Apache Doris :Rollup 物化视图
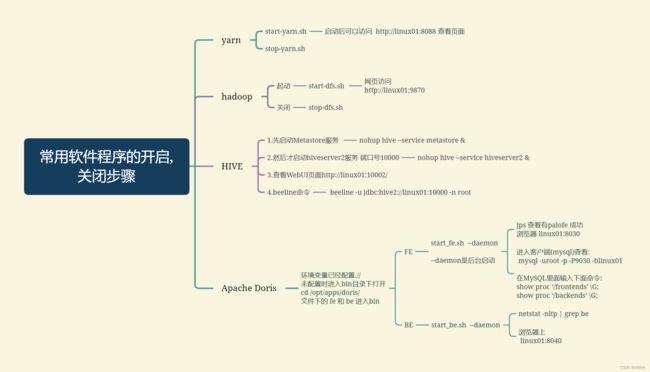
整理了一下目前开启虚拟机需要用到的程序, 包括MySQL,Hadoop,Linux, hive,Doris
3.5 Rollup
ROLLUP 在多维分析中是“上卷”的意思,即将数据按某种指定的粒度进行进一步聚合。
1.求每个城市的每个用户的每天的总销售额
select
user_id,city,date,
sum(sum_cost) as sum_cost
from t
group by user_id,city,date
– user_id date city sum_cost
10000 2017/10/2 北京 195
10000 2017/10/1 上海 100
10000 2017/10/2 上海 30
10000 2017/10/3 上海 55
10000 2017/10/4 上海 65
10001 2017/10/1 上海 30
10001 2017/10/2 上海 10
10001 2017/10/2 天津 18
10001 2017/10/1 天津 46
10002 2017/10/1 天津 55
10002 2017/10/3 北京 55
10002 2017/10/2 天津 20
10002 2017/10/2 北京 35
2.求每个用户、每个城市的总消费额
select
user_id,city,
sum(sum_cost) as sum_cost
from t
group by user_id,city
user_id city sum_cost
10000 北京 195
10000 上海 100
10001 上海 40
10001 天津 64
10002 天津 75
10002 北京 90
3.求每个用户的总消费额
select
user_id,
sum(sum_cost) as sum_cost
from t
group by user_id
user_id sum_cost
10000 295
10001 104
10002 165
3.5.1基本概念
通过建表语句创建出来的表称为 Base 表(Base Table,基表)
在 Base 表之上,我们可以创建任意多个 ROLLUP 表。这些 ROLLUP 的数据是基于 Base 表产生的,并且在物理上是独立存储的。
Rollup表的好处:
- 和基表共用一个表名,doris会根据具体的查询逻辑选择合适的数据源(合适的表)来计算结果
- 对于基表中数据的增删改,rollup表会自动更新同步
3.5.2 Aggregate 模型中的 ROLLUP
查看下之前建得一张表:
mysql> desc ex_user all;
示例:查看某个用户的总消费
添加一个roll up
alter table aggregate表名 add rollup “rollup表的表名” (user_id,city,date,cost);
alter table ex_user add rollup rollup_ucd_cost(user_id,city,date,cost);
alter table ex_user add rollup rollup_u_cost(user_id,cost);
alter table ex_user add rollup rollup_cd_cost(city,date,cost);
alter table ex_user drop rollup rollup_u_cost;
alter table ex_user drop rollup rollup_cd_cost;
–如果是replace聚合类型得value,需要指定所有得key
– alter table ex_user add rollup rollup_cd_visit(city,date,last_visit_date);
– ERROR 1105 (HY000): errCode = 2, detailMessage = Rollup should contains
– all keys if there is a REPLACE value
–添加完成之后可以show一下,看看底层得rollup有没有执行完成
SHOW ALTER TABLE ROLLUP;
再次查看该表得详细信息后发现,多了一个IndexName为rollup_cost_userid(这是我们自己取得roll
Up 名字)
Doris 会自动命中这个 ROLLUP 表,从而只需扫描极少的数据量,即可完成这次聚合查询。
explain SELECT user_id, sum(cost) FROM ex_user GROUP BY user_id;
3.5.3 Unique 模型中的 ROLLUP
unique模型示例表
drop table if exists test.user;
CREATE TABLE IF NOT EXISTS test.user
(
user_id LARGEINT NOT NULL COMMENT “用户 id”,
username VARCHAR(50) NOT NULL COMMENT “用户昵称”,
city VARCHAR(20) COMMENT “用户所在城市”,
age SMALLINT COMMENT “用户年龄”,
sex TINYINT COMMENT “用户性别”,
phone LARGEINT COMMENT “用户电话”,
address VARCHAR(500) COMMENT “用户地址”,
register_time DATETIME COMMENT “用户注册时间” )
UNIQUE KEY(user_id, username)
DISTRIBUTED BY HASH(user_id) BUCKETS 1;
插入语句
insert into test.user values
(10000,‘zss’,‘北京’,18,0,12345678910,'北京朝阳区 ',‘2017-10-01 07:00:00’),
(10000,‘zss’,‘北京’,18,0,12345678910,'北京朝阳区 ',‘2017-10-01 08:00:00’),
(10001,‘lss’,‘北京’,20,0,12345678910,‘北京海淀区’,‘2017-11-15 06:10:20’);
很显然,里面的数据是这样的
mysql> select * from user;
±--------±---------±-------±-----±-----±------------±-----------------±--------------------+
| user_id | username | city | age | sex | phone | address | register_time |
±--------±---------±-------±-----±-----±------------±-----------------±--------------------+
| 10000 | lss | 北京 | 20 | 0 | 12345678910 | 北京海淀区 | 2017-11-15 06:10:20 |
| 10000 | zss | 北京 | 19 | 0 | 12345678910 | 北京朝阳区 | 2017-10-01 07:00:00 |
±--------±---------±-------±-----±-----±------------±-----------------±--------------------+
在unique模型中做rollup表,rollup的key必须延用base表中所有的key,不同的是value可以随意指定
alter table user add rollup rollup_username_id(username,user_id,age);
所以说,unique模型中建立rollup表没有什么太多的意义
3.5.4 Duplicate 模型中的 ROLLUP
因为 Duplicate 模型没有聚合的语意。所以该模型中的 ROLLUP,已经失去了“上卷” 这一层含义。而仅仅是作为调整列顺序,以命中前缀索引的作用。下面详细介绍前缀索引,以及如何使用 ROLLUP 改变前缀索引,以获得更好的查询效率。
ROLLUP 调整前缀索引(新增一套前缀索引)
因为建表时已经指定了列顺序,所以一个表只有一种前缀索引。这对于使用其他不能命中前缀索引的列作为条件进行的查询来说,效率上可能无法满足需求。因此,我们可以通过创建 ROLLUP 来人为的调整列顺序。
当我们进行如下查询时:
SELECT * FROM table where age=20 and message LIKE “%error%”;
会优先选择 ROLLUP 表,因为 ROLLUP 的前缀索引匹配度更高。
示例:针对上面的log_detail这张基表添加两个rollup表
按照type 和error_code 进行建前缀索引
alter table log_detail add rollup rollup_tec(type,error_code,timestamp,error_msg,op_id,op_time);
alter table log_detail drop rolluprollup_tec
按照op_id和error_code 进行建前缀索引
alter table log_detail add rollup rollup_oec(op_id,error_code,timestamp,type,error_msg,op_time);
查看表中基表和rollup表
mysql> desc log_detail all;
±-----------±--------------±-----------±--------------±-----±------±--------±------±--------+
| IndexName | IndexKeysType | Field | Type | Null | Key | Default | Extra | Visible |
±-----------±--------------±-----------±--------------±-----±------±--------±------±--------+
| log_detail | DUP_KEYS | timestamp | DATETIME | No | true | NULL | | true |
| | | type | INT | No | true | NULL | | true |
| | | error_code | INT | Yes | false | NULL | NONE | true |
| | | error_msg | VARCHAR(1024) | Yes | false | NULL | NONE | true |
| | | op_id | BIGINT | Yes | false | NULL | NONE | true |
| | | op_time | DATETIME | Yes | false | NULL | NONE | true |
| | | | | | | | | |
| rollup_oec | DUP_KEYS | op_id | BIGINT | Yes | true | NULL | | true |
| | | error_code | INT | Yes | true | NULL | | true |
| | | timestamp | DATETIME | No | true | NULL | | true |
| | | type | INT | No | false | NULL | NONE | true |
| | | error_msg | VARCHAR(1024) | Yes | false | NULL | NONE | true |
| | | op_time | DATETIME | Yes | false | NULL | NONE | true |
| | | | | | | | | |
| rollup_tec | DUP_KEYS | type | INT | No | true | NULL | | true |
| | | error_code | INT | Yes | true | NULL | | true |
| | | timestamp | DATETIME | No | true | NULL | | true |
| | | error_msg | VARCHAR(1024) | Yes | false | NULL | NONE | true |
| | | op_id | BIGINT | Yes | false | NULL | NONE | true |
| | | op_time | DATETIME | Yes | false | NULL | NONE | true |
±-----------±--------------±-----------±--------------±-----±------±--------±------±--------+
示例:看如下sql会命中哪一张表
explain select * from log_detail where type = 1;
explain select * from log_detail where type = 1 and error_code = 404;
explain select * from log_detail where op_id = 101 ;
explain select * from log_detail where op_id = 101 and error_code = 404;
explain select * from log_detail where timestamp = ‘2017-10-01 08:00:05’ ;
explain select * from log_detail where timestamp = ‘2017-10-01 08:00:05’ and type = 1;
ROLLUP使用说明
- ROLLUP 是附属于 Base 表的,用户可以在 Base 表的基础上,创建或删除 ROLLUP,但是不能在查询中显式的指定查询某 ROLLUP。是否命中 ROLLUP 完全由 Doris 系统自动决定
- ROLLUP 的数据是独立物理存储的。因此,创建的 ROLLUP 越多,占用的磁盘空间也就越大。同时对导入速度也会有影响,但是不会降低查询效率(只会更好)。
- ROLLUP 的数据更新与 Base 表是完全同步的。用户无需关心这个问题。
- 在聚合模型中,ROLLUP 中列的聚合类型,与 Base 表完全相同。在创建 ROLLUP 无需指定,也不能修改。
- 可以通过 EXPLAIN your_sql; 命令获得查询执行计划,在执行计划中,查看是否命中 ROLLUP。
- 可以通过 DESC tbl_name ALL; 语句显示 Base 表和所有已创建完成的 ROLLUP
3.6 物化视图
就是查询结果预先存储起来的特殊的表。物化视图的出现主要是为了满足用户,既能对原始明细数据的任意维度分析,也能快速的对固定维度进行分析查询
3.6.1 优势 - 可以复用预计算的结果来提高查询效率 ==> 空间换时间
- 自动实时的维护物化视图表中的结果数据,无需额外人工成本(自动维护会有计算资源的开销)
- 查询时,会自动选择最优物化视图
3.6.2 物化视图 VS Rollup
- 明细模型表下,rollup和物化视图的差别:
物化视图:都可以实现预聚合,新增一套前缀索引
rollup:对于明细模型,新增一套前缀索引 - 聚合模型下,功能一致
3.6.3 创建物化视图
语法:
CREATE MATERIALIZED VIEW [MV name] as
[query] – sql逻辑
–[MV name]:雾化视图的名称
–[query]:查询条件,基于base表创建雾化视图的逻辑
取消正在创建的物化视图
CANCEL ALTER MATERIALIZED VIEW FROM db_name.table_name
物化视图创建成功后,用户的查询不需要发生任何改变,也就是还是查询的 base 表。Doris 会根据当前查询的语句去自动选择一个最优的物化视图,从物化视图中读取数据并计算。
用户可以通过 EXPLAIN 命令来检查当前查询是否使用了物化视图。
3.6.4 案例演示
创建一个 Base 表:
用户有一张销售记录明细表,存储了每个交易的交易id,销售员,售卖门店,销售时间,以及金额
drop table sales_records;
create table sales_records(
record_id int,
seller_id int,
store_id int,
sale_date date,
sale_amt bigint)
duplicate key (record_id,seller_id,store_id,sale_date)
distributed by hash(record_id) buckets 2
properties(“replication_num” = “1”);
– 插入数据
insert into sales_records values
(1,1,1,‘2022-02-02’,100),
(2,2,1,‘2022-02-02’,200),
(3,3,2,‘2022-02-02’,300),
(4,3,2,‘2022-02-02’,200),
(5,2,1,‘2022-02-02’,100),
(6,4,2,‘2022-02-02’,200),
(7,7,3,‘2022-02-02’,300),
(8,2,1,‘2022-02-02’,400),
(9,9,4,‘2022-02-02’,100);
如果用户需要经常对不同门店的销售量进行统计
第一步:创建一个物化视图
– 不同门店,看总销售额的一个场景
select store_id, sum(sale_amt)
from sales_records
group by store_id;
CREATE MATERIALIZED VIEW store_id_sale_amonut as
select store_id, sum(sale_amt)
from sales_records
group by store_id;
CREATE MATERIALIZED VIEW store_amt as
select store_id, sum(sale_amt) as sum_amount
from sales_records
group by store_id;
–针对上述场景做一个物化视图
create materialized view store_amt as
select store_id, sum(sale_amt) as sum_amount
from sales_records
group by store_id;
第二步:检查物化视图是否构建完成(物化视图的创建是个异步的过程)
show alter table materialized view from 库名 order by CreateTime desc limit 1;
show alter table materialized view from test order by CreateTime desc limit 1;
±------±--------------±--------------------±--------------------±--------------±----------------±---------±--------------±---------±-----±---------±--------+
| JobId | TableName | CreateTime | FinishTime | BaseIndexName | RollupIndexName | RollupId | TransactionId | State | Msg | Progress | Timeout |
±------±--------------±--------------------±--------------------±--------------±----------------±---------±--------------±---------±-----±---------±--------+
| 15093 | sales_records | 2022-11-25 10:32:33 | 2022-11-25 10:32:59 | sales_records | store_amt | 15094 | 3008 | FINISHED | | NULL | 86400 |
±------±--------------±--------------------±--------------------±--------------±----------------±---------±--------------±---------±-----±---------±--------+
查看 Base 表的所有物化视图
desc sales_records all;
±--------------±--------------±----------±-------±-----±------±--------±------±--------+
| IndexName | IndexKeysType | Field | Type | Null | Key | Default | Extra | Visible |
±--------------±--------------±----------±-------±-----±------±--------±------±--------+
| sales_records | DUP_KEYS | record_id | INT | Yes | true | NULL | | true |
| | | seller_id | INT | Yes | true | NULL | | true |
| | | store_id | INT | Yes | true | NULL | | true |
| | | sale_date | DATE | Yes | true | NULL | | true |
| | | sale_amt | BIGINT | Yes | false | NULL | NONE | true |
| | | | | | | | | |
| store_amt | AGG_KEYS | store_id | INT | Yes | true | NULL | | true |
| | | sale_amt | BIGINT | Yes | false | NULL | SUM | true |
±--------------±--------------±----------±-------±-----±------±--------±------±--------+
第三步:查询
看是否命中刚才我们建的物化视图
EXPLAIN SELECT store_id, sum(sale_amt) FROM sales_records GROUP BY store_id;
±-----------------------------------------------------------------------------------+
| Explain String |
±-----------------------------------------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS:store_id | sale_amt) |
| PARTITION: UNPARTITIONED |
| |
| VRESULT SINK |
| |
| 4:VEXCHANGE |
| |
| PLAN FRAGMENT 1 |
| |
| PARTITION: HASH_PARTITIONED: store_id |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 04 |
| UNPARTITIONED |
| |
| 3:VAGGREGATE (merge finalize) |
| | output: sum(sale_amt)) |
| | group by: store_id |
| | cardinality=-1 |
| | |
| 2:VEXCHANGE |
| |
| PLAN FRAGMENT 2 |
| |
| PARTITION: HASH_PARTITIONED: default_cluster:study.sales_records.record_id |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 02 |
| HASH_PARTITIONED: store_id |
| |
| 1:VAGGREGATE (update serialize) |
| | STREAMING |
| | output: sum(sale_amt) |
| | group by: store_id |
| | cardinality=-1 |
| | |
| 0:VOlapScanNode |
| TABLE: sales_records(store_amt), PREAGGREGATION: ON |
| partitions=1/1, tablets=10/10, tabletList=15095,15097,15099 … |
| cardinality=7, avgRowSize=1560.0, numNodes=3 |
±-----------------------------------------------------------------------------------+
删除物化视图语法
– 语法:
DROP MATERIALIZED VIEW 物化视图名 on base_table_name;
–示例:
drop materialized view store_amt on sales_records;
案例一:计算广告的 pv、uv
用户有一张点击广告的明细数据表
需求:针对用户点击计广告明细数据的表,算每天,每个页面,每个渠道的 pv,uv
pv:page view,页面浏览量或点击量
uv:unique view,通过互联网访问、浏览这个网页的自然人
drop table if exists ad_view_record;
create table ad_view_record(
dt date,
ad_page varchar(10),
channel varchar(10),
refer_page varchar(10),
user_id int
)
distributed by hash(dt)
properties(“replication_num” = “1”);
select
dt,ad_page,channel,
count(ad_page) as pv,
count(distinct user_id ) as uv
from ad_view_record
group by dt,ad_page,channel
插入数据
insert into ad_view_record values
(‘2020-02-02’,‘a’,‘app’,‘/home’,1),
(‘2020-02-02’,‘a’,‘web’,‘/home’,1),
(‘2020-02-02’,‘a’,‘app’,‘/addbag’,2),
(‘2020-02-02’,‘b’,‘app’,‘/home’,1),
(‘2020-02-02’,‘b’,‘web’,‘/home’,1),
(‘2020-02-02’,‘b’,‘app’,‘/addbag’,2),
(‘2020-02-02’,‘b’,‘app’,‘/home’,3),
(‘2020-02-02’,‘b’,‘web’,‘/home’,3),
(‘2020-02-02’,‘c’,‘app’,‘/order’,1),
(‘2020-02-02’,‘c’,‘app’,‘/home’,1),
(‘2020-02-03’,‘c’,‘web’,‘/home’,1),
(‘2020-02-03’,‘c’,‘app’,‘/order’,4),
(‘2020-02-03’,‘c’,‘app’,‘/home’,5),
(‘2020-02-03’,‘c’,‘web’,‘/home’,6),
(‘2020-02-03’,‘d’,‘app’,‘/addbag’,2),
(‘2020-02-03’,‘d’,‘app’,‘/home’,2),
(‘2020-02-03’,‘d’,‘web’,‘/home’,3),
(‘2020-02-03’,‘d’,‘app’,‘/addbag’,4),
(‘2020-02-03’,‘d’,‘app’,‘/home’,5),
(‘2020-02-03’,‘d’,‘web’,‘/addbag’,6),
(‘2020-02-03’,‘d’,‘app’,‘/home’,5),
(‘2020-02-03’,‘d’,‘web’,‘/home’,4);
创建物化视图
– 怎么去计算pv,uv
select
dt,ad_page,channel,
count(ad_page) as pv,
count(distinct user_id) as uv
from ad_view_record
group by dt,ad_page,channel;
– 1.物化视图中,不能够使用两个相同的字段
– 2.在增量聚合里面,不能够使用count(distinct) ==> bitmap_union
– 3.count(字段)
create materialized view dpc_pv_uv as
select
dt,ad_page,channel,
– refer_page 没有null的情况
count(refer_page) as pv,
– doris的物化视图中,不支持count(distint) ==> bitmap_union
– count(distinct user_id) as uv
bitmap_union(to_bitmap(user_id)) uv_bitmap
from ad_view_record
group by dt,ad_page,channel;
//1. count(必须加字段名) 不能写count(1)
//2.同一个字段在物化视图的sql逻辑中不能出现两次
//3. count(distinct) 不能使用。需要用bitmap_union来代替
create materialized view tpc_pv_uv as
select
dt,ad_page,channel,
count(refer_page) as pv,
– refer_page 不能为null
– count(user_id) as pv
– count(1) as pv,
bitmap_union(to_bitmap(user_id)) as uv_bitmap
–count(distinct user_id) as uv
from ad_view_record
group by dt,ad_page,channel;
–结论:在doris的物化视图中,一个字段不能用两次,并且聚合函数后面必须跟字段名称
在 Doris 中,count(distinct) 聚合的结果和 bitmap_union_count 聚合的结果是完全一致的。而 bitmap_union_count 等于 bitmap_union 的结果求 count,所以如果查询中涉及到count(distinct) 则通过创建带 bitmap_union 聚合的物化视图方可加快查询。因为本身 user_id 是一个 INT 类型,所以在 Doris 中需要先将字段通过函数 to_bitmap 转换为 bitmap 类型然后才可以进行 bitmap_union 聚合。
查询自动匹配
explain
select
dt,ad_page,channel,
count(refer_page) as pv,
count(distinct user_id) as uv
from ad_view_record
group by dt,ad_page,channel;
会自动转换成。
explain
select
dt,ad_page,channel,
count(1) as pv,
bitmap_union_count(to_bitmap(user_id)) as uv
from ad_view_record
group by dt,ad_page,channel;
这个sql用的是哪张表呢?
explain
select
dt,ad_page,
count(refer_page) as pv,
count(distinct user_id) as uv
from ad_view_record
group by dt,ad_page;
TABLE: ad_view_record_1(tpc_pv_uv), PREAGGREGATION: ON
– 很显然命中的是tpc_pv_uv 这个物化视图
当然,我们还可以根据日期和页面的维度再去创建一张物化视图
create materialized view tp_pv_uv as
select
dt,ad_page,
count(refer_page) as pv,
bitmap_union(to_bitmap(user_id)) as uv
from ad_view_record
group by dt,ad_page;
再去执行上面的sql,显然命中的就是tp_pv_uv这个物化视图
explain
select
dt,ad_page,
count(refer_page) as pv,
count(distinct user_id) as uv
from ad_view_record
group by dt,ad_page;
– TABLE: ad_view_record_1(tp_pv_uv), PREAGGREGATION: ON
explain
select
dt,
count(refer_page) as pv,
count(distinct user_id) as uv
from ad_view_record
group by dt;
总结:
- 在创建doris的物化视图中,同一个字段不能被使用两次,并且聚合函数后面必须跟字段名称(不能使用count(1)这样的聚合逻辑)
- doris在选择使用哪一个物化视图表的时候,按照维度上卷的原则,选距离查询维度最接近,并且指标可以复用的物化视图
- 一张基表可以创建多个物化视图(计算资源占用比较多)