canal使用指南(一)
Canal的使用指南。实现一个简单纯净的client-service,暂时不接入mq。
文章目录
- 一、什么是canal
- 二、准备工作
- 三、canal服务端搭建
-
- 3.1 配置文件
-
- 3.1.1 canal.properties
- 3.1.2 instance 实例配置
- 3.2 开始启动
- 3.3 查看日志
- 四、客户端实现
一、什么是canal
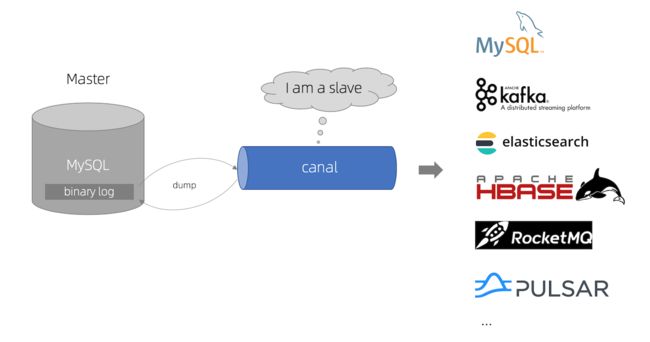
canal [kə’næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
基于日志增量订阅和消费的业务包括
- 数据库镜像
- 数据库实时备份
- 索引构建和实时维护(拆分异构索引、倒排索引等)
- 业务 cache 刷新
- 带业务逻辑的增量数据处理
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x。
简单的说,就是canal伪装成MySQL slave,向 MySQL master 发送dump 协议,最终通过解析binary log获取MySQL实时的数据变化。
二、准备工作
以下我们按照CentOS 7版本的服务器安装canal为例进行展开。
-
首先保证服务器的jdk环境已经就绪,因为canal是由java进行开发的,所以必须具备java运行环境。
-
由于canal作为与MySQL的管道工作,那么我们的MySQL就必须要提前准备好。
第一步的jdk环境准备就不做赘述了,用yum安装还是其他方式安装都比较快捷方便。
我们着重介绍第二步的MySQL准备工作,除了安装好之外还需要开启bin-log日志以及支持行模式。
- 需要编辑/etc/my.cnf:
[mysqld]
# 打开binlog
log-bin=mysql-bin
# 选择ROW(行)模式
binlog-format=ROW
# mysql实例唯一id,但是切记不能与下文中需要配置的canal的slaveId重复
server_id=1
-
重启MySQL服务
-
查看是否生效
show variables like 'log_bin';
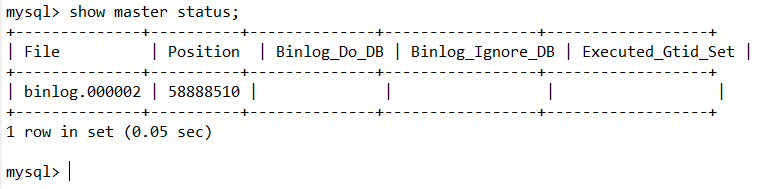
查看正在写入的binlog文件状态:
show master status;
创建一个mycanal的库,并在该库下创建一个最简单的示例test表:
CREATE TABLE `test` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`name` varchar(255) COLLATE utf8_bin DEFAULT NULL COMMENT '姓名',
`age` int DEFAULT NULL COMMENT '年龄',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3 COLLATE=utf8_bin;
三、canal服务端搭建
-
首先需要从官方仓库下载对应的发行版本
访问alibaba/canal/releases,截至目前最新的版本为2021年上半年发布的1.1.5版本:

由于我们这里主要是搭建服务端,所以选择deployer即可,deployer-1.1.5:

-
将下载好的压缩包丢到服务器上,进行解压
tar -xzvf canal.deployer-1.1.5-SNAPSHOT.tar.gz解压后我们能够看到以下5个文件夹:
drwxr-xr-x 2 root root 4096 Dec 19 13:36 bin drwxr-xr-x 5 root root 4096 Dec 19 13:36 conf drwxr-xr-x 2 root root 4096 Dec 19 13:36 lib drwxrwxrwx 2 root root 4096 Aug 22 2020 logs drwxrwxrwx 2 root root 4096 Aug 22 2020 plugin-
bin:启动、停止等脚本命令
-
conf:配置文件目录
-
lib:相关依赖jar包
-
logs:日志目录
-
plugin:相关mq依赖插件jar包
-
3.1 配置文件
最重要的两块地方:canal.properties、example(可改名或者自定义一个新的instance)
-
重点关注conf目录
-rwxrwxrwx 1 root root 291 Aug 31 2019 canal_local.properties -rwxrwxrwx 1 root root 5801 Aug 21 2020 canal.properties drwxrwxrwx 2 root root 4096 Dec 19 13:36 example -rwxrwxrwx 1 root root 3437 Feb 28 2020 logback.xml drwxrwxrwx 2 root root 4096 Dec 19 13:36 metrics drwxrwxrwx 3 root root 4096 Dec 19 13:36 spring
3.1.1 canal.properties
设置canal的启动端口、mq等设置,文件内容如下(这里只贴出重要的部分):
#################################################
######### common argument #############
#################################################
# tcp bind ip
canal.ip =
# register ip to zookeeper
canal.register.ip =
canal.port = 11111
canal.metrics.pull.port = 11112
# canal instance user/passwd
# canal.user = canal
# canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458
# canal admin config
#canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
canal.zkServers =
# flush data to zk
canal.zookeeper.flush.period = 1000
canal.withoutNetty = false
# tcp, kafka, rocketMQ, rabbitMQ
canal.serverMode = tcp
# flush meta cursor/parse position to file
canal.file.data.dir = ${canal.conf.dir}
canal.file.flush.period = 1000
## memory store RingBuffer size, should be Math.pow(2,n)
canal.instance.memory.buffer.size = 16384
## memory store RingBuffer used memory unit size , default 1kb
canal.instance.memory.buffer.memunit = 1024
## meory store gets mode used MEMSIZE or ITEMSIZE
canal.instance.memory.batch.mode = MEMSIZE
canal.instance.memory.rawEntry = true
## detecing config
canal.instance.detecting.enable = false
#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
canal.instance.detecting.sql = select 1
canal.instance.detecting.interval.time = 3
canal.instance.detecting.retry.threshold = 3
canal.instance.detecting.heartbeatHaEnable = false
# support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
canal.instance.transaction.size = 1024
# mysql fallback connected to new master should fallback times
canal.instance.fallbackIntervalInSeconds = 60
# network config
canal.instance.network.receiveBufferSize = 16384
canal.instance.network.sendBufferSize = 16384
canal.instance.network.soTimeout = 30
# binlog filter config
canal.instance.filter.druid.ddl = true
canal.instance.filter.query.dcl = false
canal.instance.filter.query.dml = false
canal.instance.filter.query.ddl = false
canal.instance.filter.table.error = false
canal.instance.filter.rows = false
canal.instance.filter.transaction.entry = false
# binlog format/image check
canal.instance.binlog.format = ROW,STATEMENT,MIXED
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB
# binlog ddl isolation
canal.instance.get.ddl.isolation = false
# parallel parser config
canal.instance.parser.parallel = true
## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
#canal.instance.parser.parallelThreadSize = 16
## disruptor ringbuffer size, must be power of 2
canal.instance.parser.parallelBufferSize = 256
# table meta tsdb info
canal.instance.tsdb.enable = true
canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:}
canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
canal.instance.tsdb.dbUsername = canal
canal.instance.tsdb.dbPassword = canal
# dump snapshot interval, default 24 hour
canal.instance.tsdb.snapshot.interval = 24
# purge snapshot expire , default 360 hour(15 days)
canal.instance.tsdb.snapshot.expire = 360
#################################################
######### destinations #############
#################################################
canal.destinations = example
# conf root dir
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
canal.auto.scan = true
canal.auto.scan.interval = 5
...
重点关注:
-
canal.port = 11111
canal服务启动端口
-
canal.destinations = example
实例名称,这里可以指定多个实例,多个实例用逗号隔开。一个实例即对应conf目录下的 包含instance.properties文件的文件夹,例如此处的example即表示默认的conf/example目录(下文将会着重介绍)
-
canal.conf.dir = …/conf:配置文件目录
-
mq配置在文件底部,这里为了复杂度考虑暂时不引入mq。
为了演示环境最小化更容易理解,我们主要修改一个canal.destinations,将实例名称从原先的example调整为example,mycanal,表示部署两个实例。
3.1.2 instance 实例配置
回到conf目录下,复制一个example目录重命名为mycanal表示这是我们配的一个自定义实例。以下按照example监听所有库表,而mycanal只监听某个库中的某个表进行配置。
cp -r example mycanal
vim example/instance.properties
#################################################
## mysql serverId , v1.0.26+ will autoGen
# canal.instance.mysql.slaveId=0
# enable gtid use true/false
canal.instance.gtidon=false
# position info
canal.instance.master.address=127.0.0.1:3306
canal.instance.master.journal.name=
canal.instance.master.position=
canal.instance.master.timestamp=
canal.instance.master.gtid=
# rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId=
# table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=
# username/password
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.connectionCharset = UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==
# table regex
canal.instance.filter.regex=.*\\..*
# table black regex
canal.instance.filter.black.regex=mysql\\.slave_.*
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch
# mq config
canal.mq.topic=example
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,mytest2\\..*,.*\\..*
canal.mq.partition=0
# hash partition config
#canal.mq.partitionsNum=3
#canal.mq.partitionHash=test.table:id^name,.*\\..*
#canal.mq.dynamicTopicPartitionNum=test.*:4,mycanal:6
#################################################
重点关注:
-
canal.instance.master.address=127.0.0.1:3306
配置数据库连接地址
-
canal.instance.master.journal.name=
配置mysql主库链接时起始的binlog文件,例如mysql-bin.000002,表示我跳过mysql-bin.000001的文件,直接从2开始。不指定表示从初始位置开始。在example实例中这里我们不指定
-
canal.instance.master.position=
配置mysql主库链接时起始的binlog偏移量。不指定表示从初始位置开始。在example实例中这里我们不指定
-
canal.instance.dbUsername=canal
数据库账号
-
canal.instance.dbPassword=canal
数据库密码
-
canal.instance.filter.regex
mysql 数据解析关注的表,Perl正则表达式
例如:mycanal schema下的一张表:mycanal.test1、
mycanal下的以canal打头的表:mycanal.canal.*
-
canal.instance.filter.black.regex
mysql数据解析表的黑名单,表达式规则见白名单的规则
在example实例中,我们只修改数据库连接信息,其他均按照默认配置来。
接下来我们配置mycanal实例,即回到conf目录下找到我们复制过去的mycanal文件夹,同样修改instance.properties配置文件
vim mycanal/instance.properties但是我们指定canal.instance.filter.regex=mycanal.test,表示只监听mycanal库下的test表。
3.2 开始启动
回到bin目录下执行启动命令:
./startup.sh
3.3 查看日志
-
查看canal运行日志:看到the canal server is running now …即表示启动成功
cat logs/canal/canal.log
-
查看instance实例日志
cat logs/example/example.log cat logs/mycanal/mycanal.log如果出现以下报错,找不到数据库对应的@127.0.0.1的用户,并且由于本人使用的MySQL8版本用的caching_sha2_password加密方式,所以需要修改为mysql_native_password:

在数据库中创建一个@127.0.0.1且使用mysql_native_password加密方式的用户:
# 创建一个root用户名在127.0.0.1下的账号,密码设置为vainycos CREATE USER 'root'@'127.0.0.1' IDENTIFIED BY 'vainycos'; # 调整密码策略 ALTER USER 'root'@'127.0.0.1' IDENTIFIED WITH mysql_native_password BY 'vainycos'; # 授权用户 GRANT ALL PRIVILEGES ON *.* to 'root'@'127.0.0.1'; # 刷新系统权限表 flush privileges;设置完之后,我们重启一下canal的服务:
./bin/restart.sh看到以下instance实例日志日志就说明启动成功了。
这个时候我们去查看各自实例文件夹,会发现多了两个文件:
h2.mv.db:
meta.dat:
我们先观察一下meta.data的文件,刚启动的时候是这样的:
{"clientDatas":[],"destination":"mycanal"}等后面我们接入canal客户端的时候再回过头来观察这个文件。
至此,canal的服务端搭建就此结束了。
四、客户端实现
在这里,我们使用springboot结合canal-client实现一个初版的简单客户端。
-
首先,在项目的pom文件中导入依赖
<dependency> <groupId>com.alibaba.ottergroupId> <artifactId>canal.clientartifactId> <version>1.1.5version> dependency> <dependency> <groupId>com.alibaba.ottergroupId> <artifactId>canal.protocolartifactId> <version>1.1.5version> dependency> <dependency> <groupId>org.projectlombokgroupId> <artifactId>lombokartifactId> <optional>trueoptional> dependency> -
实现核心代码
- 首先定义连接参数(这里我们先以mycanal实例为例,配置文件中只监听mycanal库下的test表)
/** * 连接ip */ private static final String IP = "xxx.xxx.xxx.xxx"; /** * 连接端口号 */ private static final Integer PORT = 11111; /** * 连接canal通道 */ private static final String DESTINATION = "mycanal"; /** * 批次最大数量 */ private final static int BATCH_SIZE = 1000;-
建立连接
// 后面两个参数是账号和密码,这里未设置账号密码故空着 CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(IP, PORT), DESTINATION, "", ""); // 打开连接 connector.connect(); // 订阅mycanal库下的test单表 connector.subscribe("mycanal.test"); -
实时获取:这里使用一个while(true)循环获取
while (true) { // 获取指定数量的数据 Message message = connector.getWithoutAck(BATCH_SIZE); //获取批量ID long batchId = message.getId(); //获取批量的数量 int size = message.getEntries().size(); //如果没有数据 if (batchId == -1 || size == 0) { // 若无数据则不打印,避免日志臃肿 // log.info("无数据"); try { // 线程休眠2秒 Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } } else { // 如果有数据,处理数据 printEntry(message.getEntries()); } // 进行 batch id 的确认。确认之后,小于等于此 batchId 的 Message 都会被确认。 connector.ack(batchId); } -
解析binlog获得的实体类信息:体现在printEntry()方法
private void printEntry(List<CanalEntry.Entry> entrys) { for (CanalEntry.Entry entry : entrys) { if (isTransactionEntry(entry)){ //开启/关闭事务的实体类型,跳过 continue; } //RowChange对象,包含了一行数据变化的所有特征 //比如isDdl 是否是ddl变更操作 sql 具体的ddl sql beforeColumns afterColumns 变更前后的数据字段等等 CanalEntry.RowChange rowChage; try { rowChage = CanalEntry.RowChange.parseFrom(entry.getStoreValue()); } catch (Exception e) { throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(), e); } //获取操作类型:insert/update/delete类型 CanalEntry.EventType eventType = rowChage.getEventType(); //打印Header信息 log.info("================》; binlog[{} : {}] , name[{}, {}] , eventType : {}", entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(), entry.getHeader().getSchemaName(), entry.getHeader().getTableName(), eventType); //判断是否是DDL语句 if (rowChage.getIsDdl()) { log.info("================》;isDdl: true,sql:{}", rowChage.getSql()); } //获取RowChange对象里的每一行数据,打印出来 for (CanalEntry.RowData rowData : rowChage.getRowDatasList()) { //如果是删除语句 if (eventType == CanalEntry.EventType.DELETE) { log.info(">>>>>>>>>> 删除 >>>>>>>>>>"); printColumnAndExecute(rowData.getBeforeColumnsList(), "DELETE"); //如果是新增语句 } else if (eventType == CanalEntry.EventType.INSERT) { log.info(">>>>>>>>>> 新增 >>>>>>>>>>"); printColumnAndExecute(rowData.getAfterColumnsList(), "INSERT"); //如果是更新的语句 } else { log.info(">>>>>>>>>> 更新 >>>>>>>>>>"); //变更前的数据 log.info("------->; before"); printColumnAndExecute(rowData.getBeforeColumnsList(), null); //变更后的数据 log.info("------->; after"); printColumnAndExecute(rowData.getAfterColumnsList(), "UPDATE"); } } } } -
判断当前entry是否为事务日志:若为事务日志则跳过
/** * 判断当前entry是否为事务日志 */ private boolean isTransactionEntry(CanalEntry.Entry entry){ if(entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONBEGIN){ log.info("********* 日志文件为:{}, 事务开始偏移量为:{}, 事件类型为type={}", entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(), entry.getEntryType() ); return true; }else if (entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONEND){ log.info("********* 日志文件为:{}, 事务结束偏移量为:{}, 事件类型为type={}", entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(), entry.getEntryType() ); return true; }else { return false; } } -
实际处理数据:体现在printColumnAndExecute()方法
/** * 执行数据同步 * @param columns * @param type */ private void printColumnAndExecute(List<CanalEntry.Column> columns, String type) { if(type == null){ return; } JSONObject jsonObject = new JSONObject(); for (CanalEntry.Column column : columns) { jsonObject.put(column.getName(), column.getValue()); log.info("{}: {}", column.getName(), column.getValue()); } // 此处使用json转对象的方式进行转换 // JSONObject.parseObject(jsonObject.toString(), xxx.class) if(type.equals("INSERT")){ // 执行新增 log.info("新增成功->{}", jsonObject.toJSONString()); }else if (type.equals("UPDATE")){ // 执行编辑 log.info("编辑成功->{}", jsonObject.toJSONString()); }else if (type.equals("DELETE")){ // 执行删除 log.info("删除成功->{}", jsonObject.toJSONString()); } }
启动完成后,通过我们的程序端日志打印可以看到数据库的bin-log历史日志:

这个时候我们去观察mycanal实例的meta.dat文件就能看到文件内容变更了:
{"clientDatas":[{"clientIdentity":{"clientId":1001,"destination":"mycanal","filter":"mycanal.test"},"cursor":{"identity":{"slaveId":-1,"sourceAddress":{"address":"VM-0-16-centos","port":3306}},"postion":{"gtid":"","included":false,"journalName":"binlog.000001","position":1808,"serverId":1,"timestamp":1639998702000}}}],"destination":"mycanal"}
这个文件记录了当前被客户端载入的journalName和position。
我们测试一下在mycanal库里的test表中手动新建一条记录:
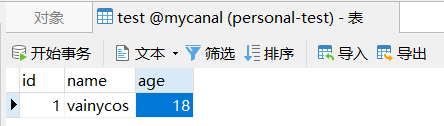
观察客户端的控制台日志打印:

观察meta.dat文件,会发现meta.dat的position偏移量也同步发生了变更:
{"clientDatas":[{"clientIdentity":{"clientId":1001,"destination":"mycanal","filter":"mycanal.test"},"cursor":{"identity":{"slaveId":-1,"sourceAddress":{"address":"VM-0-16-centos","port":3306}},"postion":{"gtid":"","included":false,"journalName":"binlog.000001","position":3541,"serverId":1,"timestamp":1640077721000}}}],"destination":"mycanal"}
客户端读取的开始节点就是根据meta.dat文件中的position来定位,目前position为3541,下一次客户端读取的时候就会从3541后面接着读取。
同理,在example的实例中,我们配置了监听全库全表,我们在客户端将DESTINATION改为example,然后重启一下就能看到该数据库下所有的库表变动了。
在这里我们推荐的做法是在配置文件中监听全库全表,然后在客户端加上监听库表的设置参数。
至此,我们就实现了一个纯净版本的canal服务端和客户端。而实际上,通过观察canal配置文件我们也可以发现有大量关于zk以及mq的相关配置信息。在生产环境中应该还需要接入mq消息队列,在后续的章节中将会持续迭代。
参考仓库:https://gitee.com/dearvainycos/mycanal
参考资料:
- 超详细的Canal入门,看这篇就够了!
- Canal配置
- CANAL环境搭建(几乎帮你避过所有的坑)