python爬取小说以及数据分析
from pyecharts import options as opts
from pyecharts.charts import Bar, Grid, Line, Liquid, Page, Pie
from pyecharts.commons.utils import JsCode
from pyecharts.components import Table
from pyecharts.faker import Faker
import requests
from bs4 import BeautifulSoup
import csv
header={"User-Agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Mobile Safari/537.36 Edg/112.0.1722.48"}
for i in range (1):
URL="https://www.qidian.com/rank/readindex/page{}/".format(i)
resp=requests.get(URL)
soup=BeautifulSoup(resp.content,"html.parser")
big_div=soup.find("div",attrs={"class":"rank-body"})
#名字
name=[]
names=big_div.find_all("h2")
for i in names:
n=i.text
name.append(n)
# print(name)
#小说类型
lx=[]
lxs=big_div.find_all("a",attrs={"data-eid":"qd_C42"})
# print(lxs)
for i in lxs:
l=i.text
lx.append(l)
#数据清洗,变成[(”a","b")]格式
tuples=dict(zip(name,lx))
my_list = list(zip(tuples.keys(),tuples.values()))
# print(my_list)
#将数据写入csv中
with open("xiaoshuo.csv.csv","w",encoding="utf-8",newline="") as file:
f=csv.writer(file)
con=["名字","类型"]
f.writerow(con)
f.writerows(my_list)
#作图
#去掉类型中的第一行 获得所有类型
lx2=[]
with open("xiaoshuo.csv.csv","r",encoding="utf-8") as file:
bb=csv.reader(file)
for i in bb:
# print(i[1])
if i[1] not in lx:
pass
else:
lx2.append(i[1])
# print(lx2)
#获得类型的数目
def getcount(shujv):
count=0
for i in lx2:
if i== shujv:
count+=1
else:
continue
return count
a=getcount("奇幻")
b=getcount("武侠")
c=getcount("都市")
d=getcount("诸天无限")
e=getcount("仙侠")
f=getcount("游戏")
g=getcount("军事")
h=getcount("悬疑")
i=getcount("轻小说")
j=getcount("体育")
k=getcount("历史")
l=getcount("科幻")
m=getcount("玄幻")
#获得所有类型的种类 将类型列表转换成集合
# print(set(lx))
shuliang=[a,b,c,d,e,f,g,h,i,j,k,l,m]
leixing=["奇幻","武侠","都市","诸天无限","仙侠","游戏","军事","悬疑","轻小说","体育","历史","科幻","玄幻"]
tupless=dict(zip(leixing,shuliang))
# print(tupless)
# print(a+b+c+d+e+f+g+h+i+k+j+l+m)
# 画图
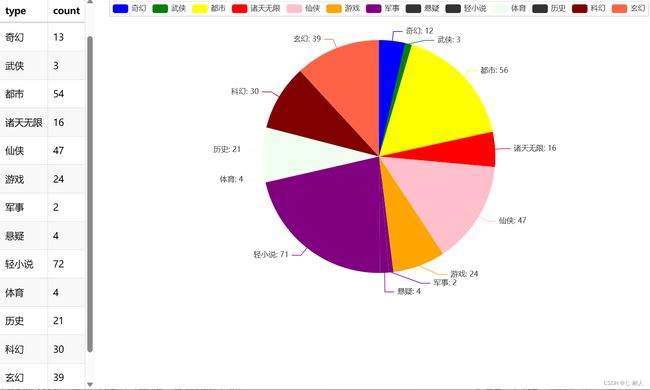
def bar_datazoom_slider() -> Bar:
c = (
Pie()
.add("", [list(z) for z in zip(tupless.keys(), tupless.values())])
.set_colors(
["blue", "green", "yellow", "red", "pink", "orange", "purple", "DoderBlue", "Auqamarin", " Honeydew",
"BrulyWood", "Maroon", "Tomato", "DarkKhaki"])
.set_global_opts(title_opts=opts.TitleOpts(title=""))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
return c
def table_base() -> Table:
table = Table()
headers = ["type", "count"]
rows = [
["奇幻", 13],
["武侠", 3],
["都市", 54],
["诸天无限", 16],
["仙侠", 47],
["游戏", 24],
["军事",2],
["悬疑",4],
["轻小说",72],
["体育",4],
["历史",21],
["科幻",30],
["玄幻",39]
]
table.add(headers, rows)
return table
page = Page()
page.add(
table_base()
)
page.render("page.html")可以生成两个html 然后将两个htnl整合在一起
all.html
运行结果