一款OLAP数据库ClickHouse

本篇主题:基于3W1H原则,讲解ClickHouse,以便于后续开发实践。
中文文档:如何使用 ClickHouse 测试您的硬件 | ClickHouse Docs
1 clickhouse是什么?
ClickHouse 是俄罗斯的Yandex于2016年开源的列式存储数据库(DBMS),使用C++语言编写,主要用于在线分析处理查询(OLAP),能够使用SQL查询实时生成分析数据报告。
tips:
OLTP(on-line transaction processing)翻译为联机事务处理, OLAP(On-Line Analytical Processing)翻译为联机分析处理,从字面上来看OLTP是做事务处理,OLAP是做分析处理。从对数据库操作来看,OLTP主要是对数据的增删改,OLAP是对数据的查询。
1.1 Why we choose it
1.1.1 经典架构及分析

架构分析
- 数据的实效性,中间过程经过Kafka、ETL、调度处理,报表的实效性不理想
- 即席分析性能,Hive存储是hdfs文件系统,查询效率不高,不适合即席查询
- 涉及Hadoop组件多
- 数据链路长,数据链路处理流程长,繁琐容错也不好
1.1.2 为啥选择ClickHouse
- ClickHouse独立于hadoop生态之外,开源的OLAP数据库
- 支持海量数据,实时导入,适合在线查询,多维 聚合分析
- 真正的面向列的DBMS,SQL语法支持
- 简单、开箱即用
- 主主架构,支持线性扩展
- 其他原因,请看下方特性
1.2 clickhouse特点
1、完备的DBMS功能
ClickHouse拥有完备的管理功能,所以它称得上是一个DBMS(Database Management System,数据库管理系统),而不仅是一个数据库。作为一个DBMS,它具备了一些基本功能,如下所示。
- DDL(数据定义语言):可以动态地创建、修改或删除数据库、表和视图,而无须重启服务。
- DML(数据操作语言):可以动态查询、插入、修改或删除数据。
- 权限控制:可以按照用户粒度设置数据库或者表的操作权限,保障数据的安全性。
- 数据备份与恢复:提供了数据备份导出与导入恢复机制,满足生产环境的要求。
- 分布式管理:提供集群模式,能够自动管理多个数据库节点。
这里只列举了一些最具代表性的功能,但已然足以表明为什么Click House称得上是DBMS了。
2、列式存储与数据压缩
列式存储和数据压缩,对于一款高性能数据库来说是必不可少的特性。一个非常流行的观点认为,如果你想让查询变得更快,最简单且有效的方法是减少数据扫描范围和数据传输时的大小,而列式存储和数据压缩就可以帮助我们实现上述两点。列式存储和数据压缩通常是伴生的,因为一般来说列式存储是数据压缩的前提。
列式存储相比于行式存储,列式存储在分析场景下有着许多优良的特性。
- 分析场景中往往需要读大量行但是少数几个列。
在行存模式下,数据按行连续存储,所有列的数据都存储在一个block中,不参与计算的列在IO时也要全部读出,读取操作被严重放大。
列存模式下,只需要读取参与计算的列即可,极大的减低了IO cost,加速了查询。
- 同一列中的数据属于同一类型,压缩效果显著,压缩比高。
列存往往有着高达十倍甚至更高的压缩比,节省了大量的存储空间,降低了存储成本。
更高的压缩比意味着更小的data size,从磁盘中读取相应数据耗时更短。
- 自由的压缩算法选择。clickhouse默认使用LZ4算法压缩,数据总体的压缩比可以达到8:1。
不同列的数据具有不同的数据类型,适用的压缩算法也就不尽相同。可以针对不同列类型,选择最合适的压缩算法。 - 高压缩比,意味着同等大小的内存能够存放更多数据,系统cache效果更好。
官方显示,通过列存储,在某些分析场景下,能获得100倍甚至更高的加速效果。


3、向量化执行引擎
clickhouse不仅将数据按列存储,而且按列进行计算。传统的OLTP数据库通常采用按行计算,原因是事务处理中以点查为主,SQL计算量小,实现这些技术的收益不够明显,单个SQL所涉及计算量可能极大,将每行作为一个基本单元进行处理会带来严重的性能损耗:
1)对每一行数据都要调用相应的函数,函数调用开销占比高;
2)存储层按列存储数据,在内存中按列组织,但是计算层按行处理,无法充分利用CPU Cache的预读能力,造成CPU Cache miss严重;
3)按行处理,无法利用高效的SIMD指令
ClickHouse实现了向量化执行引擎(Vectorized execution engine),对内存中的列式数据,一个batch调用一次SIMD指令(而非每一行调用一次),不仅减少函数调用次数,降低Cache miss,而且可以充分发挥SIMD指令的并行能力,大幅度缩短了计算耗时。向量执行引擎,通常能够带来数倍的性能提升。
SIMD全称Sigle Instuction Multiple Data,单指令多数据流,能够赋值多个操作数,并把它们打包在大型寄存器的一组指令集。以同步方式,在同一时刻执行同一条指令。
4、关系模型与SQL查询
相比HBase和Redis这类NoSQL数据库,ClickHouse使用关系模型描述数据并提供了传统数据库的概念(数据库、表、视图和函数等)。
与此同时,ClickHouse完全使用SQL作为查询语言(支持GROUP BY、ORDER BY、JOIN、IN等大部分标准SQL)。
5、多样化的表引擎
ClickHouse和MySQL类似,把表级的存储引擎插件化,根据表的不同需求可以设定不同的存储引擎。目前包括合并树、日志、接口和其他四大类20多种引擎。
不同的引擎决定了表数据的存储特点和表数据的操作行为:
1)决定表存储在哪里以及以何种方式存储
2)支持哪些查询以及如何支持
3)并发数据访问
4)索引的使用
5)是否可以执行多线程请求
6)数据复制参数
表引擎决定了数据在文件系统的存储方式,常用的也是官方推荐的MergeTree系列,如果需要数据副本的话可以使用ReplicateMergeTree系列,相当于MergeTree的副本版本。读取集群数据需要使用分布式表引擎Distribute。
6、多线程与分布式
如果说向量化执行是通过数据级并行的方式提升了性能,那么多线程处理就是通过线程级并行的方式实现了性能的提升。相比基于底层硬件实现的向量化执行SIMD,线程级并行通常由更高层次的软件层面控制。由于SIMD不适合用于带有较多分支判断的场景,ClickHouse也大量使用了多线程技术以实现提速,以此和向量化执行形成互补。
ClickHouse使用分布式分而治之的思想,利用多台服务的资源协同处理。在数据层面预先将数据分布到各太服务器,在计算层面,将数据的计算查询直接下推到数据所在服务器。在数据存取方面,既支持分区(纵向扩展,利用多线程原理),也支持分片(横向扩展,利用分布式原理),可以说是将多线程和分布式的技术应用到了极致。
7、多主架构
HDFS、Spark、HBase和Elasticsearch这类分布式系统,都采用了Master-Slave主从架构,由一个管控节点作为Leader统筹全局。而ClickHouse则采用Multi-Master多主架构,集群中的每个节点角色对等,客户端访问任意一个节点都能得到相同的效果。这种多主的架构有许多优势,例如对等的角色使系统架构变得更加简单,不用再区分主控节点、数据节点和计算节点,集群中的所有节点功能相同。所以它天然规避了单点故障的问题,非常适合用于多数据中心、异地多活的场景。
8、数据分片与分布式查询
数据分片是将数据进行横向切分,这是一种在面对海量数据的场景下,解决存储和查询瓶颈的有效手段,是一种分治思想的体现。
ClickHouse支持分片,而分片则依赖集群。每个集群由1到多个分片组成,而每个分片则对应了ClickHouse的1个服务节点。分片的数量上限取决于节点数量(1个分片只能对应1个服务节点)。
ClickHouse并不像其他分布式系统那样,拥有高度自动化的分片功能。ClickHouse提供了本地表(Local Table)与分布式表(Distributed Table)的概念。一张本地表等同于一份数据的分片。而分布式表本身不存储任何数据,它是本地表的访问代理,其作用类似分库中间件。借助分布式表,能够代理访问多个数据分片,从而实现分布式查询。
这种设计类似数据库的分库和分表,十分灵活。例如在业务系统上线的初期,数据体量并不高,此时数据表并不需要多个分片。所以使用单个节点的本地表(单个数据分片)即可满足业务需求,待到业务增长、数据量增大的时候,再通过新增数据分片的方式分流数据,并通过分布式表实现分布式查询。
1.3 clickhouse性能测试
官网提供的测试:ClickBench — a Benchmark For Analytical DBMS
专家测试:http://www.clickhouse.com.cn/topic/5c453371389ad55f127768ea

1.4 clickhouse适用和不适用场景
官网文档:OLAP使用场景
总结:
- 数据只是添加到数据库,没有必要修改
- 读取数据时,会从数据库中提取出大量的行,但只用到一小部分列
- 大宽表,读大量行但是少量列,结果集较小,列的值是比较小的数值和短字符串
- 数据需要以大批次(大于1000行)进行更新,而不是单行更新;或者根本没有更新操作
- 无需事务,数据一致性要求低
- 每次查询中只会查询一个大表。除了一个大表,其余都是小表
- 查询结果显著小于数据源。即数据有过滤或聚合。返回结果不超过单个服务器内存大小
2 clickhouse的使用
官网在线测试链接:https://play.clickhouse.tech/?file=welcome
2.1 数据类型
基础类型只有数值、字符串和时间三种类型,没有 Boolean 类型,但可以使用整型的 0 或 1 替代。
ClickHouse 的数据类型和常见的其他存储系统的数据类型对比:
| MySQL |
Hive |
CLickHouse(区分大小写) |
| byte |
TINYINT |
Int8 |
| short |
SMALLINT |
Int16 |
| int |
INT |
Int32 |
| long |
BIGINT |
Int64 |
| varchar |
STRING |
String |
| timestamp |
TIMESTAMP |
DateTime |
| float |
FLOAT |
Float32 |
| double |
DOUBLE |
Float64 |
| boolean |
BOOLEAN |
无 |
看官网:数据类型 | ClickHouse Docs
说明:Clickhouse的字段默认是不允许为NULL的,如果数据有可能为NULL,需要将字段定义为类似Nullable(Int64)的类型。
2.2 存储引擎
ClickHouse 提供了大约 28 种表引擎,各有各的用途,比如有 Log 系列用来做小表数据分析,MergeTree 系列用来做大数据量分析,而 Integration 系列则多用于外表数据集成。再考虑复制表Replicated 系列,分布式表 Distributed 等,纷繁复杂,新用户上手选择时常常感到迷惑。
ClickHouse表引擎一共分为四个系列,分别是Log、MergeTree、Integration、Special。其中包含了两种特殊的表引擎Replicated、Distributed,功能上与其他表引擎正交,根据场景组合使用。
最强大的表引擎当属 MergeTree (合并树)引擎及该系列(*MergeTree)中的其他引擎。对于大多数正式的任务,推荐使用MergeTree 族中的引擎。因为只有合并树系列的表引擎才支持主键索引、数据分区、数据副本和数据采样这些特性,同时也只有此系列的表引擎支持ALTER相关操作。
Log、Special、Integration 主要用于特殊用途,场景相对有限。MergeTree 系列才是官方主推的存储引擎,支持几乎所有 ClickHouse 核心功能。
存储引擎,去查阅官方文档
2.2.1 表引擎概览

一共分为四个系列,分别是Log、MergeTree、Integration、Special。其中包含了两种特殊的表引擎Replicated、Distributed,功能上与其他表引擎正交。表引擎(即表的类型)决定了:
(1)数据的存储方式和位置,写到哪里以及从哪里读取数据
(2)支持哪些查询以及如何支持。
(3)并发数据访问。
(4)索引的使用(如果存在)。
(5)是否可以执行多线程请求。
(6)数据复制参数。
2.2.2 翻牌子存储引擎如何选
1、Log系列
Log系列表引擎功能相对简单,主要用于快速写入小表(1百万行左右的表),然后全部读出的场景。
几种Log表引擎的共性是:
- 数据被顺序append写到磁盘上;
- 不支持delete、update;
- 不支持index;
- 不支持原子性写;
- insert会阻塞select操作。
它们彼此之间的区别是:
- TinyLog:不支持并发读取数据文件,查询性能较差;格式简单,适合用来暂存中间数据;
- StripLog:支持并发读取数据文件,查询性能比TinyLog好;将所有列存储在同一个大文件中,减少了文件个数;
- Log:支持并发读取数据文件,查询性能比TinyLog好;每个列会单独存储在一个独立文件中。
2、Integration系列
该系统表引擎主要用于将外部数据导入到ClickHouse中,或者在ClickHouse中直接操作外部数据源。
- Kafka:将Kafka Topic中的数据直接导入到ClickHouse;
- MySQL:将Mysql作为存储引擎,直接在ClickHouse中对MySQL表进行select等操作;
- JDBC/ODBC:通过指定jdbc、odbc连接串读取数据源;
- HDFS:直接读取HDFS上的特定格式的数据文件;
3、Special系列
Special系列的表引擎,大多是为了特定场景而定制的。这里也挑选几个简单介绍,不做详述。
- Memory:将数据存储在内存中,重启后会导致数据丢失。查询性能极好,适合于对于数据持久性没有要求的1亿一下的小表。在ClickHouse中,通常用来做临时表。
- Buffer:为目标表设置一个内存buffer,当buffer达到了一定条件之后会flush到磁盘。
- File:直接将本地文件作为数据存储;
- Null:写入数据被丢弃、读取数据为空;
4、MergeTree系列
Log、Special、Integration主要用于特殊用途,场景相对有限。MergeTree系列才是官方主推的存储引擎,支持几乎所有ClickHouse核心功能。
1、一般情况下使用MergeTree引擎即可。
2、子类引擎使用
特殊功能:发生在分区合并时
ReplacingMergeTree:解决数据去重问题,有相同主键无法去重的问题,主要基于order by后的字段进行去重。
CollapsingMergeTree:数据删除问题,以增代删。缺陷:多线程情况下,乱序写入,无法删除。
VersionedCollapsingMergeTree:数据删除问题,以增代删。解决CollapsingMergeTree缺陷
SummingMergeTree:特定数据合并问题,主要基于order by后的字段进行sum聚合。
AggregatingMergeTree:特定数据合并问题,主要基于order by后的字段进行AggregateFunction 类型的聚合
5、Distributed 分布式引擎
Distributed 分布式引擎本身不存储数据, 但可以在多个服务器上进行分布式查询。
2.3 clickhouse的SQL特性
参见知识库其他文档:clickhouse的语法特性 vs maxcomputer
2.4 ClickHouse的函数
ClickHouse中至少存在两种类型的函数
- 常规函数:每一行执行一次函数计算一样(对于每一行,函数的结果不依赖于其他行)
- 聚合函数。 合函数则从各行累积一组值
- arrayJoin函数 与 表函数 均属于第三种类型的函数
官网资料:Functions | ClickHouse Docs

自定义函数实现,知识库《ClickHouse源码:函数&自定义函数》
3 实践与应用
3.1 基于ClickHouse数仓分层
ck适合的数据模型
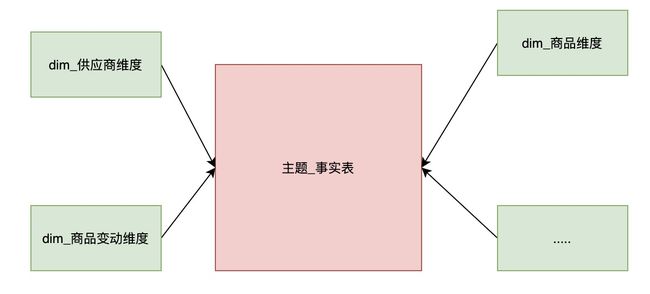
ck数仓数据模型采用星型模型搭建,星型架构是一种非正规化的结构,多维数据集的每一个维度都直接与事实表相连,不存在渐变维度,所以数据有一定冗余。因为有冗余,所以很多统计不需要做外部的关联查询,因此一般情况下效率比雪花模型高。
说明:使用星型模型搭建即最大限度的允许数据冗余,减少必要的外表连接,提高sql效率
3.2 电信用户画像案例分析
基于clickHouse数据架构

1、数据流程处理
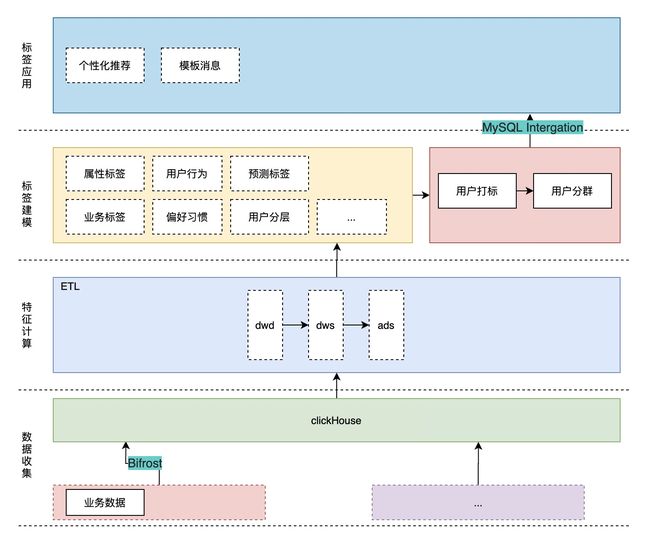
2、任务调度

3、数据导出实现

定义引擎类别MySQL,直接进行操作。
clear_dx_user_group_001 数据源是mysql;export_dx_user_group_001数据源是clickhouse。
4、bitmap函数在用户画像中实现
核心表:
CREATE TABLE IF NOT EXISTS ctuserbasecoredb.app_dx_portrait_tag_umap_1d
(
dw_gmt_create DateTime COMMENT '日期',
ds FixedString(8) COMMENT '数据分区 yyyymmdd',
tag_id String COMMENT '标签id',
tag_value String COMMENT '标签值',
us AggregateFunction(groupBitmap,UInt64) COMMENT '用户uid集合形成bitmapping'
)engine=AggregatingMergeTree()
partition by ds
order by (tag_id,tag_value)
-- 指定数据生命周期为7天,数据备份,到指定卷或者磁盘
TTL dw_gmt_create + INTERVAL 7 DAY
-- 索引粒度,默认8192
SETTINGS index_granularity = 8192
COMMENT '标签-标签聚合用户表-全量表(tag->uidbitmap)';
聚集:
INSERT INTO TABLE ctuserbasecoredb.app_dx_portrait_tag_umap_1d
select
now() AS dw_gmt_create
,'${before_date_str}' AS ds
,t.tag_id
,t.tag_value
,groupBitmapState(t.bit_map_id) AS us
from (
select
s1.tag_id
,s1.out_user_id
,s1.tag_value
,s2.bit_map_id
from(
SELECT
tag_id
,out_user_id
,tag_value
FROM ctuserbasecoredb.dwb_dx_portrait_user_lni_act_1d
where ds = '${before_date_str}'
UNION ALL
select
tag_id
,out_user_id
,tag_value
FROM ctuserbasecoredb.dwb_dx_portrait_user_attr_1d
where ds = '${before_date_str}'
)s1
join (
select out_user_id,bit_map_id
from ctuserbasecoredb.dim_dx_user_bitmap_id_df
where ds = '${before_date_str}'
)s2
on s1.out_user_id = s2.out_user_id
)t
group by t.tag_id,t.tag_value;
关键SQL:
insert into app_dx_portrait_group_tag_aggregation_1d
select now() as dw_gmt_create
,'{self.ds_partition}' as ds
,'{group_id}' as group_id
,s2.out_user_id as out_user_id
,s2.tag_detail
,now() as base_time
from ( select arrayJoin(bitmapToArray(t.us)) as id from ({group_tag_conditions_sql})t) s1
join (
select out_user_id,bit_map_id,tag_detail
from dim_dx_user_bitmap_id_df
where ds = '20211013'
)s2
on s1.id = s2.bit_map_id
group_tag_conditions_sql:
select arrayJoin(bitmapToArray(t.us)) as id
from (
select groupBitmapOrState(us) as us from (
select groupBitmapAndState(us) as us from (
select us from app_dx_portrait_tag_umap_1d where ds='20211013' and tag_id='DX_01_AB_0001' and tag_value = 'true'
UNION ALL
select us from app_dx_portrait_tag_umap_1d where ds='20211013' and tag_id='DX_01_AA_0001' and tag_value = 'true'
UNION ALL
select us from app_dx_portrait_tag_umap_1d where ds='20211013' and tag_id='DX_01_AA_0002' and tag_value = '电信'
UNION ALL
select groupBitmapOrState(us) as us from app_dx_portrait_tag_umap_1d where ds='20211013' and tag_id='DX_01_AA_0003' and tag_value in ('未知', '浙江', '上海', '北京', '湖北')
)
)
)
3.3 ClickHouse监控
知识库文档:ClickHouse 监控平台
监控 | ClickHouse Docs
这是官网给出的方案:基于prometheus + grafana生态。
测试环境:http://172.31.28.31:3000/d/10Bw94W7z/clickhousece-shi-huan-jing?orgId=1
4 clickhouse优化
4.1 Clickhouse SQL常规优化
单表查询:
- Prewhere替代where
- 列裁剪与分区裁剪,代替使用select *
- orderby 结合where、limit
- 避免构建虚拟列(as xx),不要在结果集上构建虚拟列,虚拟列非常消耗资源浪费性能,可以考虑在前
- uniqCombined替代distinct ,uniqCombined底层采用类似HyperLogLog算法实现,能接收2%左右的数据误差,可直接使用这种去重方式提升查询性能。
多表查询:
- 用IN 代替JOIN
insert into hits_v2 select a.* from hits_v1 a where a. CounterID in (select CounterID from visits _v1
- 大小表JOIN ,小表在右
insert into table hits_v2 select a.* from hits_v1 a left join visits_v 2 b on a. CounterID=b. CounterID;
- 注意谓词下推(版本差异),每个子查询提前完成过滤操作
- 分布式表使用GLOBAL
- 使用字典表,字典表会常驻内存,在需要进行关联分析的业务中使用
4.2 clickhouse explain
基本语法:
EXPLAIN [AST | SYNTAX | PLAN | PIPELINE] [setting = value, ...] SELECT ... [FORMAT ...]
➢ PLAN:用于查看执行计划,默认值。
- header 打印计划中各个步骤的head 说明,默认关闭,默认值0;
- description 打印计划中各个步骤的描述,默认开启,默认值1;
- actions 打印计划中各个步骤的详细信息,默认关闭,默认值0。
➢ AST :用于查看语法树;
➢ SYNTAX:用于优化语法;
➢ PIPELINE:用于查看PIPELINE 计划。
- header 打印计划中各个步骤的head 说明,默认关闭;
- graph 用DOT图形语言描述管道图,默认关闭,需要查看相关的图形需要配合graphviz查看;
- actions 如果开启了graph,紧凑打印打,默认开启。
注:PLAN 和PIPELINE 还可以进行额外的显示设置,如上参数所示。
-- 先做一次查询 SELECT number = 1 ? 'hello' : (number = 2 ? 'world' : 'hello') FROM numbers(10); -- 查看语法优化 EXPLAIN SYNTAX SELECT number = 1 ? 'hello' : (number = 2 ? 'world' : 'hello') FROM numbers(10); -- 开启三元运算符优化 SET optimize_if_chain_to_multiif = 1; -- 再次查看语法优化 EXPLAIN SYNTAX SELECT number = 1 ? 'hello' : (number = 2 ? 'world' : 'hello') FROM numbers(10); -- 返回优化后的语句 SELECT if(number = 1, 'hello', if(number = 2, 'world', 'hello')) FROM numbers(10);