面向人群属性关系挖掘的数据可视化———基于美国人口adult数据集
目录
面向人群属性关系挖掘的数据可视化
一、课程设计内容及目的
二、总体设计
(一)题目需求分析
(二)系统整体流程图或组成框图
三、详细设计
(一)读取数据并导入需要的第三方库
(二)通过判断每个属性的取值范围来估计属性及其类型
(三)除去数据值前的空格,调整数据格式,并处理缺失数据
四、数据可视化展示及分析
(二)职业情况(Occupation)与收入情况(income)关系可视化及分析
(三)工作时长(hours-per-week)与收入情况(income)关系可视化及分析
(四)职业情况(Occupation)与性别(gender)关系可视化及分析
五、心得体会
面向人群属性关系挖掘的数据可视化
一、课程设计内容及目的
在这个信息大爆炸的时代,面对铺天盖地的数据,是哪种数据的表示形式更让人容易接受,是以文字形式,还是以图形化呢?“人类有五官,能通过 5 种渠道感受这个物质世界,那么为什么单单要青睐可视化的方式来传递信息呢?这是因为人类利用视觉获取的信息量巨大,人眼结合大脑构成了一台高带宽巨量视觉信号输入的并行处理器。具有超强模式识别能力,有超过 50% 功能用于视觉感知相关处理的大脑。大量视觉信息在潜意识阶段就被处理完成,人类对图像的处理速度比文本快得多。所以数据可视化是一种高带宽的信息交流方式。面对复杂数据,图形化表示更容易让人脑接受,方便挖掘数据中的规律和价值。
如果我们知道对收入高低起决定性的因素,或者哪些因素组合在一起有着能够增大收入的可能性,并将这些数据转化为人们通俗易懂,更容易接受的图形化的话,那么这样可以帮助很多人少走弯路,朝着正确的方向努力,早日达到目标。 就像许多传授给我们人生智慧的书籍一样,我们的目标是探寻一种影响人收入的条件体系并在以后的日子里继续对这套体系做出完善,以求能找到富裕的秘诀。
二、总体设计
(一)题目需求分析
通过对数据进行模型选择、数据导入、数据删除与清洗和数据转化等操作对数据进行简单的预处理,便于后面进行数据分析以及数据可视化的实施,再通过决策树、朴素贝叶斯模型述数据集进行预测
再然后对:受教育情况(education)与收入情况(income)是否存在关系?具有怎样的联系?职业情况(Occupation)与收入情况(income)是否存在关系?具有怎样的联系?职业情况(Occupation)与性别(gender)是否存在关系?具有怎样的联系?工作时长(hours-per-week)与收入情况(income)是否存在关系?具有怎样的联系?这些问题进行数据可视化,并加以分析
(二)系统整体流程图或组成框图

图2-1绘制整体流程图
三、详细设计
- 读取数据并导入需要的第三方库
需要用到的数据分析工具包有:numpy、pandas
需要用到的数据可视化工具包有:pyecharts、matplotlib、missingno、seaborn

图3-1读取数据
(二)通过判断每个属性的取值范围来估计属性及其类型
假设我们目前还不清楚数据集各个特征属性的详细信息(如名称、数据类型、数据量等),通过提取各个属性的取值范围(即非重复值)来估计该属性的一些情况。并得到如下结果:
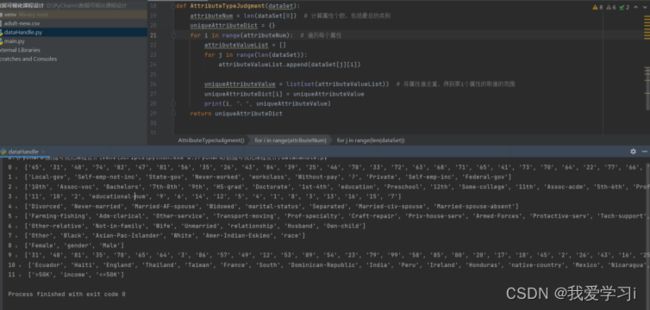
图3-2分析每个属性的取值范围
通过对每个属性所有非重复值的观察与分析,可以猜测到部分属性可能的名称,以及判断每一个属性的值的数据类型。再通过查找关于该数据集的介绍性的资料,得出该数据集各个属性名称及数据类型如下:
表3-1数据集各个属性名称及数据类型
| 属性 |
名称 |
属性类型 |
数据格式 |
| age |
年龄 |
离散属性 |
Int64 |
| workclass |
工作类型 |
标称属性 |
object |
| fnlwgt |
序号 |
连续属性 |
Int64 |
| education |
学历 |
标称属性 |
object |
| education_num |
受教育时间 |
连续属性 |
Int64 |
| marital_status |
婚姻状态 |
标称属性 |
object |
| occupation |
职业 |
标称属性 |
Object |
| relationship |
关系 |
标称属性 |
Object |
| race |
种族 |
标称属性 |
Object |
| sex |
性别 |
二元属性 |
object |
| capital_gain |
资本收益 |
连续属性 |
Int64 |
| capital_loss |
资本损失 |
连续属性 |
Int64 |
| hours_per_week |
每周工作小时数 |
离散属性 |
Int64 |
| native_country |
原籍 |
标称属性 |
object |
| 类别 |
名称 |
数据格式 |
|
| wage_class |
收入类别 |
Object |
(三)除去数据值前的空格,调整数据格式,并处理缺失数据
可以注意到数据集里面的每一个数据的数据类型都是字符串类型,并且开头存在一个空格,因此需要先去除每个数据前的空格,并且把每个特征数据里面的数据类型由字符串转换成其对应有的数据类型。得到数据集中数值型属性数据分布如下:

图3-3数据集中数值型属性数据分布
首先通过如下代码查看有数据缺失的属性:
#可视化查看特征属性缺失值
msno.matrix(newDataFrame, labels=True, fontsize=9) #矩阵图
plt.show()

图3-4缺失值可视化分布图
可以直观看出属性“workclass”、“occupation”、“native_country”存在缺失值,数据集中样本总数为32561个。由于这三个属性均是标称属性,所以可以采取用属性中出现次数最多的值来代替(即使用最有可能值来代替缺失值)。三个属性中出现次数最多的值分别为:“Private”、“Prof-specialty”、“United-States”。
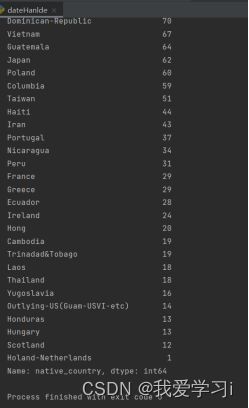
图3-5缺失值处理成功
四、数据可视化展示及分析
(一)受教育情况(education)与收入情况(income)关系可视化及分析
通过使用matplotlib对education和income数据进行可视化,可得到下图:
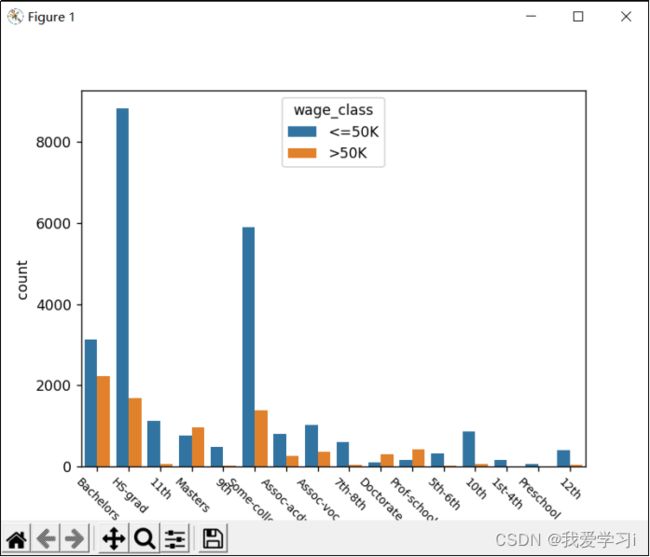
图4-1受教育情况与收入情况的关系可视化图形
使用到的代码如下:
# "education" 学历分析
print(list(dict(newDataFrame['education'].value_counts()).keys()))
sns.countplot('education', hue='wage_class', data=newDataFrame)
plt.xticks(fontsize=8, rotation=-45)
plt.show()
通过对数据和图形的分析可知,“education”是标称属性,取值有:'HS-grad', 'Some-college', 'Bachelors', 'Masters', 'Assoc-voc', '11th', 'Assoc-acdm', '10th', '7th-8th', 'Prof-school', '9th', '12th', 'Doctorate', '5th-6th', '1st-4th', 'Preschool'。从下图可以看出,学历越高收入>50K的占比越高,大部分人受过高等教育。
(二)职业情况(Occupation)与收入情况(income)关系可视化及分析
通过使用matplotlib对occupation和income数据可视化,可得到下图:
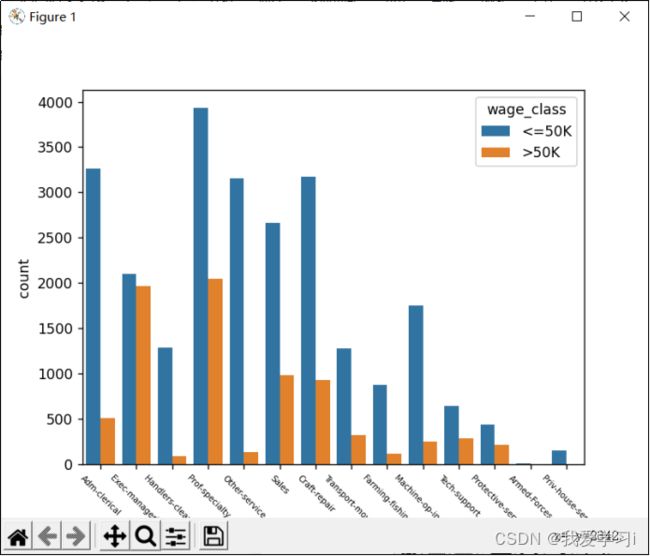
图4-2职业情况与收入情况关系可视化图形
从上图中可以直观看出高收入占比比较高的是执行管理(Exec-managerial)、专业教授(Prof-specialty),比较低的是清洁工(Handlers-cleaners)、养殖渔业(Farming-fishing)。高收入的职业往往是一些技术含量要高一些的工作或者是科研方面的。
使用到的代码如下:
# "occupation" 职业分析
print(list(dict(newDataFrame['occupation'].value_counts()).keys()))
sns.countplot('occupation', hue='wage_class', data=newDataFrame)
plt.xticks(fontsize=6, rotation=-45) #调整x轴标签字体大小
plt.show()
(三)工作时长(hours-per-week)与收入情况(income)关系可视化及分析
通过使用matplotlib对hours-per-week和income数据进行可视化,可得到下图:

图4-3工作时间与薪资关系柱状图

图4-4工作时长与收入情况关系可视化图形
“hours_per_week”是连续属性,因此也需要离散化。从每周工作小时数数据分布直方图上看,可以将每周工作小时数等距划分为3个层次:'shortTime', 'middleTime', 'longTime'。从划分后的图表上看,随着每周工作小时数的增加,高收入占比也在增高。
使用到的代码如下:
# "hours_per_week" 每周工作小时数分析
#查看每周工作小时数详情
print(newDataFrame['hours_per_week'].describe())
#查看每周工作小时数分布
plt.hist(newDataFrame['hours_per_week'], bins =10)
plt.show()
# 将每周工作小时数离散化,分为3个层次:短时、中时、长时
newDataFrame['hours_per_week'] = pd.cut(newDataFrame['hours_per_week'], bins=3, labels=['shortTime', 'middleTime', 'longTime'])
sns.countplot('hours_per_week', hue='wage_class', data=newDataFrame)
plt.show()
(四)职业情况(Occupation)与性别(gender)关系可视化及分析
通过使用Echarts对occupation和gender数据进行可视化,可得到下图:

图4-5各个职业中性别占比图(动态)
通过对职业数据中的性别分析,可视化后可以看出,大部分的职业还是存在男女差距较大的现象,在武装部队(Armed-Forces)这些特殊的职业中,男性的比例更是达到了100%,其他存在较大差距的还有维修工艺(Craft-repair)、清洁工(Handlers-cleaners)、养殖渔业(Farming-fishing)、运输行业(Transport-moving)、私人房屋服务(Priv-house-serv)、保卫工作(Protective-serv)这些比较特殊的行业;剩下的这些比较长的职业中的性别比例还是比较平均的。
五、心得体会
本次课程设计,使我对《数据可视化》这门课程有了更深⼊的理解。《数据可视化》是⼀门实践性较强的课程,为了学好这门课程,必须在掌握理论知识的同时,加强上机实践。
面向人群属性关系挖掘的数据可视化课程设计题⽬是一个非常好的题目,能有效的锻炼我们对知识的掌握程度,更好的提高对知识的理解以及动手能力。刚开始做这个程序的时候,感到完全⽆从下⼿,甚⾄让我觉得完成这次程序设计根本就是不可能的,于是开始查阅各种资料以及参考⽂献,之后便开始着⼿写程序,写完运⾏时有很多问题。特别是对数据处理的过程很多情况没有考虑周全,经常运⾏出现错误,但通过同学间的帮助最终基本解决问题。
在本课程设计中,我明⽩了理论与实际应⽤相结合的重要性,并提⾼了⾃⼰处理数据及将数据关系进行可视化的能⼒。培养了基本的、良好的程序设计技能以及数据分析能⼒。这次课程设计同样提⾼了我的综合运⽤所学知识的能⼒。并对Echart有了更深⼊的了解。
通过这段时间的课程设计,我认识到数据可视化是⼀门⽐较难的课程。需要一次一次的去尝试,一次次的试错,去探索,最终才能得到我们想要的结果。这次的课程设计培养了我实际分析问题、寻找问题的答案和动⼿能⼒,使我掌握了数据可视化的基本技能,提⾼了我面对问题善于分析,善于从多方面思考的能⼒。
由于时间和本身技术有限的问题,使得课程设计的完成并不是那么的完美。对于数据还可以进一步的去分析找出潜在的关系,但由于对算法的了解还不够足够的深入,所以也是非常的无能为力,所以需要我们不断地去学习掌握新的知识,才能更好的去解决我们遇到的每一个问题。另一方面由于时间的问题,不能更好的将这些可视化的图形进行选取与尝试,我认为只有实践了才能去发现这些可视化图形是否符合我们对数据可视化展示的要求,是否能展示出其中内涵的数据关系,所有在之后的空闲时间中,还需要投入大量的时间去处理和完善这些图形的处理。
总的来说,这次课程设计让我获益匪浅,对数据可视化也有了进⼀步的理解和认识。古语说的好:学⽆⽌境啊!