kafka安装及配置
1. 下载
下载地址:Apache Kafka
我这里下载的是 3.2.1 版本。
2. 上传并解压
上传到 linux 下的 /home/software/ 目录下,然后解压 kafka_2.13-3.2.1.tgz 包到/usr/local/
cd /home/software
tar -zxvf kafka_2.13-3.2.1.tgz -C /usr/local # -C 选项的作用是:指定需要解压到的目录。
# 重命名
cd /usr/local
mv kafka_2.13-3.2.1 kafka-3.2.13. 修改kafka配置文件
vim /usr/local/kafka-3.2.1/config/server.properties修改内容:
broker.id=0 # broker的id,每个broker的id必须不一样
port=9092 # 服务端口
host.name=192.168.31.101 # 主机地址
advertised.host.name=192.168.31.101 # 备用主机地址
log.dirs=/usr/local/kafka-3.2.1/kafka-logs # kafka存储消息(log日志数据)的目录
num.partitions=5 # 创建topic时默认的分区数量
zookeeper.connect=192.168.11.221:2181,192.168.11.222:2181,192.168.11.223:2181 # zookeeper地址配置文件中的一些配置项解释:
- zookeeper.connect : ZooKeeper服务地址
, 多个zk节点用逗号隔开。 - listeners :用的比较少,表示客户端要连接的broker入口地址列表
- broker.id : kafka 节点的标示,每个节点必须不一样
- log.dir 和 log.dirs :kafka存储消息(log日志数据)的目录,log.dir配置单个目录,log.dirs可以配置多个目录
- message.max.bytes:用来指定broker能够接受的单个消息最大值,默认1M左右
- group.initial.rebalance.delay.ms :这个参数的主要效果就是让 coordinator(调度器) 推迟空消费组接收到成员加入请求后本应立即开启的 rebalance 。在实际使用时,假设你预估你的所有 consumer 组成员加入需要在10s内完成,那么你就可以设置该参数=10000,即表示10s之后重新分配消费者 consumer。
4. 创建kafka存储消息(log日志数据)的目录
由于配置文件里配置的 log.dirs=/usr/local/kafka-3.2.1/kafka-logs,所以要创建一个该目录:
mkdir /usr/local/kafka-3.2.1/kafka-logs5. 启动kafka
以配置文件的方式启动,后面的 & 表示后台启动。(注意如果kafka依赖了zookeeper,需要先启动zookeeper)
/usr/local/kafka-3.2.1/bin/kafka-server-start.sh /usr/local/kafka-3.2.1/config/server.properties &关闭命令:
/usr/local/kafka-3.2.1/bin/kafka-server-stop.sh使用 jps 命令检查 kafka 是否启动成功,如下所示则是启动成功:

如果想要搭建集群的话,需要对于其他的虚拟机节点也按照上述方法执行安装,只是其中配置文件里的 broker.id=0 的值需要修改一下,每个节点必须保证不一样。
6. 安装kafka manager可视化管控台
(1)kafka manager 下载
下载地址:kafka-manage-2.0.0.2
把 kafka manager 的压缩包上传到 192.168.31.102 虚拟机上
(2)解压zip文件
unzip kafka-manager-2.0.0.2.zip -d /usr/local/(3)修改配置文件:
vim /usr/local/kafka-manager-2.0.0.2/conf/application.conf修改内容:
kafka-manager.zkhosts="192.168.31.101:2181,192.168.31.102:2181,192.168.31.103:2181"(4)启动kafka manager 控制台
/usr/local/kafka-manager-2.0.0.2/bin/kafka-manager &如果提示权限不够,可以使用 chmod kafka-manager 修改权限 。
(5)浏览器访问控制台:默认端口号是9000
http://192.168.31.102:9000/
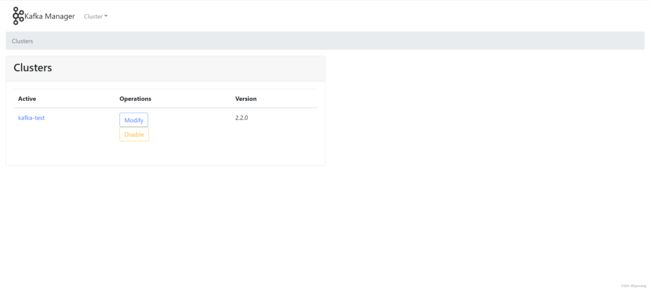
添加Cluster集群:

添加 topic :

7. 操作:
(1)通过控制台创建了一个topic为"topic-test" 2个分区 1个副本
(2)消费发送与接收验证
在 192.168.31.101 节点上打开两个终端界面分别用于执行消息的发送和接收。
启动发送消息的脚本
cd /usr/local/kafka-3.2.1/bin
./kafka-console-producer.sh --broker-list 192.168.31.101:9092 --topic topic-test
## --broker-list 192.168.31.101 指的是 kafka broker 的地址列表
## --topic topic-test 指的是把消息发送到 topic-test 主题启动接收消息的脚本
cd /usr/local/kafka-3.2.1/bin
./kafka-console-consumer.sh --bootstrap-server 192.168.31.101:9092 --topic topic-test截图如下:

8. 使用 java 代码连接 kafka 节点失败
(1)报错
java端代码启动生产者或者消费者时,报错如下:
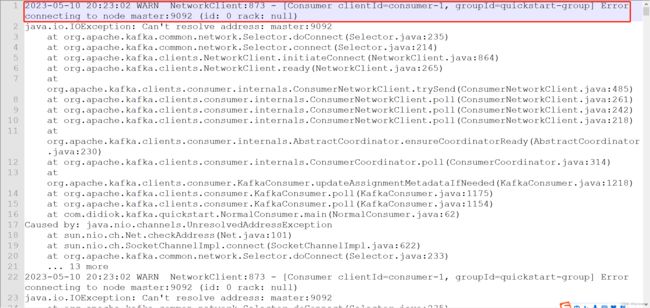
java代码是在我的windows电脑中,而 kafka 是安装在CentOS虚拟机中,虚拟机的 hostname 是 master,报错提示是连接到 master 节点失败,也就是java代码连不上虚拟机中的kafka服务。
(2)解决方案:
修改 kafka 节点上的 配置文件:
vim /usr/local/kafka-3.2.1/config/server.properties修改内容为:在配置文件中加入下面一行代码(原来这行代码是被注释掉的):
listeners=PLAINTEXT://192.168.31.101:9092 # 其中的ip地址修改成你的 kafka 节点的ip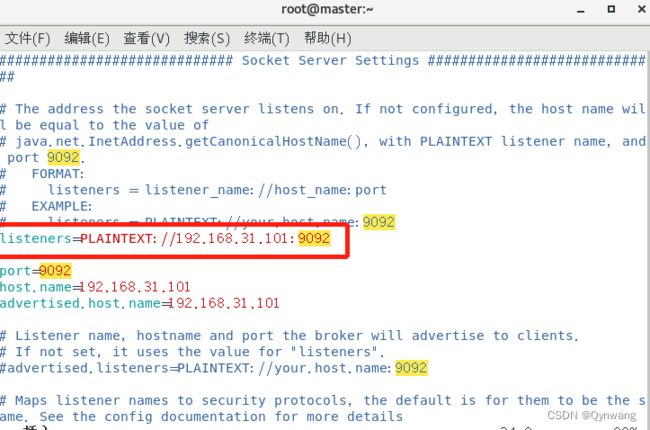
9. 一些命令
# 创建 topic
./kafka-topics.sh --bootstrap-server 192.168.31.101:9092 --create --topic topic02 --partitions 1 --replication-factor 1
# 查看 kafka 中topic列表
./kafka-topics.sh --bootstrap-server 192.168.31.101:9092 --list
# 查看某个topic的情况
./kafka-topics.sh --bootstrap-server 192.168.31.101:9092 --topic topic01 --describe
# 模拟消费者拉取topic中的数据
./kafka-console-consumer.sh -bootstrap-server 192.168.31.101:9092 --topic didiok_users --from-beginning
# 查看消费者组group02订阅的topic的消费进度
./kafka-consumer-groups.sh --bootstrap-server 192.168.31.101:9092 --describe --group group02
# 模拟生产者发送消息到 topic
./kafka-console-producer.sh --broker-list 192.168.31.101:9092 --topic topic-test
# 模拟消费者拉取topic中的数据
./kafka-console-consumer.sh -bootstrap-server 192.168.31.101:9092 --topic topic-test --from-beginning