ZooKeeper【实际案例】
服务器动态上下线监听
需求
在我们的分布式系统中,有多台服务器节点,我们希望任意一台客户端都能实时收到服务器节点的上下线。
实现
服务器节点上线以后自动去zookeeper目录注册自己的节点信息(创建Znode临时节点),这就需要我们创建一个永久目录节点 servers 来供服务器集群在这之下创建临时节点。
客户端监听zookeeper目录下节点的变化。
ZooKeeper可以监听到七种类型变化:
- None:连接建立事件
- NodeCreated:节点创建
- NodeDeleted:节点删除
- NodeDataChanged:节点数据变化
- NodeChildrenChanged:子节点列表变化
- DataWatchRemoved:节点监听被移除
- ChildWatchRemoved:子节点监听被移除

DistributeClient
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class DistributeClient {
private String connectionString = "hadoop102:2181,hadoop103:2181,hadoop104:2181";
private int sessionTimeOut = 2000;
private ZooKeeper zk;
public static void main(String[] args) throws InterruptedException, KeeperException, IOException {
DistributeClient client = new DistributeClient();
//1.获取zookeeper连接
client.getConnection();
//2.监听/servers 下面子节点的变化
client.getServerList();
//3.业务逻辑
client.business();
}
private void business() throws InterruptedException {
Thread.sleep(Long.MAX_VALUE);
}
private void getServerList() throws InterruptedException, KeeperException {
//设置一直监听 它会自动走初始化ZooKeeper时指定的监听器方法process()
List children = zk.getChildren("/servers", true);
//存储主机名称
ArrayList servers = new ArrayList<>();
for (String child : children) {
byte[] data = zk.getData("/servers/" + child, false, null);
servers.add(new String(data));
}
//直接打印List集合
System.out.println(servers);
}
private void getConnection() throws IOException {
zk = new ZooKeeper(connectionString , sessionTimeOut, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
try {
//一直监听
getServerList();
} catch (InterruptedException | KeeperException e) {
e.printStackTrace();
}
}
});
}
}
DistributeServer
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Id;
import java.io.IOException;
public class DistributeServer {
private String connectionString = "hadoop102:2181,hadoop103:2181,hadoop104:2181";
private int sessionTimeOut = 2000;
private ZooKeeper zk;
public static void main(String[] args) throws IOException, InterruptedException, KeeperException {
DistributeServer server = new DistributeServer();
//1.连接zookeeper集群
server.getConnection();
//2.注册Znode到zookeeper目录
server.register("hadoop102");
//3.启动业务逻辑
server.business();
}
private void business() throws InterruptedException {
Thread.sleep(Long.MAX_VALUE);
}
private void register(String hostname) throws InterruptedException, KeeperException {
String s = zk.create("/servers/" + hostname, hostname.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
System.out.println(hostname+" is online !");
}
private void getConnection() throws IOException {
zk = new ZooKeeper(connectionString, sessionTimeOut, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
}
});
}
}
测试
测试时,zookeeper集群必须开启,因为我们需要通过API来连接我们的zookeeper集群才能实现节点的创建。此外,我们的服务器地址映射需要再windows端进行配置后才能使用,或者直接使用服务器的 ip 。
命令行测试
开启客户端集群,再通过命令行来模拟服务器集群测试客户端的监听效果。
运行DistributeClient ,观察控制台输出:
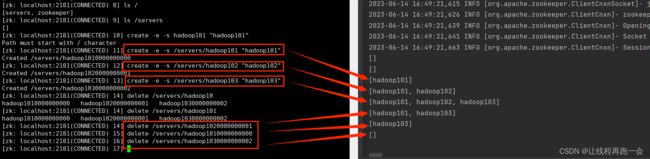
模拟服务器测试
运行DistributeServer来模拟服务器hadoop102上线,观察DistributeServer控制台的输出:

停止运行DistributeServer,意味着服务器下线,临时节点也就自动删除了。
分布式锁案例
单机情况下也就是只有一个进程的情况下使用Synchronized是可以保证线程安全的。但是分布式情况下是多个不同的进程,而不是一个进程里面不同的线程,所以Synchronized是无法保证多个进程安全的。
定义
互斥是我们分布式系统同步化问题中的一个重要部分,ZooKeeper帮我们解决了这一问题。 分布式系统的基础是多进程之间并发和协作,不同进程将需要同时访问相同的资源,为了保证这种并发访问不会崩溃资源或使其不一致,需要保证进程的互斥访问,当一个进程使用某个共享资源,其他进程不允许对这个资源操作。
过程

- 多个客户端对某一共享资源进行访问请求
- zookeeper收到请求之后,在zookeeper的 /locks 目录下创建多个临时带序列编号节点,代表每个客户端的请求。
- 编号最小的请求节点优先获得锁,进行资源的访问,此时其它请求节点不允许访问该资源。
- 其它请求节点会监听自己前一个编号小的请求,监听前一个请求节点是否已经释放掉锁。
- 如果前一个请求节点完成之后释放掉锁自己就立即拿到锁,重复第3部
实现
分布式锁对象 DistributeLock
Hadoop集群中不同的节点之间需要协作完成各种任务。这就需要多个节点在同一时间对某一个资源进行访问,并防止并发冲突。Zookeeper提供了分布式锁机制,可以提供多个节点之间的同步和互斥,避免数据不一致等问题。
在zookeeper中,我们每个需要互斥访问的请求任务都会有一把锁(每个任务一把锁),对应到这个案例是每个 /locks 下的任务节点都有一把自己的锁,每把锁都有两个功能(上锁和解锁),当自己拿到资源的时候就上锁,避免别的进程来访问,当自己使用完之后,就解锁,供其它任务节点按照顺序使用。
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;
import java.io.IOException;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.CountDownLatch;
public class DistributeLock {
//配置多个zookeeper服务器
private final String connectString = "hadoop102:2181,hadoop103:2181,hadoop104:2181";
//设置客户端连接的最大时间 ms
private final int sessionTimeOut = 2000;
private final ZooKeeper zk;
private String lastPath;
private CountDownLatch waitLatch = new CountDownLatch(1);
private CountDownLatch connectLatch = new CountDownLatch(1);
private String currentNode;
public DistributeLock() throws IOException, InterruptedException, KeeperException {
//获取连接 zk
zk = new ZooKeeper(connectString, sessionTimeOut, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
//connectLatch 如果连接上zk 就释放它 不然它会一直阻塞
if (watchedEvent.getState()==Event.KeeperState.SyncConnected){
connectLatch.countDown();
}
//如果前一个请求节点释放了锁(前一个节点在释放锁之后会被自动删除 这样我们就可以监听到)
if (watchedEvent.getType()==Event.EventType.NodeDeleted && watchedEvent.getPath().equals(lastPath)){
waitLatch.countDown();
}
}
});
//等待zk正常连接后才能继续往下走
connectLatch.await();
//判断根节点/locks是否存在
Stat stat = zk.exists("/locks", false);
if (stat == null){
//创建一个永久节点
zk.create("/locks","locks".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);
}
}
//对资源上锁
public void zkLock() throws InterruptedException, KeeperException {
//创建临时带序号节点
currentNode = zk.create("/locks/" + "tmp-", null, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
//判断当前任务节点是不是最小的节点
List children = zk.getChildren("/locks", false);
//如果节点/locks目录下只有一个节点
if (children.size()==1){
return;
}else {
Collections.sort(children);
//获取节点名称 tmp-000000
String thisNode = currentNode.substring("/locks/".length());
//通过节点名称来获取到集合中的位置
int index = children.indexOf(thisNode);
//
if (index == -1){
System.err.println("数据异常");
}else if(index == 0){//说明自己就是第一个节点 拿到锁
return;
}else {
//前一个节点 = 当前节点序号 - 1
lastPath = "/locks/"+children.get(index - 1);
//需要监听前一个节点锁的情况 这里设置监听 需要再初始化ZooKeeper中实现process的逻辑代码
zk.getData(lastPath, true, null);
//等待监听
waitLatch.await();
return;
}
}
}
//解锁
public void unLock() throws InterruptedException, KeeperException {
//删除节点
zk.delete(currentNode,-1);
}
}
模拟任务节点使用分布式锁的过程
开启两个线程来模拟两个请求任务同时被记录到 /locks 目录节点下,当其中一个线程占用了资源(上了锁),另一个线程就只能等待其释放锁。
import org.apache.zookeeper.KeeperException;
import java.io.IOException;
public class DistributeLockTest {
public static void main(String[] args) throws IOException, InterruptedException, KeeperException {
DistributeLock lock1 = new DistributeLock();
DistributeLock lock2 = new DistributeLock();
//开启两个线程
new Thread(new Runnable() {
@Override
public void run() {
try {
lock1.zkLock();
System.out.println("线程1启动 获取到锁");
Thread.sleep(5000);
lock1.unLock();
System.out.println("线程1 释放锁");
} catch (InterruptedException | KeeperException e) {
e.printStackTrace();
}
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
try {
lock2.zkLock();
System.out.println("线程2启动 获取到锁");
Thread.sleep(5000);
lock1.unLock();
System.out.println("线程2 释放锁");
} catch (InterruptedException | KeeperException e) {
e.printStackTrace();
}
}
}).start();
}
}

此时,变化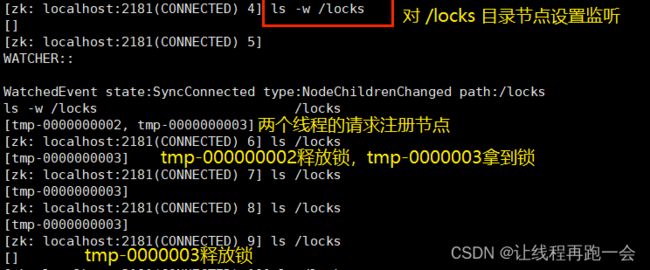
Curator框架实现分布式锁
依赖
org.apache.curator
curator-framework
4.2.0
org.apache.curator
curator-recipes
4.2.0
org.apache.curator
curator-client
4.2.0
可重入锁
可重入锁(Reentrant Lock)是一种支持重进入的锁。重进入是指可以多次获得同一把锁,并且锁释放的次数与获得的次数相同。
例如,一个线程在持有锁时可以再次获取该锁,而不会被阻塞,同时该线程释放该锁的次数与锁的次数相同,直到该线程完全释放该锁。
这种锁的主要作用是避免线程死锁,并提高锁的性能。在多层,递归或嵌套调用方法时,使用可重入锁将十分方便,因为锁可以重复获得而不被其他线程影响。可重入锁是Java并发编程中一种非常重要的锁机制。
代码实现
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.recipes.locks.InterProcessMutex;
import org.apache.curator.retry.ExponentialBackoffRetry;
public class CuratorLockTest {
public static void main(String[] args) {
//1.创建分布式锁1
InterProcessMutex lock1 = new InterProcessMutex(getCuratorFramework(), "/locks");
//2.创建分布式锁2
InterProcessMutex lock2 = new InterProcessMutex(getCuratorFramework(), "/locks");
new Thread(new Runnable() {
@Override
public void run() {
try {
//拿到锁
lock1.acquire();
System.out.println("线程1 拿到锁");
//实现可重入锁
lock1.acquire();
System.out.println("线程1 再次获取到锁");
Thread.sleep(5000);
lock1.release();
System.out.println("线程1 释放锁");
lock1.release();
System.out.println("线程1 再次释放锁");
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
try {
//拿到锁
lock2.acquire();
System.out.println("线程2 拿到锁");
//实现可重入锁
lock2.acquire();
System.out.println("线程2 再次获取到锁");
Thread.sleep(5000);
lock2.release();
System.out.println("线程2 释放锁");
lock2.release();
System.out.println("线程2 再次释放锁");
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
}
private static CuratorFramework getCuratorFramework() {
//连接失败的话 每3s重新尝一次 尝试3次
ExponentialBackoffRetry policy = new ExponentialBackoffRetry(3000, 3);
CuratorFramework client = CuratorFrameworkFactory.builder().connectString("hadoop102:2181,hadoop103:2181,hadoop104:2181")
.connectionTimeoutMs(2000)
.sessionTimeoutMs(2000)
.retryPolicy(policy).build();
//启动客户端
client.start();
System.out.println("zookeeper连接成功");
return client;
}
}
