数据挖掘各流程中常用方法总结(二)
数据挖掘各流程中的常用方法(二)
- 数据预处理
-
- 特征选择
- 特征编码
-
- 分类型特征
-
- 独热编码(One-hot Encoder)
- 标签编码(label Encoder)
- 序列编码(Ordinal Encoder)
- 数值型特征
-
- 取整和缩放
- 分箱
- 特征标准化
-
- MaxMinScaler(线性归一化)
- StandScaler(一般标准化)
- RobustScaler(健壮标准化)
上一节我们讲到数据预处理中构造衍生特征部分的特征交互的简单原理。但是,通过这种方式我们会产生大量的新特征,这就造成很多特征事实上包含了大量重复的信息,在训练模型的时候很容易产生额外的性能消耗,其次也容易发生过拟合的现象。基于上述原因,我们应该对冗余特征进行过滤,在充分保留有效信息的基础上尽可能地简化特征,这就是特征选择的基本目标。
数据预处理
特征选择
接下来,我们基于银行客户满意度预测任务来研究特征选择的两个基本操作:1、删除与目标变量低相关的特征。2、删除彼此之间高度相关的特征(保留一个与TARGET相关性最高的特征)
def remove_corr_var(train=X_train,test=X_test,
target_threshold=10**-3,within_threshold=0.95):
#删除与目标变量相关性低的特征,删除彼此之间相关性高的特征(保留一个)
initial_feature = train.shape[1]
corr = train.drop('ID',axis=1).corr().abs()
corr_target = pd.DataFrame(corr['TARGET']).sort_values(by='TARGET')
print('corr_target')
print(corr_target)
feat_df = corr_target[corr_target['TARGET']<=target_threshold]
print('有 %i 个特征因为与目标变量TARGET的相关系数绝对值小于 %.3f而被删除' % (feat_df.shape[0],target_threshold))
print('deleting...')
for df in [train,test]:
df.drop(feat_df.index,axis=1,inplace=True)
print('已删除!')
#删除彼此之间相关性高的特征(保留一个与TARGET相关性最高的特征)
corr.sort_values(by='TARGET',ascending=False,inplace=True)#将相关矩阵每一行先按TARGET列降序排列
corr = corr.reindex(columns=corr.index)# 现在行按照与targt的相关性进行排序了,再将每一列按照行索引重排序
corr.drop('TARGET',axis=1,inplace=True)#删除target行
corr.drop('TARGET',axis=0,inplace=True)
corr.drop(feat_df.index,axis=1,inplace=True)#删除feat_df中特征在corr表corr表里的行
corr.drop(feat_df.index,inplace=True)
#pandas.where:根据条件来替换值,如果满足条件就保持原来的值,如果不满足就替换成别的值,默认替换为nan,当然也可以自己指定
#np.triu()获取相关矩阵的上三角,k代表对角线向何方向移动多少距离,正为上,负为下
upper = corr.where(np.triu(np.ones(corr.shape),k=1).astype(np.bool)) # 获取相关矩阵的上三角
column = [col for col in upper.columns if any(upper[col] > within_threshold)] # 获取与特征之一高度相关的所有列
print("有 %i 个特征与另一个特征高度相关且相关系数为 %.3f 及以上而被删除" % (len(column), within_threshold))
print("删除中.........")
for df in [train, test]:
df.drop(column, axis=1, inplace=True)
print("已删除!")
print("特征数从 %i 个变成 %i 个,其中 %i 个特征已被删除" %
(initial_feature, test.shape[1], initial_feature - test.shape[1]))
既然要删除低相关特征,我们如何定义“低相关”?一般地,我们基于特征与目标变量的相关系数选定一个阈值,低于阈值的就被认为是“低相关”。接下来我们来看操作,我们先计算除去ID列的数据集的相关系数矩阵,并取绝对值。接下来,我们按照target列进行降序排序。然后,我们进行了条件过滤,筛选出了相关矩阵中’TARGET’列小于低相关阈值的部分(feat_df),然后使用df.drop(feat_df.index,axis=1,inplace=True)按行删除。
接下来我们研究一下彼此高相关的特征如何删除,这里我们指定高相关的阈值是0.95。我们还是先按照与target的相关性进行排序,这里要注意,我们需要保证矩阵的结构不改变,即行和列的索引应该是一致的,因此我们对行索引重排之后,需要corr.reindex(column=corr.index)对列索引进行重排。后面我们分别删除TARGET列和feat_df.index行。由于相关矩阵是对称的,这里我们只需要取上半部分。对角线上的元素是特征本身,因此我们也不需要,将k设置为1,表示将对角线向上移动一行,空白部分我们使用NaN进行填充,最终得到的矩阵是这样的:
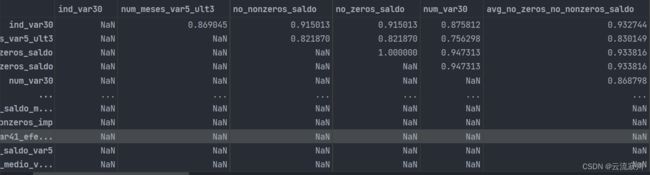
现在我们就可以按照条件进行过滤了,column = [col for col in upper.columns if any(upper[col] > within_threshold)]这里挑选出了所有值大于相关阈值的列,any()函数的意思是这一列所有的值都大于阈值才为True。结果如下:
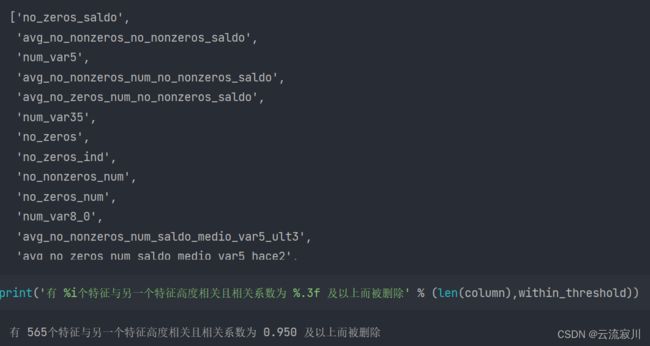
接下来我们按照列进行删除。最终特征由952个变成337个,删除了615个特征。在上面的案例中我们利用相关系数进行了简单的特征选择,当然特征选择的依据并不局限于此,我们可以在此基础上进行深入的探究。
特征编码
分类型特征
我们拿到的数据通常比较脏乱,可能会带有各种非数字特殊符号,比如中文。实际上机器学习模型需要的数据是数字型的,因为只有数字类型才能进行计算。因此,对于各种特殊的特征值,我们都需要对其进行相应的编码,也是量化的过程。
独热编码(One-hot Encoder)
独热编码即One-Hot编码,是一种将分类变量转换为几个二进制列的方法,其中1表示具有该属性特征,0表示不具有该属性特征。下面的例子中有一个特征Pet,它的取值类别为Cat、Dog、Trutle、Fish、Cat,在采用One-Hot编码后,会生成四个新的特征(新特征数量与类别数量一致),每一列新特征的取值限定在0,1中,并且每一行的四个新特征中,只能有一个取值为1,其他则全为0。如果该特征类别的数量非常多,则此方法会产生很多列,从而大大降低学习速度。
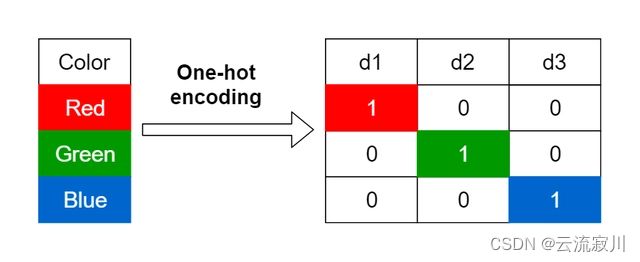
标签编码(label Encoder)
label-encoding就是用标签进行编码的意思,即我们给特征变量自定义数字标签,量化特征。假设特征取值有n个不同值,即n个类别,那么将按照特征数据的大小将其编码为0-(n-1)之间的整数。
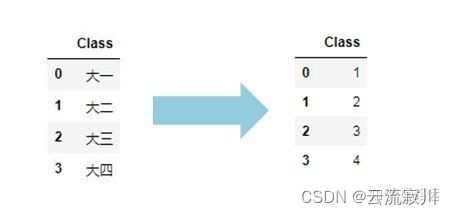
序列编码(Ordinal Encoder)
对于ordinal 变量,将1到N按顺序赋值给这个N类的定序变量。但是其实是将表征interval变量的方法应用到ordinal变量上。比如天气寒冷为1, 温暖为2, 炎热为3。 对于成绩这样含有小数的特征,在大多数情况下小数部分可能对标签并没有太大影响,可以对其取整,也可以保留大部分的信息,缩放亦是如此。 对数值型进行分箱,可以把连续型数据转换为离散型。 MinMaxScaler移动数据,使所有特征都刚好位于0到1之间。对于二维数据集来说,所有数据都包含在x轴0到1与y轴0到1组成的矩形中。 该方法适用于样本分布较为集中的时候,否则归一化结果不够稳定,归一化结果范围为0~1 该方法适用于样本原始分布近似于高斯分布(正态分布),归一化结果范围为0~1。确保每个特征的平均值为0、方差为1,使所有特征都位于同一量级。但这种缩放不能保证特征任何特定的最大值和最小值。 但是,如果数据集中依然存在一定的离群点,可能会影响特征的平均值和方差,影响标准化结果。在此种情况下,使用中位数和四分位数间距进行缩放会更有效。 工作原理与StandScaler类似,确保每个特征的统计属性都位于同一范围。但RobustScaler使用的是中位数和四分位数,而不是平均值和方差。这种方法能够获得更稳健的特征缩放结果。与StandardScaler缩放不同,异常值根本不包括在RobustScaler计算中。因此在包含异常值的数据集中,更有可能缩放到接近正态分布。 这样RobustScaler会忽略与其他点有很大不同的数据点(比如测量误差)。这些与众不同的数据点也叫异常值(outlier),可能会给其他缩放方法造成麻烦。 至此,我们将数据从探索性分析和数据预处理部分的常用方法介绍完毕。
类似于标签编码,但是是按照提前指定好的编号顺序对类别进行编码。如果我们以温度标尺为顺序,则顺序值应从“冷”到“非常热”。顺序编码会将值指定为 ( Cold(1)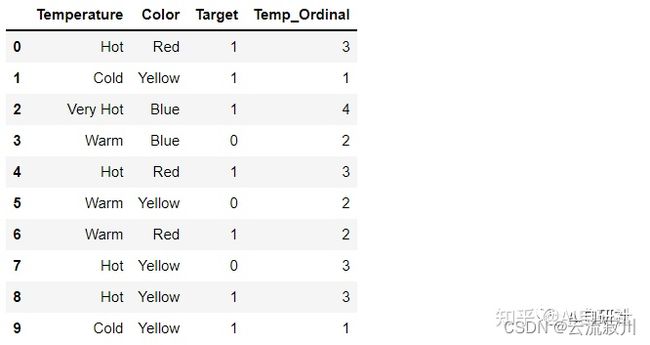
数值型特征
取整和缩放
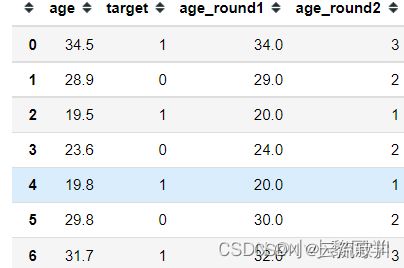
df = pd.DataFrame({
'age': [34.5, 28.9, 19.5, 23.6, 19.8, 29.8, 31.7],
'target': [1, 0, 1, 0, 1, 0, 1]
})
df['age_round1'] = df['age'].round()#取整
df['age_round2'] = (df['age'] / 10).astype(int)#缩放
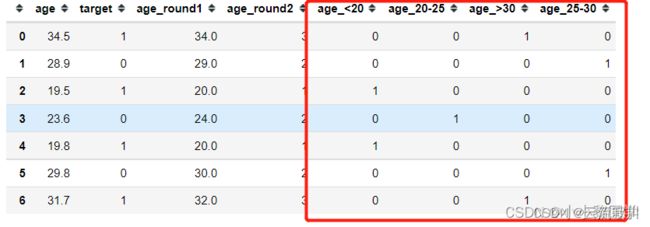
分箱
df['age_<20'] = (df['age'] <= 20).astype(int)
df['age_20-25'] = ((df['age'] > 20) & (df['age'] <=25)).astype(int)
df['age_25-30'] = ((df['age'] > 25) & (df['age'] <= 30)).astype(int)
df['age_>30'] = (df['age'] > 30).astype(int)
特征标准化
MaxMinScaler(线性归一化)
![]()
StandScaler(一般标准化)
![]()
我们在做数据预处理时通常会使用sklearn的StandardScaler来做特征的标准化,但如果你的数据中包含异常值,那么效果可能不好。RobustScaler(健壮标准化)
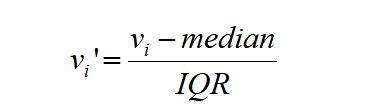
IQR:四分位距,第三四分位数(0.75)与第一四分位数(0.25)之间的距离