日志分析系统可以实时收集、分析、监控日志并报警,当然也可以非实时的分析日志。splunk是功能强大且用起来最省心的,但是要收费,免费版有每天500M的限制,超过500M的日志就没法处理了。ELK系统是最常见的,缺点是配置麻烦一些,比较重量级。graylog是开源免费的,配置上要比ELK系统简单。综上,本文尝试容器方式搭建一套graylog系统,不做实时收集日志和报警的配置,只完成非实时被动接收网站日志,分析日志各项指标的功能。
docker官方镜像国内速度我觉得慢,改成国内镜像。新建文件daemon.json如下
vi /etc/docker/daemon.json
{
"registry-mirrors": ["https://registry.docker-cn.com"]
}也可以用网易镜像http://hub-mirror.c.163.com
配置完重启docker才能生效
#service docker restart拉取如下三个镜像
docker pull mongo:3
docker pull docker.elastic.co/elasticsearch/elasticsearch-oss:6.8.10
docker pull graylog/graylog:3.3不要急着按照网上的方法启动镜像,我开始docker启动elasticsearch,虽然显示启动成功,但过半分钟后偷偷退出,这导致graylog在浏览器打不开。最后通过查看容器启动时的日志,发现elasticsearch对于系统参数是有要求的,按如下修改。
在 /etc/sysctl.conf文件最后添加一行
vm.max_map_count=262144vi /etc/security/limits.conf
* - nofile 102400 修改完成后重启系统使变量生效。
docker启动elasticsearch时要加上参数
--ulimit nofile=65536:65536 --ulimit nproc=4096:4096,确保容器内环境满足要求,否则在docker pa -a命令下会看到exit(78)或exit(1)的容器异常退出错误。
查看容器启动报错最准确的方法是“docker logs -f 容器ID”这个命令,我们不加--ulimit 参数试试
[root@bogon ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
7e4a811093d9 docker.elastic.co/elasticsearch/elasticsearch-oss:6.8.10 "/usr/local/bin/dock 6 seconds ago Up 4 seconds 0.0.0.0:9200->9200/tcp, 0.0.0.0:9300->9300/tcp elasticsearch用上面的CONTAINER ID产看启动时的日志
[root@bogon ~]# docker logs -f 7e4a811093d9
最后会打印出
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
[2]: max number of threads [3869] for user [elasticsearch] is too low, increase to at least [4096]
[2020-08-27T06:10:25,888][INFO ][o.e.n.Node ] [WG6mVz4] stopping ...
[2020-08-27T06:10:25,903][INFO ][o.e.n.Node ] [WG6mVz4] stopped
[2020-08-27T06:10:25,903][INFO ][o.e.n.Node ] [WG6mVz4] closing ...
[2020-08-27T06:10:25,928][INFO ][o.e.n.Node ] [WG6mVz4] closed两行too low的提示就是容器退出的原因。
三个容器正确的启动命令如下
docker run --name mongo -d mongo:3
docker run --name elasticsearch \
-e "http.host=0.0.0.0" \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
--ulimit nofile=65536:65536 --ulimit nproc=4096:4096 \
-p 9200:9200 -p 9300:9300 \
-d docker.elastic.co/elasticsearch/elasticsearch-oss:6.8.10
docker run --name graylog --link mongo --link elasticsearch \
-p 9000:9000 -p 12201:12201 -p 1514:1514 -p 5555:5555 \
-v /home/graylog/geodata:/usr/share/graylog/log \
-e GRAYLOG_HTTP_EXTERNAL_URI="http://192.168.56.106:9000/" \
-d graylog/graylog:3.3mongo的启动没什么可说的。
elasticsearch的--ulimit必须加否则启动后退出,-p 9200:9200是管理端口,将来删除数据需要访问这个端口。
graylog 9000端口是系统界面,5555是开的tcp端口,用于被动接收日志数据的。
-v /home/graylog/geodata:/usr/share/graylog/log是把本地/home/graylog/geodata挂载到容器的/usr/share/graylog/log目录,我这么配置是为了让graylog能读到GeoLite2-City.mmdb地理信息数据库,这个库是把ip和地理位置对应起来了。本来想把它拷贝到容器里,但报错
[root@localhost graylog]# docker cp ./GeoLite2-City.mmdb 151960c2f33b:/usr/share/graylog/data/
Error: Path not specified说是要升级docker1.7到更高版本,不想升级,改成挂载方法了。如果不想挂载什么文件,-v这行参数可以去掉。
我是用命令“#docker exec -it graylog容器ID bash" 先进入容器,看到容器内/usr/share/graylog/log目录没什么东西,所以选择挂载到这个目录的。
地理数据用于显示访问网站的ip分布在哪个城市国家,还有世界地图的显示。需要在https://dev.maxmind.com/zh-ha...,麻烦的是这里需要注册。我下载的是GeoLite2-City_20200825.tar.gz,解压后有GeoLite2-City.mmdb,上传这个文件到Linux的/home/graylog/geodata目录,这个文件是需要挂载到容器,给graylog使用的。
不想注册请从下面链接下载
链接:https://pan.baidu.com/s/1Lovr...
niI66CkmA
提取码:bsmm
GRAYLOG_HTTP_EXTERNAL_URI的地址不要写127.0.0.1,这样如果在Linux的外部访问,虽然能通,但是网页是空白一片,要写Linux对外的ip地址,这样在外部浏览器打开才正常。
另外graylog的启动是依赖于mongo和elasticsearch的,等其它两个都成功启动,再启动graylog。
下面开始演示如果配置graylog系统,并且分析网站的Apache标准格式的日志。大概步骤如下
配置input->给input配置extractor->配置地理信息数据库->手动输入日志->分析日志。
浏览器输入http://192.168.56.106:9000/ 用户名和密码都是admin,登陆进graylog系统。
system->input,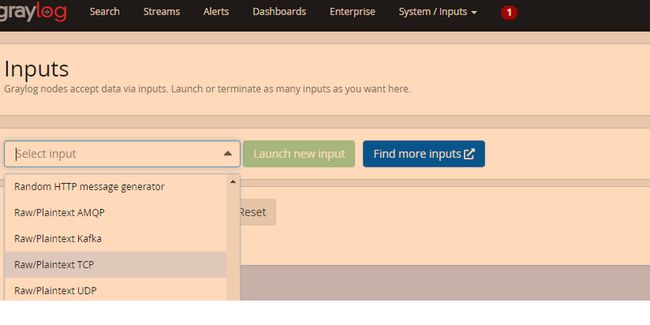
点击select input右侧的下拉箭头,出现下拉列表,选择raw/plaintext TCP

然后点击Lanch new input,Node下拉唯一选择给选上,Title随意起名,Port写5555,因为我们docker启动参数写的-p 5555:5555 这两个必须保持一致。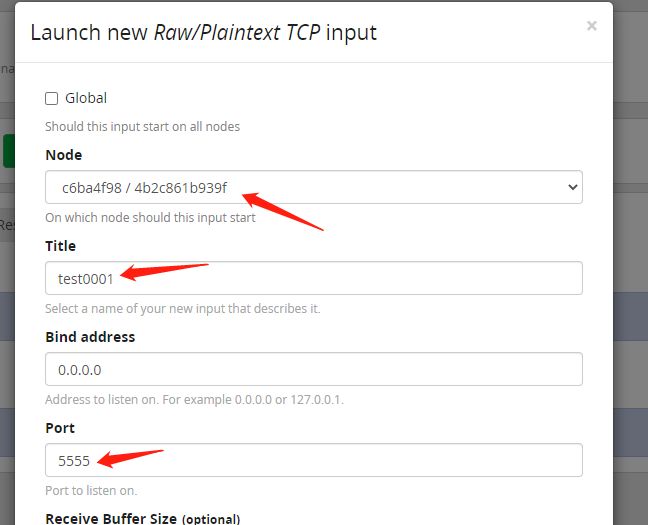
其它不用填点击下方SAVE按钮,会自动启动该input,可以看到local inputs下方增加了刚才的配置。其实现在用cat access.log | nc localhost 5555等命令给5555端口发送日志数据,数据就可以进入到graylog系统,并且可以进行简单的搜索了。但这种搜索是最基础的字符串匹配,价值不大。我们要分析日志的各项指标,并且生成图表,必须让系统能解析每条日志的各个field(字段或域值),例如clientip就是一个field,request也是一个field。要解析出field要给input配置extractor,点击Manager exactor。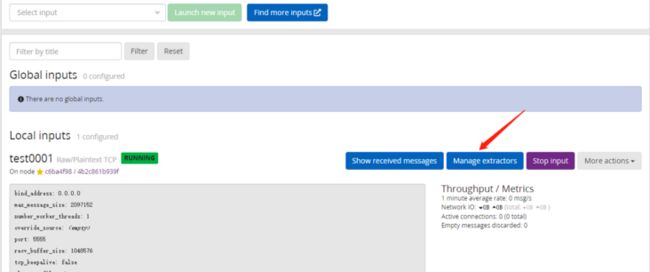
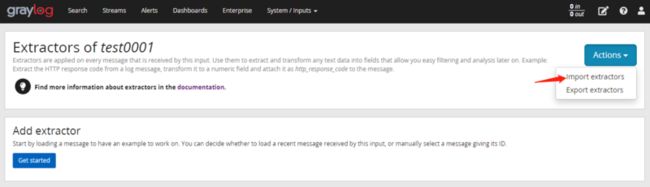
Extractors JSON里贴入下面内容
{
"extractors": [
{
"title": "commonapache",
"extractor_type": "grok",
"converters": [],
"order": 0,
"cursor_strategy": "copy",
"source_field": "message",
"target_field": "",
"extractor_config": {
"grok_pattern": "%{COMMONAPACHELOG}"
},
"condition_type": "none",
"condition_value": ""
}
],
"version": "3.3.5"
}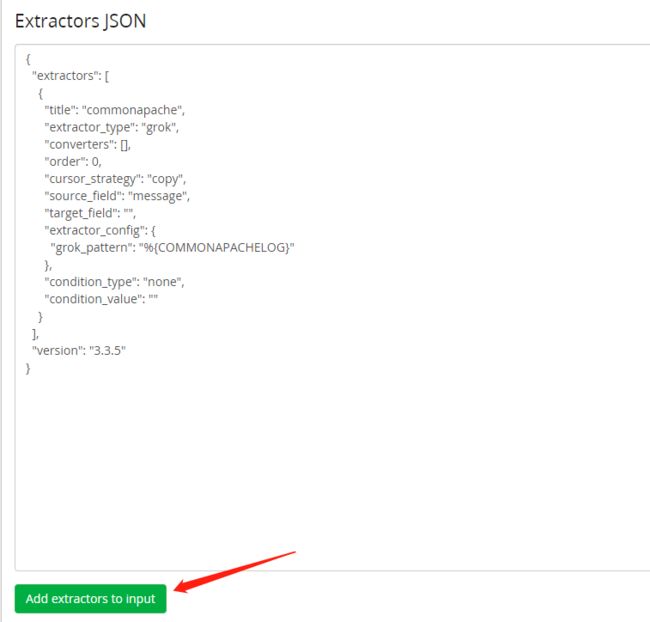
最后点击 add extrators to input,显示successful即可。
到这里已经可以正确解析日志得field了。但是如果我们想分析和地理位置相关的信息,还必须配置地理信息数据库,上文下载的mmdb文件。
system->configurations,最右下方有一项Geo-Location Processor,点击改项目下方的update按钮
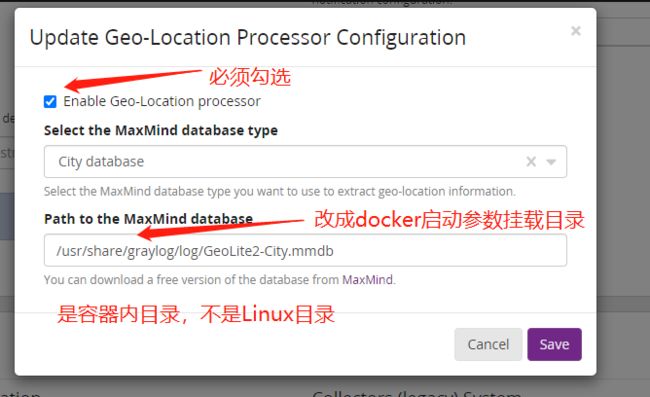
配置完成,点击save。
Configurations最上方Message Processors Configuration下方表格里要把GeoIP Resolver放在表格的最下方。点击表格下方的update 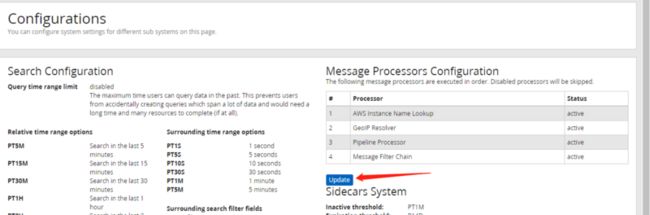
鼠标按住GeoIP Resolver往下方拖, 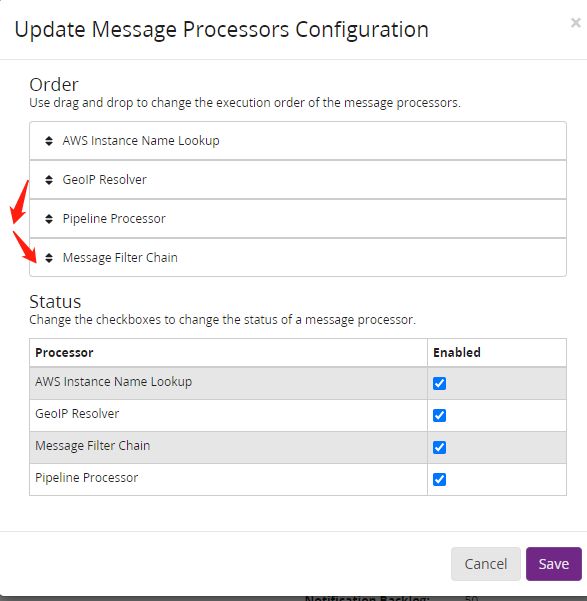
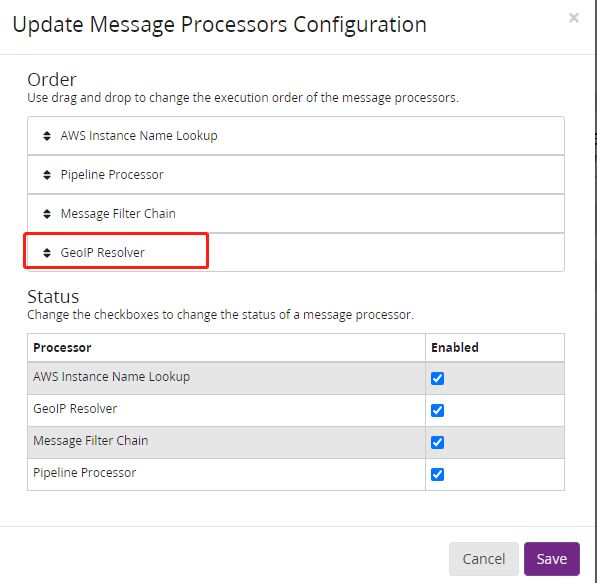
完成后点击save。Message Processors Configuration表格的GeoIP Resolver到了最下方。
下面是手动输入日志到input了,我将access2020-07-06.log放到了Linux目录下,在目录下执行
# cat access2020-07-06.log | head -n 10000 | nc localhost 5555命令是将log从头开始的10000行日志发送到本机的5555端口,由于graylog的input配置的也是5555端口,docker run graylog时命令参数也是-p 5555:5555,只要这三处保持一致,这个命令是一定能成功的。这里命令nc、ncat、netcat三个都能到达同样的效果。
导入完成后,选择graylog最上方的search选项 
上方的按钮是查询时间范围,这个时间是日志导入的时间,不是日志本身记录请求的时间,如果要查全部直接选择search in all messages
下方放大镜按钮就是搜索,后方可以添加搜索关键字,或者某个field的限制,有很多搜索语法非常方便,点击搜索后,不符合条件的日志记录会被去除。
下方All Messages就是符合条件的原始的日志结果。
如果想统计访问来源于哪些城市,点击左侧边栏最下的X(field)形按钮。选择clientip_cityname->show top values 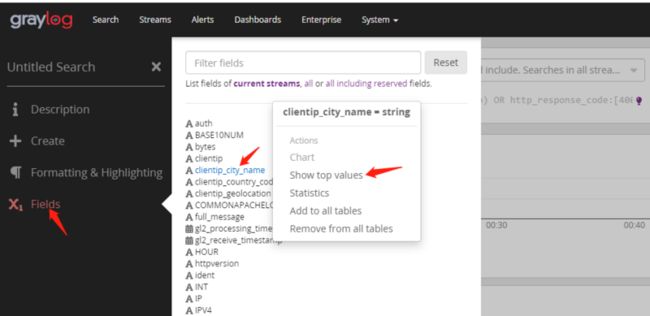
鼠标点击右侧灰色区域,回到主界面,访问来源的城市信息已经在列表里了。 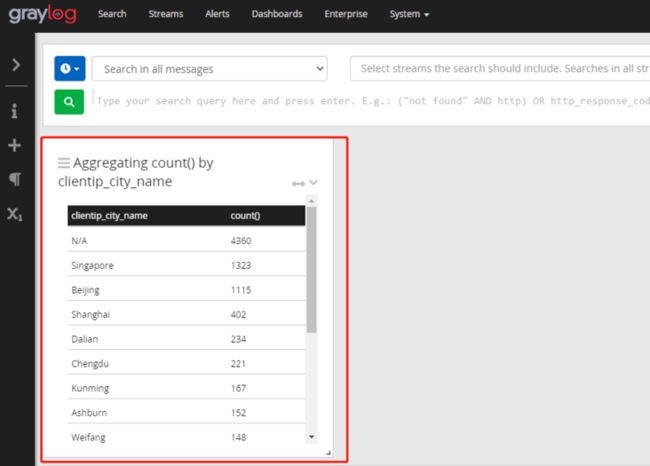
N/A表示的是有大量请求识别不出ip所在的城市,这有可能是我们的地理信息数据库不全不新,或者有些192 172这种内网地址的访问无法识别地区,这里不重点讨论了。如果要剔除N/A数据,只看可识别城市的分布,鼠标放到N/A右侧,会出现下拉菜单的箭头,点击箭头,选择exclude from results,N/A的数据就会去除,上面的搜索栏内也会自动增加这个筛选条件, 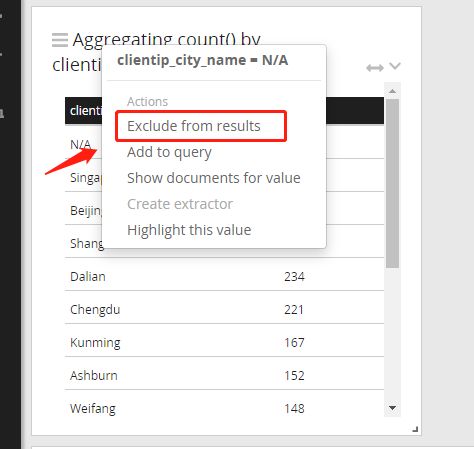
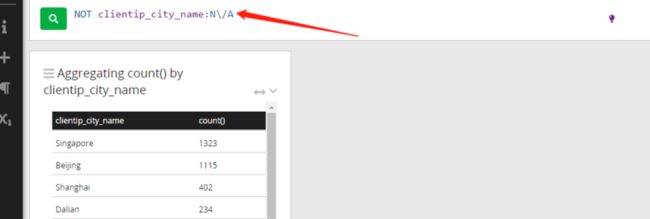
注意现在的统计是剔除了N/A的数据,数据范围实际是比全部日志范围缩小了的,这在实际应用中很有价值,很多情况下我们统计某些指标,就是要看某个局部范围的。下面我们看看访问来源城市的统计图,点击右上角下拉箭头,选择Edit 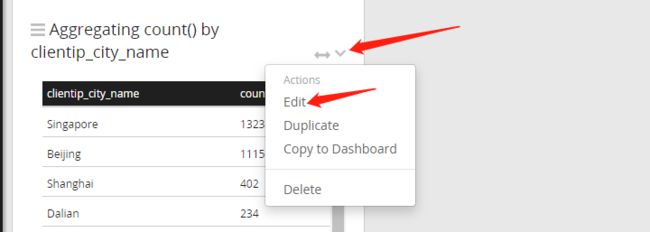
点击左侧Date Table处下拉菜单,可以看到柱状图、饼状图、散点图等都列在里面,选择哪个右侧就会出现那种统计的图表。 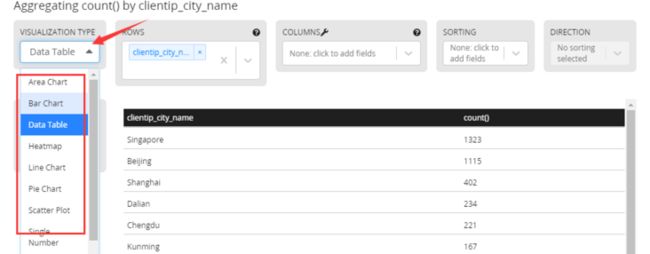
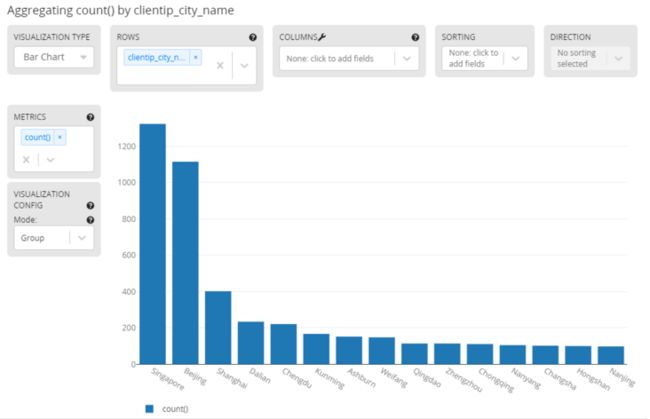
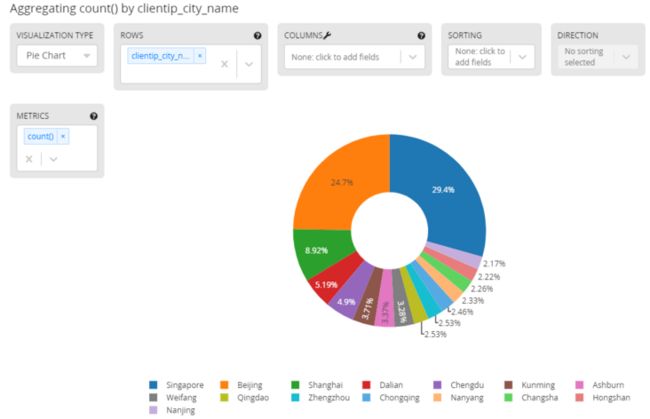
如果要展示访问来源在世界地图的分布,field菜单选择clientip_geolocation->show top values,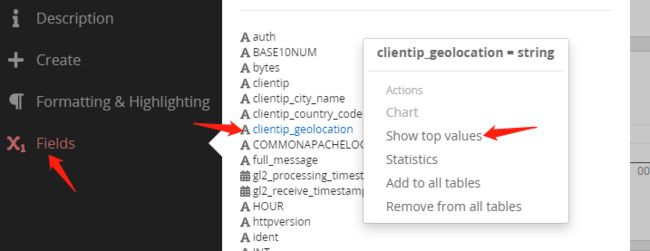
弹出的统计表格是经纬度坐标的访问次数。和上面图标一样,进入Date Tabel下拉菜单,最下方有world map 
选择会显示地图统计结果,放大调整位置如下图 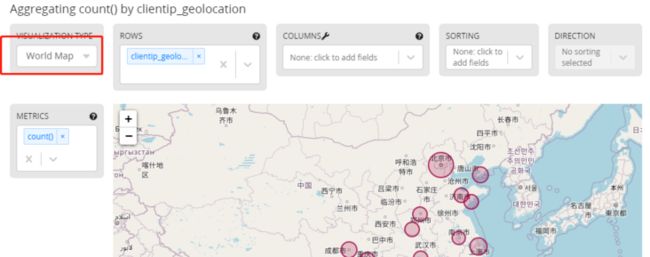
其它指标的统计如request分布,访问时间分布,在field下列表里都有,根据需要按上面同样操作。地理信息数据和标准的Apache日志可以结合生效,但一些自定义的extractor是否生效是不一定的。
番外篇
给input配置extractor,上面配置的是标准的Apache格式日志,如果日志格式是nginx或者自定义的怎么办呢?
graylog提供了给日志配置extractor的功能,假设我们配置完input,没有给input配置extractor,直接导入日志,按如下步骤配置extractor
input界面选择manager extractor 
getstarted 
load message会将刚进入的日志中的一条显示出来,点击message位置的select extractor type,表示我们要对message也就是整条信息配置extractor,下拉菜单选择Grok Pattern。如果日志进入时间比较久,load message无法展示日志,需要通过旁边message ID的标签来搜索日志,需要提供message ID和index,这两个参数在搜索界面下方all message里,随便点击一条日志数据,展开就可以看到。message ID形如4b282600-e8d2-11ea-b962-0242ac110008,index形如graylog_0。 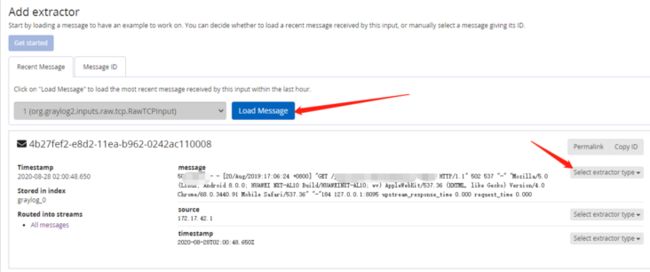
进入Extractor configuration,里面的pattern要自己填写,可以在右侧已有的pattern选择若干个组合,也可以自己定义,这里需要对grok和正则语法熟练了。我这里填写的是解析nginx原生日志的pattern格式,也是网上搜索的。填写完点击try against example,如果解析成功,下方会表格形式列出各个field对应该条日志的值。不成功就会报错,需要修改pattern直到不报错。 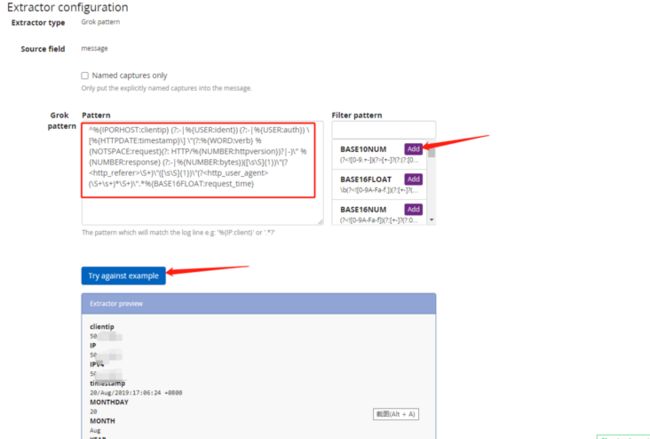
我的pattern如下
^%{IPORHOST:clientip} (?:-|%{USER:ident}) (?:-|%{USER:auth}) \[%{HTTPDATE:timestamp}\] \"(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|-)\" %{NUMBER:response} (?:-|%{NUMBER:bytes})([\s\S]{1})\"(?\S+)\"([\s\S]{1})\"(?(\S+\s+)*\S+)\".*%{BASE16FLOAT:request_time} 解析成功,Extractor title随便起个名,点击最下方create extractor
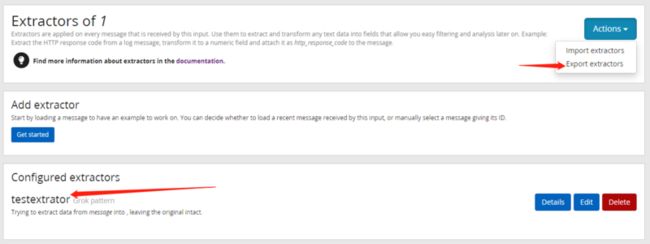
extractor已经成功添加给input了,上面的action有export extractor,点击可以以json格式展示刚才配置的extractor。 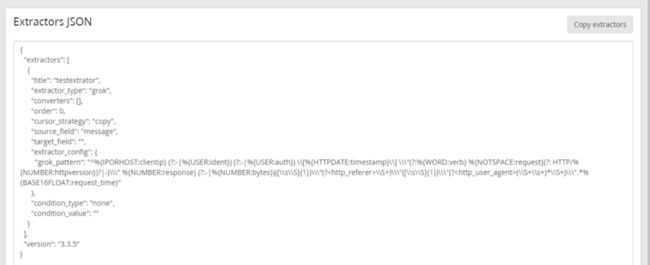
拷贝这个json文本,保存在本地,以后遇到nginx原生格式日志,直接通过上面的import extractor就直接使用,不用在配置grok pattern测试了。
需要说明的是一条日志记录有没有被解析为各个field,取决于日志进入系统时,有没有配置extractor。后配置的extractor对在之前的日志是起不到解析作用的。
如果配置完extractor,相同格式日志只进入系统一小部分,不要找其它原因了,原因就是pattern不对,虽然测试通过了,也配上了,但是还需要你重新修改pattern,如果pattern正确,符合格式的日志应该全都进入系统。
对于有些日志格式,配置grok pattern需要大量调试,graylog调试并不方便,官方grok调试器网站国内都打不开了。下面提供一个工具,可以直接粘贴日志到页面调试
链接:https://pan.baidu.com/s/1gWX4...
提取码:t6q6
windows的cmd直接java -jar GrokConstructor-0.1.0-SNAPSHOT-standalone.jar
然后浏览器访问127.0.0.1:8080,点击matcher,上面填写日志,下方填写grok pattern, 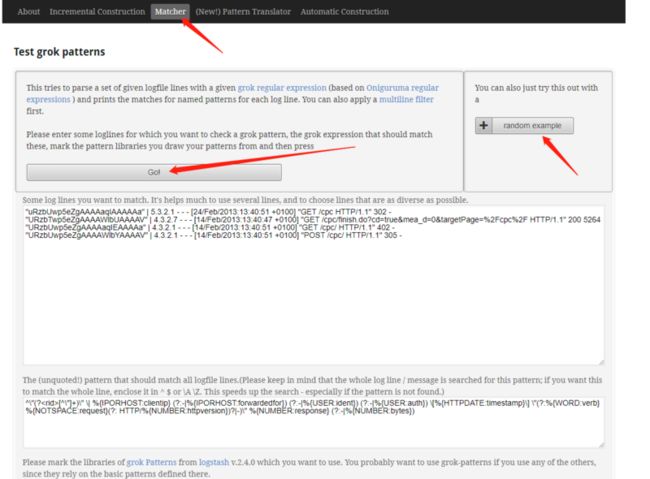
点击go,如果成功解析,会表格形式展示解析各个field结果。 
ramdom example给出了一些常见日志的例子和对应的pattern格式。
如果要重新配置graylog和输入数据,先
docker stop $(docker ps -a -q)停止所有容器,然后
docker rm $(docker ps -a -q)删除所有容器,然后docker run 按顺序启动三个容器,这样启动的容器是全新的,之前的配置和数据都会丢失。
上面对容器的操作麻烦,可以使用
curl -L https://github.com/docker/compose/releases/download/1.25.0/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose安装docker-compose,将启动参数等要求写到docker-compose.yml文件里,这种方式操作命令会很简单。