java集合小结
Collection
集合的由来:
数组的长度是固定的,当添加的元素超过了数组的长度时,需要对数组重新定义,太麻烦。Java内部给我们提供了集合类,长度是可以改变的。
数组和集合的区别:
区别一:
数组既可以存储基本数据类型,也可以存储引用数据类型,基本数据类型存储的是值,引用数据类型存储的是地址值
集合只能存储引用数据类型(对象)。也可以存储基本数据类型,但在存储的时候会自动装箱变成对象
区别二:
数组长度是固定的,不能自动增长
集合的长度是可变的,可以根据元素个数的变化而变化
使用时机:
元素个数固定推荐使用数组
元素个数不是固定推荐使用集合
集合继承体系图

主要方法
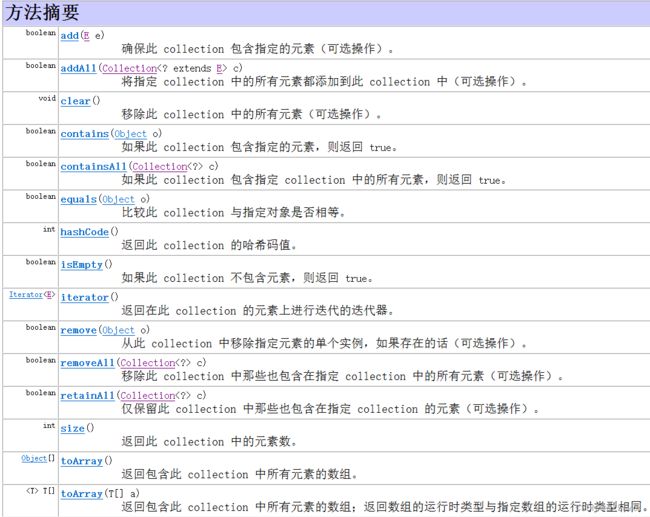
Iterator

public class Test {
public static void main(String[] args) {
Collection<Person> c = new ArrayList<Person>();
c.add(new Person(1, "John", "12"));
c.add(new Person(2, "Tom", "34"));
c.add(new Person(3, "Mick", "45"));
c.add(new Person(4, "Jack", "56"));
System.out.println(c);
System.out.println("--------------------------------");
Iterator<Person> it = c.iterator();
while (it.hasNext()) {
// System.out.println(it.next());
Person person = (Person) it.next();
System.out.println(person.getAge()+" "+person.getId()+" "+person.getName());
}
}
}
迭代器原理:
迭代器是对集合进行遍历,而每一个集合内部的存储结构是不同的,所以每一个集合存和取都是不一样的那么就需要在每一个类中定义hasNext()和next()方法,这样做是可以的,但是会让整个集合体系过于臃肿,迭代器将这样的方法向上抽取出接口,然后在每一个类的内部,定义自己的迭代方法,这样做的好处有二个:第一规定了整个集合体系的遍历方式都是hasNext()和next()方法,第二代码由底层内部实现,使用者不需要关心如何实现,会用即可
List集合
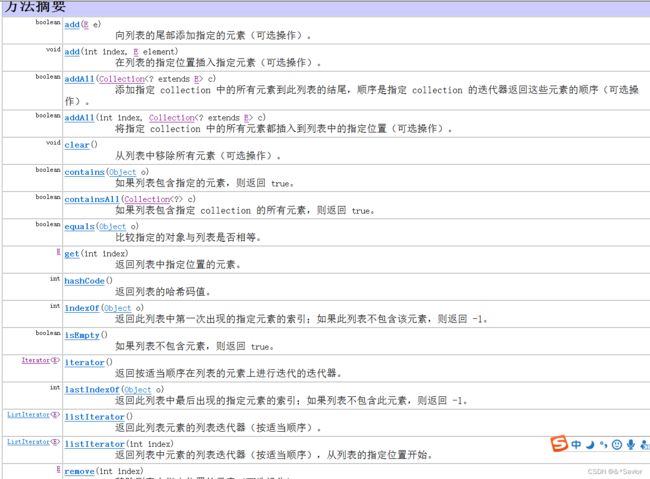

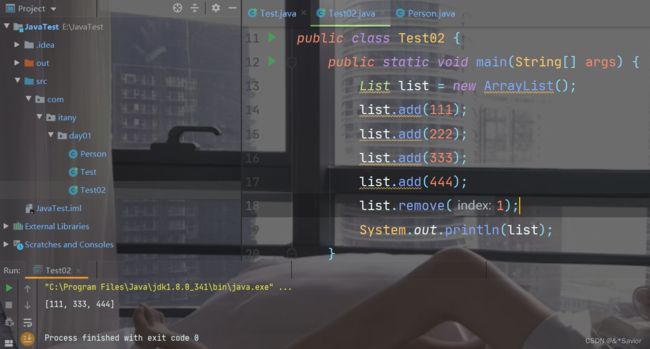
注意一:删除时不会自动装箱,remove()方法里面写索引

注意二:使用迭代器的时候再进行增删操作会导致并发异常
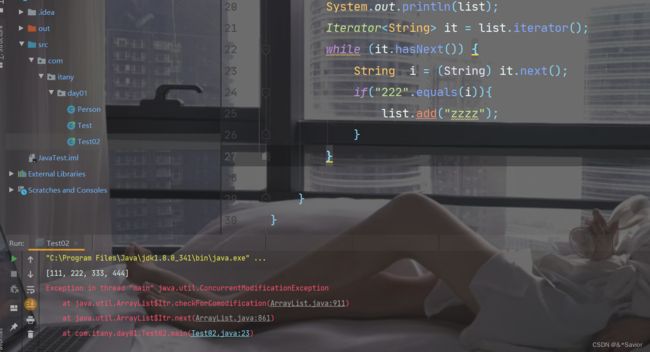
List中特有的ListIterator可以解决这个问题

vector特有的添加和迭代方式
public class Test03 {
public static void main(String[] args) {
Vector<String> vector = new Vector<String>();
// vector.add("a");
// vector.add("b");
// vector.add("c");
// vector.add("d");
// System.out.println(vector);
vector.addElement("a");
vector.addElement("b");
vector.addElement("c");
vector.addElement("d");
Enumeration<String> v = vector.elements();//获取枚举
while (v.hasMoreElements()) {//判断集合中是否有元素
System.out.println(v.nextElement());//获取集合中的元素
}
}
}
数组和链表区别:
数组:查询快,修改也快,增删慢
链表:查询慢,修改也慢,增删快
List三个子类的特点
ArrayList:
底层数组实现,查询快,增删慢。线程不安全,效率高
Vector:
底层数组实现,查询快,增删慢,线程安全,效率低
LinkedList:
底层链表实现,查询慢,增删快,线程不安全,效率高
Vector相对ArrayList查询慢(线程安全)
Vector相对LinkedList增删慢
Vector和ArrayList区别:
vector是线程安全的,效率低
ArrayList是线程不安全的,效率高
ArrayList和LinkedList的区别:
ArrayList底层是数组结构,查询和修改快
LinkedList底层是链表结构,增删比较快
使用时机:
查询多用ArrayList
增删多用LinkedList
都多用ArrayList
例题:去重(通过ArrayList实现)
思路:创建一个新的ArrayList集合,判断是否包含,不包含就加入
public class Test04 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<String>();
list.add("a");
list.add("b");
list.add("c");
list.add("a");
list.add("b");
list.add("d");
list.add("e");
list.add("a");
ArrayList<String> list2 = new ArrayList<String>();
Iterator<String> it = list.iterator();
while (it.hasNext()) {
Object o = it.next();
if(!list2.contains(o)){
list2.add((String) o);
}
}
System.out.println("list:"+list);
System.out.println("list2:"+list2);
}
}
注意:如果是对象,需要重写equals方法
原因:contains方法判断是否包含底层依赖的是equals方法
remove方法判断是否删除,底层依赖的也是equals方法
public class Test05 {
public static void main(String[] args) {
ArrayList<Person> list = new ArrayList<Person>();
list.add(new Person(1,"John","23"));
list.add(new Person(1,"John","23"));
list.add(new Person(2,"Tom","33"));
list.add(new Person(3,"Jack","44"));
list.add(new Person(4,"John","23"));
list.add(new Person(4,"Mick","23"));
ArrayList<Person> list2 = new ArrayList<Person>();
Iterator<Person> it = list.iterator();
while (it.hasNext()) {
Object o = it.next();
if(!list2.contains(o)){
list2.add((Person) o);
}
}
System.out.println("list:"+list);
System.out.println("list2:"+list2);
}
}
package com.itany.day01;
import java.util.Objects;
/**
* Author: zhh
* Date: 2022-10-03 15:58
* Description: <描述>
*/
public class Person {
private Integer id;
private String name;
private String age;
public Person() {
}
public Person(Integer id, String name, String age) {
this.id = id;
this.name = name;
this.age = age;
}
/**
* 获取
* @return id
*/
public Integer getId() {
return id;
}
/**
* 设置
* @param id
*/
public void setId(Integer id) {
this.id = id;
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
this.name = name;
}
/**
* 获取
* @return age
*/
public String getAge() {
return age;
}
/**
* 设置
* @param age
*/
public void setAge(String age) {
this.age = age;
}
public String toString() {
return "Person{id = " + id + ", name = " + name + ", age = " + age + "}";
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return Objects.equals(id, person.id) &&
Objects.equals(name, person.name) &&
Objects.equals(age, person.age);
}
@Override
public int hashCode() {
return Objects.hash(id, name, age);
}
}
LinkedList

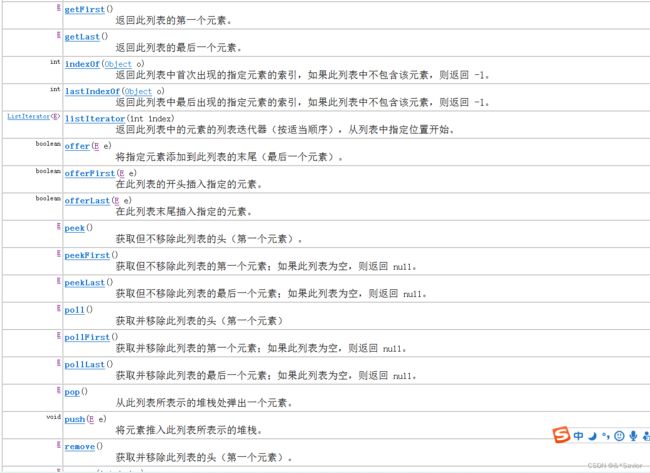

用LinkedList模拟简单栈结构
public class Stack {
private LinkedList list=new LinkedList();
/**
* 模拟进栈
*/
public void in(Object obj) {
list.addLast(obj);
}
/**
* 模拟出栈
*/
public void out(Object obj) {
list.removeLast();
}
/**
* 模拟栈是否为空
*/
public boolean isEmpty() {
return list.isEmpty();
}
}
泛型
好处:提高安全性(将运行时的错误转换到编译期)、省去强转的麻烦
基本使用:<>中放的必须是引用数据类型
注意事项:前后泛型必须一致,或者后面的泛型可以省略不写
增强for
简化数组和Collection集合遍历
格式:for(元素数据类型 变量:数组或者Collection集合){使用变量即可}
三种迭代能否删除
- 普通for循环,可以删除,但是索引要–(可以反过来)
- 迭代器:可以删除,但是必须使用迭代器自身的remove方法,否则会发生并发修改异常
- 增强for循环:不可以删除
数组转集合
注意基本数据类型的数组转换成集合,会将整个数组当成一个对象转换
将数组转换成集合,数组必须是引用数据类型
public class Test07 {
public static void main(String[] args) {
//注意基本数据类型的数组转换成集合,会将整个数组当成一个对象转换
//将数组转换成集合,数组必须是引用数据类型
// int[] arr={11,22,33,44,55};
// Listlist = Arrays.asList(arr);
// System.out.println(list);//结果[[I@1b6d3586]
Integer[] arr={11,22,23,24,25,26,27,28,29};
List<Integer> list = Arrays.asList(arr);
System.out.println(list);//结果[11, 22, 23, 24, 25, 26, 27, 28, 29]
}
}
集合转数组
注意:当数组长度小于集合的size时,转换后的数组长度等于集合的size
当数组的长度大于等于集合的size时,转换后的数组长度和指定的数组长度一样
public class Test08 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<String>();
list.add("a");
list.add("b");
list.add("c");
list.add("d");
// String[] arr=list.toArray(new String[10]);
// System.out.println(arr.length);//10
String[] arr=list.toArray(new String[2]);
for (String s:arr){
System.out.println(s);
}
System.out.println(arr.length);//4
}
}
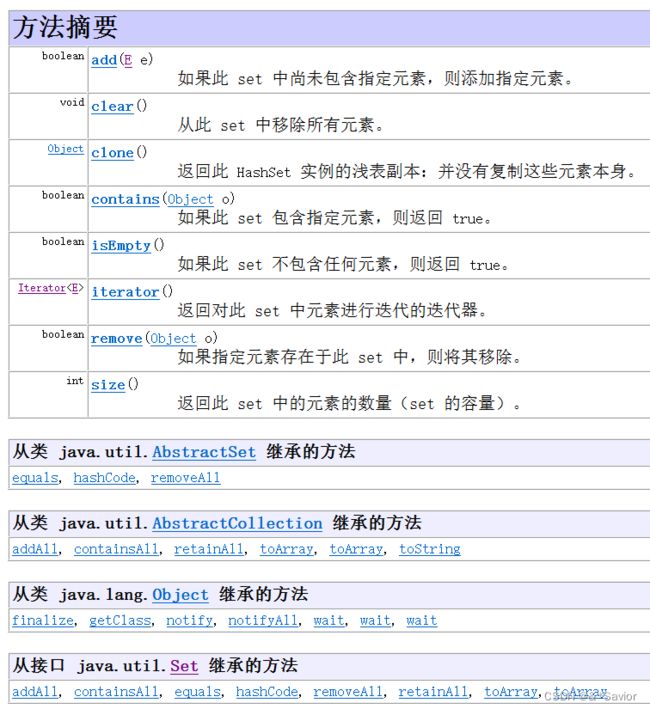
Set集合
HashSet
public class Test09 {
public static void main(String[] args) {
HashSet<String> set = new HashSet<String>();
boolean b1 = set.add("a");
boolean b2 = set.add("b");
boolean b3 = set.add("b");//重复添加返回true
// System.out.println(set);
System.out.println(b1);//true
System.out.println(b2);//true
System.out.println(b3);//false
for(String s:set){//能用迭代器迭代的就能使用增强for循环遍历
System.out.println(s);
}
}
}
注意:添加对象需要重写equals()和hashCode()方法
public class Test10 {
public static void main(String[] args) {
HashSet<Person> set = new HashSet<Person>();
set.add(new Person(1, "John", "23"));
set.add(new Person(2, "John", "55"));
set.add(new Person(3, "John", "23"));
set.add(new Person(1, "John", "23"));
for(Person person :set) {
System.out.println(person);
}
//未重写equals和hashCode结果
//Person{id = 3, name = John, age = 23}
//Person{id = 2, name = John, age = 55}
//Person{id = 1, name = John, age = 23}
//Person{id = 1, name = John, age = 23}
//重写equals和hashCode结果
//Person{id = 1, name = John, age = 23}
//Person{id = 2, name = John, age = 55}
//Person{id = 3, name = John, age = 23}
}
}
HashSet原理:
我们使用Set集合是需要去重复的,如果在存储的时候逐个比较equals,效率较低,哈希算法提高了去重复的效率,降低了使用equals方法的次数
- 当HashSet调用add方法存储对象的时候,先调用对象的hashCode()方法得到一个哈希值,然后在集合中查找是否有哈希值相同的对象
- 如果没有哈希值相同的对象,直接放入集合中
- 如果有哈希值相同的对象,就和哈希值相同的对象进行equals比较,比较结果为false就存入,比较结果为true则不存
将自定义的对象存入HashSet去重复
- 类中必须重写equals()和hashCode()方法
- hashCode():属性相同的对象必须返回值必须相同,属性不同的对象返回值尽可能不同(提高效率)
- equals():属性相同返回true,属性不同返回false,返回false时存储
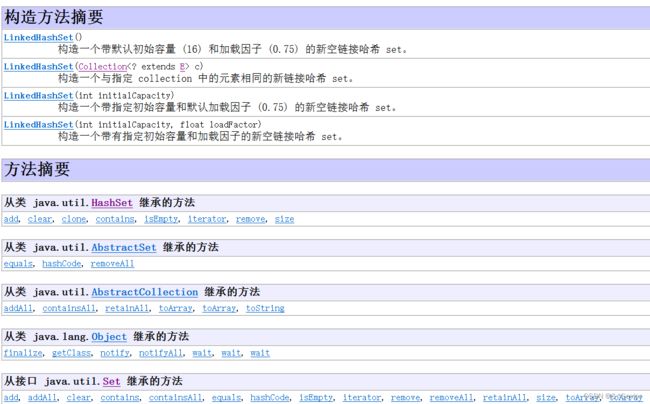
LinkedHsahSet
- LinkedHashSet底层是链表实现的,是set中唯一一个能保证怎么存就怎么取的集合对象
- 因为是HashSet的子类,所以也保证元素的唯一,与HashSet的原理一样
public class Test11 {
public static void main(String[] args) {
LinkedHashSet<String> st = new LinkedHashSet<>();
st.add("c");
st.add("d");
st.add("e");
st.add("a");
st.add("b");
st.add("b");
st.add("c");
st.add("d");
st.add("e");
st.add("e");
for(String s :st){
System.out.println(s);
}
//结果
//c
//d
//e
//a
//b
}
}
例题1:编写一个程序,获取10个1-20之间的随机数,要求随机数不能重复,并把最终的随机数输出到控制台
public class Test12 {
public static void main(String[] args) {
Random rand = new Random();
HashSet<Integer> hs = new HashSet<Integer>();
while(hs.size()<10){
hs.add(rand.nextInt(20)+1);
}
for(Integer h : hs){
System.out.print(h+" ");
}
}
}
例题2:去除字符串中的重复字符
public class Test13 {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
System.out.println("请输入一个字符串:");
String str = scanner.nextLine();
char[] ch = str.toCharArray();
HashSet<Character> chSet = new HashSet<Character>();
for(int i=0;i<ch.length;i++){
chSet.add(ch[i]);
}
for(char chs : chSet){
System.out.print(chs);
}
}
}
例题3:去除List集合中的重复元素
public class Test14 {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("a");
list.add("e");
list.add("f");
list.add("b");
list.add("a");
list.add("b");
list.add("c");
list.add("d");
list.add("a");
list.add("b");
list.add("c");
list.add("d");
list.add("e");
LinkedHashSet<String> lhs = new LinkedHashSet<String>(list);
list.clear();
list.addAll(lhs);
for (String li:list) {
System.out.print(li+" ");//a e f b c d
}
}
}
TreeSet



- TreeSet集合是用来对对象元素进行排序的,同样他也可以保证元素的唯一
public class Test15 {
public static void main(String[] args) {
TreeSet<Integer> ts=new TreeSet<Integer>();
ts.add(2);
ts.add(5);
ts.add(9);
ts.add(1);
ts.add(3);
ts.add(2);
System.out.println(ts);//[1, 2, 3, 5, 9]
}
}
注意:存对象时需要让它继承comparable接口,并重写compareTo方法
- 当compareTo方法返回0的时候,集合中只有一个元素
- 当compareTo方法返回正数的时候,集合会怎么存就怎么取
- 当compareTo方法返回负数的时候,集合会倒序存取
public class Test16 {
public static void main(String[] args) {
TreeSet<Person> ts = new TreeSet<Person>();
ts.add(new Person(1,"zjj","34"));
ts.add(new Person(2,"jack","22"));
ts.add(new Person(3,"zhh","25"));
ts.add(new Person(4,"zj","34"));
ts.add(new Person(4,"zj","34"));
System.out.println(ts);//返回0//[Person{id = 1, name = zjj, age = 34}]
System.out.println(ts);//返回1
//[Person{id = 1, name = zjj, age = 34}, Person{id = 2, name = jack, age = 22}, Person{id = 3, name = zhh, age = 25}, Person{id = 4, name = zj, age = 34}, Person{id = 4, name = zj, age = 34}]
System.out.println(ts);//返回-1
// [Person{id = 4, name = zj, age = 34}, Person{id = 4, name = zj, age = 34}, Person{id = 3, name = zhh, age = 25}, Person{id = 2, name = jack, age = 22}, Person{id = 1, name = zjj, age = 34}]
}
}
原理:
二叉树:两个叉
小的存储在左边(负数),大的存储在右边(正数),相等就不存(0)
在TreeSet集合中如何存储元素取决于compareTo方法的返回值
重写compareTo方法示例:
// @Override
// public int compareTo(Person o) {
// int num=this.age.compareTo(o.getAge());//年龄是比较的主要条件
// return num == 0 ? this.name.compareTo(o.getName()):num;//姓名是比较的次要条件
// }
// @Override
// public int compareTo(Person o) {
// int num=this.id-o.getId();
// //id是比较的主要条件
// return num == 0 ? this.age.compareTo(o.getAge()):num;
// //年龄是比较的次要条件
// }
@Override
public int compareTo(Person o) {
int oid=this.id-o.getId();
//id是比较的主要条件
int num=oid==0?this.name.compareTo(o.getName()) : oid;
//姓名是比较的第二条件
return num == 0 ? this.age.compareTo(o.getAge()):num;
//年龄是比较的次要条件
}
// @Override
// public int compareTo(Person o) {
// return -1;
// }
怎样决定排序方式:
1、自然顺序(Comparable)
- TreeSet类的add方法中会把存入的对象提升为Comparable类型
- 调用compareTo方法和集合中的对象比较
- 根据compareTo方法放回的结果进行存储
2、比较器顺序(Comparator)
- 创建TreeSet的时候可以制定一个比较器(Comparator)
- 如果传入了Comparator的子类对象,那么TreeSet就会按照比较器的顺序进行排序
- add方法内部会自动调用Comparator接口中的compare方法进行排序
3、两种方式的区别
- TreeSet构造函数什么都不传,默认按照类中的Comparable的顺序(没有就报错)
- TreeSet如果传入Comparator,就优先按照Comparator
public class Test18 {
public static void main(String[] args) {
// TreeSet ts=new TreeSet(new CompareByParam());
TreeSet<Person> ts=new TreeSet<Person>(new Comparator<Person>() {
@Override
public int compare(Person o1, Person o2) {
int oid=o1.getAge().compareTo(o2.getAge());
//年龄是比较的主要条件
int num=oid==0?o1.getName().compareTo(o2.getName()) : oid;
//姓名是比较的第二条件
return num == 0 ? o1.getId().compareTo(o2.getId()):num;
//id是比较的次要条件
}
});
ts.add(new Person(1, "张飞", "28"));
ts.add(new Person(3, "李白", "22"));
ts.add(new Person(5, "后羿", "28"));
ts.add(new Person(2, "百里守约", "40"));
System.out.println(ts);
}
//不写内部类想多次使用可以在这边写一个
// static class CompareByParam implements Comparator{
//
// @Override
// public int compare(Person o1, Person o2) {
// int oid=o1.getAge().compareTo(o2.getAge());
// //年龄是比较的主要条件
// int num=oid==0?o1.getName().compareTo(o2.getName()) : oid;
// //姓名是比较的第二条件
// return num == 0 ? o1.getId().compareTo(o2.getId()):num;
// //id是比较的次要条件
// }
// }
}
例题1:在一个集合中存储了无序并且重复的字符串,定义一个方法,让其有序(字典顺序),而且不能去除重复
public class Test19 {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("a");
list.add("d");
list.add("d");
list.add("b");
list.add("b");
list.add("c");
list.add("c");
list.add("c");
list.add("b");
list.add("b");
list.add("a");
sort(list);
System.out.println(list);//[a, a, b, b, b, b, c, c, c, d, d]
}
public static void sort(List<String> list){
TreeSet<String> ts=new TreeSet<String>(new Comparator<String>(){
@Override
public int compare(String o1, String o2) {
int num=o1.compareTo(o2);
return num==0?1:num;
}
});
ts.addAll(list);
list.clear();
list.addAll(ts);
}
}
Map接口

Map接口和Collection接口的不同
- Map接口是双列的,Collection接口是单列的
- Map的键唯一,Collection的子体系Set是唯一的
- Map集合的数据结构只针对键有效,跟值无关,Collection集合的数据结构是针对元素有效
- 双列集合没有迭代器Iterator

put方法

public class Test20 {
public static void main(String[] args) {
Map<String,Integer> map = new HashMap<String,Integer>();
Integer i1=map.put("zhh",1);
Integer i2=map.put("zh",3);
Integer i3=map.put("zjh",5);
Integer i4=map.put("zhj",7);
Integer i5=map.put("zzj",9);
Integer i6=map.put("zhh",3);
System.out.println(map);
System.out.println(i1);
System.out.println(i2);
System.out.println(i3);
System.out.println(i4);
System.out.println(i5);
System.out.println(i6);
//结果
//{zjh=5, zhh=3, zzj=9, zhj=7, zh=3}
//null
//null
//null
//null
//null
//1
}
}
remove方法
public class Test21 {
public static void main(String[] args) {
Map<String,Integer> map = new HashMap<>();
Integer i1=map.put("zhh",1);
Integer i2=map.put("zh",3);
Integer i3=map.put("zjh",5);
Integer i4=map.put("zhj",7);
Integer i5=map.put("zzj",9);
Integer i6=map.put("zhh",3);
Integer ii1=map.remove("zhj");
Integer ii2=map.remove("zjjj");
System.out.println(map);
System.out.println(ii1);
System.out.println(ii2);
//结果
// {zjh=5, zhh=3, zzj=9, zh=3}
// 7
// null
}
}
containsKey和containsValue和isEmpty方法
public class Test22 {
public static void main(String[] args) {
Map<String,Integer> map = new HashMap<>();
Integer i1=map.put("zhh",1);
Integer i2=map.put("zh",3);
Integer i3=map.put("zjh",5);
Boolean b1=map.containsKey("zhh");
Boolean b2=map.containsKey("zhhh");
Boolean b3=map.containsValue(1);
Boolean b4=map.containsValue(6);
Boolean b5=map.isEmpty();
System.out.println(map);
System.out.println(b1);
System.out.println(b2);
System.out.println(b3);
System.out.println(b4);
System.out.println(b5);
//结果
// {zjh=5, zhh=1, zh=3}
//true
//false
//true
//false
//false
}
}
map.keySet()和map.get(key)方法
public class Test23 {
public static void main(String[] args) {
Map<String,Integer> map = new HashMap<>();
Integer i1=map.put("zhh",1);
Integer i2=map.put("zh",3);
Integer i3=map.put("zjh",5);
Integer value1=map.get("zhh");//根据键获取值
Integer value2=map.get("zhhh");//根据键获取值
System.out.println(map);
System.out.println(value1);//1
System.out.println(value2);//null
Set<String> keySet = map.keySet();//获取所有键的集合
Iterator<String> it = keySet.iterator();//获取迭代器
while(it.hasNext()) {
String key = it.next();
Integer value = map.get(key);//根据key获取值
System.out.println(key + "=" + value);
// zjh=5
// zhh=1
// zh=3
}
//增强for循环简化
for(String key : map.keySet()) {
System.out.println(key + "=" + map.get(key));
}
}
}
Map.entrySet()

public class Test24 {
public static void main(String[] args) {
Map<String,Integer> map = new HashMap<>();
Integer i1=map.put("zhh",1);
Integer i2=map.put("zh",3);
Integer i3=map.put("zjh",5);
System.out.println(map);
Set<Map.Entry<String,Integer>> EntrySet = map.entrySet();
for(Map.Entry<String,Integer> entry : EntrySet){
System.out.println(entry.getKey()+"="+entry.getValue());
}
}
}
LinkedHashMap
底层是链表实现的,可以保证怎么存就怎么取
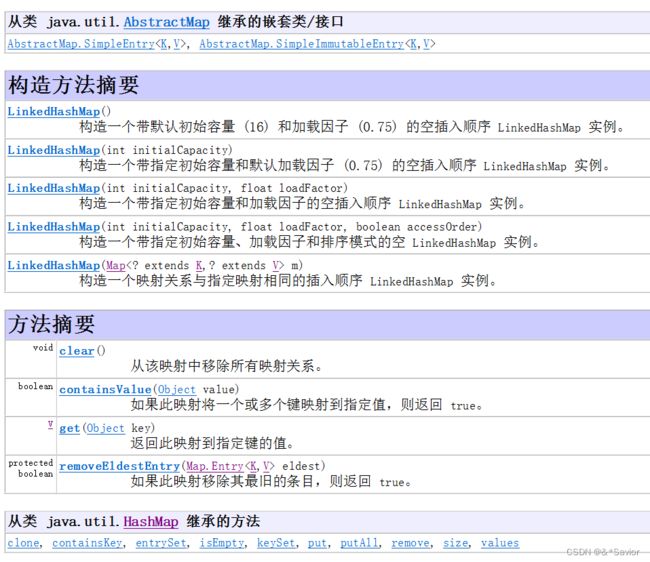
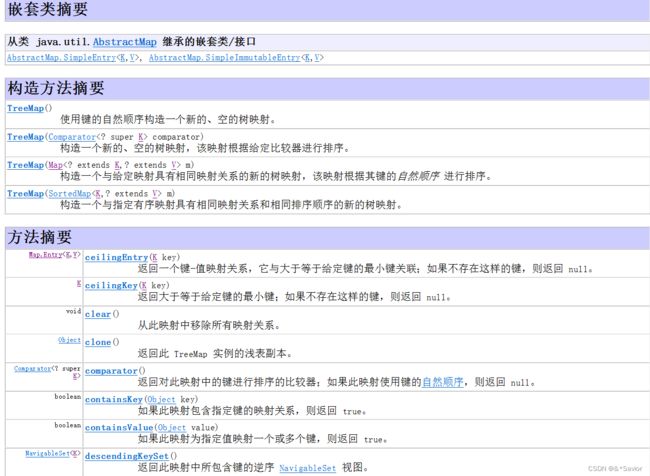
TreeMap



public class Test25 {
public static void main(String[] args) {
TreeMap<Person,String> treeMap=new TreeMap<Person,String>(new Comparator<Person>() {
@Override
public int compare(Person o1, Person o2) {
int oid=o1.getAge().compareTo(o2.getAge());
//年龄是比较的主要条件
int num=oid==0?o1.getName().compareTo(o2.getName()) : oid;
//姓名是比较的第二条件
return num == 0 ? o1.getId().compareTo(o2.getId()):num;
//id是比较的次要条件
}
});
treeMap.put(new Person(1, "zhh","33"), "江苏");
treeMap.put(new Person(3, "zjj","58"), "南京");
treeMap.put(new Person(6, "abc","44"), "江苏");
treeMap.put(new Person(3, "jig","33"), "北京");
System.out.println(treeMap);
}
例题1:统计字符串中每个字符出现的次数
public class Test26 {
public static void main(String[] args) {
String ss="abcdefgaaaaahhhhgggccc";
char[] c=ss.toCharArray();
HashMap<Character,Integer> hashMap=new HashMap<Character,Integer>();
// for(int i=0;i
// if(hashMap.containsKey(c[i])){
// hashMap.put(c[i],hashMap.get(c[i])+1);
// }else{
// hashMap.put(c[i],1);
// }
// }
//简化写法
for(char cx :c){
hashMap.put(cx,!hashMap.containsKey(cx)?1:hashMap.get(cx)+1);
}
System.out.println(hashMap);
}
}
HashTable


HashMap和HashTable区别:
共同点:
- 底层都是哈希算法,都是双列集合
区别:
- HashMap是线程不安全的,效率高,JDK1.2版本
- HashTable是线程安全的,效率低,JDK1.0版本
- HashMap可以存储null键和null值
- HashTable不可以存储null键和null值
public class Test27 {
public static void main(String[] args) {
HashMap<String,Integer> hashMap = new HashMap<String,Integer>();
hashMap.put("a",null);
hashMap.put("c",null);
hashMap.put("b",null);
hashMap.put("null",null);
hashMap.put("null",1);
System.out.println(hashMap);//{a=null, b=null, c=null, null=1}
}
}
HashTable键和值都不能为null,有任何一个就会报java.lang.NullPointerException
Collections工具类


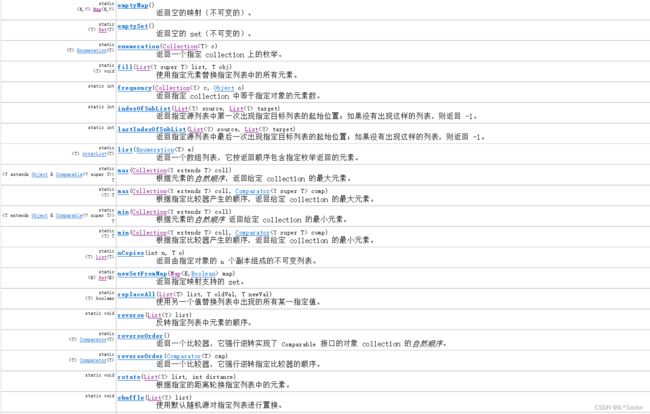
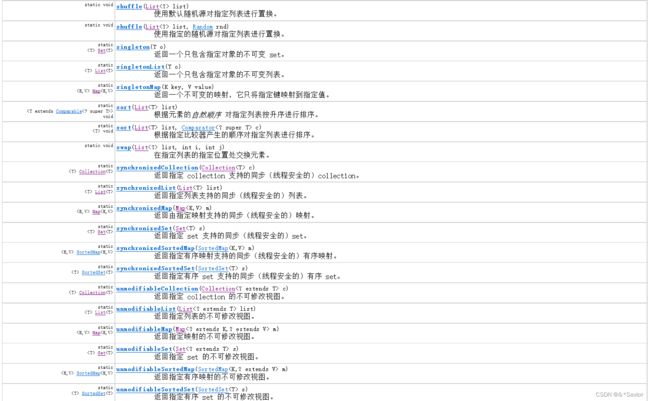
常用方法示例
sort
public class Test29 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<String>();
list.add("c");
list.add("a");
list.add("a");
list.add("d");
list.add("b");
System.out.println("list: " + list);//list: [c, a, a, d, b]
Collections.sort(list);
System.out.println("list排序后: " + list);//list排序后: [a, a, b, c, d]
}
}
binarySearch
public class Test30 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<String>();
list.add("a");
list.add("c");
list.add("d");
list.add("g");
list.add("h");
System.out.println(Collections.binarySearch(list,"c"));//1
System.out.println(Collections.binarySearch(list,"b"));//-2//没有返回(-插入点-1)
}
}
max、reverse、shuffle
public class Test31 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<String>();
list.add("a");
list.add("c");
list.add("d");
list.add("h");
list.add("g");
System.out.println("反转前:"+list);//反转前:[a, c, d, h, g]
System.out.println(Collections.max(list));//h
Collections.reverse(list);
System.out.println("反转后:"+list);//反转后:[g, h, d, c, a]
Collections.shuffle(list);
System.out.println("随机置换后:"+list);//随机置换后:[d, a, g, c, h]
Collections.shuffle(list);
System.out.println("随机置换后:"+list);//随机置换后:[d, g, a, c, h]
Collections.shuffle(list);
System.out.println("随机置换后:"+list);//随机置换后:[d, g, a, h, c]
}
}