GORM---高级查询
文章目录
- 构建Demo数据
-
- 模型定义
- 数据表
- 高级查询
-
- 子查询
- 选择字段
- 排序
- 数量
- 偏移
- 总数
- Group & Having
- 连接
- Pluck
- 扫描
构建Demo数据
模型定义
type Users struct {
Id uint64 `gorm:"primary_key;NOT NULL"`
EmailId uint64 `gorm:"foreignKey:email_id;references:Email;"`
Email Email `gorm:"constraint:OnUpdate:CASCADE,OnDelete:SET NULL"`
Age uint64
Name string
}
type Email struct {
EmailId uint64 `gorm:"column:email_id;primary_key;NOT NULL"`
Addr string
}
数据表
Users表:
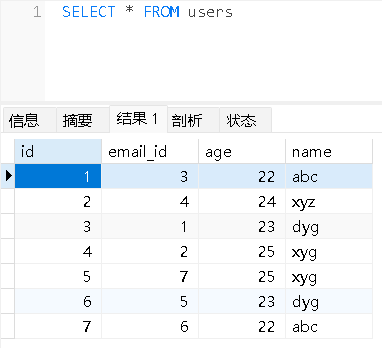
Email表:
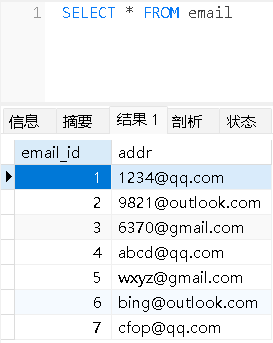
高级查询
子查询
子查询是指一个查询语句嵌套在另一个查询语句内部的查询,内部的查询是外部查询的条件。
//查询大于平均年龄的所有记录
var u1 []*connect.Users
connect.DB.Where("age > (?)", connect.DB.Table("users").Select("AVG(age)")).Find(&u1)
//SELECT * FROM `users` WHERE age > (SELECT AVG(age) FROM `users`)
for _, v := range u1 {
fmt.Printf("%+v\n", v)
}
运行结果如下:

由于平均年龄需要计算,所以内层的SELECT语句的作用是为了得到平均年龄(connect.DB.Table(“users”).Select(“AVG(age)”)),外层的SELECT语句的作用就是条件判断。
var u2 []*connect.Users
subQuery := connect.DB.Select("AVG(age)").Where("name LIKE ?", "%y%").Table("users")
connect.DB.Select("name,AVG(age) as avgAge").Group("name").Having("AVG(age) > (?)", subQuery).Find(&u2)
//SELECT name,AVG(age) as avgAge FROM `users` GROUP BY `name` HAVING AVG(age) > (SELECT AVG(age) FROM `users` WHERE name LIKE '%y%')
for _, v := range u2 {
fmt.Printf("%+v\n", v.Name)
}
运行结果如下:
![]()
虽然这个子查询的例子的实际意义不大,但实在是想不出什么好的例子了。首先subQuery变量存储的是内层SELECT语句的查询结果,就是查询在users表中查找name字段类似于%y%的(中间有y的name字段)的记录,并计算这些记录的平均年龄(24+23+25+25+23)/5=24。接下来就外层SELECT语句的作用就是:根据name指定分组(共四组:abc、xyz、dyg、xyg),找出这四组中的年龄大于24的记录。不熟悉group having的详见:mysql必知必会——GROUP BY和HAVING
选择字段
Select方法能指定你想从数据库中检索出的字段,默认会选择全部字段。
var u1, u2 []*connect.Users
connect.DB.Select("name, age").Find(&u1) //写法一
//SELECT `name`,`age` FROM `users`
connect.DB.Select([]string{"name", "age"}).Find(&u2) //写法二
//SELECT `name`,`age` FROM `users`
//例二
var age int
rows, err := connect.DB.Table("users").Select("COALESCE(age,?)", 0).Rows()
//SELECT COALESCE(age,23) FROM `users`
if err != nil {
fmt.Println(err.Error())
}
defer rows.Close()
for rows.Next() {
if err = rows.Scan(&age); err != nil {
fmt.Println(err.Error())
}
fmt.Println(age)
}
例二的代码分析如下:
- 使用 Table() 方法指定要查询的数据表为 users。
- 使用 Select() 方法指定查询的字段为 COALESCE(age,?),其中 COALESCE() 函数是一个条件判断函数,如果 age 不为 NULL,则返回 age 的值,否则返回指定的值,这里指定的值是 ?,这代表一个占位符,会在执行查询语句时被具体的值替换,这里占位符的值为 0。
- 使用 Rows() 方法执行查询并返回结果集,该方法会返回一个 *sql.Rows 对象,表示整个结果集。
- 使用 rows 变量可以遍历结果集,处理每一行数据。
排序
Order,指定从数据库中检索出记录的顺序。
var u1, u2 []*connect.Users
connect.DB.Order("age desc, name").Find(&u1)
// SELECT * FROM users ORDER BY age desc, name;
for _, v := range u1 {
fmt.Printf("%+v\n", v)
}
// 多字段排序
connect.DB.Order("age desc").Order("name").Find(&u2)
// SELECT * FROM users ORDER BY age desc, name;
for _, v := range u2 {
fmt.Printf("%+v\n", v)
}
数量
Limit,指定从数据库检索出的最大记录数。
var u1, u2, u3 []*connect.Users
connect.DB.Limit(3).Find(&u1)
//SELECT * FROM `users` LIMIT 3 (u1)
// -1 取消 Limit 条件
connect.DB.Limit(5).Find(&u2).Limit(-1).Find(&u3)
//SELECT * FROM `users` LIMIT 5 (u2)
//SELECT * FROM `users` (u3)
偏移
Offset,指定开始返回记录前要跳过的记录数。需要注意的是,在mysql中OFFSET关键字必须要与LIMIT关键字搭配使用。
var u1, u2, u3 []connect.Users
connect.DB.Limit(3).Offset(3).Find(&u1)
//SELECT * FROM `users` LIMIT 5 OFFSET 3
for _, v := range u1 {
fmt.Printf("%+v\n", v)
}
connect.DB.Limit(3).Offset(2).Find(&u2).Offset(-1).Find(&u3)
//SELECT * FROM `users` LIMIT 2 OFFSET 2 (u2)
//SELECT * FROM `users` LIMIT 2 (u3)
for _, v := range u2 {
fmt.Printf("%+v\n", v)
}
fmt.Println()
for _, v := range u3 {
fmt.Printf("%+v\n", v)
}
运行结果如下:

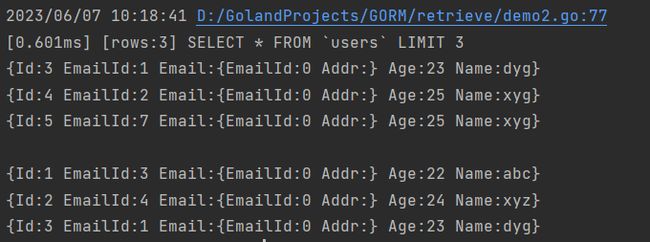
总数
Count,该 model 能获取的记录总数。
var u []connect.Users
var count1, count2, count3 int64
connect.DB.Where("name = ?", "xyg").Or("name = ?", "dyg").Find(&u).Count(&count1)
//SELECT * FROM `users` WHERE name = 'xyg' OR name = 'dyg'
//SELECT count(*) FROM `users` WHERE name = 'xyg' OR name = 'dyg'
connect.DB.Model(&connect.Users{}).Where("name = ?", "abc").Count(&count2)
//SELECT count(*) FROM `users` WHERE name = 'abc'
connect.DB.Table("email").Select("count(distinct(addr))").Count(&count3)
//SELECT count(distinct(addr)) FROM `email`
注意 Count 必须是链式查询的最后一个操作 ,因为它会覆盖前面的 SELECT,但如果里面使用了 count 时不会覆盖。
Group & Having
详见子查询。
连接
Joins,指定连接条件。
//SELECT users.name, email.addr FROM `users` left join email on email.email_id = users.email_id
rows, err := connect.DB.Table("users").Select("users.name, email.addr").Joins("left join email on email.email_id = users.email_id").Rows()
if err != nil {
fmt.Println(err)
}
type Result struct {
Name string
Addr string
}
var r Result
for rows.Next() {
if err = rows.Scan(&r.Name, &r.Addr); err != nil {
fmt.Println(err.Error())
}
fmt.Println(r)
}
运行结果如下:
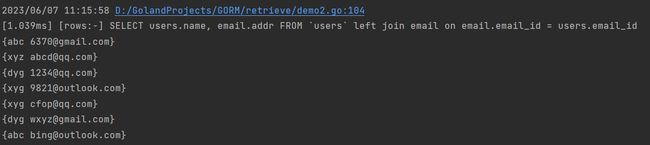
Pluck
Pluck,查询 model 中的一个列作为切片。
var ages []int64
connect.DB.Table("users").Pluck("age", &ages)
fmt.Println(ages)
运行结果如下:

扫描
Scan用来扫描结果至一个 struct。
type Result struct {
Name string
Age int
}
var result1, result2 Result
var results []Result
connect.DB.Table("users").Select("name, age").Where("name = ?", "xyg").Scan(&result1)
//SELECT name, age FROM `users` WHERE name = 'xyg'
fmt.Println(result1)
connect.DB.Table("users").Select("name, age").Where("id > ?", 0).Scan(&results)
//SELECT name, age FROM `users` WHERE id > 0
fmt.Println(results)
// 原生 SQL
connect.DB.Raw("SELECT name, age FROM users WHERE name = ?", "xyg").Scan(&result2)
//SELECT name, age FROM users WHERE name = 'xyg'
fmt.Println(result2)
