python基础学习
说明:下面所写为学习爬虫所需要的python基础,并不是整个的,所以有些东西并不全面。
注释
单行注释
#单行注释
多行注释
'''
多行注释
'''
变量以及数据类型
变量
- 定义:变量名=变量值 注意:变量名不需要用引号包裹
name ='zhh'
print(name)
数据类型
- Numbers(数字){
- int 有符号整型
- long 长整型(也可以代表八进制和十六进制)
- float 浮点型
- complex 复数 }
- 布尔类型{
- True
- False }
- String 字符串
- List 列表
- Tuple 元组
- Dictionary 字典
注意 在python中,变量没有类型,数据才有类型。只要给一个变量赋值,系统会自动辨别
查看数据类型
- type(变量名)
name ='zhh'
num=122
#标识符和关键字
标识符
- 计算机编程语言中,标识符是用户编程时使用的名字,用于给变量、常量、函数、语句块等命名,以建立起名称与使用之间的关系。
-
- 标识符由字母、下划线和数字组成,且数字不能开头。
- 严格区分大小写。
- 不能使用关键字。
命名规范
- 驼峰命名法,又分为大驼峰命名法和小驼峰命名法。
- 小驼峰式命名法(lower camel case): 第一个单词以小写字母开始;第二个单词的首字母大写, 例如:myName、aDog
- 大驼峰式命名法(upper camel case): 每一个单字的首字母都采用大写字母,例如: FirstName、LastName.
- 还有一种命名法是用下划线“_”来连接所有的单词,比如send_buf.
Python的命令规则遵循PEP8标准
关键字
- 一些具有特殊功能的标识符,这就是所谓的关键字。
False None True and as assert break class
continue def del elif else except finally for
from global if import in is lambda nonlocal
not or pass raise return try while with
yield
类型转换
| 函数 | 说明 |
|---|---|
| int(x) | int(x) 将x转换为一个整数 |
| float(x) | 将x转换为一个浮点数 |
| str(x) | 将对象 x 转换为字符串 |
| bool(x) | 将对象x转换成为布尔值 |
运算符
算数运算符
| 运算符 | 描述 |
|---|---|
| + | 加 |
| - | 减 |
| * | 乘 |
| / | 除 |
| // | 取整除 |
| % | 取余 |
| ** | 指数 |
| () | 小括号 |
- 注意:混合运算时,优先级顺序为: ** 高于 * / % // 高于 + - ,为了避免歧义,建议使用 () 来处理运算符优先级。 并且,不同类型的数字在进行混合运算时,整数将会转换成浮点数进行运算。
运算符在字符串中的使用
- 如果是两个字符串做加法运算,会直接把这两个字符串拼接成一个字符串。
- 如果是数字和字符串做加法运算,会直接报错。
- 如果是数字和字符串做乘法运算,会将这个字符串重复多次。
print('2'+'454') #2454
# print("str" +5) #TypeError: can only concatenate str (not "int") to str
print('sad' + 'djd') #saddjd
print("abc"*4) #abcabcabcabc
print(4 * 'r') #rrrr
赋值运算符
| 运算符 | 描述 |
|---|---|
| = | 赋值运算符 |
num =10
print(num) #10
# 同时为多个变量赋值(使用等号连接)
a=b=4
print(a,b)#4 4
# 多个变量赋值(使用逗号分隔)
num1,f1,str1 = 100,33,'ttt'
print(num1,f1,str1) #100 33 ttt
复合赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c **= a 等效于 c = c ** a |
比较运算符
以下假设变量a为10,变量b为20:
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 等于:比较对象是否相等 | (a == b) 返回False |
| != | 不等于:比较两个对象是否不相等 | (a != b) 返回true |
| > | 大于:返回x是否大于y | (a > b) 返回False |
| >= | 大于等于:返回x是否大于等于y | (a >= b) 返回False |
| < | 小于:返回x是否小于y。所有比较运算符返回1表示真,返回0表示假。这分别与特殊的变量True和False等价 | (a < b) 返回true |
| <= | 小于等于:返回x是否小于等于y | (a <= b) 返回true |
逻辑运算符
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x andy | 只要有一个运算数是False,结果就是False;只有所有的运算数都为True时,结果才是True做取值运算时,取第一个为False的值,如果所有的值都为True,取最后一个值 | True and True and False–>结果为False True and True and True–>结果为True |
| or | x or y | 只要有一个运算数是True,结果就是True.只有所有的运算数都为False时,结果才是False做取值运算时,取第一个为True的值,如果所有的值都为False,取最后一个值 | False or False or True–>结果为True False or False or False–>结果为False |
| not | not x | 布尔"非" - 如果 x 为 True,返回 False 。如果 x 为False,它返回 True。 | not True --> False |
- 注意:and之前结果为false,后面不执行 or 之前结果未true,后面不执行
输入和输出
输出
print("hello")
a=20
#格式化输出
print("hello %d hello" % a )
输入
password = input("请输入密码:")
print("密码是:%s" %password)
注意:
- input()的小括号中放入的是提示信息,用来在获取数据之前给用户的一个简单提示
- input()在从键盘获取了数据以后,会存放到等号右边的变量中
- input()会把用户输入的任何值都作为字符串来对待
流程控制语句
if判断语句
if 要判断的条件:
条件成立时,要做的事情
注意:代码的缩进为一个tab键,或者4个空格
if else
if 条件:
满足条件时的操作
else:
不满足条件时的操作
elif
if xxx1:
事情1
elif xxx2:
事情2
elif xxx3:
事情3
num= 30;
if num>10:
num=20;
elif num <10 :
num=30
else:
num=40
print(num)
for
- 在Python中 for循环可以遍历任何序列的项目,如一个列表或者一个字符串等。
for 临时变量 in 列表或者字符串等可迭代对象:
循环满足条件时执行的代码
for i in 'hello':
print(i)
# h
# e
# l
# l
# o
range
- range 可以生成数字供 for 循环遍历,它可以传递三个参数,分别表示 起始、结束和步长。
count =0
for i in range(0,101,1):
count +=i
print(count) #5050
数据类型高级
字符串高级
字符串的常见操作
| 方法 | 作用 |
|---|---|
| 获取长度:len | len函数可以获取字符串的长度 |
| 查找内容:find | 查找指定内容在字符串中是否存在,如果存在就返回该内容在字符串中第一次出现的开始位置索引值,如果不存在,则返回-1. |
| 判断:startswith,endswith | 判断字符串是不是以谁谁谁开头/结尾 |
| 计算出现次数:count | 返回 str在start和end之间 在 mystr里面出现的次数 |
| 替换内容:replace | 替换字符串中指定的内容,如果指定次数count,则替换不会超过count次。 |
| 切割字符串:split | 通过参数的内容切割字符串 |
| 修改大小写:upper,lower | 将字符串中的大小写互换 |
| 空格处理:strip | 去空格 |
| 字符串拼接:join | 字符串拼接 |
列表高级
列表的增删改查
添加元素
- append 在末尾添加元素
- insert :insert(index, object) 在指定位置index前插入元素object
- extend 合并两个列表:通过extend可以将另一个列表中的元素逐一添加到列表中
A=['zhangsan','lisi','wangwu']
print("添加前A=%s" %A)
A.append("zhaoliu")
print("第一次添加后A=%s"%A)
A.insert(2,'AAA')
print("第二次添加后A=%s" %A)
a=[1,2,3,4,5]
b=[6,7,8,9,10]
a.extend(b)
print(a)
#添加前A=['zhangsan', 'lisi', 'wangwu']
#第一次添加后A=['zhangsan', 'lisi', 'wangwu', 'zhaoliu']
#第二次添加后A=['zhangsan', 'lisi', 'AAA', 'wangwu', 'zhaoliu']
#[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
修改元素
通过指定下标来访问列表元素,因此修改元素的时候,为指定的列表下标赋值即可。
B=[2,4,5,67,8,89]
B[1]=100
print(B)#[2, 100, 5, 67, 8, 89]
查找元素
- 所谓的查找,就是看看指定的元素是否存在
- in 和 not in
A=[1,'2',3,4,5]
i=-1
while i!='1':
i=input('请输入i:')
if i in A:
print('找到了')
else:
print('没找到')
补充注意:输入的值全是字符串,如果列表中的数字没有加引号,和输入的数字是不相等的
删除元素
- del:根据下标进行删除
- pop:删除最后一个元素
- remove:根据元素的值进行删除(不存在报错)
A=['a','b','c','d']
del A[2]
print('第一次删除后A:%s'%A)
A.pop()
print('第二次删除后A:%s'%A)
A.remove('a')
print('第三次删除后A:%s'%A)
# 第一次删除后A:['a', 'b', 'd']
# 第二次删除后A:['a', 'b']
# 第三次删除后A:['b']
元组高级
- Python的元组与列表类似,不同之处在于元组的元素不能修改。元组使用小括号,列表使用方括号。
- python中不允许修改元组的数据,包括不能删除其中的元素。
- 定义只有一个元素的元组,需要在唯一的元素后写一个逗号
t=('a','y',45)
print(t[2]) #45
t=('a',)
print(t) #('a',)
t=('a')
print(t) #a
切片
- 切片是指对操作的对象截取其中一部分的操作。字符串、列表、元组都支持切片操作
- 切片的语法:[起始:结束:步长],也可以简化使用 [起始:结束]
- 注意:选取的区间从"起始"位开始,到"结束"位的前一位结束(不包含结束位本身),步长表示选取间隔。
# 索引是通过下标取某一个元素
# 切片是通过下标去某一段元素
s = 'Hello World!'
print(s)
print(s[4]) # o 字符串里的第4个元素
print(s[3:7]) # lo W 包含下标 3,不含下标 7
print(s[1:]) # ello World! 从下标为1开始,取出 后面所有的元素(没有结束位)
print(s[:4]) # Hell 从起始位置开始,取到 下标为4的前一个元素(不包括结束位本身)
print(s[1:5:2]) # el 从下标为1开始,取到下标为5的前一个元素,步长为2(不包括结束位本身)
字典高级
查看元素
除了使用key查找数据,还可以使用get来获取数据
stu={'name':'zhangsan','age':34}
print(stu['age']) #34
print(stu['aaa']) #KeyError: 'aaa' 获取不存在的key,会发生异常
print(stu.get('sex')) #None 获取不存在的key,获取到空的内容,不会出现异常
print(stu.get('sex','男')) #男 获取不存在的key, 可以提供一个默认值。
修改元素
字典的每个元素中的数据是可以修改的,只要通过key找到,即可修改
info = {'name':'班长', 'id':100}
print('修改之前的字典为 %s' % info)
info['id'] = 200 # 为已存在的键赋值就是修改
print('修改之后的字典为 %s' % info)
# 修改之前的字典为 {'name': '班长', 'id': 100}
# 修改之后的字典为 {'name': '班长', 'id': 200}
添加元素
如果在使用 变量名[‘键’] = 数据 时,这个“键”在字典中,不存在,那么就会新增这个元素
info = {'name':'班长'}
print('添加之前的字典为:%s' % info)
info['id'] = 100 # 为不存在的键赋值就是添加元素
print('添加之后的字典为:%s' % info)
# 添加之前的字典为:{'name': '班长'}
# 添加之后的字典为:{'name': '班长', 'id': 100}
删除元素
- del:删除指定的元素、删除整个字典
info = {'name':'班长', 'id':100}
print('删除前,%s' % info)
del info['name'] # del 可以通过键删除字典里的指定元素
print('删除后,%s' % info)
# 删除前,{'name': '班长', 'id': 100}
# 删除后,{'id': 100}
info = {'name':'monitor', 'id':100}
print('删除前,%s'%info)
del info # del 也可以直接删除变量
print('删除后,%s'%info)
# 删除前,{'name': 'monitor', 'id': 100}
#NameError: name 'info' is not defined
- clear():删除整个字典
info = {'name':'monitor', 'id':100}
print('清空前,%s'%info)
info.clear()
print('清空后,%s'%info)
# 清空前,{'name': 'monitor', 'id': 100}
# 清空后,{}
字典的遍历
遍历字典的key(键)
dict={'name':'zhangsan','age':34}
for key in dict.keys():
print(key)
# name
# age
遍历字典的value(值)
dict={'name':'zhangsan','age':34}
for value in dict.values():
print(value)
#zhangsan
#34
遍历字典的项(元素)
dict={'name':'zhangsan','age':34}
for item in dict.items():
print(item)
#('name', 'zhangsan')
#('age', 34)
遍历字典的key-value(键值对)
dict={'name':'zhangsan','age':34}
for key ,value in dict.items():
print('key=%s,value=%s'%(key,value))
# key=name,value=zhangsan
# key=age,value=34
函数
定义函数
def 函数名():
代码
调用函数
通过 函数名() 即可完成调用
函数参数
def 函数名(形参1,形参2,...):
代码
函数名(实参1,实参2,...)
函数返回值
想要在函数中把结果返回给调用者,需要在函数中使用return
函数代码示例
def funcx(a,b):
return a+b
result=funcx(3,4)
print(result) #7
局部变量
- 就是在函数内部定义的变量
- 其作用范围是这个函数内部,即只能在这个函数中使用,在函数的外部是不能使用的
全局变量
- 如果一个变量,既能在一个函数中使用,也能在其他的函数中使用,这样的变量就是全局变量
- 在函数外边定义的变量叫做 全局变量
- 全局变量能够在所有的函数中进行访问
文件
文件的打开与关闭
打开文件/创建文件
- 在python,使用open函数,可以打开一个已经存在的文件,或者创建一个新文件
- open(文件路径,访问模式)
f=open('test.txt','w')
文件路径
- 绝对路径:指的是绝对位置,完整地描述了目标的所在地,所有目录层级关系是一目了然的
- 相对路径:是从当前文件所在的文件夹开始的路径。
- test.txt ,是在当前文件夹查找 test.txt 文件
- ./test.txt ,也是在当前文件夹里查找 test.txt 文件, ./ 表示的是当前文件夹。
- …/test.txt ,从当前文件夹的上一级文件夹里查找 test.txt 文件。 …/ 表示的是上一级文件夹
| 访问模式 | 说明 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。如果文件不存在,则报错。这是默认模式。 |
| w | 打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| ab+ | 以二进制格式打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
关闭文件
f=open('test.txt','w')
#关闭这个文件
f.close()
文件的读写
写数据(write)
- 使用write()可以完成向文件写入数据
f = open('test.txt', 'a')
f.write('hello world\n' * 5)
f.close()
读数据(read)
- 使用read(num)可以从文件中读取数据,num表示要从文件中读取的数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中所有的数据
f = open('test.txt', 'r')
content = f.read(5) # 最多读取5个数据
print(content)
print("‐" * 30) # 分割线,用来测试
content = f.read() # 从上次读取的位置继续读取剩下的所有的数据
print(content)
f.close()
读数据(readline)
readline只用来读取一行数据。
f = open('test.txt', 'r')
content = f.readline()
print("1:%s" % content)
content = f.readline()
print("2:%s" % content)
f.close()
读数据(readlines)
readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行为列表的一个元素。
f = open('test.txt', 'r')
content = f.readlines()
print(type(content)) #序列化和反序列化
- 通过文件操作,我们可以将字符串写入到一个本地文件。但是,如果是一个对象(例如列表、字典、元组等),就无法直接写入到一个文件里,需要对这个对象进行序列化,然后才能写入到文件里。
- 设计一套协议,按照某种规则,把内存中的数据转换为字节序列,保存到文件,这就是序列化,反之,从文件的字节序列恢复到内存中,就是反序列化。
- 对象—>字节序列 === 序列化
- 字节序列–>对象 ===反序列化
- Python中提供了JSON这个模块用来实现数据的序列化和反序列化
JSON模块
- JSON(JavaScriptObjectNotation, JS对象简谱)是一种轻量级的数据交换标准。JSON的本质是字符串。
使用JSON实现序列化
- JSON提供了dump和dumps方法,将一个对象进行序列化。
- dumps方法的作用是把对象转换成为字符串,它本身不具备将数据写入到文件的功能。
import json
file = open('names.txt', 'w')
names = ['zhangsan', 'lisi', 'wangwu', 'jerry', 'henry', 'merry', 'chris']
#file.write(names) #出错,不能直接将列表写入到文件里
# 可以调用 json的dumps方法,传入一个对象参数
result = json.dumps(names)
# dumps 方法得到的结果是一个字符串
print(type(result)) # - dump方法可以在将对象转换成为字符串的同时,指定一个文件对象,把转换后的字符串写入到这个文件里。
import json
file = open('names.txt', 'w')
names = ['zhangsan', 'lisi', 'wangwu', 'jerry', 'henry', 'merry', 'chris']
# dump方法可以接收一个文件参数,在将对象转换成为字符串的同时写入到文件里
json.dump(names, file)
file.close()
使用JSON实现反序列化
- 使用loads和load方法,可以将一个JSON字符串反序列化成为一个Python对象。
- loads方法需要一个字符串参数,用来将一个字符串加载成为Python对象。
import json
# 调用loads方法,传入一个字符串,可以将这个字符串加载成为Python对象
result = json.loads('["zhangsan", "lisi", "wangwu", "jerry", "henry", "merry", "chris"]')
print(type(result)) # - load方法可以传入一个文件对象,用来将一个文件对象里的数据加载成为Python对象。
import json
# 以可读方式打开一个文件
file = open('names.txt', 'r')
# 调用load方法,将文件里的内容加载成为一个Python对象
result = json.load(file)
print(result)
file.close()
异常
- 程序在运行过程中,由于我们的编码不规范,或者其他原因一些客观原因,导致我们的程序无法继续运行,此时,程序就会出现异常。如果我们不对异常进行处理,程序可能会由于异常直接中断掉。为了保证程序的健壮性,我们在程序设计里提出了异常处理这个概念。
读取文件异常
在读取一个文件时,如果这个文件不存在,则会报出 FileNotFoundError 错误。
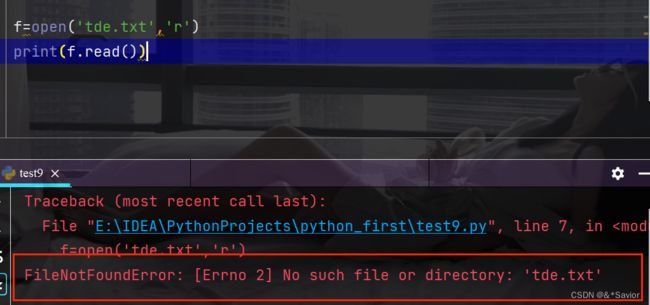
try…except语句
try…except语句可以对代码运行过程中可能出现的异常进行处理。 语法结构:
try:
可能会出现异常的代码块
except 异常的类型:
出现异常以后的处理语句
try:
f = open('txst.txt', 'r')
print(f.read())
except FileNotFoundError:
print('文件没有找到,请检查文件名称是否正确')
