4.0.0com.exampletestspark1.0-SNAPSHOTtestsparkA minimal Scala project using the Maven build tool.My Licensehttp://....repo1111UTF-82.13.11org.scala-langscala-library2.13.11org.scalametasemanticdb_2.124.1.6org.apache.sparkspark-core_2.133.4.0org.apache.sparkspark-sql_2.133.4.0providedorg.scalametamunit_2.130.7.29testsrc/main/scalasrc/test/scalanet.alchim31.mavenscala-maven-plugin3.3.2compiletestCompile
scala> val smalldf = df.select(col("src_ip"),col("src_port"),col("dest_ip"),col("dest_port"),col("message"))
scala> smalldf.show()
+---------------+--------+---------------+---------+--------------------+
| src_ip|src_port| dest_ip|dest_port| message|
+---------------+--------+---------------+---------+--------------------+
| 192.168.11.20| 38021|172.0.1.68 | 123|FRN DOS Possible ...|
………………………………
| 192.168.11.20| 47430|172.0.1.68 | 123|FRN DOS Possible ...|
+---------------+--------+---------------+---------+--------------------+
only showing top 20 rows
smalldf: Unit = ()
选择列的简单方式:
scala> lines.select('src_ip).show()
+---------------+
| src_ip|
+---------------+
| 192.168.1.46|
| 192.168.1.46|
| 192.168.1.46|
…………………………
only showing top 20 rows
scala> lines.count
res9: Long = 155395
scala> lines.distinct.count
23/05/24 02:01:31 WARN package: Truncated the string representation of a plan since it was too large. This behavior can be adjusted by setting 'spark.sql.debug.maxToStringFields'.
res10: Long = 154022
scala> lines.select('src_ip).distinct.count
res11: Long = 1454
scala>
可以看出效果截然不同
6. 过滤
scala> lines.count
res16: Long = 155395
scala> lines.filter("dest_port='123'").count
res17: Long = 97147
scala> lines.filter("src_ip='192.168.0.11' and dest_port='123'").count
res18: Long = 3202
scala> val fivetuples = lines.select('src_ip,'src_port,'dest_ip,'dest_port,'protocol)
fivetuples: org.apache.spark.sql.DataFrame = [src_ip: string, src_port: string ... 3 more fields]
scala> case class FIVETUPLE(src_ip:String,src_port:String,dest_ip:String,dest_port:String,protocol:String)
defined class FIVETUPLE
scala> val fset = fivetuples.as[FIVETUPLE]
fset: org.apache.spark.sql.Dataset[FIVETUPLE] = [src_ip: string, src_port: string ... 3 more fields]
scala> val lines = spark.read.option("header",true).csv("/sample/DOS/*.csv")
lines: org.apache.spark.sql.DataFrame = [sid: string, message_type: string ... 23 more fields]
scala> lines.createOrReplaceTempView("mytable")
scala> spark.sql("select src_ip from mytable").show
+---------------+
| src_ip|
+---------------+
| 192.168.1.1|
(1)分组统计排序
scala> spark.sql("select dest_ip,dest_port,count(*) as count from mytable group by dest_port,dest_ip order by count desc").show
+---------------+---------+-----+
| dest_ip|dest_port|count|
+---------------+---------+-----+
| 192.168.1.111| 123| 240|
| 192.168.1.112| 123| 122|
(2)对分组排序条件进行限制
scala> spark.sql("select dest_ip,dest_port,count(*) as count from mytable group by dest_port,dest_ip having count<20 order by count desc").show
+---------------+---------+-----+
| dest_ip|dest_port|count|
+---------------+---------+-----+
| 192.168.21.222| 111| 19|
| 192.168.21.222| 111| 19|
scala> spark.sql("select dest_ip,dest_port,count(*) as count from mytable where dest_ip like '173%' group by dest_port,dest_ip having count<20 order by count desc").show
+---------------+---------+-----+
| dest_ip|dest_port|count|
+---------------+---------+-----+
|173.112.111.111| 111| 19|
|173.112.111.112| 111| 19|
(3)嵌套碰撞
scala> spark.sql("select src_ip from mytable where src_ip in (select dest_ip from mytable)").show
+---------------+
| src_ip|
+---------------+
| 10.0.0.1|
(4)仅显示5行:
scala> spark.sql("select src_ip,count(*) as count from mytable group by src_ip having count>100 limit 5").show
+---------------+-----+
| src_ip|count|
+---------------+-----+
| 192.168.1.1| 726|
| 192.168.1.2| 2030|
| 192.168.1.3| 328|
| 192.168.1.4| 204|
| 192.168.1.5| 190|
(5)去重
scala> spark.sql("select protocol from mytable").show
+--------+
|protocol|
+--------+
| udp|
| udp|
| udp|
…………
| udp|
| udp|
+--------+
only showing top 20 rows
scala> spark.sql("select distinct protocol from mytable").show
+--------+
|protocol|
+--------+
| tcp|
| udp|
+--------+
eclipse中使用maven插件的时候,运行run as maven build的时候报错
-Dmaven.multiModuleProjectDirectory system propery is not set. Check $M2_HOME environment variable and mvn script match.
可以设一个环境变量M2_HOME指
1.建好一个专门放置MySQL的目录
/mysql/db数据库目录
/mysql/data数据库数据文件目录
2.配置用户,添加专门的MySQL管理用户
>groupadd mysql ----添加用户组
>useradd -g mysql mysql ----在mysql用户组中添加一个mysql用户
3.配置,生成并安装MySQL
>cmake -D
好久没有去安装过MYSQL,今天自己在安装完MYSQL过后用navicat for mysql去厕测试链接的时候出现了10061的问题,因为的的MYSQL是最新版本为5.6.24,所以下载的文件夹里没有my.ini文件,所以在网上找了很多方法还是没有找到怎么解决问题,最后看到了一篇百度经验里有这个的介绍,按照其步骤也完成了安装,在这里给大家分享下这个链接的地址
import java.io.UnsupportedEncodingException;
/**
* 转换字符串的编码
*/
public class ChangeCharset {
/** 7位ASCII字符,也叫作ISO646-US、Unicode字符集的基本拉丁块 */
public static final Strin
其实这个没啥技术含量,大湿们不要操笑哦,只是做一个简单的记录,简单用了一下递归算法。
import java.io.File;
/**
* @author Perlin
* @date 2014-6-30
*/
public class PrintDirectory {
public static void printDirectory(File f
linux安装mysql出现libs报冲突解决
安装mysql出现
file /usr/share/mysql/ukrainian/errmsg.sys from install of MySQL-server-5.5.33-1.linux2.6.i386 conflicts with file from package mysql-libs-5.1.61-4.el6.i686
Dear,
I'm pleased to announce that ktap release v0.1, this is the first official
release of ktap project, it is expected that this release is not fully
functional or very stable and we welcome bu





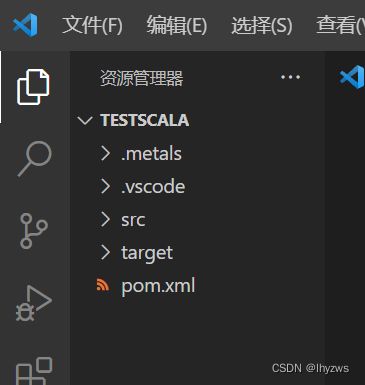
 关闭原来的窗口,使用新打开的窗口就好。此时项目的目录结构应该时这样的,可以看到pom文件已经出现了:
关闭原来的窗口,使用新打开的窗口就好。此时项目的目录结构应该时这样的,可以看到pom文件已经出现了: