深度学习应用篇-元学习[15]:基于度量的元学习:SNAIL、RN、PN、MN
1.Simple Neural Attentive Learner(SNAIL)
元学习可以被定义为一种序列到序列的问题,
在现存的方法中,元学习器的瓶颈是如何去吸收同化利用过去的经验。
注意力机制可以允许在历史中精准摘取某段具体的信息。
Simple Neural Attentive Learner (SNAIL)
组合时序卷积和 soft-attention,
前者从过去的经验整合信息,后者精确查找到某些特殊的信息。
1.1 Preliminaries
1.1.1 时序卷积和 soft-attention
时序卷积 (TCN) 是有因果前后关系的,即在下一时间步生成的值仅仅受之前的时间步影响。
TCN 可以提供更直接,高带宽的传递信息的方法,这允许它们基于一个固定大小的时序内容进行更复杂的计算。
但是,随着序列长度的增加,卷积膨胀的尺度会随之指数增加,需要的层数也会随之对数增加。
因此这种方法对于之前输入的访问更粗略,且他们的有限的能力和位置依赖并不适合元学习器,
因为元学习器应该能够利用增长数量的经验,而不是随着经验的增加,性能会被受限。
soft-attention 可以实现从超长的序列内容中获取准确的特殊信息。
它将上下文作为一种无序的关键值存储,这样就可以基于每个元素的内容进行查询。
但是,位置依赖的缺乏(因为是无序的)也是一个缺点。
TCN 和 soft-attention 可以实现功能互补:
前者提供高带宽的方法,代价是受限于上下文的大小,后者可以基于不确定的可能无限大的上下文提供精准的提取。
因此,SNAIL 的构建使用二者的组合:使用时序卷积去处理用注意力机制提取过的内容。
通过整合 TCN 和 attention,SNAIL 可以基于它过去的经验产出高带宽的处理方法且不再有经验数量的限制。
通过在多个阶段使用注意力机制,端到端训练的 SNAIL 可以学习从收集到的信息中如何摘取自己需要的信息并学习一个恰当的表示。
1.1.2 Meta-Learning
在元学习中每个任务 $\mathcal{T}_{i}$ 都是独立的,
其输入为 $x_{t}$ ,输出为 $a_{t}$ ,损失函数是 $\mathcal{L}_{i}\left(x_{t}, a_{t}\right)$ ,
一个转移分布 $P_{i}\left(x_{t} \mid x_{t-1}, a_{t-1}\right)$ ,和一个输出长度 $H_i$ 。
一个元学习器(由 $\theta$ 参数化)建模分布:
$$ \pi\left(a_{t} \mid x_{1}, \ldots, x_{t} ; \theta\right) $$
给定一个任务的分布 $\mathcal{T}=P\left(\mathcal{T}_{i}\right)$ ,
元学习器的目标是最小化它的期待损失:
$$ \begin{aligned} &\min _{\theta} \mathbb{E}_{\mathcal{T}_{i} \sim \mathcal{T}}\left[\sum_{t=0}^{H_{i}} \mathcal{L}_{i}\left(x_{t}, a_{t}\right)\right] \\ &\text { where } x_{t} \sim P_{i}\left(x_{t} \mid x_{t-1}, a_{t-1}\right), a_{t} \sim \pi\left(a_{t} \mid x_{1}, \ldots, x_{t} ; \theta\right) \end{aligned} $$
元学习器被训练去针对从 $\mathcal{T}$ 中抽样出来的任务 (或一个 mini-batches 的任务) 优化这个期望损失。
在测试阶段,元学习器在新任务分布 $\widetilde{\mathcal{T}}=P\left(\widetilde{\mathcal{T}}_{i}\right)$ 上被评估。
1.2 SNAIL
1.2.1 SNAIL 基础结构
两个时序卷积层(橙色)和一个因果关系层(绿色)的组合是 SNAIL 的基础结构,
如图1所示。
在监督学习设置中,
SNAIL 接收标注样本 $\left(x_{1}, y_{1}\right), \ldots,\left(x_{t-1}, y_{t-1}\right)$ 和末标注的 $\left(x_{t},-\right)$,
然后基于标注样本对 $y_{t}$ 进行预测。
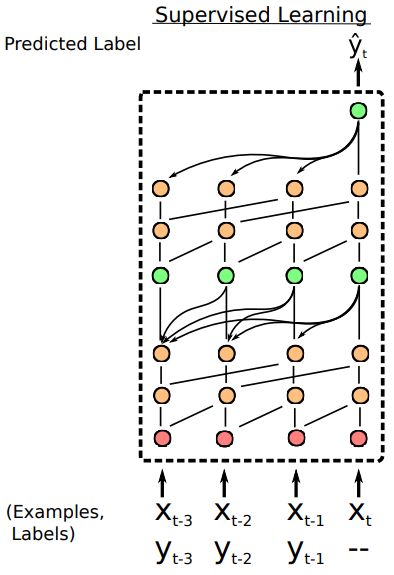
图1 SNAIL 基础结构示意图。
1.2.2 Modular Building Blocks
对于构建 SNAIL 使用了两个主要模块:
Dense Block 和 Attention Block。
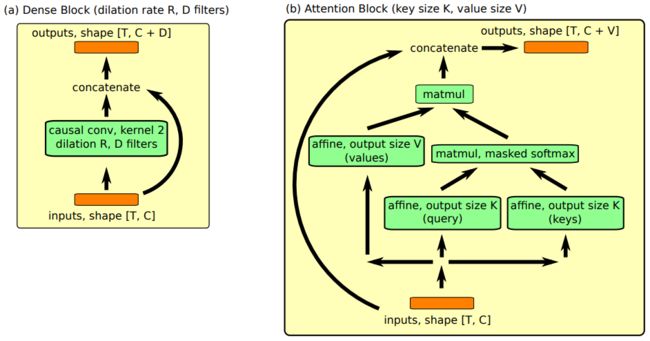
图1 SNAIL 中的 Dense Block 和 Attention Block。(a) Dense Block 应用因果一维卷积,然后将输出连接到输入。TC Block 应用一系列膨胀率呈指数增长的 Dense Block。(b) Attention Block 执行(因果)键值查找,并将输出连接到输入。
Densen Block
用了一个简单的因果一维卷积(空洞卷积),
其中膨胀率 (dilation)为 $R$ 和卷积核数量 $D$ ([1] 对于所有的实验中设置卷积核的大小为2),
最后合并结果和输入。
在计算结果的时候使用了一个门激活函数。
具体算法如下:
function DENSENBLOCK (inuts, dilation rate $R$, number of filers $D$):
- xf, xg = CausalConv (inputs, $R$, $D$), CausalConv (inputs, $R$, $D$)
- activations = tanh (xf) * sigmoid (xg)
- return concat (inputs, activations)
TC Block
由一系列 dense block 组成,这些 dense block 的膨胀率$R$ 呈指数级增长,直到它们的接受域超过所需的序列长度。具体代码实现时,对序列是需要填充的为了保持序列长度不变。具体算法如下:
function TCBLOCK (inuts, sequence length $T$, number of filers $D$):
for i in $1, \ldots, \left[log_2T\right]$ do
1. inputs = DenseBlock (inputs, $2^i$, $D$)- return inputs
Attention Block
[1] 中设计成 soft-attention 机制,
公式为:
$$ \mathrm{ Attention }(Q, K, V)=\mathrm{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V $$
function ATTENTIONBLOCK (inuts, key size $K$, value size $V$):
- keys, query = affine (inputs, $K$), affine (inputs, $K$)
- logits = matmul (query, transpose (keys))
- probs = CausallyMaskedSoftmax ($\mathrm{logits} / \sqrt{K}$)
- values = affine (inputs, $V$)
- read = matmul (probs, values)
- return concat (inputs, read)
1.3 SNAIL 分类结果
表1 SNAIL 在 Omniglot 上的分类结果。
| Method | 5-way 1-shot | 5-way 5-shot | 20-way 1-shot | 20-way 5-shot |
|---|---|---|---|---|
| Santoro et al. (2016) | 82.8 $\%$ | 94.9 $\%$ | -- | -- |
| Koch (2015) | 97.3 $\%$ | 98.4 $\%$ | 88.2 $\%$ | 97.0 $\%$ |
| Vinyals et al. (2016) | 98.1 $\%$ | 98.9 $\%$ | 93.8 $\%$ | 98.5 $\%$ |
| Finn et al. (2017) | 98.7 $\pm$ 0.4 $\%$ | 99.9 $\pm$ 0.3 $\%$ | 95.8 $\pm$ 0.3 $\%$ | 98.9 $\pm$ 0.2 $\%$ |
| Snell et al. (2017) | 97.4 $\%$ | 99.3 $\%$ | 96.0 $\%$ | 98.9 $\%$ |
| Munkhdalai $\&$ Yu (2017) | 98.9 $\%$ | -- | 97.0 $\%$ | -- |
| SNAIL | 99.07 $\pm$ 0.16 $\%$ | 99.78 $\pm$ 0.09 $\%$ | 97.64 $\pm$ 0.30 $\%$ | 99.36 $\pm$ 0.18 $\%$ |
表1 SNAIL 在 miniImageNet 上的分类结果。
| Method | 5-way 1-shot | 5-way 5-shot |
|---|---|---|
| Vinyals et al. (2016) | 43.6 $\%$ | 55.3 $\%$ |
| Finn et al. (2017) | 48.7 $\pm$ 1.84 $\%$ | 63.1 $\pm$ 0.92 $\%$ |
| Ravi $\&$ Larochelle (2017) | 43.4 $\pm$ 0.77 $\%$ | 60.2 $\pm$ 0.71 $\%$ |
| Snell et al. (2017) | 46.61 $\pm$ 0.78 $\%$ | 65.77 $\pm$ 0.70 $\%$ |
| Munkhdalai $\&$ Yu (2017) | 49.21 $\pm$ 0.96 $\%$ | -- |
| SNAIL | 55.71 $\pm$ 0.99 $\%$ | 68.88 $\pm$ 0.92 $\%$ |
- 参考文献
[1] A Simple Neural Attentive Meta-Learner
2.Relation Network(RN)
Relation Network (RN) 使用有监督度量学习估计样本点之间的距离,
根据新样本点和过去样本点之间的距离远近,对新样本点进行分类。
2.1 RN
RN 包括两个组成部分:嵌入模块和关系模块,且两者都是通过有监督学习得到的。
嵌入模块从输入数据中提取特征,关系模块根据特征计算任务之间的距离,
判断任务之间的相似性,找到过去可借鉴的经验进行加权平均。
RN 结构如图1所示。

图1 RN 结构。
嵌入模块记为 $f_{\varphi}$,关系模块记为 $g_{\phi}$,
支持集中的样本记为 $\boldsymbol{x}_{i}$,
查询集中的样本记为 $\boldsymbol{x}_{j}$。
- 将 $\boldsymbol{x}_{i}$ 和 $\boldsymbol{x}_{j}$ 输入 $f_{\varphi}$ ,
产生特征映射 $f_{\varphi}\left(\boldsymbol{x}_{i}\right)$
和 $f_{\varphi}\left(\boldsymbol{x}_{j}\right)$ 。 - 通过运算器 $C(.,.)$ 将 $f_{\varphi}\left(\boldsymbol{x}_{i}\right)$
和 $f_{\varphi}\left(\boldsymbol{x}_{j}\right)$ 结合,
得到 $C(f_{\varphi}\left(\boldsymbol{x}_{i}\right),f_{\varphi}\left(\boldsymbol{x}_{j}\right))$ 。 - 将 $C(f_{\varphi}\left(\boldsymbol{x}_{i}\right),f_{\varphi}\left(\boldsymbol{x}_{j}\right))$ 输入 $g_{\phi}$,
得到 $[0, 1]$ 范围内的标量,
表示 $\boldsymbol{x}_{i}$ 和 $\boldsymbol{x}_{j}$ 之间的相似性,记为关系得分 $r_{i, j}$ 。
$\boldsymbol{x}_{i}$ 和 $\boldsymbol{x}_{j}$ 相似度越高,$r_{i, j}$ 越大。
$$ r_{i, j}=g_{\phi}\left(C\left(f_{\varphi}\left(\boldsymbol{x}_{i}\right), f_{\varphi}\left(\boldsymbol{x}_{j}\right)\right)\right), \ i = 1, 2, ..., C $$
2.2 RN 目标函数
$$ \phi, \varphi \leftarrow \underset{\phi, \varphi}{\arg \min } \sum_{i=1}^{m} \sum_{j=1}^{n}\left(r_{i, j}-1\left(\boldsymbol{y}_{i}==\boldsymbol{y}_{j}\right)\right)^{2} $$
其中, $1\left(\boldsymbol{y}_{i}=\boldsymbol{y}_{j}\right)$ 用来判断 $\boldsymbol{x}_{i}$ 和 $\boldsymbol{x}_{j}$ 是否属于同一类别。
当 $\boldsymbol{y}_{i}=\boldsymbol{y}_{j}$ 时, $1\left(\boldsymbol{y}_{i}==\boldsymbol{y}_{j}\right)=1$,
当 $\boldsymbol{y}_{i} \neq \boldsymbol{y}_{j}$ 时,$1\left(\boldsymbol{y}_{i}==\boldsymbol{y}_{j}\right)=0$ 。
2.3 RN 网络结构
嵌入模块和关系模块的选取有很多种,包括卷积网络、残差网络等。
图2给出了 [1] 中使用的 RN 模型结构。
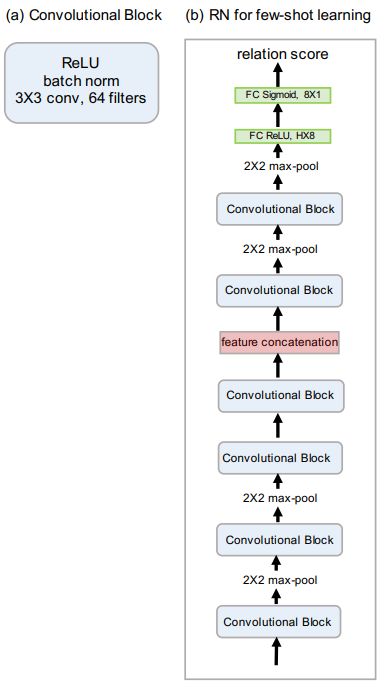
图2 RN 模型结构。
2.3.1 嵌入模块结构
- 每个卷积块分别包含 64 个 3 $\times$ 3 滤波器进行卷积,一个归一化层、一个 ReLU 非线性层。
- 总共有四个卷积块,前两个卷积块包含 2 $\times$ 2 的最大池化层,后边两个卷积块没有池化层。
3.2 关系模块结构
- 有两个卷积块,每个卷积模块中都包含 2 $\times$ 2 的最大池化层。
- 两个全连接层,第一个全连接层是 ReLU 非线性变换,最后的全连接层使用 Sigmoid 非线性变换输出 $r_{i,j}$ 。
2.4 RN 分类结果
表1 RN 在 Omniglot 上的分类结果。
| Model | Fine Tune | 5-way 1-shot | 5-way 5-shot | 20-way 1-shot | 20-way 5-shot |
|---|---|---|---|---|---|
| MANN | N | 82.8 $\%$ | 94.9 $\%$ | -- | -- |
| CONVOLUTIONAL SIAMESE NETS | N | 96.7 $\%$ | 98.4 $\%$ | 88.0 $\%$ | 96.5 $\%$ |
| CONVOLUTIONAL SIAMESE NETS | Y | 97.3 $\%$ | 98.4 $\%$ | 88.1 $\%$ | 97.0 $\%$ |
| MATCHING NETS | N | 98.1 $\%$ | 98.9 $\%$ | 93.8 $\%$ | 98.5 $\%$ |
| MATCHING NETS | Y | 97.9 $\%$ | 98.7 $\%$ | 93.5 $\%$ | 98.7 $\%$ |
| SIAMESE NETS WITH MEMORY | N | 98.4 $\%$ | 99.6 $\%$ | 95.0 $\%$ | 98.6 $\%$ |
| NEURAL STATISTICIAN | N | 98.1 $\%$ | 99.5 $\%$ | 93.2 $\%$ | 98.1 $\%$ |
| META NETS | N | 99.0 $\%$ | -- | 97.0 $\%$ | -- |
| PROTOTYPICAL NETS | N | 98.8 $\%$ | 99.7 $\%$ | 96.0 $\%$ | 98.9 $\%$ |
| MAML | Y | 98.7 $\pm$ 0.4 $\%$ | 99.9 $\pm$ 0.1 $\%$ | 95.8 $\pm$ 0.3 $\%$ | 98.9 $\pm$ 0.2 $\%$ |
| RELATION NET | N | 99.6 $\pm$ 0.2 $\%$ | 99.8 $\pm$ 0.1 $\%$ | 97.6 $\pm$ 0.2 $\%$ | 99.1 $\pm$ 0.1 $\%$ |
表1 RN 在 miniImageNet 上的分类结果。
| Model | FT | 5-way 1-shot | 5-way 5-shot |
|---|---|---|---|
| MATCHING NETS | N | 43.56 $\pm$ 0.84 $\%$ | 55.31 $\pm$ 0.73 $\%$ |
| META NETS | N | 49.21 $\pm$ 0.96 $\%$ | -- |
| META-LEARN LSTM | N | 43.44 $\pm$ 0.77 $\%$ | 60.60 $\pm$ 0.71 $\%$ |
| MAML | Y | 48.70 $\pm$ 1.84 $\%$ | 63.11 $\pm$ 0.92 $\%$ |
| PROTOTYPICAL NETS | N | 49.42 $\pm$ 0.78 $\%$ | 68.20 $\pm$ 0.66 $\%$ |
| RELATION NET | N | 50.44 $\pm$ 0.82 $\%$ | 65.32 $\pm$ 0.70 $\%$ |
- 参考文献
[1] Learning to Compare: Relation Network for Few-Shot Learning
3.Prototypical Network(PN)
Prototypical Network (PN) 利用支持集中每个类别提供的少量样本,
计算它们的嵌入中心,作为每一类样本的原型 (Prototype),
接着基于这些原型学习一个度量空间,
使得新的样本通过计算自身嵌入与这些原型的距离实现最终的分类。
3.1 PN
在 few-shot 分类任务中,
假设有 $N$ 个标记的样本 $S=\left(x_{1}, y_{1}\right), \ldots,\left(x_{N}, y_{N}\right)$ ,
其中, $x_{i} \in$ $\mathbb{R}^{D}$ 是 $D$ 维的样本特征向量,
$y \in 1, \ldots, K$ 是相应的标签。
$S_{K}$ 表示第 $k$ 类样本的集合。
PN 计算每个类的 $M$ 维原型向量 $c_{k} \in \mathbb{R}^{M}$ ,
计算的函数为 $f_{\phi}: \mathbb{R}^{D} \rightarrow \mathbb{R}^{M}$ ,
其中 $\phi$ 为可学习参数。
原型向量 $c_{k}$ 即为嵌入空间中该类的所有 支持集样本点的均值向量
$$ c_{k}=\frac{1}{\left|S_{K}\right|} \sum_{\left(x_{i}, y_{i}\right) \in S_{K}} f_{\phi}\left(x_{i}\right) $$
给定一个距离函数 $d: \mathbb{R}^{M} \times \mathbb{R}^{M} \rightarrow[0,+\infty)$ ,
不包含任何可训练的参数,
PN 通过在嵌入空间中对距离进行 softmax 计算,
得到一个针对 $x$ 的样本点的概率分布
$$ p_{\phi}(y=k \mid x)=\frac{\exp \left(-d\left(f_{\phi}(x), c_{k}\right)\right)}{\sum_{k^{\prime}} \exp \left(-d\left(f_{\phi}(x), c_{k^{\prime}}\right)\right)} $$
新样本点的特征离类别中心点越近,
新样本点属于这个类别的概率越高;
新样本点的特征离类别中心点越远,
新样本点属于这个类别的概率越低。
通过在 SGD 中最小化第 $k$ 类的负对数似然函数 $J(\phi)$ 来推进学习
$$ J(\phi)= \underset{\phi}{\operatorname{argmin}}\left(\sum_{k=1}^{K}-\log \left(p_{\phi}\left(\boldsymbol{y}=k \mid \boldsymbol{x}_{k}\right)\right)\right) $$
PN 示意图如图1所示。

图1 PN 示意图。
3.2 PN 算法流程
Input: Training set $\mathcal{D}=\left\{\left(\mathbf{x}_{1}, y_{1}\right), \ldots,\left(\mathbf{x}_{N}, y_{N}\right)\right\}$, where each $y_{i} \in\{1, \ldots, K\}$. $\mathcal{D}_{k}$ denotes the subset of $\mathcal{D}$ containing all elements $\left(\mathbf{x}_{i}, y_{i}\right)$ such that $y_{i}=k$.
Output: The loss $J$ for a randomly generated training episode.
- select class indices for episode: $V \leftarrow \text { RANDOMSAMPLE }\left(\{1, \ldots, K\}, N_{C}\right)$
for $k$ in $\left\{1, \ldots, N_{C}\right\}$ do
- select support examples: $S_{k} \leftarrow \text { RANDOMSAMPLE }\left(\mathcal{D}_{V_{k}}, N_{S}\right)$
- select query examples: $Q_{k} \leftarrow \text { RANDOMSAMPLE }\left(\mathcal{D}_{V_{k}} \backslash S_{k}, N_{Q}\right)$
- compute prototype from support examples: $c_k \leftarrow \frac{1}{N_{C}} \sum_{\left(\mathbf{x}_{i}, y_{i}\right) \in S_{k}} f_{\phi}\left(\mathbf{x}_{i}\right)$
- end for
- $J \leftarrow 0$
for $k$ in $\left\{1, \ldots, N_{C}\right\}$ do
- for $x, y$ in $Q_{k}$ do
- update loss $\left.J \leftarrow J+\frac{1}{N_{C} N_{Q}}\left[d\left(f_{\phi}(\mathbf{x}), \mathbf{c}_{k}\right)\right)+\log \sum_{k^{\prime}} \exp \left(-d\left(f_{\phi}(\mathbf{x}), \mathbf{c}_{k^{\prime}}\right)\right)\right]$
- end for
- end for
其中,
- $N$ 是训练集中的样本个数;
- $K$ 是训练集中的类个数;
- $N_{C} \leq K$ 是每个 episode 选出的类个数;
- $N_{S}$ 是每类中 support set 的样本个数;
- $N_{Q}$ 是每类中 query set 的样本个数;
- $\mathrm{RANDOMSAMPLE}(S, N)$ 表示从集合 $\mathrm{S}$ 中随机选出 $\mathrm{N}$ 个元素。
3.3 PN 分类结果
表1 PN 在 Omniglot 上的分类结果。
| Model | Dist. | Fine Tune | 5-way 1-shot | 5-way 5-shot | 20-way 1-shot | 20-way 5-shot |
|---|---|---|---|---|---|---|
| MATCHING NETWORKS | Cosine | N | 98.1 $\%$ | 98.9 $\%$ | 93.8 $\%$ | 98.5 $\%$ |
| MATCHING NETWORKS | Cosine | Y | 97.9 $\%$ | 98.7 $\%$ | 93.5 $\%$ | 98.7 $\%$ |
| NEURAL STATISTICIAN | - | N | 98.1 $\%$ | 99.5 $\%$ | 93.2 $\%$ | 98.1 $\%$ |
| MAML | - | N | 98.7 $\%$ | 99.9 $\%$ | 95.8 $\%$ | 98.9 $\%$ |
| PROTOTYPICAL NETWORKS | Euclid. | N | 98.8 $\%$ | 99.7 $\%$ | 96.0 $\%$ | 98.9 $\%$ |
表1 PN 在 miniImageNet 上的分类结果。
| Model | Dist. | Fine Tune | 5-way 1-shot | 5-way 5-shot |
|---|---|---|---|---|
| BASELINE NEAREST NEIGHBORS | Cosine | N | 28.86 $\pm$ 0.54 $\%$ | 49.79 $\pm$ 0.79 $\%$ |
| MATCHING NETWORKS | Cosine | N | 43.40 $\pm$ 0.78 $\%$ | 51.09 $\pm$ 0.71 $\%$ |
| MATCHING NETWORKS (FCE) | Cosine | N | 43.56 $\pm$ 0.84 $\%$ | 55.31 $\pm$ 0.73 $\%$ |
| META-LEARNER LSTM | - | N | 43.44 $\pm$ 0.77 $\%$ | 60.60 $\pm$ 0.71 $\%$ |
| MAML | - | N | 48.70 $\pm$ 1.84 $\%$ | 63.15 $\pm$ 0.91 $\%$ |
| PROTOTYPICAL NETWORKS | Euclid. | N | 49.42 $\pm$ 0.78 $\%$ | 68.20 $\pm$ 0.66 $\%$ |
- 参考文献
[1] Prototypical Networks for Few-shot Learning
4.Matching Network(MN)
Matching Network (MN)
结合了度量学习 (Metric Learning) 与记忆增强神经网络 (Memory Augment Neural Networks),
并利用注意力机制与记忆机制加速学习,同时提出了 set-to-set 框架,
使得 MN 能够为新类产生合理的测试标签,且不用网络做任何改变。
4.1 MN
将支持集 $S=\left\{\left(x_{i}, y_{i}\right)\right\}_{i=1}^{k}$
映射到一个分类器 $c_{S}(\hat{x})$ ,
给定一个测试样本 $\hat{x}$ ,$c_{S}(\hat{x})$ 定义一个关于输出 $\hat{y}$ 的概率分布,即
$$ S \rightarrow c_{S}\left(\hat{x}\right):= P\left(\hat{y} \mid \hat{x}, S\right) $$
其中, $P$ 被网络参数化。
因此,当给定一个新的支持集 $S^{\prime}$ 进行小样本学习时,
只需使用 $P$ 定义的网络来预测每个测试示例 $\hat{x}$ 的适当标签分布
$P\left(\hat{y} \mid \hat{x}, S^{\prime}\right)$ 即可。
4.1.1 注意力机制
模型以最简单的形式计算 $\hat{y}$ 上的概率:
$$ P(\hat{y} \mid \hat{x}, S)=\sum_{i=1}^{k} a\left(\hat{x}, x_{i}\right) y_{i} $$
上式本质是将一个输入的新类描述为支持集中所有类的一个线性组合,
结合了核密度估计KDE( $a$ 可以看做是一种核密度估计)和 KNN 。
其中, $k$ 表示支持集中样本类别数,
$a\left(\hat{x}, x_{i}\right)$ 是注意力机制,
类似 attention 模型中的核函数,
用来度量 $\hat{x}$ 和训练样本 $x_{i}$ 的匹配度。
$a$ 的计算基于新样本数据与支持集中的样本数据的嵌入表示的余弦相似度以及softmax函数:
$$ a\left(\hat{x}, x_{i}\right)=\frac{e^{c\left(f(\hat{x}), g\left(x_{i}\right)\right)}}{\sum_{j=1}^{k} e^{c\left(f(\hat{x}), g\left(x_{j}\right)\right)}} $$
其中, $c(\cdot)$ 表示余弦相似度,
$f$ 与 $g$ 表示施加在测试样本与训练样本上的嵌入函数 (Embedding Function)。
如果注意力机制是 $X \times X$ 上的核,
则上式类似于核密度估计器。
如果选取合适的距离度量以及适当的常数,
从而使得从 $x_{i}$ 到 $\hat{x}$ 的注意力机制为 0 ,
则上式等价于 KNN 。
图1是 MN 的网络结构示意图。
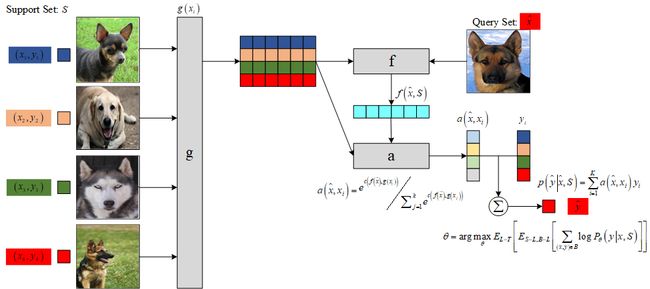
图1 MN 示意图。
4.1.2 Full Context Embeddings
为了增强样本嵌入的匹配度,
[1] 提出了 Full Context Embeeding (FCE) 方法:
支持集中每个样本的嵌入应该是相互独立的,
而新样本的嵌入应该受支持集样本数据分布的调控,
其嵌入过程需要放在整个支持集环境下进行,
因此 [1] 采用带有注意力的 LSTM 网络对新样本进行嵌入。
在对余弦注意力定义时,
每个已知标签的输入 $x_i$ 通过 CNN 后的 embedding ,
因此 $g(x_i)$ 是独立的,前后没有关系,
然后与 $f\left(\hat{x}\right)$ 进行逐个对比,
并没有考虑到输入任务 $S$ 改变 embedding $\hat{x}$ 的方式,
而 $f(\cdot)$ 应该是受 $g(S)$ 影响的。
为了实现这个功能,[1] 采用了双向 LSTM 。
在通过嵌入函数 $f$ 和 $g$ 处理后,
输出再次经过循环神经网络进一步加强 context 和个体之间的关系。
$$ f\left(\hat{x},S\right)=\mathrm{attLSTM}\left(f'\left(\hat{x}\right),g(S),K\right) $$
其中, $S$ 是相关的上下文, $K$ 为网络的 timesteps 。
因此,经过 $k$ 步后的状态为:
$$ \begin{aligned} & \hat{h}_{k}, c_{k} =\operatorname{LSTM}\left(f^{\prime}(\hat{x}),\left[h_{k-1}, r_{k-1}\right], c_{k-1}\right) \\ & h_{k} =\hat{h}_{k}+f^{\prime}(\hat{x}) \\ & r_{k-1} =\sum_{i=1}^{|S|} a\left(h_{k-1}, g\left(x_{i}\right)\right) g\left(x_{i}\right) \\ & a\left(h_{k-1}, g\left(x_{i}\right)\right) =e^{h_{k-1}^{T} g\left(x_{i}\right)} / \sum_{j=1}^{|S|} e^{h_{k-1}^{T} g\left(x_{j}\right)} \end{aligned} $$
4.2 网络结构
特征提取器可采用常见的 VGG 或 Inception 网络,
[1] 设计了一种简单的四级网络结构用于图像分类任务的特征提取,
每级网络由一个 64 通道的 3 $\times$ 3 卷积层,一个批规范化层,
一个 ReLU 激活层和一个 2 $\times$ 2 的最大池化层构成。
然后将最后一层输出的特征输入到 LSTM 网络中得到最终的特征映射
$f\left(\hat{x},S\right)$ 和 $g\left({x_i},S\right)$ 。
4.3 损失函数
$$ \theta=\arg \max _{\theta} E_{L \sim T}\left[E_{S \sim L, B \sim L}\left[\sum_{(x, y) \in B} \log P_{\theta}(y \mid x, S)\right]\right] $$
4.4 MN 算法流程
- 将任务 $S$ 中所有图片 $x_i$ (假设有 $K$ 个)和目标图片 $\hat{x}$(假设有 1 个)
全部通过 CNN 网络,获得它们的浅层变量表示。 - 将( $K+1$ 个)浅层变量全部输入到 BiLSTM 中,获得 $K+1$ 个输出,
然后使用余弦距离判断前 $K$ 个输出中每个输出与最后一个输出之间的相似度。 - 根据计算出来的相似度,按照任务 $S$ 中的标签信息 $y_1, y_2, \ldots, y_K$
求解目标图片 $\hat{x}$ 的类别标签 $\hat{y}$。
4.5 MN 分类结果
表1 MN 在 Omniglot 上的分类结果。
| Model | Matching Fn | Fine Tune | 5-way 1-shot | 5-way 5-shot | 20-way 1-shot | 20-way 5-shot |
|---|---|---|---|---|---|---|
| PIXELS | Cosine | N | 41.7 $\%$ | 63.2 $\%$ | 26.7 $\%$ | 42.6 $\%$ |
| BASELINE CLASSIFIER | Cosine | N | 80.0 $\%$ | 95.0 $\%$ | 69.5 $\%$ | 89.1 $\%$ |
| BASELINE CLASSIFIER | Cosine | Y | 82.3 $\%$ | 98.4 $\%$ | 70.6 $\%$ | 92.0 $\%$ |
| BASELINE CLASSIFIER | Softmax | Y | 86.0 $\%$ | 97.6 $\%$ | 72.9 $\%$ | 92.3 $\%$ |
| MANN (NO CNOV) | Cosine | N | 82.8 $\%$ | 94.9 $\%$ | -- | -- |
| CONVOLUTIONAL SIAMESE NET | Cosine | Y | 96.7 $\%$ | 98.4 $\%$ | 88.0 $\%$ | 96.5 $\%$ |
| CONVOLUTIONAL SIAMESE NET | Cosine | Y | 97.3 $\%$ | 98.4 $\%$ | 88.1 $\%$ | 97.0 $\%$ |
| MATCHING NETS | Cosine | N | 98.1 $\%$ | 98.9 $\%$ | 93.8 $\%$ | 98.5 $\%$ |
| MATCHING NETS | Cosine | Y | 97.9 $\%$ | 98.7 $\%$ | 93.5 $\%$ | 98.7 $\%$ |
表1 MN 在 miniImageNet 上的分类结果。
| Model | Matching Fn | Fine Tune | 5-way 1-shot | 5-way 5-shot |
|---|---|---|---|---|
| PIXELS | Cosine | N | 23.0 $\%$ | 26.6 $\%$ |
| BASELINE CLASSIFIER | Cosine | N | 36.6 $\%$ | 46.0 $\%$ |
| BASELINE CLASSIFIER | Cosine | Y | 36.2 $\%$ | 52.2 $\%$ |
| BASELINE CLASSIFIER | Cosine | Y | 38.4 $\%$ | 51.2 $\%$ |
| MATCHING NETS | Cosine | N | 41.2 $\%$ | 56.2 $\%$ |
| MATCHING NETS | Cosine | Y | 42.4 $\%$ | 58.0 $\%$ |
| MATCHING NETS | Cosine (FCE) | N | 44.2 $\%$ | 57.0 $\%$ |
| MATCHING NETS | Cosine (FCE) | Y | 46.6 $\%$ | 60.0 $\%$ |
4.6 创新点
- 采用匹配的形式实现小样本分类任务,
引入最近邻算法的思想解决了深度学习算法在小样本的条件下无法充分优化参数而导致的过拟合问题,
且利用带有注意力机制和记忆模块的网络解决了普通最近邻算法过度依赖度量函数的问题,
将样本的特征信息映射到更高维度更抽象的特征空间中。 - one-shot learning 的训练策略,一个训练任务中包含支持集和 Batch 样本。
4.7 算法评价
- MN 受到非参量化算法的限制,
随着支持集 $S$ 的增长,每次迭代的计算量也会随之快速增长,导致计算速度降低。 - 在测试时必须提供包含目标样本类别在内的支持集,
否则它只能从支持集所包含的类别中选择最为接近的一个输出其类别,而不能输出正确的类别。 - 参考文献
[1] Matching Networks for One Shot Learning
更多优质内容请关注公号:汀丶人工智能
