Redis 缓存穿透、缓存击穿和缓存雪崩
目录
-
- Redis 缓存穿透、缓存击穿和缓存雪崩
-
- Redis 缓存穿透(查不到)
- Redis缓存穿透的解决方案
-
- 方案一:接口校验
- 方案二:缓存空对象
- 方案三:布隆过滤器
- Redis 缓存击穿
-
- Redis 缓存击穿的解决方案
- Redis 缓存雪崩
- Redis 缓存雪崩解决方案
Redis 缓存穿透、缓存击穿和缓存雪崩
缓存穿透、缓存击穿和缓存雪崩这三个概念和知识点我们一定要掌握,而且我们也要牢牢掌握其解决方案,因为我们工作中经常会遇到缓存穿透、缓存击穿和缓存雪崩的情况。
Redis 缓存穿透(查不到)
缓存穿透是指客户端请求一个缓存和数据库中都不存在的 key。由于缓存中不存在,所以请求会透过缓存查询数据库;由于数据库中也不存在,所以也没办法更新缓存。因此下一次同样的请求还是会打在数据库上。当用户数量很多的时候,如我们的秒数场景,缓存都没有命中,好像缓存都被穿透了一样,如同虚设,所有无效的数据请求都会打穿 Redis,进而直接访问数据库,导致数据库负载升高甚至崩溃,这个时候就出现了缓存穿透。
Redis缓存穿透的解决方案
方案一:接口校验
在请求的入口进行校验,比如对用户进行鉴权,数据合法性检查等这些操作,这样可以减少缓存穿透发生的概率。

这种方式减轻了Redis 和数据库的压力,但是增加了客户端的编码和维护的工作量,如果请求的入口有很多,那么工作量巨大。
方案二:缓存空对象
从缓存上取不到数据,在数据库中也取不到,就设置一个空值写入 Redis缓存,这时可以把key-value键值对写成key-null键值对,并且设置有效时间(短一些)。由于在缓存中设置空值,所以请求在缓存这一级别就返回,也就不会被穿透。这样可以防止带有恶意的用户频繁用一个值来攻击数据库。
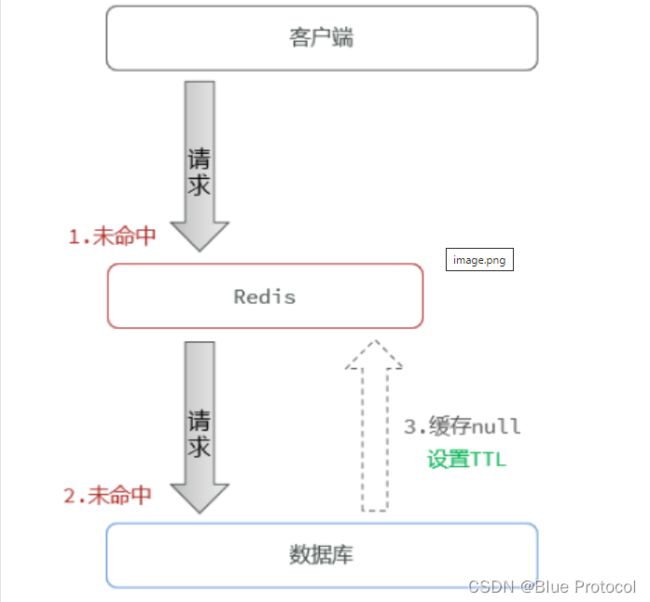
但是在缓存中设置空对象会出现一些问题:由于不存在的 key 几乎是无限的,所有不可能都被设置到缓存中,而且大量这样的空值 key 设置到缓存中,虽然携带过期时间,但是也会占用大量的内存空间。
解决方案:可以使用布隆过滤器来直接过滤掉不存在的key。
方案三:布隆过滤器
说到布隆过滤器,我们先来说一下布隆过滤器是一个什么东西,原理是什么,作为想作为高级开发工程师的我们,一定需要去探究底层原理。
首先先来对布隆过滤器做一个简介和特点。
简介
布隆过滤器(Bloom Filter)是由布隆提出的。它实际上是一种数据结构,是一个很长的二进制bit数组和一系列随机映射函数组成的。布隆过滤器可以用于判断一个元素是否在一个集合中。它的特点是存在性检测,如果数据在布隆过滤器中存在,实践数据也不一定存在;如果在布隆过滤器中不存在,那么实践数据一定不存在;相比于传统的数据结构来说List、Set等,布隆过滤器更高效,占用的空间更少。缺点是它对存在的判断是具有概率性的。
布隆过滤器原理
布隆过滤器的原理是当一个元素被加入集合时,通过K个 Hash 函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就大约知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。
假设有一个这样的一个集合S,它包括a、b、c三个元素。那么布隆过滤器会利用多个 Hash 函数(图中是三个哈希函数 h1、h2、h3)来计算所在位置,然后将该位设置为1.比如元素 a ,经过三个 Hash 函数计算后,将想要的位设置为1,也就是图中的红线。元素 b 和元素 c 也是按照相应的方法进行计算处理。这时布隆过滤器初始化完毕。

假设有一个元素 d,需要判断它是否在我们刚才所创建的布隆过滤器中(图中的黄色线条)。经过三个哈希函数 h1、h2、h3 计算后,发现相应的位都是 1,布隆过滤器会返回 true。也就是认为这个元素可能在,也可能不在集合中。看到这里,我们就会产生疑问:“既然这个布隆过滤器都不知道这个元素是不是在集合中,对我们有什么用呢?”
布隆过滤器的强大之处是可以利用较小的缓存,就可以判断出某个元素是否不在集合中。比如又来了一个元素 e,经过三个哈希函数 h1、h2、h3 计算后,发现 h1(e) 所对应的位是 0。那么这个元素 e 肯定不在集合中。有同学又说了:“我用 HashMap 不是也能判断出某个元素在不在集合中呀?”
HashMap 是可以判断,但需要存储集合中所有的元素。如果集合中有上亿个元素,那么就会占用大量的内存。内存空间毕竟是有限,可能还不一定放的下这么多的元素。与 HashMap 相比, 布隆过滤器占用的空间很小,所以很适合判断大集合中某个元素是否不存在。
之前的示例中可以看出,布隆过滤器判断为不存在的元素,则一定不存在;而判断存在的元素,则大概率存在。也就是说,有的元素可能并不在集合中,但是布隆过滤器会认为它存在。这就涉及到一个概念:误识别率。误识别率指的错误判断一个元素在集合中的概率。
假设布隆过滤器有 m bit 大小,需要放入 n 个元素,每个元素使用 k 个哈希函数,那么它的误识别率如下表所示。
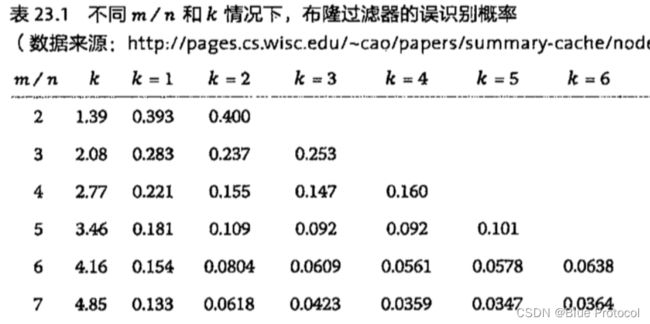

其实从图中我们可以看出,布隆过滤器长度越小,误识别率越高,布隆过滤器长度越长,误识别率越低。在布隆过滤器长度很长的情况下,Hash 函数越多,误识别率越低,比如上图 m/n = 19或者20 的情况下。
布隆过滤器防止缓存穿透
为什么说布隆过滤器能防止缓存穿透?
我们先来看一个图

我们所说缓存穿透的用户数据,实际上在数据库中不存在的数据,数据库中不存在,缓存中就更不会存在了,当这样不存在的数据经过缓存在要查询数据库之前,需要在布隆过滤器中查找,并及时返回结果,这样数据自然也不会到达数据库。所以布隆过滤器就可以起到防止缓存穿透的作用。
布隆过滤器的应用场景
根据布隆过滤器的特性,它可以告诉我们 “某个元素一定不存在集合中或者可能存在集合中”,也就是说布隆过滤器说这个数不存在则一定不存,布隆过滤器说这个数存在可能不存在(误判);以下是它的常见的应用场景:
- 解决Redis缓存穿透问题
- 邮件过滤,使用布隆过滤器来做邮件黑名单过滤
- 解决新闻推荐过的不再推荐(类似抖音刷过的往下滑动不再刷到)
- HBase\RocksDB\LevelDB等数据库内置布隆过滤器,用于判断数据是否存在,可以减少数据库的IO请求
布隆过滤器的使用
具体布隆过滤器的使用看我另一篇博客:布隆过滤器的使用
Redis 缓存击穿
所谓缓存击穿,指的是针对于某个热点数据,突然在缓存中失效,在突然的这一刻瞬间,所有的并发请求就穿破缓存直接砸向数据库(访问数据库),导致数据库瞬间压力过大,甚至导致数据库奔溃。就像在一个屏幕上凿开了一个洞一样。
Redis 缓存击穿的解决方案
1、设置热点数据永不过期。
我们可以判断当前 key 快要过期时,通过后台异步线程重新构建热点缓存。
2、我们可以设置接口的限流、服务降级和熔断。
重要的接口我们一定要做好限流策略,防止用户恶意刷接口,同时我们还要准备做服务降级,在某些接口不可用的时候,进行熔断,快速返回失败机制。
3、我们可以使用互斥锁。
在并发的多个请求中,只有第一个请求的线程能拿到锁并执行数据库查询操作,其他的线程拿不到锁就阻塞等着,等到第一个线程见数据写入缓存后,直接走缓存。
我们可以使用分布式锁来解决这个问题,比如Redis分布式锁。但是这种方式将高并发的压力转移到分布式锁上,对分布式锁的考验很大,我们可以简单使用下面的步骤来解决,具体如何保证一个高并发、高可靠的分布式锁见下文。
现在简述一下简单步骤,具体什么是分布式锁见我博客:分布式锁
1)我们在缓存失效的时候(判断拿出来的值为空),我们不要立即去请求数据库。
2)我们可以使用Redis setnx(实践上并不会这样使用来实现分布式锁,这样会出现一些问题,具体见上文)去设置一个分布式/互斥锁:
当设置成功时,我们再进行请求访问数据库,并设置缓存,然后delete掉分布式锁。
当设置不成功时,说明分布式锁已经被别的线程抢占了,我们可以让当前线程睡眠一段时间再重试整个get缓存的方法。
Redis 缓存雪崩
我们还是先来说一下概念:什么是缓存雪崩。
所谓缓存雪崩指的是由于大量缓存数据失效或者缓存整体宕机不能提供服务,导致大量的并发请求查询访问数据库,进而可能导致数据库崩溃,这就是缓存雪崩。
其实我觉得数据的集中过期,到不是非常致命的问题,无非就是对数据库产生周期性的压力而已,而比较致命的缓存雪崩,是缓存服务器某个节点宕机或者是断网,这个对数据库造成的压力是不可预知的,很可能瞬间就把数据库压垮。
Redis 缓存雪崩解决方案
既然是由于缓存数据失效或者是缓存服务器宕机,那么我们就对症下药,由这两点下手。
从缓存数据失效这个方面。
1、如果我们直接一点,我们可以设置缓存数据不过期,这样就不会导致大量缓存同时失效的问题,但是随之而来就是Redis需要更多的存储空间,而且,我们在实际中基本上不会这样子使用。
2、使用互斥锁重建缓存数据
在高并发场景下,我们根据 key 去缓存中查询数据,当缓存未命中时,那么只有第一个请求的线程能拿到锁并执行数据库查询操作,其他的线程拿不到锁就阻塞等着,等到第一个线程见数据写入缓存后,直接走缓存。
如果是在单机环境下直接可以使用synchronized或者是ReentrantLock。
如果是在分布式环境下,我们可以使用分布式锁,分布式锁上面已经提及到,现在再熟悉一次。
我们可以使用分布式锁来解决这个问题,比如Redis分布式锁。但是这种方式将高并发的压力转移到分布式锁上,对分布式锁的考验很大,我们可以简单使用下面的步骤来解决,具体如何保证一个高并发、高可靠的分布式锁见下文。
现在简述一下简单步骤,具体什么是分布式锁见我博客:分布式锁
1)我们在缓存失效的时候(判断拿出来的值为空),我们不要立即去请求数据库。
2)我们可以使用Redis setnx(实践上并不会这样使用来实现分布式锁,这样会出现一些问题,具体见上文)去设置一个分布式/互斥锁:
当设置成功时,我们再进行请求访问数据库,并设置缓存,然后delete掉分布式锁。
当设置不成功时,说明分布式锁已经被别的线程抢占了,我们可以让当前线程睡眠一段时间再重试整个get缓存的方法。
这里提供一个分布式环境下互斥锁重建缓存伪代码
public String get(String key) {
// redis中查询key对应的value
String value = redis.get(key);
// 缓存未命中
if (value == null) {
// 互斥锁
String key_mutex_lock = "mutex:lock" + key;
// 互斥锁加锁成功
if(redis.setnx(key_mutex_lock,"1")) { // 返回 0(false),1(true)
try {
// 设置互斥锁超时时间,这里设置的是锁的失效时间,而不是key的失效时间
redis.expire(key_mutex_lock,3*60);
// 从数据库查询
value = db.get(key);
// 数据写入缓存
redis.set(key,value);
} finally {
// 释放锁
boolean keyExist = jedis.exists(key_mutex_lock);
if(keyExist){
redis.delete(key_mutex_lock);
}
} else {
// 加锁失败,线程休息50ms后重试
Thread.sleep(50);
return get(key); // 直接返回缓存结果
}
}
}
不发送环境下使用Redis分布式(互斥)锁实现缓存重建
优点是:设计思路简单,对数据一致性有保障。
缺点是:代码复杂度增加,有可能会造成用户等待。
3、使用异步重建数据
采用异步异步重建缓存策略,会从线程池中获取线程来异步进行构建缓存,而不会让所有的请求直接到数据库,在这个方案中每个Redis key 维护一个逻辑超时时间(可以是设置缓存的时间+(过期时间/2)),当逻辑超时时间小于等于当前时间,则说明当前缓存已经失效,应当进行缓存更新,否则说明当前缓存未失效,直接放回缓存中的value值。如在 Redis 中将 key 的过期时间设置为60 min ,在对应的 valueObject 中设置逻辑超时时间为 30 min。这样当 key 到了 30 min 的逻辑过期时间,就可以异步更新这个 key 的缓存,这样,在更新缓存的这段时间内,旧的缓存依旧可以用。
这里提供一个分布式环境下异步重建缓存伪代码
public String get(String key) {
// 重缓存中查询key对应的ValueObject对象
ValueObject valueObject = redis.get(key);
// 获取存储中对应的value值
String value = valueObject.getValue();
// 获取实体模型中的缓存过期的时间:timeOut = 设置缓存时的当前时间+过期时间(如30秒,60秒等等)
long logicTimeOut = valueObject.getTimeOut(); // 等位换算为long类型
// 当前可以在逻辑上失效
if (logicTimeOut <= System.currentTimeMillis()) {
// 异步更新缓存
threadPool.execute(new Runnable() {
String key_mutex_lock = "mutex_lock" + key;
// 互斥锁加锁成功
if(redis.setnx(key_mutex_lock,"1")) { // 返回 0(false),1(true)
try {
// 设置互斥锁超时时间,这里设置的是锁的失效时间,而不是key的失效时间
redis.expire(key_mutex_lock,3*60);
// 从数据库查询
dbValue = db.get(key);
// 数据写入缓存
redis.set(key,dbValue);
} finally {
// 释放锁
boolean keyExist = jedis.exists(key_mutex_lock);
if(keyExist){
redis.delete(key_mutex_lock);
}
}
} else {
}
});
return value; // 直接返回缓存结果
}
}
4、优化缓存过期时间
设置缓存的时候,为每一个key选择合适的过期时间,避免大量的key在同一时刻同时失效。
从缓存整体不能提供服务这个方面
5、我们可以使用Redis的高可用方案来解决缓存整体不能提供服务的问题,具体Redis高可用见我博客:Redis缓存数据库。
其他小知识
1、数据预热。
数据预热就是系统上线之前提前将相关的数据加载到缓存中。避免用户请求的时候,先查询数据库,然后再将数据缓存,用户查询到的数据是实现被预热过的缓存数据。
数据预热有三种操作方式
1)直接写个缓存刷新页面,上线之前手动操作下。
2)如果在数据量不大的情况下,可以在项目启动的时候自动进行加载。
3)定时刷新缓存。