汇编学习教程:灵活寻址(三)
引言:
在上篇博文中,我们学习了一个灵活寻址方式:[bx+idata],该方式我们可以形象的将它类比成高级语言中的一维数组,其中idata可以看成是数组的起始地址,bx看成是数组的下标。
除此之外,我们还介绍了bx的两个小伙伴:si和di。它们两个主要应用于数据拷贝复制场景,打破了 [bx+idata] 形式所存在的局限性。
那么,接下来在本篇博文中,我们将会继续学习其他形式的灵活寻址,si、di 又会和bx碰撞出什么样的火花呢,就让我们马上开始本篇的学习吧~
[bx+si]、[bx+di]
好朋友就要一起玩耍,bx当然也能和si、di搭配来实现灵活寻址~由于 [bx+si] 和 [bx+di] 这两个功能相同,下面我们就主要以 [bx+si] 来作为讲解。
[bx+si]
和 [bx+idata] 意思相近的是,[bx+si] 同样表示为一个内存单元,该内存单元的偏移地址则为:bx中的值加上si中的值。
那么指令:mov ax,[bx+si] 含义如下:
将段地址为DS,偏移地址为bx中的值加上si中的值,下的字单元数据送入AX寄存器中。
数学化描述为:ax = ((ds)*16+(bx)+(si))
由于bx、si都能够在程序运行中动态变化,所以 [bx+si] 的寻址形式要比 [bx+idata] 更加灵活。那么 [bx+si] 它灵活体现在什么地方呢?
对于 [bx+idata] ,我们将它与高级语言中的一维数组进行对比,而 [bx+si] 则可以形象地看成高级语言中的二维数组,有了行列之分。
如下部分代码示例:
data segment
db '11111111'
db '22222222'
db '33333333'
data ends我们在数据段中开辟了三块内存空间,每块内存空间大小都为8个字节大小,如果我们将这三块内存空间当作一个整体来看,便可以看作是一个 3X8 大小的二维数组,每一个内存空间代表二维数组中的每一行,内存空间中的每一个字节单元代表二维数组中的每一列。
如果我们对上述定义好的数据段空间进行寻址,该如何来做?
答案就是使用 [bx+si] 的形式进行寻址。我们使用bx来定位每一行,使用si来定位每一列。bx记录每一行的起始地址,si记录每一行中的偏移地址。在上述数据段中,bx分别记录每行的起始地址:0H,8H,10H,si则负责 0H~7H进行偏移。
汇编中的双重循环
当我们学习到 [bx+si] 的时候,也就意味着从现在开始我们进入了双重循环的世界。对于我们开发人员来说,双重循环可谓是屡见不鲜了,有时候一个复杂的业务场景可能会嵌套三重、四重甚至多重循环。在汇编开发中,也不例外,照样存在着多重循环。
我们的学习就从简单的双重开始。双重循环即在一个循环内又存在一个循环,分为外层循环和内层循环。对于一维数组来说,我们只需要一个循环便可以完成它的遍历,而对于二维数组,我们则需要一个双重循环才能够完成遍历,外层循环遍历每一行,内层循环遍历每一行中的元素。
[bx+si] 正是用来实现双重循环来设计的,由于bx、si两个寄存器均可动态变化,所以我们得以在同时修改这两个寄存器值完成二维的空间寻址。在双重循环中,外层循环控制bx寄存器完成行的遍历访问,内层循环则控制si寄存器完成每行中列的遍历访问。
为了加深我们的理解,还是需要通过实际动手操作才行。
编码实现
下面我们编写汇编,使用 [bx+si] 来对上述的案例中数据进行遍历访问,代码如下:
assume cs:code,ds:data
data segment
db '11111111'
db '22222222'
db '33333333'
data ends
code segment
start:
mov ax,data
mov ds,ax ; 设置数据段
mov bx,0 ; 行偏移从0开始
mov ax,0 ; 列偏移从0开始
mov cx,3 ; 设置外层循环为3次(共3行)
s:mov si,0 ; 每一行中列的偏移从0开始
mov di,cx ; 保存当前外层循环剩余的循环次数(重要!)
mov cx,8 ; 设置内层循环为8次(共8列)
s1:mov al,[bx+si] ; 读取一个字节的数据到AL寄存器中
add si,1 ; 列偏移加1
loop s1 ; 判断内层循环是否结束
add bx,8 ; 行偏移加8,移到下一行开始
mov cx,di ; 还原外层循环的当前循环次数
loop s ; 判断外层循环是否结束
mov ax,4c00H
int 21H
code ends
end start汇编语言中的双重循环结构,唯一难点就是CX的设置。因为CX里面存放的是循环次数,循环会有很多个,但是CX都有一个,它们共用同一个CX,所以多个循环下CX中的值就会被不断覆盖掉,这样就导致循环发生异常程序崩溃。
那么在多层循环下,就需要注意CX值被覆盖问题。上层循环的循环次数被下层循环的循环次数覆盖,这是无可奈何的事情,重点就是当退出下层循环后,我们该如何恢复上层循环的当前循环次数。
使用di
在上面的代码中,我们采用了di寄存器和cx寄存器相互配合,来恢复上层循环的循环次数。
代码中我们可以看到,当进入第一层循环后,指令:mov di,cx,作用就是记录此时外层循环的循环次数,然后便设置CX为内层循环的循环次数;退出内层循环后,指令:mov cx,di,作用便是恢复此前记录的外层循环次数,以便下面外层循环的 loop 指令进行判断处理。
di寄存器在代码中承担的角色就好比是一个临时储存站,临时将外层循环的循环次数储存起来,在需要的时候再释放出来,这样保证了双重循环的程序执行正确稳定。
那么是不是就意味着使用di寄存器来辅助完成多重循环是最优选择呢?
答案当然不是。我们来分析这样的问题:如果此时我们面临的是一个三重循环该怎么办?di记录了第一层循环,那么第二层循环谁来记录呢?你可能会说,还有别的空闲的寄存器呀,例如dx什么的。那好就算你找到了一个空闲寄存器来记录第二层循环次数,那如果这是四层循环呢?第三层循环次数又要派哪个寄存器呢?如果五层、六层、甚至更多层的循环呢?
寄存器是非常有限的,且寄存器资源是非常的宝贵,不可能说把所有的寄存器都派出去辅助多重循环。在上面的编程实例中,它只是个双重循环,所以使用di寄存器来当临时辅助是没什么问题,在面临很多层的多重循环下,那么则完全不能使用一个寄存器来当记录员!
使用栈
既然使用一个寄存器并不是可靠的解决方案,那么我们就需要另寻他处来当作临时储存站。我们思来想去,很快就意识到可以使用栈来解决问题。而栈的设计实际上就是用来解决此问题。栈的存在使得开发人员可以方便的存储一些标志数据,记录程序的运行轨迹。
那么接下来,我们来优化上述代码,使用栈来存储cx寄存器值,代替此前的ds寄存器。代码如下:
assume cs:code,ds:data,ss:stack
data segment
db '11111111'
db '22222222'
db '33333333'
data ends
stack segment ; 定义栈段
dw 0,0,0,0,0,0,0,0 ; 栈空间初始化16个字节空间
stack ends ; 栈段结束
code segment
start:
mov ax,data
mov ds,ax
mov ax,stack
mov ss,ax ; 设置栈段
mov sp,16 ; 设置栈顶指针指向栈底
mov bx,0
mov ax,0
mov cx,3
s:mov si,0
push cx ; 将此时外层循环数送入栈
mov cx,8
s1:mov al,[bx+si]
add si,1
loop s1
add bx,8
pop cx ; 将此时外层循环数出栈
loop s
mov ax,4c00H
int 21H
code ends
end start优化后代码如上。首先我们先定义一个16个字节空间大小的栈段,然后设置SS和SP,在之前保存和释放外层循环CX的位置分别替换成进栈和出栈,这样使用栈我们就可以实现一个多重循环。
我们同样可以实现一个三层循环,格式如下:
mov cx,xxx
s:
push cx
mov cx,xxx
s1:
push cx
mov cx,xxx
s2:
具体逻辑
loop s2
pop cx
loop s1
pop cx
loop s上述格式展示了一个三层循环结构实现,如果是一个更多层的四层、五层循环,则只需嵌套增加push、pop 指令即可。
现在我们对其进行总结:
1、push指令在进入内层循环之前使用,用来保存当前外层循环的剩余循环次数
2、pop指令在退出内层循环后、外层循环Lopp指令前,使用,用与恢复当前外层循环的剩余循环次数
3、push、pop是成对出现
4、一定要注意push、pop指令调用位置,避免程序执行错误
编程实例
我们接下来通过编程案例来进一步学习灵活寻址。
编程示例:
assume cs:code,ds:data
data segment
db '1. file '
db '2. edit '
db '3. search '
db '4. view '
db '5. options '
db '6. help '
data ends
code segment
start:
code ends
end start题目:编程实现将data段中每一个单词的头一个字母改为大写。
我们首先可以看到这类似于二维数组,那么存在一个循环需要访问到每一行,是不是还需要第二个循环?答案是不需要,因为我们只需要访问到每一行中的第四列数据即可,不需要对每一行进行遍历,所以就不存在第二个循环。
那么该如何访问到每一行中的第四列数据呢?我们可以看到,每一行中的偏移都是固定的数值,为4,所以我们使用 [bx+idata] 形式便可进行访问。那么最终实现代码如下:
assume cs:code,ds:data
data segment
db '1. file '
db '2. edit '
db '3. search '
db '4. view '
db '5. options '
db '6. help '
data ends
code segment
start:
mov ax,data
mov ds,ax ; 设置数据段
mov cx,6 ; 共6行,循环6次
mov bx,0 ; 偏移从0开始
s:
mov al,[bx+3] ; 读取当前行中第4列的字节到AL寄存器中
and al,5FH ; 进行And运算,转为大写字母,将结果放入AL寄存器中
mov [bx+3],al ; 将AL寄存器中的数据放入当前行中第4列的字节下
add bx,16 ; 偏移加16,移到下一行
loop s ; 判断循环是否结束
mov ax,4c00H
int 21H
code ends
end start在上述代码中,通过 [bx+idata] 的形式直接定位到需要操作的英文字符,然后bx偏移移到下一行继续循环,通过一个循环的方式便达到了所需效果。
我们将上述代码编译链接,在Debug中运行一下:
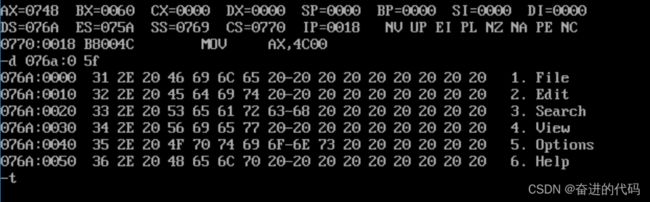
如图所示实现题目要求。
示例2
编程示例:
assume cs:code,ds:data
data segment
db 'ibm '
db 'dec '
db 'doc '
db 'vax '
data ends题目:编程实现将data段中每一个单词都改为大写字母。
根据题目要求,我们发现每一行中需要操作的字母为3个,偏移范围为 0~2,那么就不能使用 [bx+idata] 形式来做,则需要使用我们上述讲述的 [bx+si]形式来完成。
还是老样子,bx用来定位每一行,则si用来定位每一行中的偏移。如此一来,则需要使用双重循环才能完成内存寻址了。双重循环的实现我们上面已经讲述的很清晰了,那么本题目编写代码如下:
assume cs:code,ds:data,ss:stack
data segment
db 'ibm '
db 'dec '
db 'doc '
db 'vax '
data ends
stack segment
dw 0,0,0,0,0,0,0,0
stack ends
code segment
start:
mov ax,data
mov ds,ax ; 设置数据段
mov ax,stack
mov ss,ax ; 设置栈段
mov sp,16 ; 设置栈底
mov cx,4 ; 共4行,设置外层循环4次
mov bx,0 ; 行偏移从0开始
s:
push cx ; 将当前外层循环剩余次数入栈
mov cx,3 ; 一行中共操作3个字节,设置内层循环3次
mov si,0 ; 列偏移从0开始
s1:
mov al,[bx+si] ; 读取一个字节的数据到AL寄存器中
and al,5FH ; 进行与运算,将其转成大写字母
mov [bx+si],al ; 将结果放到原字节内存地址处
add si,1 ; 列偏移加1
loop s1 ; 判断一行中的字母是否全部操作完毕
pop cx ; 将当前外层循环次数出栈到CX寄存器中
add bx,16 ; 行偏移加16,移到下一行
loop s ; 判断所有行是否操作完毕
mov ax,4c00H
int 21H
code ends
end start我们将上述代码编译连接,在Debug中运行,结果如下:
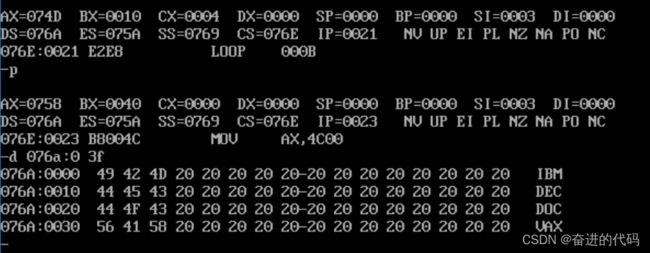
如图所示,我们实现了题目编程要求。
本篇结束语
在本篇博文中,我们主要学习了 [bx+si] 这种灵活寻址形式,与此配合的则是汇编中的双重循环实现,还有栈在多重循环中的使用。
下篇博文中,我们将会继续学习探讨其他的灵活寻址实现。