Java性能权威指南-总结10
Java性能权威指南-总结10
- 垃圾收集算法
-
- 理解G1垃圾收集器
垃圾收集算法
理解G1垃圾收集器
G1垃圾收集器是一种工作在堆内不同分区上的并发收集器。分区(region)既可以归属于老年代,也可以归属于新生代(默认情况下,一个堆被划分成2048个分区),同一个代的分区不需要保持连续。为老年代设计分区的初衷是并发后台线程在回收老年代中没有引用的对象时,有的分区垃圾对象的数量很多,另一些分区的垃圾对象相对较少。虽然分区的垃圾收集工作实际仍然会暂停应用程序线程,不过由于G1收集器专注于垃圾最多的分区,最终的效果是花费较少的时间就能回收这些分区的垃圾。这种只专注于垃圾最多分区的方式就是G1垃圾收集器名称的由来,即首先收集垃圾最多的分区。
不过这一算法并不适用于新生代的分区:新生代进行垃圾回收时,整个新生代空间要么被回收,要么被晋升(对象被移动到Survivor空间,或者移动到老年代)。新生代也采用分区机制的部分原因,是因为采用预定义的分区能够便于代的大小调整。
G1收集器的收集活动主要包括4种操作:
- 新生代垃圾收集;
- 后台收集,并发周期;
- 混合式垃圾收集;
- 以及必要时的FullGC。
首先讨论的是G1收集器的新生代垃圾收集,如下图所示: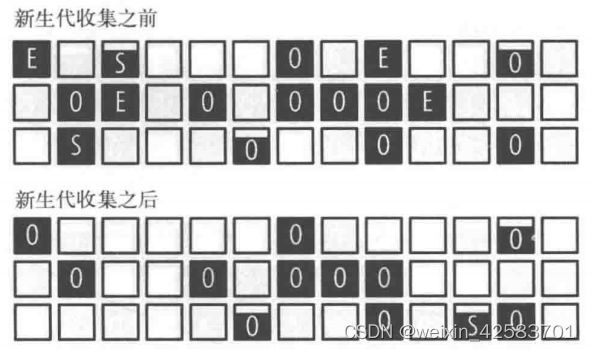
图中的每一个小方块都代表一个G1的分区。分区中黑色的区域代表数据,每个分区中的字母表示该区域属于哪个代([E]代表Eden空间,[0]代表老年代,[S]代表Survivor空间)。空的分区不属于任何一个代;需要的时候G1收集器会强制指定这些空的分区用于任何需要的代。
Eden空间耗尽会触发G1垃圾收集器进行新生代垃圾收集(这个例子中,标识为Eden的4个分区填满之后就会触发新生代收集)。新生代收集之后不会有新的分区马上分配到Eden空间,因为这时Eden空间为空。不过至少会有一个分区分配到Survivor空间(这个例子中,Survivor空间被部分填满),一部分数据会移动到老年代。。
G1垃圾收集器中,新生代垃圾收集的日志与其他的收集器略有不同。与往常一样,可以使用PrintGCDetails输出例子的垃圾回收日志,不过G1收集的日志要详细得多。这里仅仅列出了例子中重要的几行。
下面是新生代垃圾收集的标准流程:
23.430:[GC pause(young),0.23094400 secs]
[Eden: 1286M(1286M)->0B(1212M)
Survivors:78M->152M Heap: 1454M(4096M)->242M(4096M)]
[Times:user=0.85 sys=0.05,real=0.23 secs]
这里新生代垃圾收集的Real时间消耗是0.23秒,这期间,垃圾收集线程消耗了0.85秒的CPU时间,1286 MB的对象移出了Eden空间(Eden空间的大小调整到了1212 MB);这其中的74 MB移动到了Survivor空间(Survivor空间的大小从78 MB增加到了152 MB),其余的空间都被垃圾收集器回收掉了。通过观察堆的总占用降低了1212 MB,这些空间被释放了。通常情况下,一部分对象已经从Survivor空间移动到老年代空间,如果Survivor空间被填满,无法容纳新生代的晋升对象,部分Eden空间的对象会被直接晋升到老年代空间——这种情况下,老年代空间的占用也会增加。
下图是并发G1垃圾收集周期(concurrent G1 cycle)开始和结束时的情况:
这幅图中有三方面值得关注。首先,新生代的空间占用情况发生了变化:在并发周期中,至少有一次(很可能是多次)新生代垃圾收集。因此,在将Eden空间中的分区标记为完全释放之前,新的Eden分区已经开始分配了。
其次,一些分区现在被标记为X。这些分区属于老年代(注意,它们依然还保持着数据),它们就是标记周期(marking cycle)找出的包含最多垃圾的分区。
最后,还要留意老年代(包括标记为O或者X的分区)的空间占用,在周期结束时实际可能更多。这是因为在标记周期中,新生代的垃圾收集会晋升对象到老年代。除此之外,标记周期中实际不会释放老年代中的任何对象:它仅仅锁定了那些垃圾最多的分区。这些分区中的垃圾数据会在之后的周期中被回收释放。
G1收集器的并发周期包括多个阶段,其中的一些会暂停所有应用线程,另一些则不会。
并发周期的第一个阶段是初始一标记(initial-mark)阶段。这个阶段会暂停所有应用线程——部分源于初始一标记阶段也会进行新生代垃圾收集。
50.541:[GC pause(young)(initial-mark),0.27767100 secs]
[Eden:1220M(1220M)->0B(1220M)
Survivors: 144M->144M Heap: 3242M(4096M)->2093M(4096M)]
[Times: user=1.02 sys=0.04,real=0.28 secs]
同常规的新生代垃圾收集一样,初始一标记阶段中,应用线程被暂停(大约时长0.28秒),之后新生代被清空(71MB的数据从新生代移到了老年代)。初始一标记阶段的输出日志表明后台并发周期启动。由于初始一标记阶段也需要暂停所有的应用线程,G1收集器重用了新生代GC周期来完成这部分的工作。在新生代垃圾收集中添加初始标记阶段的影响并不大:与之前的垃圾收集相比较,CPU周期的开销增加了大约20%,即便如此,停顿时间只有些微的增长(幸运的是,这台机器上有空闲的CPU周期可以运行并发G1收集线程,否则停顿时间会更长一些)。
接下来,G1收集器会扫描根分区(root region):
50.819:[GC concurrent-root-region-scan-start]
51.408:[GC concurrent-root-region-scan-end,0.5890230]
这个过程耗时0.58秒,不过扫描过程中不需要暂停应用现场,G1收集器使用后台线程进行扫描工作。不过,这个阶段中不能发生新生代垃圾收集,因此预留足够的CPU周期给后台线程运行是非常重要的。如果扫描根分区时,新生代空间刚巧用尽,新生代垃圾收集(会暂停所有的应用线程)必须等待根扫描结束才能完成。效果上,这意味着新生代垃圾收集的停顿时间会更长(远超过正常的耗时)。这种情况在GC日志中如下所示:
350.994:[GC pause(young)
351.093:[GC concurrent-root-region-scan-end,0.6100090]
351.093:[GC concurrent-mark-start],
0.37559600 secs]
此处GC的停顿发生在根分区扫描之前,这意味着GC停顿还会继续等待,可以看到GC日志中的相互交织的输出。GC日志的时间戳显示应用线程等待了大概100毫秒——这就是新生代GC停顿时间比日志中其他停顿的平均持续时间还长100毫秒的原因。这是一个信号,说明G1收集器需要进行调优。
根分区扫描完成后,G1收集器就进入到并发标记阶段。这个阶段完全在后台运行,阶段启动和停止时在GC日志中各会打印一条日志。
111.382:[GC concurrent-mark-start]....
120.905:[GC concurrent-mark-end, 9.5225160 sec]
并发标记阶段是可以中断的,所以这个阶段中可能发生新生代垃圾收集。紧接在标记阶段之后的是重新标记(remarking)阶段和正常的清理阶段。
120.910:[GC remark 120.959:
[GC ref-PRC,0.0000890 secs],0.0718990 secs]
[Times:user=0.23 sys=0.01,real=0.08 secs]
120.985:[GC cleanup 3510M->3434M(4096M),0.0111040 secs]
[Times: user=0.04 sys=0.00,real=0.01 secs]
这几个阶段都会暂停应用线程,虽然暂停的时间通常很短。紧接着是一个额外的并发清理阶段:
120.996:[GC concurrent-cleanup-start]
120.996:[GC concurrent-cleanup-end,0.0004520]
这之后,正常的G1周期就结束了——至少是垃圾的定位就完成了。清理阶段真正回收的内存数量很少,G1到这个点为止真正做的事情是定位出哪些老的分区可回收垃圾最多(即上图中标记为X的分区)。
现在,G1会执行一系列的混合式垃圾回收(mixed GC)。这些垃圾回收被称作“混合式”是因为它们不仅进行正常的新生代垃圾收集,同时也回收部分后台扫描线程标记的分区。混合式垃圾收集的效果下如图所示:

同新生代垃圾收集通常的行为一样,G1收集器已经清空了Eden空间,同时调整了Survivor空间的大小。此外,标记的两个分区也已经被回收。这些分区在之前的扫描中已经证实包含大量垃圾对象,因此绝大部分已经被释放。
这些分区中的活跃数据被移动到另一个分区(就像把活跃数据从新生代移动到老年代的分区)。这就是为什么G1收集器最终出现碎片化的堆的频率,跟CMS收集器比较起来要小得多的原因——随着G1垃圾的回收以这种方式移动对象,实际伴随着压缩。
关于混合式垃圾回收操作,参考下面的日志:
79.826:[GC pause (mixed),0.26161600 secs]
[Eden: 1222M(1222M)->0B(1220M)
Survivors: 142M->144M Heap: 3200M(4096M)->1964M(4096M)]
[Times: user=1.01 sys=0.00,real=0.26 secs]
应注意,减少的整个堆的使用不仅仅是Eden空间移走的1222 MB。这其中的差异看起来很小(只有16MB),但是同时还有部分Survivor空间的对象晋升到了永久代,除此之外,每次混合式垃圾回收只会清理部分目标老年代分区。接下来会看到确保混合式垃圾收集清理掉足够的内存对避免将来发生并发失效有多重要。
混合式垃圾回收周期会持续运行直到(几乎)所有标记的分区都被回收,这之后G1收集器会恢复常规的新生代垃圾回收周期。最终,G1收集器会启动再一次的并发周期,决定哪些分区应该在下一次垃圾回收中释放。
同CMS收集器一样,有的时候会在垃圾回收日志中观察到Full GC,这些日志是一个信号,表明需要进一步调优(具体的方式很多,甚至很可能要分配更多的堆空间)才能提升应用程序的性能。主要有4种情况会触发这类的Full GC,如下所列:
并发模式失效
G1垃圾收集启动标记周期,但老年代在周期完成之前就被填满,在这种情况下,G1收集器会放弃标记周期:
51.408:[GC concurrent-mark-start]
65.473:[Full GC 4095M->1395M(4096M),6.1963770 secs]
[Times:user=7.87 sys=0.00,real=6.20 secs]
71.669:[GC concurrent-mark-abort]
发生这种失败意味着堆的大小应该增加了,或者G1收集器的后台处理应该更早开始,或者是需要调整周期,让它运行得更快(譬如,增加后台处理的线程数)。
晋升失败
G1收集器完成了标记阶段,开始启动混合式垃圾回收,清理老年代的分区,不过,老年代空间在垃圾回收释放出足够内存之前就会被耗尽。垃圾回收日志中,这种情况的现象通常是混合式GC之后紧接着一次Full GC。
2226.224:[GC pause(mixed)
2226.440:[SoftReference,0 refs, 0.0000060 secs]
2226.441:[NeakReference,θ refs,0.0000020 secs]
2226.441:[FinalReference,0 refs, 0.0000010 secs]
2226.441:[PhantomReference,0 refs,0.0000010 secs]
2226.441:[JNI Neak Reference, 0.0090030 secs]
(to-space exhausted),0.2390040 secs]
[Eden:0.0B(400.0M)->0.0B(400.0M)
Survivors:0.0B->0.0B Heap:2006.4M(2048.0M)->2006.4M(2048.0M)]
[Times:user=1.70 sys=0.04,real=0.26 secs]
2226.510:[Full GC(Allocation Failure)
2227.519:[SoftReference, 4329 refs,0.0005520 secs]
2227.520:[NeakReference,12646 refs,0.0010510 secs]
2227.521:[FinalReference, 7538 refs,0.0005660 secs]
2227.521:[PhantomReference, 168 refs,0.0000120 secs]
2227.521:[JNI Weak Reference,0.0000020 secs]
2006M->907M(2048M),4.1615450 secs]
[Times: user=6.76 sys=0.01,real=4.16 secs]
这种失败通常意味着混合式收集需要更迅速地完成垃圾收集;每次新生代垃圾收集需要处理更多老年代的分区。
疏散失败
进行新生代垃圾收集时,Survivor空间和老年代中没有足够的空间容纳所有的幸存对象。这种情形在GC日志中通常被当成一种特别的新生代:
60.238:[GC pause(young)(to-space overflow),0.41546900 secs]
这条日志表明堆已经几乎完全用尽或者碎片化了。G1收集器会尝试修复这一失败,但是可以预期,结果会更加恶化:G1收集器会转而使用Full GC。解决这个问题最简单的方式是增加堆的大小。
巨型对象分配失败
使用G1收集器时,分配非常巨大对象的应用程序可能会遭遇另一种Full GC。目前为止没有工具可以很方便地专门诊断这种类型的失败,尤其是从标准垃圾收集日志中进行诊断。不过,如果发生了莫名其妙的Full GC,其源头很可能是巨型对象分配导致的问题。
快速小结
- G1垃圾收集包括多个周期(以及并发周期内的阶段)。调优良好的JVM运行G1收集器时应该只经历新生代周期、混合式周期和并发GC周期。
- G1的并发阶段会产生少量的停顿。
- 恰当的时候,我们需要对G1进行调优,才能避免FulI GC周期发生。