【无标题】邮件分类
锁定"发票"词汇,给定先验概率p(垃圾)=0.5, p(正常)=0.5, p(发票|垃圾) = 5%, p(发票|正常) = 0.1%, 其中后两者是假定概率,会影响到判断,解决方法是对邮件进行分词统计寻求频率。
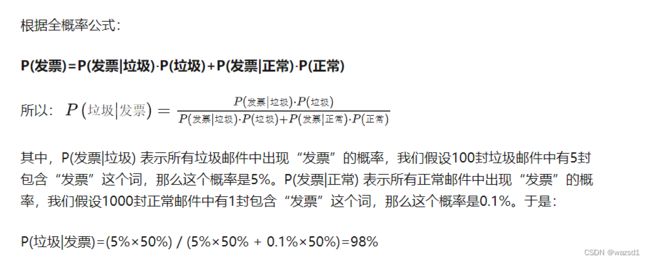
以上是一个简单的思路。
刚起步的简单分类,之后完善:
text1 = '根据银行发票提供的信息,您于昨天贷款100亿元,接下来为您念一篇作文:月光随着溪水一起远逝,' \
'流向远方另一个春意盎然的世界……天空云卷云舒,月儿把它那轻纱披上东方山峦轮廓逐渐明晰起来,曙光晞微,崭新的一天开始了……' \
'岸边的金柳对着水梳弄着自已秀发,今天的她就是最美的新娘。小孩追着跑着趟过溪水,欢笑声把花儿也陶醉了。' \
'溪边草丛里隐约闪现着鸟儿的身影,也许在为它们的孩子捕食呢。天空蓝灿灿似明镜一般,空彻透明……' \
'山林里传来农夫的吆喝声,农民的活计来了……小河流得更欢了,带着希望之花流向远方……'
text2 = '根据银行发票提供的信息,您于昨天贷款100亿元,接下来为您念一篇作文:月光随着溪水一起远逝,' \
'流向远方另一个春意盎然的世界……天空云卷云舒,月儿把它那轻纱披上东方山峦轮廓逐渐明晰起来,曙光晞微,崭新的一天开始了……' \
'岸边的金柳对着水梳弄着自已秀发,今天的她就是最美的新娘。小孩追着跑着趟过溪水,欢笑声把花儿也陶醉了。' \
'溪边草丛里隐约闪现着鸟儿的身影,也许在为它们的孩子捕食呢。天空蓝灿灿似明镜一般,空彻透明……' \
'山林里传来农夫的吆喝声,农民的活计来了……小河流得更欢了,带着希望之花流向远方……'
text3 = '根据银行发票提供的信息,您于昨天贷款100亿元,接下来为您念一篇作文:月光随着溪水一起远逝,' \
'流向远方另一个春意盎然的世界……天空云卷云舒,月儿把它那轻纱披上东方山峦轮廓逐渐明晰起来,曙光晞微,崭新的一天开始了……' \
'岸边的金柳对着水梳弄着自已秀发,今天的她就是最美的新娘。小孩追着跑着趟过溪水,欢笑声把花儿也陶醉了。' \
'溪边草丛里隐约闪现着鸟儿的身影,也许在为它们的孩子捕食呢。天空蓝灿灿似明镜一般,空彻透明……' \
'山林里传来农夫的吆喝声,农民的活计来了……小河流得更欢了,带着希望之花流向远方……'
text4 = '根据银行发票提供的信息,您于昨天贷款100亿元,接下来为您念一篇作文:月光随着溪水一起远逝,' \
'流向远方另一个春意盎然的世界……天空云卷云舒,月儿把它那轻纱披上东方山峦轮廓逐渐明晰起来,曙光晞微,崭新的一天开始了……' \
'岸边的金柳对着水梳弄着自已秀发,今天的她就是最美的新娘。小孩追着跑着趟过溪水,欢笑声把花儿也陶醉了。' \
'溪边草丛里隐约闪现着鸟儿的身影,也许在为它们的孩子捕食呢。天空蓝灿灿似明镜一般,空彻透明……' \
'山林里传来农夫的吆喝声,农民的活计来了……小河流得更欢了,带着希望之花流向远方……'
text5 = '根据银行发票提供的信息,您于昨天贷款100亿元,接下来为您念一篇作文:月光随着溪水一起远逝,' \
'流向远方另一个春意盎然的世界……天空云卷云舒,月儿把它那轻纱披上东方山峦轮廓逐渐明晰起来,曙光晞微,崭新的一天开始了……' \
'岸边的金柳对着水梳弄着自已秀发,今天的她就是最美的新娘。小孩追着跑着趟过溪水,欢笑声把花儿也陶醉了。' \
'溪边草丛里隐约闪现着鸟儿的身影,也许在为它们的孩子捕食呢。天空蓝灿灿似明镜一般,空彻透明……' \
'山林里传来农夫的吆喝声,农民的活计来了……小河流得更欢了,带着希望之花流向远方……'
text6 = '接下来为您念一篇作文:月光随着溪水一起远逝,' \
'流向远方另一个春意盎然的世界……天空云卷云舒,月儿把它那轻纱披上东方山峦轮廓逐渐明晰起来,曙光晞微,崭新的一天开始了……' \
'岸边的金柳对着水梳弄着自已秀发,今天的她就是最美的新娘。小孩追着跑着趟过溪水,欢笑声把花儿也陶醉了。' \
'溪边草丛里隐约闪现着鸟儿的身影,也许在为它们的孩子捕食呢。天空蓝灿灿似明镜一般,空彻透明……' \
'山林里传来农夫的吆喝声,农民的活计来了……小河流得更欢了,带着希望之花流向远方……'
text7 = '接下来为您念一篇作文:月光随着溪水一起远逝,' \
'流向远方另一个春意盎然的世界……天空云卷云舒,月儿把它那轻纱披上东方山峦轮廓逐渐明晰起来,曙光晞微,崭新的一天开始了……' \
'岸边的金柳对着水梳弄着自已秀发,今天的她就是最美的新娘。小孩追着跑着趟过溪水,欢笑声把花儿也陶醉了。' \
'溪边草丛里隐约闪现着鸟儿的身影,也许在为它们的孩子捕食呢。天空蓝灿灿似明镜一般,空彻透明……' \
'山林里传来农夫的吆喝声,农民的活计来了……小河流得更欢了,带着希望之花流向远方……'
text8 = '接下来为您念一篇作文:月光随着溪水一起远逝,' \
'流向远方另一个春意盎然的世界……天空云卷云舒,月儿把它那轻纱披上东方山峦轮廓逐渐明晰起来,曙光晞微,崭新的一天开始了……' \
'岸边的金柳对着水梳弄着自已秀发,今天的她就是最美的新娘。小孩追着跑着趟过溪水,欢笑声把花儿也陶醉了。' \
'溪边草丛里隐约闪现着鸟儿的身影,也许在为它们的孩子捕食呢。天空蓝灿灿似明镜一般,空彻透明……' \
'山林里传来农夫的吆喝声,农民的活计来了……小河流得更欢了,带着希望之花流向远方……'
text9 = '接下来为您念一篇作文:月光随着溪水一起远逝,' \
'流向远方另一个春意盎然的世界……天空云卷云舒,月儿把它那轻纱披上东方山峦轮廓逐渐明晰起来,曙光晞微,崭新的一天开始了……' \
'岸边的金柳对着水梳弄着自已秀发,今天的她就是最美的新娘。小孩追着跑着趟过溪水,欢笑声把花儿也陶醉了。' \
'溪边草丛里隐约闪现着鸟儿的身影,也许在为它们的孩子捕食呢。天空蓝灿灿似明镜一般,空彻透明……' \
'山林里传来农夫的吆喝声,农民的活计来了……小河流得更欢了,带着希望之花流向远方……'
text10 = '接下来为您念一篇作文:月光随着溪水一起远逝,' \
'流向远方另一个春意盎然的世界……天空云卷云舒,月儿把它那轻纱披上东方山峦轮廓逐渐明晰起来,曙光晞微,崭新的一天开始了……' \
'岸边的金柳对着水梳弄着自已秀发,今天的她就是最美的新娘。小孩追着跑着趟过溪水,欢笑声把花儿也陶醉了。' \
'溪边草丛里隐约闪现着鸟儿的身影,也许在为它们的孩子捕食呢。天空蓝灿灿似明镜一般,空彻透明……' \
'山林里传来农夫的吆喝声,农民的活计来了……小河流得更欢了,带着希望之花流向远方……'
from fractions import Fraction
p_zheng = Fraction(1, 2)
p_la = Fraction(1, 2)
import re
import jieba
import pandas as pd
# 分词并统计词频
def count_words(content):
content = re.sub(r'[\s。……“”,?!]', '', content)
word_list = jieba.cut(content)
word_list = pd.Series(word_list).value_counts()
return list(word_list) # 返回统计词频
for i in range(1, 11):
pass垃圾分类的过程描述:
(1)收集数据:提供文本文件。
(2)准备数据:将文本文件解析成词条向量。
(3)分析数据:检查词条确保解析的正确性。
(4)训练算法:计算不同的独立特征的条件概率。
(5)测试算法:计算错误率。
(6)使用算法:构建一个完整的程序对一组文档进行分类
这里引用其他博主的代码提供一个完全的过程:
import os
import re
import string
import math
DATA_DIR = 'enron'
target_names = ['ham', 'spam']
def get_data(DATA_DIR):
subfolders = ['enron%d' % i for i in range(1, 7)]
data = []
target = []
for subfolder in subfolders:
# spam
spam_files = os.listdir(os.path.join(DATA_DIR, subfolder, 'spam'))
for spam_file in spam_files:
with open(os.path.join(DATA_DIR, subfolder, 'spam', spam_file), encoding="latin-1") as f:
data.append(f.read())
target.append(1)
# ham
ham_files = os.listdir(os.path.join(DATA_DIR, subfolder, 'ham'))
for ham_file in ham_files:
with open(os.path.join(DATA_DIR, subfolder, 'ham', ham_file), encoding="latin-1") as f:
data.append(f.read())
target.append(0)
return data, target
X, y = get_data(DATA_DIR)
class SpamDetector_1(object):
"""Implementation of Naive Bayes for binary classification"""
# 清除空格
def clean(self, s):
translator = str.maketrans("", "", string.punctuation)
return s.translate(translator)
# 分开每个单词
def tokenize(self, text):
text = self.clean(text).lower()
return re.split("\W+", text)
# 计算某个单词出现的次数
def get_word_counts(self, words):
word_counts = {}
for word in words:
word_counts[word] = word_counts.get(word, 0.0) + 1.0
return word_counts
class SpamDetector_2(SpamDetector_1):
# X:data,Y:target标签(垃圾邮件或正常邮件)
def fit(self, X, Y):
self.num_messages = {}
self.log_class_priors = {}
self.word_counts = {}
# 建立一个集合存储所有出现的单词
self.vocab = set()
# 统计spam和ham邮件的个数
self.num_messages['spam'] = sum(1 for label in Y if label == 1)
self.num_messages['ham'] = sum(1 for label in Y if label == 0)
# 计算先验概率,即所有的邮件中,垃圾邮件和正常邮件所占的比例
self.log_class_priors['spam'] = math.log(
self.num_messages['spam'] / (self.num_messages['spam'] + self.num_messages['ham']))
self.log_class_priors['ham'] = math.log(
self.num_messages['ham'] / (self.num_messages['spam'] + self.num_messages['ham']))
self.word_counts['spam'] = {}
self.word_counts['ham'] = {}
for x, y in zip(X, Y):
c = 'spam' if y == 1 else 'ham'
# 构建一个字典存储单封邮件中的单词以及其个数
counts = self.get_word_counts(self.tokenize(x))
for word, count in counts.items():
if word not in self.vocab:
self.vocab.add(word) # 确保self.vocab中含有所有邮件中的单词
# 下面语句是为了计算垃圾邮件和非垃圾邮件的词频,即给定词在垃圾邮件和非垃圾邮件中出现的次数。
# c是0或1,垃圾邮件的标签
if word not in self.word_counts[c]:
self.word_counts[c][word] = 0.0
self.word_counts[c][word] += count
MNB = SpamDetector_2()
MNB.fit(X[100:], y[100:])
class SpamDetector(SpamDetector_2):
def predict(self, X):
result = []
flag_1 = 0
# 遍历所有的测试集
for x in X:
counts = self.get_word_counts(self.tokenize(x)) # 生成可以记录单词以及该单词出现的次数的字典
spam_score = 0
ham_score = 0
flag_2 = 0
for word, _ in counts.items():
if word not in self.vocab:
continue
# 下面计算P(内容|垃圾邮件)和P(内容|正常邮件),所有的单词都要进行拉普拉斯平滑
else:
# 该单词存在于正常邮件的训练集和垃圾邮件的训练集当中
if word in self.word_counts['spam'].keys() and word in self.word_counts['ham'].keys():
log_w_given_spam = math.log(
(self.word_counts['spam'][word] + 1) / (
sum(self.word_counts['spam'].values()) + len(self.vocab)))
log_w_given_ham = math.log(
(self.word_counts['ham'][word] + 1) / (sum(self.word_counts['ham'].values()) + len(
self.vocab)))
# 该单词存在于垃圾邮件的训练集当中,但不存在于正常邮件的训练集当中
if word in self.word_counts['spam'].keys() and word not in self.word_counts['ham'].keys():
log_w_given_spam = math.log(
(self.word_counts['spam'][word] + 1) / (
sum(self.word_counts['spam'].values()) + len(self.vocab)))
log_w_given_ham = math.log(1 / (sum(self.word_counts['ham'].values()) + len(
self.vocab)))
# 该单词存在于正常邮件的训练集当中,但不存在于垃圾邮件的训练集当中
if word not in self.word_counts['spam'].keys() and word in self.word_counts['ham'].keys():
log_w_given_spam = math.log(1 / (sum(self.word_counts['spam'].values()) + len(self.vocab)))
log_w_given_ham = math.log(
(self.word_counts['ham'][word] + 1) / (sum(self.word_counts['ham'].values()) + len(
self.vocab)))
# 把计算到的P(内容|垃圾邮件)和P(内容|正常邮件)加起来
spam_score += log_w_given_spam
ham_score += log_w_given_ham
flag_2 += 1
# 最后,还要把先验加上去,即P(垃圾邮件)和P(正常邮件)
spam_score += self.log_class_priors['spam']
ham_score += self.log_class_priors['ham']
# 最后进行预测,如果spam_score > ham_score则标志为1,即垃圾邮件
if spam_score > ham_score:
result.append(1)
else:
result.append(0)
flag_1 += 1
return result
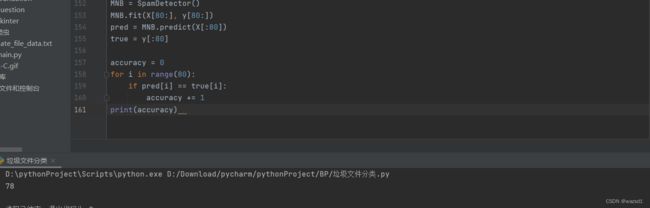
MNB = SpamDetector()
MNB.fit(X[100:], y[100:])
pred = MNB.predict(X[:100])
true = y[:100]
accuracy = 0
for i in range(100):
if pred[i] == true[i]:
accuracy += 1
print(accuracy) 结果反映的是正确分辨率为78%。(这是修改了一部分,原博主为98%)