selenium基础定位元素入门
参考文章链接
什么是selenium?
selenium是一个web自动化测试工具
selenium环境部署安装
首先需要安装python环境
1、安装
在cmd 直接输入 :pip install selenium
2、卸载:
在cmd输入:pip uninstall selenium
3、查看:
pip show selenium 或者 pip list
4、安装浏览器驱动
谷歌(国内镜像地址)
其他浏览器的话需要自行下载查看,对应自身浏览器的版本进行选择即可
若没发现对应的64位的驱动,用32位的也可以,不影响使用。
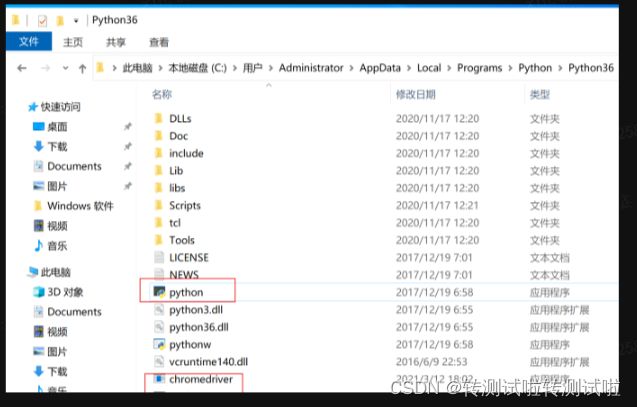
5、浏览器驱动安装
下载好驱动压缩包过后,解压得到 chromedriver.exe 驱动程序把他放进Python解释器根目录下,就ok了
selenium初体验
"""
web 自动化基本代码
"""
# 1、导包
from time import sleep
from selenium import webdriver
# 2、实例化浏览器对象:类名()
driver = webdriver.Chrome()
# 3、打开网页包含协议头
driver.get('https://www.baidu.com/')
# 4、时间轴观察效果
sleep(5)
# 5、关闭网页
driver.quit()
八大元素定位
浏览器点击f12或者右键点击浏览器的检查,调出开发者工具进行元素选择的调试
定位方式:
1、id
2、name
3、class_name(使用的是class属性进行定位)
4、teg_name (标签名称)
5、link_text(定位超链接 a 标签)
6、partial_link_text(定位超链接 a 标签 包含关系)
7、xpath (路径)
8、css (元素选择器)
id定位法(由于版本迭代,新版的selenium已经不再使用find_element_by_id方法。)
改用方法为:
driver.find_element(By.ID, 'kw').send_keys('苹果15')

同理其他方式定位则用By.对应的定位方式
name定位方式
说明:通过元素的name属性来定位, name一般名称为重复
提示:元素必须要有name属性
1、name方法:由于元素的 name 属性值可能存在重复, 必须确定其能够代表⽬标元素唯⼀性之后, ⽅可使⽤
2、当页⾯面内有多个元素的特征值是相同的时候, 定位元素的⽅法执⾏时,默认只会获取第⼀个符合要求的特征对应的元素
3、因此, 定位元素时需要尽量保证使⽤的特征值能够代表⽬标元素在当前⻚页⾯内的唯⼀性!否则定不了位,添加在第一个定位的位置
driver.find_element(By.NAME, 'wd').send_keys('苹果15')
class_name 方法
说明:通过元素的class属性来定位,class属性一般为多个值。
提示:元素必须要有class属性
driver.find_element(By.CLASS_NAME, 's_ipt').send_keys('苹果15')
tag_name 方法
说明:通过元素的标签名称来定位,标签名(查看元素时尖括号(<)紧挨着的单词或字母就是标签名) (标签名也就是元素名)
tag_name 方法:由于存在大量标签,并且重复性更高,因此必须确定其能够代表目标元素唯一性之后,方可以使用;如果页面中存在多个相同标签,默认返回第一个标签元素。
注意:一般标签重复性过高,要精确定位,都不会选择tag_name !
link_text
说明:定位超链接标签
注意:
1、只能使用精准匹配(a标签的全部文本内容)
2、该⽅法只针对超链接元素(a 标签),并且需要输入超链接的全部⽂本信息
driver.find_element(By.LINK_TEXT, '新闻').click()
partial_link_text
说明:定位超链接标签
注意:
1. 可以使用精准或模糊匹配,如果使用模糊匹配最好使用能代表唯一的关键词
2. 如果有多个值,默认返回第一个值
他和link_text的区别在于,他可以模糊的匹配,但link_text只能精确匹配
driver.find_element(By.PARTIAL_LINK_TEXT, '新').click()
定位一组元素的方法
通常我们定义元素方法的是 driver.find_element,但是也有driver.find_elements()这种element后面带s,表示执行结果返回的是列表类型,里面的数据是多个元素对象。
其用法与获取单个元素时差不多,但driver.find_elements()返回的则是一个数组列表
# 说明:通过元素的id属性定位,id一般情况下在当前页面中是唯一。
# 提示:元素必须要有id属性。
"""
语法:find_element_by_id(元素value)
1、元素定位:首先调用find_element_by_id(元素value)获得元素定位(过时了)
2、调用send_keys来填写内容
3、通过⽬标元素的 id 属性值定位, 由于 id 值一般是唯一的,因此当元素存在 id 属性值时, 优先使用 id 方法定位元素
"""
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
# 实例化浏览器对象
driver = webdriver.Chrome()
# 打开网址url
driver.get('https://www.baidu.com/')
# 需求
# driver.find_element_by_id('kw').send_keys('苹果15')
# driver.find_element(By.ID, 'kw').send_keys('苹果15')
# driver.find_element(By.NAME, 'wd').send_keys('苹果15')
# driver.find_element(By.CLASS_NAME, 's_ipt').send_keys('苹果15')
# driver.find_element(By.LINK_TEXT, '新闻').click()
# driver.find_element(By.PARTIAL_LINK_TEXT, '新').click()
aLinks = driver.find_elements(By.CLASS_NAME, 'c-color-t')
aLinks[0].click()
aLinks[1].click()
aLinks[2].click()
# 观察效果
sleep(3)
# 关闭网页
driver.quit()
总结:
1、id,name,class,都是依赖于元素这三个对应的属性,如果元素没有这个三个属性,定位方法不能使用;
2、link_text, partial_link_text: 只适合超链接定位
3、tag_name: 只能找页面唯一元素,或者 页面中多个相同元素中的第一个元素
xpath (重点掌握,这个是常用的方式)
说明:Xpath策略有多种,无论使用哪一种策略(方法),定位的方法都是同一个,不同策略只决定方法的参数的写法
什么是xpath定位
基于元素的路径定位
Xpath常用的定位策略:
绝对路径:从最外层元素到指定元素之间所有经过元素层级的路径 ,绝对路径是以/html根节点开始,使用 / 来分割元素层级
语法:/html/body/div/fieldset/form/p[1]/input (可能会有多个p标签,所以也是用索引的方式定位,是从一开始以便读者看懂)
绝对路径对页⾯结构要求比较严格,不建议使⽤!!!!
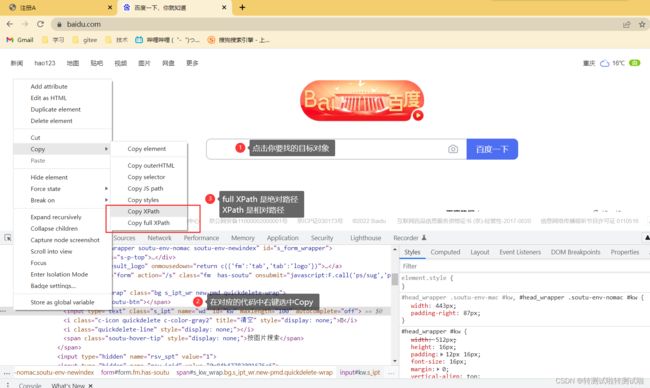
相对路径:匹配任意层级的元素,不限制元素的位置 ,相对路径是以 // 开始, // 跟元素名称,不知元素名称可以使用*代替。
语法://input 或者 //*
推荐使用相对路径!!
利用元素属性策略
1、路径结合属性
该方法可以使用目标元素的任意一个属性和属性值(需要保证唯⼀性)
# 语法1://标签名[@属性名='属性值']
# 语法2://*[@属性名='属性值']
注意:
1、使用 XPath 策略, 需要在浏览器⼯具中根据策略语法, 组装策略值,验证后再放入代码中使用
2、⽬标元素的有些属性和属性值, 可能存在多个相同特征的元素, 需要注意唯一性
2、路径结合逻辑(多个属性)
解决的是单个属性和属性值无法定位元素唯一性的问题。
# 语法: //*[@属性1="属性值1" and @属性2="属性值2"]
注意:多个属性可有由 多个 and 链接,每一个属性前面都要有 @ 开头,可以根据需求使用更多属性值
3、层级和属性结合策略
目标元素⽆法直接定位, 可以考虑先定位其父层级或祖辈层级, 再获取目标元素
# 语法://*[@id='父级id属性值']/input (⽗层级定位策略/目标元素定位策略)
# 导包
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
# 实例化浏览器对象
driver = webdriver.Chrome()
# 打开网址url
driver.get('https://www.baidu.com/')
# 需求
# 1、相对路径
# ele = driver.find_element(By.XPATH, '//*[@id="kw"]')
# ele.send_keys('苹果15')
# # 2、绝对路径//这个验证会报错找不到元素
# driver.find_element(By.XPATH, '/html/body/div[1]/div[2]/div[5]/div[1]/div/form/span[1]/input').send_keys('苹果15')
#
# # 3、路径结合属性 语法1://标签名[@属性名='属性值']
# driver.find_element(By.XPATH, "//input[@id='kw']").send_keys('苹果15')
# # 语法2: //*[@属性名='属性值']
# driver.find_element(By.XPATH, "//*[@id='kw']").send_keys('苹果15')
#
# # 4、路径结合逻辑(多个属性)
# driver.find_element(By.XPATH, "//*[@id='kw' and @name ='wd']").send_keys('苹果15')
#
# 5、层级和属性结合策略//这个验证会报错找不到元素
driver.find_element(By.XPATH, "//*[@id='s_kw_wrap']/input").send_keys('苹果15')
# 观察效果
sleep(3)
# 关闭网页
driver.quit()
xpath 扩展
1. //*[text()='文本信息'] # 定位文本值等于XXX的元素
提示:一般适合 p标签,a标签
2. //*[contains(@属性,'属性值的部分内容')] # 定位属性包含xxx的元素 【重点】
提示:contains为关键字,不可更改。
3. //*[starts-with(@属性,'属性值的开头部分')] # 定位属性以xxx开头的元素
提示:starts-with为关键字不可更改
driver.find_element(By.XPATH, "//*[text()='新闻']").click()
driver.find_element(By.XPATH, "//*[contains(@autocomplete,'f')]").send_keys('苹果15')
driver.find_element(By.XPATH, "//*[starts-with(@autocomplete,'o')]").send_keys('苹果15')
css定位 (重点掌握)
通过 css 的选择器语法定位元素
1、Selenium框架官方推荐使用 css ,因为定位效率高于xpath
2、 CSS一种标记语言,焦点:数据的样式。控制元素的显示样式,就必须先找到元素,在css标记语言中找元素使用css选择器;
3、css的选择策略也有很多,但是无论选择哪一种选择策略都是用的同一种定位方法
# 导包
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
# 实例化浏览器对象
driver = webdriver.Chrome()
# 打开网址url
driver.get('https://www.baidu.com/')
# 需求
# 方法:
# driver.find_element(By.CSS_SELECTOR, '#kw').send_keys('苹果15')
# driver.find_element(By.CSS_SELECTOR, '[class="s_ipt"]').send_keys('苹果15')
# 语法属性选择器
# driver.find_element(By.CSS_SELECTOR, 'input[id="kw"]').send_keys('苹果15')
# driver.find_element(By.CSS_SELECTOR, '[name="wd"]').send_keys('苹果15')
# 观察效果
sleep(3)
# 关闭网页
driver.quit()
css的扩展方法 (重点掌握)
1. [属性^='开头的字母'] # 获取指定属性以指定字母开头的元素
2. [属性$='结束的字母'] # 获取指定属性以指定字母结束的元素
3. [属性*='包含的字母'] # 获取指定属性包含指定字母的元素
# 语法1:[属性^='开头的字母'] # 获取指定属性以指定字母开头的元素
driver.find_element(By.CSS_SELECTOR, "[class^='s_i']").send_keys('苹果15')
# 语法2:[属性$='结束的字母'] # 获取指定属性以指定字母结束的元素
driver.find_element(By.CSS_SELECTOR, "[class$='pt']").send_keys('苹果15')
# 语法3:[属性*='包含的字母'] # 获取指定属性包含指定字母的元素
driver.find_element(By.CSS_SELECTOR, "[autocomplete*='f']").send_keys('苹果15')