ADBPG&Greenplum 成本优化之磁盘水位管理

一 背景描述
目前,企业的核心数据一般都以二维表的方式存储在数据库中。在核心技术自主可控的大环境下,政企行业客户都在纷纷尝试使用国产数据库或开源数据库,尤其在数据仓库OLAP领域的步伐更快,Greenplum的应用越来越广泛,阿里云ADB PG的市场机会也越来越多。另外,随着近年来数据中台的价值被广泛认可,企业建设数据中台的需求也非常迫切,数据中台的很多场景都会用到Greenplum或ADB PG。因此,今年阿里云使用ADB PG帮助很多客户升级了核心数仓。我们发现,客户往往比较关注使用云原生数仓的成本。究竟如何帮助客户节约成本,便值得我们去探索和落地。
ADB PG全称云原生数据仓库AnalyticDB PostgreSQL版,它是一款大规模并行处理(MPP)架构的数据库,是阿里云基于开源Greenplum优化后的云原生数据仓库,因此本文探讨的成本优化方法也适用于Greenplum开源版。图1是ADB PG的架构示意图(Greenplum亦如此),Master负责接受连接请求,SQL解析、优化、事务等处理,并分发任务到Segment执行;并协调每一个Segment返回的结果以及把最终结果呈现给客户端程序。Segment是一个独立的PostgreSQL数据库,负责业务数据的存储和计算,每个Segment位于不同的独立物理机上,存储业务数据的不同部分,多个Segment组成计算集群;集群支持横向扩展。从架构上很清楚,节约Greenplum的成本,最重要的是要尽可能节约Segment的服务器数,但既要保证整体MPP的算力,也要能满足数据对存储空间的需求。通常,数据仓库中的数据是从企业各个领域的上游生产系统同步而来,这些数据在分析领域有生命周期,很多数据需要反应历史变化,因此数据仓库中数据的特点是来源多、历史数据多、数据量比较大。数据量大,必然消耗存储空间,在MPP架构下就是消耗服务器成本。帮客户优化成本,节约存储空间是首当其冲的。

图1:ADB PG的架构示意图
下面,我们将通过一个实际的磁盘空间优化案例来说明,如何帮助客户做成本优化。
二 ADB PG & Greenplum的磁盘管理简介
1 ADB PG磁盘管理的关键技术点
ADB PG是基于Greenplum(简称“GP”)内核修改的MPP数据库,对于磁盘空间管理来讲,有几个技术点与Greenplum是通用的:
(1)业务数据主要分布在Segment节点;
(2)Segment有Primary和Mirror节点,因此,业务可用空间是服务器总空间的1/2;
(3)Greenplum的MVCC机制,导致表数据发生DML后产生垃圾数据dead tuples;
(4)复制表(全分布表)会在每个Segment上存储相同的数据拷贝;分布表会根据分布键打散存储数据到各个Segment。
(5)Greenplum有Append Only类型的表,支持压缩存储,可以节约空间;当然用户访问时,解压缩需要时间,所以需要在性能和空间之间取得平衡。
云原生数据库的特点是不再单独提供数据库存储和计算的内核,也会配套运维管理平台,简称“数据库管控”。搞清楚ADB PG磁盘管理原理后,我们需要了解数据库管控在磁盘水位管理方面的设计。
2 数据库管控的磁盘预留机制
我们看下某数仓实验环境的各个Segment节点的磁盘占用示意图。
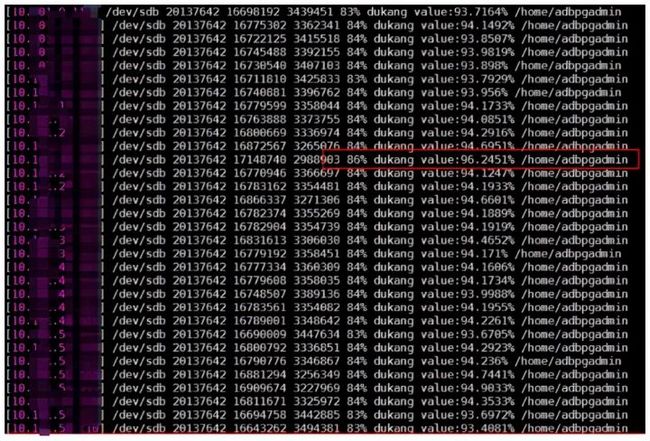
图2:Segment维度的磁盘占用示意图
上图第一个百分比是Segment所在物理机的磁盘使用百分比;第二个百分比是数据库管控的磁盘使用百分比。管控的数据为啥要跟服务器实际占用不一致呢?其实就是水位管理中第一个很重要的预防性措施:空间预留。即,ADB的管控在创建Segment实例时,根据服务器的空间,进行了一定的预留,占比大概是12%,即20T的服务器,管控认为业务最大可用17.6T,这个逻辑会通知监控系统。所以计算磁盘占比时,监控系统的分母不是20T,而是17.6T。这是第一级保护措施。
预留空间,还有重要的一点原因是数据库本身有WAL事务日志、错误日志等也占用空间。因此,磁盘的空间有一部分需要给日志使用,客户的业务数据无法使用100%的服务器空间,这就是为何图2中,会显示两个空间百分比的原因。
3 数据库管控的“锁定写” 保护机制
第二级保护措施是“磁盘满锁定写”。在17.6T的基础上,管控并不让业务完全写满,写满容易造成数据文件损坏,带来数据库宕机及无法恢复的灾难。因此,这里有第二个阈值,即当磁盘写到90%时,数据库管控的自动巡检任务会启动“锁定写”的操作,此时所有请求ADB的DML都会失败。这是一个重要的保护机制。如下图3所示,如果达到阈值,会提示“need to lock”。 阈值可以配置,如果磁盘空间紧张,可以根据实际情况适当调大阈值。

图3:数据库管控的自动化锁盘日志示例
以上数据库管控的两个机制可以有效保障磁盘在安全水位下运行。这些设计,是我们做成本优化的基础,磁盘的成本优化意味着服务器的磁盘尽可能物尽其用。节约磁盘空间,就必须要在相对较高的磁盘水位运行(这里是指数据量确实很大的情况),因此,磁盘有效管理,及时的问题监控发现的机制非常重要。
三 磁盘空间优化方案
下面我们以某客户的案例来说明磁盘空间优化方法。该客户数据仓库中的数据(含索引)大于1.5PB,但客户一期为ADB数仓采购了40台机器,约800T总容量。客户明确要求阿里云需要配合业务方做好数仓设计,帮其节约成本。客户把成本优化的KPI已经定好了,需要阿里云通过技术去落实。我们协同业务方在设计阶段做了一些预案,技术上主要从表压缩和冷热数据分离的角度去做考虑;业务上,让开发商从设计上,尽量缩减在ADB中的存量数据。最终,开发商预估大概有360T左右的热数据从旧的数仓迁移到ADB。上线前,开发商需要把必要的基础业务数据(比如贴源层,中间层),从DB2迁移到ADB PG。迁移完成,业务进行试运行期,我们发现空间几乎占满(如图2)。空间优化迫在眉睫,于是我们发起了磁盘空间优化治理。图4是磁盘空间治理优化的框架。

图4:磁盘水位优化框架
接下来,我们展开做一下说明。
1 表的存储格式及压缩
表的压缩存储可以有效保障客户节约存储空间。Greenplum支持行存、Append-only行存、Append-only列存等存储格式。若希望节约存储空间,Append-only列存表是较好的选择,它较好的支持数据压缩,可以在建表时指定压缩算法和压缩级别。合适的压缩算法和级别,可以节约数倍存储空间。建表示例语句如下:
CREATE TABLE bar (id integer, name text)
WITH(appendonly=true, orientation=column, COMPRESSTYPE=zstd, COMPRESSLEVEL=5)
DISTRIBUTED BY (id);列存表必须是Append-only类型,创建列存表时,用户可以通过指定COMPRESSTYPE字段来指定压缩的类型,如不指定则数据不会进行压缩。目前支持三种压缩类型:
zstd、zlib和lz4,zstd算法在压缩速度、解压缩度和压缩率三个维度上比较均衡,实践上推荐优先考虑采用zstd算法。zlib算法主要是为了兼容一些已有的数据,一般新建的表不采用zlib算法。lz4算法的压缩速度和压缩率不如zstd,但是解压速度明显优于zstd算法,因此对于查询性能要求严格的场景,推荐采用lz4算法。
用户可以通过指定COMPRESSLEVEL字段来决定压缩等级,数值越大压缩率越高,取值范围为1-19,具体压缩等级并不是数字越大越好,如上文所述,解压缩也消耗时间,压缩率高,则解压缩会相对更慢。因此,需要根据业务实际测试来选定,一般5-9都是有实际生产实践的压缩级别。
2 冷热数据分层存储
在大型企业的数据仓库设计中,MPP数据库(ADB属于MPP)只是其中一种数据存储,而且是偏批处理、联机查询、adHoc查询的场景使用较多;还有很多冷数据、归档数据,其实一般都会规划类似Hadoop、MaxCompute甚至OSS进行存储;另外,近年来兴起的流数据的计算和存储,需求也非常强烈,可以通过Kafka、Blink、Storm来解决。因此,当MPP数据库空间告急时,我们也可以做冷热数据分级存储的方案。ADB PG的分级存储方案,大致有两种:1是业务方自己管理冷数据和热数据;2是利用ADB PG冷热数据分层存储和转换功能。
业务方通过PXF外表访问HDFS冷数据
业务方把部分冷数据以文件的方式存到HDFS或Hive,可以在ADB创建PXF外部表进行访问;外部表不占用ADB PG的磁盘空间。PXF作为Greenplum与Hadoop集群数据交互的并行通道框架,在Greenplum中通过PXF可以并行加载和卸载Hadoop平台数据。具体使用方法如下:
(1)控制台开通PXF服务
· 登录ADB管控台,访问ADB PG实例外部表页面,点击开通新服务

图5:PXF外表服务
填写详细的Hadoop的服务信息后(涉及kerberos认证,非此文重点),PXF服务会启动,启动成功后如上图。
(2)创建PXF扩展
-- 管理员执行
create extension pxf_fdw;(3)创建PXF外表
CREATE EXTERNAL TABLE pxf_hdfs_textsimple(location text, month text, num_orders int, total_sales float8)
LOCATION ('pxf://data/pxf_examples/pxf_hdfs_simple.txt?PROFILE=hdfs:text&SERVER=23')
FORMAT 'TEXT' (delimiter=E',');说明:Location是hdfs源文件信息,/data/pxf_examples/pxf_hdfs_simple.txt,即业务访问的外部冷数据文件;SERVER=23指明了Hadoop外表的地址信息,其中23是集群地址信息的存放目录,在图8中可以根据PXF服务查到。
(4)访问外部表
访问外部表就和访问普通表没有区别

图6:外部表访问示例
ADB PG冷热数据分层存储方案
上面的pxf外表访问,有一个弊端,是如果冷数据(外表)要和热数据join,效率较差,原因是数据要从HDFS加载到ADB,再和ADB的表进行Join,徒增大量IO。因此,ADB PG在Greenplum的PXF外表的基础上,提供了冷热数据转换的功能,业务方可以在需要Join外表和普通表分析时,把外部表先转换为ADB的普通表数据,再做业务查询,整体方案称为冷热数据分层存储。由于都是利用PXF外表服务,3.4.1中的第1和第2步骤可以复用。额外的配置方法如下:
(1) 配置分层存储默认使用刚才的Foreign Server
用超级管理员执行
ALTER DATABASE postgres SET RDS_DEF_OPT_COLD_STORAGE TO 'server "23",resource "/cold_data", format "text",delimiter ","';注意,这里需要将postgres替换为实际的数据库名,并将/cold_data替换为实际在HDFS上需要用来存储冷数据的路径。
(2) 重启数据库实例后执行检查
SHOW RDS_DEF_OPT_COLD_STORAGE;验证是否配置成功。
(3) 创建测试表,并插入少量测试数据
create table t1(a serial) distributed by (a);
insert into t1 select nextval('t1_a_seq') from generate_series(1,100);
postgres=# select sum(a) from t1;
sum
------
5050
(1 row)此时,t1表的数据是存在ADB的本地存储中的,属于热数据。
(4) 将表数据迁移到冷存HDFS
alter table t1 set (storagepolicy=cold);
图7:转换数据为冷数据
注意这个NOTICE在当前版本中是正常的,因为在冷存上是不存在所谓分布信息的,或者说分布信息是外部存储(HDFS)决定。
(5) 验证冷数据表的使用
首先,通过查看表的定义,验证表已经迁移到冷存

图8:冷存表的定义
然后正常查询表数据;
postgres=# select sum(a) from t1;
sum
------
5050
(1 row)(6) 将数据迁回热存
alter table t1 set (storagepolicy=hot);
图9:数据迁回热存
注意:迁移回热存后,distributed信息丢失了,这是当前版本的限制。如果表有索引,则索引在迁移后会丢失,需要补建索引。以上两个方案,都能一定程度上把冷数据从ADB PG中迁移到外部存储,节约ADB PG的空间。
方案1,Join效率低,不支持冷热数据转换,但不再占用ADB的空间;
方案2,Join效率高,支持冷热数据转换,部分时间需要占用ADB的空间。
两个方案各有利弊,实际上项目中,根据业务应用来定。在该客户案例中,冷热数据分层存储方案,为整体ADB节约了数百T空间,这数百T空间中,大部分是设计阶段解决的,少部分是试运行期间进一步优化的。
3 垃圾数据vacuum
由于GP内核的MVCC管理机制,一个表的DML(t2时刻)提交后的数据元组,实际上并没有立即删除,而是一直与该表的正常元组存储在一起,被标记为dead tuples;这会导致表膨胀而占用额外空间。垃圾数据回收有两个方法:内核自动清理、SQL手动清理。自动清理的机制是:表的dead tuples累积到一定百分比,且所有查询该表的事务(t1时刻 手动回收方法 (1)统计出系统的top大表; (2)查询大表的dead tuple占比和空间; -- 根据统计信息查询膨胀率大于20%的表 (3)使用pg_cron定时任务帮助业务回收垃圾数据 或 或 这里需要与业务沟通清楚执行时间,具体vacuum时,虽然不影响读写,但还是有额外的IO消耗。vacuum full tablename要慎重使用,两者的区别要重点说明一下:简单的VACUUM(没有FULL)只是回收表的空间并且令原表可以再次使用。这种形式的命令和表的普通读写可以并发操作,因为没有请求排他锁。然而,额外的空间并不返回给操作系统;仅保持在相同的表中可用。VACUUM FULL将表的全部内容重写到一个没有任何垃圾数据的新文件中(占用新的磁盘空间,然后删除旧表的文件释放空间),相当于把未使用的空间返回到操作系统中。这种形式要慢许多并且在处理的时候需要在表上施加一个排它锁。因此影响业务使用该表。 (4)vacuum加入业务代码的恰当环节进行回收 如果某些表,更新频繁,每日都会膨胀,则可以加入到业务的代码中进行vacuum,在每次做完频繁DML变更后,立即回收垃圾数据。 系统表也需要回收 这是一个极其容易忽视的点。特别是在某些数据仓库需要频繁建表、改表(临时表也算)的场景下,很多存储元数据的系统表也存在膨胀的情况,而且膨胀率跟DDL频繁度正相关。某客户出现过pg_attribute膨胀到几百GB,pg_class膨胀到20倍的情况。以下表,是根据实际总结出来比较容易膨胀的pg系统表。 图10:pg_class膨胀率示例 手动Vacuum的限制 手动做vacuum有一定的限制,也要注意。 (1)不要在IO使用率高的期间执行vacuum; (2)vacuum full需要额外的磁盘空间才能完成。 如果磁盘水位高,剩余空间少,可能不够vacuum full大表;可以采取先删除一些历史表,腾出磁盘空间,再vacuum full目标table。 (3)必须先结束目标table上的大事务 有一次例行大表维护时,一个表做了一次vacuum,膨胀的空间并没有回收,仔细一查pg_stat_activity,发现这个表上有一个大事务(启动时间比手动vacuum启动更早)还没结束,这个时候,内核认为旧的数据还可能被使用,因此还不能回收,手动也不能。 4 冗余索引清理 索引本身也占用空间,尤其大表的索引。索引是数据库提高查询效率比较常用又基础的方式,用好索引不等于尽可能多的创建索引,尤其在大库的大表上。空间紧张,可以试着查一下是否有冗余索引可以清理。 排查思路 (1)是否有包含“异常多”字段的复合索引; (2)是否有存在前缀字段相同的多个复合索引; (3)是否存在优化器从来不走的索引。 排查方法与例子 首先,我们从第1个思路开始,查询索引包含字段大于等于4个列的表。SQL如下: 某个客户,就建了很多10个字段以上的复合索引,如下图所示: 图11:按索引列数排序的复合索引 一般超过6个字段的复合索引,在生产上都很少见,因此我们初步判断是建表时,业务方创建了冗余的索引;接下来,可以按照索引的大小排序后输出冗余索引列表。SQL如下: 图12:按大小排序的复合索引 这里,我们很清楚发现,部分索引的大小都在500G以上,有10多个索引的size超过1TB,看到这些信息时,我们震惊又开心,开心的是应该可以回收很多空间。接下来,需要跟业务方去沟通,经过业务方确认不需要再删除。 在这个客户案例中,我们删除了200多个冗余索引,大小达24T,直接释放了7%的业务空间!非常可观的空间优化效果。这次优化也非常及时,我记得优化在11月底完成;接着正好12月初高峰来临,业务方又写入了20TB新数据,如果没有这次索引优化,毫不夸张:12月初该客户的ADB集群撑不住了! 第(2)个思路(是否有存在前缀字段相同的多个复合索引),排查SQL如下。最好把索引及包含的字段元数据导出到其他GP库去分析,因为涉及到索引数据的分析对比(涉及向量转字符数组,以及子集与超集的计算),比较消耗性能; 以下是排查例子user_t上复合第2个问题的索引,如下: 以下是查询结果 以上例子结果解释:multi_index1是multi_index2的子集,前者的索引列已经在后者中做了索引,因此,multi_index1属于冗余索引。 第(3)个思路:是否存在优化器从来不走的索引,排查的SQL如下: 下面以一个测试表,讲述排查例子 执行SQL可以查到idx_scan=0的索引idx_b 另外,有一个很重要的知识点,Append-Only列存表上的索引扫描只支持bitmap scan方式,如果Greenplum关闭了bitmap scan的索引扫描方式,那么所有AO列存表的访问都会全表扫描,即理论上AO列存表上的所有非唯一索引都无法使用,可以全部drop掉。当然,这个操作风险很高,要求整个database里使用AO列存表的业务几乎都只做批处理,不存在点查或范围查找的业务。综上,删除冗余索引,可以帮助客户节约磁盘空间。 5 复制表修改为分布表 众所周知,ADB PG的表分布策略有DISTRIBUTED BY(哈希分布),DISTRIBUTED RANDOMLY(随机分布),或DISTRIBUTED REPLICATED(全分布或复制表)。前两种的表会根据指定的分布键,把数据按照hash算法,打散分布到各个Segment上;复制表,则会在每个Segment上存放完整的数据拷贝。复制表分布策略(DISTRIBUTED REPLICATED)应该在小表上使用。将大表数据复制到每个节点上无论在存储还是维护上都是有很高代价的。查询全分布表的SQL如下: 查询结果如下图,找到了大概10TB的全分布表,前3个表较大可以修改为哈希分布表,大概可以节约7T空间。 图13:业务库中的复制表 6 临时表空间独立存放 我们知道,Greenplum的默认表空间有两个 如果建表不指定表空间,默认会放到pg_default表空间,包含堆表、AO表、列存表、临时表等。具体到Segment的文件目录,则是每个Segment服务器上的~/data/Segment/${Segment_id}/base/${database_oid}目录下。同时,Greenplum在多种场景都会产生临时表,如: (1)sql中order by、group by等操作; (2)GP引擎由于数据读取或shuffle的需要,创建的临时表; (3)业务方在ETL任务中创建的临时表。 这样存在一个问题,就是业务运行产生的临时表也会占用空间,但这部分不是业务表的数据占用,不方便精确管理大库的磁盘空间;因此我们把临时表的表空间独立出来,在服务器文件层面也独立出来,方便与业务数据进行分别精细化管理。好处还有:我们可以分别监控临时表空间、数据表空间、wal日志、错误日志,知道各个部分占用情况,如果磁盘空间告警,可以针对性采取措施。Greenplum创建临时表空间的方法,比较标准,如下: 表空间独立后,监控可以区分临时表空间、数据表空间、WAL日志、错误日志进行独立监控和告警,以下是监控采集输出的样例: 监控输出的效果如下 图14:监控采集输出示意图 这样可以很清楚的了解业务数据或临时表数据在每个节点上的实际size,以及是否存在数据倾斜情况(超过平均值的10%)单独提醒,非常实用。 7 其他优化方案 除了上面详述的优化方案,一般来讲,Greenplum还有一些通用的处理方法:扩容Segment计算节点、业务数据裁剪、备份文件清理。计算节点扩容是最有效的。一般来讲,不管是阿里自己的业务,还是外部客户的业务,数据库的磁盘占用达到60%,考虑业务增量便会规划扩容,这些“基本实践”我们需要告诉客户。 业务数据裁剪,除了冷数据外,有一些中间表和历史表,我们也可以推动业务方做好数据生命周期管理,及时删除或转存归档。另外,对于临时运维操作,留下的备份文件,在操作完后需要及时进行清理,这个简单的习惯是非常容易忽略的,需要注意。在大库的磁盘管理中,任何小问题都会放大。 1 为客户节约服务器成本 本案例,客户原DB2的数据量大于1PB,而我们通过上述方法综合优化,在ADB中只保存了300多T的数据,就让整体业务完整的运行起来。为客户节约了大概100台服务器及相关软件license费用,约合金额千万级别。 2 避免磁盘水位过高造成次生灾害 磁盘水位高会带来很多问题,通过磁盘空间优化方案,可以避免这些问题的发生。包括: 1.业务稍微增长,可能导致磁盘占满,发生“写锁定”,数据库临时罢工; 2.磁盘空间不足时,运维人员定位问题无法创建临时表; 3.ADB的大表维护,例如vacuum full,无空余磁盘空间使用。 以上磁盘空间优化方法不一定非常全面,希望对读者有所帮助。如果文中有疏漏或读者有补充,欢迎多多交流,一起探讨上云成本优化。 名词解释 业务方:指使用Greenplum做业务开发或数据分析的用户,通常是客户或客户的开发商。 OLAP:指联机分析处理型系统,是数据仓库系统最主要的应用,专门设计用于支持复杂的大数据量的分析查询处理,并快速返回直观易懂的结果。 DML:指增加、删除、修改、合并表数据的SQL,在数据库领域叫DML型SQL。 PB:1PB=1024TB=1024 * 1024 GB 作者 | 玉翮 原文链接 本文为阿里云原创内容,未经允许不得转载。select *,pg_size_pretty(size) from
(select oid,relname,pg_relation_size(oid) as size from pg_class where relkind = 'r' order by 3 desc limit 100)t;
-- limit 100表示top100SELECT ((btdrelpages/btdexppages)-1)*100||'%', b.relname FROM gp_toolkit.gp_bloat_expected_pages a
join pg_class b on a.btdrelid=b.oid
where btdrelpages/btdexppages>1.2;vacuum tablename;vacuum analyze tablename;-- 先执行一个VACUUM 然后是给每个选定的表执行一个ANALYZEvacuum full tablename;pg_attribute -- 存储表字段详情
pg_attribute_encoding -- 表字段的扩展信息
pg_class -- 存储pg的所有对象
pg_statistic -- 存储pg的数据库内容的统计数
with t as (select indrelid, indkey,count(distinct unnest_idx) as unnest_idx_count
from pg_catalog.pg_index, unnest(indkey) as unnest_idx group by 1,2
having count(distinct unnest_idx)>=4 order by 3 desc)
select relname tablename,t.unnest_idx_count idx_cnt from pg_class c ,t where c.oid=t.indrelid;
with t as (select indrelid,indexrelid, indkey,count(distinct unnest_idx) as unnest_idx_count
from pg_catalog.pg_index, unnest(indkey) as unnest_idx group by 1,2,3
having count(distinct unnest_idx)>=3 order by 3 desc
)
select relname tablename,(pg_relation_size(indexrelid))/1024/1024/1024 indexsize,
t.unnest_idx_count idx_cnt from pg_class c ,t where c.oid=t.indrelid order by 2 desc;
select idx1.indrelid::regclass,idx1.indexrelid::regclass, string_to_array(idx1.indkey::text, ' ') as multi_index1,string_to_array(idx2.indkey::text, ' ') as multi_index2,idx2.indexrelid::regclass
from pg_index idx1 , pg_index idx2 where idx1.indrelid= idx2.indrelid
and idx1.indexrelid!=idx2.indexrelid and idx1.indnatts > 1
and string_to_array(idx1.indkey::text, ' ') <@ string_to_array(idx2.indkey::text, ' ');

SELECT
PSUI.indexrelid::regclass AS IndexName
,PSUI.relid::regclass AS TableName
FROM pg_stat_user_indexes AS PSUI
JOIN pg_index AS PI
ON PSUI.IndexRelid = PI.IndexRelid
WHERE PSUI.idx_scan = 0
AND PI.indisunique IS FALSE;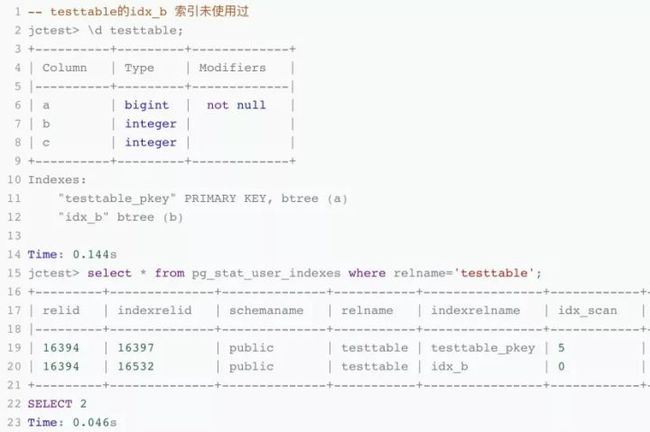

select n.nspname AS "schemaname",c.relname AS "tablename",case when p.policytype='p' then 'parted' when p.policytype='r' then 'replicated' else 'normal' end as "distrb_type", pg_size_pretty(pg_relation_size(c.oid))
from pg_class c
left join gp_distribution_policy p on c.oid=p.localoid
left join pg_namespace n on c.relnamespace=n.oid
where n.nspname='public'
and c.relkind='r'
and p.policytype='r'
order by 4 desc;

#查看临时表的表空间现状,发现都在base目录下,即与数据目录共用
postgres=# select * from pg_relation_filepath('tmp_jc');
pg_relation_filepath
----------------------
base/13333/t_845345
#查询实例的Segment的所有hosts,用于创建临时表空间目录
psql -d postgres -c 'select distinct address from gp_Segment_configuration order by 1' -t > sheng_seg_hosts
#创建临时表空间的文件目录
gpssh -f sheng_seg_hosts -e "ls -l /home/adbpgadmin/tmptblspace"
gpssh -f sheng_seg_hosts -e "mkdir -p /home/adbpgadmin/tmptblspace"
~$ gpssh -f dg_seg_hosts -e "ls -l /home/adbpgadmin/tmptblspace"
# 创建临时表空间
postgres=# create tablespace tmp_tblspace location '/home/adbpgadmin/tmptblspace';
postgres=# select * from pg_tablespace;
spcname | spcowner | spcacl | spcoptions
--------------+----------+--------+------------
pg_default | 10 | |
pg_global | 10 | |
tmp_tblspace | 10 | |
(3 rows)
#修改角色的临时表空间
postgres=# alter role all set temp_tablespaces='tmp_tblspace';
#退出psql,然后重新登录
#创建临时表进行验证
create temp table tmp_jc2(id int);
insert into tmp_jc2 select generate_series(1,10000);
#查看表的filepath,发现临时表空间的文件路径不是base目录了
select * from pg_relation_filepath('tmp_jc2');
---------------------------------------------------
pg_tblspc/2014382/GPDB_6_301908232/13333/t_845369~$ sh check_disk_data_size.sh
usage: sh check_disk_data_size.sh param1 param2, param1 is file recording Segment hosts; param2 data, xlog, log or temp
四 优化收益