linux的系统性能监控
目录
一、如果用户反馈说打开网站非常慢,原因是什么呢?
如何知道你的linux系统是否繁忙?
1、看CPU的使用率
2、看平均负载
3、看内存使用率
4、看网络流量
5、看磁盘的容量和读写速度
6、看nginx的并发连接数
二、CPU的使用率
1、查看cpu的信息
2、查看cpu的使用率(top命令)
三、内存的使用率
查看内存的使用率
top可以查看内存的使用率
free -m :可以查询到内存的使用率
如何清除buff/cache内的缓存信息呢?
OOM错误现象是什么?
sync命令:sync命令可以把linux缓存里的东西写进磁盘当中。
找出消耗cpu最多的前10个进程(或者消耗内存最多的前10个进程)
load average:系统平均负载
进程的状态:
四、查看网络带宽
如何知道你的网络带宽是否用完?
如何知道你的交换机路由器的流量负载呢?
如何查看本机器网卡的流量限制呢 ?编辑
查看本机端口使用netstat命令:
查看其他电脑端口的命令:
端口扫描工具:nc nmap fping telnet
1、nc命令
写一个脚本监控百度服务器的 80端口
2、nmap命令
3、fping命令
4、telnet命令
查看网络流量的命令:
1、iptraf命令
2、dstat命令
3、iftop命令
4、glances命令
5、nerhogs命令
五、查看磁盘的容量和读写速度IO
查看磁盘的读写速度:
1、sar命令:
%util :表示繁忙度
其中tps和IOPS:
2、iostat命令
3、iotop命令
4、dd测试命令
查看磁盘容量:
1、df -Th 命令查看磁盘的容量
六、查看nginx的并发连接数
系统运行单进程多线程性能更好还是多进程单线程性能更好呢?
七、总结
一、如果用户反馈说打开网站非常慢,原因是什么呢?
1、可能是用户的网络出现问题,可以让用户通过访问其他网站(百度,京东等)是否也出现打开网站十分慢来证明用户电脑是否存在网络问题,cpu问题或者是内存问题等(替换法)
2、假如上述没有出现问题,那就是web服务器可能出现问题了,运维人员应该检查cpu、内存、磁盘IO、网络带宽、nginx的进程等
3、最后可能是网络运营商出现了问题(如电信,移动,联通等)
因此,我们需要对linux和nginx进行监控
监控的目的:为了获取数据,通过数据了解分析机器是否运行正常
我们为什么对系统的性能如此在乎呢? 因为它牵扯到了我们程序的运行成本。
如何知道你的linux系统是否繁忙?
1、看CPU的使用率
2、看平均负载
3、看内存使用率
4、看网络流量
5、看磁盘的容量和读写速度
6、看nginx的并发连接数
二、CPU的使用率
1、查看cpu的信息
lscpu:可以查看cpu的信息
cat /proc/cpuinfo:同样可以查看cpu的信息
2、查看cpu的使用率(top命令)
top:可以查看cpu的使用率(默认情况下是以cpu的使用率作为排名的)
(如果想以内存作为排序的话,在top界面敲击'M'即可)

系统调用就是操作系统给其他应用程序的接口,也是实现某个功能的程序
top -n 1表示刷新一次就会退出top
id --》 idle 空闲的,表示未使用的cpu百分比
top -n 1|grep Cpu --》表示查找到Cpu的使用率
top -n 1| grep Cpu | awk '{print $8}' --> 查看Cpu的空闲度
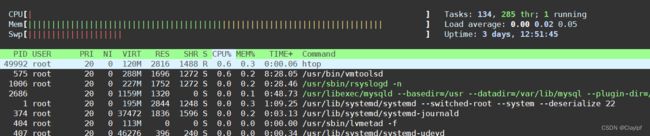
也可以使用htop命令 (在top命令的基础上变得更加漂亮了)
但是需要安装:yum install htop -y
三、内存的使用率
查看内存的使用率
top可以查看内存的使用率
free -m :可以查询到内存的使用率
-m:表示以兆(M)为单位
-h:表示以适合的方式为单位 如G、M等
[root@claylpf ~]# free -m
total used free shared buff/cache available
Mem: 972 469 95 8 407 351
Swap: 2047 477 1570
[root@claylpf ~]#
Mem是物理内存的大小:表达的是内存条的大小
Swap是交换分区的内存大小:交换分区是从磁盘里划分出来的一块空间,临时被当作内存使用的,但是前提条件是物理内存不足的时候,将不活跃的进程交换到Swap分区
Cpu速度:火箭
内存速度:高铁
磁盘IO速度:小汽车/拖拉机
因此我们尽量不使用交换分区,因为速度很慢
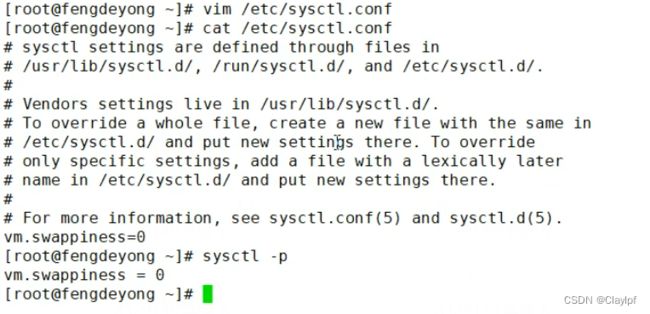
使用 cat /proc/sys/vm/swappiness 输出 30 表达的是当物理内存只剩下30的空间的时候,开始使用交换分区
可以通过改变swappiness文件从而改变使用Swap分区的限制,增加内存的使用率,提升linux的内核参数,提升性能
下图为如何修改swappiness参数的方式
total 总的内存大小
used 应用程序已经使用的内存
free 表示空闲的
shared 表示共享的内存消耗的空间
buff/cache 缓存:正在使用的内存
buffer : 内存 --》 data --》 磁盘 正在运行的进程将内存里的数据写到磁盘的时候,先写到buffer里面,等buffer满了再写道磁盘里面,减少IO次数,提升性能。
cache : 磁盘 --》data --》 内存 将经常需要的数据先读取到cache里,这样可以提升运行速度
所以:total = used + free + shared + buff/cache
available :下一个进程可以使用的空间
因此:available = free + (buff/cache里未使用的空间)
如何清除buff/cache内的缓存信息呢?
参考文档:(22条消息) Linux清理缓存_linux清除缓存_前行-学海无涯的博客-CSDN博客

手工清除linux内的缓存。

OOM错误现象是什么?
OOM全称” OUT Of Memory“ 翻译为中文就是”内存用完了“
出现OOM可能的原因是:
1、分配的内存过少了
2、应用太多了,并且存在某些应用没有释放,一直占用内存空间,将内存浪费了
当系统或者应用程序需要使用的内存超出了可用内存大小时,就会出现OOM错误导致程序崩溃或无法正常运行。通常在操作系统或应用程序中出现OOM错误的情况下,需要通过释放未使用的内存或增加可用的物理内存等措施来解决问题。
进程如果出现OOM现象,一般都是不能提供正常的业务访问,会被内核杀死 或者 会重启
sync命令:sync命令可以把linux缓存里的东西写进磁盘当中。
sync命令一般在关机之前使用一下。
找出消耗cpu最多的前10个进程(或者消耗内存最多的前10个进程)
[root@mysql ~]# ps aux|tail -n +2|sort -rn -k 4|head|awk '{print $3,$4,$11}'
0.0 25.2 /usr/local/mysql/bin/mysqld
0.0 1.1 /usr/bin/python2
0.0 0.9 /usr/lib/polkit-1/polkitd
0.0 0.6 sshd:
0.0 0.6 sshd:
0.0 0.6 sshd:
0.0 0.5 /usr/sbin/NetworkManager
0.0 0.4 pickup
0.0 0.3 /usr/lib/systemd/systemd-journald
0.0 0.3 mysql
[root@mysql ~]#
如上图所示显示的是消耗内存最多的前10个进程,如果我们想要找出消耗cpu最多的,只需要把sort中的-k后接的4换为3即可。
load average:系统平均负载
系统平均负载是指过去的1分子,5分钟,15分钟,(处在可运行或不可中断状态的 进程 的平均数量)就是处在运行或者就绪或者阻塞的状态的 进程 的平均数,是用来判断我们的系统是否繁忙的指标,假如我们的系统是只有一个cpu核心,这个值超过1就说明系统比较繁忙了,但是不超过5就说明cpu还没有达到最忙的时候。0~5以内,说明系统还可以运行,并且只要超过1就说明cpu比较繁忙了。
使用uptime 命令可以查看 top命令的第一行
[root@claylpf ~]# uptime
21:05:10 up 3 days, 13:28, 4 users, load average: 0.00, 0.01, 0.05
可以使用 man uptime查看load average的意思:
the system load averages for the past 1, 5, and 15 minutes.
System load averages is the average number of processes that are either in a runnable or uninterruptable state. A process in a runnable state is either using the CPU or waiting
to use the CPU. A process in uninterruptable state is waiting for some I/O access, eg waiting for disk. The averages are taken over the three time intervals. Load averages
are not normalized for the number of CPUs in a system, so a load average of 1 means a single CPU system is loaded all the time while on a 4 CPU system it means it was idle 75%
of the time.
系统负载在过去1分钟、5分钟和15分钟内的平均值。
系统平均负载是处于可运行或不可中断状态的进程的平均数量。处于可运行状态的进程要么正在使用CPU,要么正在等待
使用CPU。处于不可中断状态的进程正在等待一些I/O访问,例如等待磁盘。取三个时间间隔的平均值。平均负载
在一个系统中,平均负载为1意味着一个CPU系统一直处于负载状态,而在一个4 CPU系统上,这意味着它空闲75%可运行状态:就绪态 到 执行态 之间都为可运行状态
不可中断状态:在执行态时不能被打断的,并且等待IO请求(到达阻塞态)
因此
当你的cpu为1个的时候,这个比较繁忙的值就是1,队列里同时又5个进程等待运行的时候,值就会到达5,这样说明cpu很忙(最忙)
说明对于一个cpu,可以接收的值尽量不大于5
0~5 说明还能接收负载
超过5的时候,说明cpu非常忙
如果你的cpu是8核的,这个所有cpu比较忙的时候 值就是8,8*5 = 40 所以当值到达l40的时候,cpu非常非常忙
例如:
当load average :1,0.5,0.2 --》说明最近1分钟的时候比较忙,而15分钟内的时候为0.2,最近比较忙,但是之后就就不是特别忙了。
当load average:0.5,0.7,0.9 --》说明前段时间比较忙 15分钟内都比较忙。
进程的状态:

因此我们可以通过看进程的数量来判断Cpu是否忙,内存是否消耗多等
四、查看网络带宽
如何知道你的网络带宽是否用完?
如果你的服务器网络带宽只有1M,而一个用户就会消耗1k - - 》最多1000个用户左右
但是你的cpu 和 内存可以接收5000个用户,这就会导致你的服务器很容易出现瓶颈,如果要解决这个问题,就需要增加带宽,这样能提升你的服务器的瓶颈。
如何知道你的交换机路由器的流量负载呢?
通过监控软件进行:prometheus,zabbix这些软件可以更加方便地监控交换机路由器的流量负载,提供更加全面的报警和分析功能。
前提是要知道交换机路由器的流量负载,可以使用SNMP(Simple Network Management Protocol)进行监控。
SNMP是一种网络管理协议,可以实现对网络设备的监控、配置和排错等操作。SNMP Agent是安装在网络设备上的代理程序,它可以向管理者提供设备的各种信息,包括CPU利用率、内存利用率、网络流量等数据。而SNMP Manager则是用于收集和分析这些数据的工具。
通过SNMP,可以监控交换机路由器的流量负载情况,包括带宽利用率、流量峰值、流量分布等信息。常用的SNMP监控软件包括MRTG、Zabbix、Cacti等。
总之,使用SNMP协议可以方便快捷地监控交换机路由器的流量负载情况,及时发现和解决网络问题。
如何查看本机器网卡的流量限制呢 ?
查看本机端口使用netstat命令:
下载netstat命令:yum install net-tools -y
使用:
-anutlp
-a all 显示所有的信息
-n [--numeric|-n] 以数字的形式显示--》不显示名字
-u 查看udp协议
-t 查看tcp协议
-l 处于listen状态
-p 显示程序的名字 PID/Program nameRecv-Q:接受数据的队列 receive queue --》内存里存放数据的临时空间
Send-Q:发送数据的队列 send queue
Local Address
127.0.0.1 --》loopback
192.168.1.141 --》ens33
0.0.0.0 --》代表这个linux服务器所有接口的ip地址--》通配符--》任意ip地址Foreign Address
0.0.0.0:* --》ipv4---》代表任意ip任意端口
:::* --》ipv6里的任意ip任意端口10:15 ~10~35 休息20分钟
State
有哪些状态--》三次握手、四次断开 --》tcp
LISTEN --》监听 --》服务器开启了某个端口,对外提供服务
ESTABLISHED --》建立连接
TIME_WAIT 表示已经要断开--》自己发起的断开--》释放连接
查看其他电脑端口的命令:
端口扫描工具:nc nmap fping telnet
安装:yum install nc nmap fping telnet -y
1、nc命令
[root@sc-mysql-master ~]# nc -w 1 -z www.baidu.com 8080
[root@sc-mysql-master ~]# echo $? #表示百度的8080端口没有打开
1
[root@sc-mysql-master ~]#
[root@mysql ~]# nc -w 1 -z www.baidu.com 80
[root@mysql ~]# echo $? #表示百度的80端口打开了
0
[root@mysql ~]#
其中-w 表示超时时间, -z表示不发送任何信息给百度的8080端口
使用echo $?来查看上条命令是否成功运行
写一个脚本监控百度服务器的 80端口
[root@mysql lianxi]# bash monitor_baidu.sh #测试,说明百度打开了 80 端口
20230414110055 baidu server www.baidu.com is up
20230414110056 baidu server www.baidu.com is up
20230414110058 baidu server www.baidu.com is up
20230414110059 baidu server www.baidu.com is up
20230414110100 baidu server www.baidu.com is up
^C
[root@mysql lianxi]# cat monitor_baidu.sh #脚本
#!/bin/bash
while :
do
ctime=$(date +%Y%m%d%H%M%S)
if nc -z -w 1 www.baidu.com 80
then
echo "$ctime baidu server www.baidu.com is up"|tee /var/log/web_server_160.log
else
echo "$ctime baidu server www.baidu.com is down"|tee /var/log/web_server_160.log
fi
sleep 1
done
[root@mysql lianxi]#
2、nmap命令
它可以帮助我们扫描一些常见的端口(3306、80、5000、22等)

3、fping命令
[root@centos8-zabbix ~]# fping -g 192.168.0.0/24
一个网段里哪些ip在使用,哪些没有使用
4、telnet命令

表示百度的80端口打开了。
查看网络流量的命令:
1、iptraf命令
下载安装iptraf:yum install iptraf -y
在命令行里输入 iptraf-ng 他会显示如下信息
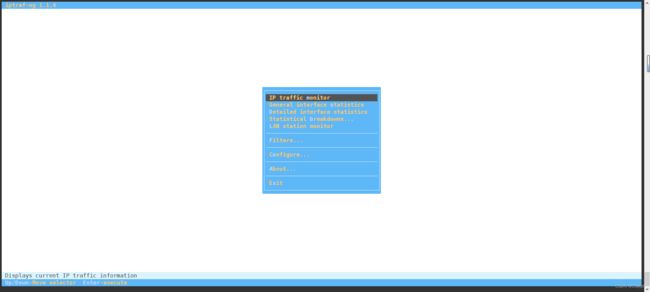
按回车,会出现以下选项

选取ens33 可监控ens33网卡的网络带宽、网络流量

2、dstat命令
下载安装dstat:yum install dstat -y
在命令行里输入dstat 他会显示如下信息(1s刷新一次)

dstat -N ens33 --》可以单独查看ens33接口的信息
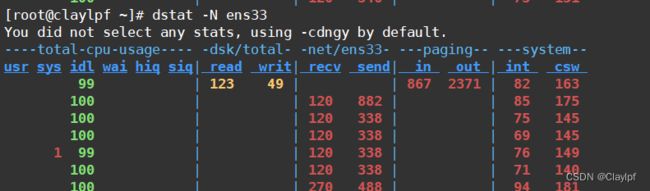
或者添加 total --》 可以查看所有接口的信息

查看消耗的内存、cpu、IO等的命令:

将获取的信息写入文件夹中:
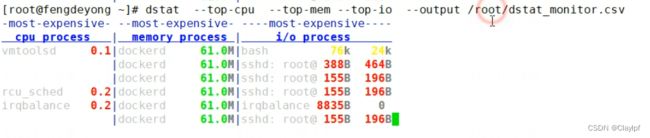
其他选项可以通过man dstat查看
3、iftop命令
下载安装iftop:yum install iftop -y
在命令行里输入 iftop 他会显示如下信息(1s刷新一次)

按q退出
4、glances命令
下载安装glances:yum install glances -y
在命令行里输入glances 他会显示如下信息(1s刷新一次)
按q可以退出
5、nerhogs命令
nethogs命令与glances和上面的几个命令不同的是,它可以查看某个进程所消耗的网络带宽
上面的命令都只能查看总的带宽,因此它更加便捷我们去获取进程的网络带宽
下载安装nethogs:yum install nethogs -y(前提是你已经安装了 epel-release)
在命令行里输入nethogs 他会显示如下信息(1s刷新一次)
它可以查看nginx进程所消耗的带宽
[root@claylpf ~]# ps aux |grep nginx
root 57816 0.0 0.0 39308 940 ? Ss 00:31 0:00 nginx: master process nginx
nginx 57817 0.0 0.1 41784 1940 ? S 00:31 0:00 nginx: worker process
root 57821 0.0 0.0 112808 968 pts/2 R+ 00:31 0:00 grep --color=auto nginx
[root@claylpf ~]# nethogs
下面可以看出nginx消耗的带宽为多少:

五、查看磁盘的容量和读写速度IO
查看磁盘的读写速度:
1、sar命令:
sar命令查看磁盘的读写速度IO和繁忙度
[root@mysql lianxi]# sar -d 1 3 #每隔一秒查看本机的IO读写速度,一共查看3次
Linux 3.10.0-1160.el7.x86_64 (mysql) 2023年04月14日 _x86_64_ (1 CPU)
11时41分48秒 DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
11时41分49秒 dev8-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
11时41分49秒 dev11-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
11时41分49秒 dev253-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
11时41分49秒 dev253-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
11时41分49秒 DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
11时41分50秒 dev8-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
11时41分50秒 dev11-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
11时41分50秒 dev253-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
11时41分50秒 dev253-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
11时41分50秒 DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
11时41分51秒 dev8-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
11时41分51秒 dev11-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
11时41分51秒 dev253-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
11时41分51秒 dev253-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
平均时间: DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
平均时间: dev8-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
平均时间: dev11-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
平均时间: dev253-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
平均时间: dev253-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
[root@mysql lianxi]# %util :表示繁忙度
当%util = 100% 说明磁盘的读写性能达到极限了
其中tps和IOPS:
tps: transfer per second 每秒钟传输(读写)的次数
tps
Total number of transfers per second that were issued to physical devices. A transfer is an I/O
request to a physical device
IOPS: INPUT output per second 每秒钟读写的次数
2、iostat命令
iostat -x 查看磁盘读写的速度和繁忙度
[root@mysql lianxi]# iostat -x
Linux 3.10.0-1160.el7.x86_64 (mysql) 2023年04月14日 _x86_64_ (1 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.07 0.00 0.12 0.00 0.00 99.81
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.01 0.19 0.27 15.95 55.27 310.76 0.00 1.12 1.16 1.08 0.43 0.02
scd0 0.00 0.00 0.00 0.00 0.00 0.00 114.22 0.00 1.50 1.50 0.00 1.11 0.00
dm-0 0.00 0.00 0.19 0.28 15.89 55.24 305.16 0.00 1.13 1.18 1.10 0.42 0.02
dm-1 0.00 0.00 0.00 0.00 0.01 0.02 10.92 0.00 7.55 2.48 9.29 0.39 0.00
[root@mysql lianxi]#
同样,他也可以跟sar命令一样,确定查看间隔时间和查看次数
[root@mysql lianxi]# iostat -x -d 1 3
Linux 3.10.0-1160.el7.x86_64 (mysql) 2023年04月14日 _x86_64_ (1 CPU)
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.01 0.19 0.27 15.94 55.24 310.75 0.00 1.12 1.16 1.08 0.43 0.02
scd0 0.00 0.00 0.00 0.00 0.00 0.00 114.22 0.00 1.50 1.50 0.00 1.11 0.00
dm-0 0.00 0.00 0.19 0.28 15.89 55.22 305.15 0.00 1.13 1.18 1.10 0.42 0.02
dm-1 0.00 0.00 0.00 0.00 0.01 0.02 10.92 0.00 7.55 2.48 9.29 0.39 0.00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
scd0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
dm-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
scd0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
dm-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
[root@mysql lianxi]#
3、iotop命令
iotop命令可以查看磁盘IO(默认没有安装。需要下载yum install iotop -y)

可以查看哪个进程在大量的对磁盘进行读写
4、dd测试命令
我们可以使用dd命令测试磁盘性能的命令(可以知道磁盘的读写能力好不好)
[root@mysql lianxi]# dd if=/dev/zero of=test.dd
^C记录了700985+0 的读入
记录了700985+0 的写出
358904320字节(359 MB)已复制,1.82578 秒,197 MB/秒
[root@mysql lianxi]#
说明磁盘的读写能力还算不错,197MB每秒命令:[root@docker1 ~]# dd if=/dev/zero of=sc.dd bs=1M count=1000
dd是一个数据备份的命令
if input file 输入文件
/dev/zero 会产生零 0
output file 输出文件
bs=1M 数据单元
count=1000 数量
注:切记不要一直运行dd命令,否则会导致你的磁盘空间存满,导致无法存入其他数据了,所有我们测试玩之后,我们必须删除掉test.dd文件,不要让它占用我们太多的磁盘空间了
查看磁盘容量:
1、df -Th 命令查看磁盘的容量
[root@mysql lianxi]# df -Th
文件系统 类型 容量 已用 可用 已用% 挂载点
devtmpfs devtmpfs 475M 0 475M 0% /dev
tmpfs tmpfs 487M 0 487M 0% /dev/shm
tmpfs tmpfs 487M 7.7M 479M 2% /run
tmpfs tmpfs 487M 0 487M 0% /sys/fs/cgroup
/dev/mapper/centos-root xfs 17G 6.7G 11G 40% /
/dev/sda1 xfs 1014M 137M 878M 14% /boot
tmpfs tmpfs 98M 0 98M 0% /run/user/0
[root@mysql lianxi]#
六、查看nginx的并发连接数
开启nginx的状态统计模块(在配置nginx的时候加入 http_stub_status_moduld)
只能通过查看nginx内部的状态统计功能模块,而其他的命令是无法查看nginx内部的并发数量的
下面是最终nginx页面统计的输出的结果:

系统运行单进程多线程性能更好还是多进程单线程性能更好呢?
单进程多线程和多进程单线程各有优缺点,要根据具体情况选择使用。
对于CPU密集型任务,例如大规模计算等需要大量处理器资源的任务,多进程单线程的性能更好。因为每个进程都有自己的寄存器、栈、代码段等资源,多进程可以平衡地分配这些资源,从而使得每个进程都能够充分利用硬件资源。此外,多进程拥有更好的稳定性和安全性,进程间相互独立,避免一个线程崩溃影响整个程序的运行。
而对于I/O密集型任务,例如网络通信、文件读写等需要大量I/O操作的任务,单进程多线程的性能更好。因为多线程可以在某一线程进行I/O时,其他线程继续进行计算任务,从而提高了CPU的利用率。此外,多线程也可以实现各线程之间数据共享,减少了数据的传输和转换,提高了程序的运行效率。多线程cpu资源利用率更高,可以承载更多的用户访问。
因此,在选择单进程多线程和多进程单线程时,应该考虑到具体任务的特点以及系统的硬件资源配置等因素,综合评估各种方案的优缺点,选择更加适合的方式。
七、总结
上面所有对linux系统性能的监控,都是通过人去敲击命令获取系统性能的各种数据,但是它是一种非常原始的方法,缺点十分明显:效率低下,需要知道很多linux命令,而且维护的机器数量也比较少,无法完成集群项目。
因此我们需要监控更加方便的话,需要使用一些监控的工具:如 prometheus等
prometheus官网:Prometheus - Monitoring system & time series database
而这些工具的创造者就是 运维开发人员
运维开发:制作很好的工具 --》 如监控的软件:可以使我们获取各种各样的系统性能数据