【Mysql】 表的增删查改

文章目录
- 【Mysql】表的增删查改
-
-
- Create --创建数据
- Retireve -- 读取数据
-
- select 列
- where条件
- order by -- 结果排序
- limit -- 分页
- Update -- 更新数据
- Delete -- 删除数据
-
- delete
- truncate -- 截断表
- 插入查询结果
- 聚合函数
- group by 子句
-
【Mysql】表的增删查改
CRUD : Create(创建), Retrieve(读取,检索),Update(更新),Delete(删除)
之前博客记录的都是对结构的操作之类的操作,而这篇博客记录的就是对表中的数据进行管理;
Create --创建数据
语法:
INSERT [INTO] table_name (所要插入表中的列字段) values (数据1), (数据2) ... ;
案例:
先创建一张学生表
CREATE TABLE students (
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
sn INT NOT NULL UNIQUE COMMENT '学号',
name VARCHAR(20) NOT NULL,
qq VARCHAR(20)
);
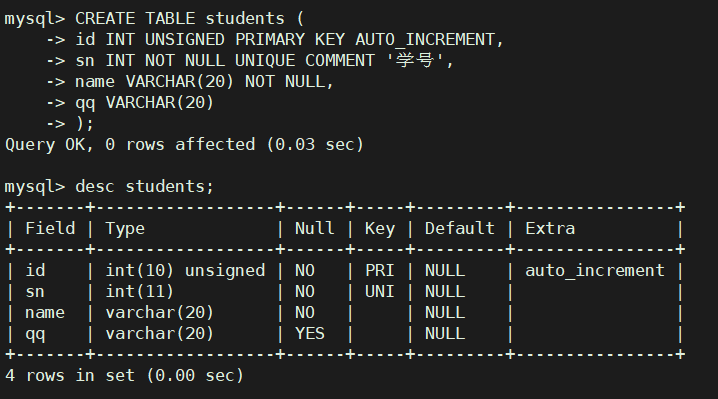
单行数据 + 全列插入
- 全列插入数据时,values_list 数量和顺序一定要和表定义时一致
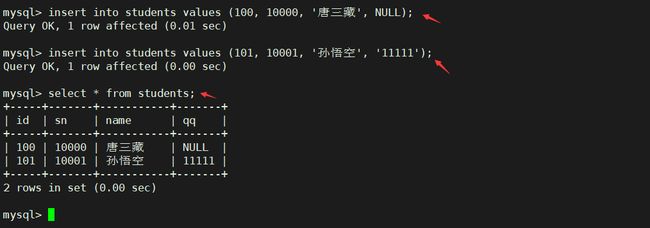
insert into students values (100, 10000, '唐三藏', NULL);
insert into students values (101, 10001, '孙悟空', '11111');
查看插入结果
多行数据 + 指定列插入
- 使用指定列插入时,需要指定要插入的列是什么,且values_list 要和指定列数量和顺序一致,否则插入失败
INSERT INTO students (id, sn, name) VALUES
(102, 20001, '曹孟德'),
(103, 20002, '孙仲谋');
查看插入结果

插入失败否则更新
例如:
下面俩条语句插入时,因为主键或者唯一键冲突的原因,会插入失败
insert into students (id,sn, name) values (100, 10010,'唐大师'); -- 主键id冲突
insert into students (sn,name) values (20001,'曹啊满'); -- 唯一键sn冲突
插入结果:

这时候就可以选择同步更新操作语法:
insert ... on duplicate key update 所需要更新的列在字段及数据,...;
例:
insert into students (id,sn, name) values (100, 10010,'唐大师') on duplicate key update sn = 10010, name = '唐大师' ;
执行结果:

其中还可以通过语句后面的执行结果判断我们是否插入成功
-- 0 row affected: 表中有冲突数据,但冲突数据的值和 update 的值相等
-- 1 row affected: 表中没有冲突数据,数据被插入
-- 2 row affected: 表中有冲突数据,并且数据已经被更新
即实际上上面这条语句的作用就是 当插入数据出现冲突,就将修该冲突数据;但我个人感觉比较’鸡肋‘
替换
作用: 将表中冲突的数据替换掉
说明:
-
– 主键 或者 唯一键 没有冲突,则直接插入;
– 主键 或者 唯一键 如果冲突,则删除后再插入
replace into students (sn,name) values (20001,'曹阿满');
-- 1 row affected: 表中没有冲突数据,数据被插入
-- 2 row affected: 表中有冲突数据,删除后重新插入
执行结果:
即因为唯一键发生冲突,将原有数据(102,'20001',曹孟德, NULL),删除之后再重新插入了

Retireve – 读取数据
注: 下面演示的查询都是使用的上面的学生测试表和下面的成绩表
语法:
[DISTINCT] {* | {column [, column] ...} -- 去重
[FROM table_name] -- 筛选
[WHERE ...] -- 筛选
[ORDER BY column [ASC | DESC], ...] -- 排序
LIMIT .. --分页
例:
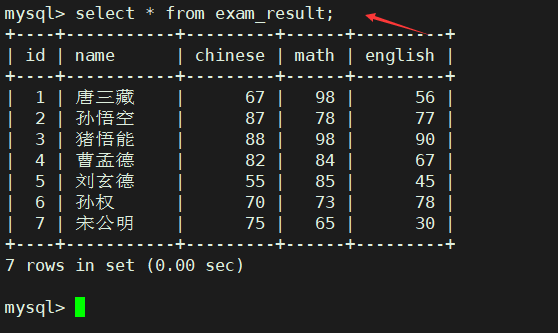
先创建表结构和插入数据:
CREATE TABLE exam_result (
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL COMMENT '同学姓名',
chinese float DEFAULT 0.0 COMMENT '语文成绩',
math float DEFAULT 0.0 COMMENT '数学成绩',
english float DEFAULT 0.0 COMMENT '英语成绩'
);
-- 插入测试数据
INSERT INTO exam_result (name, chinese, math, english) VALUES
('唐三藏', 67, 98, 56),
('孙悟空', 87, 78, 77),
('猪悟能', 88, 98, 90),
('曹孟德', 82, 84, 67),
('刘玄德', 55, 85, 45),
('孙权', 70, 73, 78),
('宋公明', 75, 65, 30);

select 列
全列查询
-
– 通常情况下不建议使用 * 进行全列查询
– 1. 查询的列越多,意味着需要传输的数据量越大;
– 2. 可能会影响到索引的使用。
注: * 表示通配
指定列查询
**注:**查询时指定列的顺序不需要安定义表的顺序来
- 查询字段不包含表达式
select id , name, english from exam_result;

- 查询列包含表达式,表达式不包含字段

- 查询列包含表达式,表达式包含一个字段

- 查询列包含表达式,表达式包含多个字段

- 为查询结果指定别名
语法:
select column [as] alias_name[...] from table_name;
- [] 表示可省略
alias_name:别名
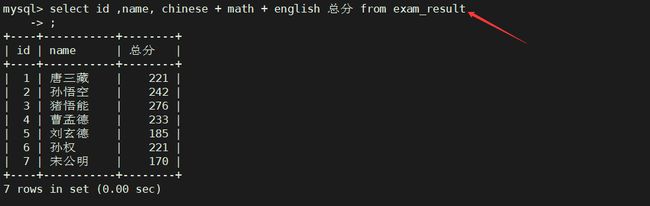
例:
select id ,name, chinese + math + english 总分 from exam_result
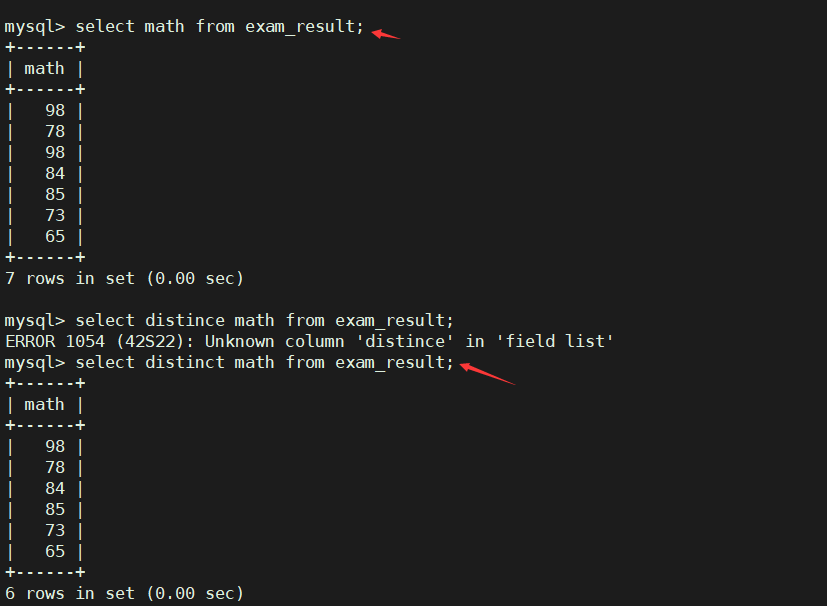
- 结果去重
语法:
select distinct math from exam_reuslt;
where条件
| 运算符 | 说明 |
|---|---|
| >, >=, <, <= | 大于,大于等于,小于,小于等于 |
| = | 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL |
| <=> | 等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1) |
| !=, <> | 不等于 |
| BETWEEN a0 AND a1 | 范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 TRUE(1) |
| IN (option, …) | 如果是 option 中的任意一个,返回 TRUE(1) |
| IS NULL | 是 NULL |
| IS NOT NULL | 不是 NULL |
| LIKE | 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符 |
逻辑运算符:
| 运算符 | 说明 |
|---|---|
| AND | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| OR | 任意一个条件为 TRUE(1) ,结果为 TRUE(1) |
| NOT | 条件为TRUE(1) ,结果为false(0); |
案例:
英语不及格的同学及英语成绩(<60) – < 使用
select name , english from exam_result where english < 60;
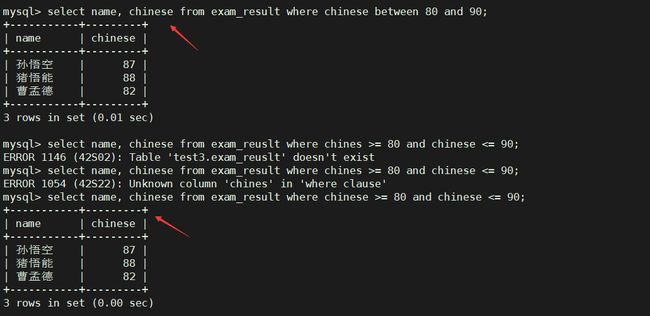
语文成绩在 [80, 90] 分的同学及语文成绩 – and,between 使用
select name, chinese from exam_result where chinese between 80 and 90; --between and
select name, chinese from exam_result where chinese >= 80 and chinese <= 90; -- and <= >=
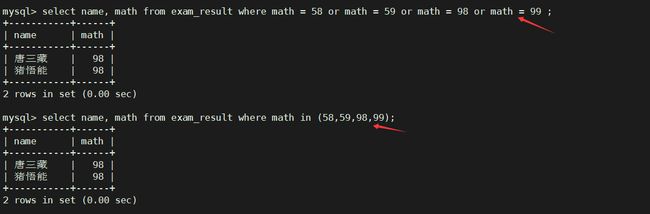
数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩 – in
-- 使用or 进行条件连接
select name, math from exam_result where math = 58 or math = 59 or math = 98 or math = 99 ;
-- 使用in 语句
select name, math from exam_result where math in (58,59,98,99);
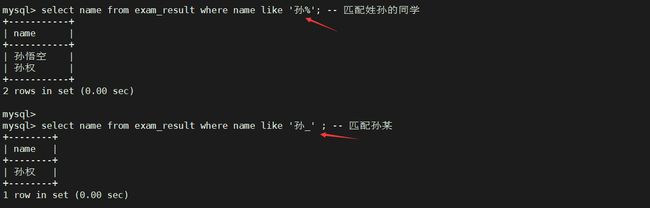
**姓孙的同学 及 孙某同学 ** – like
注:
%: 匹配任意多个(包括0个) 任意字符_: 匹配严格的一个任意字符
例: ‘孙%’ 匹配姓孙的同学 ‘孙_’ 匹配孙某 ’孙__'匹配孙某某
select name from exam_result where name like '孙%'; -- 匹配姓孙的同学
select name from exam_result where name like '孙_' ; -- 匹配孙某
语文成绩好于英语成绩的同学
select name, chinese, english from exam_result where chinese > english;
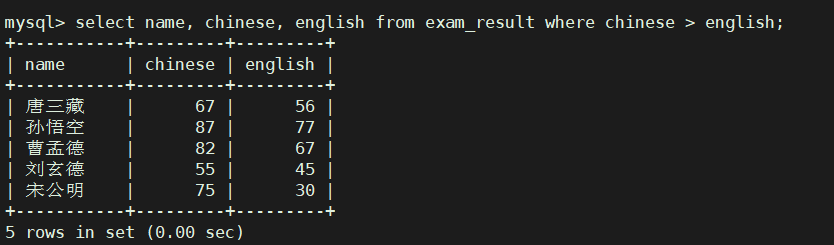
总分在 200 分以下的同学
select name, chinese + math + english 总分 from exam_result where chinese + math + english < 200;

语文成绩>80 并且不姓孙的同学
select name,chinese from exam_result where chinese > 80 and name not like '孙%' ;

孙某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80
select name, chinese ,math ,english ,chinese + math + english 总分 from exam_result where name like '孙_' or (chinese + math + english > 200 and chinese < math and english >80);

NULL 的查询
注:
- 在mysql中,
NULL就是代表空的意思什么都没有 ,和""(空串),0是不等价的 - 所以平时判断是否为空时建议使用 is null - -个人感觉逻辑更为清晰

order by – 结果排序
语法:
-- ASC 为升序(从小到大)
-- DESC 为降序(从大到小)
-- 默认为 ASC
SELECT ... FROM table_name [WHERE ...]
ORDER BY column [ASC|DESC], [...]
案例:
同学及数学成绩, 按数学成绩升序显示
select name, math from exam_result order by math;

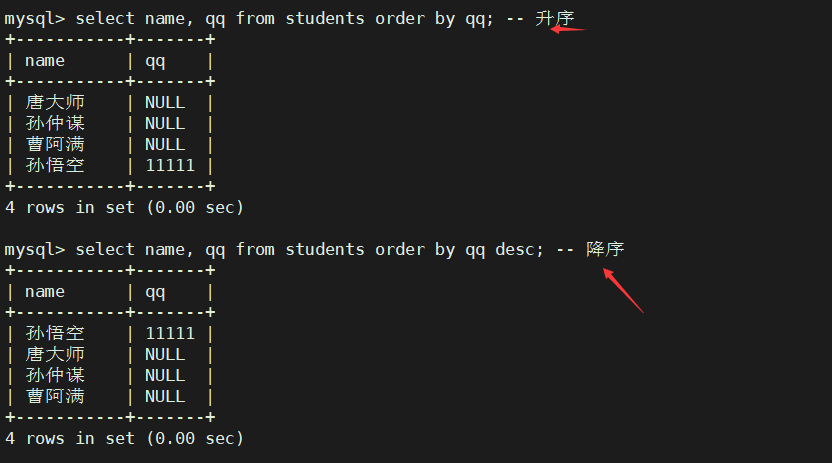
同学及qq号, 按qq号排序显示
select name, qq from students order by qq; -- 升序
select name, qq from students order by qq desc; -- 降序
说明:
- null 在mysql中默认为最小的 所以排升序时自然在最前面
查询同学各门成绩, 依次按 数学降序 , 英语升序,语文升序的方式显示
select name, math, english , chinese from exam_result order by math desc, english , chinese;
注: 虽然说排序时指定按多列排序,但优先级是不一样的,即优先通过math对数据排降序,如果数学相同的再通过english进行进行升序排序…

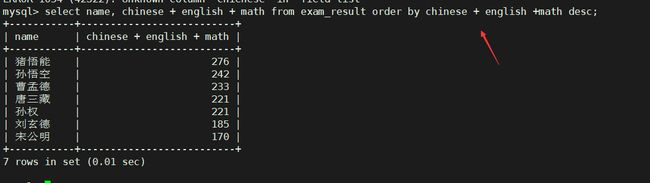
查询同学及总分,由高到低
select name, chinese + english + math from exam_result order by chinese + english +math desc;
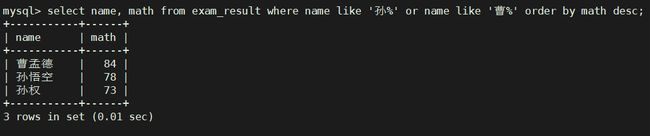
查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示
select name, math from exam_result where name like '孙%' or name like '曹%' order by math desc;
limit – 分页
语法:
-- 起始下标为 0
-- 从 0 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;
-- 从 s 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n;
-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;
注:对未知表进行查询时,最好加一条 LIMIT 1,避免因为表中数据过大,查询全表数据导致数据库卡死
按id进行分页,每页3条记录,分别显示第1,2,3页
-- 第1页
select id, name, math , english ,chinese from exam_result order by id limit 3 offset 0;
-- 第2页
select id, name, math , english , chinese from exam_result order by id limit 3 offset 3;
-- 第3页
select id, name, math , english , chinese from exam_result order by id limit 3 offset 6;
表中数据不足时, 依旧不会有什么影响

Update – 更新数据
语法:
UPDATE table_name SET column = expr [, column = expr ...]
[WHERE ...] [ORDER BY ...] [LIMIT ...]
案例:
将孙悟空同学的数学成绩变更为 80分
update exam_result set math = 80 where name = '孙悟空';

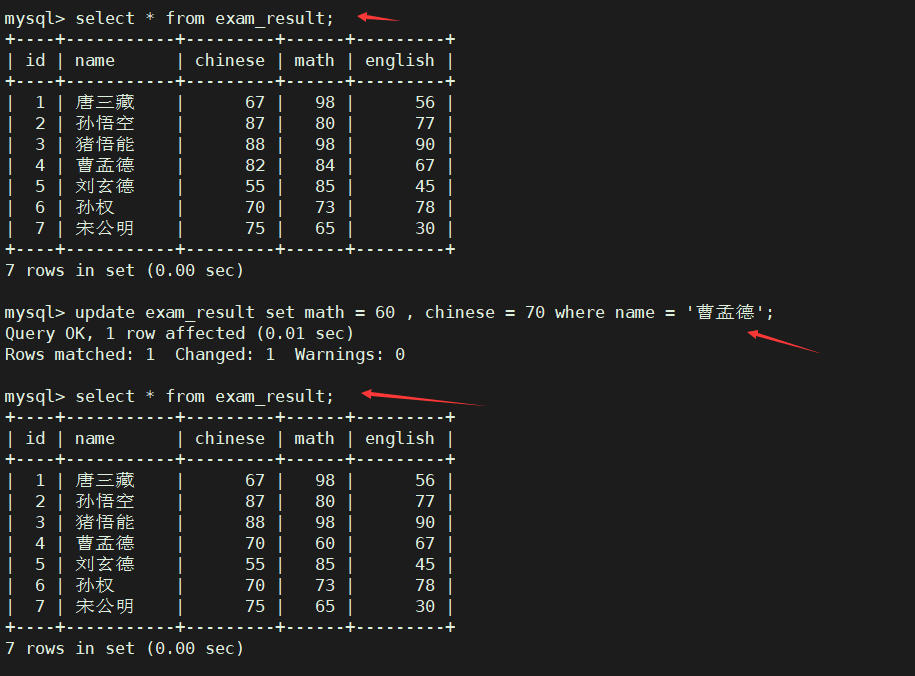
将曹孟德同学的数学成绩变更为60分,语文成绩变更为70分
update exam_result set math = 60 , chinese = 70 where name = '曹孟德';
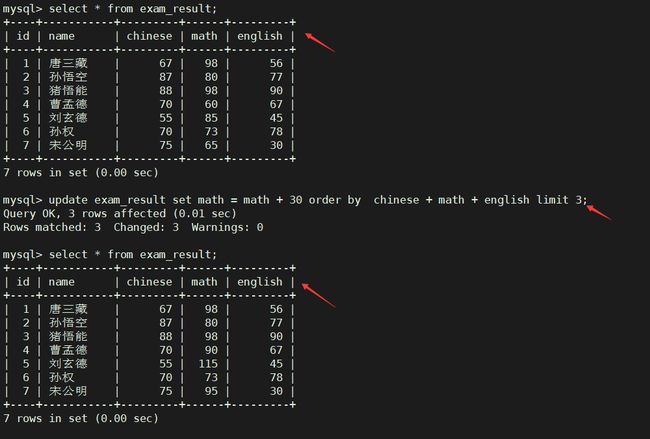
将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
注:mysql是不支持+= 等操作的
update exam_result set math = math + 30 order by chinese + math + english limit 3;
将所有同学的语文成绩更新为原来的 2 倍
update exam_result set chinese = 2 * chinese ;

Delete – 删除数据
delete
语法:
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]
案例:
删除孙悟空同学的考试成绩
delete from exam_result where name = '孙悟空';

删除整张表的数据
准备测试表
create table for_delete (
id int primary key auto_increment,
name varchar(20)
);
插入测试数据:
insert into for_delete (name) values ('A') ,('B'), ('C');

查看测试数据之后,将整张表数据删除

而后再插入一个数据,发现自增 id 在原值上升

show create 一下 我们会发现表中的auto_increment 保存下个插入数据的自增id

小总结:
- delete 删除全表数据,auto_increment 会保持增长
truncate – 截断表
注意: 这个操作慎用
- 只能对整表操作,不能像
DELETE一样针对部分数据操作; - 实际上 MySQL 不对数据操作,所以比
DELETE更快,但是TRUNCATE在删除数据的时候,并不经过真正的事物,所以无法回滚 - 会重置
AUTO_INCREMENT项
案例:
准备测试表
create table for_truncate (
id int primary key auto_increment,
name varchar(20)
);
插入测试数据
insert into for_truncate (name) values ('A') , ('B'), ('C');
查看测试数据
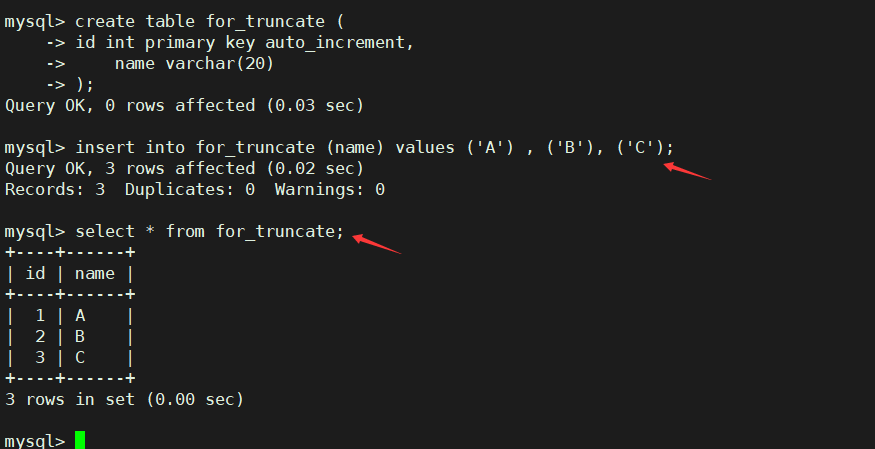
截断整张表数据,注意影响行数是0 , 所以实际上没有对数据进行真正操作
truncate for_truncate;

重新插入一条结果发现自增id 在重新自增

插入查询结果
语法:
INSERT INTO table_name [(column [, column ...])] SELECT ...
案例: 删除表中的重复记录,重复的数据只能有一个
思路: 使用 distinct 将数据筛选出来而后插入到一张新表中就得到了不重复的数据
创建原数据表
create table duplicate_table (id int , name varchar(20));
---插入测试数据
INSERT INTO duplicate_table VALUES
(100, 'aaa'),
(100, 'aaa'),
(200, 'bbb'),
(200, 'bbb'),
(200, 'bbb'),
(300, 'ccc');

然后我们准备一个空表no_duplicate_table 接收去重之后的查询结果
create table no_duplicate_table like duplicate_table;
insert into no_dupliacate_table select distinct * from duplicate_table; -- 将查询的去重结果插入到表中
将结果插入进去之后,我们就得到了我们想要的去重结果

聚合函数
| 函数 | 说明 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
案例:
统计班级共有多少同学
注: 使用 * 做统计 ,不受NULL影响
select count(*) from students;

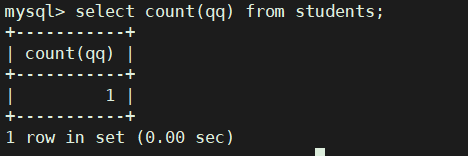
统计班级收集的qq号有多少
注: count不会统计 NULL
select count(qq) from students;
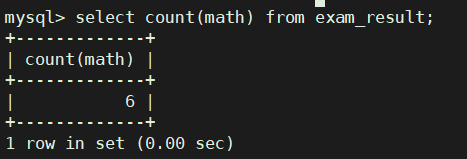
统计本次考试的数学成绩分数个数
select count(math) from exam_result;
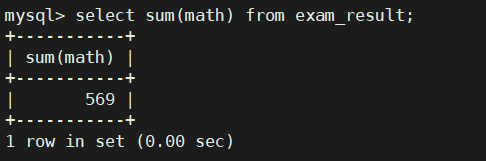
统计数学成绩总分
select sum(math) from exam_result;
统计平均总分
select avg(chinese + math + english ) 平均总分 from exam_result;

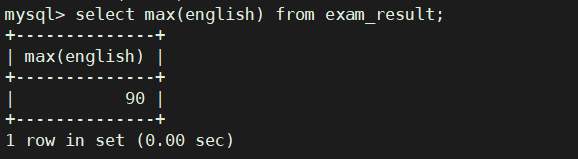
返回英语最高分
select max(english) from exam_result;
返回 > 70 分以上的数学最低分
select min(math) from exam_result where math > 70;

group by 子句
在select中使用group by 子句可以对指定列进行分组查询
select column1, column2, .. from table group by column;
案例:
-
准备工作,创建一个雇员信息表(来自oracle 9i的经典测试表)
EMP员工表
DEPT部门表
SALGRADE工资等级表
DROP database IF EXISTS `scott`;
CREATE database IF NOT EXISTS `scott` DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
USE `scott`;
DROP TABLE IF EXISTS `dept`;
CREATE TABLE `dept` (
`deptno` int(2) unsigned zerofill NOT NULL COMMENT '部门编号',
`dname` varchar(14) DEFAULT NULL COMMENT '部门名称',
`loc` varchar(13) DEFAULT NULL COMMENT '部门所在地点'
);
DROP TABLE IF EXISTS `emp`;
CREATE TABLE `emp` (
`empno` int(6) unsigned zerofill NOT NULL COMMENT '雇员编号',
`ename` varchar(10) DEFAULT NULL COMMENT '雇员姓名',
`job` varchar(9) DEFAULT NULL COMMENT '雇员职位',
`mgr` int(4) unsigned zerofill DEFAULT NULL COMMENT '雇员领导编号',
`hiredate` datetime DEFAULT NULL COMMENT '雇佣时间',
`sal` decimal(7,2) DEFAULT NULL COMMENT '工资月薪',
`comm` decimal(7,2) DEFAULT NULL COMMENT '奖金',
`deptno` int(2) unsigned zerofill DEFAULT NULL COMMENT '部门编号'
);
DROP TABLE IF EXISTS `salgrade`;
CREATE TABLE `salgrade` (
`grade` int(11) DEFAULT NULL COMMENT '等级',
`losal` int(11) DEFAULT NULL COMMENT '此等级最低工资',
`hisal` int(11) DEFAULT NULL COMMENT '此等级最高工资'
);
insert into dept (deptno, dname, loc)
values (10, 'ACCOUNTING', 'NEW YORK');
insert into dept (deptno, dname, loc)
values (20, 'RESEARCH', 'DALLAS');
insert into dept (deptno, dname, loc)
values (30, 'SALES', 'CHICAGO');
insert into dept (deptno, dname, loc)
values (40, 'OPERATIONS', 'BOSTON');
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7369, 'SMITH', 'CLERK', 7902, '1980-12-17', 800, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7499, 'ALLEN', 'SALESMAN', 7698, '1981-02-20', 1600, 300, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7521, 'WARD', 'SALESMAN', 7698, '1981-02-22', 1250, 500, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7566, 'JONES', 'MANAGER', 7839, '1981-04-02', 2975, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7654, 'MARTIN', 'SALESMAN', 7698, '1981-09-28', 1250, 1400, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7698, 'BLAKE', 'MANAGER', 7839, '1981-05-01', 2850, null, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7782, 'CLARK', 'MANAGER', 7839, '1981-06-09', 2450, null, 10);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7788, 'SCOTT', 'ANALYST', 7566, '1987-04-19', 3000, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7839, 'KING', 'PRESIDENT', null, '1981-11-17', 5000, null, 10);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7844, 'TURNER', 'SALESMAN', 7698,'1981-09-08', 1500, 0, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7876, 'ADAMS', 'CLERK', 7788, '1987-05-23', 1100, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7900, 'JAMES', 'CLERK', 7698, '1981-12-03', 950, null, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7902, 'FORD', 'ANALYST', 7566, '1981-12-03', 3000, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7934, 'MILLER', 'CLERK', 7782, '1982-01-23', 1300, null, 10);
insert into salgrade (grade, losal, hisal) values (1, 700, 1200);
insert into salgrade (grade, losal, hisal) values (2, 1201, 1400);
insert into salgrade (grade, losal, hisal) values (3, 1401, 2000);
insert into salgrade (grade, losal, hisal) values (4, 2001, 3000);
insert into salgrade (grade, losal, hisal) values (5, 3001, 9999);
使用方式: 创建一个后缀为sql的文件 ,然后将代码拷贝一下,登录mysql 之后 source一下sql文件
显示每个部门的平均工资和最高工资
select deptno,avg(sal),max(sal) from emp group by deptno;

显示每个部门的每种岗位的平均工资和最低工资
select avg(sal),min(sal),job, deptno from emp group by deptno, job;

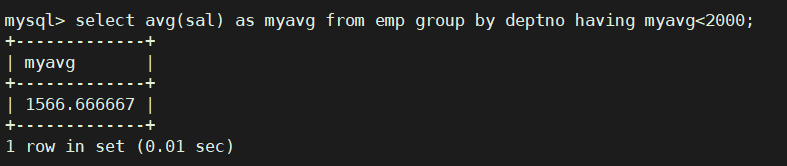
显示平均工资低于2000的部门和它的平均工资
select avg(sal) as myavg from emp group by deptno having myavg<2000;
-- having经常和group by搭配使用,作用是对分组进行筛选,作用有些像where
思考: 如果将上的
having换成where行不行呢?
select avg(sal) as myavg from emp group by deptno where myavg<2000;
![]()
答案是不行的,因为
- SQL查询中各个关键字的执行先后顺序 from > on> join > where > group by > with > having > select > distinct > order by > limit
ysql 之后 source一下sql文件
显示每个部门的平均工资和最高工资
select deptno,avg(sal),max(sal) from emp group by deptno;
[外链图片转存中…(img-1PMOzser-1685959423379)]
显示每个部门的每种岗位的平均工资和最低工资
select avg(sal),min(sal),job, deptno from emp group by deptno, job;
[外链图片转存中…(img-YQ8EbHd6-1685959423379)]
显示平均工资低于2000的部门和它的平均工资
select avg(sal) as myavg from emp group by deptno having myavg<2000;
-- having经常和group by搭配使用,作用是对分组进行筛选,作用有些像where
[外链图片转存中…(img-8JUTBLQr-1685959423379)]
思考: 如果将上的
having换成where行不行呢?
select avg(sal) as myavg from emp group by deptno where myavg<2000;
[外链图片转存中…(img-Hdv1PTmm-1685959423379)]
答案是不行的,因为
-
SQL查询中各个关键字的执行先后顺序 from > on> join > where > group by > with > having > select > distinct > order by > limit
-
而我们取别名时是在
select中取的,而where子句的执行优先级比select高,即执行where子句之时,别名还未产生; 且将myavg 改成 avg(sal) 也是不行的,