【SQL SERVER】递归查询
有示例数据,表名为SYS_Department
| id | departmentName | parentId | remark | isEnable | staffId |
| 2 | 总经理 | 1 | 总经理 | 1 | |
| 3 | 账务部 | 2 | 账务部 | 1 | 1006 |
| 4 | 技术部 | 2 | 技术部 | 1 | 1004 |
| 9 | 产品部 | 2 | 产品部 | 1 | 1005 |
| 10 | 市场部 | 2 | 市场部 | 1 | |
| 11 | 人事部 | 2 | 人事部 | 1 | 1013 |
| 5 | 测试部 | 4 | 测试部 | 1 | 1002 |
| 6 | 开发部 | 4 | 开发部 | 1 | 1003 |
| 7 | 设计部 | 4 | 设计部 | 1 | |
| 8 | 物联部 | 4 | 物联部 | 1 | |
| 12 | JAVA一部 | 6 | JAVA一部 | 1 | 1009 |
| 13 | JAVA二部 | 6 | JAVA二部 | 1 | |
| 14 | .NET部 | 6 | .NET部 | 1 | 1008 |
| 15 | 前端部 | 6 | 前端部 | 1 |
递归查询原理
SQL Server中的递归查询是通过CTE(表表达式)来实现。至少包含两个查询,第一个查询为定点成员,定点成员只是一个返回有效表的查询,用于递归的基础或定位点;第二个查询被称为递归成员,使该查询称为递归成员的是对CTE名称的递归引用是触发。在逻辑上可以将CTE名称的内部应用理解为前一个查询的结果集。
递归查询语法
with 子查询名称 查询字段列表 as --查询字段列表输入格式为([查询字段名1],[查询字段名2],...),也可用*代替,需要注意的是此处的查询字段列表中的字段与下方内容中定点成员与递归成员查询字段列表内容需一致
(
--定点成员
select 查询字段列表 from 查询表名 where 查询条件
union all
--递归成员
select 查询字段列表 from 查询表名 a inner join 子查询名称 on 递归条件 )
select 显示字段名 from 子查询名称已示例数据为例
--通过根节点向下查找该根节点下的子节点
with temp([id],[departmentName]) as
( select [id],[departmentName] from SYS_Department where id = 2
union all select a.[id],a.[departmentName] from SYS_Department a inner join temp on a.[parentId] = temp.[id] )
select * from temp
--通过子节点向上查找该子节点的根节点
with temp([id],[departmentName]) as
( select [id],[departmentName] from SYS_Department where id = 2
union all select a.[id],a.[departmentName] from SYS_Department a inner join temp on
--调换查询字段
a.[id] = temp.[parentId] )
select * from temp查询结果

不指定查询字段列表
--查询1
--不指定子查询查询字段列表
with temp as
(
--查询表中所有字段
select * from SYS_Department where id = 2
union all
--查询主表中所有字段(根据UNION ALL语法需与定点成员查询字段保持一致)
select a.* from SYS_Department a inner join temp on a.[parentId] = temp.[id] )
--显示表中所有字段
select * from temp
--查询2
--不指定子查询查询字段列表
with temp as
(
--查询表中所有字段
select * from SYS_Department where id = 2
union all
--查询主表中所有字段(根据UNION ALL语法需与定点成员查询字段保持一致)
select a.* from SYS_Department a inner join temp on a.[parentId] = temp.[id] )
--显示表中id字段
select id from temp查询结果1

查询结果2

总结:
以树的概念去理解查询原理可能相对比较容易一些,以下是以结果反推的个人理解:
关键字:
定点成员(示例语句中:select * from SYS_Department where id = 2)
递归成员(示例语句中:select a.* from SYS_Department a inner join temp on a.[parentId] = temp.[id])
拼接(使用UNION ALL)
SQL递归查询是以定点成员为查询起始点(即语句中的select * from SYS_Department where id = 2),第一次查询时取到定点成员的子节点(即示例数据中parentid=2的数据,可以将查询起始点理解为树的根节点),通过特定的顺序遍历取到的子节点(遍历顺序经测试为倒序遍历,即先遍历id=4的数据,再遍历id=3的数据),当该子节点下存在数据时(即已select a.* from SYS_Department a inner join temp on a.[parentId] = temp.[id]的查询结果不为NULL时)显示数据并继续遍历该节点,直至查询导的结果为空或达到最大的迭代次数(默认为100),最终将所有节点遍历完成并将遍历的结果以UNION ALL语句拼接输出结果集。
以示例数据为例,反推的查询流程以及数据如图所示:
1.第一次递归时(目前无法确定开始执行的顺序是先执行定点成员语句后递归还是获取到子节点后递归,猜测顺序为执行完定点成员SQL后进行第一次递归)获取拼接下图中
2.递归遍历通过定点成员获取到的子节点,先遍历id=11的节点,但该节点下获取的数据为空所以不拼接任何数据,id=10和9的同理,当遍历到id为4的节点时,获取拼接下图数据

3.递归遍历上图中获取到的节点,先遍历id=8的节点,但该节点下获取的数据为空所以不拼接任何数据,id=7和5的同理,当遍历到id为6的节点时,获取拼接下图数据
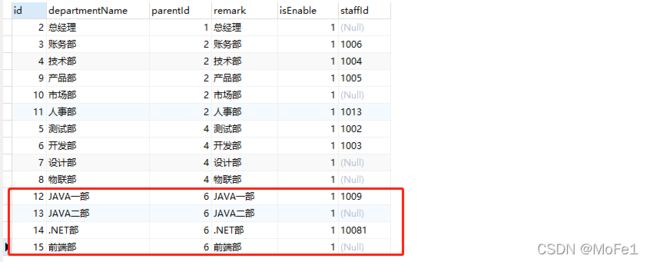
4.递归遍历上图中获取到的节点,先遍历id=15的节点,但该节点下获取的数据为空所以不拼接任何数据,id=14,13,12的节点同理
5.此时以id=4的节点为根节点的所有节点已遍历完成,继续递归遍历通过定点成员获取到的子节点,即遍历id=3的节点,但该节点下获取的数据为空所以不拼接任何数据,最终显示结果集如下图所示

原文参考:
WITH common_table_expression (Transact-SQL) | Microsoft Docs
Recursive Queries Using Common Table Expressions | Microsoft Docs
思路借鉴:SQL中的递归的用法_SQL数据库开发的博客-CSDN博客