一个简单的Ajax加载post请求的爬虫实例)
一个简单的Ajax加载post请求的爬虫实例
- 内容简介
- 爬虫简介
-
- URL分析
- 请求分析
- 重要代码解释
- 完整代码
内容简介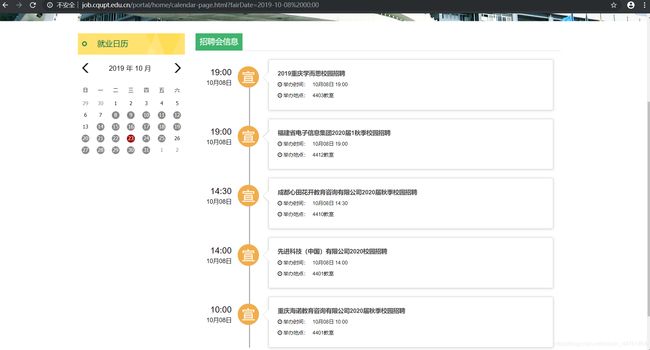

上图1是我们学校的校招网站,没有反爬机制,但是是Ajax加载并且是post的请求方式并且需要将上图2信息抓取下来
爬虫简介
URL分析
一、首先分析一级URL:
http://job.cqupt.edu.cn/portal/home/calendar-page.html?fairDate=2019-10-08%2000:00
http://job.cqupt.edu.cn/portal/home/calendar-page.html?fairDate=2019-10-09%2000:00
http://job.cqupt.edu.cn/portal/home/calendar-page.html?fairDate=2019-10-10%2000:00
可以发现变化的只有fairDate中的日期,因此构建URL的时候只需要改变日期就可以了
二、接着分析一下二级URL:
http://job.cqupt.edu.cn/portal/home/special-recruitment-detail.html?level2MenuId=1200&menuId=60&type=1&id=3219
http://job.cqupt.edu.cn/portal/home/special-recruitment-detail.html?level2MenuId=1200&menuId=60&type=1&id=3251
http://job.cqupt.edu.cn/portal/home/special-recruitment-detail.html?level2MenuId=1200&menuId=60&type=1&id=3191
分容易发现改变的只有id这一个元素,但是分析了多个二级URL,还是没有找到id变化规律,因此最后决定直接在网页当中抓取二级URL,但是后来发现这是一个Ajax加载的网页,并且请求的方式为post请求。
请求分析
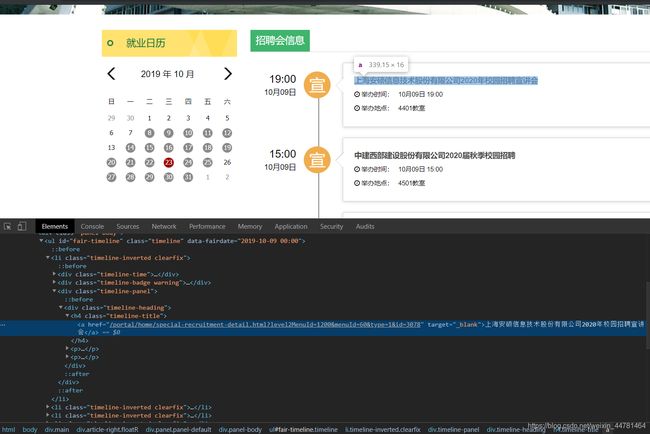
上图可以发现在第一个网站当中可以直接在源代码中抓取到我们需要构建的二级URL,同时我也发现了这个网址是一个Ajax加载的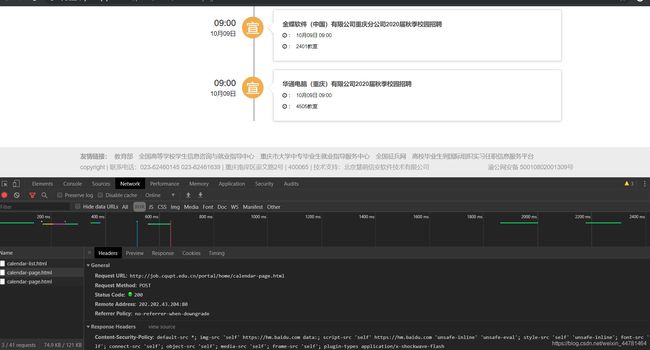
如上图,这是一个Ajax加载的,并且为post请求方式,而且在后期发现是由Form Data 改变参数得到的,因此需要在请求的时候用其他的处理方式。
重要代码解释
results = []
num = 0
try:
headers = {
'User-Agent': 'Mozilla/5.0(Windows NT 10.0;Win64;x64)'
+ ' AppleWebKit/537.36 (KHTML,like Gecko)'
+ 'Chrome/73.0.3683.103 Safari/537.36',
}
for first_url in first_urls_list:
response = requests.get(first_url, headers=headers)
html = etree.HTML(response.text)
if response.status_code == 200:
panduan = html.xpath('//ul[@id = "fair-timeline"]/li')
if panduan:
url = first_url # 赋予网址
# 构建请求头
for a in range(1, 11, 1):
formdata = {
"fairDate": '2019-09-25 00:00',
"pageIndex": a
}
data = parse.urlencode(formdata).encode(encoding='UTF8')
# 全局取消证书验证
ssl._create_default_https_context = ssl._create_unverified_context
request = urllib.request.Request(url, data=data, headers=headers)
# 返回结果
response = urllib.request.urlopen(request).read()
# utf-8解码
text = response.decode('utf-8', 'ignore')
html_text = etree.HTML(text)
if panduan:
list_makes = html_text.xpath('//h4[@class = "timeline-title"]/a/@href')
num = num + len(list_makes)
for list_make in list_makes:
# list_makes 是界面当中抓取下来的url后缀列表
# 这个for循环是给爬取下来的URL加工
url_1 = 'http://job.cqupt.edu.cn' + str(list_make)
results.append(url_1)
else:
break
print(str(day_info['月份']) + "月" + str(day_info['起始日期']) + "日有发布" + str(num) + "信息") # 后台输出有反馈
day_info['起始日期'] = int(day_info['起始日期']) + 1
num = 0 #初始化num参数
else:
print(str(day_info['月份']) + "月" + str(day_info['起始日期']) + '日无发布信息') # 后台输出无反馈
day_info['起始日期'] = int(day_info['起始日期']) + 1
else:
print("访问错误主网页错误")
return None
return results
except RequestException:
return None
上图是我创建二级URL的一个函数,其中
formdata = {
“fairDate”: ‘2019-09-25 00:00’,
“pageIndex”: a
}
data = parse.urlencode(formdata).encode(encoding=‘UTF8’)
# 全局取消证书验证
ssl._create_default_https_context = ssl._create_unverified_context
request = urllib.request.Request(url, data=data, headers=headers)
# 返回结果
response = urllib.request.urlopen(request).read()
# utf-8解码
text = response.decode(‘utf-8’, ‘ignore’)
html_text = etree.HTML(text)
这一个代码块用来处理Ajax加载的post请求,如果对Ajax加载不清楚的可以参考 lPython 解决Ajax动态加载问题(二十六).现在很多的网页都使用了AJAX加载,但是AJAX一般返回的是JSON,直接对AJAX地址进行post或get,就返回JSON数据了。但是需要我们自己写一个请求数据,就比如
formdata = {
“fairDate”: ‘2019-09-25 00:00’,
“pageIndex”: a
}
data = parse.urlencode(formdata).encode(encoding=‘UTF8’)
之后直接获取返回的结果就行了,因为我们学校的这个网站是我们学生自己搭建的,所以我怕证书有问题还取消了证书验证验证。在这个函数当中有一个参数叫做panduan,因为不是每一天都会有公司来学校招聘,因此爬取前进行一个if判断,如果发现panduan为空的话就证明今天没有校招,就直接将这个一级网址抛弃。
try:
headers = {
'User-Agent': 'Mozilla/5.0(Windows NT 10.0;Win64;x64)'
+ ' AppleWebKit/537.36 (KHTML,like Gecko)'
+ 'Chrome/73.0.3683.103 Safari/537.36',
}
for url_list in url:
response = requests.get(url_list, headers=headers)
if response.status_code == 200:
html = etree.HTML(response.text)
article_title = html.xpath('//h1[@class = "article_title"]/text()')
The_company_name = html.xpath('//tr/td[@class = "tl"]/text()')
place = html.xpath('//tr//td[@class = "tl" and@colspan="2"]/text()')
results_zhiwei = []
results_xueyuan = []
results_zhuanye = []
results_renshu = []
results_gangweizhize = []
results_yaoqiu = []
results_xinchou = []
results_leibie = []
active = True
while active:
for a in range(2, 50, 1):
bef = '//table[@class = "page-table" ]//tr['
aft_zhiwei = ']//td[1]/text()'
aft_xueyuan = ']//td[3]/text()'
aft_zhuanye = ']//td[4]/text()'
aft_renshu = ']//td[5]/text()'
aft_gangweizhize = ']//td[6]/text()'
aft_yaoqiu = ']//td[7]/text()'
aft_xinchou = ']//td[8]/text()'
aft_leibie = ']//td[9]/text()'
url_zhiwei = bef + str(a) + aft_zhiwei
url_xueyuan = bef + str(a) + aft_xueyuan
url_zhuanye = bef + str(a) + aft_zhuanye
url_renshu = bef + str(a) + aft_renshu
url_gangweizhize = bef + str(a) + aft_gangweizhize
url_yaoqiu = bef + str(a) + aft_yaoqiu
url_xinchou = bef + str(a) + aft_xinchou
url_leibie = bef + str(a) + aft_leibie
zhiwei = html.xpath(url_zhiwei)
xueyuan = html.xpath(url_xueyuan)
zhuanye = html.xpath(url_zhuanye)
renshu = html.xpath(url_renshu)
gangweizhize = html.xpath(url_gangweizhize)
yaoqiu = html.xpath(url_yaoqiu)
xinchou = html.xpath(url_xinchou)
leibie = html.xpath(url_leibie)
results_zhiwei.append(zhiwei)
results_xueyuan.append(xueyuan)
results_zhuanye.append(zhuanye)
results_renshu.append(renshu)
results_gangweizhize.append(gangweizhize)
results_yaoqiu.append(yaoqiu)
results_xinchou.append(xinchou)
results_leibie.append(leibie)
if zhiwei:
pass
else:
active = False
break
del results_zhiwei[-1] #最后一个为空,删除掉
del results_xueyuan[-1] # 最后一个为空,删除掉
del results_zhuanye[-1] # 最后一个为空,删除掉
del results_renshu[-1] # 最后一个为空,删除掉
del results_gangweizhize[-1] # 最后一个为空,删除掉
del results_yaoqiu[-1] # 最后一个为空,删除掉
del results_xinchou[-1] # 最后一个为空,删除掉
del results_leibie[-1] # 最后一个为空,删除掉
#print(str(henduo))
results = {
"标题": article_title[0],
"公司名字": The_company_name[0],
"地点": place[0],
"负责老师": place[1],
"招聘职位": results_zhiwei,
"学院": results_xueyuan,
"专业": results_zhuanye,
"需求人数": results_renshu,
"岗位职责": results_gangweizhize,
"专业技能要求": results_yaoqiu,
"薪酬": results_xinchou,
"职位类别": results_leibie,
"详细信息网址": url_list,
}
print(results)
else:
print("访问失败")
return results
except RequestException:
return None
上面这段代码是我通过上一个代码得到的二级URL进行的一些操作,取得这些子网页当中的我所需要的信息。都是一些常规操作,在这里我同样用了一个叫做zhiwei的参数来判断是由需要接着抓取,因为每一家公司可能同时提供多个职位,每个公司提供的职位个数不同,所以需用通过一个参数告诉计算机,这家公司的已经爬取完啦,你可以开始进行下一个公司的爬取了。
完整代码
import requests
import json
import ssl
import urllib.request
from urllib import parse
from lxml import etree
from requests.exceptions import RequestException
def make_info(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0(Windows NT 10.0;Win64;x64)'
+ ' AppleWebKit/537.36 (KHTML,like Gecko)'
+ 'Chrome/73.0.3683.103 Safari/537.36',
}
for url_list in url:
response = requests.get(url_list, headers=headers)
if response.status_code == 200:
html = etree.HTML(response.text)
article_title = html.xpath('//h1[@class = "article_title"]/text()')
The_company_name = html.xpath('//tr/td[@class = "tl"]/text()')
place = html.xpath('//tr//td[@class = "tl" and@colspan="2"]/text()')
results_zhiwei = []
results_xueyuan = []
results_zhuanye = []
results_renshu = []
results_gangweizhize = []
results_yaoqiu = []
results_xinchou = []
results_leibie = []
active = True
while active:
for a in range(2, 50, 1):
bef = '//table[@class = "page-table" ]//tr['
aft_zhiwei = ']//td[1]/text()'
aft_xueyuan = ']//td[3]/text()'
aft_zhuanye = ']//td[4]/text()'
aft_renshu = ']//td[5]/text()'
aft_gangweizhize = ']//td[6]/text()'
aft_yaoqiu = ']//td[7]/text()'
aft_xinchou = ']//td[8]/text()'
aft_leibie = ']//td[9]/text()'
url_zhiwei = bef + str(a) + aft_zhiwei
url_xueyuan = bef + str(a) + aft_xueyuan
url_zhuanye = bef + str(a) + aft_zhuanye
url_renshu = bef + str(a) + aft_renshu
url_gangweizhize = bef + str(a) + aft_gangweizhize
url_yaoqiu = bef + str(a) + aft_yaoqiu
url_xinchou = bef + str(a) + aft_xinchou
url_leibie = bef + str(a) + aft_leibie
zhiwei = html.xpath(url_zhiwei)
xueyuan = html.xpath(url_xueyuan)
zhuanye = html.xpath(url_zhuanye)
renshu = html.xpath(url_renshu)
gangweizhize = html.xpath(url_gangweizhize)
yaoqiu = html.xpath(url_yaoqiu)
xinchou = html.xpath(url_xinchou)
leibie = html.xpath(url_leibie)
results_zhiwei.append(zhiwei)
results_xueyuan.append(xueyuan)
results_zhuanye.append(zhuanye)
results_renshu.append(renshu)
results_gangweizhize.append(gangweizhize)
results_yaoqiu.append(yaoqiu)
results_xinchou.append(xinchou)
results_leibie.append(leibie)
if zhiwei:
pass
else:
active = False
break
del results_zhiwei[-1] #最后一个为空,删除掉
del results_xueyuan[-1] # 最后一个为空,删除掉
del results_zhuanye[-1] # 最后一个为空,删除掉
del results_renshu[-1] # 最后一个为空,删除掉
del results_gangweizhize[-1] # 最后一个为空,删除掉
del results_yaoqiu[-1] # 最后一个为空,删除掉
del results_xinchou[-1] # 最后一个为空,删除掉
del results_leibie[-1] # 最后一个为空,删除掉
#print(str(henduo))
results = {
"标题": article_title[0],
"公司名字": The_company_name[0],
"地点": place[0],
"负责老师": place[1],
"招聘职位": results_zhiwei,
"学院": results_xueyuan,
"专业": results_zhuanye,
"需求人数": results_renshu,
"岗位职责": results_gangweizhize,
"专业技能要求": results_yaoqiu,
"薪酬": results_xinchou,
"职位类别": results_leibie,
"详细信息网址": url_list,
}
print(results)
else:
print("访问失败")
return results
except RequestException:
return None
def make_main_URL():
the_mon = input("输入需要查询的月份:")
start_day = input("输入需要查询的起始日期:")
finish_day = input("请输入需要查询的结束日期:")
text_1 = int(finish_day)
text_2 = text_1 + 1 # 结束日期+1 不然在循环时会少循环一次
day_info = {
"月份": the_mon,
"起始日期": start_day
}
first_urls_list = []
if start_day == finish_day:
befor_url = 'http://job.cqupt.edu.cn/portal/home/calendar-page.html?fairDate=2019'
after_url = '%2000:00'
first_urls_list = []
first_url = befor_url + '-' + the_mon + '-' + str(start_day) + after_url
first_urls_list.append(first_url)
url = make_all_URL(first_urls_list, day_info)
make_info(url)
else:
# first_urls_list 是第一个URL及有20个子网页的URL
for x in range(int(start_day), text_2, 1):
befor_url = 'http://job.cqupt.edu.cn/portal/home/calendar-page.html?fairDate=2019'
after_url = '%2000:00'
first_urls = befor_url + '-' + the_mon + '-' + str(x) + after_url
first_urls_list.append(first_urls)
url = make_all_URL(first_urls_list, day_info)
make_info(url)
def make_all_URL(first_urls_list, day_info):
# 通过传输进来的URL列表生成每一个URL里面的子URL及公司校招详细信息网
# return位置不对 导致输出无发布有些有有些没有。貌似return后该函数就不执行下面的了
results = []
num = 0
try:
headers = {
'User-Agent': 'Mozilla/5.0(Windows NT 10.0;Win64;x64)'
+ ' AppleWebKit/537.36 (KHTML,like Gecko)'
+ 'Chrome/73.0.3683.103 Safari/537.36',
}
for first_url in first_urls_list:
response = requests.get(first_url, headers=headers)
html = etree.HTML(response.text)
if response.status_code == 200:
panduan = html.xpath('//ul[@id = "fair-timeline"]/li')
if panduan:
url = first_url # 赋予网址
# 构建请求头
for a in range(1, 11, 1):
formdata = {
"fairDate": '2019-09-25 00:00',
"pageIndex": a
}
data = parse.urlencode(formdata).encode(encoding='UTF8')
# 全局取消证书验证
ssl._create_default_https_context = ssl._create_unverified_context
request = urllib.request.Request(url, data=data, headers=headers)
# 返回结果
response = urllib.request.urlopen(request).read()
# utf-8解码
text = response.decode('utf-8', 'ignore')
html_text = etree.HTML(text)
if panduan:
list_makes = html_text.xpath('//h4[@class = "timeline-title"]/a/@href')
num = num + len(list_makes)
for list_make in list_makes:
# list_makes 是界面当中抓取下来的url后缀列表
# 这个for循环是给爬取下来的URL加工
url_1 = 'http://job.cqupt.edu.cn' + str(list_make)
results.append(url_1)
else:
break
#num = num + len(results)
print(str(day_info['月份']) + "月" + str(day_info['起始日期']) + "日有发布" + str(num) + "信息") # 后台输出有反馈
day_info['起始日期'] = int(day_info['起始日期']) + 1
num = 0 #初始化num参数
else:
print(str(day_info['月份']) + "月" + str(day_info['起始日期']) + '日无发布信息') # 后台输出无反馈
day_info['起始日期'] = int(day_info['起始日期']) + 1
else:
print("访问错误主网页错误")
return None
return results
except RequestException:
return None
if __name__ == '__main__':
make_main_URL()
print("爬取完毕")