPC client and are abstracted by the memory handle created. The memory handle is then serialized along with the parameters of the RPC function and transferring large data using non-contiguous memory regions therefore results in the same process described above. Note that the handle may be variable size in this case as it may contain more information and also depends on the underlying network implementation that can support registration of memory segments directly.
通过这个过程传输数据对于用户来说是透明的,特别是因为RPC接口还可以处理内存句柄和其他参数的序列化/反序列化。当必须传输非连续内存段时,这一点尤其重要。在这两种情况下,内存段都会自动在RPC客户端上注册,并由创建的内存句柄进行抽象。然后将内存句柄与RPC函数的参数一起序列化,因此使用非连续内存区域传输大数据会导致上述相同的过程。注意,在这种情况下,句柄可能是可变大小的,因为它可能包含更多的信息,并且还取决于可以直接支持内存段注册的底层网络实现。
IV. EVALUATION
The architecture previously defined enables generic RPC calls to be shipped along with handles that can describe contiguous and non-contiguous memory regions when a bulk data transfer is required. We present in this section how one can take advantage of this architecture to build a pipelining mechanism that can easily request blocks of data on demand.
先前定义的体系结构允许在需要批量数据传输时,将通用RPC调用与可以描述连续和非连续内存区域的句柄一起发布。我们在本节中介绍如何可以利用这个架构的优势来构建一个流水线机制,可以方便地按需请求数据块。
A. Pipelining Bulk Data Transfers
Pipelining transfers is a typical use case when one wants to overlap communication and execution. In the architecture that we described, requesting a large amount of data to be processed results in an RPC request being sent from the RPC client to the RPC server as well as a bulk data transfer. In a common use case, the server may wait for the entire data to be received before executing the requested call. However, by pipelining the transfers, one can in fact start processing the data while it is being transferred, avoiding to pay the cost of the latency for an entire RMA transfer. Note that although we focus on this point in the example below, using this technique can also be particularly useful if the RPC server does not have enough memory to handle all the data that needs to be sent, in which case it will also need to transfer data as it processes it.
当想要重叠通信和执行时,管道传输是一个典型的用例。在我们描述的体系结构中,请求处理大量数据会导致RPC请求从RPC客户端发送到RPC服务器以及大量数据传输。在一个常见的用例中,服务器可能在执行请求的调用之前等待接收到全部数据。然而,通过管道传输,实际上可以在传输数据时开始处理数据,从而避免为整个RMA传输支付延迟成本。请注意,尽管我们在下面的示例中关注这一点,但如果RPC服务器没有足够的内存来处理需要发送的所有数据,那么使用这种技术也会特别有用,在这种情况下,它还需要在处理数据时传输数据。
A simplified version of the RPC client code is presented below:
RPC客户端代码的简化版本如下:
#define BULK_NX 16
#define BULK_NY 128
int main(int argc, char *argv[])
{
hg_id_t rpc_id;
write_in_t in_struct;
write_out_t out_struct;
hg_request_t rpc_request;
int buf[BULK_NX][BULK_NY];
hg_bulk_segment_t segments[BULK_NX];
hg_bulk_t bulk_handle = HG_BULK_NULL;
/* Initialize the interface */
[...]
/* Register RPC call */
rpc_id = HG_REGISTER("write",write_in_t, write_out_t);
/* Provide data layout information */
for (i = 0; i < BULK_NX ; i++) {
segments[i].address = buf[i];
segments[i].size = BULK_NY * sizeof(int);
}
/* Create bulk handle with segment info */
HG_Bulk_handle_create_segments(segments,BULK_NX, HG_BULK_READ_ONLY, &bulk_handle);
/* Attach bulk handle to input parameters */
[...]
in_struct.bulk_handle = bulk_handle;
/* Send RPC request */
HG_Forward(server_addr, rpc_id,&in_struct, &out_struct, &rpc_request);
/* Wait for RPC completion and response */
HG_Wait(rpc_request, HG_MAX_IDLE_TIME,HG_STATUS_IGNORE);
/* Get output parameters */
[...]
ret = out_struct.ret;
/* Free bulk handle */
HG_Bulk_handle_free(bulk_handle);
/* Finalize the interface */
[...]
}
When the client initializes, it registers the RPC call it wants to send. Because this call involves non contiguous bulk data transfers, memory segments that describe the memory regions are created and registered. The resulting bulk_handle is then passed to the HG_Forward call along with the other call parameters. One may then wait for the response and free the bulk handle when the request has completed (a notification may also be sent in the future to allow the bulk handle to be freed earlier, and hence the memory to be unpinned).
当客户端初始化时,它注册想要发送的RPC调用。因为这个调用涉及到非连续的批量数据传输,所以会创建并注册描述内存区域的内存段。生成的bulk_handle然后与其他调用参数一起传递给HG_Forward调用。然后可以等待响应并在请求完成时释放大容量句柄(也可以在将来发送通知以允许更早地释放大容量句柄,从而解除内存绑定)。
The pipelining mechanism happens on the server, which takes care of the bulk transfers. The pipeline itself has here a fixed pipeline size and a pipeline buffer size. A simplified version of the RPC server code is presented below:
管道机制发生在服务器上,它负责批量传输。管道本身在这里有一个固定的管道大小和一个管道缓冲区大小。RPC服务器代码的简化版本如下所示:
#define PIPELINE_BUFFER_SIZE 256
#define PIPELINE_SIZE 4
int rpc_write(hg_handle_t handle)
{
write_in_t in_struct;
write_out_t out_struct;
hg_bulk_t bulk_handle;
hg_bulk_block_t bulk_block_handle;
hg_bulk_request_t bulk_request[PIPELINE_SIZE];
void *buf;
size_t nbytes, nbytes_read = 0;
size_t start_offset = 0;
/* Get input parameters and bulk handle */
HG_Handler_get_input(handle, &in_struct);
[...]
bulk_handle = in_struct.bulk_handle;
/* Get size of data and allocate buffer */
nbytes = HG_Bulk_handle_get_size(bulk_handle);
buf = malloc(nbytes);
/* Create block handle to read data */
HG_Bulk_block_handle_create(buf, nbytes,
HG_BULK_READWRITE, &bulk_block_handle);
/* Initialize pipeline and start reads */
for (p = 0; p < PIPELINE_SIZE; p++) {
size_t offset = p * PIPELINE_BUFFER_SIZE;
/* Start read of data chunk */
HG_Bulk_read(client_addr, bulk_handle,
offset, bulk_block_handle, offset,
PIPELINE_BUFFER_SIZE, &bulk_request[p]);
}
while (nbytes_read != nbytes) {
for (p = 0; p < PIPELINE_SIZE; p++) {
size_t offset = start_offset + p * PIPELINE_BUFFER_SIZE;
/* Wait for data chunk */
HG_Bulk_wait(bulk_request[p],
HG_MAX_IDLE_TIME, HG_STATUS_IGNORE);
nbytes_read += PIPELINE_BUFFER_SIZE;
/* Do work (write data chunk) */
write(buf + offset, PIPELINE_BUFFER_SIZE);
/* Start another read */
offset += PIPELINE_BUFFER_SIZE * 51 PIPELINE_SIZE;
if (offset < nbytes) {
HG_Bulk_read(client_addr,bulk_handle, offset,bulk_block_handle, offset,PIPELINE_BUFFER_SIZE,&bulk_request[p]);
} else {
/* Start read with remaining piece */
}
}
start_offset += PIPELINE_BUFFER_SIZE * PIPELINE_SIZE;
}
/* Free block handle */
HG_Bulk_block_handle_free(bulk_block_handle);
free(buf);
/* Start sending response back */
[...]
out_struct.ret = ret;
HG_Handler_start_output(handle, &out_struct);
}
int main(int argc, char *argv[])
{
/* Initialize the interface */
[...]
/* Register RPC call */
HG_HANDLER_REGISTER("write", rpc_write,write_in_t, write_out_t);
while (!finalized) {
/* Process RPC requests (non-blocking) */
HG_Handler_process(0, HG_STATUS_IGNORE);
}
/* Finalize the interface */
[...]
}
Every RPC server, once it is initialized, must loop over a HG_Handler_process call, which waits for new RPC requests and executes the corresponding registered callback (in the same thread or new thread depending on user needs). Once the request is deserialized, the bulk_handle parameter can be used to get the total size of the data that is to be transferred, allocate a buffer of the appropriate size and start the bulk data transfers. In this example, the pipeline size is set to 4 and the pipeline buffer size is set to 256, which means that 4 RMA requests of 256 bytes are initiated. One can then wait for the first piece of 256 bytes to arrive and process it. While it is being processed, other pieces may arrive. Once one piece is processed a new RMA transfer is started for the piece that is at stage 4 in the pipeline and one can wait for the next piece, process it. Note that while the memory region registered on the client is non-contiguous, the HG_Bulk_read call on the server presents it as a contiguous region, simplifying server code. In addition, logical offsets (relative to the beginning of the data) can be given to move data pieces individually, with the bulk data interface taking care of mapping from the continuous logical offsets to the non-contiguous client memory regions.
每个RPC服务器,一旦初始化,必须循环HG_Handler_process调用,它等待新的RPC请求并执行相应的注册回调(在同一线程或新线程中,取决于用户需要)。一旦对请求进行了反序列化,就可以使用bulk_handle参数来获取要传输的数据的总大小,分配适当大小的缓冲区并开始批量数据传输。在本例中,管道大小设置为4,管道缓冲区大小设置为256,即发起4个256字节的RMA请求。然后可以等待第一块256字节到达并处理它。当它被处理的时候,其他的碎片可能会到达。一旦处理了一个片段,就会为管道中处于阶段4的片段启动一个新的RMA传输,并且可以等待下一个片段进行处理。注意,虽然在客户机上注册的内存区域是非连续的,但服务器上的HG_Bulk_read调用将其表示为连续区域,从而简化了服务器代码。此外,可以给出逻辑偏移量(相对于数据的开头)来单独移动数据块,而批量数据接口负责将连续的逻辑偏移量映射到不连续的客户端内存区域。
We continue this process until all the data has been read / processed and the response (i.e., the result of the function call) can be sent back. Again we only start sending the response by calling the HG_Handler_start_output call and its completion will only be tested by calling HG_Handler_process, in which case the resources associated to the response will be freed. Note that all functions support asynchronous execution, allowing Mercury to be used in event driven code if so desired.
我们继续这个过程,直到所有的数据都被读取/处理,并且响应(即函数调用的结果)可以被发送回来。同样,我们只能通过调用HG_Handler_start_output调用来开始发送响应,并且只能通过调用HG_Handler_process来测试其完成情况,在这种情况下,与响应相关的资源将被释放。注意,所有函数都支持异步执行,如果需要的话,可以在事件驱动代码中使用Mercury。
B. Network Plugins and Testing Environment
Two plugins have been developed as of the date this paper is written to illustrate the functionality of the network abstraction layer. At this point, the plugins have not been optimized for performance. One is built on top of BMI [10]. However, as we already pointed out in section II, BMI does not provide RMA semantics to efficiently take advantage of the network abstraction layer defined and the one-sided bulk data transfer architecture. The other one is built on top of MPI [17], which has only been providing full RMA semantics [18] recently with MPI3 [19]. Many MPI implementations, specifically those delivered with already installed machines, do not yet provide all MPI3 functionality. As BMI has not yet been ported to recent HPC systems, to illustrate the functionality and measure early performance results, we only consider the MPI plugin in this paper. This plugin, to be able to run on existing HPC systems limited to MPI-2 functionality, such as Cray systems, implements bulk data transfers on top of two-sided messaging.
In practice, this means that for each bulk data transfer, an additional bulk data control message needs to be sent to the client to request either sending or receiving data. Progress on the transfer can then be realized by using a progress thread or by entering progress functions
在撰写本文时,已经开发了两个插件来说明网络抽象层的功能。此时,插件还没有针对性能进行优化。一个是建立在BMI之上的[10]。然而,正如我们在第二节中已经指出的,BMI没有提供RMA语义来有效地利用定义的网络抽象层和单侧批量数据传输体系结构。另一个是建立在MPI[17]之上的,它最近才通过MPI3[19]提供完整的RMA语义[18]。许多MPI实现,特别是那些已经安装的机器,还没有提供所有的MPI3功能。由于BMI尚未移植到最近的高性能计算系统,为了说明功能和测量早期性能结果,我们在本文中只考虑MPI插件。这个插件,能够在现有的仅限于MPI-2功能的HPC系统上运行,比如Cray系统,在双边消息传递的基础上实现批量数据传输。
实际上,这意味着对于每次批量数据传输,需要向客户端发送额外的批量数据控制消息,以请求发送或接收数据。然后可以通过使用进度线程或输入进度函数来实现传输的进度。
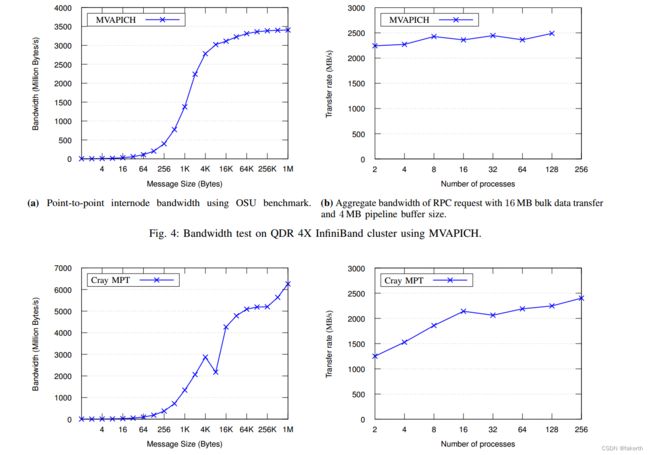
For testing we make use of two different HPC systems. One is an Infiniband QDR 4X cluster with MVAPICH [20] 1.8.1, the other one is a Cray XE6 with Cray MPT [21] 5.6.0.
为了进行测试,我们使用了两个不同的HPC系统。一个是使用MVAPICH[20] 1.8.1的Infiniband QDR 4X集群,另一个是使用Cray MPT[21] 5.6.0的Cray XE6集群。
C. Performance Evaluation
As a first experiment, we measured the time it takes to execute a small RPC call (without any bulk data transfer involved) for an empty function (i.e., a function that returns immediately). On the Cray XE6 machine, measuring the average time for 20 RPC invocations, each call took 23 µs.This time includes the XDR encoding and decoding of the parameters of the function. However, as pointed out earlier, most HPC systems are homogeneous and thus don’t require the data portability provided by XDR. When disabling XDR encoding (performing a simple memory copy instead) the time drops to 20 µs. This non-negligible improvement (15%) demonstrates the benefit of designing an RPC framework specifically for HPC environments.
作为第一个实验,我们测量了为空函数(即立即返回的函数)执行一个小RPC调用(不涉及任何批量数据传输)所需的时间。在Cray XE6机器上,测量20个RPC调用的平均时间,每个调用花费23µs。这一次包括函数参数的XDR编码和解码。然而,正如前面指出的,大多数HPC系统都是同构的,因此不需要XDR提供的数据可移植性。当禁用XDR编码(执行简单的内存复制代替)时,时间下降到20µs。这个不可忽视的改进(15%)证明了专门为HPC环境设计RPC框架的好处。
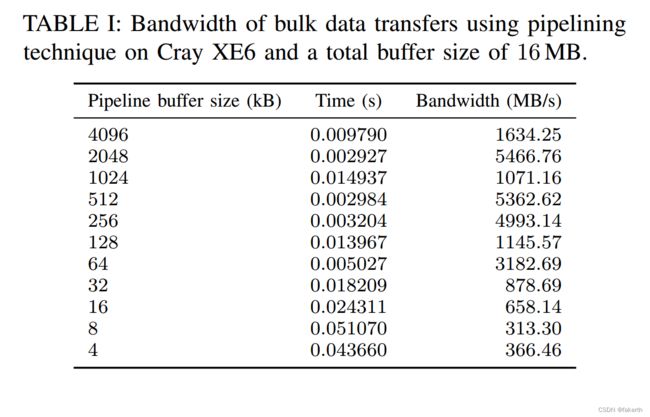
The second experiment consists of testing the pipelining technique for bulk data transfers previously explained between one client and one server. As shown in table I, on Cray XE6 pipelining transfers can be particularly efficient when requests have already completed while other pipeline stages are being processed, allowing us to get very high bandwidth. However, the high injection bandwidth on this system makes it difficult to get good performance for small packets (such as the bulk data control messages due to the emulation of one-sided features on this system) particularly when data flow is not continuous.
第二个实验包括测试之前在一个客户端和一个服务器之间解释的批量数据传输的管道技术。如表1所示,在Cray XE6上,当请求已经完成而其他管道阶段正在处理时,管道传输可以特别有效,从而允许我们获得非常高的带宽。然而,该系统上的高注入带宽使得小数据包(例如由于该系统上的单侧功能的模拟而产生的批量数据控制消息)难以获得良好的性能,特别是在数据流不是连续的情况下。
Finally we evaluated the scalability of the RPC server by evaluating the total data throughput while increasing the number of clients. Figures 4 and 5 show the results for a QDR InfiniBand system (using MVAPICH) and the Cray XE6 system respectively. In both cases, in part due to the server side bulk data flow control mechanism, Mercury shows excellent scalability, with throughput either increasing or remaining stable as the number of concurrent clients increases. For comparison, the point to point message bandwidth on each system is shown.On the InfiniBand system, Mercury achieves about 70% of maximum network bandwidth. This is an excellent result, considering that the Mercury time represents an RPC call in addition to the data transfer, compared to the time to send a single message for the OSU benchmark. On the Cray system, performance is less good (about 40% of peak). We expect that this is mainly due to the relatively poor small message performance of the system, combined with the extra control messages caused by the one-sided emulation.
最后,我们评估了RPC Serverby的可伸缩性,在增加客户端时数时评估了总数据吞吐量。 图4和5分别显示了AQDR Infiniband系统(使用MVAPICH)和CRAY XE6SYSTEM的结果。 在这两种情况下,部分由于服务器sidebulk数据流控制机制,HG显示出卓越的性能,并且吞吐量增加或剩余stableas,并发客户的数量增加。 为了进行比较,显示了每个系统上的点消息带宽。在Infiniband系统中,Mercury达到了最大网络带宽的70%。 考虑到HG时间代表了数据传输的RPC调用,这是一个很好的结果,与发送OSU基准的Asingle消息的时间相比。 在Cray系统上,性能不佳(约占峰值的40%)。 我们期望这主要是由于该系统的较小信息性能,以及由单方面仿真引起的额外控制措施。 然而,低性能也可能是由系统限制引起的,考虑到 Nessie 的类似操作(读取)[22] 的性能显示相同的低带宽,即使它通过绕过 MPI 并使用真正的 RDMA interconnect 的原生 uGNI API。
V. CONCLUSION AND FUTURE WORK
In this paper we presented the Mercury framework. Mercury is specifically designed to offer RPC services in a HighPerformance Computing environment. Mercury builds on a small, easily ported network abstraction layer providing operations closely matched to the capabilities of contemporary HPC network environments. Unlike most other RPC frameworks, Mercury offers direct support for handling remote calls containing large data arguments. Mercury’s network protocol is designed to scale to thousands of clients. We demonstrated the power of the framework by implementing a remote write function including pipelining of large data arguments. We subsequently evaluated our implementation on two different HPC systems, showing both single client performance and multi-client scalability.
在本文中,我们介绍了Mercury框架。Mercury专门设计用于在高性能计算环境中提供RPC服务。Mercury构建在一个小型的、易于移植的网络抽象层上,提供与当代HPC网络环境的功能紧密匹配的操作。与大多数其他RPC框架不同,Mercury为处理包含大数据参数的远程调用提供了直接支持。Mercury的网络协议被设计成可扩展到数千个客户端。我们通过实现一个远程写入函数(包括大数据参数的流水线)来展示该框架的强大功能。我们随后在两个不同的HPC系统上评估了我们的实现,展示了单客户端性能和多客户端可伸缩性。
With the availability of the high-performing, portable, generic RPC functionality provided by Mercury, IOFSL can be simplifed and modernized by replacing the internal, hard coded IOFSL code by Mercury calls. As the network abstraction layer on top of which Mercury is built already supports using BMI for network connectivity, existing deployments of IOFSL continue to be supported, at the same time taking advantage of the improved scalability and performance of Mercury’s network protocol.
有了Mercury提供的高性能、可移植、通用RPC功能,IOFSL可以通过用Mercury调用替换内部硬编码的IOFSL代码来简化和现代化。由于构建Mercury的网络抽象层已经支持使用BMI进行网络连接,因此现有的IOFSL部署将继续得到支持,同时利用Mercury网络协议改进的可扩展性和性能。
Currently, Mercury does not offer support for canceling ongoing RPC calls. Cancellation is important for resiliency in environments where nodes or network can fail. Future work will include support for cancellation.
目前,Mercury不支持取消正在进行的RPC调用。取消对于节点或网络可能出现故障的环境中的弹性非常重要。未来的工作将包括对取消的支持。
While Mercury already supports all required functionality to efficiently execute RPC calls, the amount of user code required for each call can be further reduced. Future versions of Mercury will provide a set of preprocessor macros, reducing the user’s effort by automatically generating as much boiler plate code as possible.
虽然Mercury已经支持有效执行RPC调用所需的所有功能,但每个调用所需的用户代码还可以进一步减少。未来版本的Mercury将提供一组预处理器宏,通过自动生成尽可能多的样板代码来减少用户的工作量。
The network abstraction layer currently has plugins for BMI, MPI-2 and MPI-3. However, as MPI RMA functionality is difficult to use in a client/server context [23], we intend to add native support for Infiniband networks, and the Cray XT and IBM BG/P and Q networks.
网络抽象层目前有BMI、MPI-2和MPI-3的插件。然而,由于MPI RMA功能很难在客户端/服务器环境中使用[23],我们打算增加对Infiniband网络、Cray XT和IBM BG/P和Q网络的本地支持。
论文链接