BLEU详解及计算
《BLEU: a Method for Automatic Evaluation of Machine Translation》介绍到:Bleu 分数介于 0 和 1 之间。0.6 或 0.7 的分数被认为是您可以达到的最佳分数。即使是两个人也可能会为一个问题想出不同的句子变体,并且很少能达到完美匹配。出于这个原因,接近 1 的分数在实践中是不现实的,并且应该引发您的模型过度拟合的标志。
在我们了解如何计算 Bleu 分数之前,让我们先了解两个概念,即。N-gram 和精度。
N-gram
“n-gram”实际上是常规文本处理中广泛使用的概念,并不特定于 NLP 或 Bleu Score。这只是描述“一个句子中的一组'n'个连续单词”的一种奇特方式。
例如,在句子“The ball is blue”中,我们可以有 n-gram,例如:
- 1-gram (unigram):“The”、“ball”、“is”、“blue”
- 2-gram (bigram):“The ball”、“ball is”、“is blue”
- 3-gram (trigram): “The ball is”, “ball is blue”
- 4-gram:“The ball is blue”
请注意,n-gram 中的单词是按顺序排列的,因此“blue is The ball”不是有效的 4-gram。
精度(Precision)
该指标衡量预测句子中也出现在目标句子中的单词数量。
假设我们有:
- Target Sentence: He eats an apple
- Predicted Sentence: He ate an apple
我们通常会使用以下公式计算精度:
Precision = 正确预测词数 / 总预测词数
Precision = 3 / 4
但是像这样使用 Precision 还不够好。有两种情况我们仍然需要处理。
重复(Repetition)
第一个问题是这个公式允许我们作弊。我们可以预测一个句子:
- Target Sentence: He eats an apple
- Predicted Sentence: He He He
并获得完美的精度 = 3 / 3 = 1
多个目标句(Multiple Target Sentences)
其次,正如我们已经讨论过的,有很多正确的方式来表达同一个句子。在许多 NLP 模型中,我们可能会得到多个可接受的目标句子来捕捉这些不同的变化。
我们使用修改后的 Precision 公式来解释这两种情况,我们将其称为“Clipped Precision”。
裁剪精度 (Clipped Precision)
让我们通过一个例子来了解它是如何工作的。
假设我们有以下句子:
- Target Sentence 1: He eats a sweet apple
- Target Sentence 2: He is eating a tasty apple
- Predicted Sentence: He He He eats tasty fruit
我们现在做两件不同的事情:
- 我们将预测句子中的每个单词与所有目标句子进行比较。如果该词与任何目标句子匹配,则认为它是正确的。
- 我们将每个正确单词的计数限制为该单词在目标句子中出现的最大次数。这有助于避免重复问题。这将在下面变得更清楚。
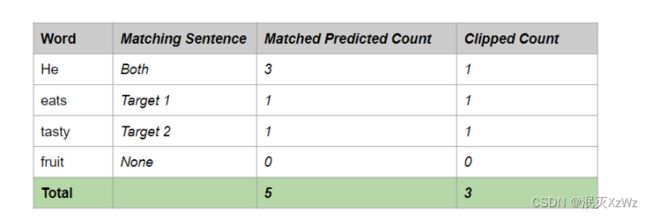
例如,“he”这个词在每个目标句中只出现一次。因此,即使“he”在预测句中出现三次,我们也将计数“剪裁”为 1,因为这是任何目标句中的最大计数。
Clipped Precision= 裁剪的正确预测词数 / 总预测词数
Clipped Precision = 3 / 6
注意:对于本文的其余部分,我们将仅使用“Precision”来表示“Clipped Precision”。
我们现在准备继续计算 Bleu 分数
Bleu 分数是如何计算的?
假设我们有一个 NLP 模型,可以生成如下预测的句子。为简单起见,我们将只采用一个目标 句,但如上例所示,多个目标句的过程非常相似。
- Target Sentence: The guard arrived late because it was raining
- Predicted Sentence: The guard arrived late because of the rain
Precision 1-gram
Precision 1-gram = Number of correct predicted 1-grams / Number of total predicted 1-grams

So, Precision 1-gram (p₁) = 5 / 8
Precision 2-gram
Precision 2-gram = Number of correct predicted 2-grams / Number of total predicted 2-grams
Let’s look at all the 2-grams in our predicted sentence:

So, Precision 2-gram (p₂) = 4 / 7
Precision 3-gram
Similarly, Precision 3-gram (p₃) = 3 / 6

Precision 3-gram (Image by Author)
Precision 4-gram
And, Precision 4-gram (p₄) = 2 / 5

Precision 4-gram(Image by Author)
Geometric Average Precision Scores
接下来,我们使用下面的公式组合这些精度分数。这可以针对不同的 N 值并使用不同的权重值来计算。通常,我们使用N = 4和统一权重wₙ = N / 4
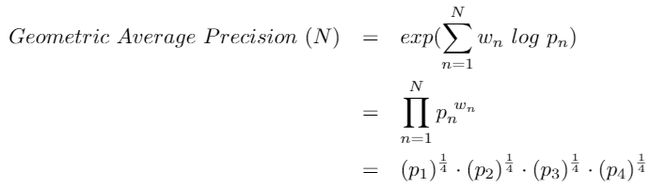
Brevity Penalty
第三步是计算“Brevity Penalty”。
如果您注意到 Precision 是如何计算的,我们可以输出一个由单个单词组成的预测句子,例如“The”或“late”。为此,1-gram Precision 应该是 1/1 = 1,表示满分。这显然具有误导性,因为它鼓励模型输出更少的单词并获得高分。
为了抵消这一点,简洁惩罚会惩罚太短的句子。
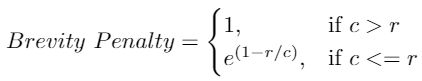
- c 是预测长度 = 预测句子中的单词数,并且
- r 是目标长度 = 目标句子中的单词数
这确保了即使预测句子比目标长得多,Brevity Penalty 也不能大于 1。而且,如果你预测的词很少,这个值就会很小。
在这个例子中,c = 8 和 r = 8,这意味着简洁惩罚 = 1
Bleu Score
最后,为了计算 Bleu 分数,我们将简洁罚分与精度分数的几何平均值相乘。
![]()
可以为不同的 N 值计算 Bleu 分数。通常,我们使用 N = 4。
- BLEU-1 使用 unigram Precision 分数
- BLEU-2 使用unigram和bigram的几何平均值
- BLEU-3 使用unigram、bigram和trigram的几何平均值
- 等等。
在 Python 中实现 Bleu 分数
在实践中,您很少需要自己实现 Bleu Score 算法。nltk 库是一个非常有用的 NLP 功能库,它 提供了 Bleu Score 的实现。
-
from nltk.translate.bleu_score
import corpus_bleu
-
-
references = [[[
'my',
'first',
'correct',
'sentence'], [
'my',
'second',
'valid',
'sentence']]]
-
candidates = [[
'my',
'sentence']]
-
score = corpus_bleu(references, candidates)
Bleu 评分的优势
Bleu Score 如此受欢迎的原因在于它有几个优点:
- 计算速度快,易于理解。
- 它与人类评估相同文本的方式相对应。
- 重要的是,它与语言无关,因此可以直接应用于您的 NLP 模型。
- 当您有多个基本事实句子时,可以使用它。
- 它的使用非常广泛,这使得将您的结果与其他工作进行比较变得更加容易。
Bleu 分数的弱点
尽管它很受欢迎,但 Bleu Score 因其弱点而受到批评:
- 它不考虑单词的含义。对于人类来说,使用具有相同含义的不同单词是完全可以接受的,例如。使用“watchman”而不是“guard”。但 Bleu Score 认为这是一个不正确的词。
- 它只查找完全匹配的单词。有时可以使用同一个词的变体,例如。“rain”和“raining”,但 Bleu Score 将其视为错误。
- 它忽略了文字的重要性。使用 Bleu Score 时,像“to”或“an”这样与句子不太相关的不正确单词会受到与对句子意义有重大贡献的单词一样严重的惩罚。
- 它不考虑单词的顺序,例如。句子“The guard arrived late because of the rain”和“The rain arrived late because of the guard”会得到相同的 (unigram) Bleu Score,尽管后者完全不同。
参考文章:https://towardsdatascience.com/foundations-of-nlp-explained-bleu-score-and-wer-metrics-1a5ba06d812b https://towardsdatascience.com/foundations-of-nlp-explained-bleu-score-and-wer-metrics-1a5ba06d812b
https://towardsdatascience.com/foundations-of-nlp-explained-bleu-score-and-wer-metrics-1a5ba06d812b