Doris集成Spark读写的简单示例
Doris集成Spark读写的简单示例
文章目录
- Doris集成Spark读写的简单示例
-
- 0、写在前面
- 1、Spark Doris Connector介绍
- 2、基本示例
-
- 2.1 提前准备表和数据
- 2.2 新建项目
- 2.3 使用SQL方式进行读写
-
- 2.3.1 代码
- 2.3.2 相关Error
- 2.4 使用DataFrame方式读写数据(**batch**)
-
- 2.4.1 代码
- 2.4.2 写入数据
- 2.4.2 读取数据
- 2.5 RDD演示
- 2.6 写入数据的其他方式
- 3. 配置项说明
-
- 3.1 通用配置项
- 3.2 SQL 和 Dataframe 专有配置
- 3.3 RDD 专有配置
- 3.4 Doris 和 Spark 列类型映射关系
- 4. 使用 **JDBC** 的方式
- 5. 其他集成系统
- 6. 参考资料
0、写在前面
- Doris版本:Doris-1.1.5
- Spark版本:Spark-3.0.0
- IDEA版本:IntelliJ IDEA 2019.2.3
- Scala版本:Scala-2.12.11
1、Spark Doris Connector介绍
- 介绍
Spark Doris Connector 支持通过 Spark 读取 Doris 中存储的数据,也支持通过Spark写入数据到Doris。
代码库地址:https://github.com/apache/incubator-doris-spark-connector
- 版本兼容
| Connector | Spark | Doris | Java | Scala |
|---|---|---|---|---|
| 2.3.4-2.11.xx | 2.x | 0.12+ | 8 | 2.11 |
| 3.1.2-2.12.xx | 3.x | 0.12.+ | 8 | 2.12 |
| 3.2.0-2.12.xx | 3.2.x | 0.12.+ | 8 | 2.12 |
- 使用Maven进行管理
<dependency>
<groupId>org.apache.dorisgroupId>
<artifactId>spark-doris-connector-3.1_2.12artifactId>
<version>1.1.0version>
dependency>
Note:同时此处的Spark Doris Connector版本不要使用官网的1.0.1版本,下文会演示相关error
2、基本示例
2.1 提前准备表和数据
开启doris的fe、be
-- 创建表table1
CREATE TABLE table1 (
siteid INT DEFAULT '10',
citycode SMALLINT,
username VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(siteid, citycode, username)
DISTRIBUTED BY HASH(siteid) BUCKETS 10
PROPERTIES("replication_num" = "1");
-- 插入数据
insert into table1 values (1,1,'jim',2),
(2,1,'grace',2),
(3,2,'tom',2),
(4,3,'bush',3),
(5,3,'helen',3);
2.2 新建项目
-
新建一个名为doris-module的Maven工程
-
准备Spark环境:pom.xml
<properties>
<scala.binary.version>2.12scala.binary.version>
<spark.version>3.0.0spark.version>
<maven.compiler.source>8maven.compiler.source>
<maven.compiler.target>8maven.compiler.target>
properties>
<dependencies>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_${scala.binary.version}artifactId>
<scope>providedscope>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_${scala.binary.version}artifactId>
<scope>providedscope>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-hive_${scala.binary.version}artifactId>
<scope>providedscope>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>2.12.11version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.47version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.49version>
dependency>
<dependency>
<groupId>org.apache.dorisgroupId>
<artifactId>spark-doris-connector-3.1_2.12artifactId>
<version>1.1.0version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.scala-toolsgroupId>
<artifactId>maven-scala-pluginartifactId>
<version>2.15.1version>
<executions>
<execution>
<id>compile-scalaid>
<goals>
<goal>add-sourcegoal>
<goal>compilegoal>
goals>
execution>
<execution>
<id>test-compile-scalaid>
<goals>
<goal>add-sourcegoal>
<goal>testCompilegoal>
goals>
execution>
executions>
plugin>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>3.2.2version>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-assembly-pluginartifactId>
<version>3.0.0version>
<executions>
<execution>
<id>make-assemblyid>
<phase>packagephase>
<goals>
<goal>singlegoal>
goals>
execution>
executions>
<configuration>
<archive>
<manifest>
manifest>
archive>
<descriptorRefs>
<descriptorRef>jar-with- dependenciesdescriptorRef>
descriptorRefs>
configuration>
plugin>
plugins>
build>
2.3 使用SQL方式进行读写
2.3.1 代码
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object SQLDemo {
def main(args: Array[String]): Unit = {
// TODO 如果要打包提交集群执行,请注释掉(此处直接在本地演示)
val sparkConf = new SparkConf().setAppName("SQLDemo").setMaster("local[2]")
val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
sparkSession.sql( """
|CREATE TEMPORARY VIEW spark_doris
|USING doris
|OPTIONS(
| "table.identifier"="test_db.table1",
| "fenodes"="node01:8030",
| "user"="test",
| "password"="test"
|); """.stripMargin)
// 读取数据
sparkSession.sql("select * from spark_doris").show()
// 写入数据
// sparkSession.sql("insert into spark_doris values(99,99,'haha',5)")
}
}
读取数据运行结果:
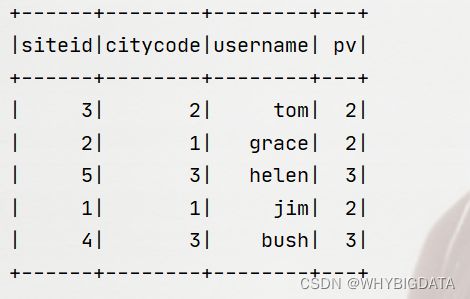
验证结果正确性:进入fe连接MySQL,查询table1表的数据,结果如下
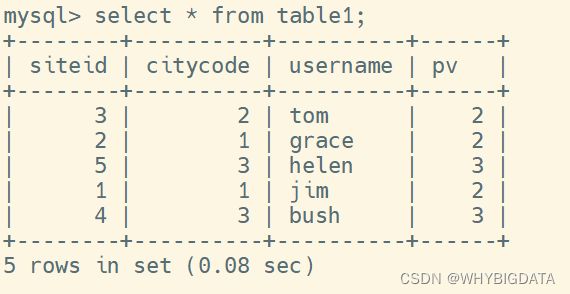
运行结果与实际结果相一致
- 写入数据
运行结束,查询table1表的数据,结果如下:
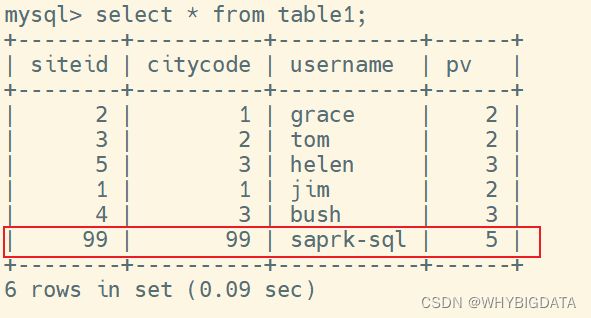
可以看到,利用spark写入数据到Doris已经成功了
2.3.2 相关Error
一开始,右键项目
Add framework support没有Scala
- 选中scala相关依赖并删除掉(如下图所示)
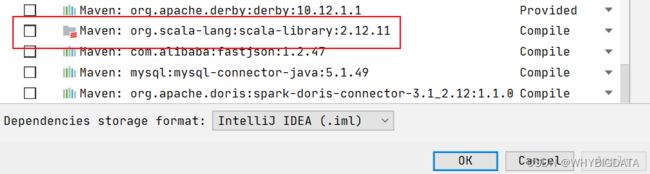
重新右键
Add framework support就可以添加Scala环境了
java.lang.NoClassDefFoundError: org/apache/spark/SparkConf
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/spark/SparkConf
at cn.whybigdata.doris.spark.SQLDemo$.main(SQLDemo.scala:7)
at cn.whybigdata.doris.spark.SQLDemo.main(SQLDemo.scala)
Caused by: java.lang.ClassNotFoundException: org.apache.spark.SparkConf
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:335)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 2 more
Process finished with exit code 1
因为在pom.xml文件中,spark-core_x.xx、spark-sql_x.xx、spark-hive_x.xx都是
provided的范围,解决方案如下:
- 选择
Edit Run/Debug configuration,选中需要执行的Application,勾选Include dependencies with "Provided" scope即可,如下图所示
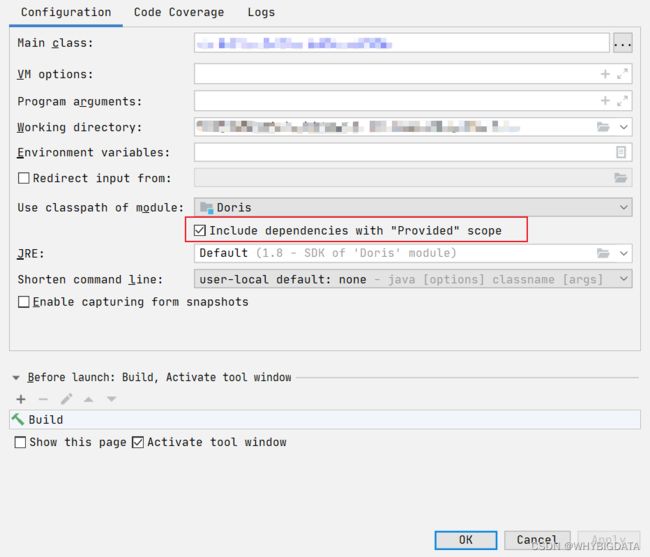
上述方式只对当前.scala程序起作用,如果要对该项目的所有Application起作用,可以选择
template,然后选择Application,勾选Include dependencies with "Provided" scope即可
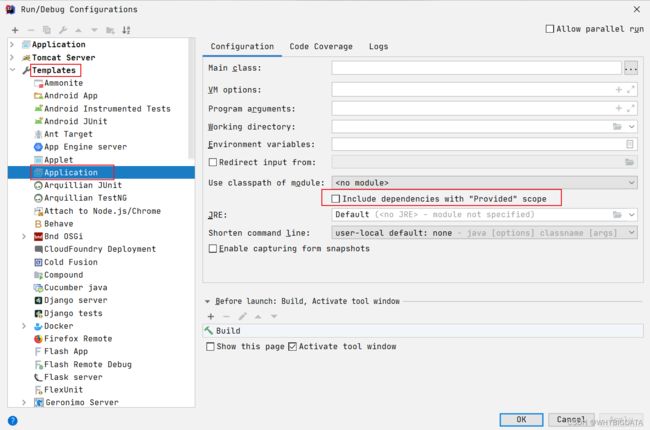
还有一种更直接的方式:直接注释掉
spark-core_x.xx、spark-sql_x.xx、spark-hive_x.xx依赖的scope范围,但是这种方式不推荐,因为大多数情况下是选择打包到集群上执行,而非本地,而集群一般都是已经拥有spark这些以来环境的,使用provided的scope范围,在集群中执行时是不会加载的。
- [Bug] spark doris connector read table error: Doris FE’s response cannot map to schema.
原因是1.0.1版本的spark-doris-connector自身的bug,已经在1.1.0版本修复了
2.4 使用DataFrame方式读写数据(batch)
2.4.1 代码
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object DataFrameDemo {
def main(args: Array[String]): Unit = {
//TODO 如果要打包提交集群执行,请注释掉
val sparkConf = new SparkConf().setAppName("DataFrameDemo").setMaster("local[2]")
val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
// TODO 写入数据
// import sparkSession.implicits._
// val mockDataDF = List(
// (11,23, "haha", 8),
// (11, 3, "hehe", 9),
// (11, 3, "heihei", 10)
// ).toDF("siteid", "citycode", "username","pv")
// mockDataDF.show(5)
//
// mockDataDF.write.format("doris")
// .option("doris.table.identifier", "test_db.table1")
// .option("doris.fenodes", "node01:8030")
// .option("user", "test")
// .option("password", "test")
// // 指定你要写入的字段
// // .option("doris.write.fields", "user")
// .save()
// TODO 读取数据
val dorisSparkDF = sparkSession.read.format("doris")
.option("doris.table.identifier", "test_db.table1")
.option("doris.fenodes", "hadoop102:8030")
.option("user", "test")
.option("password", "test")
.load()
dorisSparkDF.show()
}
}
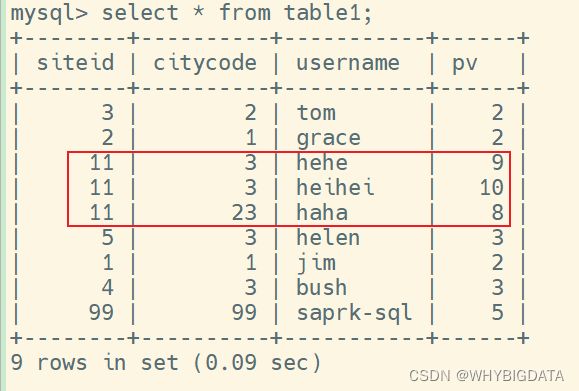
2.4.2 写入数据
运行结果:
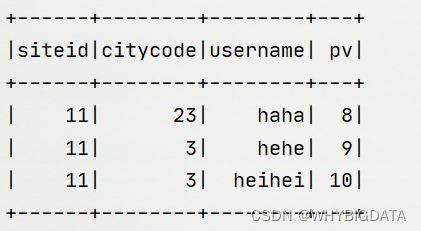
验证:
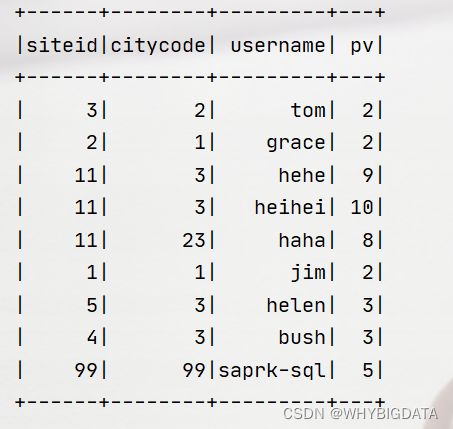
2.4.2 读取数据
运行结果:
2.5 RDD演示
RDD目前只支持读取数据
- 代码
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.SparkSession
object RDDDemo {
def main(args: Array[String]): Unit = {
//TODO 如果要打包提交集群执行,请注释掉
val sparkConf = new SparkConf().setAppName("RDDDemo").setMaster("local[2]")
val sc = new SparkContext(sparkConf)
// TODO 读取数据
import org.apache.doris.spark._
val dorisSparkRDD = sc.dorisRDD(
tableIdentifier = Some("test_db.table1"),
cfg = Some(Map(
"doris.fenodes" -> "node01:8030",
"doris.request.auth.user" -> "test",
"doris.request.auth.password" -> "test"
))
)
dorisSparkRDD.collect().foreach(println)
}
}
运行结果:

2.6 写入数据的其他方式
关于通过Saprk写入数据到Doris,还可以通过StructStreaming的方式,
- 官方示例
## stream sink(StructuredStreaming)
val kafkaSource = spark.readStream
.option("kafka.bootstrap.servers", "$YOUR_KAFKA_SERVERS")
.option("startingOffsets", "latest")
.option("subscribe", "$YOUR_KAFKA_TOPICS")
.format("kafka")
.load()
kafkaSource.selectExpr("CAST(key AS STRING)", "CAST(value as STRING)")
.writeStream
.format("doris")
.option("checkpointLocation", "$YOUR_CHECKPOINT_LOCATION")
.option("doris.table.identifier", "$YOUR_DORIS_DATABASE_NAME.$YOUR_DORIS_TABLE_NAME")
.option("doris.fenodes", "$YOUR_DORIS_FE_HOSTNAME:$YOUR_DORIS_FE_RESFUL_PORT")
.option("user", "$YOUR_DORIS_USERNAME")
.option("password", "$YOUR_DORIS_PASSWORD")
//其它选项
//指定你要写入的字段
.option("doris.write.fields","$YOUR_FIELDS_TO_WRITE")
.start()
.awaitTermination()
3. 配置项说明
3.1 通用配置项
| Key | Default Value | Comment |
|---|---|---|
| doris.fenodes | – | Doris FE http 地址,支持多个地址,使用逗号分隔 |
| doris.table.identifier | – | Doris 表名,如:db1.tbl1 |
| doris.request.retries | 3 | 向Doris发送请求的重试次数 |
| doris.request.connect.timeout.ms | 30000 | 向Doris发送请求的连接超时时间 |
| doris.request.read.timeout.ms | 30000 | 向Doris发送请求的读取超时时间 |
| doris.request.query.timeout.s | 3600 | 查询doris的超时时间,默认值为1小时,-1表示无超时限制 |
| doris.request.tablet.size | Integer.MAX_VALUE | 一个RDD Partition对应的Doris Tablet个数。 此数值设置越小,则会生成越多的Partition。从而提升Spark侧的并行度,但同时会对Doris造成更大的压力。 |
| doris.batch.size | 1024 | 一次从BE读取数据的最大行数。增大此数值可减少Spark与Doris之间建立连接的次数。 从而减轻网络延迟所带来的额外时间开销。 |
| doris.exec.mem.limit | 2147483648 | 单个查询的内存限制。默认为 2GB,单位为字节 |
| doris.deserialize.arrow.async | false | 是否支持异步转换Arrow格式到spark-doris-connector迭代所需的RowBatch |
| doris.deserialize.queue.size | 64 | 异步转换Arrow格式的内部处理队列,当doris.deserialize.arrow.async为true时生效 |
| doris.write.fields | – | 指定写入Doris表的字段或者字段顺序,多列之间使用逗号分隔。 默认写入时要按照Doris表字段顺序写入全部字段。 |
| sink.batch.size | 10000 | 单次写BE的最大行数 |
| sink.max-retries | 1 | 写BE失败之后的重试次数 |
| sink.properties.* | – | Stream Load 的导入参数。 例如: ‘sink.properties.column_separator’ = ', ’ |
| doris.sink.task.partition.size | – | Doris写入任务对应的 Partition 个数。Spark RDD 经过过滤等操作,最后写入的 Partition 数可能会比较大,但每个 Partition 对应的记录数比较少,导致写入频率增加和计算资源浪费。 此数值设置越小,可以降低 Doris 写入频率,减少 Doris 合并压力。该参数配合 doris.sink.task.use.repartition 使用。 |
| doris.sink.task.use.repartition | false | 是否采用 repartition 方式控制 Doris写入 Partition数。默认值为 false,采用 coalesce 方式控制(注意: 如果在写入之前没有 Spark action 算子,可能会导致整个计算并行度降低)。 如果设置为 true,则采用 repartition 方式(注意: 可设置最后 Partition 数,但会额外增加 shuffle 开销)。 |
3.2 SQL 和 Dataframe 专有配置
| Key | Default Value | Comment |
|---|---|---|
| user | – | 访问Doris的用户名 |
| password | – | 访问Doris的密码 |
| doris.filter.query.in.max.count | 100 | 谓词下推中,in表达式value列表元素最大数量。超过此数量,则in表达式条件过滤在Spark侧处理。 |
3.3 RDD 专有配置
| Key | Default Value | Comment |
|---|---|---|
| doris.request.auth.user | – | 访问Doris的用户名 |
| doris.request.auth.password | – | 访问Doris的密码 |
| doris.read.field | – | 读取Doris表的列名列表,多列之间使用逗号分隔 |
| doris.filter.query | – | 过滤读取数据的表达式,此表达式透传给Doris。Doris使用此表达式完成源端数据过滤。 |
3.4 Doris 和 Spark 列类型映射关系
| Doris Type | Spark Type |
|---|---|
| NULL_TYPE | DataTypes.NullType |
| BOOLEAN | DataTypes.BooleanType |
| TINYINT | DataTypes.ByteType |
| SMALLINT | DataTypes.ShortType |
| INT | DataTypes.IntegerType |
| BIGINT | DataTypes.LongType |
| FLOAT | DataTypes.FloatType |
| DOUBLE | DataTypes.DoubleType |
| DATE | DataTypes.StringType1 |
| DATETIME | DataTypes.StringType1 |
| BINARY | DataTypes.BinaryType |
| DECIMAL | DecimalType |
| CHAR | DataTypes.StringType |
| LARGEINT | DataTypes.StringType |
| VARCHAR | DataTypes.StringType |
| DECIMALV2 | DecimalType |
| TIME | DataTypes.DoubleType |
| HLL | Unsupported datatype |
Note:Connector中,将
DATE和DATETIME映射为String。由于Doris底层存储引擎处理逻辑,直接使用时间类型时,覆盖的时间范围无法满足需求。所以使用String类型直接返回对应的时间可读文本。
4. 使用 JDBC 的方式
这种方式是早期写法,
不推荐,原因是:Spark 无法感知Doris 的数据分布,会导致打到 Doris 的查询压力非常大。
- 代码:
import java.util.Properties
import org.apache.spark.SparkConf
import org.apache.spark.sql.{SaveMode, SparkSession}
object JDBCDemo {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("JDBCDemo").setMaster("local[2]")
val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
// TODO 写入数据
// import sparkSession.implicits._
// val mockDataDF = List(
// (21,23, "bj", 8),
// (21,13, "sh", 9),
// (21,31, "sz", 10)
// ).toDF("siteid", "citycode", "username","pv")
//
// val prop = new Properties()
// prop.setProperty("user", "test")
// prop.setProperty("password", "test")
//
// mockDataDF.write.mode(SaveMode.Append)
// .jdbc("jdbc:mysql://node01:9030/test_db", "table1", prop)
// TODO 读取数据
val df=sparkSession.read.format("jdbc")
.option("url","jdbc:mysql://node01:9030/test_db")
.option("user","test")
.option("password","test")
.option("dbtable","table1")
.load()
df.show()
}
}
- 写入数据
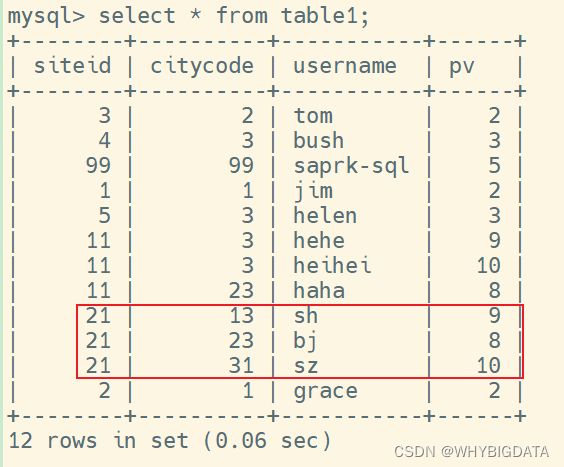
- 读取数据
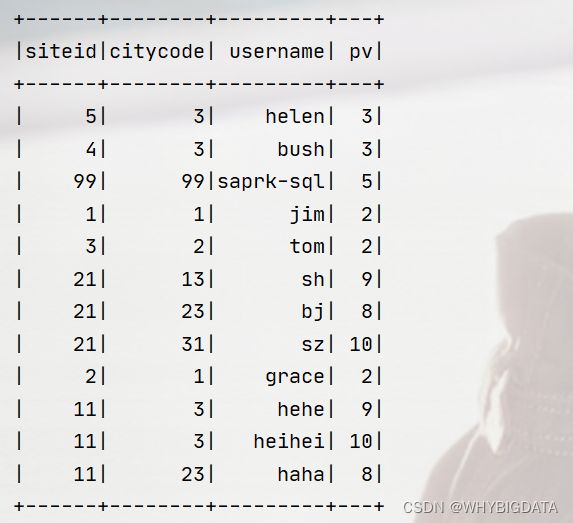
5. 其他集成系统
Doris还可以与Flink、DataX、MySQL、Logstash、ODBC外部表集成使用,可以直接参考官网
6. 参考资料
- https://doris.apache.org/zh-CN/docs/dev/ecosystem/spark-doris-connector
- https://9to5answer.com/java-lang-noclassdeffounderror-org-apache-spark-sql-sparksession
- https://github.com/apache/doris-spark-connector/issues/39