Oracle的学习心得和知识总结(二十六)|Oracle数据库Real Application Testing测试指南(数据库回放)
目录结构
注:提前言明 本文借鉴了以下博主、书籍或网站的内容,其列表如下:
1、参考书籍:《Oracle Database SQL Language Reference》
2、参考书籍:《PostgreSQL中文手册》
3、EDB Postgres Advanced Server User Guides,点击前往
4、PostgreSQL数据库仓库链接,点击前往
5、PostgreSQL中文社区,点击前往
6、Oracle Real Application Testing 官网首页,点击前往
7、Oracle 21C RAT Testing Guide,点击前往
1、本文内容全部来源于开源社区 GitHub和以上博主的贡献,本文也免费开源(可能会存在问题,评论区等待大佬们的指正)
2、本文目的:开源共享 抛砖引玉 一起学习
3、本文不提供任何资源 不存在任何交易 与任何组织和机构无关
4、大家可以根据需要自行 复制粘贴以及作为其他个人用途,但是不允许转载 不允许商用 (写作不易,还请见谅 )
Oracle数据库Real Application Testing测试指南 数据库回放
- 文章快速说明索引
- 数据库测试的简介
-
- SQL 性能分析器
- 数据库回放
- 数据库回放
-
- 数据库重放简介
-
- 工作负载捕获
- 工作负载预处理
- 工作负载重放
- 分析和报告
- PDB 中的工作负载捕获和重放
- 捕获数据库工作负载
-
- 捕获数据库工作负载的先决条件
- 设置捕获目录
- 工作负载捕获选项
-
- 重启数据库
- 将筛选器与工作负载捕获一起使用
- 工作负载捕获限制
- 启用和禁用工作负载捕获功能
- 使用 API 捕获数据库工作负载
-
- 定义工作负载捕获过滤器
- 启动工作负载捕获
- 停止工作负载捕获
- 为工作负载捕获导出 AWR 数据
- 为工作负载捕获导入 AWR 数据
- 使用 API 加密和解密现有工作负载捕获
-
- 加密现有工作负载捕获
- 解密加密的工作负载捕获
- 使用视图监控工作负载捕获
- 预处理数据库工作负载
-
- 使用 API 预处理数据库工作负载
-
- 运行工作负载分析器命令行界面
- 重放数据库工作负载
-
- 重放数据库工作负载的步骤
-
- 设置重放目录
- 恢复数据库
- 解析对外部系统的引用
- 连接重映射
- 用户重映射
- 指定重放选项
-
- 指定同步方法
- 控制会话连接速率
- 控制会话中的请求率
- 将过滤器与工作负载重放一起使用
- 设置重放客户端
-
- 校准重放客户端
- 启动重放客户端
- 显示主机信息
- 使用 API 重放数据库工作负载
-
- 初始化回放数据
- 重新映射连接
- 重新映射用户
- 设置工作负载重放选项
- 定义工作负载重放过滤器和重放过滤器集
-
- 添加工作负载重放过滤器
- 删除工作负载重放过滤器
- 创建重放过滤器集
- 使用重放过滤器集
- 设置重放超时操作
- 启动工作负载重放
- 暂停工作负载重放
- 恢复工作负载重放
- 取消工作负载重放
- 检索有关工作负载重放的信息
- 为工作负载重放加载分歧数据
- 删除有关工作负载重放的信息
- 为工作负载重放导出 AWR 数据
- 为工作负载重放导入 AWR 数据
- 使用 API 监控工作负载重放
-
- 检索有关分歧调用的信息
- 使用视图监控工作负载重放
- 分析捕获和重放的工作负载
-
- 使用工作负载捕获报告
-
- 使用 API 生成工作负载捕获报告
- 查看工作负载捕获报告
- 使用工作负载重放报告
-
- 使用 API 生成工作负载重放报告
- 查看工作负载重放报告
-
- 重放会话
- 同步化
- 跟踪提交
- 会话失败
- 使用回放比较期间报告
-
- 使用 API 生成回放比较期间报告
- 查看回放比较期间报告
-
- 一般信息
- 重放发散
- 主要性能统计
- 热门 SQL/调用
- 硬件使用比较
- ADDM比较
- ASH 数据对比
-
- 比较总结
- TOP SQL
- 长时间运行的 SQL
- 常用SQL
- TOP对象
- 使用 SQL 性能分析器报告
-
- 使用 API 生成 SQL 性能分析器报告
- 使用工作负载智能
-
- 工作负载智能概述
-
- 关于工作负载智能
- 工作负载智能用例
- 使用工作负载智能的要求
- 使用工作负载智能分析捕获的工作负载
-
- 为工作负载智能创建数据库用户
- 创建工作负载智能作业
- 生成工作负载模型
- 识别工作负载中的模式
- 生成工作负载智能报告
- 示例:工作负载智能结果
- 使用统一数据库重放
-
- 合并数据库重放的用例
-
- 使用可插拔数据库进行数据库整合
- 压力测试
- 放大测试
- 使用统一数据库重放的步骤
-
- 为整合数据库重放捕获数据库工作负载
-
- 支持的工作负载捕获类型
- 捕获子集
- 为合并数据库重放设置测试系统
- 为整合数据库重放预处理数据库工作负载
- 为合并数据库重放重放数据库工作负载
-
- 定义重放计划
-
- 添加工作负载捕获
- 添加计划订单
- 重新映射合并数据库重放的连接
- 为合并数据库重放重新映射用户
- 准备合并数据库重放
- 重放单个工作负载
- 合并数据库重放的报告和分析
- 将合并数据库重放与 API 结合使用
-
- 使用 API 生成捕获子集
- 使用 API 设置合并重放目录
- 使用 API 定义重放计划
-
- 使用 API 创建重放计划
- 使用 API 将工作负载捕获添加到重放计划
- 使用 API 将计划订单添加到重放计划
- 使用 API 保存重放计划
- 使用 API 运行合并数据库重放
-
- 使用 API 初始化合并数据库重放
- 使用 API 重新映射连接
- 使用 API 重新映射用户
- 使用 API 准备合并数据库重放
- 使用 API 启动统一数据库重放
- 关于仅查询数据库重放
-
- 仅查询数据库重放的用例
- 执行仅查询数据库重放
- 示例:使用 API 重放整合工作负载
- 使用工作负载扩展
-
- 工作负载扩展概述
-
- 关于时移
- 关于工作负载折叠
- 关于架构重映射
- 使用时移
- 使用工作负载折叠
- 使用架构重映射

文章快速说明索引
学习目标:
目的:接下来这段时间我想做一些兼容Oracle数据库Real Application Testing (即:RAT)上的一些功能开发,本专栏这里主要是学习以及介绍Oracle数据库功能的使用场景、原理说明和注意事项等,基于PostgreSQL数据库的功能开发等之后 由新博客进行介绍和分享!
学习内容:(详见目录)
1、Oracle数据库DBMS程序包解密方法及SQL Developer和Unwrapper的安装与使用
学习时间:
2023年05月07日 17:41:38
学习产出:
1、Oracle数据库DBMS程序包解密方法及SQL Developer和Unwrapper的安装与使用
2、CSDN 技术博客 1篇
注:下面我们所有的学习环境是Centos7+PostgreSQL15.0+Oracle19c+MySQL5.7
postgres=# select version();
version
-----------------------------------------------------------------------------
PostgreSQL 15.0 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 7.1.0, 64-bit
(1 row)
postgres=#
#-----------------------------------------------------------------------------#
SQL> select * from v$version;
BANNER BANNER_FULL BANNER_LEGACY CON_ID
--------------------------------------------------------------------------- --------------------------------------------------------------------------- --------------------------------------------------------------------------- ----------
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production 0
Version 19.3.0.0.0
SQL>
#-----------------------------------------------------------------------------#
mysql> select version();
+-----------+
| version() |
+-----------+
| 5.7.19 |
+-----------+
1 row in set (0.06 sec)
mysql>
数据库测试的简介
Oracle 数据库的 Oracle Real Application Testing 选件可帮助您安全地确保数据库更改的完整性并管理测试数据。
Oracle Real Application Testing 选项使您能够执行 Oracle 数据库的真实世界测试。通过在生产部署之前捕获生产负载并评估系统更改对这些负载的影响,Oracle Real Application Testing 最大限度地降低了与系统更改相关的不稳定风险。SQL Performance Analyzer 和 Database Replay 是 Oracle Real Application Testing 的关键组件。根据正在测试的系统更改的性质和影响,以及将执行测试的系统类型,您可以使用其中一个或两个组件来执行测试。
SQL 性能分析器
系统变更,如升级数据库、增加索引等,可能会导致SQL语句的执行计划发生变化,从而对SQL性能产生重大影响。在某些情况下,系统更改可能会导致 SQL 语句倒退,从而导致性能下降。在其他情况下,系统更改可能会提高 SQL 性能。能够准确预测系统变化对 SQL 性能的潜在影响,使您能够在 SQL 语句退化的情况下预先调优系统,或者在 SQL 语句性能提高的情况下验证和衡量性能增益。
SQL Performance Analyzer 通过识别每个 SQL 语句的性能差异,自动评估更改对整个 SQL 工作负载的总体影响。提供的报告显示更改对工作负载性能的净影响。对于回归的 SQL 语句,SQL Performance Analyzer 还提供适当的执行计划详细信息以及调优建议。因此,您可以在最终用户受到影响之前纠正任何负面结果。此外,您可以在节省大量时间和成本的情况下验证对生产环境的系统更改将带来净改进。
您可以使用 SQL Performance Analyzer 来分析任何类型的系统更改对 SQL 性能的影响,包括:
- 数据库升级
- 可插拔数据库 (PDB) 的数据库整合测试和手动模式整合
- 操作系统或硬件的配置更改
- 架构更改(Schema changes)
- 更改数据库初始化参数
- 刷新优化器统计信息
- 验证 SQL 调优操作
数据库回放
在进行系统更改(例如硬件和软件升级)之前,通常会在测试环境中执行大量测试以验证更改。然而,尽管进行了测试,但新系统在投入生产时经常遇到意外行为,因为测试不是使用实际工作负载执行的。无法在测试期间模拟真实的工作负载是验证系统更改时面临的最大挑战之一。
数据库重放通过在测试系统上重新创建生产工作负载环境来实现对系统更改的真实测试。使用数据库重放,您可以捕获生产系统上的工作负载并在具有原始工作负载的准确时间、并发性和事务特征的测试系统上重放它。这使您能够全面评估变更的影响,包括不期望的结果、新的争用点或计划回归。提供广泛的分析和报告以帮助识别任何潜在问题,例如遇到的新错误和性能差异。
数据库重放在数据库级别捕获外部数据库客户端的工作负载,并且性能开销可以忽略不计。捕获生产工作负载消除了开发模拟工作负载或脚本的需要,从而显着降低成本并节省时间。通过使用数据库重放,以前使用负载模拟工具需要几个月才能完成的复杂应用程序的真实测试现在可以在几天内完成。这使您能够以更高的信心和更低的风险快速测试更改并采用新技术。
您可以使用数据库重放来测试任何重大的系统更改,包括:
- 数据库和操作系统升级
- PDB 的数据库整合测试和手动模式整合
- 使用工作负载扩展编写和试验各种场景
- 配置更改,例如将数据库从单个实例转换为 Oracle Real Application Clusters (Oracle RAC) 环境
- 存储、网络和互连更改
- 操作系统和硬件迁移
数据库回放
数据库重放使您能够在测试系统上重放完整的生产工作负载,以评估系统更改的总体影响。
数据库重放简介
您可以使用数据库重放来捕获生产系统上的工作负载,并在具有原始工作负载的准确时间、并发性和事务特征的测试系统上重放它。这使您能够在不影响生产系统的情况下测试系统更改的影响。
数据库重放支持在运行 Oracle 数据库 10g 第 2 版和更新版本的系统上捕获负载。为了捕获运行 Oracle 数据库 10g 第 2 版的系统上的负载,数据库版本必须为 10.2.0.4 或更高版本。仅运行 Oracle Database 11g 第 1 版和更新版本的系统支持工作负载重放。
使用数据库重放分析系统更改的影响涉及以下步骤,如下图所示:
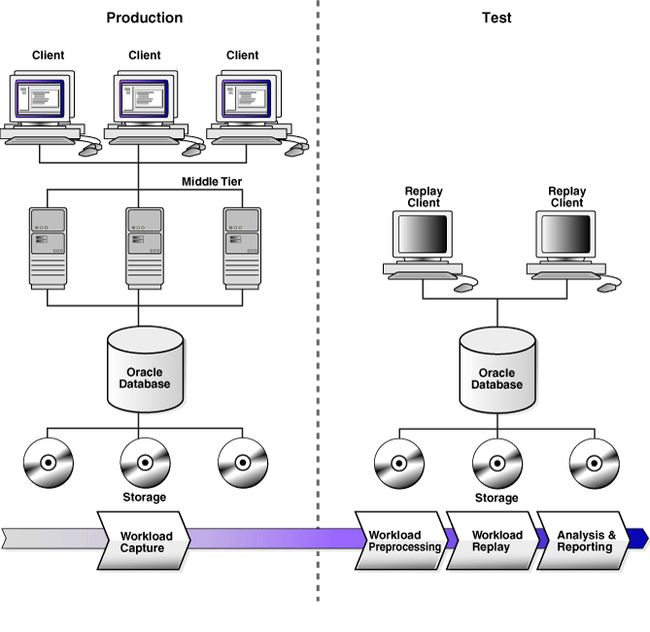
- 在生产系统上,将工作负载捕获到捕获文件中
- 将捕获文件复制到测试系统并对其进行预处理
- 在测试系统上,重放预处理文件
- 使用数据库重放生成的报告,对工作负载捕获和工作负载重放进行详细分析
工作负载捕获
使用Database Replay的第一步是捕获生产工作负载。捕获工作负载包括记录外部客户端向Oracle数据库发出的所有请求。
启用负载捕获后,所有指向 Oracle 数据库的外部客户端请求都会被跟踪并存储在文件系统上的二进制文件(称为捕获文件)中。您可以指定存储捕获文件的位置。一旦工作负载捕获开始,所有外部数据库调用都将写入捕获文件。捕获文件包含有关客户端请求的所有相关信息,例如 SQL 文本、绑定值和事务信息。不捕获后台活动和数据库调度程序作业。这些捕获文件与平台无关,可以传输到另一个系统。
工作负载预处理
捕获工作负载后,必须对捕获文件中的信息进行预处理。预处理会创建重放工作负载所需的所有必要元数据。在重放之前,必须为每个捕获的工作负载执行一次此操作。捕获的负载经过预处理后,可以在运行相同版本 Oracle 数据库的重放系统上重复重放。通常,应将捕获文件复制到测试系统进行预处理。由于工作负载预处理可能非常耗时且占用大量资源,因此建议在将重放工作负载的测试系统上执行此步骤。
工作负载重放
捕获的工作负载经过预处理后,可以在测试系统上重放。在负载重放阶段,Oracle 数据库通过使用与生产系统相同的时间、并发性和事务依赖性重新创建所有捕获的外部客户端请求,在测试系统上执行负载捕获阶段记录的操作。
数据库重放使用称为重放客户端的客户端程序来重新创建在工作负载捕获期间记录的所有外部客户端请求。根据捕获的工作负载,您可能需要一个或多个重放客户端才能正确重放工作负载。提供了一个校准工具来帮助确定特定工作负载所需的重放客户端数量。由于重放了整个工作负载(包括 DML 和 SQL 查询),因此重放系统中的数据在逻辑上应尽可能与捕获系统中的数据相似。这将最大限度地减少回放差异并实现更可靠的回放分析。
分析和报告
重放工作负载后,将为您提供深入的报告,以对工作负载捕获和重放进行详细分析。
工作负载捕获报告和工作负载重放报告提供有关工作负载捕获和重放的基本信息,例如重放期间遇到的错误以及 DML 或 SQL 查询返回的行中的数据分歧。还提供了工作负载捕获和工作负载重放之间的多个统计数据(例如数据库时间、平均活动会话和用户调用)的比较。
重放比较周期报告可用于执行一个工作负载重放与其捕获或同一捕获的另一个重放的高级比较。还提供了差异摘要,其中分析了是否发生任何数据差异以及是否存在任何重大性能变化。此外,自动数据库诊断监视器 (ADDM) 的调查结果已纳入这些报告中。
对于高级分析,可以使用自动工作负载存储库 (AWR) 报告来详细比较工作负载捕获和工作负载重放之间的性能统计数据。这些报告中提供的信息非常详细,可以预料到工作负载捕获和重放之间存在一些差异。此外,工作负载智能对工作负载捕获期间记录的数据进行操作,以创建描述工作负载的模型。 该模型可用于识别作为工作负载的一部分执行的模板中的重要模式。对于每个模式,您都可以查看重要的统计信息,例如给定模式的执行次数以及该模式在执行期间消耗的数据库时间。
SQL Performance Analyzer 报告可用于比较来自工作负载捕获的 SQL 调优集与来自工作负载重放的另一个 SQL 调优集,或来自两个工作负载重放的两个 SQL 调优集。将 SQL 调优集与数据库重放进行比较比 SQL Performance Analyzer test-execute 提供更多信息,因为它考虑并显示每个 SQL 语句的所有执行计划,而 SQL Performance Analyzer test-execute 仅为每个 SQL 试验的每个 SQL 语句生成一个执行计划。此外,SQL 语句在更真实的环境中执行,因为数据库重放捕获所有绑定值并更准确地再现动态会话状态(例如 PL/SQL 包状态)。建议您首先运行 SQL Performance Analyzer test-execute 作为健全性测试,以确保 SQL 语句没有倒退并且在使用数据库重放执行负载和通用测试之前正确设置了测试系统。
除了使用回放差异信息来分析给定系统更改的回放特征外,您还应该使用应用程序级验证程序来评估系统更改。考虑开发一个脚本来评估回放的总体成功率。例如,如果在工作负载捕获期间处理了 10,000 个订单,您应该验证在回放期间也处理了类似数量的订单。
回放分析完成后,您可以将数据库恢复到工作负载捕获时的原始状态,并重复工作负载回放以测试对系统的其他更改。
PDB 中的工作负载捕获和重放
可以启用工作负载捕获并可以在可插拔数据库 (PDB) 级别启动工作负载重放。
在 Oracle 数据库版本 19c 之前,负载捕获和重放仅供容器数据库 (CDB) 管理员使用,其中捕获和重放是从 CDB 根启动的。从 Oracle 数据库版本 19c 开始,可以为当前的可插拔数据库 (PDB) 启用负载捕获。还可以为当前 PDB 启动工作负载重放。
注意:在 PDB 级别支持并发工作负载捕获和重放。
捕获数据库工作负载
本章介绍如何捕获生产系统上的数据库工作负载。使用数据库重放的第一步是捕获生产负载。
捕获数据库工作负载的先决条件
在开始工作负载捕获之前,您应该准备好在测试系统上恢复数据库的策略。在可以重放工作负载之前,重放系统上应用程序数据的逻辑状态应该类似于重放开始时捕获系统的逻辑状态。为此,请考虑使用以下方法之一:
- Recovery Manager (RMAN)
DUPLICATEcommand - Snapshot standby
- Data Pump Import and Export
这将允许您将重放系统上的数据库恢复到工作负载捕获开始时的应用程序状态。
如果数据库受 Database Vault 保护,则您需要获得授权才能在 Database Vault 环境中使用 DBMS_WORKLOAD_CAPTURE 和 DBMS_WORKLOAD_REPLAY 程序包,然后才能使用 Database Replay。
设置捕获目录
确定位置并设置将存储捕获的工作负载的目录。在开始工作负载捕获之前,请确保该目录为空并且有足够的磁盘空间来存储工作负载。如果目录在工作负载捕获期间用完磁盘空间,则捕获将停止。要估计所需的磁盘空间量,您可以在短时间内(例如几分钟)对您的工作负载运行测试捕获,以推断完整捕获需要多少空间。为避免潜在的性能问题,您还应确保目标重放目录挂载在单独的文件系统上。
对于 Oracle RAC,请考虑使用共享文件系统。或者,您可以设置一个捕获目录路径,解析为每个实例上的单独物理目录,但您需要将在这些目录中的每个目录中创建的文件合并到一个目录中。对于 Oracle RAC 数据库上的捕获,Enterprise Manager 仅支持配置有共享文件系统的 Oracle RAC。每个实例上本地捕获目录的全部内容(不仅是捕获文件)必须先复制到共享目录,然后才能用于预处理。例如,假设您是:
- 使用名为 host1 和 host2 的两个数据库实例在 Linux 中运行 Oracle RAC 环境
- 在两个实例上使用名为 CAPDIR 的捕获目录对象解析为 /$ORACLE_HOME/rdbms/capture
- 使用位于 /nfs/rac_capture 中的共享目录
您将需要登录到每个主机并运行以下命令:
cp -r /$ORACLE_HOME/rdbms/capture/* /nfs/rac_capture
为这两个实例完成此操作后,/nfs/rac_capture 共享目录就可以进行预处理或屏蔽了。
工作负载捕获选项
需要在工作负载捕获之前进行适当的规划,以确保捕获在另一个环境中重放时准确且有用。
在捕获数据库工作负载之前,请仔细考虑以下选项:
- 重启数据库
- 将过滤器与工作负载捕获一起使用
重启数据库
虽然此步骤不是必需的,但 Oracle 建议在捕获负载之前重新启动数据库,以确保允许在捕获开始之前完成或回滚正在进行的和依赖的事务。如果在捕获开始之前数据库没有重新启动,则正在进行或尚未提交的事务将不会在工作负载中被完全捕获。正在进行的事务因此不会被正确重放,因为只有调用被捕获的事务部分会被重放。当重放工作负载时,这可能会导致不希望的重放分歧。任何依赖于不完整事务的后续事务也可能在重放期间产生错误。在繁忙的系统上,看到一些重放分歧是正常的,但如果分歧调用在 DB 时间和其他方面不构成重放的重要部分,那么回放仍然可以用于对系统更改进行有意义的分析。
在重新启动数据库之前,确定在中断最少的工作负载捕获之前关闭生产数据库的适当时间。例如,您可能想要捕获从上午 8:00 开始的工作负载。但是,为了避免在正常工作时间中断服务,您可能不希望在这段时间内重新启动数据库。在这种情况下,您应该考虑在较早的时间开始工作负载捕获,以便可以在中断较少的时间重新启动数据库。
重新启动数据库后,在任何用户会话重新连接并开始发出任何工作负载之前启动工作负载捕获非常重要。否则,这些用户会话执行的事务将无法在后续的数据库重放中正常重放,因为只有在工作负载捕获开始后执行调用的事务部分才会被重放。为避免此问题,请考虑使用 STARTUP RESTRICT 在 RESTRICTED 模式下重新启动数据库,这将只允许 SYS 用户登录并启动工作负载捕获。默认情况下,一旦工作负载捕获开始,任何处于 RESTRICTED 模式的数据库实例将自动切换到 UNRESTRICTED 模式,并且在捕获工作负载时可以继续正常操作。
在任何给定时间只能执行一次工作负载捕获。如果您有 Oracle Real Application Clusters (Oracle RAC) 配置,则会对整个数据库执行负载捕获。一旦为其中一个 Oracle RAC 节点启用捕获,就会在所有数据库实例上启动负载捕获(负载捕获过程是 Oracle RAC 感知的)。虽然这不是必需的,但建议在负载捕获之前重新启动 Oracle RAC 配置中的所有实例,以避免捕获正在进行的事务。
在负载捕获之前重启 Oracle RAC 配置中的所有实例:
- 关闭所有实例
- 重新启动所有实例
- 开始工作负载捕获
- 连接应用程序并启动用户工作负载
将筛选器与工作负载捕获一起使用
默认情况下,在工作负载捕获期间记录所有用户会话。您可以使用工作负载筛选器来指定在工作负载捕获期间要包含在工作负载中或从工作负载中排除的用户会话。工作负载筛选器有两种类型:包含筛选器和排除筛选器。您可以在工作负载捕获中使用包含筛选器或排除筛选器,但不能同时使用这两种筛选器。
包含筛选器使您能够指定将在工作负载中捕获的用户会话。如果您只想捕获数据库工作负载的一个子集,这将非常有用。
排除筛选器使您能够指定不会在工作负载中捕获的用户会话。如果您想筛选出不需要在工作负载中捕获的会话类型,例如那些监视基础结构的会话类型(如Oracle Enterprise Manager(EM)或Statspack)或其他已经在测试系统上运行的进程),这将非常有用。例如,如果要重放工作负载的系统正在运行EM,则在系统上重放捕获的EM会话将导致工作负载的重复。在这种情况下,您可能需要使用排除筛选器来筛选EM会话。
工作负载捕获限制
某些类型的用户会话和客户端请求有时可能会在工作负载中被捕获,但数据库重放不支持它们。在工作负载中捕获这些会话和请求类型可能会导致在工作负载重放期间出错。
数据库重放不支持以下类型的用户会话和客户端请求:
- 使用 SQL*Loader 等实用程序从外部文件直接路径加载数据
- 非基于 PL/SQL 的高级队列 (AQ)
- 闪回查询
- 基于 Oracle 调用接口 (OCI) 的对象导航
- 非基于 SQL 的对象访问
- 分布式事务:捕获的任何分布式事务都将作为本地事务重放
- XA 事务:不捕获或重放 XA 事务。 捕获所有本地事务
- JAVA_XA 事务:如果工作负载使用 JAVA_XA 包,则 JAVA_XA 函数和过程调用将被捕获为正常的 PL/SQL 工作负载。为避免工作负载重放期间出现问题,请考虑在重放系统上删除 JAVA_XA 包以使重放能够成功完成
- 数据库常驻连接池 (DRCP)
- 使用 OUT 绑定的工作负载
- 同步模式设置为 OBJECT_ID 的多线程服务器 (MTS) 和共享服务器会话
- 迁移的会话:为迁移的会话捕获工作负载。但是,不会捕获用户登录或会话迁移操作。如果没有有效的用户登录或会话迁移,重放可能会导致错误,因为工作负载可能会被错误的用户重放。
通常,数据库重放会避免捕获这些类型的不受支持的用户会话和客户端请求。即使捕获了它们,数据库重放也不会重放它们。因此,通常不需要手动过滤掉不支持的用户会话和客户端请求。如果在重放期间捕获并发现它们会导致错误,请考虑使用工作负载捕获过滤器将它们从工作负载中排除。
启用和禁用工作负载捕获功能
数据库重放支持在运行 Oracle 数据库 10g 第 2 版的系统上捕获数据库负载,可用于测试数据库升级到 Oracle 数据库 11g 和后续版本。默认情况下,Oracle 数据库 10g 第 2 版 (10.2) 中未启用负载捕获特性。您可以通过指定 PRE_11G_ENABLE_CAPTURE 初始化参数来启用或禁用此功能。
注意:只有在运行 Oracle 数据库 10g 第 2 版的系统上捕获数据库负载时,才需要启用负载捕获特性。如果您在运行 Oracle 数据库 11g 第 1 版或更高版本的系统上捕获数据库负载,则无需启用负载捕获功能,因为它默认处于启用状态。此外,PRE_11G_ENABLE_CAPTURE 初始化参数仅对 Oracle 数据库 10g 第 2 版 (10.2) 有效,不能用于后续版本。
要在运行 Oracle 数据库 10g 第 2 版的系统上启用负载捕获特性,请在 SQL 提示符下运行 wrrenbl.sql 脚本:
@$ORACLE_HOME/rdbms/admin/wrrenbl.sql
wrrenbl.sql 脚本调用 ALTER SYSTEM SQL 语句将 PRE_11G_ENABLE_CAPTURE 初始化参数设置为 TRUE。如果使用了服务器参数文件(spfile),PRE_11G_ENABLE_CAPTURE 初始化参数将被修改为当前正在运行的实例并记录在spfile 中,以便在数据库重新启动时新设置将保留。如果未使用 spfile,PRE_11G_ENABLE_CAPTURE 初始化参数将仅针对当前运行的实例进行修改,并且新设置不会在数据库重新启动时保留。要在不使用 spfile 的情况下使设置持久化,您需要在初始化参数文件 (init.ora) 中手动指定参数。
要禁用工作负载捕获,请在 SQL 提示符下运行 wrrdsbl.sql 脚本:
@$ORACLE_HOME/rdbms/admin/wrrdsbl.sql
wrrdsbl.sql 脚本调用 ALTER SYSTEM SQL 语句将 PRE_11G_ENABLE_CAPTURE 初始化参数设置为 FALSE。如果使用服务器参数文件(spfile),PRE_11G_ENABLE_CAPTURE 初始化参数将被修改为当前正在运行的实例并记录在 spfile 中,以便在数据库重新启动时新设置将保留。如果未使用 spfile,PRE_11G_ENABLE_CAPTURE 初始化参数将仅针对当前运行的实例进行修改,并且新设置不会在数据库重新启动时保留。要在不使用 spfile 的情况下使设置持久化,您需要在初始化参数文件 (init.ora) 中手动指定参数。
注意:PRE_11G_ENABLE_CAPTURE 初始化参数只能用于 Oracle 数据库 10g 第 2 版 (10.2)。该参数在后续版本中无效。升级数据库后,需要将服务器参数文件(spfile)或初始化参数文件(init.ora)中的参数去掉;否则,数据库将无法启动。
使用 API 捕获数据库工作负载
使用 DBMS_WORKLOAD_CAPTURE 包捕获数据库工作负载涉及:
- 定义工作负载捕获过滤器
- 启动工作负载捕获
- 停止工作负载捕获
- 为工作负载捕获导出 AWR 数据
- 为工作负载捕获导入 AWR 数据
定义工作负载捕获过滤器
本节介绍如何添加和删除工作负载捕获过滤器。
将过滤器添加到工作负载捕获:
- 使用 ADD_FILTER 过程:
BEGIN
DBMS_WORKLOAD_CAPTURE.ADD_FILTER (
fname => 'user_ichan',
fattribute => 'USER',
fvalue => 'ICHAN');
END;
/
在此示例中,ADD_FILTER 过程添加了一个名为 user_ichan 的过滤器,可用于过滤掉属于用户名 ICHAN 的所有会话。
此示例中的 ADD_FILTER 过程使用以下参数:
- fname 必需参数指定将添加的过滤器的名称
- fattribute 必需参数指定将应用过滤器的属性。有效值包括 PROGRAM、MODULE、ACTION、SERVICE、INSTANCE_NUMBER 和 USER
- fvalue 必需参数指定将应用过滤器的相应属性的值。可以对某些属性(例如模块和操作)使用通配符,例如 %
要从工作负载捕获中删除过滤器:
- 使用 DELETE_FILTER 过程:
BEGIN
DBMS_WORKLOAD_CAPTURE.DELETE_FILTER (fname => 'user_ichan');
END;
/
在此示例中,DELETE_FILTER 过程从工作负载捕获中删除名为 user_ichan 的过滤器。
此示例中的 DELETE_FILTER 过程使用 fname 必需参数,该参数指定要删除的过滤器的名称。DELETE_FILTER 过程不会删除属于已完成捕获的过滤器;它仅适用于尚未开始的捕获过滤器。
启动工作负载捕获
本节介绍如何开始工作负载捕获。在开始工作负载捕获之前,您必须先完成捕获数据库工作负载的先决条件以及查看(或使用)工作负载捕获选项。
为工作负载有一个明确定义的起点很重要,这样重放系统可以在启动捕获的工作负载的重放之前恢复到该点。要为工作负载捕获定义明确的起点,最好在开始工作负载捕获时不要有任何活动的用户会话。如果活动会话执行正在进行的事务,则这些事务将不会在后续数据库重放中正确重放,因为只有在工作负载捕获开始后执行调用的那部分事务才会被重放。为避免此问题,请考虑在开始工作负载捕获之前使用 STARTUP RESTRICT 以受限模式重新启动数据库。一旦工作负载捕获开始,数据库将自动切换到不受限模式,并且在捕获工作负载时可以继续正常操作。有关在捕获工作负载之前重新启动数据库的更多信息,请参阅上面的“重新启动数据库”。
要开始工作负载捕获:
- 使用 START_CAPTURE 过程:
BEGIN
DBMS_WORKLOAD_CAPTURE.START_CAPTURE (name => 'dec10_peak',
dir => 'dec10',
duration => 600,
capture_sts => TRUE,
sts_cap_interval => 300,
plsql_mode => 'extended',
encryption => 'AES256');
END;
/
在此示例中,名为 dec10_peak 的工作负载将被捕获 600 秒,并存储在名为 dec10 的数据库目录对象指向的文件系统目录中。SQL 调优集也将与工作负载捕获并行捕获。
此示例中的 START_CAPTURE 过程使用以下参数:
- name 必需参数指定将捕获的工作负载的名称
- dir 必需参数指定一个目录对象,指向将存储捕获的工作负载的目录
- 持续时间参数指定工作负载捕获结束前的秒数。如果未指定值,工作负载捕获将继续,直到调用 FINISH_CAPTURE 过程
- capture_sts 参数指定是否在工作负载捕获的同时捕获 SQL 调优集。如果该参数设置为TRUE,您可以在负载捕获时捕获一个SQL调优集,然后在负载重放时捕获另一个SQL调优集,并使用SQL Performance Analyzer对比SQL调优集,而无需重新执行SQL语句。这使您能够在运行数据库重放时获取 SQL 性能分析器报告并比较更改前后的 SQL 性能。您还可以使用 EXPORT_AWR 过程导出生成的 SQL 调整集及其 AWR 数据。Oracle RAC 不支持此功能。使用 DBMS_WORKLOAD_CAPTURE 定义的工作负载捕获过滤器不适用于 SQL 调整集捕获。此参数的默认值为 FALSE
- sts_cap_interval 参数指定从游标缓存中捕获 SQL 调优集的持续时间(以秒为单位)。默认值为 300。将此参数的值设置为低于默认值可能会导致某些工作负载产生额外开销,因此不建议这样做
- 可选的 plsql_mode 参数决定了 PL/SQL 在捕获和重放期间如何被 DB Replay 处理。可以为 plsql_mode 参数设置这两个值:
- top_level:仅捕获和重放顶级 PL/SQL 调用,这是 Oracle Database 12c 第 2 版 (12.2.0.1) 之前的 DB Replay 处理 PL/SQL 的方式。这是默认值
- extended:捕获顶级 PL/SQL 调用和从 PL/SQL 调用的 SQL。重放工作负载时,可以在顶层或扩展级别完成重放
- 加密参数指定用于加密捕获文件的算法。加密参数可以使用以下加密标准:
- NULL - 捕获文件未加密(默认值)
- AES128 - 捕获文件使用 AES128 加密
- AES192 - 捕获文件使用 AES192 加密
- AES256 - 捕获文件使用 AES256 加密
注意:要使用加密运行 START_CAPTURE,您必须使用 oracle.rat.database_replay.encryption(区分大小写)标识符设置密码。密码存储在软件密钥库中。有关创建软件密钥库的更多信息,请参阅 Oracle 数据库高级安全指南。
示例:设置基于密码的软件密钥库:
-- 以下语句创建一个基于密码的软件密钥库:
ADMINISTER KEY MANAGEMENT CREATE KEYSTORE 'MYKEYSTORE' IDENTIFIED BY password;
-- 以下语句打开基于密码的软件密钥库并创建基于密码的软件密钥库的备份:
ADMINISTER KEY MANAGEMENT SET KEYSTORE OPEN IDENTIFIED BY password;
ADMINISTER KEY MANAGEMENT SET KEY IDENTIFIED BY password WITH BACKUP;
-- 以下语句将客户端“oracle.rat.database_replay.encryption”的带有标记 DBREPLAY 的秘密 secret_key 添加到基于密码的软件密钥库。 它还会在添加秘密之前创建基于密码的软件密钥库的备份:
ADMINISTER KEY MANAGEMENT ADD SECRET secret_key FOR CLIENT 'oracle.rat.database_replay.encryption' USING TAG 'DBREPLAY' IDENTIFIED BY password WITH BACKUP;
-- 以下语句关闭基于密码的软件密钥库:
ADMINISTER KEY MANAGEMENT SET KEYSTORE CLOSE IDENTIFIED BY password;
注意:在运行数据库捕获和数据库重放之前,软件密钥库必须保持打开状态。
停止工作负载捕获
本节介绍如何停止工作负载捕获。
要停止工作负载捕获:
- 使用 FINISH_CAPTURE 过程:
BEGIN
DBMS_WORKLOAD_CAPTURE.FINISH_CAPTURE ();
END;
/
在此示例中,FINISH_CAPTURE 过程完成工作负载捕获并将数据库返回到正常状态。
注:在生产系统上捕获工作负载后,您需要预处理捕获的工作负载,如预处理数据库工作负载中所述。
为工作负载捕获导出 AWR 数据
导出 AWR 数据可以对工作负载进行详细分析。如果您计划在一对工作负载捕获或重放上运行 Replay Compare Period 报告或 AWR Compare Period 报告,也需要此数据。
要导出 AWR 数据:
- 使用 EXPORT_AWR 过程:
BEGIN
DBMS_WORKLOAD_CAPTURE.EXPORT_AWR (capture_id => 2);
END;
/
在此示例中,导出对应于捕获 ID 为 2 的工作负载捕获的 AWR 快照,以及可能在工作负载捕获期间捕获的任何 SQL 调优集。
EXPORT_AWR 过程使用 capture_id 必需参数,该参数指定将导出其 AWR 快照的捕获的 ID。capture_id 参数的值显示在 DBA_WORKLOAD_CAPTURES 视图的 ID 列中。
注意:仅当在当前数据库中执行了相应的工作负载捕获并且与原始捕获时间段对应的 AWR 快照仍然可用时,此过程才有效。
为工作负载捕获导入 AWR 数据
从捕获系统导出 AWR 数据后,您可以将 AWR 数据导入另一个系统,例如将要重放捕获的工作负载的测试系统。导入 AWR 数据可以对工作负载进行详细分析。如果您计划在一对工作负载捕获或重放上运行 Replay Compare Period 报告或 AWR Compare Period 报告,也需要此数据。
要导入 AWR 数据:
- 使用 IMPORT_AWR 函数,如以下示例所示:
CREATE USER capture_awr
SELECT DBMS_WORKLOAD_CAPTURE.IMPORT_AWR (capture_id => 2,
staging_schema => 'capture_awr')
FROM DUAL;
在此示例中,使用名为 capture_awr 的暂存模式导入与捕获 ID 为 2 的工作负载捕获相对应的 AWR 快照。
此示例中的 IMPORT_AWR 过程使用以下参数:
- capture_id 必需参数指定将导入其 AWR 快照的捕获的 ID。capture_id 参数的值显示在 DBA_WORKLOAD_CAPTURES 视图的 ID 列中
- staging_schema 必需参数指定当前数据库中现有模式的名称,在将 AWR 快照从捕获目录导入到 SYS AWR 模式时,该模式将用作临时区域
注意:如果 staging_schema 参数指定的模式包含与任何 AWR 表同名的任何表,则此函数失败。
使用 API 加密和解密现有工作负载捕获
本节介绍如何使用 API 加密和解密现有工作负载捕获。
在工作负载捕获期间,会保存连接字符串、SQL 文本和绑定值等各种信息。如果此信息包含敏感数据,则可以对其进行加密。您可以在工作负载捕获期间启用加密,如启动工作负载捕获中所述。
加密现有工作负载捕获
本节介绍如何加密现有工作负载捕获。
要加密现有的工作负载捕获:
- 使用 ENCRYPT_CAPTURE 过程:
BEGIN
DBMS_WORKLOAD_CAPTURE.ENCRYPT_CAPTURE(src_dir => 'dec10',
dst_dir => 'dec10_enc',
encryption => 'AES128');
END;
/
此示例中的 ENCRYPT_CAPTURE 过程使用以下参数:
- src_dir 参数指向包含要加密的工作负载捕获的目录
- dst_dir参数指向加密后保存加密抓包的目录
- encryption 参数指定用于加密工作负载捕获的算法
注意:在运行 DBMS_WORKLOAD_CAPTURE.ENCRYPT_CAPTURE 之前,您必须将 oracle.rat.database_replay.encryption(区分大小写)标识符存储在软件密钥库中。
解密加密的工作负载捕获
本节介绍如何解密加密的工作负载捕获。
可以使用 DBMS_WORKLOAD_CAPTURE.DECRYPT_CAPTURE 过程对加密的工作负载捕获进行解密。
要解密加密的工作负载捕获:
- 使用 DECRYPT_CAPTURE 过程:
BEGIN
DBMS_WORKLOAD_CAPTURE.DECRYPT_CAPTURE(src_dir => 'dec10_enc',
dst_dir => 'dec10');
END;
/
此示例中的 DECRYPT_CAPTURE 过程使用以下参数:
- src_dir 参数指向包含加密捕获的目录
- dst_dir参数指向解密后保存解密抓包的目录
注意:在运行 DBMS_WORKLOAD_CAPTURE.DECRYPT_CAPTURE 之前,您必须将 oracle.rat.database_replay.encryption(区分大小写)标识符存储在软件密钥库中。
使用视图监控工作负载捕获
本节总结了您可以显示以监控工作负载捕获的视图。要访问这些视图,您需要 DBA 权限:
- DBA_WORKLOAD_CAPTURES 视图列出了当前数据库中已捕获的所有工作负载捕获
- DBA_WORKLOAD_FILTERS 视图列出了用于当前数据库中定义的工作负载捕获的所有工作负载过滤器
预处理数据库工作负载
捕获工作负载并完成测试系统设置后,必须对捕获的数据进行预处理。预处理捕获的工作负载会创建所有必要的元数据以重放工作负载。在重放之前,必须为每个捕获的工作负载执行一次此操作。捕获的工作负载经过预处理后,可以在重放系统上反复重放。
要预处理捕获的工作负载,您首先需要将所有捕获的数据文件从它们存储在捕获系统上的目录移动到将执行预处理的实例上的目录。预处理是资源密集型的,应该在以下系统上执行:
- 与生产系统分离
- 运行与重放系统相同版本的 Oracle 数据库
对于 Oracle Real Application Clusters (Oracle RAC),选择一个回放系统的数据库实例进行预处理。此实例必须有权访问需要预处理的捕获数据文件,这些文件可以存储在本地或共享文件系统中。如果捕获系统上的捕获目录路径在每个实例中解析为单独的物理目录,您将需要将它们合并到将执行预处理的单个捕获目录中。所有目录必须具有相同的目录树,并且每个目录中包含的所有文件必须移动到与捕获目录具有相同相对路径的目录中。
通常,您将在重放系统上预处理捕获的工作负载。如果计划在独立于重放系统的系统上预处理捕获的工作负载,则还需要在预处理完成后将所有预处理数据文件从预处理系统上存储它们的目录移动到重放系统上的某个目录。
使用 API 预处理数据库工作负载
本节介绍如何使用 DBMS_WORKLOAD_REPLAY 包预处理捕获的工作负载。
在您可以预处理捕获的工作负载之前,您必须首先捕获生产系统上的工作负载,如捕获数据库工作负载中所述。
预处理捕获的工作负载:
- 使用 PROCESS_CAPTURE 过程:
BEGIN
DBMS_WORKLOAD_REPLAY.PROCESS_CAPTURE (capture_dir => 'dec06',
plsql_mode => 'extended');
END;
/
在此示例中,将对存储在 dec06 目录中的捕获工作负载进行预处理。
此示例中的 PROCESS_CAPTURE 过程使用 capture_dir 必需参数,该参数指定包含要预处理的捕获工作负载的目录。
可选的 plsql_mode 参数指定 PL/SQL 的处理模式。
可以为 plsql_mode 参数设置这两个值:
- top_level:仅为顶级PL/SQL调用生成元数据;这将是重放的唯一选择。这是默认值
- extended:为顶级 PL/SQL 调用和从 PL/SQL 调用的 SQL 生成元数据。在捕获根目录下创建一个新目录 ppe_X.X.X.X(其中 X 代表当前 Oracle 版本)。必须使用相同的 plsql_mode 参数值完成捕获。重放可以使用
TOP_LEVEL或EXTENDED
注1:只能为plsql_mode参数设置为extended时捕获的工作负载设置extended值。如果指定了extended,但捕获没有在extended模式下执行,那么您将收到一条错误消息。
注2:要在加密的工作负载捕获上运行 PROCESS_CAPTURE,您需要使用标识符 oracle.rat.database_replay.encryption(区分大小写)设置密码。密码存储在软件密钥库中。您可以从 DBA_WORKLOAD_CAPTURES 视图中了解工作负载捕获是否已加密。
运行工作负载分析器命令行界面
工作负载分析器是一个 Java 程序,它分析工作负载捕获目录并识别由于数据不足、工作负载捕获期间发生的错误或数据库重放不支持的使用功能而可能无法准确重放的捕获工作负载部分。工作负载分析的结果保存到名为 wcr_cap_analysis.html 的 HTML 报告中,该报告位于正在分析的捕获目录中。如果可以避免错误,工作负载分析报告会显示可以在重放之前实施的可用预防措施。如果无法更正错误,工作负载分析报告会提供错误描述,以便在重放期间对其进行说明。运行工作负载分析器是默认选项,强烈建议使用。
注意:如果您使用 Oracle Enterprise Manager 预处理工作负载捕获,则不需要在命令行界面中运行工作负载分析器。Oracle Enterprise Manager 使您能够将工作负载分析器作为工作负载预处理的一部分运行。
工作负载分析器由两个 JAR 文件组成,dbranalyzer.jar 和 dbrparser.jar,位于运行 Oracle 数据库企业版 11.2.0.2 或更高版本的系统的 $ORACLE_HOME/rdbms/jlib/ 目录中。工作负载分析器需要 Java 1.5 或更高版本以及位于 $ORACLE_HOME/jdbc/lib/ 目录中的 ojdbc6.jar 文件。
要运行工作负载分析器:
- 在命令行界面中,在一行中运行以下 java 命令:
java -classpath
$ORACLE_HOME/jdbc/lib/ojdbc6.jar:$ORACLE_HOME/rdbms/jlib/dbrparser.jar:
$ORACLE_HOME/rdbms/jlib/dbranalyzer.jar:
oracle.dbreplay.workload.checker.CaptureChecker
<capture_directory> <connection_string>
对于 capture_directory 参数,输入捕获目录的操作系统路径。此目录还应包含为工作负载捕获导出的 AWR 数据。对于 connection_string 参数,输入 11.1 或更高版本的 Oracle 数据库的连接字符串。
此命令的示例可能是:
java -classpath
$ORACLE_HOME/jdbc/lib/ojdbc6.jar:$ORACLE_HOME/rdbms/jlib/dbrparser.jar:
$ORACLE_HOME/rdbms/jlib/dbranalyzer.jar:
oracle.dbreplay.workload.checker.CaptureChecker /scratch/capture
jdbc:oracle:thin:@myhost.mycompany.com:1521:orcl
- 出现提示时,输入对 DBMS_WORKLOAD_CAPTURE 包具有执行权限的数据库用户的用户名和密码,并在目标数据库上具有 SELECT_CATALOG 角色。
重放数据库工作负载
捕获的负载经过预处理后,可以在运行相同版本 Oracle 数据库的重放系统上重复重放。通常,将重放预处理工作负载的重放系统应该是与生产系统分开的测试系统。
重放数据库工作负载的步骤
正确准备回放系统和规划工作负载回放可确保回放准确无误。在重放数据库工作负载之前,请完成以下步骤以准备重放系统和工作负载重放:
- 设置重放目录
- 恢复数据库
- 解析对外部系统的引用
- 连接重映射
- 用户重映射
- 指定重放选项
- 将过滤器与工作负载重放一起使用
- 设置重放客户端
设置重放目录
捕获的工作负载必须经过预处理并复制到重放系统。重放系统中必须存在预处理工作负载复制到的目录的目录对象。
恢复数据库
在重放工作负载之前,重放系统上的应用程序数据状态在逻辑上应该与工作负载捕获开始时捕获系统的状态相同。这最大限度地减少了重放期间的重放分歧。 恢复数据库的方法取决于捕获工作负载之前使用的备份方法。例如,如果使用 RMAN 备份捕获系统,您可以使用 RMAN DUPLICATE 功能创建测试数据库。
在重放系统上使用适当的应用程序数据创建数据库后,执行您要测试的系统更改,例如数据库或操作系统升级。数据库重放的主要目的是测试系统更改对捕获的工作负载的影响。因此,您所做的系统更改应该定义您使用捕获的工作负载进行的测试。
解析对外部系统的引用
捕获的工作负载可能包含对外部系统的引用,例如数据库链接或外部表。通常,您应该重新配置这些外部交互以避免在回放期间影响其他生产系统。在重放工作负载之前需要解决的外部引用包括:
-
数据库链接:回放系统通常不希望与其他数据库交互。因此,您应该重新配置所有数据库链接以指向包含重放所需数据的适当数据库。
-
外部表:使用外部表引用的目录对象指定的所有外部文件都需要在重放期间对数据库可用。这些文件的内容应与捕获时的内容相同,用于定义外部表的文件名和目录对象也应有效。
-
目录对象:您应该通过在恢复数据库后适当地重新定义重放系统中存在的目录对象来重新配置对生产系统上目录的任何引用。
-
URL:需要配置存储在数据库中的 URL/URI,以便在工作负载捕获期间访问的 Web 服务将在回放期间指向正确的 URL。如果工作负载引用存储在生产系统中的 URL,则应在回放期间隔离测试系统网络。
-
电子邮件:为避免在回放期间重新发送电子邮件通知,回放系统可访问的任何电子邮件服务器都应配置为忽略传出电子邮件的请求。
提示:为避免在回放期间影响其他生产系统,Oracle 强烈建议在无法访问生产环境主机的隔离专用网络中运行回放。
连接重映射
在工作负载捕获期间,用于连接到生产系统的连接字符串被捕获。为了重放成功,您需要将这些连接字符串重新映射到重放系统。然后重放客户端可以使用重新映射的连接连接到重放系统。
对于 Oracle Real Application Clusters (Oracle RAC) 数据库,您可以将所有连接字符串映射到一个负载平衡连接字符串。如果回放系统上的节点数与捕获系统上的节点数不同,这将特别有用。或者,如果您想将工作负载定向到特定实例,您可以使用服务或在重新映射的连接字符串中明确指定实例标识符。
用户重映射
在工作负载捕获期间,捕获用于连接到生产系统的数据库用户或模式的用户名。您可以选择将捕获的用户名重新映射到新用户或模式的用户名。
指定重放选项
恢复数据库并重新映射连接和用户后,您可以设置适当的重放选项。例如:
- 指定同步方法
- 控制会话连接速率
- 控制会话中的请求率
指定同步方法
同步参数控制用于数据库重放的同步方法。
如果参数设置为 TIME,重放将使用与捕获相同的挂钟计时。所有数据库会话登录时间都将与捕获时完全相同。同样,数据库会话中事务之间的所有时间都将被保留并在捕获时重放。这种同步方法将为大多数工作负载产生良好的回放。
如果此参数设置为 SCN,则在重放期间将观察捕获的工作负载中的 COMMIT 顺序,并且仅在所有依赖的 COMMIT 操作完成后才会执行所有重放操作。这种同步方法可能会给某些工作负载带来明显的延迟。如果是这种情况,建议使用 TIME 作为同步参数。
如果此参数设置为 OBJECT_ID,则只有在所有相关的 COMMIT 操作完成后,才会执行所有重放操作。相关的 COMMIT 操作必须满足以下条件:
- 在工作负载捕获中的给定操作之前发出
- 隐式或显式修改了至少一个给定操作所引用的数据库对象
将此参数设置为 OBJECT_ID 允许在工作负载捕获期间不引用相同数据库对象的 COMMIT 操作的工作负载重放期间实现更多并发。
控制会话连接速率
connect_time_scale 参数使您能够缩放从工作负载捕获开始到每个会话连接的时间之间经过的时间。您可以使用此选项以给定的百分比值在回放期间操纵会话连接时间。默认值为 100,这将尝试连接捕获的所有会话。将此参数设置为 0 将尝试立即连接所有会话。
控制会话中的请求率
用户思考时间是重放用户在单个会话中发出调用之间等待的时间。要控制重放速度,请使用 think_time_scale 参数来缩放重放期间的用户思考时间。
如果用户调用在重放期间比捕获期间执行得慢,您可以通过将 think_time_auto_correct 参数设置为 TRUE 来使数据库重放尝试赶上。这将使重放客户端缩短调用之间的思考时间,从而使重放的总体运行时间将更接近于捕获的运行时间。
如果用户调用在回放期间比捕获期间执行得更快,则将 think_time_auto_correct 参数设置为 TRUE 不会更改思考时间。重放客户端不会增加调用之间的思考时间以匹配捕获的经过时间。
将过滤器与工作负载重放一起使用
默认情况下,所有捕获的数据库调用都会在工作负载重放期间重放。您可以使用工作负载过滤器来指定在工作负载重放期间要包含在工作负载中或从工作负载中排除的数据库调用。
首先定义工作负载重放过滤器,然后将其添加到重放过滤器集,以便在工作负载重放中使用它们。有两种类型的工作负载过滤器:包含过滤器和排除过滤器。包含过滤器使您能够指定将重放的数据库调用。排除过滤器使您能够指定不会重放的数据库调用。您可以在工作负载重放中使用包含过滤器或排除过滤器,但不能同时使用两者。创建重放过滤器集时,工作负载过滤器被确定为包含或排除过滤器。
设置重放客户端
重放客户端是一个多线程程序(一个名为 wrc 的可执行文件,位于 $ORACLE_HOME/bin 目录中),其中每个线程从捕获的会话中提交工作负载。在重放开始之前,数据库将等待重放客户端连接。此时,您需要设置并启动重放客户端,它将连接到重放系统并根据工作负载中捕获的内容发送请求。
在启动重放客户端之前,请确保:
- 重放客户端软件安装在将要运行的主机上
- 重放客户端可以访问重放目录
- 重放目录包含预处理的工作负载捕获
- 重放用户拥有正确的用户ID、密码和权限(重放用户需要DBA角色,不能是SYS用户)
- 重放客户端未在运行数据库的系统上启动
- 重放客户端在与数据库文件所在的文件系统不同的文件系统上读取捕获目录。为此,将捕获目录复制到重放客户端将运行的系统。回放完成后,您可以删除捕获目录
满足这些先决条件后,您可以使用 wrc 可执行文件继续设置和启动重放客户端。wrc 可执行文件使用以下语法:
wrc [user/password[@server]] MODE=[value] [keyword=[value]]
参数 user、password 和 server 指定用于连接到重放数据库的用户名、密码和连接字符串。参数 mode 指定运行 wrc 可执行文件的模式。可能的值包括 replay(默认值)、calibrate 和 list_hosts。参数关键字指定用于执行的选项,并且取决于所选的模式。要显示可能的关键字及其相应的值,请运行不带任何参数的 wrc 可执行文件。
以下部分描述了您在运行 wrc 可执行文件时可以选择的模式:
- 校准重放客户端
- 启动重放客户端
- 显示主机信息
校准重放客户端
由于一个重放客户端可以启动与数据库的多个会话,因此没有必要为每个捕获的会话启动一个重放客户端。需要启动的重放客户端数量取决于工作负载流的数量、主机数量以及每个主机的重放客户端数量。
要估计重放特定工作负载所需的重放客户端和主机的数量,请在校准模式下运行 wrc 可执行文件。
在校准模式下,wrc 可执行文件接受以下关键字:
- replaydir 指定包含要重放的预处理工作负载捕获的目录。如果未指定,则默认为当前目录
- process_per_cpu 指定每个 CPU 可以运行的最大客户端进程数。默认值为 4
- threads_per_process 指定可以在客户端进程中运行的最大线程数。默认值为 50
以下示例显示了如何在校准模式下运行 wrc 可执行文件:
%> wrc mode=calibrate replaydir=./replay
在此示例中,执行 wrc 可执行文件以估计重放存储在当前目录下名为 replay 的子目录中的工作负载捕获所需的重放客户端和主机的数量。在以下示例输出中,建议使用至少 21 个重放客户端,分配给 6 个 CPU:
Workload Replay Client: Release 12.1.0.0.1 - Production on Fri Sept 30
13:06:33 2011
Copyright (c) 1982, 2011, Oracle. All rights reserved.
Report for Workload in: /oracle/replay/
-----------------------
Recommendation:
Consider using at least 21 clients divided among 6 CPU(s).
Workload Characteristics:
- max concurrency: 1004 sessions
- total number of sessions: 1013
Assumptions:
- 1 client process per 50 concurrent sessions
- 4 client process per CPU
- think time scale = 100
- connect time scale = 100
- synchronization = TRUE
启动重放客户端
确定重放工作负载所需的重放客户端数量后,您需要通过在安装它们的主机上以重放模式运行 wrc 可执行文件来启动重放客户端。一旦启动,每个重放客户端将启动一个或多个与数据库的会话以驱动工作负载重放。
在回放模式下,wrc 可执行文件接受以下关键字:
- userid 和password 指定replay 客户端的replay 用户的用户ID 和密码。如果未指定,这些值默认为系统用户
- 服务器指定用于连接到重放系统的连接字符串。如果未指定,则该值默认为空字符串
- replaydir 指定包含要重放的预处理工作负载捕获的目录。如果未指定,则默认为当前目录
- workdir 指定将写入客户端日志的目录。此参数仅与调试参数一起用于调试目的
- debug 指定是否创建调试数据。 可能的值包括:
- ON 调试数据将写入工作目录中的文件
- OFF 不会写入调试数据(默认值)
- connection_override 指定是否覆盖存储在 DBA_WORKLOAD_CONNECTION_MAP 视图中的连接映射。如果设置为 TRUE,将忽略存储在 DBA_WORKLOAD_CONNECTION_MAP 视图中的连接重新映射,并使用使用服务器参数指定的连接字符串。如果设置为 FALSE,所有重放线程将使用存储在 DBA_WORKLOAD_CONNECTION_MAP 视图中的连接重新映射进行连接。这是默认设置
- walletdir 指向自动登录软件密钥库目录的位置。默认值为空字符串。walletdir 在重放加密的工作负载捕获期间是必需的。对于非加密捕获,不得设置 walletdir,它默认为空字符串
注意事项:
- 对于加密的工作负载捕获,您必须使用 oracle.rat.database_replay.encryption(区分大小写)标识符设置密码。密码存储在自动登录软件密钥库中
- 在重放加密工作负载捕获期间,您必须设置单独的客户端软件密钥库。例如:
rm -rf keystore_location mkdir keystore_location mkstore -wrl keystore_location -create mkstore -wrl keystore_location -createEntry 'oracle.rat.database_replay.encryption' secret_key mkstore -wrl keystore_location -createSSOsecret_key 必须与在工作负载捕获加密期间创建的服务器端软件密钥库中使用的 secret_key 相匹配。
在所有重放客户端连接后,数据库将自动在所有可用的重放客户端之间分配工作负载捕获流,然后工作负载重放就可以开始了。您可以使用 V$WORKLOAD_REPLAY_THREAD 视图监视重放客户端的状态。回放结束后,所有回放客户端将自动断开连接。
示例:在重放模式下运行 wrc 可执行文件以进行非加密捕获
-- 以下示例显示了如何在重放模式下运行 wrc 可执行文件:
%> wrc system/password@test mode=replay replaydir=./replay
-- 在此示例中,wrc 可执行文件启动重放客户端以重放存储在当前目录下名为 replay 的子目录中的工作负载捕获
示例:在重放模式下运行 wrc 可执行文件以进行加密捕获
-- 以下示例显示了如何在重放模式下运行 wrc 可执行文件以捕获加密的工作负载:
%> wrc system/password@test mode=replay replaydir=./replay walletdir=/tmp/replay_encrypt_cwallet
-- 在此示例中,wrc 可执行文件启动重放客户端以重放存储在当前目录下名为 replay 的子目录中的工作负载捕获
-- walletdir 指向自动登录软件密钥库目录的位置
显示主机信息
您可以通过在 list_hosts 模式下运行 wrc 可执行文件来显示参与工作负载捕获和工作负载重放的主机。
在 list_hosts 模式下,wrc 可执行文件接受关键字 replaydir,它指定包含要重放的预处理工作负载捕获的目录。如果未指定,则默认为当前目录。
以下示例显示了如何在 list_hosts 模式下运行 wrc 可执行文件:
%> wrc mode=list_hosts replaydir=./replay
在此示例中,执行 wrc 可执行文件以列出所有参与捕获或重放存储在当前目录下名为 replay 的子目录中的工作负载捕获的主机。在以下示例输出中,显示了参与工作负载捕获和三个后续重放的主机:
Workload Replay Client: Release 12.1.0.0.1 - Production on Fri Sept 30
13:44:48 2011
Copyright (c) 1982, 2011, Oracle. All rights reserved.
Hosts found:
Capture:
prod1
prod2
Replay 1:
test1
Replay 2:
test1
test2
Replay 3:
testwin
使用 API 重放数据库工作负载
本节介绍如何使用 DBMS_WORKLOAD_REPLAY 包重放数据库工作负载。
使用 DBMS_WORKLOAD_REPLAY 包重放数据库工作负载是一个多步骤过程,涉及:
- 初始化回放数据
- 重新映射连接
- 重新映射用户
- 设置工作负载重放选项
- 定义工作负载重放过滤器和重放过滤器集
- 设置重放超时操作
- 启动工作负载重放
- 暂停工作负载重放
- 恢复工作负载重放
- 取消工作负载重放
- 检索有关工作负载重放的信息
- 为工作负载重放加载分歧数据
- 删除有关工作负载重放的信息
- 为工作负载重放导出 AWR 数据
- 为工作负载重放导入 AWR 数据
初始化回放数据
在预处理工作负载捕获并适当准备测试系统后,可以初始化回放数据。初始化重放数据将必要的元数据加载到工作负载重放所需的表中。例如,捕获的连接字符串被加载到一个表中,可以在其中重新映射它们以进行重放。
初始化回放数据:
使用 INITIALIZE_REPLAY 过程:
BEGIN
DBMS_WORKLOAD_REPLAY.INITIALIZE_REPLAY (replay_name => 'dec06_102',
replay_dir => 'dec06',
plsql_mode => 'top_level');
END;
/
在此示例中,INITIALIZE_REPLAY 过程将预处理的工作负载数据从 dec06 目录加载到数据库中。
本例中的 INITIALIZE_REPLAY 过程使用以下参数:
- replay_name 必需参数指定可与其他 API 一起使用的重放名称,以检索以前重放的设置和过滤器
- replay_dir 必需参数指定包含将重放的工作负载捕获的目录
- 可选的 plsql_mode 参数指定 PL/SQL 重放模式。可以为 plsql_mode 参数设置这两个值:
- top_level:仅顶级 PL/SQL 调用。这是默认值
- extended:如果里面没有记录SQL,则在PL/SQL或顶层PL/SQL中执行的SQL。非 PL/SQL 调用将以通常的方式重放
注意:要在加密的工作负载捕获上运行 INITIALIZE_REPLAY,您需要使用 oracle.rat.database_replay.encryption(区分大小写)标识符设置密码。密码存储在软件密钥库中。您可以从 DBA_WORKLOAD_CAPTURES 视图中了解工作负载捕获是否已加密。
重新映射连接
重放数据初始化后,需要重新映射工作负载捕获中使用的连接字符串,以便用户会话可以连接到适当的数据库并执行重放期间捕获的外部交互。要查看连接映射,请使用 DBA_WORKLOAD_CONNECTION_MAP 视图。
重新映射连接:
- 使用 REMAP_CONNECTION 过程:
BEGIN
DBMS_WORKLOAD_REPLAY.REMAP_CONNECTION (connection_id => 101,
replay_connection => 'dlsun244:3434/bjava21');
END;
/
在此示例中,与连接 ID 101 对应的连接将使用 replay_connection 参数定义的新连接字符串。
此示例中的 REMAP_CONNECTION 过程使用以下参数:
- connection_id 必需参数在初始化回放数据时生成,对应于工作负载捕获的连接
- replay_connection 必需参数指定将在工作负载重放期间使用的新连接字符串
重新映射用户
除了重新映射连接字符串之外,您还可以使用新的架构或用户来代替工作负载捕获中捕获的用户。要查看捕获的用户,请使用 DBA_WORKLOAD_USER_MAP 视图。
重新映射用户:
- 使用 SET_USER_MAPPING 过程:
BEGIN
DBMS_WORKLOAD_REPLAY.SET_USER_MAPPING (capture_user => 'PROD',
replay_user => 'TEST');
END;
/
在此示例中,捕获期间使用的 PROD 用户在回放期间重新映射到 TEST 用户。
此示例中的 SET_USER_MAPPING 过程使用以下参数:
- capture_user 必需参数指定在工作负载捕获期间捕获的用户名
- replay_user 必需参数指定捕获的用户在重放期间重新映射到的用户名。如果此参数设置为 NULL,则映射被禁用
设置工作负载重放选项
初始化重放数据并重新映射连接和用户后,您需要为工作负载重放准备数据库。在回放系统上准备工作负载回放:
- 使用 PREPARE_REPLAY 过程:
BEGIN
DBMS_WORKLOAD_REPLAY.PREPARE_REPLAY (synchronization => 'OBJECT_ID',
capture_sts => TRUE,
sts_cap_interval => 300);
END;
/
在此示例中,PREPARE_REPLAY 过程准备一个先前已初始化的重放。SQL 调整集也将与工作负载重放并行捕获。
PREPARE_REPLAY 过程使用以下参数:
第一个(synchronization):需要同步的参数控制工作负载重放期间使用的同步类型。
如果参数设置为 TIME,重放将使用与捕获相同的挂钟计时。所有数据库会话登录时间都将与捕获时完全相同。同样,数据库会话中事务之间的所有时间都将被保留并在捕获时重放。这种同步方法将为大多数工作负载产生良好的回放。
如果此参数设置为 SCN(默认值),则在重放期间将观察捕获的工作负载中的 COMMIT 顺序,并且仅在所有依赖的 COMMIT 操作完成后才会执行所有重放操作。这种同步方法可能会给某些工作负载带来明显的延迟。如果是这种情况,建议使用 TIME 作为同步参数。
如果此参数设置为 OBJECT_ID,则只有在所有相关的 COMMIT 操作完成后,才会执行所有重放操作。相关的 COMMIT 操作必须满足以下条件:
- 在工作负载捕获中的给定操作之前发出
- 隐式或显式修改了至少一个给定操作所引用的数据库对象
将此参数设置为 OBJECT_ID 可以在工作负载重放期间允许更多并发性用于在工作负载捕获期间不引用相同数据库对象的 COMMIT 操作。
第二个(connect_time_scale):connect_time_scale 参数缩放从工作负载捕获开始到会话与指定值连接的经过时间,并解释为 % 值。使用此参数可增加或减少重放期间的并发用户数。默认值为 100
第三个(think_time_scale):think_time_scale 参数缩放来自同一会话的两个连续用户调用之间经过的时间,并被解释为 % 值。将此参数设置为 0 将在重放期间尽快将用户调用发送到数据库。默认值为 100
第四个(think_time_auto_correct):think_time_auto_correct 参数在用户调用在回放期间比在捕获期间需要更长的时间才能完成时更正调用之间的思考时间(基于 think_time_scale 参数)。此参数可以设置为 TRUE 或 FALSE。如果工作负载重放花费的时间比工作负载捕获的时间长,则将此参数设置为 TRUE 会减少思考时间。默认值是true
第五个(scale_up_multiplier):scale_up_multiplier 参数定义了在回放期间扩大工作负载的次数。每个捕获的会话将同时重放此参数指定的次数。但是,每组相同的重放会话中只有一个会话会同时执行查询和更新。其余会话将只执行查询
第六个(capture_sts):capture_sts 参数指定是否在工作负载重放的同时捕获 SQL 调优集。如果此参数设置为 TRUE,您可以在工作负载重放期间捕获 SQL 调优集,并使用 SQL Performance Analyzer 将其与另一个 SQL 调优集进行比较,而无需重新执行 SQL 语句。这使您能够在运行数据库重放时获取 SQL 性能分析器报告并比较更改前后的 SQL 性能。您还可以使用 EXPORT_AWR 过程导出生成的 SQL 调整集及其 AWR 数据,如“为工作负载重放导出 AWR 数据”中所述
Oracle RAC 不支持此功能。使用 DBMS_WORKLOAD_REPLAY 定义的工作负载重放过滤器不适用于 SQL 调整集捕获。此参数的默认值为 FALSE
第七个(sts_cap_interval):sts_cap_interval 参数指定从游标缓存中捕获 SQL 调优集的持续时间(以秒为单位)。默认值为 300。将此参数的值设置为低于默认值可能会导致某些工作负载产生额外开销,因此不建议这样做
定义工作负载重放过滤器和重放过滤器集
本节介绍如何添加和删除工作负载重放过滤器,以及如何创建和使用重放过滤器集。本节包含以下主题:
- 添加工作负载重放过滤器
- 删除工作负载重放过滤器
- 创建重放过滤器集
- 使用重放过滤器集
添加工作负载重放过滤器
本节介绍如何添加要在回放过滤器集中使用的新过滤器。要添加新过滤器:
- 使用 ADD_FILTER 过程:
BEGIN
DBMS_WORKLOAD_REPLAY.ADD_FILTER (
fname => 'user_ichan',
fattribute => 'USER',
fvalue => 'ICHAN');
END;
/
在此示例中,ADD_FILTER 过程添加了一个名为 user_ichan 的过滤器,可用于过滤掉属于用户名 ICHAN 的所有会话。
此示例中的 ADD_FILTER 过程使用以下参数:
- fname 必需参数指定将添加的过滤器的名称
- fattribute 必需参数指定将应用过滤器的属性。有效值包括 PROGRAM、MODULE、ACTION、SERVICE、USER 和 CONNECTION_STRING。您必须指定一个有效的捕获连接字符串,该字符串将在重放期间用作 CONNECTION_STRING 属性
- fvalue 必需参数指定将应用过滤器的相应属性的值。可以对某些属性(例如模块和操作)使用通配符,例如 %
添加所有工作负载重放过滤器后,您可以创建一个重放过滤器集,可在重放工作负载时使用。
删除工作负载重放过滤器
本节介绍如何删除工作负载重放过滤器。
要删除工作负载重放过滤器:
- 使用 DELETE_FILTER 过程:
BEGIN
DBMS_WORKLOAD_REPLAY.DELETE_FILTER (fname => 'user_ichan');
END;
/
在此示例中,DELETE_FILTER 过程删除名为 user_ichan 的过滤器。
DELETE_FILTER 过程使用 fname 必需参数,它指定要删除的过滤器的名称。
创建重放过滤器集
添加工作负载重放过滤器后,您可以创建一组重放过滤器以用于工作负载重放。创建重放过滤器集时,将使用自上一个重放过滤器集创建以来添加的所有工作负载重放过滤器。
要创建重放过滤器集:
- 使用 CREATE_FILTER_SET 过程:
BEGIN
DBMS_WORKLOAD_REPLAY.CREATE_FILTER_SET (
replay_dir => 'apr09',
filter_set => 'replayfilters',
default_action => 'INCLUDE');
END;
/
在此示例中,CREATE_FILTER_SET 过程创建一个名为 replayfilters 的重放过滤器集,它将重放存储在 apr09 目录中的所有捕获的重放调用,重放过滤器定义的工作负载部分除外。
此示例中的 CREATE_FILTER_SET 过程使用以下参数:
- replay_dir参数指定要过滤的replay存放的目录
- filter_set 参数指定要创建的过滤器集的名称
- default_action 参数确定是否应重放每个捕获的数据库调用,以及是否应将工作负载重放过滤器视为包含或排除过滤器
如果此参数设置为 INCLUDE,则将重放所有捕获的数据库调用,重放过滤器定义的部分工作负载除外。在这种情况下,所有重放过滤器都将被视为排除过滤器,因为它们将定义不会重放的工作负载部分。这是默认行为
如果此参数设置为 EXCLUDE,则不会重放任何捕获的数据库调用,重放过滤器定义的工作负载部分除外。在这种情况下,所有重放过滤器都将被视为包含过滤器,因为它们将定义将被重放的工作负载部分
使用重放过滤器集
创建回放过滤器集并初始化回放后,您可以使用回放过滤器集来过滤 replay_dir 目录中的回放。
要使用重放过滤器集:
- 使用 USE_FILTER_SET 程序:
BEGIN
DBMS_WORKLOAD_REPLAY.USE_FILTER_SET (filter_set => 'replayfilters');
END;
/
在此示例中,USE_FILTER_SET 过程使用名为 replayfilters 的过滤器集。
此示例中的 USE_FILTER_SET 过程使用 filter_set 必需参数,该参数指定要在回放中使用的过滤器集的名称。
设置重放超时操作
本节介绍如何为工作负载重放设置超时操作。您可以设置重放超时操作以中止在重放期间明显变慢的用户调用或导致重放挂起。例如,您可能希望设置重放超时操作以中止数据库升级后由次优执行计划引起的失控查询。
启用重放超时操作后,如果延迟超过重放超时操作指定的条件,用户调用将退出并出现 ORA-15569 错误。中止的调用及其错误被报告为错误分歧。
要设置重放超时:
- 使用 SET_REPLAY_TIMEOUT 程序:
BEGIN
DBMS_WORKLOAD_REPLAY.SET_REPLAY_TIMEOUT (
enabled => TRUE,
min_delay => 20,
max_delay => 60,
delay_factor => 10);
END;
/
在这个例子中,SET_REPLAY_TIMEOUT过程定义了一个重放超时动作,如果重放期间的延迟超过60分钟,或者如果重放期间延迟超过20分钟,并且经过的时间比捕获经过的时间大10倍,则该动作将中止用户调用。
本例中的 SET_REPLAY_TIMEOUT 过程使用以下参数:
- enabled 参数指定是启用还是禁用重放超时操作。默认值是true
- min_delay 参数以分钟为单位定义调用延迟的下限值。仅当延迟超过此值时才会激活重放超时操作。默认值为 10
- max_delay 参数定义了调用延迟的上限值,以分钟为单位。当延迟超过此值时,将激活重放超时操作并发出错误。默认值为 120
- delay_factor 参数定义了介于 min_delay 和 max_delay 值之间的调用延迟因子。当当前重放经过时间高于捕获经过时间与此值的乘积时,重放超时操作会发出错误。默认值为 8
要检索重放超时操作设置:
- 使用 GET_REPLAY_TIMEOUT 过程:
DECLARE
enabled BOOLEAN;
min_delay NUMBER;
max_delay NUMBER;
delay_factor NUMBER;
BEGIN
DBMS_WORKLOAD_REPLAY.GET_REPLAY_TIMEOUT(enabled, min_delay, max_delay,
delay_factor);
END;
/
此示例中的 GET_REPLAY_TIMEOUT 过程返回以下参数:
- enabled 参数返回重放超时操作是启用还是禁用
- min_delay 参数以分钟为单位返回调用延迟的下限值
- max_delay 参数以分钟为单位返回调用延迟的上限值
- delay_factor 参数返回延迟因子
启动工作负载重放
在开始工作负载重放之前需要执行一些任务。例如:
- 预处理捕获的工作负载
- 初始化回放数据
- 指定重放选项
- 启动重放客户端
注意:一旦开始工作负载重放,新的重放客户端将无法连接到数据库。只有在执行 START_REPLAY 过程之前启动的重放客户端才会用于重放捕获的工作负载。
要开始工作负载重放:
- 使用 START_REPLAY 程序:
BEGIN
DBMS_WORKLOAD_REPLAY.START_REPLAY ();
END;
/
注意:从 Oracle Database Release 19c 开始,DBA_RAT_CAPTURE_SCHEMA_INFO 视图为 SQL 语句提供 login_schema 和 current_schema 信息。在扩展模式下回放时,如果遇到ORA-00942: table or view does not exist 错误,则使用DBA_RAT_CAPTURE_SCHEMA_INFO 和DBA_WORKLOAD_CAPTURE_SQLTEXT 视图查找发生错误的表。然后将表上的必要权限授予遇到错误的用户并重试重放;这可能会解决问题。
暂停工作负载重放
暂停工作负载重放将停止重放客户端发出的所有后续用户调用,直到恢复或取消工作负载重放。已经在进行中的用户调用将被允许完成。此选项使您能够暂时停止回放以执行更改并观察其对回放剩余部分的影响。
要暂停工作负载重放:
- 使用 PAUSE_REPLAY 过程:
BEGIN
DBMS_WORKLOAD_REPLAY.PAUSE_REPLAY ();
END;
/
恢复工作负载重放
本节介绍如何恢复暂停的工作负载重放。
要恢复工作负载重放:
- 使用 RESUME_REPLAY 过程:
BEGIN
DBMS_WORKLOAD_REPLAY.RESUME_REPLAY ();
END;
/
取消工作负载重放
本节介绍如何取消工作负载重放。
要取消工作负载重放:
- 使用 CANCEL_REPLAY 过程:
BEGIN
DBMS_WORKLOAD_REPLAY.CANCEL_REPLAY ();
END;
/
检索有关工作负载重放的信息
您可以在重放目录对象中检索有关工作负载捕获的所有信息,以及从目录中重放工作负载尝试的历史记录。默认情况下,不加载工作负载重放分歧数据,但您可以选择性地选择加载此数据。
要检索有关工作负载重放的信息:
调用 DBMS_WORKLOAD_REPLAY.GET_REPLAY_INFO 函数。
GET_REPLAY_INFO 函数首先将一行导入 DBA_WORKLOAD_CAPTURES 视图,其中包含有关工作负载捕获的信息。默认情况下,它只会导入以前未加载到 DBA_WORKLOAD_REPLAYS 视图中的重放信息。此函数返回捕获目录的 cap_id(对于合并的捕获目录,返回的 cap_id 为 0),它可以与 DBA_WORKLOAD_REPLAYS 视图中的 CAPTURE_ID 列相关联以访问检索到的信息。
GET_REPLAY_INFO 函数使用以下参数:
- replay_dir 必需参数,它指定工作负载重放目录对象的名称
- load_divergence 可选参数,指定是否加载发散数据。此参数的默认值为 FALSE。要加载发散数据(将从重放目录检索到的每次重放尝试的行导入到 DBA_WORKLOAD_REPLAY_DIVERGENCE 视图中),请将此参数设置为 TRUE。或者,您可以使用 LOAD_DIVERGENCE 过程在检索到重放信息后为目录对象中的单个重放或所有重放有选择地加载分歧数据,如“为工作负载重放加载分歧数据”中所述
示例:检索有关工作负载重放的信息
以下示例显示如何检索有关工作负载捕获的信息和名为 jul14 的重放目录对象的工作负载重放尝试的历史记录,并验证是否已检索到该信息。
DECLARE
cap_id NUMBER;
BEGIN
cap_id := DBMS_WORKLOAD_REPLAY.GET_REPLAY_INFO(replay_dir => 'jul14');
SELECT capture_id
FROM dba_workload_replays
WHERE capture_id = cap_id;
END;
/
为工作负载重放加载分歧数据
为工作负载重放加载差异数据将从重放目录中检索的每次重放尝试的行导入 DBA_WORKLOAD_REPLAY_DIVERGENCE 视图,该视图显示有关重放尝试期间的分歧调用和错误的信息。您可以选择为给定目录对象中的单个工作负载重放或所有工作负载重放加载分歧数据。
为工作负载重放加载分歧数据:
- 使用以下参数之一调用 WORKLOAD_REPLAY.LOAD_DIVERGENCE 过程:
- replay_id 参数指定要为其加载发散数据的工作负载重放的 ID。如果您只想为单个工作负载重放加载分歧数据,请使用此参数
- replay_dir 参数指定目录对象的名称(值区分大小写)。如果要为给定目录对象中的所有工作负载重放加载分歧数据,请使用此参数
- 要查看发散数据的加载状态,请查询 DBA_WORKLOAD_REPLAYS 视图中的 DIVERGENCE_LOAD_STATUS 列。值为 TRUE 表示已加载发散数据,值为 FALSE 表示尚未加载
示例:为单个工作负载重放加载分歧数据
以下示例显示如何为 replay_id 值为 12 的工作负载重放加载分歧数据,以及如何验证是否已加载分歧数据。
DECLARE
rep_id NUMBER;
BEGIN
rep_id := DBMS_WORKLOAD_REPLAY.LOAD_DIVERGENCE (replay_id => 12);
SELECT divergence_load_status
FROM dba_workload_replays
WHERE capture_id = rep_id;
END;
/
删除有关工作负载重放的信息
您可以删除为单个工作负载重放或重放目录中的所有工作负载重放检索的信息。可以使用 GET_REPLAY_INFO 函数检索已删除的信息,如“检索有关工作负载重放的信息”中所述。
要删除有关工作负载重放的信息:
- 使用 replay_id 参数调用 DBMS_WORKLOAD_REPLAY.DELETE_REPLAY_INFO 过程
replay_id 参数指定要删除其重放信息的工作负载重放的 ID。如果您只想删除单个工作负载重放的信息,请使用此参数
- 默认情况下,删除有关工作负载重放的信息不会从磁盘中删除数据
示例:删除有关工作负载重放的信息
以下示例删除检索到的有关工作负载捕获的信息以及 ID 为 2 的工作负载重放的工作负载重放尝试历史记录。重放数据不会从磁盘中删除,因此可以通过调用 GET_REPLAY_INFO 函数来检索,如所述 在“检索有关工作负载重放的信息”中。
BEGIN
DBMS_WORKLOAD_REPLAY.DELETE_REPLAY_INFO (replay_id => 2);
END;
/
为工作负载重放导出 AWR 数据
导出 AWR 数据可以对工作负载进行详细分析。如果您计划在一对工作负载捕获或重放上运行 AWR Compare Period 报告,也需要此数据。
要导出 AWR 数据:
- 使用 EXPORT_AWR 过程:
BEGIN
DBMS_WORKLOAD_REPLAY.EXPORT_AWR (replay_id => 1);
END;
/
在此示例中,导出对应于重放 ID 为 1 的工作负载重放的 AWR 快照,以及可能在工作负载重放期间捕获的任何 SQL 调优集。
EXPORT_AWR 过程使用 replay_id 必需参数,该参数指定将导出其 AWR 快照的重放的 ID。
注意:仅当在当前数据库中执行了相应的工作负载重放并且与原始重放时间段对应的 AWR 快照仍然可用时,此过程才有效。
为工作负载重放导入 AWR 数据
从回放系统导出 AWR 数据后,您可以将 AWR 数据导入另一个系统。导入 AWR 数据可以对工作负载进行详细分析。如果您计划在一对工作负载捕获或重放上运行 AWR Compare Period 报告,也需要此数据。
要导入 AWR 数据:
- 使用 IMPORT_AWR 函数:
CREATE USER capture_awr
SELECT DBMS_WORKLOAD_REPLAY.IMPORT_AWR (replay_id => 1,
staging_schema => 'capture_awr')
FROM DUAL;
在此示例中,使用名为 capture_awr 的暂存模式导入与捕获 ID 为 1 的工作负载重放相对应的 AWR 快照。
此示例中的 IMPORT_AWR 过程使用以下参数:
- replay_id 必需参数指定要导入其 AWR 快照的重放的 ID
- staging_schema 必需参数指定当前数据库中现有模式的名称,在将 AWR 快照从重放目录导入 SYS AWR 模式时,该模式将用作临时区域
注意:如果 staging_schema 参数指定的模式包含与任何 AWR 表同名的任何表,则此函数失败。
使用 API 监控工作负载重放
本节介绍如何使用 API 和视图监控工作负载重放。
本节包含以下主题:
- 检索有关分歧调用的信息
- 使用视图监控工作负载重放
检索有关分歧调用的信息
在回放期间,回放系统和捕获系统之间的任何错误和数据差异都被记录为分歧的调用。
要检索有关分歧调用的信息(包括其 SQL 标识符、SQL 文本和绑定值),请使用以下参数调用 GET_DIVERGING_STATEMENT 函数:
- 将 replay_id 参数设置为调用发生分歧的重放的 ID
- 设置 stream_id 参数为分流调用的流 ID
- 设置call_counter参数为分流调用的调用计数器
要查看有关分流调用的这些信息,请使用 DBA_WORKLOAD_REPLAY_DIVERGENCE 视图。以下示例说明了函数调用:
DECLARE
r CLOB;
ls_stream_id NUMBER;
ls_call_counter NUMBER;
ls_sql_cd VARCHAR2(20);
ls_sql_err VARCHAR2(512);
CURSOR c IS
SELECT stream_id, call_counter
FROM DBA_WORKLOAD_REPLAY_DIVERGENCE
WHERE replay_id = 72;
BEGIN
OPEN c;
LOOP
FETCH c INTO ls_stream_id, ls_call_counter;
EXIT when c%notfound;
DBMS_OUTPUT.PUT_LINE (ls_stream_id||''||ls_call_counter);
r:=DBMS_WORKLOAD_REPLAY.GET_DIVERGING_STATEMENT(replay_id => 72,
stream_id => ls_stream_id, call_counter => ls_call_counter);
DBMS_OUTPUT.PUT_LINE (r);
END LOOP;
END;
/
使用视图监控工作负载重放
本节总结了您可以显示以监控工作负载重放的视图。您需要 DBA 权限才能访问这些视图
- DBA_WORKLOAD_CAPTURES 视图列出了当前数据库中已捕获的所有工作负载捕获
- DBA_WORKLOAD_FILTERS 视图列出了当前数据库中定义的工作负载捕获的所有工作负载过滤器
- DBA_WORKLOAD_REPLAYS 视图列出了当前数据库中已重放的所有工作负载重放
- DBA_WORKLOAD_REPLAY_DIVERGENCE 视图使您能够查看有关分流调用的信息,例如重放标识符、流标识符和调用计数器
- DBA_WORKLOAD_DIV_SUMMARY 视图在 DBA_WORKLOAD_REPLAY_DIVERGENCE 视图中显示重放发散信息的摘要
- DBA_WORKLOAD_REPLAY_FILTER_SET 视图列出了当前数据库中定义的工作负载重放的所有工作负载过滤器
- DBA_WORKLOAD_CONNECTION_MAP 视图列出了工作负载重放的连接映射信息
- V$WORKLOAD_REPLAY_THREAD 视图列出了来自重放客户端的所有会话的信息
分析捕获和重放的工作负载
本章介绍如何使用各种数据库重放报告分析捕获和重放的工作负载。
注意:重放分析完成后,您可以将数据库恢复到工作负载捕获时的原始状态,并在工作负载目录对象备份到另一个物理位置后重复工作负载重放以测试系统的其他更改。
使用工作负载捕获报告
工作负载捕获报告包含捕获的工作负载统计信息、有关捕获的顶级会话活动的信息以及捕获过程中使用的任何工作负载过滤器。
使用 API 生成工作负载捕获报告
您可以使用 DBMS_WORKLOAD_CAPTURE 程序包生成工作负载捕获报告。
要生成有关最新工作负载捕获的报告:
- 使用 DBMS_WORKLOAD_CAPTURE.GET_CAPTURE_INFO 过程。GET_CAPTURE_INFO 过程检索有关工作负载捕获的所有信息并返回工作负载捕获的 cap_id。此函数使用 dir 必需参数,该参数指定工作负载捕获目录对象的名称
- 调用 DBMS_WORKLOAD_CAPTURE.REPORT 函数。REPORT 函数使用 GET_CAPTURE_INFO 过程返回的 cap_id 生成报告。该函数使用以下参数:
- capture_id 必需参数与包含将为其生成报告的工作负载捕获的目录相关。该目录应该是包含工作负载捕获的主机系统中的有效目录。此参数的值应与 GET_CAPTURE_INFO 过程返回的 cap_id 匹配
- format 必需参数指定报告格式。有效值包括 DBMS_WORKLOAD_CAPTURE.TYPE_TEXT 和 DBMS_WORKLOAD_REPLAY.TYPE_HTML
在此示例中,GET_CAPTURE_INFO 过程在 jul14 目录中检索有关工作负载捕获的所有信息,并返回工作负载捕获的 cap_id。然后,REPORT 函数使用 GET_CAPTURE_INFO 过程返回的 cap_id 生成文本报告。
DECLARE
cap_id NUMBER;
cap_rpt CLOB;
BEGIN
cap_id := DBMS_WORKLOAD_CAPTURE.GET_CAPTURE_INFO(dir => 'jul14');
cap_rpt := DBMS_WORKLOAD_CAPTURE.REPORT(capture_id => cap_id,
format => DBMS_WORKLOAD_CAPTURE.TYPE_TEXT);
END;
/
查看工作负载捕获报告
工作负载捕获报告包含各种类型的信息,可用于评估工作负载捕获的有效性。使用此报告中提供的信息,您可以确定捕获的工作负载是否:
- 表示您要重放的实际工作负载
- 不包含您要排除的任何工作负载
- 可以重放
工作负载捕获报告中包含的信息分为以下几类:
- 有关工作负载捕获的详细信息(例如工作负载捕获的名称、定义的过滤器、日期、时间和捕获的 SCN)
- 有关工作负载捕获的总体统计信息(例如捕获的总数据库时间、捕获的登录和事务数)以及相对于总系统活动的相应百分比
- 捕获的工作负载的配置文件
- 由于版本限制未捕获的工作负载的配置文件
- 使用定义的过滤器排除的未捕获工作负载的配置文件
- 由后台进程或计划作业组成的未捕获工作负载的配置文件
使用工作负载重放报告
工作负载重放报告包含可用于衡量捕获系统和重放系统之间性能差异的信息。
使用 API 生成工作负载重放报告
您可以使用 DBMS_WORKLOAD_REPLAY 包生成工作负载重放报告。
要使用 API 为工作负载捕获生成有关最新工作负载重放的报告:
- 通过调用 DBMS_WORKLOAD_REPLAY.GET_REPLAY_INFO 函数从重放目录对象中检索有关工作负载捕获的信息和工作负载重放尝试的历史记录。GET_REPLAY_INFO 函数返回单个捕获目录的 cap_id(对于统一捕获目录,返回的 cap_id 为 0)
- 使用 GET_REPLAY_INFO 函数返回的 cap_id,运行查询以返回适当的 rep_id 以获取最新的工作负载重放
- 调用 DBMS_WORKLOAD_REPLAY.REPORT 函数。REPORT 函数使用 SELECT 语句返回的 rep_id 生成报告。REPORT 函数使用以下参数:
- replay_id 必需参数指定包含将为其生成报告的工作负载重放的目录。该目录应该是包含工作负载重放的主机系统中的有效目录。此参数的值应与先前查询返回的 rep_id 匹配
- format 参数必需参数指定报告格式。有效值包括 DBMS_WORKLOAD_REPLAY.TYPE_TEXT、DBMS_WORKLOAD_REPLAY.TYPE_HTML 和 DBMS_WORKLOAD_REPLAY.TYPE_XML
在此示例中,GET_REPLAY_INFO 函数从 jul14 重放目录对象中检索有关工作负载捕获的所有信息以及所有工作负载重放尝试的历史记录。该函数返回捕获目录的 cap_id,它可以与 DBA_WORKLOAD_REPLAYS 视图中的 CAPTURE_ID 列相关联以访问检索到的信息。SELECT 语句返回适当的 rep_id 以用于负载的最新重放。然后,REPORT 函数使用 SELECT 语句返回的 rep_id 生成 HTML 报告。
DECLARE
cap_id NUMBER;
rep_id NUMBER;
rep_rpt CLOB;
BEGIN
cap_id := DBMS_WORKLOAD_REPLAY.GET_REPLAY_INFO(replay_dir => 'jul14');
/* Get the latest replay for that capture */
SELECT max(id)
INTO rep_id
FROM dba_workload_replays
WHERE capture_id = cap_id;
rep_rpt := DBMS_WORKLOAD_REPLAY.REPORT(replay_id => rep_id,
format => DBMS_WORKLOAD_REPLAY.TYPE_HTML);
END;
/
查看工作负载重放报告
在测试系统上重放工作负载后,重放的内容与捕获的内容可能存在一些差异。有很多因素会导致回放发散,可以使用工作负载回放报告进行分析。工作负载重放报告中包含的信息包括性能和重放差异。当在重放系统中引入影响数据库整体性能的新算法时,可能会导致性能差异。例如,如果负载在较新版本的 Oracle 数据库上重放,新算法可能会导致特定请求运行得更快,而差异将表现为执行速度更快。在这种情况下,这是一个理想的背离。
当 DML 或 SQL 查询的结果与最初在工作负载中捕获的结果不匹配时,就会出现数据分歧。例如,重放期间 SQL 语句返回的行数可能少于捕获期间返回的行数。
重放数据库调用时出现错误分歧:
- 遇到一个新的没有被捕获的错误
- 没有遇到被捕获的错误
- 遇到与捕获的错误不同的错误
工作负载重放报告中包含的信息分为以下几类:
- 有关工作负载重放和工作负载捕获的详细信息,例如作业名称、状态、数据库信息、每个过程的持续时间和时间,以及目录对象和路径
- 为工作负载重放选择的重放选项和已启动的重放客户端数量
- 有关工作负载重放和工作负载捕获的总体统计信息(例如捕获和重放的总数据库时间,以及捕获和重放的登录和事务的数量)以及相对于总系统活动的相应百分比
- 重放工作负载的配置文件
- 重放分歧
- 误差发散
- DML 和 SQL 查询数据分歧
从 Oracle 数据库版本 19c 开始,负载重放报告提供了诊断负载重放缓慢所需的信息。工作负载重放报告中包含的信息包含以下附加部分:
- 重放会话
- 同步化
- 跟踪提交
- 会话失败
重放会话
Replay Sessions 部分包括有关正在进行和已完成的重放会话的统计信息,例如热门事件、最慢的重放会话和最快的重放会话。与正在进行的重放会话相关的统计信息仅在重放正在进行时显示。使用本节中的信息了解正在进行的和已完成的重放会话的主要事件、比捕获慢的重放会话,以及捕获和重放之间会话经过时间的比较。
同步化
在工作负载重放期间,捕获的 SQL 语句的执行顺序将被保留。当 SQL 语句的执行在重放期间被延迟或阻塞时,结果是工作负载重放速度变慢。
同步部分包含有关阻止执行同步 SQL 语句之一的会话的信息。此信息仅在 SQL 语句的执行被阻止时显示。使用本节中的信息了解工作负载重放被阻止或比工作负载捕获慢的原因。此部分还包括与运行同步 SQL 语句的会话相关的热门事件和热门 SQL 语句。
跟踪提交
数据库重放跟踪在工作负载捕获期间执行的提交以及它们执行之间消耗的时间。它可以检测缓慢的提交并识别捕获的工作负载中减慢工作负载重放的部分。
Tracked Commits 部分包含有关捕获的提交数量和执行提交时间的信息。使用此信息可以确定工作负载重放是否比工作负载捕获移动得慢。
会话失败
当用户会话的工作负载重放失败时,将跳过会话中剩余调用的重放。Session Failures 部分包括有关在会话失败期间执行的 SQL 语句、失败会话的文件 ID 和调用计数器以及未执行的调用总数的信息。
使用回放比较期间报告
回放比较周期报告可用于多种目的。例如,您可以使用回放比较期间报告来比较以下各项的性能:
- 工作负载重放到其工作负载捕获
- 一个工作负载重放到同一工作负载捕获的另一个重放
- 多个工作负载捕获到合并重放
使用 API 生成回放比较期间报告
本节介绍如何使用 DBMS_WORKLOAD_REPLAY 包生成回放比较周期报告。此报告仅比较包含至少 5 分钟数据库时间的工作负载重放。
要生成回放比较周期报告,请使用 DBMS_WORKLOAD_REPLAY.COMPARE_PERIOD_REPORT 过程:
BEGIN
DBMS_WORKLOAD_REPLAY.COMPARE_PERIOD_REPORT (
replay_id1 => 12,
replay_id2 => 17,
format => DBMS_WORKLOAD_CAPTURE.TYPE_HTML,
result => :report_bind);
END;
/
在此示例中,COMPARE_PERIOD_REPORT 过程生成一个 HTML 格式的重放比较周期报告,该报告将重放 ID 为 12 的工作负载重放与 ID 为 17 的另一个重放进行比较。
此示例中的 COMPARE_PERIOD_REPORT 过程使用以下参数:
- replay_id1 参数指定将为其生成报告的更改后工作负载重放的数字标识符。此参数是必需的
- replay_id2 参数指定将为其生成报告的更改前工作负载重放的数字标识符。如果未指定,比较将与工作负载捕获一起执行
- format 参数指定报告格式。有效值包括用于 HTML 的 DBMS_WORKLOAD_CAPTURE.TYPE_HTML 和用于 XML 的 DBMS_WORKLOAD_CAPTURE.TYPE_XML。此参数是必需的
- 结果参数指定报告的输出
查看回放比较期间报告
查看回放比较周期报告使您能够确定是否发生任何回放差异以及是否存在任何重大性能变化。
根据正在进行的比较类型,将生成三种类型的回放比较周期报告之一:
- 捕获与重放:此报告类型将工作负载重放的性能与其工作负载捕获的性能进行比较
- 重放与重放:此报告类型比较相同工作负载捕获的两个工作负载重放的性能
- 综合重放:此报告类型将多个工作负载捕获的性能与合并重放的性能进行比较。只有 ASH 数据比较部分可用于此报告类型
所有回放比较周期报告类型都包含有关正在比较的两次运行之间最重要变化的信息。使用此信息来确定要采取的适当操作。例如,如果发现新的并发问题,请查看自动数据库诊断监视器 (ADDM) 报告来诊断问题。如果发现新的 SQL 性能问题,运行 SQL Tuning Advisor 来解决问题。
回放比较周期报告中的信息分为以下部分:
- 一般信息
- 重放发散
- 主要业绩统计
- 热门 SQL/调用
- 硬件使用比较
- ADDM比较
- ASH 数据对比
一般信息
此部分包含有关报告中正在比较的两次运行的元数据。两次运行之间的任何 init.ora 参数更改也显示在这里。查看此部分以验证是否执行了正在测试的系统更改。
重放发散
本节包含第二次运行相对于第一次运行的分歧分析。如果分析显示出明显的分歧,请查看完整的分歧报告。
主要性能统计
本节包含两次运行的高级性能统计比较(例如数据库时间的变化)。如果比较显示数据库时间的变化很小,那么两次运行的性能通常是相似的。如果数据库时间发生重大变化,请查看统计信息以确定导致最大变化的组件(CPU 或用户 I/O)。
热门 SQL/调用
本节比较单个 SQL 语句从一次运行到下一次运行的性能变化。SQL 语句按数据库时间的总变化排序。大多数数据库时间倒退的顶级 SQL 语句是 SQL 调优的最佳候选者。
硬件使用比较
本节比较两次运行中的 CPU 和 I/O 使用情况。所有实例的 CPU 数量相加,CPU 使用率是实例的平均数。
显示数据和临时文件的 I/O 统计信息。单块读取时间的高值(远高于 10 毫秒)表明系统受 I/O 限制。如果是这种情况,则查看总读写时间以确定延迟是由过多的 I/O 请求还是低 I/O 吞吐量引起的。
ADDM比较
本节包含对按影响的绝对差异排序的两次运行的 ADDM 分析的比较。比较两次运行的 ADDM 结果,以确定仅在一次运行中存在的可能问题。如果正在测试的系统更改旨在提高数据库性能,则验证预期的改进是否反映在 ADDM 结果中。
ASH 数据对比
本节比较两次运行的 ASH 数据。比较期间的开始时间和结束时间显示在表格中。这些时间可能与所比较的两次运行的捕获和重放时间不匹配。相反,这些时间代表采集 ASH 样本的时间。ASH 数据比较部分包含以下小节:
- 比较总结
- TOP SQL
- 长时间运行的 SQL
- 常用SQL
- 顶级对象
比较总结
本节根据数据库时间和等待时间分布总结了两次运行期间的活动。例如:
-
DB Time Distribution 指示总数据库时间如何分布在 CPU 使用率、等待时间和 I/O 请求之间。
下图显示了示例报告的 DB Time Distribution 子部分:

-
Wait Time Distribution 表示总等待时间在等待事件中的分布情况。为两次运行列出了排名靠前的等待事件类、事件名称和事件计数。
下图显示了示例报告的等待时间分布部分:

TOP SQL
此部分按总数据库时间、CPU 时间和等待时间显示两次运行的排名靠前的 SQL 语句。
长时间运行的 SQL
此部分显示两次运行中排名靠前的长时间运行的 SQL 语句。每个长时间运行的 SQL 语句都包含有关查询的详细信息,例如最大、最小和平均响应时间。
常用SQL
此部分提取两次运行中常见的 SQL 语句,并按平均响应时间和总数据库时间的差异显示最常见的 SQL 语句。
TOP对象
此部分包含有关两次运行的总等待时间排名靠前的对象的详细信息。下图显示了示例报告的TOP对象部分:

使用 SQL 性能分析器报告
使用 SQL Performance Analyzer 报告将来自工作负载重放的 SQL 调整集与来自工作负载捕获的另一个 SQL 调整集或来自两个工作负载重放的两个 SQL 调整集进行比较。
将 SQL 调优集与数据库重放进行比较比 SQL Performance Analyzer test-execute 提供更多信息,因为它考虑并显示每个 SQL 语句的所有执行计划,而 SQL Performance Analyzer test-execute 仅为每个 SQL 试验的每个 SQL 语句生成一个执行计划。
使用 API 生成 SQL 性能分析器报告
本节介绍如何使用 DBMS_WORKLOAD_REPLAY 包生成 SQL 性能分析器报告。要生成 SQL 性能分析器报告,请使用 DBMS_WORKLOAD_REPLAY.COMPARE_SQLSET_REPORT 过程:
BEGIN
DBMS_WORKLOAD_REPLAY.COMPARE_SQLSET_REPORT (
replay_id1 => 12,
replay_id2 => 17,
format => DBMS_WORKLOAD_CAPTURE.TYPE_HTML,
result => :report_bind);
END;
/
在此示例中,COMPARE_SQLSET_REPORT 过程生成 HTML 格式的 SQL 性能分析器报告,该报告将重放 ID 为 12 的工作负载重放期间捕获的 SQL 调优集与 ID 为 17 的工作负载重放期间捕获的 SQL 调优集进行比较。
此示例中的 COMPARE_SQLSET_REPORT 过程使用以下参数:
- replay_id1 参数指定将为其生成报告的更改后工作负载重放的数字标识符。此参数是必需的
- replay_id2 参数指定将为其生成报告的更改后工作负载重放的数字标识符。如果未指定,比较将与工作负载捕获一起执行
- format 参数指定报告格式。有效值包括用于 HTML 的 DBMS_WORKLOAD_CAPTURE.TYPE_HTML、用于 XML 的 DBMS_WORKLOAD_CAPTURE.TYPE_XML 和用于文本的 DBMS_WORKLOAD_CAPTURE.TYPE_TEXT。此参数是必需的
- 结果参数指定报告的输出。
使用工作负载智能
工作负载智能分析存储在捕获的工作负载中的数据,并识别工作负载中的重要模式。
工作负载智能概述
工作负载捕获生成许多二进制文件(称为捕获文件),其中包含有关捕获的工作负载的相关信息。存储在捕获文件中的信息使工作负载重放能够在以后真实地再现捕获的工作负载。对于工作负载捕获记录的每个客户端请求,捕获的信息包括 SQL 文本、绑定值、事务信息、计时数据、访问对象的标识符以及有关请求的其他信息。
Workload Intelligence 使您能够以其他方式使用存储在捕获文件中的信息,包括以下方式:
- 分析和建模工作负载
- 发现工作负载中的重要模式和趋势
- 在工作负载捕获期间可视化生产系统上运行的内容
本节介绍工作负载智能并包含以下主题:
- 关于工作负载智能
- 工作负载智能用例
- 使用工作负载智能的要求
关于工作负载智能
Workload Intelligence 包含一套 Java 程序,使您能够分析存储在捕获的工作负载中的数据。这些 Java 程序对工作负载捕获期间记录的数据进行操作,以创建描述工作负载的模型。此模型可以帮助您识别作为工作负载的一部分执行的模板的重要模式。
一个模板代表一个只读的 SQL 语句,或者由一个或多个 SQL 语句组成的整个事务。如果两个 SQL 语句(或事务)表现出显着的相似性,则它们由相同的模板表示。
Workload Intelligence 使您能够通过探索模板模式和相应的 SQL 语句来更好地可视化捕获的工作负载。对于每个模式,您都可以查看重要的统计信息,例如给定模式的执行次数以及该模式在执行期间消耗的数据库时间。
工作负载智能用例
您可以使用工作负载智能来发现捕获的工作负载中的重要模式。
在生产系统中执行的 SQL 语句通常不是用户手动输入的,而是来自连接到数据库服务器的应用服务器上运行的一个或多个应用程序。应用程序中通常有有限数量的此类 SQL 语句。即使在特定语句的每次执行中使用不同的绑定值,它的 SQL 文本基本上保持不变。
根据用户对应用程序的输入,执行一个代码路径,其中包括一个或多个 SQL 语句,按照应用程序代码定义的给定顺序提交给数据库。频繁的用户操作对应于定期执行的应用程序代码路径。这种频繁执行的代码路径会生成 SQL 语句的频繁模式,这些语句由数据库按给定顺序执行。通过分析捕获的工作负载,Workload Intelligence 可以发现此类模式并将它们与相关的执行统计信息相关联。换句话说,工作负载智能使用存储在捕获文件中的信息来发现在工作负载捕获期间由生产系统中运行的应用程序的重要代码路径生成的模式。工作负载智能无需任何有关应用程序的信息即可执行此操作。
使用工作负载智能发现重要模式:
- 使您能够更好地可视化工作负载捕获期间数据库中运行的内容
- 提供可用于优化的更多信息
- 提供更好的上下文,因为 SQL 语句不是孤立的,而是组合在一起的
使用工作负载智能的要求
工作负载智能使用存储在捕获文件中的信息,不需要使用工作负载重放来执行工作负载。此外,Workload Intelligence 不需要任何用户模式、用户数据或与生产系统的连接。为避免生产系统中的任何开销,建议在已复制捕获文件的测试系统上使用工作负载智能,尤其是对于捕获的大型工作负载,因为运行工作负载智能可能会占用大量资源。
调用构成工作负载智能的 Java 程序所需的 Java 类打包在 $ORACLE_HOME/rdbms/jlib/dbrintelligence.jar 中。类路径中必须包含另外两个 jar 文件:$ORACLE_HOME/rdbms/jlib/dbrparser.jar 和 $ORACLE_HOME/jdbc/lib/ojdbc6.jar。
Workload Intelligence 还在内部使用一些 SYS 表和视图。
使用工作负载智能分析捕获的工作负载
本节介绍使用工作负载智能分析捕获的工作负载的步骤。例如:
要使用工作负载智能分析捕获的工作负载:
- 创建具有适当权限的数据库用户以使用工作负载智能
- 通过运行 LoadInfo Java 程序来创建新的工作负载智能作业
- 通过运行 BuildModel Java 程序生成描述工作负载的模型
- 通过运行 FindPatterns Java 程序来识别工作负载中出现的模板中的模式
- 通过运行 GenerateReport Java 程序生成报告以显示结果
为工作负载智能创建数据库用户
在使用 Workload Intelligence 之前,首先创建一个具有适当权限的数据库用户。
示例显示了如何创建可以使用工作负载智能的数据库用户:
-- 为工作负载智能创建数据库用户
create user workintusr identified by password;
grant create session to workintusr;
grant select,insert,alter on WI$_JOB to workintusr;
grant insert,alter on WI$_TEMPLATE to workintusr;
grant insert,alter on WI$_STATEMENT to workintusr;
grant insert,alter on WI$_OBJECT to workintusr;
grant insert,alter on WI$_CAPTURE_FILE to workintusr;
grant select,insert,alter on WI$_EXECUTION_ORDER to workintusr;
grant select,insert,update,delete,alter on WI$_FREQUENT_PATTERN to workintusr;
grant select,insert,delete,alter on WI$_FREQUENT_PATTERN_ITEM to workintusr;
grant select,insert,delete,alter on WI$_FREQUENT_PATTERN_METADATA to workintusr;
grant select on WI$_JOB_ID to workintusr;
grant execute on DBMS_WORKLOAD_REPLAY to workintusr;
创建工作负载智能作业
要创建工作负载智能作业,请使用 LoadInfo 程序。LoadInfo 是一个 Java 程序,它创建一个新任务来应用工作负载智能的算法。该程序解析捕获目录中包含的数据,并将运行工作负载智能所需的相关信息存储在内部表中。
LoadInfo 程序使用以下语法:
java oracle.dbreplay.workload.intelligence.LoadInfo -cstr connection_string -user username -job job_name -cdir capture_directory
java oracle.dbreplay.workload.intelligence.LoadInfo -version
java oracle.dbreplay.workload.intelligence.LoadInfo -usage
LoadInfo 程序支持以下选项:
-
-cstr
指定数据库的 JDBC 连接字符串,其中 Workload Intelligence 存储执行所需的信息和中间结果(例如,jdbc:oracle:thin@hostname:portnum:ORACLE_SID) -
-user
指定数据库用户名。用户必须具有特定权限才能使用 Workload Intelligence。有关创建具有适当权限的数据库用户的信息,请参阅“为工作负载智能创建数据库用户” -
-job
指定唯一标识工作负载智能作业的名称 -
-cdir
指定要由工作负载智能分析的捕获目录的操作系统路径 -
-version
显示 LoadInfo 程序的版本信息 -
-usage
显示 LoadInfo 程序的命令行选项
示例显示了如何使用 LoadInfo 程序创建名为 wijobsales 的工作负载智能作业:
-- 创建工作负载智能作业
java -classpath $ORACLE_HOME/rdbms/jlib/dbrintelligence.jar:
$ORACLE_HOME/rdbms/jlib/dbrparser.jar:
$ORACLE_HOME/jdbc/lib/ojdbc6.jar:
oracle.dbreplay.workload.intelligence.LoadInfo -job wijobsales -cdir
/test/captures/sales -cstr jdbc:oracle:thin:@myhost:1521:orcl -user workintusr
生成工作负载模型
要生成工作负载模型,请使用 BuildModel 程序。BuildModel 是一个 Java 程序,它从捕获的工作负载中读取数据(此数据必须由 LoadInfo 程序生成)并生成描述工作负载的模型。然后可以使用此模型来识别工作负载中出现的频繁模板模式。
BuildModel 程序使用以下语法:
java oracle.dbreplay.workload.intelligence.BuildModel -cstr connection_string -user username -job job_name
java oracle.dbreplay.workload.intelligence.BuildModel -version
java oracle.dbreplay.workload.intelligence.BuildModel -usage
BuildModel 程序支持以下选项:
- -cstr
指定数据库的 JDBC 连接字符串,其中 Workload Intelligence 存储执行所需的信息和中间结果(例如,jdbc:oracle:thin@hostname:portnum:ORACLE_SID) - -user
指定数据库用户名。用户必须具有特定权限才能使用 Workload Intelligence。有关创建具有适当权限的数据库用户的信息,请参阅“为工作负载智能创建数据库用户” - -job
指定唯一标识工作负载智能作业的名称 - -version
显示 BuildModel 程序的版本信息 - -usage
显示 BuildModel 程序的命令行选项
示例显示了如何使用 BuildModel 程序生成工作负载模型:
-- 生成工作负载模型
java -classpath $ORACLE_HOME/rdbms/jlib/dbrintelligence.jar:
$ORACLE_HOME/rdbms/jlib/dbrparser.jar:
$ORACLE_HOME/jdbc/lib/ojdbc6.jar:
oracle.dbreplay.workload.intelligence.BuildModel -job wijobsales -cstr
jdbc:oracle:thin:@myhost:1521:orcl -user workintusr
识别工作负载中的模式
要识别工作负载中的模式,请使用FindPatterns程序。FindPatterns是一个Java程序,它从捕获的工作负载(此数据必须由LoadInfo程序生成)及其相应的工作负载模型(工作负载模型必须由BuildModel程序生成)中读取数据,并识别工作负载中频繁出现的模板模式。
FindPatterns 程序使用以下语法:
java oracle.dbreplay.workload.intelligence.FindPatterns -cstr connection_string
-user username -job job_name -t threshold
java oracle.dbreplay.workload.intelligence.FindPatterns -version
java oracle.dbreplay.workload.intelligence.FindPatterns -usage
FindPatterns 程序支持以下选项:
- -cstr
指定数据库的 JDBC 连接字符串,其中 Workload Intelligence 存储执行所需的信息和中间结果(例如,jdbc:oracle:thin@hostname:portnum:ORACLE_SID) - -user
指定数据库用户名。用户必须具有特定权限才能使用 Workload Intelligence。有关创建具有适当权限的数据库用户的信息,请参阅“为工作负载智能创建数据库用户” - -job
指定唯一标识工作负载智能作业的名称 - -t
指定阈值概率,定义从一个模板到下一个模板的转换何时是同一模式的一部分或两个模式之间的边界。有效值包括 [0.0, 1.0] 范围内的实数。设置这个值是可选的;它的默认值为 0.5 - -version
显示 FindPatterns 程序的版本信息 - -usage
显示 FindPatterns 程序的命令行选项
示例显示了如何使用 FindPatterns 程序识别工作负载中的频繁模板模式:
-- 识别工作负载中的模式
java -classpath $ORACLE_HOME/rdbms/jlib/dbrintelligence.jar:
$ORACLE_HOME/rdbms/jlib/dbrparser.jar:
$ORACLE_HOME/jdbc/lib/ojdbc6.jar:
oracle.dbreplay.workload.intelligence.FindPatterns -job wijobsales -cstr
jdbc:oracle:thin:@myhost:1521:orcl -user workintusr -t 0.2
生成工作负载智能报告
要生成工作负载智能报告,请使用 GenerateReport 程序。GenerateReport 是一个 Java 程序,它生成报告以显示工作负载智能的结果。工作负载智能报告是一个 HTML 页面,显示在工作负载中识别的模式。
GenerateReport 程序使用以下语法:
java oracle.dbreplay.workload.intelligence.GenerateReport -cstr connection_string
-user username -job job_name -top top_patterns -out filename
java oracle.dbreplay.workload.intelligence.GenerateReport -version
java oracle.dbreplay.workload.intelligence.GenerateReport -usage
GenerateReport 程序支持以下选项:
- -cstr
指定数据库的 JDBC 连接字符串,其中 Workload Intelligence 存储执行所需的信息和中间结果(例如,jdbc:oracle:thin@hostname:portnum:ORACLE_SID) - -user
指定数据库用户名。用户必须具有特定权限才能使用 Workload Intelligence。有关创建具有适当权限的数据库用户的信息,请参阅“为工作负载智能创建数据库用户” - -job
指定唯一标识工作负载智能作业的名称 - -top
指定一个数字,指示要在报告中显示多少模式。这些模式按不同的标准(执行次数、数据库时间和长度)排序,并且仅显示定义数量的最佳结果。设置这个值是可选的;它的默认值为 10 - -out
指定存储报告的文件名(HTML 格式)。设置这个值是可选的;它的默认值基于 -job 选项中指定的作业名称 - -version
显示 GenerateReport 程序的版本信息 - -usage
显示 GenerateReport 程序的命令行选项
示例显示了如何使用 GenerateReport 程序生成工作负载智能报告:
-- 生成工作负载智能报告
java -classpath $ORACLE_HOME/rdbms/jlib/dbrintelligence.jar:
$ORACLE_HOME/rdbms/jlib/dbrparser.jar:
$ORACLE_HOME/jdbc/lib/ojdbc6.jar:
oracle.dbreplay.workload.intelligence.GenerateReport -job wijobsales -cstr
jdbc:oracle:thin:@myhost:1521:orcl -user workintusr -top 5 -out wijobsales.html
示例:工作负载智能结果
本节假设一个场景,其中在 Swingbench 生成的捕获工作负载上使用工作负载智能,Swingbench 是一种用于对 Oracle 数据库进行压力测试的基准。
Workload Intelligence 发现的最重要的模式包括以下 6 个模板:
SELECT product_id, product_name, product_description, category_id, weight_class,
supplier_id, product_status, list_price, min_price, catalog_url
FROM product_information
WHERE product_id = :1;
SELECT p.product_id, product_name, product_description, category_id, weight_class,
supplier_id, product_status, list_price, min_price, catalog_url,
quantity_on_hand, warehouse_id
FROM product_information p, inventories i
WHERE i.product_id = :1 and i.product_id = p.product_id;
INSERT INTO order_items (order_id, line_item_id, product_id, unit_price, quantity)
VALUES (:1, :2, :3, :4, :5);
UPDATE orders
SET order_mode = :1, order_status = :2, order_total = :3
WHERE order_id = :4;
SELECT /*+ use_nl */ o.order_id, line_item_id, product_id, unit_price, quantity,
order_mode, order_status, order_total, sales_rep_id, promotion_id,
c.customer_id, cust_first_name, cust_last_name, credit_limit, cust_email
FROM orders o, order_items oi, customers c
WHERE o.order_id = oi.order_id
AND o.customer_id = c.customer_id
AND o.order_id = :1;
UPDATE inventories
SET quantity_on_hand = quantity_on_hand - :1
WHERE product_id = :2
AND warehouse_id = :3;
此模式对应于订购产品的常见用户操作。在此示例中,已识别的模式执行了 222,261 次(或执行总数的大约 8.21%)并消耗了 58,533.70 秒的 DB 时间(或大约 DB 总时间的 11.21%)。
Workload Intelligence 在此示例中发现的另一个重要模式包括以下 4 个模板:
SELECT customer_seq.nextval
FROM dual;
INSERT INTO customers (customer_id, cust_first_name, cust_last_name, nls_language,
nls_territory, credit_limit, cust_email, account_mgr_id)
VALUES (:1, :2, :3, :4, :5, :6, :7, :8);
INSERT INTO logon
VALUES (:1, :2);
SELECT customer_id, cust_first_name, cust_last_name, nls_language, nls_territory,
credit_limit, cust_email, account_mgr_id
FROM customers
WHERE customer_id = :1;
此模式对应于创建新的客户帐户,然后在系统中登录。在此示例中,识别的模式执行了 90,699 次(或执行总数的大约 3.35%)并消耗了 17,484.97 秒的 DB 时间(或大约 DB 总时间的 3.35%)。
使用统一数据库重放
数据库重放使您能够捕获生产系统上的工作负载并在测试系统上重放它。这在评估或采用新的数据库技术时非常有用,因为这些更改可以在测试系统上进行测试,而不会影响生产系统。但是,如果被测试的新系统提供比现有系统明显更好的性能,那么数据库重放可能无法准确预测新系统可以处理多少额外的工作负载。
例如,如果您将多个生产系统整合到一台Oracle Exadata Machine中,则在Oracle Exadata Machine上回放从现有系统之一捕获的工作负载可能会导致在回放过程中资源使用率(如主机CPU和I/O)大大降低,因为新系统的功能要强大得多。在这种情况下,更有用的是评估新系统将如何处理来自所有现有系统的组合工作负载,而不是来自一个系统的单个工作负载。
合并数据库重放使您能够合并从一个或多个系统捕获的多个工作负载,并在单个测试系统上同时重放它们。在此示例中,使用整合数据库重放将帮助您评估数据库整合将如何影响生产系统,以及单个 Oracle Exadata Machine 是否可以处理来自整合数据库的组合负载。
合并数据库重放的用例
Consolidated Database Replay 使您能够同时重放从一个或多个系统捕获的多个工作负载。在重放期间,合并的每个工作负载捕获都将在合并重放开始时开始重放。
Consolidated Database Replay 的一些典型用例包括:
- 使用可插拔数据库进行数据库整合
- 压力测试
- 放大测试
这些用例中的每一个都可以使用本章中描述的过程来执行。此外,您可以在使用合并数据库重放时采用各种工作负载扩展技术,如使用工作负载扩展中所述。
使用可插拔数据库进行数据库整合
Consolidated Database Replay 的一个用途是评估系统是否可以处理来自数据库整合的组合工作负载。
例如,假设您希望通过将 CRM、ERP 和 SCM 应用程序的数据库迁移到可插拔数据库 (PDB) 来整合它们。您可以使用 Consolidated Database Replay 组合从三个应用程序捕获的工作负载,并在 PDB 上同时重放它们。
压力测试
Consolidated Database Replay 的另一个用途是压力测试或容量规划。
例如,假设您预计 Sales 应用程序的工作负载在假期期间会增加一倍。您可以使用 Consolidated Database Replay 来测试系统上增加的压力,方法是将工作负载加倍并重放组合的工作负载。
放大测试
Consolidated Database Replay 的第三个用途是扩展测试。
例如,假设您想要测试您的系统是否可以同时处理从 Financials 应用程序和 Orders 应用程序捕获的工作负载。您可以使用 Consolidated Database Replay 通过组合工作负载并同时重放它们来测试扩展工作负载对系统的影响。
使用统一数据库重放的步骤
本节介绍使用 Consolidated Workload Replay 时涉及的步骤。它包含以下主题:
- 为整合数据库重放捕获数据库工作负载
- 为合并数据库重放设置测试系统
- 为整合数据库重放预处理数据库工作负载
- 为合并数据库重放重放数据库工作负载
- 合并数据库重放的报告和分析
为整合数据库重放捕获数据库工作负载
Consolidated Database Replay 不需要任何特殊步骤来捕获数据库工作负载。捕获数据库工作负载的步骤与捕获数据库重放的单个工作负载的步骤完全相同,如捕获数据库工作负载中所述。
本节包含以下特定于统一数据库重放的工作负载捕获主题:
- 支持的工作负载捕获类型
- 捕获子集
支持的工作负载捕获类型
Consolidated Database Replay 支持从在一个或多个操作系统上运行 Oracle Database 9i 第 2 版(9.2.0.8.0 版)或更高版本的一个或多个系统捕获多个负载。例如,您可以使用从在 HP-UX 上运行 Oracle 数据库 9i 第 2 版(9.2.0.8.0 版)的一个系统和在 AIX 上运行 Oracle 数据库 10g 第 2 版(10.2.0.4.0 版)的另一个系统捕获的工作负载。
注意:合并数据库重放仅适用于 Oracle Database 11g 第 2 版(11.2.0.2.0 版)及更高版本。
捕获子集
Consolidated Database Replay使您能够将现有的工作负载捕获转换为新的、更小的捕获子集。然后,您可以从捕获子集生成新的工作负载捕获,这些捕获子集可以在不同的用例中使用,如“Consolidated Database Replay的用例”中所述。
捕获子集是通过应用时间范围从现有工作负载捕获中定义的工作负载捕获的一部分。时间范围被指定为从工作负载捕获开始的偏移量。在指定的时间范围内捕获的所有用户工作负载都包含在定义的捕获子集中。
例如,假设工作负载是从凌晨2点到晚上8点捕获的,峰值工作负载被确定为从上午10点到下午4点。您可以定义一个捕获子集来表示峰值工作负载,方法是应用一个时间范围,该时间范围从工作负载开始后8小时(或上午10点)开始,到工作负载开始前14小时(或下午4点)结束。
但是,如果捕获子集仅包含满足指定时间范围的已记录用户工作负载,则不会记录在指定时间范围之前发生的用户登录。如果重放需要这些用户登录,则捕获子集可能不可重放。例如,如果用户会话从上午9:30开始,到上午10:30结束,并且捕获子集的指定时间范围是上午10:00到下午4:00,则如果上午9:30的用户登录不包括在工作负载中,则回放可能失败。类似地,指定的时间范围也可能包括不完整的用户调用,如果用户会话在下午3:30开始,但直到下午4:30才完成,则仅部分记录这些用户调用。
Consolidated Database Replay通过只包括由指定时间范围的开始时间引起的不完整的用户调用来解决此问题。为了避免在折叠工作负载捕获时两次包含相同的不完整用户调用,默认情况下不包括由结束时间引起的不完整的用户调用。因此,捕获子集本质上是在指定的时间范围内记录的正确重放所需的最小用户调用数,包括必要的用户登录、更改会话语句和由开始时间引起的不完整的用户调用。
为合并数据库重放设置测试系统
为 Consolidated Database Replay 设置测试系统类似于为 Database Replay 设置测试系统。但是,在为 Consolidated Database Replay 设置重放数据库时还有一些额外的注意事项。有关为数据库重放设置测试系统的更多信息,请参阅“重放数据库工作负载的步骤”。
为了最大限度地减少重放期间的差异,测试系统应包含相同的应用程序数据,并且应用程序数据的状态在逻辑上应与每次工作负载捕获开始时的捕获系统的状态相同。但是,由于合并捕获可能包含来自不同生产系统的多个工作负载捕获,因此需要为所有捕获设置测试系统。在这种情况下,建议使用多租户架构来整合多个数据库,以便每个数据库在捕获开始时都具有与其捕获系统等效的数据。
对于合并数据库重放,所有参与的工作负载捕获必须放置在测试系统上的新捕获目录下。您可以将所有工作负载捕获复制到新的捕获目录中,或创建指向原始工作负载捕获的符号链接。在整合工作负载捕获之前,确保新的捕获目录有足够的磁盘空间来存储所有参与的捕获。
下图说明了如何设置测试系统和新的捕获目录以整合三个工作负载捕获:

为整合数据库重放预处理数据库工作负载
为 Consolidated Database Replay 预处理数据库工作负载类似于为 Database Replay 预处理数据库工作负载。 有关为数据库重放预处理数据库工作负载的信息,请参阅“预处理数据库工作负载”。
对于合并数据库重放,将每个捕获的工作负载预处理到其自己的目录中。不要将不同的工作负载捕获合并到一个目录中进行预处理。捕获的负载的预处理必须使用与将重放负载的测试系统运行相同版本的 Oracle 数据库的数据库来执行。
为合并数据库重放重放数据库工作负载
使用合并数据库重放重放合并工作负载与使用数据库重放重放单个数据库工作负载有很大不同。
本节包含以下主题,用于重放特定于统一数据库重放的工作负载:
- 定义重放计划
- 重新映射合并数据库重放的连接
- 为合并数据库重放重新映射用户
- 准备合并数据库重放
- 重放单个工作负载
定义重放计划
重放计划将一个或多个工作负载捕获添加到合并的重放中,并指定捕获在重放期间开始的顺序。必须先创建重放计划,然后才能初始化合并重放。可以为合并重放定义多个重放计划。在重放初始化期间,您可以从任何现有的重放计划中进行选择。
重放计划执行两种类型的操作:
- 添加工作负载捕获
- 添加计划订单
添加工作负载捕获
重放计划执行的第一类操作是将参与的工作负载捕获添加到重放。
将工作负载捕获添加到重放计划时,将返回一个唯一编号以标识工作负载捕获。工作负载捕获可以多次添加到重放计划中,因为每次添加时都会为其分配一个不同的捕获编号。重放计划每次都会指向相同的捕获目录,以避免每次添加捕获时都复制捕获而浪费磁盘空间。
添加计划订单
重放计划执行的第二种操作是添加计划顺序,指定参与工作负载捕获在重放期间开始的顺序。
计划顺序定义已添加到重放计划的两个工作负载捕获开始之间的顺序。可以将多个计划顺序添加到重放计划中。例如,假设重放计划添加了三个工作负载捕获。可以添加一个调度顺序来指定 Capture 2 必须等待 Capture 1 完成才能开始。可以添加另一个计划顺序以指定 Capture 3 必须等待 Capture 1 完成才能开始。在这种情况下,Capture 2 和 Capture 3 都必须等待 Capture 1 完成才能开始。
重放计划可能不包含任何计划顺序。在这种情况下,重放计划中所有参与的工作负载捕获将在合并重放开始时同时开始重放。
重新映射合并数据库重放的连接
与使用数据库重放重放单个数据库工作负载的情况一样,捕获的用于连接到生产系统的连接字符串需要重新映射到重放系统。有关详细信息,请参阅“连接重新映射”。
对于合并数据库重放,您需要在重放期间将捕获的连接字符串从多个工作负载捕获重新映射到不同的连接字符串。
为合并数据库重放重新映射用户
与使用数据库重放重放单个数据库工作负载的情况一样,数据库用户的用户名和用于连接到生产系统的模式可以在重放期间重新映射。有关详细信息,请参阅“用户重新映射”。
对于合并数据库重放,您可以选择在重放期间将捕获的用户从多个工作负载捕获重新映射到不同的用户或模式。
准备合并数据库重放
与使用数据库重放重放单个数据库工作负载的情况一样,重放选项是在准备重放期间定义的。有关详细信息,请参阅“指定重放选项”。
对于合并数据库重放,合并重放中所有参与的工作负载捕获在重放期间使用在重放准备期间定义的相同重放选项。
重放单个工作负载
建议在重放合并的工作负载之前单独重放每个参与的工作负载。有关详细信息,请参阅“重放数据库工作负载”。
单独的回放可以为每个工作负载捕获建立基准性能,并用于分析合并回放的性能。
合并数据库重放的报告和分析
合并数据库重放的报告和分析是使用重放比较周期报告执行的。有关详细信息,请参阅“使用重放比较期间报告”。
合并数据库重放的重放比较周期报告识别每个单独的工作负载捕获的活动会话历史记录 (ASH) 数据,并将来自工作负载捕获的 ASH 数据与来自合并重放的过滤后的 ASH 数据进行比较。使用此报告比较同一整合工作负载捕获的回放。
合并数据库重放的重放比较周期报告将合并重放视为多次捕获与重放比较。报告的摘要部分包含一个表格,该表格总结了所有单独的捕获与重放比较。
图 15-2 显示了合并数据库重放的示例重放比较周期报告的摘要部分:

报告中的其余部分类似于回放比较期间报告的 ASH 数据比较部分,并且是通过在合并回放中加入所有捕获与回放报告而形成的。
将合并数据库重放与 API 结合使用
本节介绍如何使用 DBMS_WORKLOAD_REPLAY 包创建和重放整合的工作负载。
使用 API 创建和重放整合工作负载是一个多步骤过程,涉及:
- 使用 API 生成捕获子集
- 使用 API 设置合并重放目录
- 使用 API 定义重放计划
- 使用 API 运行合并数据库重放
使用 API 生成捕获子集
本节介绍如何使用 DBMS_WORKLOAD_REPLAY 包从现有工作负载捕获生成捕获子集。有关捕获子集的信息,请参阅“捕获子集”。
从现有工作负载捕获生成捕获子集:
- 使用 GENERATE_CAPTURE_SUBSET 过程:
DBMS_WORKLOAD_REPLAY.GENERATE_CAPTURE_SUBSET (
input_capture_dir IN VARCHAR2,
output_capture_dir IN VARCHAR2,
new_capture_name IN VARCHAR2,
begin_time IN NUMBER,
begin_include_incomplete IN BOOLEAN DEFAULT TRUE,
end_time IN NUMBER,
end_include_incomplete IN BOOLEAN DEFAULT FALSE,
parallel_level IN NUMBER DEFAULT NULL);
- 将 input_capture_dir 参数设置为指向现有工作负载捕获的目录对象的名称
- 将 output_capture_dir 参数设置为指向将存储新工作负载捕获的空目录的目录对象的名称
- 将 new_capture_name 参数设置为要生成的新工作负载捕获的名称
- 根据需要设置其他可选参数
此示例说明如何根据目录对象 rec_dir 中的现有工作负载捕获在目录对象 peak_capdir 中创建名为 peak_wkld 的捕获子集。捕获子集包括从工作负载捕获开始后 2 小时(或 7,200 秒)到工作负载捕获开始后 3 小时(或 10,800 秒)的工作负载。
EXEC DBMS_WORKLOAD_REPLAY.GENERATE_CAPTURE_SUBSET ('rec_dir', 'peak_capdir',
'peak_wkld', 7200, TRUE, 10800, FALSE, 1);
使用 API 设置合并重放目录
本节介绍如何使用 DBMS_WORKLOAD_REPLAY 包在测试系统上设置统一重放目录。将合并重放目录设置为测试系统上包含要合并和重放的工作负载捕获的目录。
设置回放目录:
- 使用 SET_CONSOLIDATED_DIRECTORY 过程:
DBMS_WORKLOAD_REPLAY.SET_CONSOLIDATED_DIRECTORY (
replay_dir IN VARCHAR2);
- 将 replay_dir 参数设置为目录对象的名称,该目录对象指向包含要用于工作负载整合的工作负载捕获的操作系统目录
提示:SET_REPLAY_DIRECTORY 过程已弃用并由 SET_CONSOLIDATED_DIRECTORY 过程取代。
-- 此示例说明如何将重放目录设置为名为 rep_dir 的目录对象
EXEC DBMS_WORKLOAD_REPLAY.SET_CONSOLIDATED_DIRECTORY ('rep_dir');
您还可以使用 DBMS_WORKLOAD_REPLAY 程序包来查看已由 SET_CONSOLIDATED_DIRECTORY 过程设置的当前合并重放目录。
查看当前已设置的统一重放目录:
- 使用 GET_REPLAY_DIRECTORY 函数:
DBMS_WORKLOAD_REPLAY.GET_REPLAY_DIRECTORY RETURN VARCHAR2;
如果未设置统一重放目录,则该函数返回 NULL。
使用 API 定义重放计划
本节介绍如何使用 DBMS_WORKLOAD_REPLAY 包定义重放计划。有关重放计划的信息,请参阅“定义重放计划”。
在定义重放计划之前,请确保满足以下先决条件:
- 所有工作负载捕获都使用 PROCESS_CAPTURE 过程在运行与重放系统相同的数据库版本的系统上进行预处理,如预处理数据库工作负载中所述
- 所有捕获目录都复制到重放系统上的重放目录
- 重放目录是使用 SET_REPLAY_DIRECTORY 过程设置的,如“使用 API 设置统一重放目录”中所述
- 数据库状态未处于重放模式
要定义重放计划:
- 创建一个新的重放计划
- 将工作负载捕获添加到重放计划
- 将计划订单添加到重放计划
- 保存重放计划
使用 API 创建重放计划
本节介绍如何使用 DBMS_WORKLOAD_REPLAY 包创建重放计划。
要创建重放计划:
- 使用 BEGIN_REPLAY_SCHEDULE 过程:
DBMS_WORKLOAD_REPLAY.BEGIN_REPLAY_SCHEDULE (
schedule_name IN VARCHAR2);
- 将 schedule_name 参数设置为此重放计划的名称
注意:BEGIN_REPLAY_SCHEDULE 过程会启动可重用重放计划的创建。一次只能定义一个重放计划。在定义重放计划时再次调用此过程将导致错误。
此示例说明如何创建名为 peak_schedule 的重放计划:
EXEC DBMS_WORKLOAD_REPLAY.BEGIN_REPLAY_SCHEDULE ('peak_schedule');
使用 API 将工作负载捕获添加到重放计划
本节介绍如何使用 DBMS_WORKLOAD_REPLAY 包将工作负载捕获添加到重放计划以及从重放计划中删除工作负载捕获。有关将工作负载捕获添加到重放计划的信息,请参阅“添加工作负载捕获”。
在将工作负载捕获添加到重放计划之前,请确保满足以下先决条件:
- 创建工作负载捕获要添加到的重放计划。
将工作负载捕获添加到重放计划:
- 使用 ADD_CAPTURE 函数:
DBMS_WORKLOAD_REPLAY.ADD_CAPTURE (
capture_dir_name IN VARCHAR2,
start_delay_seconds IN NUMBER DEFAULT 0,
stop_replay IN BOOLEAN DEFAULT FALSE,
take_begin_snapshot IN BOOLEAN DEFAULT FALSE,
take_end_snapshot IN BOOLEAN DEFAULT FALSE,
query_only IN BOOLEAN DEFAULT FALSE)
RETURN NUMBER;
DBMS_WORKLOAD_REPLAY.ADD_CAPTURE (
capture_dir_name IN VARCHAR2,
start_delay_seconds IN NUMBER,
stop_replay IN VARCHAR2,
take_begin_snapshot IN VARCHAR2 DEFAULT 'N',
take_end_snapshot IN VARCHAR2 DEFAULT 'N',
query_only IN VARCHAR2 DEFAULT 'N')
RETURN NUMBER;
此函数返回一个唯一标识符,用于标识此重放计划中的工作负载捕获。
注意:仅查询数据库重放旨在仅在测试环境中使用和执行。
- 不要在生产系统上使用仅查询数据库重放
- 在仅查询数据库重放期间预计会出现分歧
-
将 capture_dir_name 参数设置为指向顶级重放目录下工作负载捕获的目录对象的名称。该目录必须包含一个有效的工作负载捕获,该工作负载捕获是在运行与重放系统相同的数据库版本的系统上进行预处理的
-
根据需要设置其他可选参数
-- 以下示例显示如何通过在 SELECT 语句中使用 ADD_CAPTURE 函数将名为 peak_wkld 的工作负载捕获添加到重放计划。
SELECT DBMS_WORKLOAD_REPLAY.ADD_CAPTURE ('peak_wkld')
FROM dual;
您还可以使用 DBMS_WORKLOAD_REPLAY 程序包从重放计划中删除工作负载捕获。
要从重放计划中删除工作负载捕获:
- 使用 REMOVE_CAPTURE 过程:
DBMS_WORKLOAD_REPLAY.REMOVE_CAPTURE (
schedule_capture_number IN NUMBER);
- 将 schedule_capture_number 参数设置为标识此重放计划中的工作负载捕获的唯一标识符。唯一标识符与将工作负载捕获添加到重放计划时 ADD_CAPTURE 函数返回的标识符相同。
使用 API 将计划订单添加到重放计划
本节介绍如何使用 DBMS_WORKLOAD_REPLAY 包向回放计划添加计划订单和从回放计划中删除计划订单。有关将计划订单添加到重放计划的信息,请参阅“添加计划订单”。
在将计划订单添加到重放计划之前,请确保满足以下先决条件:
- 创建要添加计划订单的重放计划
- 参与计划顺序的所有工作负载捕获都添加到重放计划中
注意:将计划订单添加到重放计划是可选的。如果您不向重放计划添加计划顺序,则添加到重放计划的所有工作负载捕获将在合并重放开始时同时开始重放。
将计划订单添加到重放计划:
- 使用 ADD_SCHEDULE_ORDERING 函数:
DBMS_WORKLOAD_REPLAY.ADD_SCHEDULE_ORDERING (
schedule_capture_id IN NUMBER,
waitfor_capture_id IN NUMBER)
RETURN NUMBER;
此函数在已添加到重放计划的两个工作负载捕获之间添加计划顺序。如果无法添加计划订单,它会返回一个非零错误代码
- 将 schedule_capture_id 参数设置为您要在此调度顺序中等待的工作负载捕获
- 将 wait_for_capture_id 参数设置为您希望在此调度顺序中开始其他工作负载捕获之前完成的工作负载捕获
您还可以使用 DBMS_WORKLOAD_REPLAY 程序包从重放计划中删除计划顺序。
要从重放计划中删除计划顺序:
- 使用 REMOVE_SCHEDULE_ORDERING 过程:
DBMS_WORKLOAD_REPLAY.REMOVE_SCHEDULE ORDERING (
schedule_capture_id IN VARCHAR2,
wait_for_capture_id IN VARCHAR2);
- 将 schedule_capture_id 参数设置为在此调度顺序中等待的工作负载捕获
- 将 wait_for_capture_id 参数设置为需要在其他工作负载捕获可以按此调度顺序开始之前完成的工作负载捕获
查看计划订单:
- 使用 DBA_WORKLOAD_SCHEDULE_ORDERING 视图。
使用 API 保存重放计划
本节介绍如何保存使用 DBMS_WORKLOAD_REPLAY 包定义的重放计划。
在保存重放计划之前,请确保满足以下先决条件:
- 创建将被保存的重放计划
- 参与计划顺序的所有工作负载捕获都添加到重放计划中
- 您要使用的任何计划订单都会添加到重放计划中(此步骤是可选的)
要保存重放计划:
- 使用 END_REPLAY_SCHEDULE 过程:
DBMS_WORKLOAD_REPLAY.END_REPLAY_SCHEDULE;
此过程完成重放计划的创建。重放计划已保存并与重放目录相关联。保存回放计划后,您可以将其用于合并回放。
查看重放时间表:
- 使用 DBA_WORKLOAD_REPLAY_SCHEDULES 视图。
使用 API 运行合并数据库重放
本节介绍如何使用 DBMS_WORKLOAD_REPLAY 程序包运行合并数据库重放。
在运行合并数据库重放之前,确保满足以下先决条件:
- 所有工作负载捕获都使用 PROCESS_CAPTURE 过程在运行与重放系统相同的数据库版本的系统上进行预处理,如预处理数据库工作负载中所述
- 所有捕获目录都复制到重放系统上的重放目录
- 重放目录是使用 SET_REPLAY_DIRECTORY 过程设置的,如“使用 API 设置统一重放目录”中所述
- 在所有工作负载捕获开始时,数据库在逻辑上恢复到与所有捕获系统相同的应用程序状态
运行合并数据库重放:
- 初始化重放数据
- 重新映射连接字符串
- 重新映射用户,重新映射用户是可选的
- 准备合并重放
- 设置并启动重放客户端
- 启动合并重放
- 生成报告并执行分析
使用 API 初始化合并数据库重放
本节介绍如何使用 DBMS_WORKLOAD_REPLAY 包为合并重放初始化重放数据。
初始化回放数据执行以下操作:
- 将数据库状态置于初始化模式以重放合并的工作负载
- 指向包含参与重放计划的所有工作负载捕获的重放目录
- 将必要的元数据加载到重放所需的表中。例如,捕获的连接字符串被加载到一个表中,可以在其中重新映射它们以进行重放
初始化合并数据库重放:
- 使用 INITIALIZE_CONSOLIDATED_REPLAY 过程:
DBMS_WORKLOAD_REPLAY.INITIALIZE_CONSOLIDATED_REPLAY (
replay_name IN VARCHAR2,
schedule_name IN VARCHAR2,
plsql_mode IN VARCHAR2 DEFAULT 'TOP_LEVEL');
- 将 replay_name 参数设置为合并重放的名称
- 将 schedule_name 参数设置为要使用的重放计划的名称。schedule_name 参数是创建期间使用的重放计划的名称
可选的 plsql_mode 参数指定 PL/SQL 重放模式。
可以为 plsql_mode 参数设置这两个值:
- top_level:仅顶级 PL/SQL 调用。 这是默认值
- extended:如果里面没有记录SQL,则在PL/SQL或顶层PL/SQL中执行的SQL。所有捕获都必须在
extendedPL/SQL 模式下完成。非 PL/SQL 调用将以通常的方式重放
-- 以下示例显示如何使用名为 peak_schedule 的重放计划初始化名为 peak_replay 的合并重放
EXEC DBMS_WORKLOAD_REPLAY.INITIALIZE_CONSOLIDATED_REPLAY ('peak_replay',
'peak_schedule');
使用 API 重新映射连接
本节介绍如何使用 DBMS_WORKLOAD_REPLAY 包重新映射连接字符串以进行合并重放。
重新映射连接字符串:
- 使用 REMAP_CONNECTION 过程:
DBMS_WORKLOAD_REPLAY.REMAP_CONNECTION (
schedule_cap_id IN NUMBER,
connection_id IN NUMBER,
replay_connection IN VARCHAR2);
此过程将捕获的连接重新映射到重放计划中所有参与工作负载捕获的新连接字符串。
2. 将 schedule_capture_id 参数设置为当前重放计划中的参与工作负载捕获。schedule_capture_id 参数是将工作负载捕获添加到重放计划时返回的唯一标识符,如“使用 API 添加工作负载捕获到重放计划”中所述
3. 将 connection_id 参数设置为要重新映射的连接。connection_id 参数在重放数据初始化时生成,对应于工作负载捕获的连接
4. 将 replay_connection 参数设置为将在重放期间使用的新连接字符串
使用 API 重新映射用户
本节介绍如何使用 DBMS_WORKLOAD_REPLAY 包重新映射用户以进行合并重放。
在重新映射用户之前,请确保满足以下先决条件:
- 重放数据已初始化,如“使用 API 初始化合并数据库重放”中所述
- 数据库状态未处于重放模式
重新映射用户:
- 使用 SET_USER_MAPPING 过程:
DBMS_WORKLOAD_REPLAY.SET_USER_MAPPING (
schedule_cap_id IN NUMBER,
capture_user IN VARCHAR2,
replay_user IN VARCHAR2);
- 将 schedule_capture_id 参数设置为当前重放计划中的参与工作负载捕获。schedule_capture_id 参数是将工作负载捕获添加到重放计划时返回的唯一标识符,如“使用 API 添加工作负载捕获到重放计划”中所述
- 将 capture_user 参数设置为在工作负载捕获期间捕获的用户或模式的用户名
- 将 replay_user 参数设置为新用户的用户名或捕获的用户在重放期间重新映射到的模式。如果此参数设置为 NULL,则映射被禁用
-- 此示例显示如何将捕获期间使用的 PROD 用户重新映射到重放期间用于标识为 1001 的工作负载捕获的 TEST 用户。
EXEC DBMS_WORKLOAD_REPLAY.SET_USER_MAPPING (1001, 'PROD', 'TEST');
使用 API 准备合并数据库重放
本节介绍如何使用 DBMS_WORKLOAD_REPLAY 包准备合并重放。
在准备合并重放之前,请确保满足以下先决条件:
- 重放数据已初始化
- 捕获的连接被重新映射
- 用户已映射
重新映射用户是可选的。但是,如果您计划在回放期间重新映射用户,则必须在准备合并回放之前完成。
准备合并重放执行以下操作:
- 指定重放选项,例如同步模式、会话连接速率和会话请求速率
- 将数据库状态置于重放模式
- 启用重放客户端的启动
准备合并重放:
- 使用 PREPARE_CONSOLIDATED_REPLAY 过程:
DBMS_WORKLOAD_REPLAY.PREPARE_CONSOLIDATED_REPLAY (
synchronization IN VARCHAR2 DEFAULT 'SCN',
connect_time_scale IN NUMBER DEFAULT 100,
think_time_scale IN NUMBER DEFAULT 100,
think_time_auto_correct IN BOOLEAN DEFAULT TRUE,
capture_sts IN BOOLEAN DEFAULT FALSE,
sts_cap_interval IN NUMBER DEFAULT 300);
使用 API 启动统一数据库重放
本节介绍如何使用 DBMS_WORKLOAD_REPLAY 包启动合并重放。
在开始合并重放之前,请确保满足以下先决条件:
- 合并重放已准备就绪
- 启动了足够数量的重放客户端
要开始合并重放:
- 使用 START_CONSOLIDATED_REPLAY 程序:
DBMS_WORKLOAD_REPLAY.START_CONSOLIDATED_REPLAY;
关于仅查询数据库重放
在仅查询数据库重放中,仅重放工作负载捕获的只读查询。换句话说,在仅查询重放中,只有 SELECT 语句在重放时发送到服务器。在仅查询重放期间不执行任何 DML 语句,并且重放不会对用户模式或数据进行任何更改。
注意:只能使用合并数据库重放执行仅查询数据库重放。
注意:仅查询数据库重放旨在仅在测试环境中使用和执行。
- 不要在生产系统上使用仅查询数据库重放
- 在仅查询数据库重放期间预计会出现分歧
仅查询数据库重放的用例
您可以使用仅查询数据库重放来预热数据库缓冲区缓存并查找回归。例如:
- 预热数据库缓冲区高速缓存:在某些情况下,当数据库缓冲区缓存处于温暖状态时(数据块已经在缓冲区缓存中),会捕获工作负载。但是,当您在测试系统上重放该工作负载时,缓冲区缓存将不会很热,并且最初需要从磁盘加载数据块。这可能会使重放持续时间长于捕获持续时间,并增加数据库时间。为避免必须预热缓冲区缓存,您可以执行仅查询重放,然后在不重新启动数据库和不刷新缓冲区缓存的情况下执行读/写重放。请注意,您不必在仅查询重放后重新启动数据库,因为仅查询重放是只读的
- 寻找回归:仅查询重放是一种很好且简单的方法,可以从具有并发性的工作负载的只读部分中找到回归。只读部分包括 SELECT(不是 SELECT…FOR UPDATE)语句、没有 DML 和 DDL 的 PL/SQL、LOB 读取等。它通常是工作负载捕获的主要部分
执行仅查询数据库重放
您可以执行仅查询数据库重放。
要执行仅查询数据库重放,请按照“通过 API 使用统一数据库重放”中的说明进行操作。当您使用 ADD_CAPTURE 函数将工作负载捕获添加到重放计划(如“使用 API 添加工作负载捕获到重放计划”中所述)时,请将 query_only 参数设置为 Y。
示例:使用 API 重放整合工作负载
本节假设一个场景,其中正在整合来自在各种操作系统上运行不同版本的 Oracle 数据库的三个独立生产系统的负载。
此场景使用以下假设:
- 要整合的第一个工作负载是从 CRM 系统捕获的,该系统在 Solaris 服务器上运行 Oracle 数据库 10g 第 2 版(10.2.0.4 版)
- 要整合的第二个工作负载是从 ERP 系统捕获的,该系统在 Linux 服务器上运行 Oracle 数据库 10g 第 2 版(10.2.0.5 版)
- 要整合的第三个工作负载是从 SCM 系统捕获的,该系统在 Solaris 服务器上运行 Oracle Database 11g 第 2 版(11.2.0.2 版)
- 测试系统设置为运行 Oracle Database 12c 第 1 版(12.1.0.1 版)的多租户容器数据库 (CDB)
- CDB 包含三个从 CRM、ERP 和 SCM 系统创建的 PDB
- CDB 中包含的每个 PDB 在捕获开始时恢复到与 CRM、ERP 和 SCM 系统相同的应用程序数据状态
下图合并三个工作负载的场景:

一、在测试系统上,将捕获的各个工作负载预处理到单独的目录中:
- 对于 CRM 工作负载:
- 创建一个目录对象:
CREATE OR REPLACE DIRECTORY crm AS '/u01/test/cap_crm';
- 确保从 CRM 系统捕获的工作负载存储在该目录中
- 预处理工作负载:
EXEC DBMS_WORKLOAD_REPLAY.PROCESS_CAPTURE ('CRM');
- 对于 ERP 工作负载:
- 创建一个目录对象:
CREATE OR REPLACE DIRECTORY erp AS '/u01/test/cap_erp';
- 确保从 ERP 系统捕获的工作负载存储在该目录中
- 预处理工作负载:
EXEC DBMS_WORKLOAD_REPLAY.PROCESS_CAPTURE ('ERP');
- 对于 SCM 工作负载:
- 创建一个目录对象:
CREATE OR REPLACE DIRECTORY scm AS '/u01/test/cap_scm';
- 确保从 SCM 系统捕获的工作负载存储在该目录中
- 预处理工作负载:
EXEC DBMS_WORKLOAD_REPLAY.PROCESS_CAPTURE ('SCM');
二、创建一个根目录来存放预处理后的工作负载:
mkdir '/u01/test/cons_dir';
CREATE OR REPLACE DIRECTORY cons_workload AS '/u01/test/cons_dir';
三、将每个预处理的工作负载目录复制到根目录中:
cp -r /u01/test/cap_crm /u01/test/cons_dir
cp -r /u01/test/cap_erp /u01/test/cons_dir
cp -r /u01/test/cap_scm /u01/test/cons_dir
四、对于每个工作负载,使用新的操作系统目录路径创建一个目录对象:
CREATE OR REPLACE DIRECTORY crm AS '/u01/test/cons_dir/cap_crm';
CREATE OR REPLACE DIRECTORY erp AS '/u01/test/cons_dir/cap_erp';
CREATE OR REPLACE DIRECTORY scm AS '/u01/test/cons_dir/cap_scm';
五、将重放目录设置为先前在步骤 2 中创建的根目录:
EXEC DBMS_WORKLOAD_REPLAY.SET_REPLAY_DIRECTORY ('CONS_WORKLOAD');
六、创建重放计划并添加工作负载捕获:
EXEC DBMS_WORKLOAD_REPLAY.BEGIN_REPLAY_SCHEDULE ('CONS_SCHEDULE');
SELECT DBMS_WORKLOAD_REPLAY.ADD_CAPTURE ('CRM') FROM dual;
SELECT DBMS_WORKLOAD_REPLAY.ADD_CAPTURE ('ERP') FROM dual;
SELECT DBMS_WORKLOAD_REPLAY.ADD_CAPTURE ('SCM') FROM dual;
EXEC DBMS_WORKLOAD_REPLAY.END_REPLAY_SCHEDULE;
七、初始化合并重放:
EXEC DBMS_WORKLOAD_REPLAY.INITIALIZE_CONSOLIDATED_REPLAY ('CONS_REPLAY',
'CONS_SCHEDULE');
八、重新映射连接:
- 在 DBA_WORKLOAD_CONNECTION_MAP 视图中查询连接映射信息:
SELECT schedule_cap_id, conn_id, capture_conn, replay_conn FROM dba_workload_connection_map;
- 重新映射连接:
EXEC DBMS_WORKLOAD_REPLAY.REMAP_CONNECTION (schedule_cap_id => 1,
conn_id => 1, replay_connection => 'CRM');
EXEC DBMS_WORKLOAD_REPLAY.REMAP_CONNECTION (schedule_cap_id => 2,
conn_id => 1, replay_connection => 'ERP');
EXEC DBMS_WORKLOAD_REPLAY.REMAP_CONNECTION (schedule_cap_id => 3,
conn_id => 1, replay_connection => 'SCM');
-- replay_connection 参数表示在测试系统上定义的服务
- 验证连接重新映射:
SELECT schedule_cap_id, conn_id, capture_conn, replay_conn FROM dba_workload_connection_map;
九、准备综合回放:
EXEC DBMS_WORKLOAD_REPLAY.PREPARE_CONSOLIDATED_REPLAY (
synchronization => 'OBJECT_ID');
十、启动重放客户端:
- 估计所需的重放客户端数量:
wrc mode=calibrate replaydir=/u01/test/cons_dir/cap_crm
wrc mode=calibrate replaydir=/u01/test/cons_dir/cap_erp
wrc mode=calibrate replaydir=/u01/test/cons_dir/cap_scm
- 添加输出以确定所需的重放客户端数量。对于整合工作负载中包含的每个工作负载捕获,您将需要至少启动一个重放客户端
- 通过重复此命令启动所需数量的重放客户端:
wrc username/password mode=replay replaydir=/u01/test/cons_dir
-- replaydir 参数设置为存储工作负载捕获的根目录
十一、开始合并重放:
EXEC DBMS_WORKLOAD_REPLAY.START_CONSOLIDATED_REPLAY;
使用工作负载扩展
本章介绍了将各种工作负载扩展技术与合并数据库重放结合使用。 它包含以下部分:
- 工作负载扩展概述
- 使用时移
- 使用工作负载折叠
- 使用架构重映射
工作负载扩展概述
Consolidated Database Replay 使您能够同时重放从一个或多个系统捕获的多个工作负载。在重放期间,合并的每个工作负载捕获都将在合并重放开始时开始重放。根据用例,您可以在使用整合数据库重放时采用各种工作负载扩展技术。
本节介绍以下工作负载扩展技术:
- 关于时移
- 关于工作负载折叠
- 关于架构重映射
关于时移
数据库重放使您能够在重放捕获的工作负载时执行时移。如果您希望通过将工作负载添加到现有工作负载捕获并一起重放它们来对系统进行压力测试,则此技术很有用。
例如,假设从三个应用程序捕获了三个工作负载:Sales、CRM 和 DW。为了执行压力测试,您可以对齐这些工作负载捕获的峰值并使用合并数据库重放一起重放它们。
关于工作负载折叠
数据库重放使您能够通过折叠现有的工作负载捕获来执行扩展测试。例如,假设工作负载是从凌晨 2 点到晚上 8 点捕获的。您可以使用数据库重放将原始工作负载折叠成三个捕获子集:一个从凌晨 2 点到早上 8 点,第二个从早上 8 点到下午 2 点,第三个从下午 2 点到下午 2 点。到晚上 8 点 通过一起重放三个捕获子集,您可以折叠原始捕获并在重放期间将工作负载增加三倍以执行扩展测试。
关于架构重映射
数据库重放使您能够通过重新映射数据库模式来执行扩展测试。当您部署同一应用程序的多个实例(例如多原则应用程序)或向现有应用程序添加新的地理区域时,此技术很有用。
例如,假设销售应用程序存在单个工作负载。要执行扩展测试并识别可能的主机瓶颈,请使用销售架构中的多个架构设置测试系统。
使用时移
本节介绍如何将时移与合并数据库重放结合使用,并假设您希望使用时移来对齐从三个应用程序捕获的工作负载峰值并同时重放它们的场景。该场景演示了如何使用时移进行压力测试。有关时移的更多信息,请参阅“关于时移”。
此场景使用以下假设:
- 第一个工作负载是从销售应用程序中捕获的
- 第二个工作负载是从 CRM 应用程序捕获的,其高峰时间比销售工作负载早 1 小时
- 第三个工作负载是从 DW 应用程序捕获的,其高峰时间比销售工作负载早 30 分钟
- 为了调整这些工作负载的峰值,通过在回放期间向 CRM 工作负载添加 1 小时的延迟并向 DW 工作负载添加 30 分钟的延迟来执行时移
要在这种情况下执行时移:
一、在将进行压力测试的回放系统上,为存储捕获的工作负载的根目录创建一个目录对象:
CREATE [OR REPLACE] DIRECTORY cons_dir AS '/u01/test/cons_dir';
二、将捕获的单个工作负载预处理到单独的目录中:
- 对于销售工作负载:
- 创建一个目录对象:
CREATE OR REPLACE DIRECTORY sales AS '/u01/test/cons_dir/cap_sales';
- 确保从销售应用程序捕获的工作负载存储在此目录中
- 预处理工作负载:
EXEC DBMS_WORKLOAD_REPLAY.PROCESS_CAPTURE ('SALES');
- 对于 CRM 工作负载:
- 创建一个目录对象:
CREATE OR REPLACE DIRECTORY crm AS '/u01/test/cons_dir/cap_crm';
- 确保从 CRM 应用程序捕获的工作负载存储在此目录中
- 预处理工作负载:
EXEC DBMS_WORKLOAD_REPLAY.PROCESS_CAPTURE ('CRM');
- 对于 DW 工作负载:
- 创建一个目录对象:
CREATE OR REPLACE DIRECTORY DW AS '/u01/test/cons_dir/cap_dw';
- 确保从 DW 应用程序捕获的工作负载存储在此目录中
- 预处理工作负载:
EXEC DBMS_WORKLOAD_REPLAY.PROCESS_CAPTURE ('DW');
三、设置回放目录为根目录:
EXEC DBMS_WORKLOAD_REPLAY.SET_REPLAY_DIRECTORY ('CONS_DIR');
四、创建重放计划并添加工作负载捕获:
EXEC DBMS_WORKLOAD_REPLAY.BEGIN_REPLAY_SCHEDULE ('align_peaks_schedule');
SELECT DBMS_WORKLOAD_REPLAY.ADD_CAPTURE ('SALES') FROM dual;
SELECT DBMS_WORKLOAD_REPLAY.ADD_CAPTURE ('CRM', 3600) FROM dual;
SELECT DBMS_WORKLOAD_REPLAY.ADD_CAPTURE ('DW', 1800) FROM dual;
EXEC DBMS_WORKLOAD_REPLAY.END_REPLAY_SCHEDULE;
-- 请注意,向 CRM 工作负载添加了 3,600 秒(或 1 小时)的延迟,向 DW 工作负载添加了 1,800 秒(或 30 分钟)的延迟
五、初始化合并重放:
EXEC DBMS_WORKLOAD_REPLAY.INITIALIZE_CONSOLIDATED_REPLAY ('align_peaks_replay', 'align_peaks_schedule');
六、重新映射连接:
- 在 DBA_WORKLOAD_CONNECTION_MAP 视图中查询连接映射信息:
SELECT schedule_cap_id, conn_id, capture_conn, replay_conn FROM dba_workload_connection_map;
- 重新映射连接:
EXEC DBMS_WORKLOAD_REPLAY.REMAP_CONNECTION (schedule_cap_id => 1,
conn_id => 1, replay_connection => 'inst1');
EXEC DBMS_WORKLOAD_REPLAY.REMAP_CONNECTION (schedule_cap_id => 1,
conn_id => 2, replay_connection => 'inst1');
EXEC DBMS_WORKLOAD_REPLAY.REMAP_CONNECTION (schedule_cap_id => 2,
conn_id => 1, replay_connection => 'inst2');
EXEC DBMS_WORKLOAD_REPLAY.REMAP_CONNECTION (schedule_cap_id => 2,
conn_id => 2, replay_connection => 'inst2');
EXEC DBMS_WORKLOAD_REPLAY.REMAP_CONNECTION (schedule_cap_id => 3,
conn_id => 1, replay_connection => 'inst3');
EXEC DBMS_WORKLOAD_REPLAY.REMAP_CONNECTION (schedule_cap_id => 3,
conn_id => 2, replay_connection => 'inst3');
-- replay_connection 参数表示在测试系统上定义的服务
- 验证连接重新映射:
SELECT schedule_cap_id, conn_id, capture_conn, replay_conn
FROM dba_workload_connection_map;
七、准备综合回放:
EXEC DBMS_WORKLOAD_REPLAY.PREPARE_CONSOLIDATED_REPLAY;
八、启动重放客户端:
- 估计所需的重放客户端数量:
wrc mode=calibrate replaydir=/u01/test/cons_dir/cap_sales
wrc mode=calibrate replaydir=/u01/test/cons_dir/cap_crm
wrc mode=calibrate replaydir=/u01/test/cons_dir/cap_dw
- 添加输出以确定所需的重放客户端数量。对于整合工作负载中包含的每个工作负载捕获,您将需要至少启动一个重放客户端
- 通过重复此命令启动所需数量的重放客户端:
wrc username/password mode=replay replaydir=/u01/test/cons_dir
-- replaydir 参数设置为存储工作负载捕获的根目录
九、开始合并重放:
EXEC DBMS_WORKLOAD_REPLAY.START_CONSOLIDATED_REPLAY;
使用工作负载折叠
本节介绍如何将工作负载折叠与Consolidated Database Replay一起使用,并假设您希望使用工作负载折叠将捕获的工作负载增加三倍。该场景演示了如何使用工作负载折叠进行放大测试。有关工作负载折叠的更多信息,请参阅“关于工作负载折叠”。
此场景使用以下假设:
- 最初的工作量是从凌晨2点到晚上8点捕获的,并分成三个捕获子集
- 第一个捕获子集包含从凌晨2点到8点的原始工作负载的一部分
- 第二个捕获子集包含从上午8点到下午2点的原始工作负载的一部分
- 第三个捕获子集包含下午2点到8点的部分原始工作负载
- 为了在回放期间将工作负载增加三倍,工作负载折叠是通过同时回放三个捕获子集来执行的
要在此场景中执行工作负载折叠,请执行以下操作:
一、在您计划执行扩展测试的回放系统上,为存储捕获的工作负载的根目录创建一个目录对象:
CREATE OR REPLACE DIRECTORY cons_dir AS '/u01/test/cons_dir';
二、为存储原始工作负载的目录创建一个目录对象:
CREATE OR REPLACE DIRECTORY cap_monday AS '/u01/test/cons_dir/cap_monday';
三、为您计划存储捕获子集的目录创建目录对象:
- 为第一个捕获子集创建一个目录对象:
CREATE OR REPLACE DIRECTORY cap_mon_2am_8am
AS '/u01/test/cons_dir/cap_monday_2am_8am';
- 为第二个捕获子集创建一个目录对象:
CREATE OR REPLACE DIRECTORY cap_mon_8am_2pm
AS '/u01/test/cons_dir/cap_monday_8am_2pm';
- 为第三个捕获子集创建一个目录对象:
CREATE OR REPLACE DIRECTORY cap_mon_2pm_8pm
AS '/u01/test/cons_dir/cap_monday_2pm_8pm';
四、创建捕获子集:
- 为凌晨 2 点到早上 8 点的时间段生成第一个捕获子集:
EXEC DBMS_WORKLOAD_REPLAY.GENERATE_CAPTURE_SUBSET ('CAP_MONDAY',
'CAP_MON_2AM_8AM', 'mon_2am_8am_wkld',
0, TRUE, 21600, FALSE, 1);
- 为上午 8 点到下午 2 点的时间段生成第二个捕获子集:
EXEC DBMS_WORKLOAD_REPLAY.GENERATE_CAPTURE_SUBSET ('CAP_MONDAY',
'CAP_MON_8AM_2PM', 'mon_8am_2pm_wkld',
21600, TRUE, 43200, FALSE, 1);
- 为下午2点到8点的时间段生成第三个捕获子集:
EXEC DBMS_WORKLOAD_REPLAY.GENERATE_CAPTURE_SUBSET ('CAP_MONDAY',
'CAP_MON_2PM_8PM', 'mon_2pm_8pm_wkld',
43200, TRUE, 0, FALSE, 1);
五、预处理捕获子集:
EXEC DBMS_WORKLOAD_REPLAY.PROCESS_CAPTURE ('CAP_MON_2AM_8AM');
EXEC DBMS_WORKLOAD_REPLAY.PROCESS_CAPTURE ('CAP_MON_8AM_2PM');
EXEC DBMS_WORKLOAD_REPLAY.PROCESS_CAPTURE ('CAP_MON_2PM_8PM');
六、设置回放目录为根目录:
EXEC DBMS_WORKLOAD_REPLAY.SET_REPLAY_DIRECTORY ('CONS_DIR');
七、创建重放计划并添加捕获子集:
EXEC DBMS_WORKLOAD_REPLAY.BEGIN_REPLAY_SCHEDULE ('monday_folded_schedule');
SELECT DBMS_WORKLOAD_REPLAY.ADD_CAPTURE ('CAP_MON_2AM_8AM') FROM dual;
SELECT DBMS_WORKLOAD_REPLAY.ADD_CAPTURE ('CAP_MON_8AM_2PM') FROM dual;
SELECT DBMS_WORKLOAD_REPLAY.ADD_CAPTURE ('CAP_MON_2PM_8PM') FROM dual;
EXEC DBMS_WORKLOAD_REPLAY.END_REPLAY_SCHEDULE;
八、初始化合并重放:
EXEC DBMS_WORKLOAD_REPLAY.INITIALIZE_CONSOLIDATED_REPLAY (
'monday_folded_replay', 'monday_folded_schedule');
九、重新映射连接:
- 在 DBA_WORKLOAD_CONNECTION_MAP 视图中查询连接映射信息:
SELECT schedule_cap_id, conn_id, capture_conn, replay_conn
FROM dba_workload_connection_map;
- 重新映射连接:
EXEC DBMS_WORKLOAD_REPLAY.REMAP_CONNECTION (schedule_cap_id => 1,
conn_id => 1, replay_connection => 'inst1');
EXEC DBMS_WORKLOAD_REPLAY.REMAP_CONNECTION (schedule_cap_id => 1,
conn_id => 2, replay_connection => 'inst1');
EXEC DBMS_WORKLOAD_REPLAY.REMAP_CONNECTION (schedule_cap_id => 2,
conn_id => 1, replay_connection => 'inst2');
EXEC DBMS_WORKLOAD_REPLAY.REMAP_CONNECTION (schedule_cap_id => 2,
conn_id => 2, replay_connection => 'inst2');
EXEC DBMS_WORKLOAD_REPLAY.REMAP_CONNECTION (schedule_cap_id => 3,
conn_id => 1, replay_connection => 'inst3');
EXEC DBMS_WORKLOAD_REPLAY.REMAP_CONNECTION (schedule_cap_id => 3,
conn_id => 2, replay_connection => 'inst3');
-- replay_connection 参数表示在测试系统上定义的服务
- 验证连接重新映射:
SELECT schedule_cap_id, conn_id, capture_conn, replay_conn
FROM dba_workload_connection_map;
十、准备综合回放:
EXEC DBMS_WORKLOAD_REPLAY.PREPARE_CONSOLIDATED_REPLAY;
十一、启动重放客户端:
- 估计所需的重放客户端数量:
wrc mode=calibrate replaydir=/u01/test/cons_dir/cap_monday_2am_8am
wrc mode=calibrate replaydir=/u01/test/cons_dir/cap_monday_8am_2pm
wrc mode=calibrate replaydir=/u01/test/cons_dir/cap_monday_2pm_8pm
- 添加输出以确定所需的重放客户端数量。对于整合工作负载中包含的每个工作负载捕获,您将需要至少启动一个重放客户端
- 通过重复此命令启动所需数量的重放客户端:
wrc username/password mode=replay replaydir=/u01/test/cons_dir
-- replaydir 参数设置为存储工作负载捕获的根目录
十二、开始合并重放:
EXEC DBMS_WORKLOAD_REPLAY.START_CONSOLIDATED_REPLAY;
使用架构重映射
本节介绍如何将模式重新映射与合并数据库重放结合使用,并假设您希望使用模式重新映射来识别部署应用程序的多个实例时可能存在的主机瓶颈的场景。该场景演示了如何使用模式重新映射进行扩展测试。有关架构重新映射的详细信息,请参阅“关于架构重新映射”。
此场景使用以下假设:
- 存在从 Sales 应用程序捕获的单个工作负载
- 要使用 Sales 模式中的多个模式设置重放系统,通过将捕获的工作负载多次添加到重放计划并将用户重新映射到不同的模式来执行模式重新映射
要在此场景中执行模式重新映射:
一、在您计划执行扩展测试的回放系统上,为存储捕获的工作负载的根目录创建一个目录对象:
CREATE OR REPLACE DIRECTORY cons_dir AS '/u01/test/cons_dir';
二、为存储捕获的工作负载的目录创建一个目录对象:
CREATE OR REPLACE DIRECTORY cap_sales AS '/u01/test/cons_dir/cap_sales';
-- 确保从销售应用程序捕获的工作负载存储在此目录中
三、预处理捕获的工作负载:
EXEC DBMS_WORKLOAD_REPLAY.PROCESS_CAPTURE ('CAP_SALES');
四、设置回放目录为根目录:
EXEC DBMS_WORKLOAD_REPLAY.SET_REPLAY_DIRECTORY ('CONS_DIR');
五、创建重放计划并多次添加捕获的工作负载:
EXEC DBMS_WORKLOAD_REPLAY.BEGIN_REPLAY_SCHEDULE ('double_sales_schedule');
SELECT DBMS_WORKLOAD_REPLAY.ADD_CAPTURE ('CAP_SALES') FROM dual;
SELECT DBMS_WORKLOAD_REPLAY.ADD_CAPTURE ('CAP_SALES') FROM dual;
EXEC DBMS_WORKLOAD_REPLAY.END_REPLAY_SCHEDULE;
六、初始化合并重放:
EXEC DBMS_WORKLOAD_REPLAY.INITIALIZE_CONSOLIDATED_REPLAY (
'double_sales_replay', 'double_sales_schedule);
七、重新映射用户:
EXEC DBMS_WORKLOAD_REPLAY.SET_USER_MAPPING (2, 'sales_usr', 'sales_usr_2');
八、准备综合回放:
EXEC DBMS_WORKLOAD_REPLAY.PREPARE_CONSOLIDATED_REPLAY;
九、启动重放客户端:
- 估计所需的重放客户端数量:
wrc mode=calibrate replaydir=/u01/test/cons_dir/cap_sales
- 添加输出以确定所需的重放客户端数量。对于整合工作负载中包含的每个工作负载捕获,您将需要至少启动一个重放客户端
- 通过重复此命令启动所需数量的重放客户端:
wrc username/password mode=replay replaydir=/u01/test/cons_dir
-- replaydir 参数设置为存储工作负载捕获的根目录
十、开始合并重放:
EXEC DBMS_WORKLOAD_REPLAY.START_CONSOLIDATED_REPLAY;