处理过多SQL Server PAGEIOLATCH_SH等待类型
One of the most common wait type seen on SQL Server and definitely one that causes a lot of troubles to less experienced database administrators is the PAGEIOLATCH_SH wait type. This is one of those wait types that clearly indicates one thing, but which background and potential causes are much subtler and may lead to erroneous conclusions and worse, incorrect solutions.
PAGEIOLATCH_SH等待类型是SQL Server上最常见的等待类型之一,并且肯定给经验不足的数据库管理员造成很多麻烦的一种。 这是一种清楚地表明一件事的等待类型,但是哪些背景和潜在原因很微妙,并可能导致错误的结论和更糟糕,不正确的解决方案.
The Microsoft definition of this wait type is:
Microsoft对这种等待类型的定义是:
Occurs when a task is waiting on a latch for a buffer that is in an I/O request. The latch request is in Shared mode.
Long waits may indicate problems with the disk subsystem.
当任务在闩锁上等待I / O请求中的缓冲区时发生。 闩锁请求处于共享模式。 长时间等待可能表明磁盘子系统有问题。
To make this simple to understand, lets explain this in an example. When the data pages are requested from the buffer cache by one or multiple sessions, but those data pages are not available in the buffer cache, SQL Server will have to allocate a buffer page for each one in the buffer and it will create the PAGEIOLATCH_SH on the buffer. At the same time, while the page is moved from the physical disk to a buffer cache (a physical I/O operation) SQL Server will create PAGEIOLATCH_EX wait type. Once the page is moved to a buffer cache, since the issued PAGEIOLATCH_SH is still active and the pages can be read from the buffer cache.
为了使这一点易于理解,让我们在一个示例中进行解释。 当一个或多个会话从缓冲区高速缓存中请求数据页,但这些数据页在缓冲区高速缓存中不可用时,SQL Server将必须为缓冲区中的每个页面分配一个缓冲区页面,并在上创建PAGEIOLATCH_SH缓冲区。 同时,在将页面从物理磁盘读取到缓冲区缓存(物理I / O操作)时,SQL Server将创建PAGEIOLATCH_EX等待类型。 将页面移至缓冲区高速缓存后,由于发出的PAGEIOLATCH_SH仍处于活动状态,因此可以从缓冲区高速缓存中读取页面。
Page latches are actually light locks that are not configurable, placed by SQL Server internal processes as a way of managing access to the memory buffer. Pahe latches are placed every time that SQL Server has to physically read data from the memory buffer to a hard drive or from hard drive to the memory buffer and the thread must wait until this completes causing the PAGEIOLATCH_XX waits. The moment the requested data pages became available after the I/O reading completes, the thread will get requested data and will continue with execution. So obviously, it is normal to encounter some PAGEIOLATCH_SH waits.
页锁实际上是不可配置的轻锁,由SQL Server内部进程放置,以管理对内存缓冲区的访问。 每当SQL Server必须从内存缓冲区向硬盘驱动器或从硬盘驱动器向内存缓冲区物理读取数据时,都会放置Pahe闩锁,并且线程必须等待直到完成,从而导致PAGEIOLATCH_XX等待。 I / O读取完成后,请求的数据页可用时,线程将获取请求的数据并继续执行。 所以很明显,遇到一些PAGEIOLATCH_SH等待是正常的。
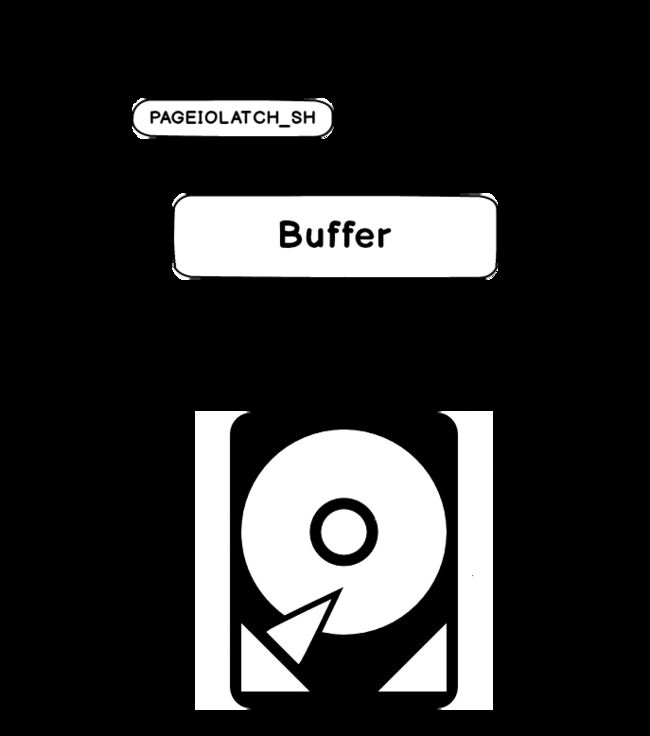
So it is clear that the PAGE IOLATCH_SH is directly related to the I/O subsystem, but does this actually mean that in case of excessive PAGE IOLATCH _SH, the I/O subsystem is always the primary/only root cause of the trouble?
因此,很明显PAGE IOLATCH_SH与I / O子系统直接相关,但这是否真的意味着在发生过多PAGE IOLATCH _SH的情况下,I / O子系统始终是问题的主要/唯一根源?
In short, the answer is no. The high PAGEIOLATCH_SH, even though it indicates the pressure is on the I/O subsystem, doesn’t necessary mean that I/O subsystem is a bottleneck per se, but it could also mean that I/O subsystem cannot cope with the excessive I/O imposed to it.
简而言之,答案是否定的。 PAGEIOLATCH_SH较高,即使它表示I / O子系统承受着压力,也不一定意味着I / O子系统本身就是一个瓶颈,但这也可能意味着I / O子系统无法应对过多的I / O强加给它。
To understand this better, let’s dive deeper into the causes of high PAGEIOLATCH_SH which will allow better understanding of this wait type, but will also allow better handling of situations when PAGEIOLATCH_SH is prevalent wait type in SQL Server.
为了更好地理解这一点,让我们更深入地研究导致PAGEIOLATCH_SH高的原因,这将有助于更好地了解此等待类型,但也可以更好地处理PAGEIOLATCH_SH是SQL Server中普遍的等待类型的情况。
-
I/O subsystem has a problem or is misconfigured
I / O子系统有问题或配置错误
-
Logical/physical drive misconception
逻辑/物理驱动器误解
-
Network issues/network latency
网络问题/网络延迟
-
Overloaded I/O subsystem by another processes that are producing the high I/O activity
I / O子系统重载了另一个正在产生高I / O活动的进程
-
Memory pressure
记忆压力
-
Synchronous Mirroring and AlwaysOn AG
同步镜像和AlwaysOn AG
-
Bad index management
不良索引管理
I / O子系统有问题或配置错误 (I/O subsystem has a problem or is misconfigured)
The PAGEIOLATCH_SH could indicate a problem with the I/O subsystem, i.e. problem with the disk. It is often possible that faulty disk does not trigger the monitoring system and in fact the disc issues could be very tricky, as disk could experience various issues which are not black and white (work/doesn’t work). Also the drives that are part of the RAID system could be even more trickier to detect considering the RAID own ability to deal with errors. In such cases, checking the S.M.A.R.T. (Self-Monitoring, Analysis and Reporting Technology) log should be the first step. In situations when the SMART log indicates a possible error or even an imminent drive failure, this could be the actual root cause of the excessive PAGEIOLATCH_SH.
PAGEIOLATCH_SH可能表示I / O子系统有问题,即磁盘有问题。 有故障的磁盘通常可能不会触发监视系统,并且实际上磁盘问题可能非常棘手,因为磁盘可能会遇到各种非黑白问题(工作/不工作)。 考虑到RAID自身的错误处理能力,作为RAID系统一部分的驱动器甚至可能更加难以检测。 在这种情况下,检查SMART(自我监控,分析和报告技术)日志应该是第一步。 在SMART日志指示可能的错误甚至驱动器即将发生故障的情况下,这可能是PAGEIOLATCH_SH过多的实际根本原因。
For those with RAID controllers, testing the RAID hardware/software for malfunctions or errors is also recommended.
对于具有RAID控制器的用户,还建议测试RAID硬件/软件是否存在故障或错误。
Another issue, very often overlooked is heavily fragmented disk. It’s not rare that defragmenting the disk subsystem resolve the I/O issue
另一个经常被忽视的问题是磁盘碎片过多。 对磁盘子系统进行碎片整理可以解决I / O问题,这种情况并不罕见。
逻辑/物理驱动器误解 (Logical/physical drive misconception)
A misconception in using the physical and logical drive is often the cause of a slow and problematic I/O subsystem. Quite often users are distributing a different part of the systems (OS, swap file, SQL Server data files, backups etc.) to a different disk partitions (C:, D:, E:, F: etc.) in order to load balance the I/O subsystem which is completely fine and recommended. But there is often misconceptions between load balancing using physical and logical disk drives. The following use case will help in understanding the problem and a provide potential solution
使用物理和逻辑驱动器时的错误观念通常是导致I / O子系统缓慢且有问题的原因。 用户经常将系统的不同部分(操作系统,交换文件,SQL Server数据文件,备份等)分发到不同的磁盘分区(C:,D:,E:,F:等)以进行加载平衡完全推荐的I / O子系统。 但是,使用物理磁盘驱动器和逻辑磁盘驱动器进行负载平衡之间常常会产生误解。 以下用例将有助于理解问题并提供潜在的解决方案
RAID arrays with multiple discs are quite common in larger organizations. In the following example, the RAID 5 array with 4 hard drives will be taken as an example. The RAID array is further divided into 3 partitions C:, D: and E:
带有多个磁盘的RAID阵列在大型组织中非常普遍。 在以下示例中,将以具有4个硬盘驱动器的RAID 5阵列为例。 RAID阵列进一步分为3个分区C:,D:和E:
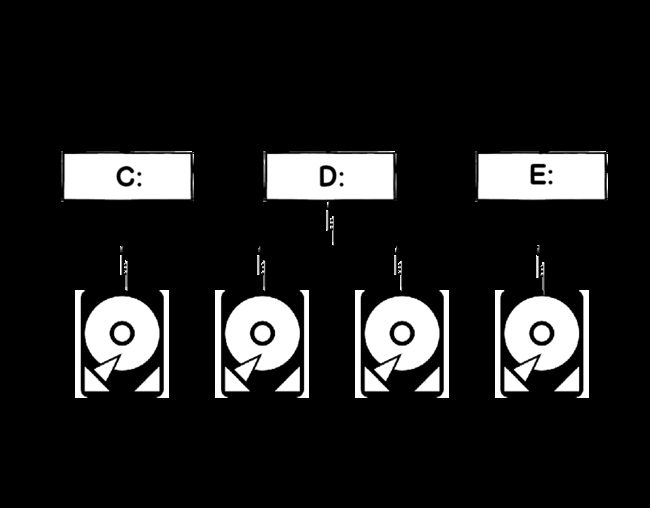
What must be clear here is that those partitions are actually logical, not physical partitions, as they share the same raid array and thus the same four physical disks – logically split RAID 5 array into 3 partitions. The RAID array for an operating system represent the single disk drive and it is not possible for OS to distribute specific data to a specific physical drive. In such scenario, OS, the page/swap file, SQL Server data files and tempDB are share same physical RAID array, namely the same physical drives. In such configurations, the different parts of the software systems are putting the pressure on each other, but also the different parts of the same software can conflict with each other (I.e. different SQL Server processes might be heavily dependent on I/O and thus conflicting to each other. In such a scenario, it is very possible to encounter excessive PAGEIOLATCH_SH as different SQL Server processes as well as different applications and OS processes could severely affect the performance of the I/O subsystem causing the slow transfer of data pages from disk to a buffer pool.
这里必须要清楚的是,这些分区实际上是逻辑分区,而不是物理分区,因为它们共享相同的RAID阵列,因此共享相同的四个物理磁盘–逻辑上将RAID 5阵列划分为3个分区。 操作系统的RAID阵列代表单个磁盘驱动器,并且OS不可能将特定的数据分发到特定的物理驱动器。 在这种情况下,操作系统,页面/交换文件,SQL Server数据文件和tempDB共享相同的物理RAID阵列,即相同的物理驱动器。 在这样的配置中,软件系统的不同部分彼此施加压力,但是同一软件的不同部分也可能彼此冲突(即,不同SQL Server进程可能严重依赖于I / O,因此发生冲突在这种情况下,很可能会遇到过多的PAGEIOLATCH_SH,因为不同SQL Server进程以及不同的应用程序和OS进程可能严重影响I / O子系统的性能,从而导致从磁盘的数据页传输缓慢到缓冲池。
The principles of the RAID system itself will not be explained here any deeper, as it is not of particular interest for understanding the main problem
RAID系统本身的原理在此不再赘述,因为它对于理解主要问题没有特别的意义。
So instead of having partitions distributed across the same drives, it is actually important having the physical hard drives that will be used for distributing the different parts of the software to ensure the proper load balance of the I/O subsystem
因此,重要的是要拥有物理硬盘驱动器,以用于分配软件的不同部分,以确保I / O子系统的适当负载平衡,而不是在同一驱动器上分配分区,这实际上很重要
The recommended scenario would be to have enough physical hard drives/RAIDs for distribution of critical parts of the software. The most widely used and recommended scenario would be the following
推荐的方案是具有足够的物理硬盘驱动器/ RAID,以分发软件的关键部分。 最广泛使用和推荐的方案如下
Set the Operating system on a dedicated RAID 1 array as minimum (one physical drive is also acceptable but risky solution)
将专用RAID 1阵列上的操作系统设置为最低(一个物理驱动器也可以接受,但风险较大的解决方案)
Set the swap file to a dedicated hard drive. No RAID is required here
将交换文件设置为专用硬盘。 此处不需要RAID
Set TempDB on a dedicated RAID 1 array as minimum. Again, one physical drive is acceptable, but it can pose the risk. TempDB will be recreated on every SQL Server restart, and if there are some SQL Server uptime requirements that consider rarely restarting SQL Server that RAID 1 option should be the first choice
至少在专用RAID 1阵列上设置TempDB。 同样,一个物理驱动器是可以接受的,但可能带来风险。 将在每次重新启动SQL Server时重新创建TempDB,并且如果有一些SQL Server正常运行时间要求,而很少考虑重新启动SQL Server,则应首选RAID 1选项。
Use the RAID 5 partition for the SQL Server data files. Storing the backups on the same RAID array is OK
将RAID 5分区用于SQL Server数据文件。 将备份存储在同一RAID阵列中是可以的
Set the transaction log files on a dedicated RAID 1 array. RAID1 is the recommended for storing the transaction log files
在专用RAID 1阵列上设置事务日志文件。 建议使用RAID1来存储事务日志文件
Using this configuration should ensure the minimal I/O pressure and thus the normal values for PAGEIOLATCH_SH but for other PAGEIOLATCH_XX wait types as well
使用此配置应确保最小的I / O压力,从而确保PAGEIOLATCH_SH以及其他PAGEIOLATCH_XX等待类型的正常值
网络问题 (Network issues)
For SQL Servers that are based on SAN (Storage Area Network) or NAS (Network Attached Storage) storage systems which are network dependent, every network latency or network slowness might/will cause excessive PAGEIOLATCH_SH (but also the other PAGEIOLATCH_XX waits) wait type values due to inability of the SQL Server to retrieve data from physical storage to a buffer pool fast enough
对于基于依赖于网络的SAN(存储区域网络)或NAS(网络连接存储)存储系统SQL Server,每个网络延迟或网络运行缓慢可能/将导致过多的PAGEIOLATCH_SH(但也会导致其他PAGEIOLATCH_XX等待)等待类型值由于SQL Server无法足够快地从物理存储检索数据到缓冲池
If the PAGEIOLATCH_SH wait type values are consistently larger than 10-15 seconds, this could be a reliable indicator of pressure on I/O subsystem and three above mentioned causes should be carefully investigated
如果PAGEIOLATCH_SH等待类型的值始终大于10-15秒,则这可能是I / O子系统上压力的可靠指标,应仔细研究上述三个原因
I / O子系统重载了另一个正在产生高I / O活动的进程 (Overloaded I/O subsystem by another processes that are producing the high I/O activity)
In this particular scenario the high I/O activity caused by other processes or subsystems will cause a slightly different representation of the PAGEIOLATCH_SH wait type, and under such scenario, a high number of short PAGEIOLATCH_SH wait types will be displayed. Generally, a high number of brief PAGEIOLATCH_SH wait types is a typical scenario where increased pressure on I/O by another processes should be investigated and resolved
在这种特定情况下,由其他进程或子系统引起的高I / O活动将导致PAGEIOLATCH_SH等待类型的表示略有不同,并且在这种情况下,将显示大量的短PAGEIOLATCH_SH等待类型。 通常,大量简短的PAGEIOLATCH_SH等待类型是一种典型的情况,应研究并解决其他进程对I / O造成的压力增加
记忆压力 (Memory pressure)
In an ideal scenario the memory buffer should be big enough to store all the necessary data for work that SQL Server has to perform. In such an ideal scenario, since all the necessary data is stored in the buffer pool, there will be no requirements for physical data read, and the only changes that will be performed would be the buffer pool data updates. Real world scenarios are rarely ideal, so physical I/O readings from storage to a buffer pool and vice versa are inevitable. The fact that SQL Server is performing the physical I/O readings from the storage is not the something that should be of concern as long as SQL Server performance is not affected. This is why it is important for a DBA to create a baseline of the system and as long as the physical I/O reads are within the created baseline no intervention should be required.
在理想情况下,内存缓冲区应足够大以存储SQL Server必须执行的所有必要数据。 在这种理想情况下,由于所有必需的数据都存储在缓冲池中,因此无需读取物理数据,唯一要做的更改就是缓冲池数据更新。 现实世界中的场景很少是理想的,因此从存储到缓冲池的物理I / O读数是不可避免的,反之亦然。 只要不影响SQL Server的性能,SQL Server就会从存储中执行物理I / O读取的事实就不值得关注。 这就是为什么DBA创建系统基准很重要的原因,并且只要物理I / O读取在所创建的基准之内,就不需要干预。
What has to be tracked and alerted for is when there is a sudden breach of the high threshold of an established baseline, especially if this occurs without visible reason and it lasts for prolonged period of time. This is almost a certain indicator that SQL Server is suffering from the memory pressure, which could be caused by a different reason including:
必须跟踪并发出警报的是当突然违反已建立的基线的高阈值时,尤其是如果这发生在没有明显原因的情况下并且持续了很长时间。 这几乎可以肯定地表明SQL Server正在遭受内存压力,这可能是由不同的原因引起的,包括:
OS processes are utilizing the larger amount of memory than usually forcing the SQL Server memory manager to reduce the size of the memory buffer. Reduced memory buffer is causing increased amount of lazy writes and read activity
与通常迫使SQL Server内存管理器减小内存缓冲区的大小相比,OS进程正在使用更多的内存。 减少的内存缓冲区导致更多的延迟写入和读取活动
A poor performing query that is causing dynamic memory default action to pose internal pressure to a physical memory as a consequence of memory settings change. The same internal pressure on physical memory might be caused due to redistribution of the reserved and stolen pages from the memory buffer
性能不佳的查询导致动态内存默认操作由于内存设置更改而对物理内存造成内部压力。 由于重新分配了内存缓冲区中保留的和被盗的页面,可能对物理内存造成相同的内部压力
Bloated query plan will cause buffer space reduction for the data cache. This is often the cause of the memory pressure so it will be explained with more details here. Query execution plans are stored in the same memory buffer as buffered data. In this way the SQL Server can reuse the execution plan without need for expensive compiling of the query every time it executes, thus relieving the pressure on CPU
膨胀的查询计划将导致数据缓存的缓冲区空间减少。 这通常是造成内存不足的原因,因此将在此处进行更详细的说明。 查询执行计划与缓冲数据存储在同一内存缓冲区中,这样,SQL Server可以重用执行计划,而无需每次执行时都进行昂贵的查询编译,从而减轻了对CPU的压力

For an execution plan to be reused for a specific query, the T-SQL statement of that query must be identical up to the last character as the one that is stored with the query plan, which is not the case with ad-hock queries.* Parametrized queries, unlike ad-hoc queries, use a parameter instead of the specific value, and thus they do not change when executing with different data values, which means that the stored query plan can be used for each execution. For SQL Servers where a large number of ad-hock queries are executed, there will be increased requirements for memory in order to store the additional query plans, as T-SQL, for these ad-hock queries will be different. The more ad-hock queries that are executed, the more memory for storing the execution plans will be required and thus more buffer memory used. Since query plans for ad-hock queries are used only once, their respective execution plans will be useless and the memory used by those plans will be wasted. But the waste of memory itself is not posing the issue, instead it is the fact that buffer memory allocated to the useless execution plans will be at the expense of the memory used for data pages, which is often referred as the “memory stealing”
为了将执行计划重用于特定查询,该查询的T-SQL语句的最后一个字符必须与查询计划中存储的字符相同,而ad-hock查询则不是这种情况。 *参数化查询,不像即席查询,使用参数而不是特定值的,从而与不同的数据值,这意味着,所存储的查询计划可用于每一执行执行时它们不会改变。 对于执行大量ad-hock查询SQL Server,为了存储其他查询计划(如T-SQL),对于内存的需求将会增加,这些ad-hock查询将有所不同。 执行的ad-hock查询越多,将需要更多的内存来存储执行计划,从而使用更多的缓冲内存。 由于用于ad-hock查询的查询计划仅使用一次,因此它们各自的执行计划将无用,并且这些计划所使用的内存将被浪费。 但是内存浪费本身并没有带来问题,而是分配给无用执行计划的缓冲内存将以牺牲数据页内存为代价,这通常被称为“内存窃取”

Reduced size of the memory for storing the data pages will force SQL Server to perform physical I/O reading from the disk more frequently, thus causing the direct impact on SQL Server performance and excessive PAGEIOLATCH_SH
减少用于存储数据页的内存大小将迫使SQL Server更频繁地从磁盘执行物理I / O读取,从而直接影响SQL Server性能和过多的PAGEIOLATCH_SH
When the memory is the cause of the excessive PAGEIOLATCH_SH, whether the to perform performance optimization and tuning of SQL Server or just to add/increase physical memory should be carefully considered. Troubleshooting and performance optimization in such cases can be time consuming and not always efficient in producing desired results. It is not unusual that after spending lots of time in tuning the SQL Server to avoid memory pressure, a DBA to ends up with no solution but to add more physical memory to a system. With the current price of memory, just increasing physical memory size could be not only instant/faster but also a cheaper (compering to the DBA labor) and thus more optimal solution in most cases
如果内存是造成PAGEIOLATCH_SH过多的原因,则应仔细考虑执行性能优化和SQL Server调整还是仅添加/增加物理内存。 在这种情况下,故障排除和性能优化可能很耗时,而且在产生所需结果方面并不总是有效的。 在花费大量时间调整SQL Server以避免内存压力之后,DBA最终没有解决方案,而是向系统添加了更多的物理内存,这并不稀奇。 以当前的内存价格,增加物理内存大小不仅可以即时/更快,而且可以便宜(与DBA劳动相比),因此在大多数情况下是更理想的解决方案
同步镜像和AlwaysOn AG (Synchronous Mirroring and AlwaysOn AG)
In situations when high safety mode is used in database mirroring, or when the synchronous-commit availability mode (synchronous-commit mode) is set for AlwaysOn AG, high availability is emphasized over performance. In this case, high availability is achieved at a cost of increased transaction latency which means that a transaction on the principal server or the primary replica cannot be committed until it receives a message that the mirror or secondary replica that the secondary database enters the SYNCHRONIZED state. In situations when the mirroring operation is delayed for any reason (network, high O/O etc.) it require increased time for physical I/O data reading and thus the PAGEIOLATCH_SH times as the thread will have to wait for the data until the synchronized signal is sent. While this often appears similar to query blocking, the actual root cause of this lies in problems with synchronization
在数据库镜像中使用高安全性模式或为AlwaysOn AG设置了同步提交可用性模式( sync-commit mode )的情况下,高可用性着重于性能。 在这种情况下,以增加事务等待时间为代价实现高可用性,这意味着直到在接收到辅助数据库的镜像或辅助副本进入辅助数据库状态的消息之前,主体服务器或主副本上的事务才能被提交。 。 在镜像操作由于任何原因(网络,高O / O等)而延迟的情况下,它需要增加时间来读取物理I / O数据,因此需要PAGEIOLATCH_SH时间,因为线程将必须等待数据直到同步信号已发送。 尽管这通常看起来类似于查询阻止,但这的真正根本原因在于同步问题
指数管理不善 (Poor index management)
Poor index management is another cause of high incidents PAGEIOLATCH_SH wait types due to forcing the index scan (table scan) instead of index seek. Generally speaking, index seek is always preferred and having index scan in execution plans is something that should be investigated. Having index scan means that no indexes that are relevant to particular query that is executing were found, so SQL Server will have to perform a full table scan, meaning that it will have to read every single row, from first to the last one, in the table. This will cause, in most cases, all pages related to the table have to be read from the disk, meaning that physical I/O reading will be performed – a direct consequence of this will be increased incidents of PAGEIOLATCH_SH wait types. The reason for this could be often that indexes doesn’t exists or that there is a missing or missing/altered nonclustered index that is required by a query.
由于强制索引扫描(表扫描)而不是索引查找,索引管理不佳是导致高事件PAGEIOLATCH_SH等待类型的另一个原因。 一般而言,索引查找始终是首选,在执行计划中进行索引扫描是应该研究的问题。 具有索引扫描意味着没有找到与正在执行的特定查询相关的索引,因此SQL Server将必须执行全表扫描,这意味着它将必须读取数据库中从第一行到最后一行的每一行。桌子。 在大多数情况下,这将导致必须从磁盘读取与该表有关的所有页面,这意味着将执行物理I / O读取-这直接导致的结果是PAGEIOLATCH_SH等待类型的事件增加。 造成这种情况的原因通常可能是索引不存在,或者查询需要缺少或缺少/更改的非聚集索引。
Excessive CXPACKET wait types present alongside with excessive PAGEIOLACH_SG wait types is often an indicator that index scan is the actual cause of excessive PAGEIOLATCH_SH
出现过多的CXPACKET等待类型以及过多的PAGEIOLACH_SG等待类型通常表明索引扫描是过多的PAGEIOLATCH_SH的真正原因
A parameter sniffing might also cause the unwanted and unneeded index scan instead of index seek, in situations when the query results could be significantly different for different parameters. During the initial execution and depending on the results retrieved by the query (for example if the retrieved number of rows consist make up a high percent of the total number of rows), SQL Server might decide that it is better to use the index scan instead of the index seek. This means that for every execution of the query, even when the small number of rows is returned the SQL Server will use the same execution plan and it will use index scan, instead of the lighter and faster index seek. Results of this will be increased PAGEIOLATCH_SH wait types due to increased physical I/O reading of the data pages from the disk
在查询结果对于不同参数可能明显不同的情况下,参数嗅探还可能导致不必要的和不需要的索引扫描,而不是索引查找。 在初始执行过程中,并取决于查询检索的结果(例如,如果检索到的行数占总行数的百分比很高),SQL Server可能会决定最好使用索引扫描来代替索引搜寻。 这意味着对于查询的每次执行,即使返回的行数较少,SQL Server也会使用相同的执行计划,并且将使用索引扫描,而不是更轻松,更快速的索引查找。 由于增加了从磁盘读取数据页的物理I / O,此结果将增加PAGEIOLATCH_SH等待类型
So to sum up this article:
所以总结一下这篇文章:
Even, although fundamentally related to the I/O, excessive PAGEIOLATCH_SH wait types don’t mean necessarily that the I/O subsystem is the root cause. It is often one of the other reasons described in this article
即使,虽然从根本上与I / O有关,但过多的PAGEIOLATCH_SH等待类型并不必然意味着I / O子系统是根本原因。 这通常是本文所述的其他原因之一
Check the SQL Server, queries and indexes as very often this could be found as a root cause of the excessive PAGEIOLATCH_SH wait types
经常检查SQL Server,查询和索引,这可能是导致PAGEIOLATCH_SH等待类型过多的根本原因
Check for memory pressure before jumping into any I/O subsystem troubleshooting
进入任何I / O子系统故障排除之前,请检查内存压力
Keep in mind that in case of high safety Mirroring or synchronous-commit availability in AlwaysOn AG, increased/excessive PAGEIOLATCH_SH can be expected
请记住,在AlwaysOn AG中具有高安全性镜像或同步提交可用性的情况下,预期PAGEIOLATCH_SH会增加/过多
- An example of what was explained in the sentence:
*句子中解释的示例:
As it can be seen in this ad hock query the specific value is used, and the value will be changed when different condition have to be used
在此广告查询中可以看到,使用了特定值,并且在必须使用其他条件时会更改该值
SELECT * FROM dbo.Table1 WHERE CustomerId = 670
SELECT * FROM dbo.Table1 WHERE CustomerId = 670
Here the parameter is used that will be replaced with original value at the time of execution
此处使用的参数将在执行时替换为原始值
SELECT * FROM dbo.Table1 WHERE CustomerId = @p
SELECT * FROM dbo.Table1 WHERE CustomerId = @p
So in case number 1, the SQL Server will have to store the execution plan for every query as if different values are used like this:
因此,在案例1中,SQL Server将必须存储每个查询的执行计划,就像使用不同的值一样:
SELECT * FROM dbo.Table1 WHERE CustomerId = 670 SELECT * FROM dbo.Table1 WHERE CustomerId = 29
SELECT * FROM dbo.Table1 WHERE CustomerId = 670 SELECT * FROM dbo.Table1 WHERE CustomerId = 29
When SQL Server compares these T-SQL statements it will identify them as different, as they actually are, so every time we use the new value for CustomerId, it will create a new execution plan and will store it in the buffer
当SQL Server比较这些T-SQL语句时,它将识别它们是否与实际不同,因此,每当我们对CustomerId使用新值时,它将创建一个新的执行计划并将其存储在缓冲区中
In case of parametrized query:
如果是参数化查询:
SELECT * FROM dbo.Table1 WHERE CustomerId = @p
SELECT * FROM dbo.Table1 WHERE CustomerId = @p
Every time it is executed the query text will be identical, so there is no need for the new execution plan as the T-SQL will not change for different values of CustomerId
每次执行时,查询文本将相同,因此不需要新的执行计划,因为对于不同的CustomerId值,T-SQL不会更改
翻译自: https://www.sqlshack.com/handling-excessive-sql-server-pageiolatch_sh-wait-types/