详解c++---set的介绍
目录标题
- set容器的介绍
- set的构造函数
- insert函数的介绍
- find函数
- erase函数
- count函数
- lower_bound
- upper_bound
- multiset
set容器的介绍
set容器可以看成我们上一篇文章学习的K结构的搜索二叉树,所以set容器不仅可以存储数据,还可以对数据进行排序和去重,另外set属于关联式容器也就是说set的每个元素都是通过某种关系相互链接起来的不想vector一样在虚拟地址上一个元素紧接着一个元素,所以set容器种没有push_bck函数只有insert函数,那么接下来我们就来看看insert函数的介绍。

set的构造函数

set容器提供了三种构造函数我们首先来看第一种,这种构造函数有两个参数并且每个参数都有一个缺省值,那么第一个参数表示的意思就是搜索二叉树的比较方法,如果库中提供的够用的话这个参数就不需要传,第二个参数就是一个有关内存池的参数,那么这个参数对于我们初学者也不需要管,所以第一种构造函数对于我们来说几乎什么参数都不用传,直接用它创建一个空容器就可以了,比如说下面的代码:
void func()
{
set<int> tmp1;
set<long long> tmp2;
set<char> tmp3;
set<double> tmp4;
}
那么第二种的形式有两个迭代器参数,那么这种形式表示的意思就是用迭代器范围的内容构造一个容器,比如说下面的代码:
void func()
{
vector<int> v = { 1,2,3,4,5 };
set<int> tmp(v.begin(), v.end());
}
那么这种形式创建的容器在一开始就会有数据:

第三种形式就是拷贝构造函数,这种形式就不必多讲了,大家可以看看下面的代码:
void func()
{
vector<int> v = { 1,2,3,4,5 };
set<int> tmp(v.begin(), v.end());
set<int> copy_tmp(tmp);
}
这里通过调试就可以看到两个容器里面的内容是一样的:

那么这就是set的构造函数,很简单跟之前学的差不多。
insert函数的介绍
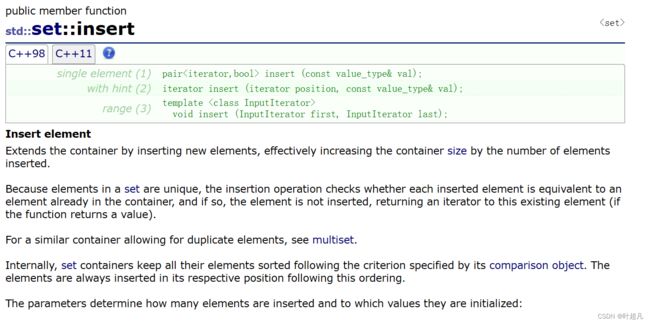
首先参数中的value_type就是模板参数中的一个参数的重命名,那么知道这个之后我们就可以明白第一个形式的insert函数表示的意思就是往容器中插入一个T类型的数据,比如说下面的代码:
void func1()
{
set<int> tmp;
tmp.insert(2);
tmp.insert(1);
tmp.insert(3);
tmp.insert(0);
}
因为名为tmp创建的时候显示实例化的类型是int,所以我们可以通过insert函数向里面插入int类型的数据,第二种形式的参数多了一个迭代器类型的参数,那么这种形式表示的意思就是往容器中的指定位置插入数据,那么这种形式希望大家谨慎使用因为可能会导致树的结构发生破坏,使其失去搜索二叉树的特征。第三种形式的参数就是两个迭代器,那么这种形式的insert函数表示的意思就是将一个范围内的数据插入到容器里面,那么这个迭代器类型可以是任意容器比如说下面的代码:
void func1()
{
set<int> tmp1;
vector<int> v = { 1,3,5,7,9 };
list<int> l = { 2,4,6,8,10 };
tmp1.insert(v.begin(), v.end());
tmp1.insert(l.begin(), l.end());
}
那么这里我们可以通过调试查看tmp1中的数据内容:

那么这就是set的insert函数的第三个形式的作用希望大家能够理解。
find函数
find函数想必大家都应该知道这个函数的作用,那么这里我们首先来看看这个函数的参数形式:

find函数只有一个形式,这种形式的意思传递你要找的数据就行,如果找到的话这里会返回这个数组所在的容器中的位置,如果找不到的话这里会返回一个指向容器结尾end的迭代器,比如说下面的代码:
void func2()
{
vector<int> v = { 1,3,5,7,9 };
set<int> tmp(v.begin(),v.end());
set<int> ::iterator it = tmp.find(3);
if (it != tmp.end())
{
cout << "找到了数据为:" << *it << endl;
}
else
{
cout << "容器中没有这个数据" << endl;
}
}
这段代码的运行结果如下:

如果我们要找一个不存在的数据的话这里运行的结果如下,比如说把上面的3改成4运行的结果就如下:

那么这里就有一个问题,set库中提供了find函数,但是算法库中也提供了find函数,并且这个函数都可以达到我们的预期,比如说下面的代码:
void func2()
{
vector<int> v = { 1,3,5,7,9 };
set<int> tmp(v.begin(),v.end());
set<int> ::iterator it = find(tmp.begin(), tmp.end(), 3);
if (it != tmp.end())
{
cout << "找到了数据为:" << *it << endl;
}
else
{
cout << "容器中没有这个数据" << endl;
}
}
这段代码的运行结果如下:

那我们用哪个find函数好呢?能不能为了统一就只是用算法库中的find函数呢?答案是最好不要因为算法库中的find函数是暴露查找通过循环逐个比对迭代器中的值是否和要找的值相匹配,这种查找方式并没有发挥搜索二叉树所特有的性质所以不推荐使用,而set库中的find函数充分的利用了二分查找的性质,所以他的效率会更高,我们更推荐使用,那么这就是两个find函数的区别,虽然都能达到目的,但是set的效率会更高。
erase函数
我们来看看erase函数的参数形式:

erase函数支持三种参数的删除,第一种的参数就是一个迭代器表示的意思就是将迭代器指向的位置的元素进行删除,比如说下面的代码:
void func3()
{
vector<int> v = { 2,1,5,4,3 };
set<int> tmp(v.begin(), v.end());
set<int>::iterator it = tmp.begin();
it++;
tmp.erase(it);
set<int> ::iterator it1 = tmp.find(2);
if (it1 != tmp.end())
{cout << "找到了数据为:" << *it1 << endl;}
else
{cout << "容器中没有这个数据" << endl;}
}
容器一开始装的数据为2,1,5,4,3,it一开始指向的是容器中的第一个元素 1,将it的值加加那么他就会指向容器中的第二个元素也就是2,当我们使用erase函数将迭代器指向的第二个元素删除之后再去查找数据2,便会发现找不到了
那么这就是erase函数的第一种形式,通过传递迭代器具体指向的位置来删除元素,这种形式的erase主要和find函数互相搭配使用,find函数找到元素之后会通过迭代器去的形式返回元素所在的位置,那么我们就可以通过erase的第一种形式将其删除,比如说下面的代码:
void func3()
{
vector<int> v = { 2,1,5,4,3 };
set<int> tmp(v.begin(), v.end());
set<int>::iterator it = tmp.find(4);
if (it != tmp.end())
{
tmp.erase(it);
}
it = tmp.find(4);
if (it != tmp.end())
{cout << "找到了数据为:" << *it << endl;}
else
{cout << "容器中没有这个数据" << endl;}
}
这段代码的运行结果如下:

那么这就是erase函数的第一种形式的用法,第二种形式就是值删除比如说我想要删除容器种的3的话我就可以在erase函数种直接添加一个3,如果删除成功的话erase函数就会返回1如果删除的元素不存在导致删除失败的话就会返回0,比如说下面的代码:
void func3()
{
vector<int> v = { 2,1,5,4,3 };
set<int> tmp(v.begin(), v.end());
cout << tmp.erase(3)<<endl;
cout << tmp.erase(6) << endl;
}
这段代码的运行结果如下:

第三个就是迭代器区间的删除,这种删除方式就是将迭代器区间的内容给删除掉,当然这里的迭代器指的是set
void func3()
{
vector<int> v = { 2,1,5,4,3,6,8,7 };
set<int> tmp(v.begin(), v.end());
tmp.erase(++tmp.begin(), --tmp.end());
}
这里的erase函数执行完之后容器中只会存在两个元素,一个是第一个元素,另外一个就是最后一个元素

那么这就是erase函数三种参数形式的使用方法以及特点希望大家能够理解。
count函数
我们来看看cout函数的参数和这个函数的作用:

cout函数的作用是返回这个值在树中出现的个数,这个函数的作用就是返回这个值在不在树里面,如果不在的话这个函数就会返回0,如果在的话这个函数就会这个数据在容器里面出现的个数,可能大家会感觉这个函数的存在属实有一点点鸡肋,因为find函数也可以干这种事情,那为什么还要这个函数呢?那这里就有两个原因,第一个就是conut函数可以更加方便的判断某个元素在不在,find函数的返回值是一个迭代器我们想要知道在不在的话得拿这个迭代器和容器的end函数做比较,而count函数则可以直接判断,第二个原因就是这个函数主要是为multiset进行服务的这个multiset也是可以看成set容器但是他允许数据冗余,也就是说容器中可以存在多个相同的数据,那么这就是count函数的作用希望大家能够理解。
lower_bound
upper_bound
我们首先来看看这两个函数的参数和介绍:


lower_bound和upper_bound的作用就是确定一个区间,lower_bound(x)找的就是大于等于x的位置upper_bound(y)找的就是大于y的位置,比如下面的代码:
void func4()
{
vector<int> v = { 1,4,3,8,7,10,11,13 ,6};
set<int> tmp(v.begin(), v.end());
set<int>::iterator it_begin = tmp.lower_bound(5);
cout << *it_begin << endl;
set<int>::iterator it_end = tmp.upper_bound(8);
cout << *it_end << endl;
}
因为容器中没有5所以lower_bound(5)找到的元素就是6,由于容器中存在8所以upper_bound(8)找的是大于8的元素的位置,所以upper_bound函数找到的就是10,比如说下面的代码:

这两个函数没什么用,可能唯一有用的地方就是搭配erase函数删除一段区间的元素给删除了,比如说下面的代码:
void func4()
{
vector<int> v = { 1,4,3,8,7,10,11,13 ,6};
set<int> tmp(v.begin(), v.end());
set<int>::iterator it_begin = tmp.lower_bound(5);
cout << *it_begin << endl;
set<int>::iterator it_end = tmp.upper_bound(8);
cout << *it_end << endl;
tmp.erase(it_begin, it_end);
}
这里就会将大于等于6小于10的元素全部都给删除了,这里通过调试给大家看看erase函数的运行结果:

大家可以看到7和8都被删除了但是10没有被删除,那么这就是两个函数的作用希望大家可以理解。
multiset
multiset也是一个容器:

我们说set函数的作用是将一段数据进行排序和去重,当往set容器里面插入多个相同数据时,set容器只会存储一个数据,其他数据都会被过滤掉,但是multiset和set不一样,他不会对重复的数据进行过滤所以在这个容器里面就可以存在多个相同的数据,比如说下面的代码:
void func5()
{
set<int> tmp1;
tmp1.insert(1);
tmp1.insert(1);
tmp1.insert(1);
multiset<int> tmp2;
tmp2.insert(1);
tmp2.insert(1);
tmp2.insert(1);
}
通过调试便可以看到下面这两个容器的不同:

multiset容器和set容器的使用方法上没有什么区别,比如说conut函数这个函数在set中只能返回0或者1因为一个元素在set中也只能出现1次或者0次,但是在multiset中相同的元素会出现多次,所以count函数的返回值也会有多个,比如说下面的代码:
void func5()
{
set<int> tmp1;
tmp1.insert(1);
tmp1.insert(1);
tmp1.insert(1);
cout << tmp1.count(1) << endl;
multiset<int> tmp2;
tmp2.insert(1);
tmp2.insert(1);
tmp2.insert(1);
cout << tmp2.count(1) << endl;
}
这个代码的运行结果如下:

那么对于multiset大家可能会存在这么几个疑问,我们知道set的底层是通过搜索二叉树来实现的,对于搜索二叉树比根节点大的值会放到根节点的右边,比根节点小的值则会放到根节点的左边,multiset也是基于搜索二叉树实现的,那出现了相等的值这个值放到根节点的左边还是右边呢?答案是左边或者右边都可以,因为会发生旋转就算你放到左边也可能会因为旋转被放到右边,所以这个时候放到左边或者右边意义就没有那么大了所以multiset的insert函数就只是排序,对于multiset还有个问题就是容器中存在多个相同的数据,那find函数找的是容器中的哪个数据呢?答案是查找到的第一个数据就是find函数返回的,我们可以通过下面的代码来验证这一点:
void func6()
{
vector<int> v = { 1,1,2,2,2,3,4,5,6 };
multiset<int> tmp1(v.begin(),v.end());
multiset<int>:: iterator it=tmp1.find(2);
while (*it == 2)
{
cout << *it << endl;
++it;
}
}
这段代码的运行结果如下:

可以看到这里打印出来了三个2,所以这里的find找到就是第一个出现的数据,那么这就是multiset的用法即性质希望大家能够理解。