std::string源码探秘和性能分析
std::string源码探秘和性能分析
本文主要讲c++标准库的string的内部实现,以及对象拷贝的性能分析。
文中采用的源码版本为gcc-4.9,测试环境为centos7, x86_64,涉及到指针等数据类型的大小也假定是在64环境位下。
stl源码可以在gnu gcc的官方网站下载到:https://gcc.gnu.org/
头文件
vector头文件,该文件也可以直接在安装了g++的linux系统中找到。主要包含以下头内容:
// vector
#include
#include
#include
...
- 1
- 2
- 3
- 4
- 5
- 6
很奇怪,里面除了头文件,没有其他内容。我们都知道string是basic_string的一个实例化类,但在这里却没有看到它的定义,于是打开stringfwd.h,果然在这里定义了:
typedef basic_string string;
- 1
- 2
basic_string.h文件定义了basic_string模板类;
basic_string.tcc存放了一些模板类的成员的实现。c++里面模板的实现不能放在.cpp文件中,必须写在头文件中,如果模板函数实现较复杂,就会导致头文件臃肿和杂乱,这里可以看到stl里面方法,就是把较复杂的实现放在.tcc文件里面,然后当做头文件来包含,我们在写模板代码的时候也可以以此为参考。
内存布局
打开basic_string.h,首先可以看到很多英文注释,大致介绍了一下basic_string的特点和优势,其中有一段是这样的:
* A string looks like this:
*
* @code
* [_Rep]
* _M_length
* [basic_string] _M_capacity
* _M_dataplus _M_refcount
* _M_p ----------------> unnamed array of char_type
* @endcode
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
这里其实是介绍了basic_string的内存布局,从起始地址出开始,_M_length表示字符串的长度、_M_capacity是最大容量、_M_refcount是引用计数,_M_p指向实际的数据。值得注意的是引用计数,说明该版本的string实现采用了copy-on-write的方式来减少无意义的内存拷贝,后面还会介绍。整体内存布局如下:
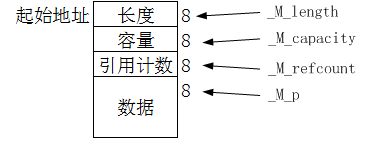
根据上图推测,一个空string,没有数据,内部开辟的内存应该是8*3=24字节,而sizeof(string)的值似乎为8*4=32字节,因为需要存储四个变量的值。而实际上并不是这样。
string对象的大小
c++对象的大小(sizeof)由非静态成员变量决定,静态成员变量和成员函数不算在内(对此有怀疑的自己可以写代码测试,在这里不过多解释)。通读basic_string.h,非静态成员变量只有一个:
mutable _Alloc_hider _M_dataplus;
- 1
- 2
_Alloc_hider是个结构体类型,其定义如下:
struct _Alloc_hider : _Alloc
{
_CharT* _M_p; // The actual data.
};
- 1
- 2
- 3
- 4
- 5
_Alloc是分配器,没有成员变量(源码请自行查看,在此不再列出),其对象大小(sizeof)为0,_M_p是指向实际数据的指针,当调用string::data()或者string::c_str()时返回的也是该值。因此sizeof(string)的大小为8,等于该指针的大小,而不是之前猜测的32字节。
奇怪的是,并没有看到之前“内存布局”里面提到的_M_length、_M_capacity、_M_refcount等成员。
string的构造
先看一下basic_string默认的构造函数:
basic_string()
#if _GLIBCXX_FULLY_DYNAMIC_STRING == 0
: _M_dataplus(_S_empty_rep()._M_refdata(), _Alloc()) { }
#else
: _M_dataplus(_S_construct(size_type(), _CharT(), _Alloc()), _Alloc()){ }
#endif
- 1
- 2
- 3
- 4
- 5
- 6
- 7
宏定义_GLIBCXX_FULLY_DYNAMIC_STRING决定了是否使用动态string,也就是不使用引用计数,而是总是拷贝内存,写段代码测试出该宏定义的值默认为0,也就是std::string默认是使用引用计数策略的,如果不想使用引用计数版的,可以在编译的时候把该宏定义设为1。
在这里我们主要关注于使用引用计数的代码,这个特性在高性能的服务端程序里面很重要。
那么焦点转到_M_dataplus成员的初始化:
_M_dataplus是_Alloc_hider类型,_Alloc_hider前文已经说过,是分配器Alloc的子类,含有唯一的成员变量_M_p, 指向string的数据部分。
_Alloc_hider构造函数的第一个参数是一个char*指针,由_S_construct函数返回,那么_S_construct又是做什么的?
_S_construct是理解string构造机制的关键,它有几个重载版本,主要作用就是根据输入的参数来构造一个string的内存区域,并返回指向该内存的指针,值得注意的是返回的指针并不是string内存空间的起始地址。这里调用的_S_construct版本为:
_CharT* basic_string<_CharT, _Traits, _Alloc>::
_S_construct(size_type __n, _CharT __c, const _Alloc& __a)
{
// Check for out_of_range and length_error exceptions.
_Rep* __r = _Rep::_S_create(__n, size_type(0), __a);
if (__n)
_M_assign(__r->_M_refdata(), __n, __c);
__r->_M_set_length_and_sharable(__n);
return __r->_M_refdata();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
该函数前两个参数__n和__c, 说明了它的作用是构造一个内存空间,并用__n个__c字符来初始化它,这正好也是string的一个构造函数的功能;_Rep::_S_create是用来构造一个空的string内存空间,并返回一个_Rep指针,_Rep的定义如下:
struct _Rep_base
{
size_type _M_length;
size_type _M_capacity;
_Atomic_word _M_refcount;
};
struct _Rep : _Rep_base
{
_CharT* _M_refdata() throw()
{ return reinterpret_cast<_CharT*>(this + 1); }
static _Rep* _S_create(size_type, size_type, const _Alloc&);
...
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
可以看到前文提到的几个变量_M_length, _M_capacity, _M_refcount, 它们并不是直接作为string对象的成员,而是通过_Rep来管理这些变量,这样string只需要保存一个_Rep指针即可,最大限度减小了string对象的大小,减小了对象拷贝的消耗。_M_refdata()用来获取指向数据部分的指针,this+1就是从起始地址开始向后加8*3个字节(_Atomic_word为int型占4个字节,代码请自行查看, 考虑字节对齐得出sizeof(_Rep)==24)。
_Rep::_S_create的代码如下,注释在代码里面:
template
typename basic_string<_CharT, _Traits, _Alloc>::_Rep*
basic_string<_CharT, _Traits, _Alloc>::_Rep::
_S_create(size_type __capacity, size_type __old_capacity,
const _Alloc& __alloc)
{
// 这里判断要创建的字符串大小是否超过最大长度,
// _S_max_size的值约等于用npos减去_Rep的大小再除以4, 也就是它的值取决于size_t类型的大小,
// 这里的__capacity和string的capacity()不一样,这里的__capacity就是指实际字符串的长度,而string的capacity()是根据它做一些调整得到的,下面会有代码。
if (__capacity > _S_max_size)
__throw_length_error(__N("basic_string::_S_create"));
const size_type __pagesize = 4096;
// 头部大小: 4*8=32字节, 这个头部并不是用来存储长度和引用计数那些信息的
// 准确的说是malloc头部, 即一次malloc的额外开销,是用来存储malloc空间的长度等信息的,后面计算页面对齐时需要用到
const size_type __malloc_header_size = 4 * sizeof(void*);
//
// 对于小内存增长,乘以2,优化内存开辟性能,此处优化与malloc机制有关。
if (__capacity > __old_capacity && __capacity < 2 * __old_capacity)
__capacity = 2 * __old_capacity;
// 初步计算需要开辟内存的大小
// __capacity + 1 的用意是多开辟一个单位内存以存储字符串结束符
// 至此, 我们知道了string既存储串长度, 也在串后面加'\0',理论上两者只要其一就可以决定一个字符串,这里实际上是以空间换时间。
size_type __size = (__capacity + 1) * sizeof(_CharT) + sizeof(_Rep);
// 页面对齐的调整,加上了malloc头部长度
const size_type __adj_size = __size + __malloc_header_size;
if (__adj_size > __pagesize && __capacity > __old_capacity)
{
// 页面对齐, 重新计算出size和capacity
const size_type __extra = __pagesize - __adj_size % __pagesize;
__capacity += __extra / sizeof(_CharT);
// 当超过最大长度时,自动截断。
// 虽然前面已经做过最大长度的判断,但后来又对capacity的调整使其在此仍有可能超过最大长度。
if (__capacity > _S_max_size)
__capacity = _S_max_size;
__size = (__capacity + 1) * sizeof(_CharT) + sizeof(_Rep);
}
// 开辟内存
void* __place = _Raw_bytes_alloc(__alloc).allocate(__size);
_Rep *__p = new (__place) _Rep;
__p->_M_capacity = __capacity;
// 开启并初始化引用计数为0。
// 前面说过的宏开关_GLIBCXX_FULLY_DYNAMIC_STRING, 也是控制是否使用饮用计数
// 但跟这里并不冲突,使用引用计数的string,有三种状态_M_refcount=-1,0, >0,
// 当调用写方法时,会把_M_refcount置为-1,此时会重新申请内存,构建对象,即copy-on-write中的write。
__p->_M_set_sharable();
return __p;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
copy-on-write机制
copy-on-write顾名思义,就是写时复制。大多数的string对象拷贝都是用于只读,每次都拷贝内存是没有必要的,而且也很消耗性能,这就有了写时复制机制,也就是把内存复制延迟到写操作时,请看如下代码:
string s = "Fuck the code.";
string s1 = s; // 读操作,不实际拷贝内存
cout << s1 << endl; // 读操作,不实际拷贝内存
s1 += "I want it."; // 写操作,拷贝内存
- 1
- 2
- 3
- 4
- 5
copy-on-write是怎么实现的呢?
- 首先,要实现写时复制。对象拷贝的时候浅拷贝,即只复制地址指针,在所有的写操作里面重新开辟空间并拷贝内存,在新的内存空间做修改;
- 其次,多对象共享一段内存,必然涉及到内存的释放时机,就需要一个引用计数,当引用计数减为0时释放内存;
- 最后,要满足多线程安全性。c++要求所有内建类型具有相同级别的线程安全性,即多线程读同一对象时是安全的,多线程写同一类型的不同对象时时安全的。第一个条件很容易理解。第二个条件似乎有点多此一举,既然是不同对象,多线程读写都应该是安全的吧?对于int、float等类型确实如此,但是对于带引用计数的string则不然,因为不同的string对象可能共享同一个引用计数,而write操作会修改该引用计数,如果不加任何保护,必然会造成多线程不一致性。要解决这个问题很简单,引用计数用原子操作即可,加互斥锁当然也可以,但效率会低很多。
来看一下basic_string的拷贝构造函数:
template
basic_string<_CharT, _Traits, _Alloc>::
basic_string(const basic_string& __str)
: _M_dataplus(__str._M_rep()->_M_grab(_Alloc(__str.get_allocator()),
__str.get_allocator()),
__str.get_allocator())
{ }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这里只有成员_M_dataplus的初始化,理解这段代码的关键在于_M_grab函数:
_CharT*
_M_grab(const _Alloc& __alloc1, const _Alloc& __alloc2)
{
return (!_M_is_leaked() && __alloc1 == __alloc2)
? _M_refcopy() : _M_clone(__alloc1);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
_M_is_leaked()判断是否是leak状态,前文已经提到过,string对象的_M_refcount有三个值:
- -1 :没有引用。当调用写操作,但尚未copy内存时,状态为此;
- 0 :引用对象的个数为1。独立构造对象时,初始状态为此;
- n>0 : 引用对象的个数为n+1。拷贝构造或赋值时,状态为此;
leak状态就是_M_refcount==-1的状态,当为非leak状态且分配器相同时只返回引用,否则拷贝内存。因此使_M_refcount==-1的操作都是写操作,都是能引起内存拷贝的操作,都是比较消耗性能的操作,比如reserve(), +=, operator[]的非const调用等,要特别注意的是substr()也会拷贝内存,尽管看起来是只读的。
再看一下basic_string的析构逻辑:
if (__gnu_cxx::__exchange_and_add_dispatch(&this->_M_refcount,
-1) <= 0)
{
_GLIBCXX_SYNCHRONIZATION_HAPPENS_AFTER(&this->_M_refcount);
_M_destroy(__a);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
if括号里面是对引用计数做原子操作,当引用计数小于等于0时,释放内存。
copy-on-write存在的问题
copy-on-write固然减少了不必要的内存拷贝,但也并非完美,若使用不当,反而不能提高性能。
1、可能增加内存拷贝的情况:string的写操作流程是,先进行内存的拷贝,然后对原string的引用计数减一,这就存在一个问题,比如A和B共享同一段内存,在多线程环境下同时对A和B进行写操作,可能会有如下序列:A写操作,A拷贝内存,B写操作,B拷贝内存,A对引用计数减一,B对引用计数减一,加上初始的一次构造总共三次内存申请,如果使用全拷贝的string,只会发生两次内存申请。假如先对引用计数减一,再决定是否拷贝内存行不行?
2、一些不经意操作可能导致意外的内存拷贝。比如以下代码:
string s1("test for copy");
string s2(s1);
cout << s2 << endl; // shared
cout << s2[1] << endl; // leaked,此处会重新申请并拷贝内存
- 1
- 2
- 3
- 4
- 5
operator[]有两个重载版本,const和非const版本,当调用非const版本的operator[]时,会造成内存拷贝。那么什么时候会调用const版本,什么时候会调用非const版本?上述代码虽然是只读的,但是gcc并不会调用const版的operator[]。调用哪个版本取决于string对象是否是const,所以好的编程习惯应该是“在const的场景下使用const”。
类似的操作的还有at(), begin(), end()等, 非const的string调用这些方法都会导致额外的内存申请和拷贝。
3、不规范的操作可能导致数据不一致:
string s1("abc");
const string s2(s1);
char *p = const_cast(&s2[0]); // 不规范的操作
*p = 'x';
cout << "s1=" << s1 << endl;
cout << "s2=" << s2 << endl;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
以上代码输出:
s1=xabc
s2=xabc
- 1
- 2
- 3
对s2的操作竟然改变了s1的内容!在函数调用关系复杂的代码里面,这种bug会很难发现。
关于不规范的操作:利用const_cast把const类型的数据转换成非const,不是在不得已的情况下不要这样做。 绕过对象提供的方法来操作对象也是不提倡的。
结语
曾经为了减少string的内存拷贝使用了shared_ptr,现在看来完全是画蛇添足,不仅没有提高性能,反而增加了性能消耗。
string的copy-on-write并不是c++标准规定的,因此不同平台,不同版本会有不同实现。在gcc-4.*版本,都是用的类似于本文介绍的机制。
copy-on-write的设计初衷是为了减少不必要的内存申请拷贝,而它也确实做到了,但仍然不够完美,存在一些陷阱。gcc5 已经放弃了copy-on-write的设计,采用短字符串优化的方案,即对长度小于16的字符串,作为string对象的一部分,直接从栈空间开辟内存,而且c++11中std::move的引入也使这种copy-on-write的优化不再必要。