Python 乱码原理及其解决办法
最近在爬虫过程中爬下来的HTML文件中出现了不认识的字符,也就是“乱码”(之前也遇到了系统之间文件显示“乱码”的问题),花了点时间学习Python编码相关的问题,主要参考了以下几位的文章:Unicode编码底层描述,Python二进制数据,Python编码问题。故取多家之长,对“乱码”问题进行了梳理,写成比较简单易懂的总结博客。
思路是先掌握常见编码格式原理,然后弄清楚各个“系统”中编码格式和要求,最后通过代码实际演示转码结果。其中涉及到显示规则(编码软件)、存储规则、显示(打印输出规则)多方规则的不同,还涉及到不同编码之间的转化,如果没有搞懂,确实很不容易“捉虫”。
一、常见的编码规范
- 二进制数据,bit(一个子位),二进制数据在python中以字节(bytes)类型,用b’为前缀。
- ASCII编码,1bytes=8bits(一个字节),不严谨的可以认为ASCII码就是bytes,能表示的最大的整数就是255(2^8-1=255),而ASCII编码,占用0 - 127用来表示大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。 还对一些如’\n’,‘\t’,‘#’,'@'等字符进行了编码。
- GB2312编码,16bit(2个字节),适用于汉字处理、汉字通信等系统之间的信息交换,通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB2312。该标准共收录6763个汉字,其中一级汉字3755个,二级汉字3008个;同时,GB 2312收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个全角字符。
- GBK编码,16bit(2个字节),兼容GB2312,收录了 21003 个汉字,共有 23940 个码位。而且它与 Unicode 组织的Unicode编码完全兼容。
- Unicode 编码,通常16bit(2个字节),为了统一所有文字的编码,Unicode应运而生,这是一种满足世界所有所有文字符号的编码。从0x000000 - 0x10FFFF, 对应全世界所有的语言、公式、符号。由于Unicode采用定长编码的方式,相较于ASCII编码方式存储文件时候太占据存储空间,比如字符’A’,ASCII编码只需要一个字节(8位),用Unicode就翻了一倍。同时,随着互联网的诞生,需要传输和存储的数据越来越多,如果都是用Unicode编码传输会造成很大的浪费,于是形成多种节约空间和兼容性的编码规范,例如UTF-8,UTF-16,UTF-32,其中应用最广泛的是UTF-8。
unicode码在python里有两种表示方式:它们是等价的,而且都是str对象1.‘\u四位十六进制数’2.u’字符串’。
# unicode码再python里有两种表示方式,它们是等价的,而且都是str对象
#1.'\u四位十六进制数'
print('\u0065')
print("***"*8)
# 2.u'字符串'
print(u'e')
---------------------------------------------------------
输出:
e
************************
e
- UTF-8,Unicode Transformation Format,可变长度编码,通常使用1~4字节为每个字符编码,兼容ASCII编码,这是Unicode的其中一种转换格式。
- ISO-8859-1 ,如果网页中没有通过chartset字段设置为"utf-8",则默认为ISO-8859-1编码模式,则无法解析中文,这是乱码的原因。通过
reqs.encoding = reqs.apparent_encoding,把apparent_encoding的编码格式赋值给encoding。apparent_encoding会从网页的内容中分析网页编码的方式,所以apparent_encoding比encoding更加准确。
二、不同“系统”编码格式要求
在码代码的过程中,会在不同的“系统”中对文件格式进行转换,所有有必要先梳理各个“系统”中要求。主要有:
- 系统默认编码
- windows简体中文系统默认编码是gbk,最新的win11系统默认为utf-8。如果将超出gbk范围的unicode码,写入系统的txt文件和在cmd中print就会报错,解决办法可以将unicode码encode为bytes再写入或print。
- macOS 系统和Linux系统默认支持的是 UTF-8 编码,在处理文件和码编码的过程中简单很多。
- 编辑界面编码
编辑界面编码,即编辑器界面输入、显示文本的编码,如cmd(小黑窗)、Python默认的IDE、VScode、pycharm软件。
- 在windows编辑界面编码默认是ascii码,也就是写的程序语句默认是ascii编码,但一旦涉及到ascii码不能表示的,就隐形转换为系统默认的gbk编码表示。
- 在macOS系统,编辑界面默认为UTF-8编码。
- 显示界面编码
显示界面编码,即打印结果显示界面(print结果显示界面)
- Windows系统中,cmd中运行程序,默认显示文本的编码是ascii编码,超出ascii编码就会转化显示或报错,具体见下文。
- 在macOS系统,编辑界面默认为UTF-8编码。
不同的类型数据显示结果不同,主要分两类:
3.1 输出为str类型即为unicode类型:输出不存在乱码问题。
3.2 输出为byte类型:
原理如下:
ASCII(0-127)内情况:每读一个字节就和ascii码比对一下,如果符合ascii码的可显示字符(共有95个可显示字符),那这个字节就按照ascii码来表示,否则就按十六进制\x某某来表示(0~31及127(共33个)是控制字符或通信专用字符—显示十六进制\x某某)
情况一:显示字符,特殊字符,字母和数字,共有95个----显示为正常字符,如‘A’。
print(b'\x40\x41')#ASCII中可显示的字符串
输出为:b'@A'
情况二:按十六进制\x某某来表示:0~31及127是控制字符或通信专用字符,共33个,显示为十六进制的数\x某某,如\x00\x01。
print(b'\x00\x01')
输出为:b'\x00\x01'
情况三: ASCIII字符外,程序报错。
print(b'中')
报错:
SyntaxError: bytes can only contain ASCII literal characters.
有时候在不同的编辑界面显示’乱码‘,是因为不能直接转码输出(系统之间默认的码表格式与输出界面之间码表格式不匹配),需要经过unicode为中介,才能正确输出。
4.代码文件编码
代码文件(py文件)本身也是一个文本,它也需要在硬盘或者其他载体上保存的文件。
Windows默认编码是系统gbk编码,macos/linux默认为UTF-8,所以py文件copy到不同平台,问题就会发生,出现“乱码”。
三、编码之间转换原理
- 几个基本概念
- 在python3中也有两种字符类型: bytes和str(unicode) 系统默认 str(unicode)。
- Unicode形式的字符串的type是str,utf-8等其他形式的字符串的type是bytes。
- UTF-8 和 GBK(显示的字符) 在内存中为的 bytes 对象,它们存储结构不同(用不同组合(即不同的位长和每个bit的0/1取值不同)表示同一个字符)。他们通过print()(即显示打印结果)出来,此处显示结果超过ASCII码表值,所以显示为十六进制格式(原理见情况二)
中文二字的显示结果
'\u4e2d\u6587'就是中文二字对应的Unicode编码
b'\xe4\xb8\xad\xe6\x96\x87'就是中文二字对应的utf-8编码
b'\xd6\xd0\xce\xc4'就是中文二字对应的gbk编码
中文二字的存储结果:
print('中文'.encode('utf-8'))
结果为:b'\xe4\xb8\xad\xe6\x96\x87'
for i in b'\xe4\xb8\xad\xe6\x96\x87':
print(i,'的二进制为:',bin(i))
结果为:
228 的二进制为: 0b11100100
184 的二进制为: 0b10111000
173 的二进制为: 0b10101101
230 的二进制为: 0b11100110
150 的二进制为: 0b10010110
135 的二进制为: 0b10000111
发现字符“中文”的utf-8编码方式为:11100100 10111000 10101101 11100110 10010110 10000111,这是它在计算机中存储的方式。
2.编码解码过程:
涉及编码问题时,需要编码与解码,第一步一定是检查变量类型,看它是str还是btyes,再决定使用encode还是decode方法
Encode()方法:将str字符(unicode对象)串按照UTF8(或GBK等)的编码规则进行编码,得到的是bytes对象。bytes对象显示规则又有不同(具体见上文)
Decode()方法:bytes(对象)按照UTF8(或GBK等)的编码规则进行解码,得到str字符(解码规则不同,得到相应的str字符也不同)。
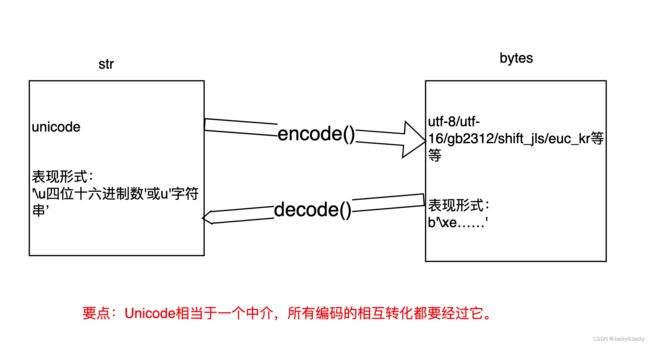 图中说明:utf-8与gbk之间转换需要使用unicode过渡,因为utf-8与gbk之间没有直接对应的转码规则。而unicode与utf-8等有直接的转码规则。
图中说明:utf-8与gbk之间转换需要使用unicode过渡,因为utf-8与gbk之间没有直接对应的转码规则。而unicode与utf-8等有直接的转码规则。
另外,浏览网页的时候,服务器会把动态生成的 Unicode 内容(有时候为gbk编码,需要自己手动转码,不然会报错),转化为 UTF-8 编码形式,再传输到浏览器,那么用户就可以看到自己能理解的语言组成的网页,比如中文、日文、韩文等等。很多网页的源代码上会有类似的信息,表示该网页是 UTF-8 编码。
四、常见报错原因及解决办法
常见报错,有位知乎大佬常见报错总结的比较好,稍加整理后如下:
- 没分清str和bytes:
我们有时会看到这样两种报错
AttributeError: 'str' object has no attribute 'decode'
AttributeError: 'bytes' object has no attribute 'encode'
上面的报错可以又下面的代码导致
a = '中文'
b = a.encode('GBK')
a.decode()
b.encode()
原因在于:
a是str类型,对应Unicode编码,只能encode不能decode
b是bytes类型,对应UTF-8编码,只能decode不能encode。
所以码表解码的时候要分清是对象类型。另外,考虑到输出(print打印)的结果意义(需要人能正常解读),我们从来不需要输出UTF-8等编码后的内容即bytes,我们要输出的永远都是str,所以不要把encode后的结果输出出来,没有任何意义。
2.字符集没有包含当前字符造成编码错误。
之前提到的UTF-8/GBK等编码,都对应字符集,即这种编码方式支持对哪些字符编码,UTF-8就支持所有字符,GBK对韩文就不支持,ASCII就不支持中文。
我们在python中输入各国文字都可以,因为Unicode是支持任意字符的。当把字符转化为一些不支持它的编码时,就会报错,示例如下:
ASCII中文:
>>>a = '中文'
>>> a.encode('ascii')
Traceback (most recent call last):
File "" , line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
GBK韩文
>>> a = '오빠-o bba'
>>> a.encode('GBK')
Traceback (most recent call last):
File "" , line 1, in <module>
UnicodeEncodeError: 'gbk' codec can't encode character '\uc624' in position 0: illegal multibyte sequence
3.二进制数据编码方式和解码方式不统一造成报错
对于一个字符集来说,每一个字符都对应着二进制数据,但是不能说这么多位的二进制数每个都对应一个字符。所以一个字符通过A编码变成的二进制数,可能在B编码中并不对应一个字符,此时用B来解码就会报错,因为找不到这样的字符
>>> a = '中文'
>>> b = a.encode('utf-8')
>>> b.decode('gbk')
Traceback (most recent call last):
File "" , line 1, in <module>
UnicodeDecodeError: 'gbk' codec can't decode byte 0xad in position 2: illegal multibyte sequence
4.二进制数据编码方式和解码方式不统一造成乱码
和上一点相似,A编码变成的二进制数,可能在B编码中正好对应着字符,但是这个字符肯定和A中对应的字符不一样了,很有可能是一些我们平时没见到过的,被我们称之为乱码,例子如下:
>>> a = '方法'
>>> b = a.encode('utf-8')
>>> b.decode('gbk')
'鏂规硶'
5.windows命令行中产生的额外错误
(这个地方我没有完全懂,有大佬懂得话帮忙解释下,特别是模式二的情况)
有时候会用windows下使用交互模式的python,有时会编写py文件在命令行中调用。这两种情况下代码运行结果都会直接打印在命令行窗口中。输出(打印)在命令行窗口的结果可能会和在jupyter中结果不同。
在网上copy了一些奇怪的文字(这是奥里亚语),在几种不同的模式下出现的结果:
在jupyter notebook中使用是可以正常返回结果的,在IDLE交互模式下也是可以返回正常结果的。
a = 'ଆପଣ କିପରି ଅଛନ୍ତି'
print(a)
# ଆପଣ କିପରି ଅଛନ୍ତି
模式一: py文件在命令行中调用 ,如果在python文件,如file1.py文件中输入上面两行代码,在cmd中输入python file1.py,会得到如下结果
Traceback (most recent call last):
File "1.py", line 2, in <module>
print(a)
UnicodeEncodeError: 'gbk' codec can't encode character '\u0b06' in position 0: illegal multibyte sequence
模式二:交互模式 如果是在cmd的python交互模式下使用是这样的(其中那个赋值的文字还显示的是方框)
>>> a = 'ଆପଣ କିପରି ଅଛନ୍ତି'
>>> print(a)
??? ????? ??????
分析模式一的情况:
从报错内容上来看,和模式二一样,可以看出这里相当于执行了a.encode(‘GBK’)(windows内部自动转换),但是实际上我们的程序只是打印了,根本没涉及到编码解码的问题。这是因为默认情况下,cmd显示字符是通过GBK来显示的,也就是会自动把字符先转化为GBK的二进制数,再用这些二进制数对应字符显示在屏幕上,所以这个屏幕只支持GBK字符集收录的字符,有不属于这个字符集的字符想显示就会报这个错误。
解决方法:先在cmd中输入chcp 65001,这样会clear之前所有命令,好像一个新的界面一样,然后再python 1.py,理论上就可以正常输出了,不过还是没完全正常。
输出的是一堆方框,但是将这些方框复制下来,粘贴到jupyter里显示的是正确的字符。说明其实打印出来的是正确的,只是在cmd中无法显示而已,这和cmd的字体有关。点击左上角图标-属性,修改字体,不过这个语言实在太偏,没有一个字体可以将其正常显示。
类似地,拿希伯来文עברית做实验,在consolas字体下也显示不出来,复制到jupyter时也是正常的,这个情况就和刚才完全一样了,字体换成courier new就发现可以正常显示了,说明显示方框确实是字体问题。
回过头来,讲一下chcp命令。chcp指代码页,具体其实不用懂,默认是chcp936,对应编码方式是中文简体GBK,而chcp65001对应的是UTF-8,更多代码页见这个链接Windows下的chcp命令(更改该控制台的活动控制台代码页)
分析模式二的情况
上面(离这里最近的那个代码块)展示的代码是直接从cmd中复制过来的,从复制结果来看,原来显示方框的在这里是正常显示的,在cmd中无法显示是因为字体无法显示;而下面?是真的没编码正确。其实问题和第一种情况是一样的。
在默认的chcp936下,字符需要先编码为GBK才能print在屏幕上,而这一步编码是失败的,所以显示的是问号,这里没有报错是和第一种的一种点差别,但是本质上是一样的。
对于方框显示问题,因为没有合适的字体,可以再拿希伯来文עברית做实验来加深理解。我们是不是直接将字体换了就可以正常显示了呢,其实也不是。因为在chcp936的情况下,是没有刚才的字体的,只有切换到chcp65001下才有可以显示的字体。
问题5的总结:
其实在windows中出现的问题就两种:
一种是由于chcp代码页的显示,会有隐藏着的编码过程,这个过程可能引起编码错误。
一种是cmd中支持的字体限制,有些字体无法正常显示一些字符,让人看起来像乱码。
五、常用转码工具代码
- GBK与utf-8转换代码:
# gbk转utf8
def gbkfileToUtf8(inFilePath, outFilePath):
with open(inFilePath, 'rb') as f1:
a = f1.read()
b = a.decode('gbk', 'ignore')#将GBK转化成Unicode
with open(outFilePath, 'w', encoding='utf8') as f2:
f2.write(b)#将Unicode转化成UTF8
print("转化完成")
# utf8转gbk
def utf8fileToGbk(inFilePath, outFilePath):
with open(inFilePath, 'rb') as f1:
a = f1.read()
b = a.decode('utf8', 'ignore')#将utf8转化成Unicode
with open(outFilePath, 'w', encoding='gbk') as f2:
f2.write(b)#将Unicode转化成gbk
print("转化完成")
2.爬虫网页过程中的编码:URL编码
由于URL 只能使用 ASCII 字符集 通过因特网进行发送,同时非ASCII格式的字符都有一个unicode的编码(毕竟它是包含世界上所有字符的编码)。通过encoding='utf-8’等,转化成服务器(默认utf8)可以接受的编码结果,这个结果也是ASCII字符集内的,所以编码后就可以通过因特网传输了。不得不再一次感叹:chatGPT太香了,比炸鸡烤串都香~

通过代码进行验证chatGPT的过程:
a= "你"
s = a.encode("utf8")
type(s),s
输出为:(bytes, b'\xe4\xbd\xa0')---跟chatGPT里面的分析过程一样。
urlib中字符的编码解码过程:使用unquote/quote函数编解码。如下:
from urllib.parse import unquote
kw = '%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88'
kw = unquote(kw,encoding ='utf-8',errors ='replace')) # 将URL编码的字符串转换为汉字
print(kw) # 输出:数据分析师
六、总结
花了不少时间总结这个Python编码问题(不管是文件传输还是爬虫解析),也算基本搞懂了编码解码的问题(win平台下没有完全搞懂)。
总结来看,
- 首先,搞清楚各个编码规范的原理。
- 其次,知道各个“系统”(是存储还是显示(打印))默认的编码规范要求。
- 再次,根据使用场景中要把对应的转码编码需要的字符集梳理清楚(到底是str还是btyes),然后将对应的字符集进行转码编码,其中最最重要的是要牢记unicode作为中间码的作用。encode()和deconde()方法其中的可选参数也要注意。
其中,一特殊场景:爬虫。爬虫过程这一应用较多且特殊的场景字符转换分析。不管是爬虫爬下来的html.text的文本编码规范,还是url中传输的非ASCII字符的编码。 - 最最重要的掌握基础知识概念后用代码运行起来!
最后,感谢我参考过的各位大佬!